文章目录
-
- 1.LoRA模型合并与量化导出
-
- [1.1 微调量化与模型导出量化](#1.1 微调量化与模型导出量化)
- [1.2 模型导出量化环境冲突问题](#1.2 模型导出量化环境冲突问题)
- 2.使用open-webui部署模型
- 补充
1.LoRA模型合并与量化导出
1.1 微调量化与模型导出量化
-
微调量化
微调量化 :QLoRA参数量化后,依然在参与学习<动态变化>,因此对模型精度的影响是非常小的(量化 丢失的精度可以通过模型学习弥补回来),因此比较推荐使用。16位量化为8位,是直接砍掉,剩下8位的精度。
反量化,即将8位变成16位,扩充不是为了补充损失的精度,是为了后处理的计算。补充是通过模型的学习来补充回来。
-
模型导出量化
模型导出量化:该行为是发生在模型已经训练完成,并测试通过,要对模型打包部署时进行的。一般来讲,导出量化是牺牲模型的精度来换取模型的推理速度(性能)。
导出量化目的:在低成本的硬件上跑起来。eg:ollama上的模型都做过导出量化。
注意:微调量化QLoRA只发生在模型训练过程中,对权重保存的类型是不产生影响的。
如果在检查点路径中选的是没有导出的权重文件,那么导出量化等级是不可以选择的。
一般来讲,到处量化为了保证量化的误差不要太大,会在量化之后,通过一个数据对量化前后的参数进行"校准"

1.2 模型导出量化环境冲突问题
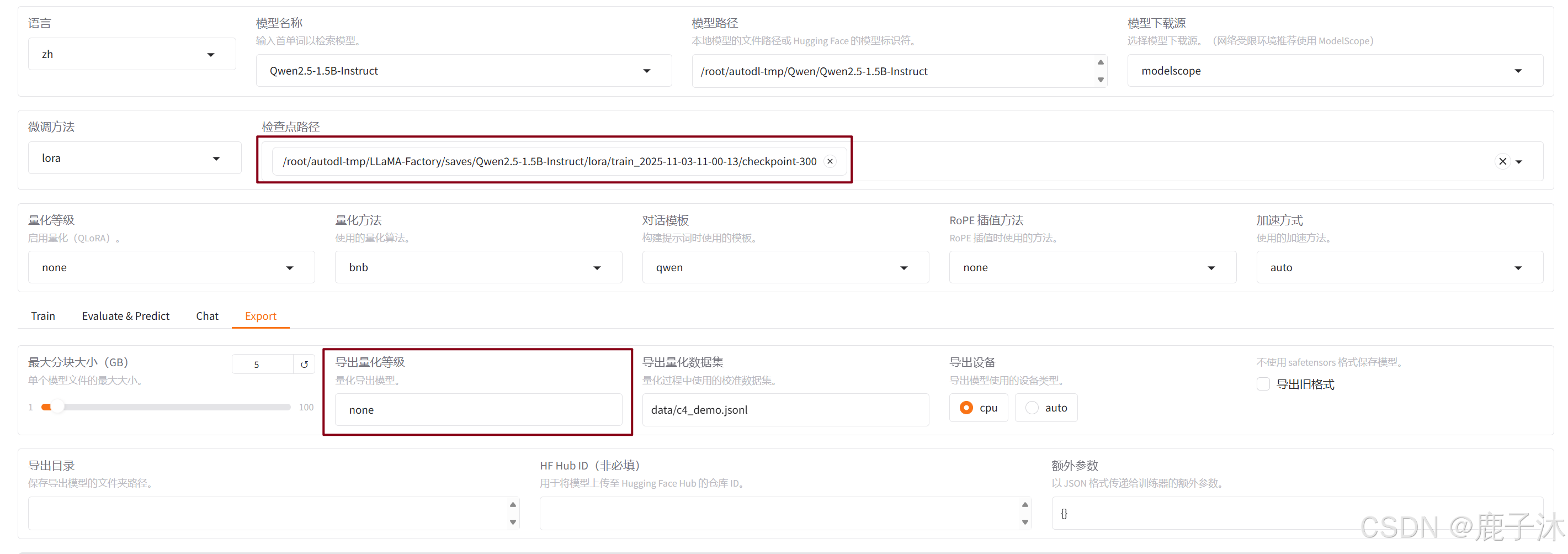
点击开始,出现bug: 
powershell
pip install optimum==1.24.0
powershell
pip install gptqmodel==2.2.0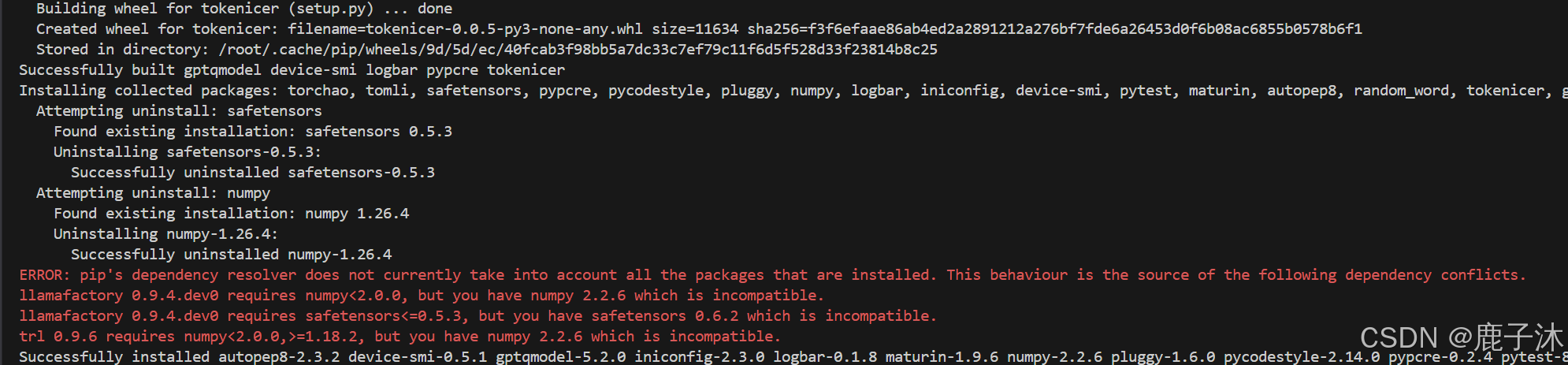
删掉环境重新配置:
powershell
pip install torch==2.3.0
pip install gptqmodel==2.2.0
pip install -e .
pip install bitsandbytes-0.43.2最后安装成功时:numpy-1.26.4, safetensors-0.5.3, bitsandbytes-0.43.2

一般来说,llama-factory直接导出原模式,不需要量化。
2.使用open-webui部署模型
<不适合微调后的模型>
- 创建虚拟环境
注:open-webui对python版本是指定的
powershell
conda create -n open-webui python==3.11- 安装依赖
bash
conda activate open-webui
pip install -U open-webui torch transformers- 运行ollama
bash
ollama serve- 运行open-webui
bash
conda activate open-webui
export ENABLE_OLLAMA_API=True
export OPENAI_API_BASE_URL=http://127.0.0.1:11434/v1
open-webui serve补充
当训练损失到0小数点三位后即可以做测试,eg:0.0006
验证集损失会逐渐增长,并且逐渐放缓,继续训练逐渐平稳,之后下降。大模型微调基本不关心验证集的损失
关于生成式模型的验证/评估问题:
生成式模型的评估分为两种主流方法:主观评估和客观评估
主观评估:通过一些核心问题对模型进行提问,人为判断模型的回复质量 。(主要评测手段)
客观评估: 通过一些具体的评估指标,来判定模型输出的内容与标准答案相似度。(一般作为辅助参考)
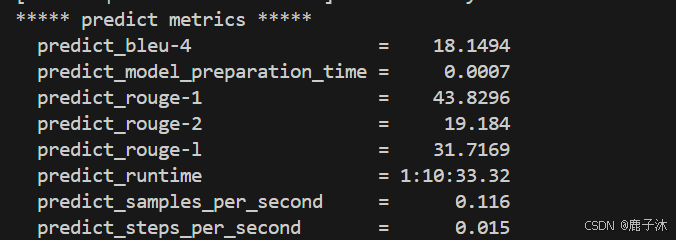
这是对于训练800轮的评估结果(中间评估网不好中断)
客观评估:
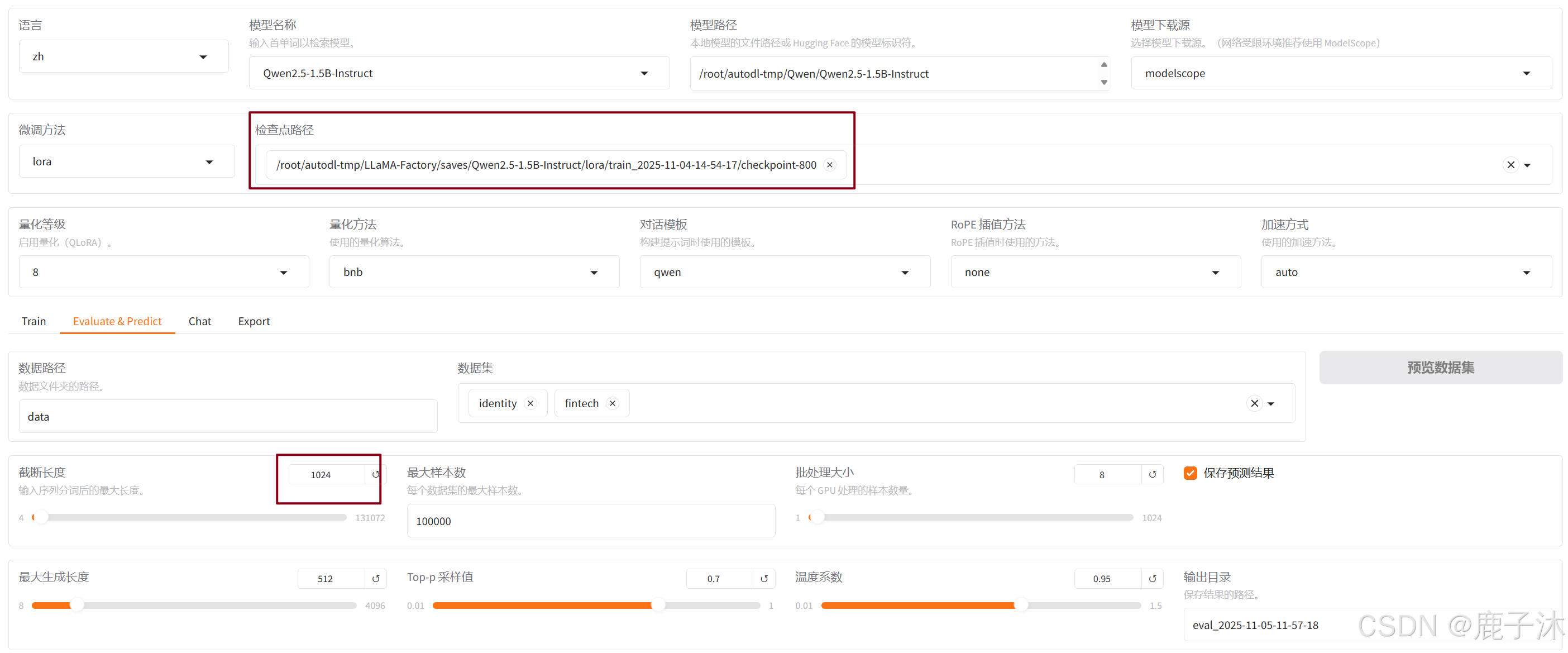
结果: