本文是对SCI自校准光照学习框架的代码解读,原文解读请看SCI文章讲解。
本文的代码来源于SCI官方实现。
1、原文概要
低光图像增强旨在显化暗部信息,但其发展受限于两类方法的缺陷:
- 模型驱动方法:基于 Retinex 理论,依赖手工正则化(如ℓ₂范数、相对总变差),需手动调参,易出现过曝光,且真实场景适应性差。
- 有监督方法:依赖配对数据,模型复杂以及推理效率低;
- 无监督方法:虽无需配对数据,但仍存在颜色失真、细节不足,且部分模型效率仍待提升。
现有方法难以同时满足视觉质量、计算效率、复杂场景鲁棒性三大需求,因此该论文提出 SCI 框架。
SCI分为训练与推理两阶段,核心是 "训练多模块、推理单块":
- 训练阶段:权重共享的级联光照学习模块 + 自校准模块,通过多阶段优化提升基础块表征能力。
- 推理阶段:仅使用单个光照学习基础块(3 个 3×3 卷积 + ReLU),大幅降低计算成本。
整体流程如下图所示:
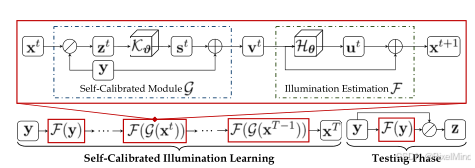
可以看到SCI的训练阶段一直在复用两个模块,分别是Self-Calibrated Module G \mathcal{G} G 以及Illumination Estimation F \mathcal{F} F,测试阶段只使用一次光照估计模块,再除以预测的光照即可得到增强图像。
2、代码结构
如下所示:
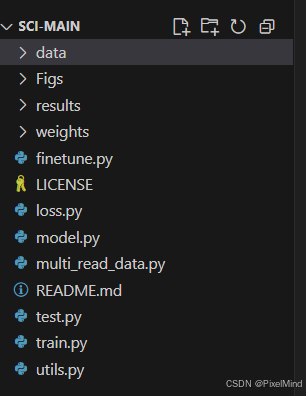
- data:存放着测试数据。
- weights:测试权重。
- finetune.py:用于额外数据微调的训练脚本(可以用于进一步提升预训练模型性能)。
- loss.py:损失函数。
- model.py:模型文件。
- multi_read_data.py:数据加载器。
- test.py:测试脚本。
- train.py:训练脚本。
- utils.py:一些辅助函数。
3 、核心代码模块
multi_read_data.py
这个文件实现了数据集的加载。
python
class MemoryFriendlyLoader(torch.utils.data.Dataset):
def __init__(self, img_dir, task):
self.low_img_dir = img_dir
self.task = task
self.train_low_data_names = []
for root, dirs, names in os.walk(self.low_img_dir):
for name in names:
self.train_low_data_names.append(os.path.join(root, name))
self.train_low_data_names.sort()
self.count = len(self.train_low_data_names)
transform_list = []
transform_list += [transforms.ToTensor()]
self.transform = transforms.Compose(transform_list)
def load_images_transform(self, file):
im = Image.open(file).convert('RGB')
img_norm = self.transform(im).numpy()
img_norm = np.transpose(img_norm, (1, 2, 0))
return img_norm
def __getitem__(self, index):
low = self.load_images_transform(self.train_low_data_names[index])
h = low.shape[0]
w = low.shape[1]
#
h_offset = random.randint(0, max(0, h - batch_h - 1))
w_offset = random.randint(0, max(0, w - batch_w - 1))
#
# if self.task != 'test':
# low = low[h_offset:h_offset + batch_h, w_offset:w_offset + batch_w]
low = np.asarray(low, dtype=np.float32)
low = np.transpose(low[:, :, :], (2, 0, 1))
img_name = self.train_low_data_names[index].split('\\')[-1]
# if self.task == 'test':
# # img_name = self.train_low_data_names[index].split('\\')[-1]
# return torch.from_numpy(low), img_name
return torch.from_numpy(low), img_name
def __len__(self):
return self.count作者在加载数据集时使用的全尺寸的数据输入。
loss.py
损失函数的定义。
python
lass LossFunction(nn.Module):
def __init__(self):
super(LossFunction, self).__init__()
self.l2_loss = nn.MSELoss()
self.smooth_loss = SmoothLoss()
def forward(self, input, illu):
Fidelity_Loss = self.l2_loss(illu, input)
Smooth_Loss = self.smooth_loss(input, illu)
return 1.5*Fidelity_Loss + Smooth_Loss
class SmoothLoss(nn.Module):
def __init__(self):
super(SmoothLoss, self).__init__()
self.sigma = 10
def rgb2yCbCr(self, input_im):
im_flat = input_im.contiguous().view(-1, 3).float()
mat = torch.Tensor([[0.257, -0.148, 0.439], [0.564, -0.291, -0.368], [0.098, 0.439, -0.071]]).cuda()
bias = torch.Tensor([16.0 / 255.0, 128.0 / 255.0, 128.0 / 255.0]).cuda()
temp = im_flat.mm(mat) + bias
out = temp.view(input_im.shape[0], 3, input_im.shape[2], input_im.shape[3])
return out
# output: output input:input
def forward(self, input, output):
self.output = output
self.input = self.rgb2yCbCr(input)
sigma_color = -1.0 / (2 * self.sigma * self.sigma)
w1 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :] - self.input[:, :, :-1, :], 2), dim=1,
keepdim=True) * sigma_color)
w2 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :] - self.input[:, :, 1:, :], 2), dim=1,
keepdim=True) * sigma_color)
w3 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, 1:] - self.input[:, :, :, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w4 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, :-1] - self.input[:, :, :, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w5 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :-1] - self.input[:, :, 1:, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w6 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, 1:] - self.input[:, :, :-1, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w7 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :-1] - self.input[:, :, :-1, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w8 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, 1:] - self.input[:, :, 1:, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w9 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :] - self.input[:, :, :-2, :], 2), dim=1,
keepdim=True) * sigma_color)
w10 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :] - self.input[:, :, 2:, :], 2), dim=1,
keepdim=True) * sigma_color)
w11 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, 2:] - self.input[:, :, :, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w12 = torch.exp(torch.sum(torch.pow(self.input[:, :, :, :-2] - self.input[:, :, :, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w13 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :-1] - self.input[:, :, 2:, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w14 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, 1:] - self.input[:, :, :-2, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w15 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :-1] - self.input[:, :, :-2, 1:], 2), dim=1,
keepdim=True) * sigma_color)
w16 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, 1:] - self.input[:, :, 2:, :-1], 2), dim=1,
keepdim=True) * sigma_color)
w17 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, :-2] - self.input[:, :, 1:, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w18 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, 2:] - self.input[:, :, :-1, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w19 = torch.exp(torch.sum(torch.pow(self.input[:, :, 1:, :-2] - self.input[:, :, :-1, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w20 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-1, 2:] - self.input[:, :, 1:, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w21 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, :-2] - self.input[:, :, 2:, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w22 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, 2:] - self.input[:, :, :-2, :-2], 2), dim=1,
keepdim=True) * sigma_color)
w23 = torch.exp(torch.sum(torch.pow(self.input[:, :, 2:, :-2] - self.input[:, :, :-2, 2:], 2), dim=1,
keepdim=True) * sigma_color)
w24 = torch.exp(torch.sum(torch.pow(self.input[:, :, :-2, 2:] - self.input[:, :, 2:, :-2], 2), dim=1,
keepdim=True) * sigma_color)
p = 1.0
pixel_grad1 = w1 * torch.norm((self.output[:, :, 1:, :] - self.output[:, :, :-1, :]), p, dim=1, keepdim=True)
pixel_grad2 = w2 * torch.norm((self.output[:, :, :-1, :] - self.output[:, :, 1:, :]), p, dim=1, keepdim=True)
pixel_grad3 = w3 * torch.norm((self.output[:, :, :, 1:] - self.output[:, :, :, :-1]), p, dim=1, keepdim=True)
pixel_grad4 = w4 * torch.norm((self.output[:, :, :, :-1] - self.output[:, :, :, 1:]), p, dim=1, keepdim=True)
pixel_grad5 = w5 * torch.norm((self.output[:, :, :-1, :-1] - self.output[:, :, 1:, 1:]), p, dim=1, keepdim=True)
pixel_grad6 = w6 * torch.norm((self.output[:, :, 1:, 1:] - self.output[:, :, :-1, :-1]), p, dim=1, keepdim=True)
pixel_grad7 = w7 * torch.norm((self.output[:, :, 1:, :-1] - self.output[:, :, :-1, 1:]), p, dim=1, keepdim=True)
pixel_grad8 = w8 * torch.norm((self.output[:, :, :-1, 1:] - self.output[:, :, 1:, :-1]), p, dim=1, keepdim=True)
pixel_grad9 = w9 * torch.norm((self.output[:, :, 2:, :] - self.output[:, :, :-2, :]), p, dim=1, keepdim=True)
pixel_grad10 = w10 * torch.norm((self.output[:, :, :-2, :] - self.output[:, :, 2:, :]), p, dim=1, keepdim=True)
pixel_grad11 = w11 * torch.norm((self.output[:, :, :, 2:] - self.output[:, :, :, :-2]), p, dim=1, keepdim=True)
pixel_grad12 = w12 * torch.norm((self.output[:, :, :, :-2] - self.output[:, :, :, 2:]), p, dim=1, keepdim=True)
pixel_grad13 = w13 * torch.norm((self.output[:, :, :-2, :-1] - self.output[:, :, 2:, 1:]), p, dim=1, keepdim=True)
pixel_grad14 = w14 * torch.norm((self.output[:, :, 2:, 1:] - self.output[:, :, :-2, :-1]), p, dim=1, keepdim=True)
pixel_grad15 = w15 * torch.norm((self.output[:, :, 2:, :-1] - self.output[:, :, :-2, 1:]), p, dim=1, keepdim=True)
pixel_grad16 = w16 * torch.norm((self.output[:, :, :-2, 1:] - self.output[:, :, 2:, :-1]), p, dim=1, keepdim=True)
pixel_grad17 = w17 * torch.norm((self.output[:, :, :-1, :-2] - self.output[:, :, 1:, 2:]), p, dim=1, keepdim=True)
pixel_grad18 = w18 * torch.norm((self.output[:, :, 1:, 2:] - self.output[:, :, :-1, :-2]), p, dim=1, keepdim=True)
pixel_grad19 = w19 * torch.norm((self.output[:, :, 1:, :-2] - self.output[:, :, :-1, 2:]), p, dim=1, keepdim=True)
pixel_grad20 = w20 * torch.norm((self.output[:, :, :-1, 2:] - self.output[:, :, 1:, :-2]), p, dim=1, keepdim=True)
pixel_grad21 = w21 * torch.norm((self.output[:, :, :-2, :-2] - self.output[:, :, 2:, 2:]), p, dim=1, keepdim=True)
pixel_grad22 = w22 * torch.norm((self.output[:, :, 2:, 2:] - self.output[:, :, :-2, :-2]), p, dim=1, keepdim=True)
pixel_grad23 = w23 * torch.norm((self.output[:, :, 2:, :-2] - self.output[:, :, :-2, 2:]), p, dim=1, keepdim=True)
pixel_grad24 = w24 * torch.norm((self.output[:, :, :-2, 2:] - self.output[:, :, 2:, :-2]), p, dim=1, keepdim=True)
ReguTerm1 = torch.mean(pixel_grad1) \
+ torch.mean(pixel_grad2) \
+ torch.mean(pixel_grad3) \
+ torch.mean(pixel_grad4) \
+ torch.mean(pixel_grad5) \
+ torch.mean(pixel_grad6) \
+ torch.mean(pixel_grad7) \
+ torch.mean(pixel_grad8) \
+ torch.mean(pixel_grad9) \
+ torch.mean(pixel_grad10) \
+ torch.mean(pixel_grad11) \
+ torch.mean(pixel_grad12) \
+ torch.mean(pixel_grad13) \
+ torch.mean(pixel_grad14) \
+ torch.mean(pixel_grad15) \
+ torch.mean(pixel_grad16) \
+ torch.mean(pixel_grad17) \
+ torch.mean(pixel_grad18) \
+ torch.mean(pixel_grad19) \
+ torch.mean(pixel_grad20) \
+ torch.mean(pixel_grad21) \
+ torch.mean(pixel_grad22) \
+ torch.mean(pixel_grad23) \
+ torch.mean(pixel_grad24)
total_term = ReguTerm1
return total_term定义了两个损失:
- L2损失。
- 平滑损失:通过空间自适应权重约束光照分量的空间平滑性,避免低光增强后出现纹理失真或噪声放大,同时兼容 RGB 图像输入(需先转换为 YUV 空间以贴合人眼视觉特性),总共24个相对点的梯度,分别是w1-w2代表垂直方向(上 - 下、下 - 上,步长 1)、w3-w4代表水平方向(左 - 右、右 - 左,步长 1)、w5-w8代表对角线方向(左上 - 右下、右下 - 左上、右上 - 左下、左下 - 右上,步长 1)、w9-w24代表大步长邻域(步长 2,覆盖垂直、水平、对角线)。
model.py
模型结构实现。
python
class EnhanceNetwork(nn.Module):
def __init__(self, layers, channels):
super(EnhanceNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.ReLU()
)
self.conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.conv)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
illu = fea + input
illu = torch.clamp(illu, 0.0001, 1)
return illu
class CalibrateNetwork(nn.Module):
def __init__(self, layers, channels):
super(CalibrateNetwork, self).__init__()
kernel_size = 3
dilation = 1
padding = int((kernel_size - 1) / 2) * dilation
self.layers = layers
self.in_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.convs = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU(),
nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=1, padding=padding),
nn.BatchNorm2d(channels),
nn.ReLU()
)
self.blocks = nn.ModuleList()
for i in range(layers):
self.blocks.append(self.convs)
self.out_conv = nn.Sequential(
nn.Conv2d(in_channels=channels, out_channels=3, kernel_size=3, stride=1, padding=1),
nn.Sigmoid()
)
def forward(self, input):
fea = self.in_conv(input)
for conv in self.blocks:
fea = fea + conv(fea)
fea = self.out_conv(fea)
delta = input - fea
return delta
class Network(nn.Module):
def __init__(self, stage=3):
super(Network, self).__init__()
self.stage = stage
self.enhance = EnhanceNetwork(layers=1, channels=3)
self.calibrate = CalibrateNetwork(layers=3, channels=16)
self._criterion = LossFunction()
def weights_init(self, m):
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
if isinstance(m, nn.BatchNorm2d):
m.weight.data.normal_(1., 0.02)
def forward(self, input):
ilist, rlist, inlist, attlist = [], [], [], []
input_op = input
for i in range(self.stage):
inlist.append(input_op)
i = self.enhance(input_op)
r = input / i
r = torch.clamp(r, 0, 1)
att = self.calibrate(r)
input_op = input + att
ilist.append(i)
rlist.append(r)
attlist.append(torch.abs(att))
return ilist, rlist, inlist, attlist
def _loss(self, input):
i_list, en_list, in_list, _ = self(input)
loss = 0
for i in range(self.stage):
loss += self._criterion(in_list[i], i_list[i])
return loss以上包含三大核心网络模块:EnhanceNetwork(光照估计网络)、CalibrateNetwork(自校准模块)、Network(级联训练框架)。
- EnhanceNetwork:输入低光图像或重定义输入,输出估计的光照分量(illu),是 SCI 框架的核心推理单元(推理时仅需 1 个该模块)。实现与公式相对应,学习的光照的残差。
- CalibrateNetwork :输入反射分量(r),输出自校准图(delta),用于重定义下一阶段的输入(input_op = input + att),推动多阶段结果收敛(训练时用,推理时弃用)。
delta对应公式中的自校准图,捕捉反射分量的偏差,通过input + att将下一阶段输入与原始低光图关联,迫使多阶段光照结果收敛到同一最优值。 - Network:封装 SCI 的多阶段级联训练流程,整合EnhanceNetwork和CalibrateNetwork,实现 "训练时多阶段优化,推理时单阶段输出",同时计算总损失(调用LossFunction,对应论文的无监督损失)。
train.py
训练脚本,常见的流程,将我们前面讲到的数据,损失和模型导入使用即可。
python
def main():
if not torch.cuda.is_available():
logging.info('no gpu device available')
sys.exit(1)
np.random.seed(args.seed)
cudnn.benchmark = True
torch.manual_seed(args.seed)
cudnn.enabled = True
torch.cuda.manual_seed(args.seed)
logging.info('gpu device = %s' % args.gpu)
logging.info("args = %s", args)
model = Network(stage=args.stage)
model.enhance.in_conv.apply(model.weights_init)
model.enhance.conv.apply(model.weights_init)
model.enhance.out_conv.apply(model.weights_init)
model.calibrate.in_conv.apply(model.weights_init)
model.calibrate.convs.apply(model.weights_init)
model.calibrate.out_conv.apply(model.weights_init)
model = model.cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr, betas=(0.9, 0.999), weight_decay=3e-4)
MB = utils.count_parameters_in_MB(model)
logging.info("model size = %f", MB)
print(MB)
train_low_data_names = 'Your train dataset'
TrainDataset = MemoryFriendlyLoader(img_dir=train_low_data_names, task='train')
test_low_data_names = './data/medium'
TestDataset = MemoryFriendlyLoader(img_dir=test_low_data_names, task='test')
train_queue = torch.utils.data.DataLoader(
TrainDataset, batch_size=args.batch_size,
pin_memory=True, num_workers=0, shuffle=True)
test_queue = torch.utils.data.DataLoader(
TestDataset, batch_size=1,
pin_memory=True, num_workers=0, shuffle=True)
total_step = 0
for epoch in range(args.epochs):
model.train()
losses = []
for batch_idx, (input, _) in enumerate(train_queue):
total_step += 1
input = Variable(input, requires_grad=False).cuda()
optimizer.zero_grad()
loss = model._loss(input)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 5)
optimizer.step()
losses.append(loss.item())
logging.info('train-epoch %03d %03d %f', epoch, batch_idx, loss)
logging.info('train-epoch %03d %f', epoch, np.average(losses))
utils.save(model, os.path.join(model_path, 'weights_%d.pt' % epoch))
if epoch % 1 == 0 and total_step != 0:
logging.info('train %03d %f', epoch, loss)
model.eval()
with torch.no_grad():
for _, (input, image_name) in enumerate(test_queue):
input = Variable(input, volatile=True).cuda()
image_name = image_name[0].split('\\')[-1].split('.')[0]
illu_list, ref_list, input_list, atten= model(input)
u_name = '%s.png' % (image_name + '_' + str(epoch))
u_path = image_path + '/' + u_name
save_images(ref_list[0], u_path)3、总结
SCI首次通过 "权重共享 + 自校准模块" 实现多阶段结果收敛,训练用多模块,推理仅用单块(3 个 3×3 卷积),大幅提升效率。利用定义的无监督损失(保真损失 + 平滑损失),无需配对数据或主观评分,提升复杂场景适应性。在下游任务(低光人脸检测、夜间语义分割)中表现优异,验证了其在安防监控、自动驾驶等实际场景的应用潜力。但也有其局限性,例如偏色。
感谢阅读,欢迎留言或私信,一起探讨和交流。
如果对你有帮助的话,也希望可以给博主点一个关注,感谢。