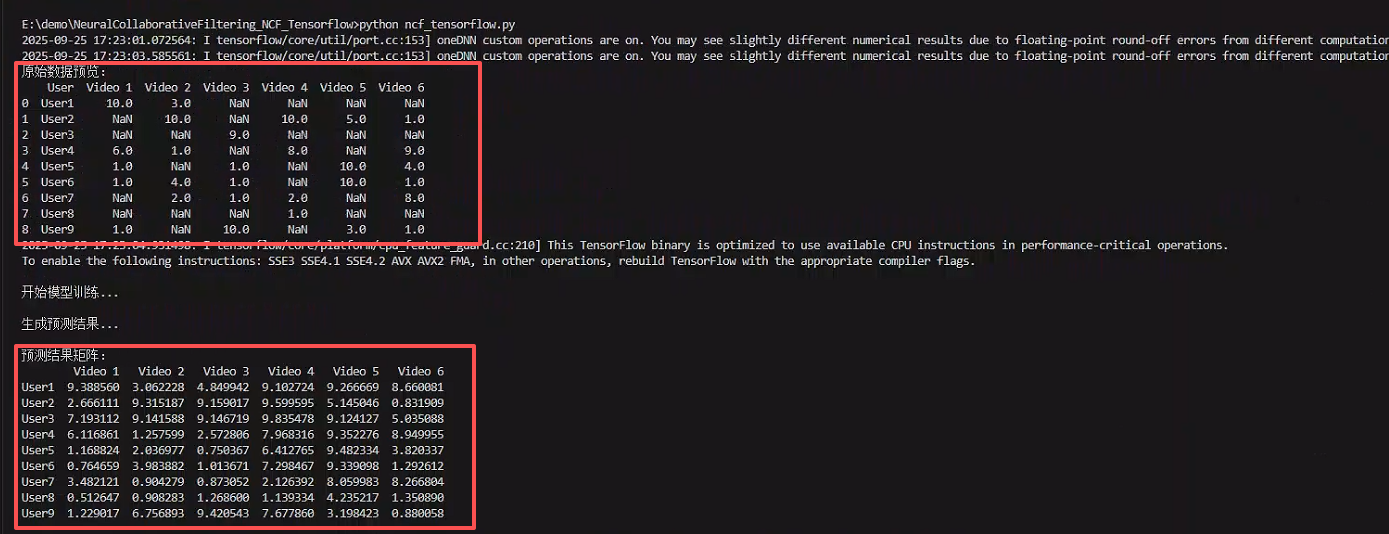
测试数据(我是在本地存了个文件,记得修改自己测试数据文件的路径):
User,Video 1,Video 2,Video 3,Video 4,Video 5,Video 6
User1,10,3,,,,
User2,,10,,10,5,1
User3,,,9,,,
User4,6,1,,8,,9
User5,1,,1,,10,4
User6,1,4,1,,10,1
User7,,2,1,2,,8
User8,,,,1,,
User9,1,,10,,3,1相关库准备:
若直接安装
scikit(如pip install scikit),会错误安装非官方包(如scikit 0.0.post1),导致功能缺失或报错。正确安装命令应为pip install scikit-learn
python
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder调用数据:
python
# 设置Pandas显示选项:显示所有列且不换行
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
# 数据加载与预处理
data = pd.read_csv('data/test-data.csv') # 读取用户-视频评分数据
print("原始数据预览:")
print(data) # 打印原始数据便于检查数据预处理阶段:
保存原始用户ID(第一列)
重置索引为数字序列
将第一列替换为数字索引
python
user_index = data[data.columns[0]] # 保存原始用户ID
video_index = data.columns # 保存视频列名
data = data.reset_index(drop=True) # 重置索引
data[data.columns[0]] = data.index.astype('int') # 将用户ID列转为数字索引
scaler = 10 # 评分缩放因子 适用于已知评分范围固定(如1-10分制)的简单场景数据重塑:
将宽格式数据转为长格式(user_id, video_id, rating)
python
df_long = pd.melt(data,
id_vars=[data.columns[0]], # 保留用户ID列
ignore_index=True, # 忽略原始索引
var_name='video_id', # 视频ID列名
value_name='rate').dropna() # 删除缺失值
df_long.columns = ['user_id', 'video_id', 'rating'] # 重命名列
df_long['rating'] = df_long['rating'] / scaler # 评分归一化
df_long['user_id'] = df_long['user_id'].apply(lambda x: user_index[x]) # 恢复原始用户ID
dataset = df_long # 最终数据集将用户ID和视频ID转换为模型可处理的数字标签:
python
user_encoder = LabelEncoder() # 用户ID编码器
video_encoder = LabelEncoder() # 视频ID编码器
dataset['user_id'] = user_encoder.fit_transform(dataset['user_id'])
dataset['video_id'] = video_encoder.fit_transform(dataset['video_id'])
# 使用全部数据作为训练集(未划分测试集)
train = dataset超参设置及选择嵌入维度
python
num_users = len(dataset['user_id'].unique()) # 唯一用户数量
num_videos = len(dataset['video_id'].unique()) # 唯一视频数量
# embedding_dim = 32 # 嵌入层维度
embedding_dim = 64 # 嵌入层维度基本准备阶段结束,进入模型配置:
神经网络协同过滤模型架构:
输入层:分别接收用户ID和视频ID
嵌入层:将ID映射为稠密向量
特征融合:连接两个嵌入向量
全连接层:学习非线性特征交互
输出层:预测评分
python
# 输入层
inputs_user = tf.keras.layers.Input(shape=(1,), name='user_input') # 用户ID输入
inputs_video = tf.keras.layers.Input(shape=(1,), name='video_input') # 视频ID输入
# 嵌入层
embedding_user = tf.keras.layers.Embedding(
num_users, embedding_dim, name='user_embedding')(inputs_user)
embedding_video = tf.keras.layers.Embedding(
num_videos, embedding_dim, name='video_embedding')(inputs_video)
# 特征融合层 Concatenate优势- 保留更多特征信息便于后续全连接层学习复杂交互
merged = tf.keras.layers.Concatenate(name='concat_embeddings')(
[embedding_user, embedding_video])
merged = tf.keras.layers.Flatten(name='flatten_features')(merged)
# 全连接层
dense = tf.keras.layers.Dense(64, activation='relu', name='dense_1')(merged)
dense = tf.keras.layers.Dense(32, activation='relu', name='dense_2')(dense)
output = tf.keras.layers.Dense(1, activation='sigmoid', name='output')(dense)
# 模型编译 mse对异常值敏感
model = tf.keras.Model(inputs=[inputs_user, inputs_video], outputs=output)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])开始训练模型:
python
print("\n开始模型训练...")
model.fit(
[train['user_id'].values, train['video_id'].values],
train['rating'].values,
batch_size=64,
epochs=100,
verbose=0,
# validation_split=0.1,
)应用模型进行评分:
python
result_df = {}
for user_i in range(1, 10):
user = f'User{user_i}'
result_df[user] = {}
for video_i in range(1, 7):
video = f'Video {video_i}'
# 编码用户和视频ID
pred_user_id = user_encoder.transform([user])
pred_video_id = video_encoder.transform([video])
# 进行预测
result = model.predict(x=[pred_user_id, pred_video_id], verbose=0)
result_df[user][video] = result[0][0] # 保存预测结果转换结果格式并输出:
python
# 结果后处理
result_df = pd.DataFrame(result_df).T # 转为DataFrame格式
result_df *= scaler # 反归一化恢复原始评分范围
print("\n预测结果矩阵:")
print(result_df)本地输出打印成功展示: