文章目录
- 一、前言
- [二、String 字符串](#二、String 字符串)
-
- [2.1 常用 String 命令](#2.1 常用 String 命令)
- [2.2 String 的存储结构](#2.2 String 的存储结构)
- [2.3 String 应用场景](#2.3 String 应用场景)
- [三、List 列表](#三、List 列表)
-
- [3.1 常用 List 命令](#3.1 常用 List 命令)
- [3.2 List 的存储结构](#3.2 List 的存储结构)
- [3.3 List 应用场景](#3.3 List 应用场景)
- [四、Hash 哈希](#四、Hash 哈希)
-
- [4.1 常用 Hash 命令](#4.1 常用 Hash 命令)
- [4.2 Hash 的存储结构](#4.2 Hash 的存储结构)
- [4.3 Hash 应用场景](#4.3 Hash 应用场景)
- [五、Set 无序集合](#五、Set 无序集合)
-
- [5.1 常用 Set 命令](#5.1 常用 Set 命令)
- [5.2 Set 应用场景](#5.2 Set 应用场景)
- [六、ZSet 有序集合](#六、ZSet 有序集合)
-
- [6.1 常用 Zset 命令](#6.1 常用 Zset 命令)
- [6.2 Zset 应用场景](#6.2 Zset 应用场景)
一、前言
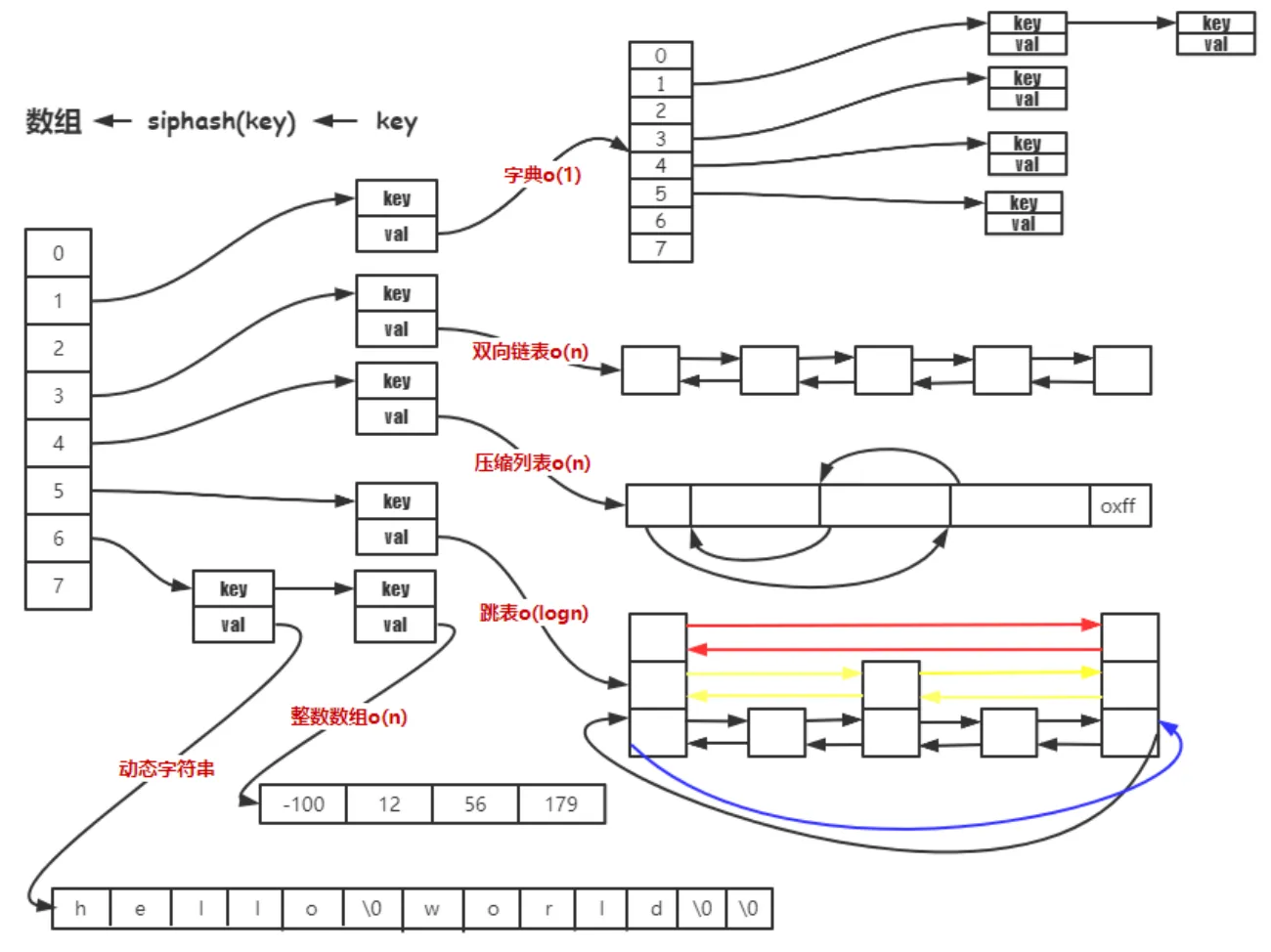
Redis 提供了多种核心数据结构,每种都有不同的特点和适用场景:
- String:是带长度信息的二进制安全字符串,既能存储文本,也能存储任意二进制数据。
- List:双端链表结构,按插入顺序有序,支持队列和栈操作,但不去重。
- Hash:由 field-value 组成的字典,field 唯一,适合存储对象属性,有去重作用。
- Set:无序集合,元素唯一,自动去重,不保证顺序。
- ZSet :有序集合,元素唯一,通过
member保证唯一性,通过score排序,既去重又能按权重排序。
| 数据类型 | 是否有序 | 元素是否唯一 | 底层特性/用途 | 去重情况 |
|---|---|---|---|---|
| String | 否 | - | 二进制安全字符串,支持文本/二进制 | 不涉及 |
| List | 有序(插入顺序) | 否 | 双端队列,支持队列/栈操作 | 不去重 |
| Hash | 否 | field 唯一 | 字典结构,适合存储对象属性 | field 去重 |
| Set | 无序 | 是 | 集合结构,元素唯一 | 元素自动去重 |
| ZSet | 有序(按 score) | 是 | 有序集合,元素唯一且按 score 排序 | 元素自动去重 |
二、String 字符串
String 是 Redis 最基本的数据类型,它是二进制安全的,可以存储任何类型的数据,包括文本、数字、序列化的对象或二进制数据。String 值的最大长度为 512MB。
2.1 常用 String 命令
基本操作命令:
cs
# 基本操作
SET key value
GET key
DEL key
# 计数操作
INCR key
INCRBY key increment
DECR key
DECRBY key decrement
# 条件设置
SETNX key value # 仅当 key 不存在时设置
SETEX key seconds value # 设置值并指定过期时间位操作命令(常用来实现签到 bitmap):
cs
# 设置或清除 key 的 value 在 offset 处的 bit 值
SETBIT key offset value
# 获取 key 的 value 在 offset 处的 bit 值
GETBIT key offset
# 统计字符串被设置为 1 的 bit 数
BITCOUNT key [start end]2.2 String 的存储结构
Redis 根据字符串的内容和长度选择不同的存储方式:
- int:字符串长度 ≤ 20 且可以转换为整数时使用(节省空间、运算快)
- embstr:字符串长度 ≤ 44 时使用,对象和字符串内存一次性分配,内存分配和访问效率高
- raw:字符串长度 > 44 时使用,标准的动态字符串(独立分配字符串)
2.3 String 应用场景
1. 对象存储
bash
# 存储 JSON 格式的对象
SET user:10001 '{"name":"gulu","sex":"female","age":100}'
# 获取对象
GET user:10001对象在应用层序列化成字符串后,Redis 只负责存储,读写 Redis 时就像操作一个字符串一样。不需要额外设计数据结构,实现简单,而且 JSON 天然跨语言,任何语言都能解析,因此在不同环境下迁移方便。
但它的缺点也很明显:
- 更新不方便 :如果要改
age,必须先把整个 JSON 取出来,应用层解析成对象,再改字段,改完再序列化写回 Redis。 - 无法局部修改:Redis 本身不能直接定位 JSON 中的某个字段。
- 占内存略多:JSON 文本比结构化存储更占空间。
这种方式更适合字段固定、不常变动的对象缓存,主要是"存一下,再整体读出来"的使用方式,比如缓存一篇文章的完整内容、一个角色的静态信息。而对于需要频繁更新、且常常只改某个字段的情况,用 Redis 的 Hash 类型会更合适,因为它支持对单个属性的高效读写。
2. 累加器(计数器)
String 可以直接进行自增、自减操作,非常适合用来做计数。适用于文章阅读数、视频播放量、点赞数、库存数等需要累加/递增的场景。
sh
# 统计文章阅读数:每次阅读 +1
incr article:1001:reads
# 一次增加 100
incrby article:1001:reads 1003. 分布式锁
利用 SETNX(set if not exists)+ 过期时间,可以实现简单的分布式锁。适用于在分布式系统中,防止多个进程/服务同时操作同一个资源(例如订单创建、库存扣减)。
cs
# 加锁:只有当 lock 键不存在时才能成功设置,并自动过期 30 秒
set lock:order123 "uuid-abc" nx ex 30
# 释放锁(注意要判断是不是自己加的锁)
if (get lock:order123 == "uuid-abc") {
del lock:order123
}4. 位运算(Bitmaps)
通过 setbit/getbit/bitcount,可以用一个字符串高效表示大量布尔状态,非常省空间。高效存储布尔信息,适合签到、活跃度、状态统计。
cs
# 用户 10001 在 2021 年 6 月 1 日签到
setbit sign:10001:202106 1 1
# 统计该用户 6 月签到天数
bitcount sign:10001:202106
# 查看 6 月 2 日是否签到(1=已签到,0=未签到)
getbit sign:10001:202106 2三、List 列表
List 是一个双向链表结构,支持从列表两端进行高效的插入和删除操作。在列表头部或尾部操作的时间复杂度为 O(1),查找中间元素的时间复杂度为 O(n)。
3.1 常用 List 命令
cs
# 两端操作
LPUSH key value [value ...]
RPUSH key value [value ...]
LPOP key
RPOP key
# 返回从队列的 start 和 stop 之间的元素
LRANGE key start stop
# 获取列表中指定下标的元素。
LINDEX key index
# 返回列表的长度(即有多少个元素)
LLEN key
# LPOP 的阻塞版本,这个命令会在给定 list 无法弹出任何元素的时候阻塞连接
BLPOP key [key ...] timeout
BRPOP key [key ...] timeout
# 从存于 key 的列表里移除前 count 次出现的值为 value 的元素
LREM key count value
# 截取列表,只保留指定范围的元素,其余的都会被删除。
LTRIM key start stop-
参数说明:
start:起始下标(从 0 开始)。stop:结束下标(包含 stop 位置的元素)。
-
下标规则:
- 下标从 0 开始。
-1表示最后一个元素,-2表示倒数第二个,以此类推。
-
brpop 阻塞:
- 当链表中没有数据时,请求连接会被挂起,连接被阻塞
- 需要从另一个连接往里面 push 数据,让链表不为空
- 这时候被阻塞的连接才会解除阻塞并返回
3.2 List 的存储结构
Redis 从 3.2 起把 list 的底层改为 quicklist 。quicklist 可以理解为:由多个 ziplist 节点串起来的双向链表。这样既能保持链表在首尾插入/删除的高效性,又能通过 ziplist 节点把多个元素紧凑存储在连续内存中,减少指针开销,从而节省大量内存。
- 当元素数量较少或元素较小时,使用 ziplist 存储以节省内存
- 当元素数量较多或元素较大时,使用双向链表存储以保证性能
配置参数:
list-max-ziplist-size:决定何时从 ziplist 转换为链表list-compress-depth:列表压缩深度,0 表示不压缩
quicklist 源码:
c
/* Minimum ziplist size in bytes for attempting compression. */
#define MIN_COMPRESS_BYTES 48
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small
*/
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all
ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual
nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to
compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;quicklist 的每个节点(quicklistNode)都包含一些关键字段:
- 指向前后节点的指针(保证双向链表结构)。
zl:存放数据的 ziplist(紧凑数组)。sz:当前 ziplist 的字节大小。count:当前 ziplist 存放的元素个数。encoding:标记是否压缩(RAW 表示未压缩,LZF 表示使用 LZF 算法压缩)。
在压缩策略上,Redis 会根据配置和元素大小来决定是否对节点进行压缩:
- 如果元素长度 小于 48 字节,一般不压缩(因为压缩反而浪费 CPU)。
- 如果压缩前后大小差距 不超过 8 字节,也不压缩(因为收益太小)。
- 其余情况会用 LZF 算法压缩,以达到节省内存的效果。
3.3 List 应用场景
1. 栈(先进后出 FILO)
cs
# LPUSH + LPOP 或 RPUSH + RPOP
LPUSH mystack "item1"
LPUSH mystack "item2"
LPOP mystack # 返回 "item2"2. 队列(先进先出 FIFO):
cs
# LPUSH + RPOP 或 RPUSH + LPOP
LPUSH myqueue "item1"
LPUSH myqueue "item2"
RPOP myqueue # 返回 "item1"3. 阻塞队列(blocking queue):
cs
# 生产者
LPUSH tasks "task1"
# 消费者(阻塞等待任务)
BRPOP tasks 30 # 30秒超时4. 获取固定窗口记录(战绩):
cs
# 在某些业务场景下,需要获取固定数量的记录;比如获取最近50条战绩;这些记录需要按照插入的先后顺序返回;
# 添加新记录
LPUSH user:10001:activities "activity at $(date)"
# 保持最近50条记录
LTRIM user:10001:activities 0 49
# 查看所有记录
LRANGE user:10001:activities 0 -1为了保证命令的原子性,通常使用 Lua 脚本或 Pipeline 执行多个命令:
bash
-- Lua 脚本实现原子操作
local record = KEYS[1]
redis.call("LPUSH", "user:activities", record)
redis.call("LTRIM", "user:activities", 0, 49)
return redis.call("LRANGE", "user:activities", 0, -1)四、Hash 哈希
Redis Hash 就像一个小型的字典,里面存放的是 字段(field)和值(value) 。它最适合用来表示对象:比如你要存一个用户,可以把 name、age、gender 分别作为字段保存。这样,Redis 的一个 key(如 user:1001)就能对应整个用户对象。
sh
HSET user:1001 name "gulu"
HSET user:1001 age 21
HSET user:1001 gender "female"和把对象整体存成 JSON 字符串相比,Hash 更灵活:
- 可以只修改某一个字段(比如直接更新
age),不用先取出整个对象再写回。 - Redis 在存储小字段时会自动用紧凑的方式节省内存。
- 支持直接对字段进行增删改查,效率高,也更方便。
另外,Hash 的容量非常大,每个 Hash 可以存储 2^32 - 1 个字段值对(40 多亿)。
4.1 常用 Hash 命令
cs
# 字段操作
HSET key field value # 设置哈希中指定字段的值
HGET key field # 获取哈希中指定字段的值
HDEL key field [field ...] # 删除哈希中指定的字段
# 批量操作
HMSET key field value [field value ...] # 设置多个哈希字段值
HMGET key field [field ...] # 获取多个哈希字段值
HGETALL key # 获取哈希中所有字段和值
# 计数操作
HINCRBY key field increment # 为哈希中指定字段的值增加整数
# 获取哈希中字段的数量
HLEN key
# 返回 Hash 中所有字段的名字
HKEYS key
# 返回 Hash 中所有字段对应的值
HVALS key
# 判断 Hash 中是否存在某个字段,存在返回1,不存在返回0
HEXISTS key field示例:
cs
127.0.0.1:6379> hmset user:10001 name gulu age 21 weight 200
OK
127.0.0.1:6379> hgetall user:10001
1) "name"
2) "gulu"
3) "age"
4) "21"
5) "weight"
6) "200"
127.0.0.1:6379> HINCRBY user:10001 weight 100
(integer) 3004.2 Hash 的存储结构
Redis 根据 Hash 的大小和内容选择存储方式:
-
ziplist :当字段数量 ≤
hash-max-ziplist-entries(默认512)且所有字段和值的字符串长度都 ≤hash-max-ziplist-value(默认64)时使用。 -
hashtable:当不满足上述条件时使用,即标准的哈希表实现,操作更快但占用更多内存。
4.3 Hash 应用场景
1. 对象存储
cs
# 存储用户信息
HMSET user:10001 name "gulu" age 99 sex "female"
# 获取用户信息
HGETALL user:10001
# 修改用户年龄
HSET user:10001 age 1002. 购物车实现
cs
# 将用户id作为 key
# 商品id作为 field
# 商品数量作为 value
# 注意:这些物品是按照我们添加顺序来显示的;
# 添加商品:
hmset MyCart:10001 40001 1 cost 5099 desc "戴尔笔记本14-3400"
lpush MyItem:10001 40001
# 增加数量:
hincrby MyCart:10001 40001 1
# 减少商品数量
hincrby MyCart:10001 40001 -1
# 获取购物车商品数量
hlen MyCart:10001
# 删除商品:
hdel MyCart:10001 40001
lrem MyItem:10001 1 40001
# 获取所有物品:
lrange MyItem:10001
# 40001 40002 40003
hget MyCart:10001 40001
hget MyCart:10001 40002
hget MyCart:10001 40003
# 获取所有商品
HGETALL MyCart:10001五、Set 无序集合
Set 是一个无序的字符串集合,不允许重复的元素集合,适合去重、集合运算(交并差)。
- 无序的字符串集合
- 元素唯一,不允许重复
- 支持集合运算(交集、并集、差集)
内部编码:
- 如果所有元素都是整数且元素数 ≤
set-max-intset-entries(默认 512),使用intset(紧凑数组); - 否则使用
dict(哈希表)。
5.1 常用 Set 命令
cs
# 元素操作
SADD key member [member ...] # 向集合添加一个或多个成员
SREM key member [member ...] # 从集合(Set)里删除一个或多个指定元素
SISMEMBER key member # 判断 member 是否是集合的成员
# 集合运算
SINTER key [key ...] # 返回给定所有集合的交集
SUNION key [key ...] # 返回给定所有集合的并集
SDIFF key [key ...] # 返回给定所有集合的差集
# 获取集合的成员数
SCARD key
# 返回集合中的所有成员
SMEMBERS key
# 随机返回集合中一个或多个成员,不删除
SRANDMEMBER key [count]
# 随机移除并返回集合中一个或多个成员
SPOP key [count]- 删除不存在的元素不会报错,只是返回 0。
5.2 Set 应用场景
1. 抽奖系统
cs
# 添加抽奖用户
SADD lottery:20230612 10001 10002 10003 10004 10005
# 查看所有参与用户
SMEMBERS lottery:20230612
# 抽取3名幸运用户
SRANDMEMBER lottery:20230612 3
# 抽取并移除一等奖1名,二等奖2名
SPOP lottery:20230612 1 # 一等奖
SPOP lottery:20230612 2 # 二等奖2. 社交关系
cs
# 用户A的关注列表
SADD follow:A B C D E
# 用户C的关注列表
SADD follow:C A B F
# 共同关注(交集)
SINTER follow:A follow:C
# A可能认识的人(差集:C关注但A未关注的人)
SDIFF follow:C follow:A
# 全部关注(并集)
SUNION follow:A follow:C3. 标签系统
cs
# 给文章添加标签
SADD article:10001:tags "redis" "database" "cache"
# 给用户添加兴趣标签
SADD user:20001:interests "programming" "redis" "python"
# 推荐相关文章(基于标签匹配)
SINTER article:10001:tags user:20001:interests六、ZSet 有序集合
Zset 是有序的字符串集合,每个成员都关联一个分数(score),用于排序。成员是唯一的,但分数可以重复。
内部实现:
- 小数据量下(≤
zset-max-ziplist-entries默认 128,且字符串长度 ≤zset-max-ziplist-value默认 64)使用ziplist; - 大数据量下使用
skiplist + dict组合:skiplist 提供按 score 的有序遍历 (O(log n)),dict 用于按 member 查找 (O(1))。 - 数据少的时候,节省空间; O ( n ) O(n) O(n)
- 数量多的时候,访问性能; O ( 1 ) O(1) O(1) or O ( l o g 2 n ) O(log_{2}{n}) O(log2n)
6.1 常用 Zset 命令
cs
# 元素操作
ZADD key [NX|XX] [CH] [INCR] score member [score member ...] # 向有序集合添加一个或多个成员
ZREM key member [member ...] # 从有序集合中移除一个或多个成员
# 范围操作
ZRANGE key start stop [WITHSCORES] # 返回有序集中指定区间内的成员(从小到大)
ZREVRANGE key start stop [WITHSCORES] # 返回有序集中指定区间内的成员(从大到小)
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] # 返回有序集中指定分数区间的成员
# 排名操作
ZRANK key member # 返回有序集中成员的排名(从小到大)
ZREVRANK key member # 返回有序集中成员的排名(从大到小)
ZSCORE key member # 返回有序集中成员的分数值
# 为有序集中成员的分数值加上增量
ZINCRBY key increment member
# 返回有序集的成员数量
ZCARD key
# 分数在指定区间[min, max]内的成员数量
ZCOUNT key min max6.2 Zset 应用场景
1. 排行榜系统
cs
# 添加用户得分
ZADD leaderboard:20230612 1000 "user1"
ZADD leaderboard:20230612 850 "user2"
ZADD leaderboard:20230612 920 "user3"
# 增加用户得分
ZINCRBY leaderboard:20230612 50 "user1"
# 获取前十名用户
ZREVRANGE leaderboard:20230612 0 9 WITHSCORES
# 获取用户排名(从高到低)
ZREVRANK leaderboard:20230612 "user1"
# 获取指定分数区间的用户
ZRANGEBYSCORE leaderboard:20230612 800 900 WITHSCORES2. 延时队列
延时队列就是把一条消息存进去,等到指定的时间再取出来处理。常见应用场景有:
- 下单 30 分钟未支付,自动取消订单;
- 消息推送延迟一段时间再发送;
- 任务重试机制(失败后延迟几秒再尝试)。
在 Redis 里,最常用的数据结构是 ZSET(有序集合):
- member:存放消息内容(比如序列化成 JSON 字符串);
- score:存放消息的"到期时间戳"。
将消息序列化成一个字符串作为 zset 的 member;这个消息的到期处理时间作为 score,然后用多个线程轮询 zset 获取到期的任务进行处理。
python
import time, uuid, json
import redis
r = redis.Redis()
# 添加延时任务
def delay(msg):
msg["id"] = str(uuid.uuid4()) # 确保唯一
value = json.dumps(msg)
retry_ts = time.time() + 5 # 5秒后执行
r.zadd("delay-queue", {value: retry_ts})
# 轮询执行任务
def loop():
while True:
now = time.time()
# 取一个到期任务
values = r.zrangebyscore("delay-queue", 0, now, start=0, num=1)
if not values:
time.sleep(1)
continue
value = values[0]
# 删除成功才处理(避免多线程重复执行)
if r.zrem("delay-queue", value):
msg = json.loads(value)
handle_msg(msg) # 用户自定义的任务处理函数- 多线程同时取任务时,会发生竞争:两个线程可能取到同一条消息,但只有一个能成功删除。
- 优化方法:用 Lua 脚本把 "取出任务 + 删除任务" 做成一个原子操作,避免并发冲突。
命令行实现:
cs
# 添加延时任务
ZADD delay_queue $(($(date +%s)+60)) "task1" # 1分钟后执行
ZADD delay_queue $(($(date +%s)+300)) "task2" # 5分钟后执行
# 循环处理
while true; do
current_timestamp=$(date +%s)
tasks=$(ZRANGEBYSCORE delay_queue 0 $current_timestamp)
if [ -n "$tasks" ]; then
for task in $tasks; do
echo "处理任务: $task"
ZREM delay_queue "$task"
done
else
sleep 1
fi
done3. 分布式定时器
定时任务的数量可能非常大,如果所有任务都放在一个 Redis 实例中,单机会成为瓶颈。
因此,做法是 把任务分散存储在多个 Redis 实例中:
-
生产者:将定时任务按照某种规则(比如任务 ID 的 hash 值)分配到不同的 Redis 实例里。
- 这样可以让不同的 Redis 节点分摊压力。
-
Dispatcher(调度进程):为每个 Redis 实例分配一个专门的进程。
- 负责定时扫描 Redis,找到已经到期的任务。
- 然后将这些任务分发给消费者去处理。
-
消费者:真正执行任务逻辑,比如发通知、清理数据、触发回调等。
通过"任务分片 + 分布式调度",系统能够高效支撑大量的定时任务,而不会压垮单台 Redis。
3. 时间窗口限流
时间窗口限流是一种常见的频率控制手段,用于限制用户在指定时间范围内的操作次数。例如,可以规定某个用户在 1 分钟内最多调用接口 10 次,或在 10 秒内最多发送 5 条消息。通过这种方式,可以有效防止恶意请求或过度访问,保障系统的稳定性和公平性。
实现方式:利用 Redis 的有序集合(ZSet)
-
每次用户行为发生时:
- 往 ZSet 里插入一条记录,score 和 member 都是当前时间戳。
-
清理过期行为:
- 删除 ZSet 中那些时间戳在「当前时间 - 窗口长度」之前的记录。
- 这样 ZSet 中只保留"窗口期内"的行为。
-
统计行为次数:
- 直接用
ZCARD统计 ZSet 的数量。 - 如果超过限制,就拒绝。
- 直接用
-
设置过期时间:
- 给 key 设置
expire,保证冷用户不会长时间占用内存。
- 给 key 设置
cs
-- Lua脚本实现时间窗口限流
local function is_action_allowed(red, userid, action, period, max_count)
local key = table.concat({"rate_limit", userid, action}, ":")
local now = tonumber(red:call("TIME")[1])
red:init_pipeline()
-- 记录当前操作
red:call("ZADD", key, now, now)
-- 移除时间窗口外的记录
red:call("ZREMRANGEBYSCORE", key, 0, now - period)
-- 获取当前窗口内的操作次数
red:call("ZCARD", key)
-- 设置键的过期时间,避免内存浪费。
red:call("EXPIRE", key, period + 1)
local res = red:commit_pipeline()
return res[3] <= max_count
end这种方式会在 ZSet 中存储窗口内的所有请求记录。如果用户数量庞大且请求频繁,ZSet 会迅速膨胀,带来较大的内存压力。可以考虑用 漏斗限流(Leaky Bucket) 或 令牌桶 等算法来优化。