- 开发语言:Python
- 框架:flask
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
系统首页
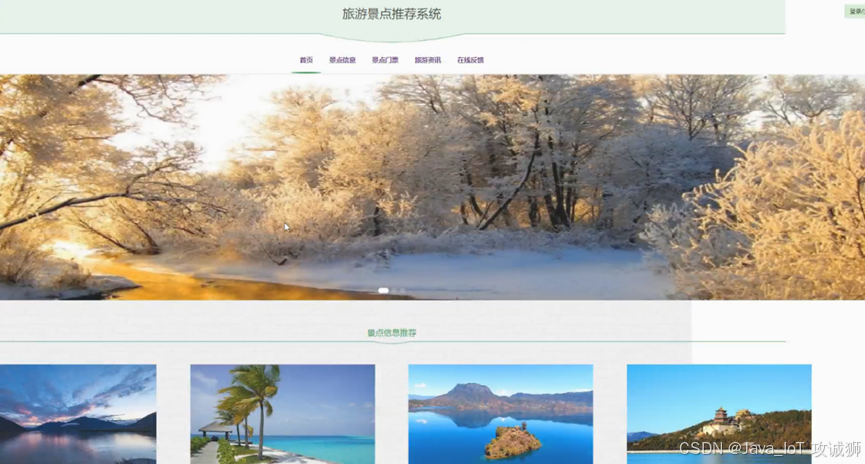
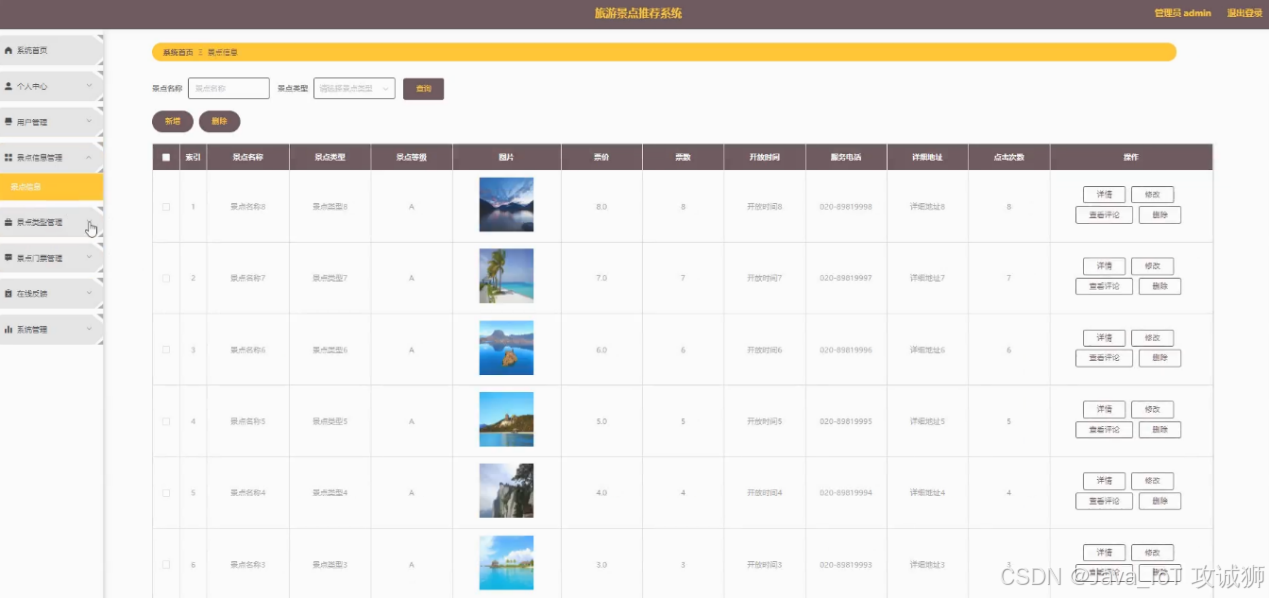
景点信息页面
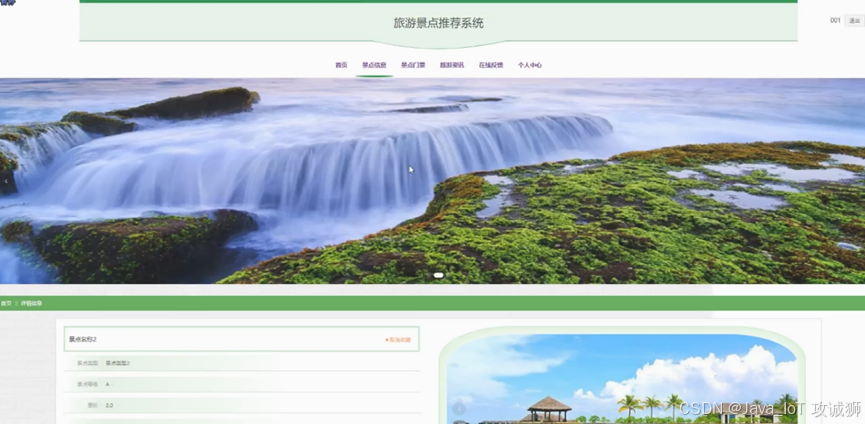
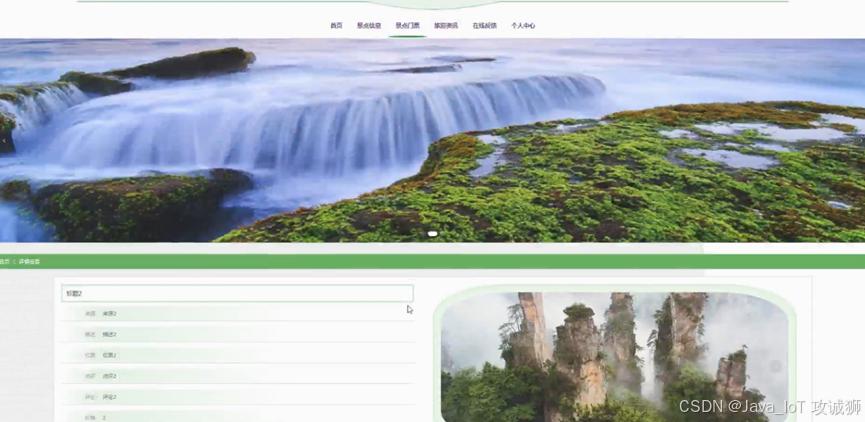
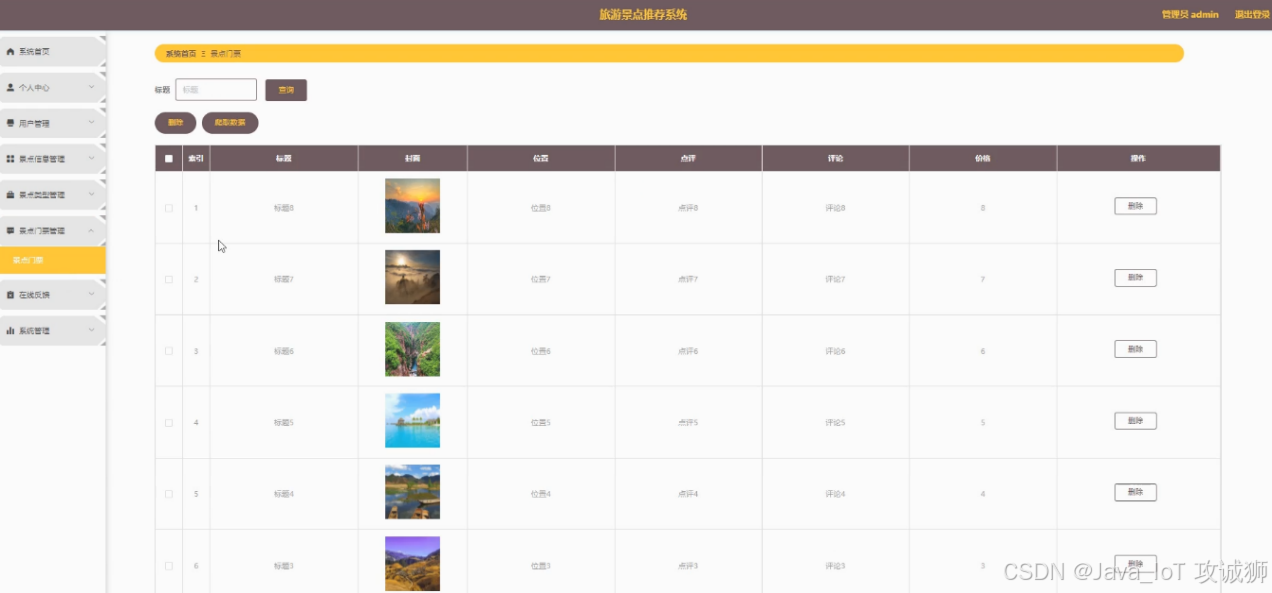
景点门票页面
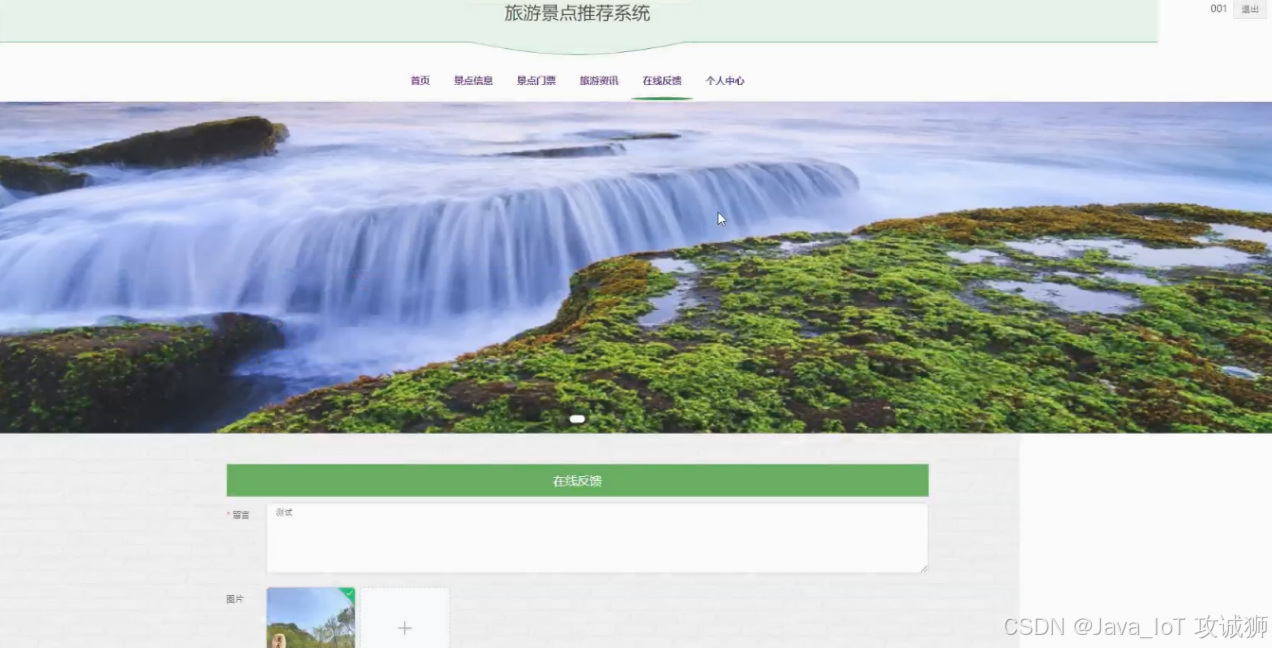
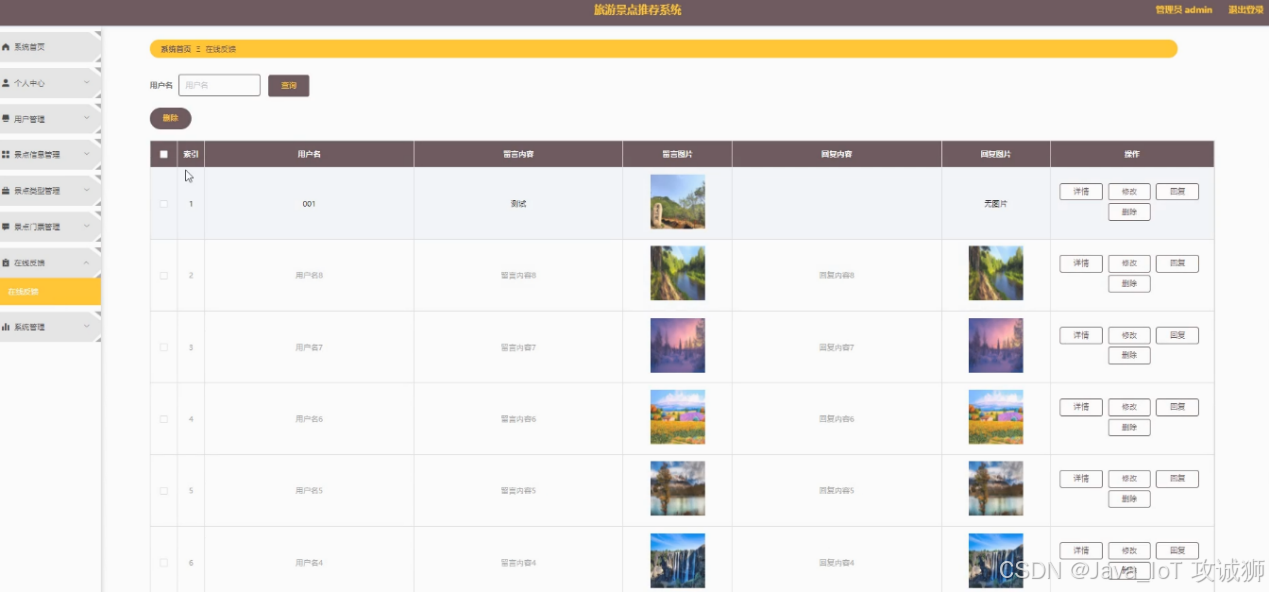
在线反馈
个人中心
管理员登录
管理员功能界面
用户管理
景点管理
门票管理
在线反馈
系统管理

摘要
相比于以前的传统旅游景点推荐手工管理方式,智能化的管理方式可以大幅降低景区的运营人员成本,实现了旅游景点推荐的标准化、制度化、程序化的管理,有效地防止了旅游景点推荐的随意管理,提高了信息的处理速度和精确度,能够及时、准确地查询和修正旅游景点推荐情况等信息。
课题主要采用Python开发技术和MySQL数据库开发技术以及基于OpenCV的图像识别。系统主要包括系统首页、个人中心、用户管理、景点信息管理、景点类型管理、景点门票管理、在线反馈、系统管理等功能,从而实现智能化的旅游景点推荐方式,提高旅游景点推荐的效率。
研究背景
主要是对于旅游景点推荐工作调研,以及对旅游景点推荐信息采集、存储、查询和更新。在旅游景点推荐问题上对于现有管理上的不足,用户可以通过后期查询旅游景点推荐信息情况,从而使旅游景点推荐更加便利。
设计者往往以需求为中心进行工作,而大多数的功能需求是从总体上进行分析和思考,即从设计者的角度去了解需求。但是要真正理解真实需要,光从开发人员的观点出发还远远不够,还需要从实际的行业发展以及相关地方情况考虑,要从更高的层面去分析,这是真实的需要;同时,我们也要更好的了解他们的用户思维,了解他们的应用情况,和他们的思想,这是他们的需要。。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Flask是一个使用Python编写的轻量级Web应用框架。它被称为一个"微框架"(microframework),因为它只提供Web应用所需的最核心的功能,如路由、会话管理和模板引擎等,而不像一些更全面的框架那样包含数据库层、表单处理等功能。然而,Flask的扩展生态系统非常丰富,开发者可以通过添加扩展来为Flask应用添加这些额外的功能。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
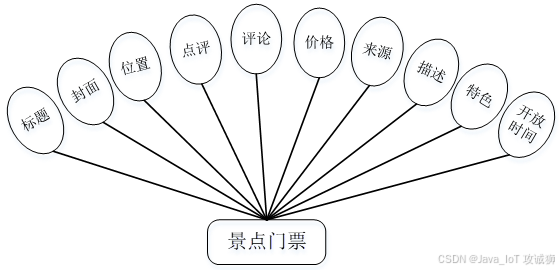
系统设计
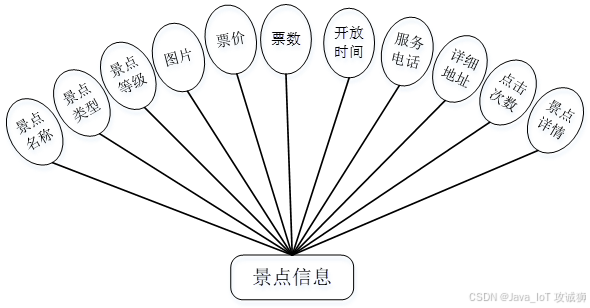
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
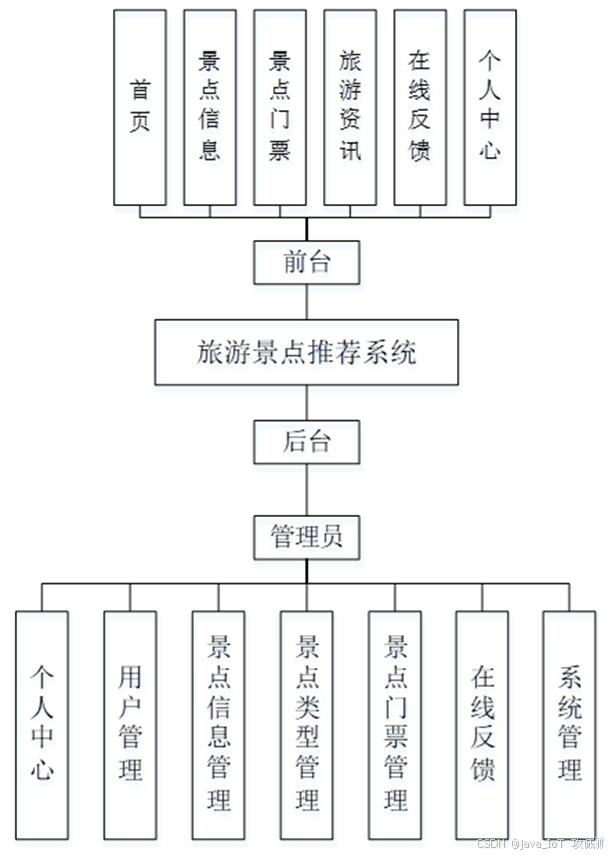
系统实现
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。在个人中心页面通过填写个人详细信息进行信息更新操作;还可以对我的收藏进行详细操作。管理员进入主页面,主要功能包括对系统首页、个人中心、用户管理、景点信息管理、景点类型管理、景点门票管理、在线反馈、系统管理等进行操作。
代码实现
python
# 景点门票
class JingdianmenpiaoSpider(scrapy.Spider):
name = 'jingdianmenpiaoSpider'
spiderUrl = 'https://piao.qunar.com/ticket/list.htm?keyword=%E4%B8%89%E4%BA%9A®ion=%E4%B8%89%E4%BA%9A&from=mpshouye_hotcity&page={}'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
headers = {
"cookie":"SECKEY_ABVK=vlhpRLsLQG31Po7dyp9LqTMtJLQ3dsXhz9zVlkQGCVY%3D; BMAP_SECKEY=fYAVeumEoDJpvS6t9mUnISYaCgDtMdIbi8Q-n0uetICzYXbs2WlisW0MqhI-p18uhCVWm-xTJAod_iP_N0XOlRagjBbmjufutVcIXstVSS5VyV6twfaq2UAs4ybEWsYz2CmZ6dZ18N7zNYBA8DNrOnho-12qc3j_p9RVMNjQliuWn7o8_7kBv-qvUvOEvKsE; QN1=00008c0031984ca726d0ccdd; HN1=v1d5a05c0541e94af107a046147dde57e6; HN2=qungnknsnqczr; QN300=s%3Dbaidu; _i=DFiEuMlwNifDZ7e6ttNii8l8C0yw; QN269=3C0E7D80A48D11EDA4E6FA163E7C276C; fid=c122ef21-269d-44af-816b-a3af77b6e9a0; ctt_june=1654604625968##iK3wWsjmahPwawPwa%3DXNWK0GE2GIaRkTESWRa%3Da8aDkGES0REDPsXPWGWKj8iK3siK3saKj%2BWKPnWsj%2BaSjnVuPwaUvt; ctf_june=1654604625968##iK3wVRtnahPwawPwasWGa%3DasWK2naS2%3DaSETVPDmWSXNWSvmXSWGX%3DPOVRDniK3siK3saKj%2BWKPnWsjmaSj%3DWwPwaUvt; cs_june=a4e7c8acd60e0c8483c9c4af0f303f81fd7bf3054fa1059b680a62984007c656679c337a756eb8f3b21f18c3ca84c016ab0131ff331f4cb4e98fa22f3456d33eb17c80df7eee7c02a9c1a6a5b97c117961a58ae707d2d19d229b1e3a0abd1ac65a737ae180251ef5be23400b098dd8ca; qunar-assist={%22version%22:%2220211215173359.925%22%2C%22show%22:false%2C%22audio%22:false%2C%22speed%22:%22middle%22%2C%22zomm%22:1%2C%22cursor%22:false%2C%22pointer%22:false%2C%22bigtext%22:false%2C%22overead%22:false%2C%22readscreen%22:false%2C%22theme%22:%22default%22}; QN205=organic; QN277=organic; QN267=9396775019e5e926c; csrfToken=CHPGSBwmGivAQIY68e9qdAdiTV3ndNSv; _vi=ZKi8xGvqZst79uJQXbKsgFL7Jho5unICeWG16K29ESyCjtCO270zex9s4MDZEOqYKZKEsVyVxT9mj8OCVxjqwvR4nt-5fXU7kef8zlXV18xDCruTUNslqEjzk6Ib_9iWpMCYzuZRKwGp093lSTj4tkPCZOLee4JlWwZgzgMT5OUU; QN57=16773851843530.3742666257450069; QN58=1677385184352%7C1677385184352%7C1; JSESSIONID=52C681FD1548DEDBCDDD65EC9D9FB783; Hm_lvt_15577700f8ecddb1a927813c81166ade=1677385185; Hm_lpvt_15577700f8ecddb1a927813c81166ade=1677385185; QN271=ba5ce393-4cec-4280-86e7-9c6d08cc86c3; __qt=v1%7CVTJGc2RHVmtYMTlhR0x4V3J2S3V1bElZaHExMmJXOEJLaC9wT2xSeWQ2THZRZVZoOEgyTUk0OEsxSlp5L29FMVFDTWo0U1BCZ2ZNK0I0WFNiTVgwZXZzMnk0WGVQODR5NmZJVkQyVmk4ZG41ZWYrSlFzMXVOSXo1TGczNG1VYXVFVnhoSXRyU3luNXBwSGQxMUYzV3VBPT0%3D%7C1677385198459%7CVTJGc2RHVmtYMTlJbEUyZnhIdWExYXdhdDE0dHdBRkNqQ2QrMkt0T1BqN3IxRFYrRUdUSzBYemVNQ2taYXFMSW5JZytsSW5MOTRjQ29LUXZLNUhqSGc9PQ%3D%3D%7CVTJGc2RHVmtYMTlnQllyaFFzTDVKQkVkdW43SGlQSW8wYlNGVVAxQXhQU2R4TEEzYTZ6T0hOQXJ1c3VscmtkTE16Vng4ZThaYWViUlYwanVCZ3JGei9GTi83VFAyanNLbGxwSTBwRUM4VVVHWUxHb1R0akFPUnA2TlVSdFA2M1JiTVpiQlFxZDhKMEVGOCtnTEdDcWxubHNZWURWS0NMQWRDaU1VelBNM1EvQWtzRTVPdjhUWlBXZ2Z4STJmRUpxdWdLeldvNnJOcDFaVis4R1ZNa09xbjBueFNTRElOeVJRVnczTllHUU9rWjdrMndRM05ySlF5RDNKTHJtQlprVjV6a3greE9zZy8xNlRrdmtWZEliVGFJRDRzWjBOMU9EVzV6cCtvRUhXVGd4VzlKenJCbHBaVkh1MEZzc3l2SzlqRmtVbGx6SElLc2dKcjdVaXUzRHlHUVdsOUIwOEJsNy9IamwxbHB6TFVjQ09MbG5FaXFCc1hqN0hKcFlhcy90aXI3NVJzTk9DRjJKc3lqNjZoMjIvS3pGTTNHMC83MjRZYUNtV3RNN1lnOERUR2FvN2tNY0ZhdGlYWXFBcndaUTl0ZjNXV3lOREg1S1lTQzgzQjdtNXpFT3llNVNrb1AycjAzaHdPM3VxQlRQZjd3YmZlaXUzOXBsNUFwSW44M253YTJLWWVBV0ZybXM0UUhmVE5Qb3BLVzl6b2R2UXN6bmNFRk1ReVZmNW9TOGdFZ3FkckFFSU1QeDhpZTBvaDUvWll0NEptRE14ZUlDNWZGc3VMcndQQ0krOVpjM3RNRjkveGRTR1RuZExmTmMyQTJTRytDSU51VGpobExnNFROVitNUEUrNHlDK3hqanA4Yll6bFdkSTNnMFdmam14MFNFV2dEQ0pVVmpkQ0NNOXZYeHljOGJSeWNWMmFVQnZkY0xFK3hLMUcrN2N0ZHFEajNUMzVQa3c2UXdjRmh1bmlWTkR4TG9ISXpKZUdYb0JvM1JnSzNXNE9CdklRaWExbEs1SndoUTdXWStoTmQ4RDFZcFBkYjFEWXZUdXFYRFNyb2xvWFRSdW9zZmxGdTV6WTIxaFVoSngxMHJnWXlyOVRQSw%3D%3D"
}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def start_requests(self):
plat = platform.system().lower()
if plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '2nn2j_jingdianmenpiao') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
headers=self.headers,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '2nn2j_jingdianmenpiao') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('div#search-list div[class~="sight_item"]')
for item in list:
fields = JingdianmenpiaoItem()
fields["laiyuan"] = self.remove_html(item.css('h3.sight_item_caption a.name::attr(href)').extract_first())
fields["jiage"] = self.remove_html(item.css('span.sight_item_price em::text').extract_first())
detailUrlRule = item.css('h3.sight_item_caption a.name::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, headers=self.headers, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div.mp-description-detail div.mp-description-view span.mp-description-name::text''':
fields["biaoti"] = re.findall(r'''div.mp-description-detail div.mp-description-view span.mp-description-name::text''', response.text, re.S)[0].strip()
else:
if 'biaoti' != 'xiangqing' and 'biaoti' != 'detail' and 'biaoti' != 'pinglun' and 'biaoti' != 'zuofa':
fields["biaoti"] = self.remove_html(response.css('''div.mp-description-detail div.mp-description-view span.mp-description-name::text''').extract_first())
else:
fields["biaoti"] = emoji.demojize(response.css('''div.mp-description-detail div.mp-description-view span.mp-description-name::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''div#mp-slider-content div.mp-description-image img::attr(src)''':
fields["fengmian"] = re.findall(r'''div#mp-slider-content div.mp-description-image img::attr(src)''', response.text, re.S)[0].strip()
else:
if 'fengmian' != 'xiangqing' and 'fengmian' != 'detail' and 'fengmian' != 'pinglun' and 'fengmian' != 'zuofa':
fields["fengmian"] = self.remove_html(response.css('''div#mp-slider-content div.mp-description-image img::attr(src)''').extract_first())
else:
fields["fengmian"] = emoji.demojize(response.css('''div#mp-slider-content div.mp-description-image img::attr(src)''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.mp-description-onesentence::text''':
fields["miaoshu"] = re.findall(r'''div.mp-description-onesentence::text''', response.text, re.S)[0].strip()
else:
if 'miaoshu' != 'xiangqing' and 'miaoshu' != 'detail' and 'miaoshu' != 'pinglun' and 'miaoshu' != 'zuofa':
fields["miaoshu"] = self.remove_html(response.css('''div.mp-description-onesentence::text''').extract_first())
else:
fields["miaoshu"] = emoji.demojize(response.css('''div.mp-description-onesentence::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span.mp-description-address::text''':
fields["weizhi"] = re.findall(r'''span.mp-description-address::text''', response.text, re.S)[0].strip()
else:
if 'weizhi' != 'xiangqing' and 'weizhi' != 'detail' and 'weizhi' != 'pinglun' and 'weizhi' != 'zuofa':
fields["weizhi"] = self.remove_html(response.css('''span.mp-description-address::text''').extract_first())
else:
fields["weizhi"] = emoji.demojize(response.css('''span.mp-description-address::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''span#mp-description-commentscore''':
fields["dianping"] = re.findall(r'''span#mp-description-commentscore''', response.text, re.S)[0].strip()
else:
if 'dianping' != 'xiangqing' and 'dianping' != 'detail' and 'dianping' != 'pinglun' and 'dianping' != 'zuofa':
fields["dianping"] = self.remove_html(response.css('''span#mp-description-commentscore''').extract_first())
else:
fields["dianping"] = emoji.demojize(response.css('''span#mp-description-commentscore''').extract_first())
except:
pass
try:
if '(.*?)' in '''span.mp-description-commentCount a::text''':
fields["pinglun"] = re.findall(r'''span.mp-description-commentCount a::text''', response.text, re.S)[0].strip()
else:
if 'pinglun' != 'xiangqing' and 'pinglun' != 'detail' and 'pinglun' != 'pinglun' and 'pinglun' != 'zuofa':
fields["pinglun"] = self.remove_html(response.css('''span.mp-description-commentCount a::text''').extract_first())
else:
fields["pinglun"] = emoji.demojize(response.css('''span.mp-description-commentCount a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.mp-charact-intro div.mp-charact-desc''':
fields["tese"] = re.findall(r'''div.mp-charact-intro div.mp-charact-desc''', response.text, re.S)[0].strip()
else:
if 'tese' != 'xiangqing' and 'tese' != 'detail' and 'tese' != 'pinglun' and 'tese' != 'zuofa':
fields["tese"] = self.remove_html(response.css('''div.mp-charact-intro div.mp-charact-desc''').extract_first())
else:
fields["tese"] = emoji.demojize(response.css('''div.mp-charact-intro div.mp-charact-desc''').extract_first())
except:
pass
try:
if '(.*?)' in '''div.mp-charact-content div.mp-charact-desc''':
fields["kaifangshijian"] = re.findall(r'''div.mp-charact-content div.mp-charact-desc''', response.text, re.S)[0].strip()
else:
if 'kaifangshijian' != 'xiangqing' and 'kaifangshijian' != 'detail' and 'kaifangshijian' != 'pinglun' and 'kaifangshijian' != 'zuofa':
fields["kaifangshijian"] = self.remove_html(response.css('''div.mp-charact-content div.mp-charact-desc''').extract_first())
else:
fields["kaifangshijian"] = emoji.demojize(response.css('''div.mp-charact-content div.mp-charact-desc''').extract_first())
except:
pass
return fields
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into jingdianmenpiao(
laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
)
select
laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
from 2nn2j_jingdianmenpiao
where(not exists (select
laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
from jingdianmenpiao where
jingdianmenpiao.laiyuan=2nn2j_jingdianmenpiao.laiyuan
and jingdianmenpiao.biaoti=2nn2j_jingdianmenpiao.biaoti
and jingdianmenpiao.fengmian=2nn2j_jingdianmenpiao.fengmian
and jingdianmenpiao.miaoshu=2nn2j_jingdianmenpiao.miaoshu
and jingdianmenpiao.weizhi=2nn2j_jingdianmenpiao.weizhi
and jingdianmenpiao.dianping=2nn2j_jingdianmenpiao.dianping
and jingdianmenpiao.pinglun=2nn2j_jingdianmenpiao.pinglun
and jingdianmenpiao.jiage=2nn2j_jingdianmenpiao.jiage
and jingdianmenpiao.tese=2nn2j_jingdianmenpiao.tese
and jingdianmenpiao.kaifangshijian=2nn2j_jingdianmenpiao.kaifangshijian
))
limit {0}
'''.format(random.randint(20,30))
cursor.execute(sql)
connect.commit()
connect.close()系统测试
系统的测试是必须的,需要知道的是这个阶段不是单独的,而是在全部的时间进行。这么做可以及时发现问题,还能找到产生矛盾的地方,并且可以尝试修改,这样就能完善系统。对于被测试的系统,都可以找到一些问题,而且还可以找到对应的位置在哪。其目的是对于整体的测试,发现需求中存在的矛盾,就可以做出修改了。测试的过程是对应于整体,有对软件的测试,发现需求的符合度,接下来,就是对数据的检测,以及对硬件的检测。
在软件测试规划中,必须了解测试流程,包括功能概述,测试周期,测试方法,测试范围,测试配置,测试技巧,测试交流,风险分析等。对于一些开发的人员,是可以知道测试方法,找到测试过程的一些的问题,然后可以应对这些问题。
结论
此次系统从整体看来,已基本达到预期的设计目的,能够实现基本的功能,但相较于市场的一些优秀系统而言,还是有许多不足的地方。遗憾的是,由于时间的有限,已经不允许再投入更多的时间和精力进行研究开发。相信在以后的工作中,我会接触到更多相关的知识,会更丰富自身的经验,我希望到时能够在此基础上完成一个丰富完整的系统,这将对我有很大的意义。
通过这次的毕业设计,我学到了很多,除了学识方面的知识,在态度上也有了很大的转变,细心和耐心是整个开发过程中最重要的两件事。我也在跟随着系统的完善而成长,这次毕业设计考核地也不单单是所学的知识,也同样在衡量着面对困难时的态度。