
笔者链接:扑克中的黑桃A
专栏链接:论文精读
本文关键词:服务依赖; 故障诊断; 微服务
引
诸位技术同仁:
本系列将系统精读的方式,深入剖析计算机科学顶级期刊/会议论文,聚焦前沿突破的核心机理与工程实现。
通过严谨的学术剖析,解耦研究范式、技术方案及实证方法,揭示创新本质。我们重点关注理论-工程交汇点的技术跃迁,提炼可迁移的方法论锚点,助力诸位的技术实践与复杂问题攻坚,共推领域持续演进。

每日一句
可以哭,
别认输。

文献来源
张齐勋, 吴一凡, 杨勇, 贾统, 李影, 吴中海. 微服务系统服务依赖发现技术综述
DOI:10.13328/j.cnki.jos.006827
软件学报, 2024, 35(1): 87--117.
已标明出处,如有侵权请联系笔者。
引
如果你把微服务系统想象成一座繁华的城市,那么每个微服务就是城市里的**"商圈"** ------ 电商系统中的 "支付商圈","购物车商圈","物流商圈" 各司其职;而服务之间的依赖关系,就是连接商圈的 "道路"------ 用户下单时,"支付商圈" 需要先调用 "购物车商圈" 获取商品信息,再调用 "物流商圈" 安排发货,就像从 "支付商圈" 到 "物流商圈" 必须先经过 "购物车商圈" 的道路。
但这座 "微服务城市" 有个大问题:道路看不见摸不着,还经常变化 ------ 今天新增一条 "临时通道"(新服务上线),明天某条道路改道(服务接口变更),后天可能某段路突然拥堵(服务故障)。更麻烦的是,故障会顺着道路快速传播:"支付商圈" 出问题,会导致 "购物车商圈" 和 "物流商圈" 跟着瘫痪,而运维人员连完整的 "道路图" 都没有,根本不知道该从哪里排查。
服务依赖发现技术,就是为 "微服务城市" 画一张精准的 "实时道路图"------ 通过分析城市里的 "车流数据"(监控数据)、"快递单号记录"(系统日志)、"包裹追踪信息"(追踪数据),识别出哪些商圈之间有道路(依赖关系)、道路是单向还是双向(依赖方向)、道路车流多大(依赖强弱)。有了这张图,运维人员能快速找到故障源头(比如拥堵的起点商圈)、优化资源分配(比如给繁忙道路加宽)、提前规避变更风险(比如修路前规划绕行路线),让 "微服务城市" 顺畅运行。
本文将从 "微服务城市" 的道路难题出发,详解如何通过三类核心数据(监控、日志、追踪)绘制 "道路图",介绍这张图在运维中的实际用途,以及当前画 "图" 技术的挑战与未来方向,让你彻底搞懂服务依赖发现的核心逻辑。
一、微服务依赖的 "道路难题":定义与挑战
要画好 "微服务道路图",首先得明确 "道路" 的定义 ------ 哪些算服务?哪些算依赖?以及画这张图难在哪里?
1. 服务:"微服务城市" 里的 "商圈"
在 "微服务城市" 中,"商圈"(服务)的定义并非唯一,就像有些商圈按 "街道范围" 划分,有些按 "功能类型" 划分,主要分为三类:
- IP:Port 级服务:最基础的 "小商圈",用 "IP 地址 + 端口号" 标识,比如 "192.168.1.1:8080" 代表 "购物车服务" 的某个实例。这就像按 "具体门牌号" 定义商圈,精准但颗粒度细,适合底层网络监控。
- 组件 / 应用级服务:功能聚合的 "中等商圈",比如 "购物车组件""支付应用",包含多个 IP:Port 实例。这就像按 "功能区" 定义商圈,比如 "王府井购物区" 包含多个商场,适合业务层面的依赖分析。
- 虚拟机级服务:如果每个虚拟机只部署一个服务,那么 "虚拟机" 也能代表服务。这就像按 "行政区" 定义商圈,比如 "朝阳区商圈",颗粒度粗,适合大规模集群的依赖管理。
无论哪种定义,服务都有 "依赖方" 和 "被依赖方":比如 "支付服务" 需要调用 "购物车服务" 获取商品清单,那么 "支付服务" 是依赖方,"购物车服务" 是被依赖方,就像 "支付商圈" 的人流依赖 "购物车商圈" 的商品供给。
2. 依赖关系:"微服务城市" 里的 "道路"
服务之间的 "道路"(依赖关系)主要分两类,对应不同的业务逻辑:
- 调用依赖:"直接问路" 的道路,即服务 A 为了响应请求,必须直接调用服务 B。比如 "支付服务" 结算时,直接调用 "订单服务" 创建订单,就像从 "支付商圈" 到 "订单商圈" 有一条直达道路,没有这条道就办不了事。这是微服务中最常见的依赖类型,文档中提到的 NSDMiner、Dapper 等技术,核心就是发现这类依赖。
- 逻辑依赖:"间接关联" 的道路,即服务 A 的运行不直接调用服务 B,但必须等服务 B 完成某个操作才能执行。比如 "物流服务" 开始发货,必须等 "支付服务" 完成付款,两者没有直接调用,但 "物流服务" 逻辑上依赖 "支付服务",就像 "物流商圈" 要等 "支付商圈" 确认收款,才会发车送货。图 2 中 ShipmentService 依赖 PaymentService,就是典型的逻辑依赖。
【此处插入图 2】:这张图是 "微服务依赖示例图",展示了开源微服务系统中的部分依赖关系 ------CheckoutService(结账服务)调用 CartService(购物车)、PaymentService(支付)、ShipmentService(物流)(调用依赖),而 ShipmentService 逻辑依赖 PaymentService(必须先支付才能发货),图中边的权重(如 0.6、0.9)代表依赖强弱,直观呈现两种依赖的区别。
此外,依赖还能按 "传递性" 分为直接依赖和间接依赖:比如 "支付服务" 依赖 "订单服务","订单服务" 依赖 "库存服务",那么 "支付服务" 间接依赖 "库存服务"。但为了 "道路图" 简洁,通常只画直接依赖,就像交通图只标直达路线,不标多步中转的间接路线。
3. 服务依赖发现:给 "微服务城市" 画 "实时道路图"
服务依赖发现的核心,就是从系统运行时产生的三类数据(监控、日志、追踪)中,找出服务之间的依赖关系,构建 "服务依赖关系图"(G=<V,E,W>)------V 是服务节点,E 是有向依赖边(A→B 表示 A 依赖 B),W 是边的权重(代表依赖置信度或强弱)。
这个过程的难点,就像画 "实时交通图" 的挑战:
- 动态变化:微服务频繁更新、新增或下线,就像城市里每天都有新道路开通、旧道路关闭,"道路图" 必须实时更新,静态的人工绘制根本跟不上。早期依赖 IBM Tivoli、微软 MOM 等工具的人工配置方法,现在已经完全不适用。
- 异构融合:不同服务用 Java、Golang 等不同语言开发,用 RESTful、RPC 等不同协议通信,就像城市里有汽车、自行车、行人等不同交通方式,需要统一的 "观测方法" 才能识别所有 "道路"。
- 相关性≠依赖:运行时数据的相关性(比如两个服务的 CPU 使用率同时升高),可能是因为它们都依赖第三个服务,而非直接依赖,就像两个路口车流同时增加,可能是因为都通向同一个商圈,而非直接相连。这会导致 "道路图" 出现误报(画了不存在的路)或漏报(漏了真实的路)。
【此处插入图 1】:这张图是 "服务依赖发现研究热度图",展示 2000-2021 年相关论文的发表数量和来源(顶级会议如 OSDI、NSDI,重要会议如 DSN、TSC)。可以看到近 20 年研究持续升温,说明 "给微服务画道路图" 已成为学术界和工业界的共同重点。
二、服务依赖发现技术:三类 "观测数据" 与对应的 "绘图方法"
要画好 "微服务道路图",关键是选对 "观测工具"------ 监控数据、系统日志、追踪数据,就像观测城市交通的 "车流摄像头""快递单号记录""包裹追踪系统",每种数据对应不同的 "绘图方法",各有优劣。
为直观对比这些方法的核心差异,先通过表 1 不同服务依赖发现方法对比,从 "运行时数据类型""目标依赖关系""是否基于相关性推断""是否需要修改服务代码""是否注入故障 / 干扰" 等维度,对现有技术进行全局对比。
【此处插入表 1】:表 1 横向列出 "运行时数据(及子类型)""文献来源""目标依赖关系""是否为相关性(基于相关性推断则易误报,直接捕捉因果则更精准)""是否修改代码""是否注入故障 / 干扰" 等关键维度,纵向覆盖 "网络通信包""资源使用""统计指标"(监控数据子类型)、"系统日志数据""追踪数据" 等技术方向,能让读者快速把握不同方法的适用场景与核心特点。
接下来,我们将分三类数据,详解每种 "绘图方法" 的技术细节。
1. 基于监控数据的依赖发现:"看车流变化画道路图"
监控数据是微服务系统的 "实时体检报告",包括网络通信包(车流轨迹)、资源使用(各商圈资源消耗)、统计指标(车辆通行时间),通过分析这些数据的规律,就能推断服务之间的依赖关系。
(1)基于网络通信包数据:"追踪车流轨迹找路线"
网络通信包是服务之间通信的 "原始轨迹",就像城市里每辆车的行驶记录(起点、终点、时间)。通过解析这些 "轨迹",能直接或间接判断服务依赖,常用方法有两类:
-
**发现逻辑依赖:看 "车流共现规律"**逻辑依赖的核心是 "服务 A 的运行与服务 B 的运行存在时间或频率关联",就像两个路口的车流经常同时出现或先后出现,说明它们之间可能有间接路线。早期的 Constellation 和 AND 方法是这类技术的代表:
- Constellation:把每个服务的网络通信看作 "输入车流"(接收的数据包)和 "输出车流"(发送的数据包),用朴素贝叶斯等机器学习算法,看 "输入车流是否活跃" 能否预测 "输出车流是否活跃"。比如,如果 "购物车服务" 的输入车流活跃时,"支付服务" 的输出车流大概率活跃,就说明 "支付服务" 逻辑依赖 "购物车服务",权重就是预测模型中的特征重要性。
- AND:更简单直接,统计 100ms 时间窗口内,两个服务的 "输出车流"(发送数据包到目标服务)是否同时出现,以及出现的先后顺序。比如 "支付服务" 和 "物流服务" 的车流经常先后出现,且 "支付" 在前,就判断 "物流服务" 依赖 "支付服务",权重是共同出现的概率。
后来的 Sherlock 优化了这种方法,提出 "推理图" 概念,把服务分为 "根因节点"(核心服务)、"观察节点"(部署监控的节点)、"元节点"(负载均衡节点),重点分析元节点上的车流共现规律。比如在负载均衡节点上,"支付服务" 和 "订单服务" 的车流在 10ms 窗口内共现概率高,就认为两者存在依赖,解决了早期方法无法处理负载均衡场景的问题。
还有 eXpose 方法,用 "信息论中的 JMeasure" 替代共现频率,解决了 "车流交叉导致依赖方向判断不准" 的问题 ------ 比如 A 和 B 的车流同时出现,JMeasure 能计算 "A 的出现对 B 的信息量贡献",从而确定是 A 依赖 B 还是 B 依赖 A,就像通过车流的 "因果信息量" 判断路线方向,比单纯看先后更精准。
-
**发现调用依赖:看 "车流嵌套关系"**调用依赖的核心是 "服务 A 调用服务 B 时,B 的通信车流嵌套在 A 的通信车流中",就像从 A 到 C 的长途车,中途会嵌套一段 A 到 B 的短途车(B 是中转站)。NSDMiner 是首个用这种逻辑发现调用依赖的技术:
- 它的核心假设是:如果服务 A→B 的 TCP 流(车流)处于活跃状态时,服务 B→C 的 TCP 流(车流)启动,且 B→C 的流在 A→B 的流关闭前关闭(嵌套),就说明 B 调用 C,B 依赖 C。
- 依赖强弱用 "嵌套比例" 计算:比如 A→B 的流活跃期间,有 80% 的时间都嵌套 B→C 的流,说明 B 对 C 的依赖很强(权重 0.8)。
后续改进的方法中,有的用 "对数计算" 优化嵌套比例(避免极端值影响),有的针对 "访问频率低的服务"(车流少难判断),提出 "相似服务推断"------ 比如服务 D 和服务 B 的相似度高(共同依赖的服务多),就用 B 的依赖关系推断 D 的依赖,就像 "如果 A 路口和 B 路口车流规律像,就用 A 的路线推断 B 的路线"。还有用 "传递熵" 替代嵌套比例的方法,通过计算两个服务通信字节数的传递熵(信息流的传递强度),熵值超过阈值就认为存在依赖,比嵌套比例更能抗噪音。
(2)基于资源使用数据:"看资源消耗同步性找关联"
服务之间有依赖关系时,它们的资源使用(CPU、内存、网络 IO)变化会同步,就像两个路口的车流量变化总是同步,说明它们之间有依赖。这类方法通过计算资源使用时间序列的 "相似度" 或 "因果关系",推断依赖关系。
1.基于相似度聚类:把资源变化相似的服务归为一类,认为同类服务存在依赖。比如:
- 早期方法用 "AR 模型"(自回归模型)拟合 CPU 使用峰值的关系,计算不同服务 AR 模型的欧氏距离(相似度),用 K-means 聚类 ------ 聚在同一簇的服务,资源变化同步,存在依赖。
- 后来的 HiKM 算法用 "多层迭代 K-means",结合多种资源数据(CPU、内存、磁盘 IO 等),还提出 "IEntropy" 计算每种资源的权重(比如 CPU 变化对依赖判断更重要,权重更高),避免单一资源的误判。
2.基于因果关系检验:相似度只能说明 "同步变化",因果关系才能更接近 "依赖"(A 的资源变化导致 B 的资源变化)。比如:
- 有方法用 "LSTM 神经网络" 构建预测模型:用 N-1 种资源数据预测第 N 种资源数据,提取对预测最重要的特征(资源),这些特征对应的服务就是依赖服务。就像 "用路口 A、B 的车流量能精准预测路口 C 的车流量,说明 C 依赖 A、B"。
- 还有方法用 "格兰杰因果检验":如果服务 A 的资源数据能显著预测服务 B 的资源数据,就认为 A 是 B 的 "格兰杰原因",即 B 依赖 A。比如 "支付服务的 CPU 使用率变化能预测物流服务的 CPU 使用率变化,说明物流依赖支付"。
1.(3)基于统计指标:"看服务响应时间规律找依赖"
服务之间的依赖会导致 "响应时间" 或 "执行时间差" 呈现规律,就像 A 路口到 B 路口的通行时间,总是比 B 路口到 C 路口的通行时间早 10 分钟,说明 A→B→C 有依赖。这类方法主要分析两类规律:
响应时间变化关联:如果干扰服务 A(比如延迟 A 的网络包),服务 B 的响应时间也跟着变长,说明 B 依赖 A。比如:
- 2.有方法对数据库表进行 "锁表操作"(干扰数据服务),统计其他服务的响应时间 ------ 如果服务 C 的响应时间与锁表时长的拟合直线斜率 > 0(锁表越久,C 响应越慢),说明 C 依赖该数据服务,斜率就是依赖强弱。
- 还有方法通过 "延迟网络包传递" 干扰服务:延迟服务 A 的数据包,看其他服务的响应时间是否变化 ------ 变化越大,依赖越强。
执行时间差规律:依赖服务的执行时间差(延迟分布)会有明显峰值,而非随机分布。比如:
- 服务 A 依赖服务 B,那么 A 开始执行到 B 开始执行的时间差,会集中在 100ms 左右(有一个峰值),而不是随机分散在 0-1000ms。通过信号处理去噪后,只要检测到峰值,就认为存在依赖。
- Rippler 方法更直接:延迟服务 A 的第一个网络包,观察其他服务的响应时间 ------ 如果服务 B 的开始执行时间延迟,说明 A 是 B 的调用依赖;如果 B 的开始执行时间不受影响,但结束时间延迟,说明 A 是 B 的逻辑依赖,完美区分了两种依赖类型。
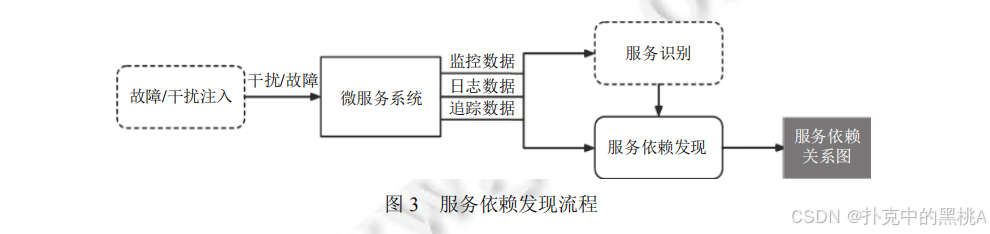
图 3是 "服务依赖发现流程图",展示了基于监控数据的发现流程 ------ 首先用故障 / 干扰注入工具(比如锁表、延迟数据包)"激活" 依赖关系,然后收集网络通信包、资源使用、统计指标数据,通过服务识别(确定服务身份)和依赖分析(计算相关性、因果关系),最终构建服务依赖关系图,清晰呈现从数据采集到建图的全流程。
2. 基于系统日志数据的依赖发现:"看记录追踪服务路径"
系统日志是服务运行的 "文字日记",记录了服务的执行状态、变量信息(比如请求 ID、IP 地址),就像城市里每个快递点的 "发货记录"。通过分析这些 "日记" 的规律,能推断服务之间的依赖,主要分三类方法:
(1)依据统一标识:"按单号追踪服务调用路径"
如果日志中包含 "统一标识"(比如 request ID、block ID),就能像 "按快递单号追踪包裹路径" 一样,找到服务之间的调用关系。这是最主流的日志依赖发现方法。
1.单一标识追踪:日志中存在唯一标识一个请求的 ID,通过该 ID 串联所有处理过该请求的服务。比如:
- 有方法从 HDFS 日志中提取 "block ID"(块标识)和 "IP 地址"(服务标识),同一 block ID 的日志对应的 IP,就是处理该块的服务,按日志时间顺序就能串联服务依赖 ------ 比如 block ID=123 的日志先出现在 IP=192.168.1.2(服务 A),再出现在 IP=192.168.1.3(服务 B),说明 A 依赖 B。
- 还有方法用 "request ID":每个请求生成唯一 ID,从前端服务到后端服务的所有日志都包含该 ID,按 ID 分组后,日志的服务顺序就是依赖顺序 ------ 比如 request ID=456 的日志顺序是 "前端服务→购物车服务→支付服务",说明前端依赖购物车,购物车依赖支付。
2.多标识串联:如果日志中没有单一统一标识,就用多个 ID(比如 user ID+order ID)"拼接" 路径。比如某请求的日志中,先出现 user ID=789+order ID=101(服务 C),再出现 order ID=101+product ID=202(服务 D),通过 order ID=101 串联,就能判断 C 依赖 D,就像 "用多个快递单号片段拼接完整路径"。
3.从代码提取关键标识:有些日志的标识不明显,需要通过静态代码分析找到 "关键 ID"。比如从服务源代码中,分析哪些 ID 会在跨服务调用时传递(比如 RPC 调用中的参数 ID),这些 ID 就是关键标识,用它们串联日志路径,避免了 "人工找标识" 的麻烦。
(2)基于共现概率:"看日志先后出现频率找关联"
如果两个服务的日志经常 "先后出现"(比如服务 A 的日志出现后 1 秒内,服务 B 的日志必出现),就说明它们可能存在逻辑依赖,就像 "某快递点 A 的发货记录出现后,快递点 B 的收货记录必出现,说明 A 依赖 B"。
- 早期方法计算 "日志共现概率":统计时间窗口内(比如 500ms),服务 A 的日志 X 出现后,服务 B 的日志 Y 出现的概率 ------ 如果概率 > 90%,就认为 B 依赖 A,权重就是概率值。
- 后来的方法用 "LSH(局部敏感哈希)" 优化:把所有日志按时间排序,对每个日志模板(比如 "订单创建成功"),计算其 "最近邻居组"(经常先后出现的日志模板),过滤后确定直接后继模板 ------ 如果服务 A 的日志模板是服务 B 日志模板的直接后继,说明 A 依赖 B,就像 "快递点 A 的'发货'模板是快递点 B'收货'模板的直接后继,说明 A 依赖 B"。
(3)基于日志频率:"看日志生成频率同步性找关联"
服务之间有依赖时,它们的日志生成频率(单位时间内的日志条数)会同步变化,就像 "快递点 A 和 B 的发货频率总是同时升高或降低,说明它们有依赖"。这类方法把日志频率作为 "信号",分析信号的相关性或因果关系。
- 有方法用 "PCA 算法" 压缩多类信号(日志频率、资源指标等),然后将不同服务的信号在时间轴上前后偏移,计算关联程度 ------ 关联度高的服务存在依赖。
- 还有方法用 "PC 因果推断算法":如果服务 A 的日志频率是服务 B 日志频率的 "因果父节点"(A 的频率变化导致 B 的频率变化),就认为 B 依赖 A,比单纯的相关性更精准。
3. 基于追踪数据的依赖发现:"按完整路径画精准道路图"
追踪数据是 "微服务城市" 的 "包裹完整追踪记录"------ 每个请求从前端到后端的所有处理步骤(哪个服务处理了、处理时间、调用关系)都被记录,就像快递从下单到签收的所有中转点都有记录。通过分析这些记录,能直接、精准地发现调用依赖,还能推断逻辑依赖,是目前最精准的依赖发现方式。
(1)核心:分布式追踪与请求执行路径
分布式追踪技术会给每个请求分配 "全局唯一 ID"(比如 Request ID),并在每个服务调用时传递 "父子事件 ID"(比如服务 A 调用服务 B,A 的事件 ID 是父 ID,B 的是子 ID),最终生成 "请求执行路径"------ 包含所有处理该请求的服务、调用顺序、因果关系。
当事件粒度是 "服务" 时,路径中的因果关系就是 "调用依赖";当事件粒度是 "方法 / 系统调用" 时,需要先将事件聚合为服务,再判断依赖。比如请求执行路径是 "前端→购物车→支付→订单",直接说明 "前端依赖购物车,购物车依赖支付,支付依赖订单",调用依赖一目了然。
(2)事件因果关系判断:两种核心方法
要从追踪数据中找依赖,关键是判断 "事件之间的因果关系"(谁调用谁),主要分两类方法:
1.基于规则的因果判断:用追踪数据中的明确标识或时间戳判断,精准度高。
- 父子事件 ID :这是最常用的方式,以谷歌 Dapper 为例:
- Dapper 提出 "Span" 概念(代表一个服务 / 方法的处理过程),每个 Span 有 "全局 Request ID" 和 "父子 Span ID"------ 父 Span 对应的服务调用子 Span 对应的服务,比如 Span1(购物车)是父 Span,Span2(支付)是子 Span,说明购物车调用支付,购物车依赖支付。
- Dapper 通过侵入动态链接库(RPC 库、线程库),自动传递 Request ID 和父子 Span ID,无需手动改代码,成为工业界标准(如 Zipkin、Jaeger 都沿用此逻辑)。
- 时间戳:如果追踪数据中没有父子 ID,就用事件的时间戳判断 ------ 同一 Request ID 下,服务 A 的事件结束时间 < 服务 B 的事件开始时间,且 A 和 B 有通信记录,说明 A 调用 B。比如 Pinpoint 工具,通过 HTTP 头传递 Request ID,用时间戳判断 Span 之间的因果关系。
- 数据读写依赖:针对消息中间件(如 Kafka、RabbitMQ),通过提取 "Message ID" 判断因果 ------ 服务 A 写入消息(Message ID=567),服务 B 读取该消息,说明 A 的写事件是 B 的读事件的原因,A 和 B 存在依赖。
2.基于统计推断的因果判断:从历史追踪数据中学习因果特征,适合没有明确标识的场景。
- 时间嵌套频率:统计服务 B 的调用时间嵌套在服务 A 调用时间内的频率 ------ 如果频率 > 80%,说明 A 调用 B。比如某电商系统中,"支付服务" 的调用时间有 90% 嵌套在 "订单服务" 的调用时间内,说明订单调用支付,订单依赖支付。
- 全连接图精简:MysteryMachine 工具先根据 Request ID 生成 "事件全连接图"(所有事件两两相连),然后用历史数据精简 ------ 如果从任意历史数据中能证明某两个事件的因果关系不成立(比如 A 的事件永远在 B 之后,不可能是 B 的父事件),就删除这条边,最后剩下的边就是因果关系,对应调用依赖。
(3)从调用依赖到逻辑依赖:进一步推断
追踪数据直接体现调用依赖,但通过分析 "调用顺序" 和 "故障影响",还能推断逻辑依赖。比如图 4展示的请求执行路径:
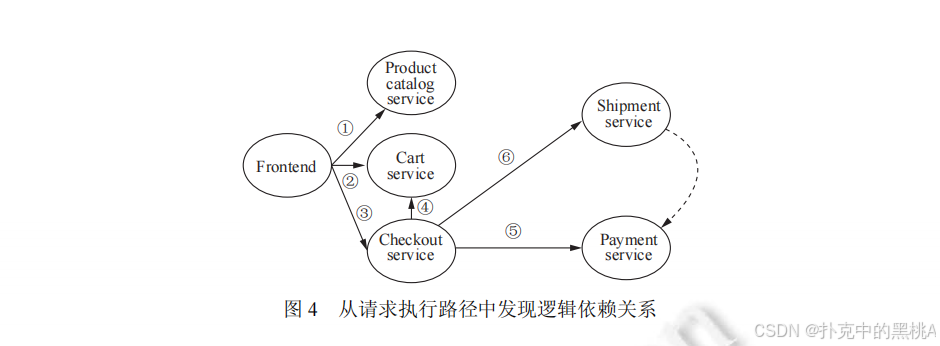
图 4是 "从请求执行路径发现逻辑依赖示意图",展示了一个电商请求的执行路径 ------Frontend(前端)→CheckoutService(结账)→CartService(购物车)、PaymentService(支付)、ShipmentService(物流),其中 PaymentService 的调用总是在 ShipmentService 之前。通过分析所有此类路径,发现:①PaymentService 必在 ShipmentService 前调用;②PaymentService 失效时,ShipmentService 也会失效(概率 > 95%),由此推断 ShipmentService 逻辑依赖 PaymentService。
具体推断逻辑分两步:
1.调用顺序验证:统计所有包含两个服务的请求路径,看服务 B 是否总是在服务 A 之后调用 ------ 如果是,说明 B 的执行可能依赖 A 的执行结果。
2.故障影响验证:模拟服务 A 失效(或分析历史故障数据),看服务 B 的调用成功率是否下降 ------ 如果下降超过阈值(比如 50%),说明 B 逻辑依赖 A。
这种方法结合了 "路径顺序" 和 "故障影响",比单纯的日志或监控数据推断更精准,是目前逻辑依赖发现的主流方向。
三、服务依赖图的核心应用:让 "微服务城市" 运维更高效
有了精准的 "服务依赖关系图",就像有了高清的 "微服务城市交通图",能解决运维中的三大核心问题:故障根因定位(找拥堵起点)、资源调度(优化交通资源)、变更治理(规避修路风险)。
1. 故障根因定位:"按交通图找拥堵起点"
微服务故障会顺着依赖关系快速传播,比如 "支付服务" 故障会导致 "购物车""订单""物流" 服务都出现异常,就像某条主干道拥堵会导致多条支路瘫痪。依赖关系图能帮运维人员 "逆着依赖链找起点",快速定位根因服务。
(1)基于可视化的定位:"直观对比交通图找异常"
通过可视化工具(如 ShiViz)展示依赖图,对比正常和异常状态的依赖关系,找出差异点。比如:
- 收集某请求的正常追踪数据(依赖图中 "支付→订单" 的响应时间正常)和异常追踪数据("支付→订单" 的响应时间变长),对比发现异常点在 "支付服务",进一步排查发现支付服务的数据库连接池耗尽,这就是根因。
- 这种方法适合简单系统,依赖人工对比,但直观易懂,适合运维人员快速上手。
(2)基于图搜索的定位:"按依赖方向遍历找根因"
根据故障传播方向(不同异常类型传播方向不同),用广度 / 深度优先搜索遍历依赖图,找到异常传播链的起点。比如:
- 性能异常(响应时间变长)和可靠性异常(服务不可用):异常从被依赖服务向依赖服务传播(比如 "订单服务" 故障→"支付服务" 异常→"购物车服务" 异常),搜索时从异常服务出发,逆向遍历依赖链(找被依赖服务)。
- 流量异常(请求量突增):异常从依赖服务向被依赖服务传播(比如 "前端服务" 请求量突增→"购物车服务" 流量异常→"订单服务" 流量异常),搜索时从异常服务出发,正向遍历依赖链(找依赖服务)。
具体流程以广度优先搜索为例:
- 从首个异常服务(如 "购物车服务")出发,根据异常类型确定遍历方向(比如性能异常,逆向找被依赖服务 "支付服务")。
- 用机器学习算法(如 Isolation Forest)检测遍历到的服务是否异常 ------ 如果 "支付服务" 异常,加入异常传播链,继续遍历其被依赖服务 "订单服务"。
- 直到遍历到 "无异常的服务" 或 "无被依赖服务",此时异常传播链的末端(比如 "订单服务")就是根因服务。
- 计算根因服务与异常服务的皮尔逊相关系数(相关性越高,根因可能性越大),对候选根因排序。
(3)基于随机游走的定位:"模拟车流找拥堵起点"
把依赖图看作 "交通网络",用随机游走算法(如 Personalized PageRank)模拟 "故障传播的概率",访问次数最多的节点就是根因服务。比如:
- 构造依赖图的邻接矩阵,边的权重是 "依赖强弱 + 异常相关性"(比如 "支付→订单" 的依赖权重 0.8,异常相关性 0.9,总权重 0.72)。
- 从异常服务(如 "购物车")出发,按权重随机游走,每次游走时,根因服务被访问的概率更高(因为它是异常传播的起点)。
- 当所有节点的访问次数(rank 值)收敛后,rank 值最高的节点就是根因服务。
后续改进的方法还会加入 "自环权重"(节点自身是根因的概率)、"反向边"(避免游走偏离方向),进一步提高定位精度。比如某电商系统中,用二阶随机游走替代 PageRank,考虑 "两步依赖" 的影响(如 "购物车→支付→订单",订单的异常可能影响支付,进而影响购物车),根因定位准确率提升了 30%。
2. 资源调度:"按车流依赖优化交通资源"
微服务的资源(CPU、内存、带宽)是 "交通资源",需要根据依赖关系优化分配,确保端到端 SLA(服务等级协议,比如响应时间 < 500ms)。依赖图能帮运维人员找到 "关键路径" 和 "资源瓶颈",精准调度资源。
(1)关键路径资源优先分配:"给繁忙主干道加宽"
从依赖图中识别 "关键路径"(对端到端响应时间影响最大的依赖链),优先给关键路径上的服务分配资源。比如:
某电商系统的关键路径是 "前端→购物车→支付→订单",其中 "支付服务" 的响应时间占比 60%,是瓶颈。通过强化学习算法,根据 "支付服务" 的资源利用率、请求量,动态调整 CPU 配额 ------ 请求量高峰时增加 CPU,低谷时减少,确保关键路径的响应时间达标。
(2)依赖亲和性部署:"把紧密度高的商圈放近"
将依赖强的服务部署在同一物理节点或同一区域,减少网络延迟,就像 "把经常有车流往来的两个商圈放在同一区域,减少通勤时间"。比如:
用主成分分析(PCA)对依赖图降维,再用 "引力聚类算法" 将依赖强的服务聚为一类(如 "支付→订单→库存" 聚为一类),然后用匈牙利匹配算法将虚拟机组分配到物理机器,网络通信开销降低了 40%。
(3)虚拟机迁移顺序优化:"按依赖顺序规划搬家"
当需要迁移虚拟机(服务载体)时,按依赖关系确定迁移顺序,减少服务停机时间,就像 "搬家时先搬依赖少的家具,再搬依赖多的"。比如:
从依赖图中用 DFS 找到连通子图(如 "购物车→支付→订单" 是一个连通子图),将边的权重设为 "流量强度的倒数"(依赖越强,权重越小),用最小生成树算法确定迁移顺序 ------ 先迁移 "订单服务"(被依赖少),再迁移 "支付服务",最后迁移 "购物车服务"(依赖多),停机时间减少了 50%。
3. 变更治理:"修路前按交通图规划风险"
微服务的变更(如版本更新、配置修改)就像 "修路",可能导致依赖服务故障。依赖图能帮运维人员 "提前评估影响范围""规划安全变更方案""检测变更异常",实现变更治理。
(1)变更风险评估:"修路前看影响哪些商圈"
在变更前,基于依赖图分析 "变更服务的直接和间接依赖服务",评估风险等级。比如:
某系统要变更 "支付服务",依赖图显示 "支付服务" 直接依赖 "订单服务",间接依赖 "库存服务",影响范围涉及 3 个核心服务。用增量评估算法,复用已有评估结果,将变更风险评估问题转换为 "布尔可满足性(SAT)问题",快速判断变更后是否满足可靠性目标 ------ 如果不满足,生成改进方案(如先灰度发布变更)。
(2)变更部署规划:"修路时规划绕行路线"
在变更部署时,基于依赖图避免 "多服务变更冲突",规划无冲突的部署顺序。比如:
数据中心要同时变更 "路由服务" 和 "负载均衡服务",依赖图显示 "路由服务" 依赖 "负载均衡服务",如果先变更 "负载均衡服务",会导致 "路由服务" 暂时不可用。通过将变更冲突建模为约束条件,用优化算法求解,得到部署顺序:先灰度变更 "负载均衡服务" 的部分实例,验证无问题后全量变更,再变更 "路由服务",避免服务中断。
(3)变更异常检测:"修路后看是否有拥堵"
变更后,基于依赖图确定 "受影响的服务范围",监控这些服务的性能指标,检测是否有异常。比如:
变更 "购物车服务" 后,依赖图显示 "前端服务""支付服务" 受影响,将这些服务作为 "研究组",选择地理位置相近、未变更的服务作为 "控制组"。用鲁棒空间回归算法对比两组在变更前后的 KPI(如响应时间、错误率)------ 如果研究组的响应时间比控制组高 20%,说明变更导致异常,需要回滚。
还有方法用 "SST(奇异谱变换)" 算法检测异常,结合 "双重差分(DiD)" 判断异常是否由变更导致,避免 "外部因素(如流量突增)误判为变更异常"。
四、工程实践:常用工具与技术栈
在实际的 "微服务城市" 运维中,服务依赖发现技术通常与 "数据采集工具""分析工具" 紧密耦合,形成完整的技术栈。以下是工业界常用的工具与技术,对应依赖发现的三类数据:
1. 日志数据采集与分析工具:"快递记录收集与分析系统"
这类工具负责采集、存储、分析系统日志,从中发现依赖关系,核心技术栈是 ELK,以及 Splunk 等商业工具:
- 数据采集:Filebeat(轻量级日志采集器,部署在每个服务节点,像 "快递点的记录员",实时收集日志)、Logstash(日志处理管道,像 "快递分拣中心",过滤、转换日志数据,比如提取 request ID)、Flume(分布式日志采集器,适合海量日志,像 "大型快递转运中心")。
- 数据存储与检索:Elasticsearch(分布式搜索引擎,像 "快递记录数据库",快速查询包含某 request ID 的所有日志)。
- 可视化与分析:Kibana(日志可视化工具,像 "快递路径可视化界面",展示日志中的依赖关系,支持按 request ID 追踪路径)。
- 商业工具:Splunk(功能更全面的日志分析平台,支持自定义依赖发现算法,像 "专业的快递追踪分析系统",适合大型企业)。
这些工具的工作流程:Filebeat 采集日志→Logstash 处理日志(提取标识、过滤噪音)→Elasticsearch 存储→Kibana 分析并构建依赖图,适合基于 "统一标识""共现概率" 的依赖发现。
2. 监控数据采集与分析工具:"交通监控与车流分析系统"
这类工具负责采集资源使用、网络通信等监控数据,分析服务依赖,核心工具包括 Prometheus、ZABBIX 等:
- 资源监控:Prometheus(开源监控系统,像 "车流统计仪",采集 CPU、内存、网络 IO 等指标,支持自定义指标,比如 "每秒 RPC 调用次数")、ZABBIX(企业级监控工具,支持分布式监控,像 "城市交通监控中心",覆盖多个数据中心的服务)。
- 网络监控:Wireshark(网络包捕获工具,像 "路口摄像头",捕获 TCP/UDP 包,提取五元组信息)、tcpdump(命令行网络包分析工具,适合服务器端批量分析)。
- 分析工具:Grafana(监控数据可视化工具,像 "交通数据仪表盘",展示资源指标的时间序列,支持计算相关性,辅助发现依赖)。
这些工具的工作流程:Prometheus 采集资源指标→Grafana 展示指标趋势,计算服务 A 和 B 的 CPU 使用率相关性→如果相关性 > 0.8,结合网络包数据(Wireshark 捕获的流信息),判断 A 和 B 存在依赖。
3. 追踪数据采集与分析工具:"包裹完整追踪系统"
这类工具负责生成、采集、分析追踪数据,精准发现调用依赖,核心工具包括 Zipkin、Jaeger、SkyWalking 等,都基于谷歌 Dapper 的思想:
- 分布式追踪框架:OpenTracing(追踪数据规范,像 "快递追踪标准",统一不同语言、框架的追踪数据格式,支持 Java、Golang、Python 等)。
- 追踪数据采集:Zipkin(Twitter 开源,像 "基础版快递追踪系统",支持通过 HTTP、Kafka 收集追踪数据,展示请求执行路径)、Jaeger(Uber 开源,像 "增强版快递追踪系统",支持分布式上下文传播、采样策略,适合大规模系统)、SkyWalking(Apache 开源,像 "专业版快递追踪系统",自动构建服务依赖图,支持可视化和告警)。
- 无侵入追踪:DeepFlow(基于 eBPF 技术,像 "隐形的快递追踪器",无需修改服务代码或依赖库,通过内核层捕获追踪数据,适合异构系统)。
这些工具的工作流程:服务调用时,OpenTracing 生成 Span(包含 Request ID、父子 ID)→Zipkin/Jaeger 收集 Span 数据→SkyWalking 分析 Span,生成请求执行路径→基于路径构建调用依赖图,还能推断逻辑依赖。
五、挑战与未来展望:让 "微服务道路图" 更精准、更通用
尽管当前的服务依赖发现技术已能解决大部分问题,但仍面临核心挑战 ------"相关性≠依赖",导致依赖图存在误报和漏报;未来需要从 "精准度""通用性""应用范围" 三个方向突破,让 "微服务道路图" 更完善。
1. 当前核心挑战:"误报与漏报" 的根源
现有方法大多通过 "运行时数据的相关性" 推断依赖,但 "相关性" 是 "依赖" 的充分非必要条件 ------ 有依赖的服务一定有相关性,但有相关性的服务不一定有依赖。比如:
- 误报:服务 A 和服务 B 都依赖服务 C,导致 A 和 B 的 CPU 使用率同步变化(相关性高),但 A 和 B 之间没有直接依赖,却被误判为有依赖,就像 "两个路口都通向 C,车流同步变化,但两者之间没有直接道路,却被误画成有道路"。
- 漏报:服务 A 依赖服务 B,但由于数据噪音(比如网络波动导致 A 的日志丢失),或依赖关系弱(A 每天只调用 B 一次),导致相关性低,被漏判为无依赖,就像 "两个路口有一条小路,但车流少,被漏画在地图上"。
此外,"人工参数设置"(如时间窗口大小、相关性阈值)也会影响结果 ------ 比如时间窗口设得太小,会错过服务 A 和 B 的共现;设得太大,会引入无关服务的共现,进一步增加误报和漏报。
2. 未来发展方向:三大突破点
(1)提升精准度:从 "相关性" 到 "真实依赖"
- 通用分布式追踪技术:当前基于追踪数据的方法最精准,但需要修改服务代码或中间件(如侵入 RPC 库),难以适配异构系统(如 Java、Golang、C++ 混合开发)。未来需要 "无侵入、通用" 的追踪技术,比如基于 eBPF 的 DeepFlow,或通过 "服务网格(Istio)" 自动注入追踪逻辑,无需修改业务代码,让追踪数据覆盖所有服务,从源头减少漏报。
- 深度学习辅助依赖发现:将服务依赖发现转化为 "带时序信息的图链接预测问题"------ 把服务看作节点,运行时数据的时序特征作为边的特征,用图神经网络(GNN)学习 "依赖关系的特征模式",结合标注数据(人工确认的依赖关系)训练模型,区分 "相关性" 和 "依赖"。比如用 GAT(图注意力网络)关注 "强因果特征"(如追踪数据中的父子 ID),弱化 "弱相关特征"(如单纯的 CPU 同步),降低误报。
- 引入额外知识:现有方法只利用运行时数据,忽略了 "系统文档""配置信息""专家知识" 等静态知识。未来可结合知识图谱技术,将这些额外知识作为 "约束条件" 辅助依赖发现 ------ 比如系统文档中明确 "支付服务依赖订单服务",可作为先验知识,修正运行时数据的误判;配置信息中 "服务 A 的数据库地址是服务 B 的地址",可辅助判断 A 依赖 B,弥补数据相关性的不足。
(2)拓展应用范围:从 "依赖发现" 到 "运维闭环"
- 变更风险实时感知:当前变更风险评估多在变更前进行,未来可结合实时依赖图,监控变更过程中 "受影响服务" 的运行状态 ------ 比如变更 "购物车服务" 时,实时监控 "前端""支付" 等依赖服务的错误率、响应时间,一旦出现异常,自动调整变更灰度比例(如从 10% 实例变更降到 5%),甚至回滚,实现 "变更 - 监控 - 调整" 的闭环。
- 故障根因与变更关联:当前故障根因定位多聚焦 "服务本身的问题"(如 CPU 耗尽),未来可结合 "变更历史" 和依赖图 ------ 故障发生时,基于依赖图找到 "与故障服务强相关的变更服务"(如故障前 1 小时变更过 "订单服务",且 "订单服务" 是故障服务的被依赖服务),用因果推断算法判断变更是否为根因,提升根因定位的效率(从小时级降到分钟级)。
(3)适配复杂场景:边缘计算、Serverless 等新架构
随着微服务架构向 "边缘计算"(服务部署在边缘节点,网络不稳定)、"Serverless"(服务按需启动,生命周期短)发展,依赖发现面临新挑战 ------ 边缘节点的网络波动导致日志 / 追踪数据丢失,Serverless 服务的短生命周期导致数据不足。未来需要:
- 边缘场景优化:采用 "边缘 - 云端协同" 的依赖发现 ------ 边缘节点采集轻量化数据(如网络包的五元组),云端聚合分析,结合 "边缘节点的地理位置依赖"(如某边缘节点的服务依赖相邻节点的服务),减少网络波动的影响。
- Serverless 场景优化:基于 "函数调用链"(而非服务)发现依赖,用 "冷启动日志" 补充数据不足 ------ 比如 Serverless 函数 A 调用函数 B,即使 A 只启动一次,也能通过冷启动时的日志提取调用关系,构建依赖图。
六、总结
服务依赖发现技术是 "微服务城市" 的 "道路测绘技术",通过分析监控、日志、追踪三类运行时数据,绘制精准的 "服务依赖关系图",解决故障根因定位、资源调度、变更治理等核心运维问题。从早期的人工配置,到现在的自动化数据驱动,技术不断向 "精准化""通用化" 发展。
未来,随着通用分布式追踪、深度学习、知识图谱的融合,服务依赖发现将实现 "从相关性到依赖" 的精准判断,构建 "数据采集 - 依赖发现 - 运维应用 - 风险控制" 的完整闭环,让 "微服务城市" 的运行更顺畅、更可靠。对于运维人员而言,掌握这些技术,就像拥有了 "微服务城市" 的 "交通指挥中心",能快速应对各种突发状况,保障业务稳定运行。
尾
本期技术解构至此。
论文揭示的方法论范式对跨领域技术实践具有普适参考价值。下期将聚焦其他前沿成果,深入剖析其的突破路径。敬请持续关注,共同深挖工程实现脉络,淬炼创新底层逻辑,在学术与工程融合中洞见技术演进规律,推动领域范式持续进化。