0. 项目研究背景
对于一些金融或者政府机构来说,数据安全十分重要,要求数据只能在内网中传输使用,不能走公网。因此需要一种可以不联网的情况下使用的ASR接口,方便给其它需要语音转写的项目去调用,而不需要调用云ASR接口,从传输层上杜绝了数据泄露风险发生。以及对于一些公司而言没有大量的资金去调用云ASR接口,需要自己组装服务器部署一套自己的ASR接口,减少资金投入。
1. 技术栈
采用分布式异步执行框架Celery和消息中间件Redis(同时做为NoSQL缓存转写结果)开发而成。接口使用fastapi编写开发。总体上是生产者-消费者模型,示意图如下所示。
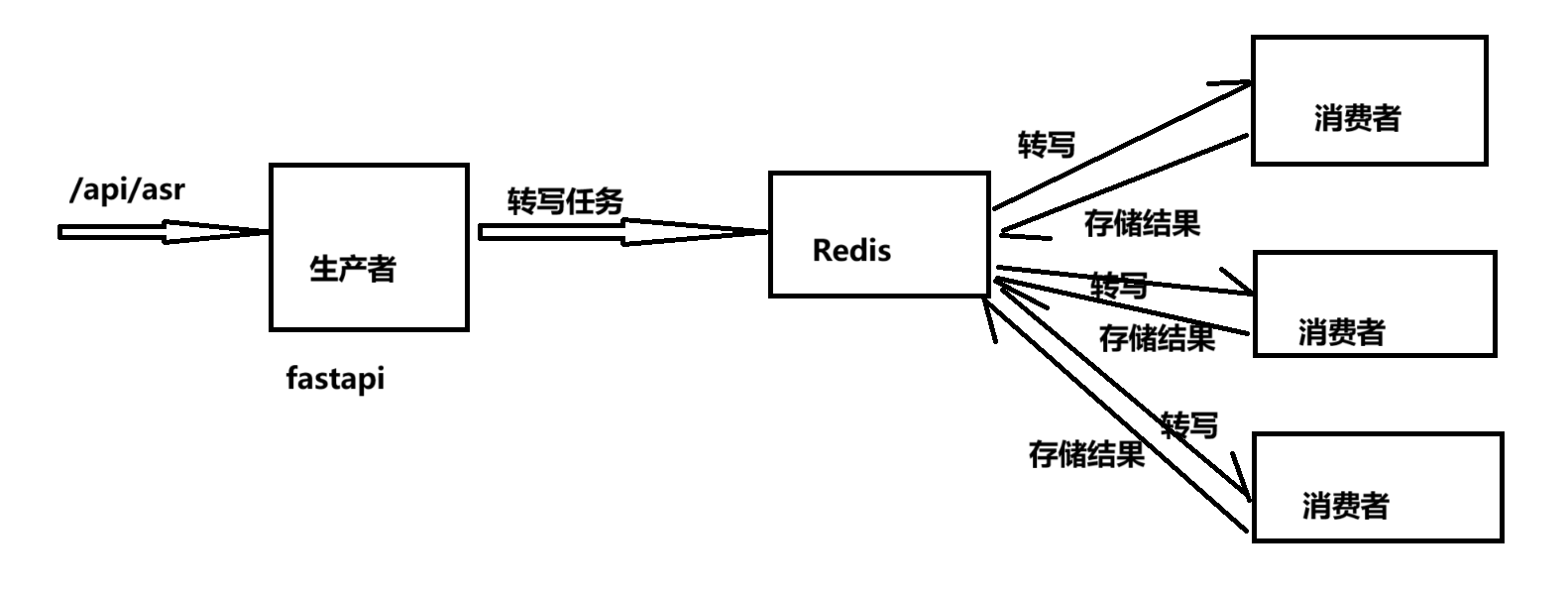
基于该架构下可以在多台服务器多张显卡中运行,可以做超大规模语音识别接口。同时可搭配nginx做反向代理,实现多生产者多消费者模式,以及Redis消息队列可以替换为RabbitMQ。
2. 运行项目
由于该项目使用Celery框架开发,需要使用Celery的命令来启动。首先启动消费者,使用下面命令。
shell
celery -A top.lukeewin.asr.service.celery_service:celery_app worker -l info --pool=prefork -c 6 -f logfile如果是在多显卡的服务器中运行,可以显卡索引。
shell
CUDA_VISIBLE_DEVICES=1 celery -A top.lukeewin.asr.service.celery_service:celery_app worker -l info --pool=prefork -c 6 -f logfile如果想要在后台不挂起一直运行,可以使用下面命令。
shell
CUDA_VISIBLE_DEVICES=1 nohup celery -A top.lukeewin.asr.service.celery_service:celery_app worker -l info --pool=prefork -c 6 -f logfile > celery.log 2>&1 &这里需要注意CUDA_VISIBLE_DEVICES一定要在最前面,而不是nohup在最前面。
上面运行了消费者,下面将运行生产者,生产者使用uvicorn命令启动,是使用fastapi开发的接口。
shell
uvicorn top.lukeewin.asr.app:app --host 0.0.0.0 --port 8080这里需要注意,如果你想要在同一网段内的全部主机都可以访问到启动的接口,那么需要指定host为0.0.0.0,端口号可以随意,这里使用了8080端口。
3. 代码解析
首先看一下项目的目录结构。
markdown
top
└─lukeewin
└─asr
├─entity
│
├─enums
│
├─service
│
└─utils然后这里对service下的代码进行分析,这是转写的核心代码。
首先看看celery_service.py这是创建celery对象的并且进行配置celery的代码。
python
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2025/10/19 16:32
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
from celery import Celery
import os
from dotenv import load_dotenv
load_dotenv()
BROKER_URL = os.getenv("BROKER_URL")
RESULT_BACKEND = os.getenv("RESULT_BACKEND")
celery_app = Celery(
"asr_tasks",
broker=BROKER_URL,
backend=RESULT_BACKEND,
include=['top.lukeewin.asr.service.asr_service']
)
celery_app.conf.update(
task_serializer='json',
result_serializer='json',
accept_content=['json'],
timezone='Asia/Shanghai',
enable_utc=True,
broker_connection_retry_on_startup=True, # 启动时可自动重连
broker_connection_max_retries=None, # 无限重试
broker_pool_limit=50, # 不限制连接池
broker_transport_options={
'visibility_timeout': 3600, # 任务最长可见性1小时
'socket_connect_timeout': 10,
'socket_keepalive': True, # 开启TCP keepalive
'socket_timeout': 60, # Socket超时
'retry_on_timeout': True, # 超时自动重试
'max_retries': 5,
'health_check_interval': 30,
},
result_backend_transport_options={
'socket_keepalive': True,
'retry_on_timeout': True,
},
broker_heartbeat=60,
broker_heartbeat_checkrate=2,
worker_prefetch_multiplier=1,
task_acks_late=True,
result_expires=600, # 结果保存600秒
)这里需要注意,一定要记得在创建celery对象的时候通过传递include参数将自己定义的任务所在的asr_service.py传递过来,否则在启动celery的时候会报错找不到对应的任务。
这里设置了结果保存时间为600秒,也就是redis中只会保存10分钟的结果,超时会自动从redis中删除结果,你可以根据自己服务器的内存情况设定超时时间。
然后我们来看看asr_service.py这里的核心代码实现。这代码主要是对任务进行消费,也就是进行语音转写,并且会区分说话人。
python
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2025/10/19 16:34
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
import asyncio
import datetime
import os.path
import time
from top.lukeewin.asr.service.celery_service import celery_app
from top.lukeewin.asr.entity.asr_entity import ASREntity
from top.lukeewin.asr.utils.http_utils import HttpUtils
from top.lukeewin.asr.utils.audio_downloader_async import AudioDownloaderAsync
from top.lukeewin.asr.utils.logger_utils import logger
from top.lukeewin.asr.utils.minio_utils import MinioClientUtil
asr = None
@celery_app.task(bind=True, name="top.lukeewin.asr.service.asr_service.asr_task")
def asr_task(self, audio_url: str, task_id):
"""
转写任务
:param self:
:param audio_url: 音频 URL
:param task_id: 任务 ID
:return:
"""
try:
global asr
if asr is None:
asr = ASREntity()
# OSS 方式提交的任务 2025-10-28/jkahgajdsf123143dfjaks.wav
if not audio_url.startswith("http://") and not audio_url.startswith("https://"):
tmp = audio_url.split("/")
bucket_name = tmp[0]
object_name = tmp[-1]
today_str = datetime.date.today().strftime("%Y-%m-%d")
save_path = os.path.join("downloads", today_str, object_name)
start = time.time()
asyncio.run(MinioClientUtil.download_file(bucket_name=bucket_name, object_name=object_name, dest_path=save_path))
end = time.time()
duration = end - start
duration = round(duration, 2)
result = asr.model.generate(save_path, is_final=True, batch_size_s=300)
if result:
sentences = []
for sentence in result[0]["sentence_info"]:
text = sentence["text"]
start = HttpUtils.to_date(sentence["start"])
end = HttpUtils.to_date(sentence["end"])
spk = sentence["spk"]
if sentences and sentence["spk"] == sentences[-1]["spk"]:
sentences[-1]["text"] += "" + sentence["text"]
sentences[-1]["end"] = end
else:
sentences.append({"text": text, "start": start, "end": end, "spk": spk})
return {"status": "success", "download_duration": duration,
"result": {"text": result[0]["text"], "sentences": sentences}}
else:
return {"status": "failed", "nan": "噪音"}
# 音频 URL 方式
download_result = asyncio.run(AudioDownloaderAsync.download(url=audio_url, audio_id=task_id))
if download_result:
audio_path, duration = download_result
result = asr.model.generate(audio_path, is_final=True, batch_size_s=300)
if result:
sentences = []
for sentence in result[0]["sentence_info"]:
text = sentence["text"]
start = HttpUtils.to_date(sentence["start"])
end = HttpUtils.to_date(sentence["end"])
spk = sentence["spk"]
if sentences and sentence["spk"] == sentences[-1]["spk"]:
sentences[-1]["text"] += "" + sentence["text"]
sentences[-1]["end"] = end
else:
sentences.append({"text": text, "start": start, "end": end, "spk": spk})
return {"status": "success", "download_duration": duration, "result": {"text": result[0]["text"], "sentences": sentences}}
else:
return {"status": "failed", "nan": "噪音"}
else:
logger.warning(f"{task_id} - 下载音频{audio_url}失败")
return {"status": "failed", "error": "音频下载失败"}
except Exception as e:
return {"status": "failed", "error": str(e)}这里有两种方式,一种是处理提交过来是音频文件的,会先上传到OSS对象存储当中,让后在获取到转写任务后,就从OSS中下载到本地服务器进行转写。第二种是提交的是音频URL,那么在处理任务的时候就会下载到本地服务器中,然后进行转写,这里可以搭配shell脚本写一个Linux定时任务,当然直接用celery做定时任务也是可以的,但是我更愿意直接使用Linux系统自带的定时任务,定时删除前一天的音频文件,当时你也可以选择保存更长时间,如果你的磁盘空间足够的话。这里暂存下载的音频是为了更好的排查,如果日后发生转写异常,可以查看是否是音频问题,比如音频中没有人讲话。
下面是编写的shell脚本。
shell
#!/bin/bash
# 设置基础目录路径
BASE_PATH="/usr/local/src/asr/downloads"
# 获取昨天的日期
YESTERDAY=$(date -d "yesterday" +%Y-%m-%d)
# 要删除的目录路径
DIR_TO_DELETE="${BASE_PATH}/${YESTERDAY}"
# 删除目录的函数
delete_old_directory() {
# 检查目录是否存在
if [ -d "$DIR_TO_DELETE" ]; then
# 删除目录
rm -rf "$DIR_TO_DELETE"
echo "已删除目录: $DIR_TO_DELETE"
else
echo "目录不存在: $DIR_TO_DELETE"
fi
}
# 执行删除操作
delete_old_directory
# 添加到系统定时任务中,每天5点执行
# 0 5 * * * /usr/local/src/asr/rm_audio_dir.sh在Linux中添加定时任务,可以执行下面命令。
shell
crontab -e然后在最下面添加下面代码即可在每天的凌晨5点删除前一天下载到服务器的音频。
shell
0 5 * * * /usr/local/src/asr/rm_audio_dir.sh这里为了防止返回的内容中过于碎片化,我还写了合并相邻相同讲话人的代码。
python
for sentence in result[0]["sentence_info"]:
text = sentence["text"]
start = HttpUtils.to_date(sentence["start"])
end = HttpUtils.to_date(sentence["end"])
spk = sentence["spk"]
if sentences and sentence["spk"] == sentences[-1]["spk"]:
sentences[-1]["text"] += "" + sentence["text"]
sentences[-1]["end"] = end
else:
sentences.append({"text": text, "start": start, "end": end, "spk": spk})4. 效果演示
这里录制过视频发布到B站"编程分享录"中,也可以点击下面的视频链接,观看演示效果。
效果截图如下所示。
5. 其它
如果有需要的老板可以搜索"lukeewin01",可以进行预约进行项目效果演示。添加时一定要备注来意"服务器端部署区分说话人语音识别接口",如果没有备注不给予通过。