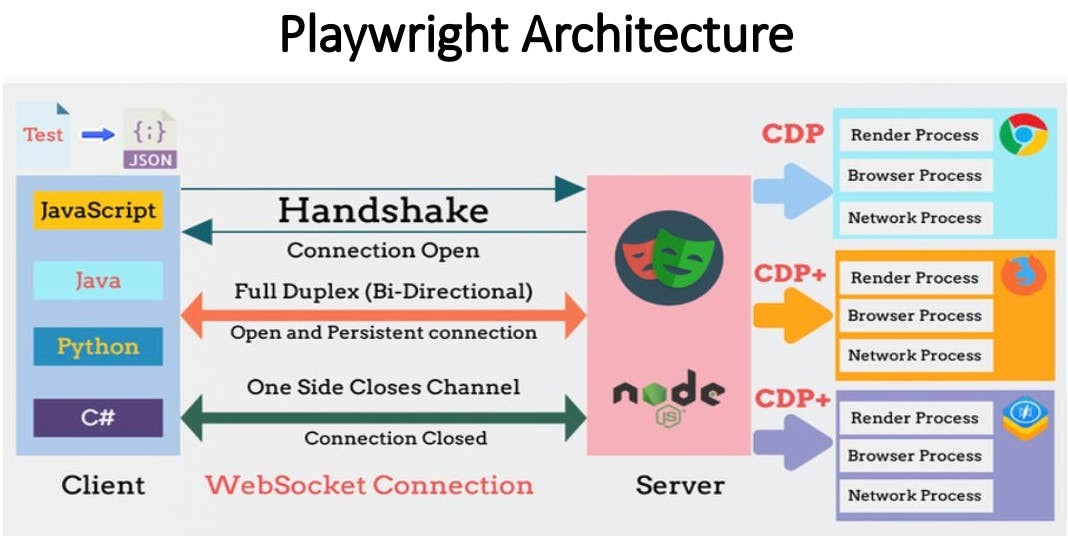
Browser-Use 是一个让 LLM 直接"看网页、点网页、填表单" 的开源代理框架,本质上是:LLM 规划 + 网页感知(DOM/截图)+ 动作执行(Playwright)+ 记忆与反馈 的闭环系统。GitHub+1
https://github.com/browser-use/browser-use?utm_source=chatgpt.com
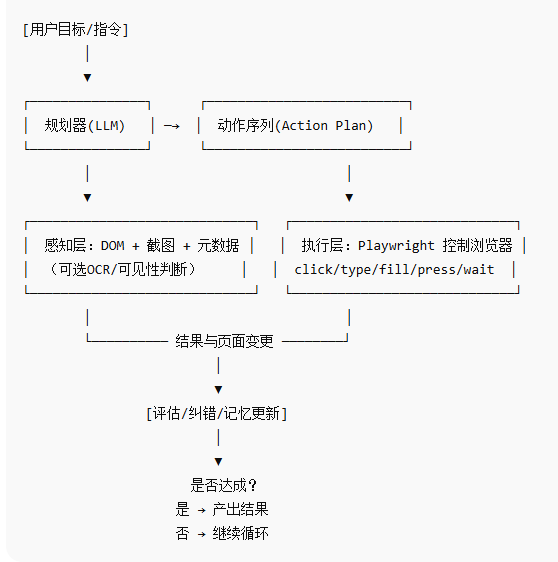
1)整体架构
-
执行载体 :底层以 Playwright 驱动真实浏览器,通过 CDP/WebSocket 与浏览器进程通讯,稳定完成多步交互与等待。
-
核心循环 :感知 → 规划 → 执行 → 反馈 → 迭代,直到达成"页面变更/目标完成"。Browser Use
https://docs.browser-use.com/?utm_source=chatgpt.com
2)关键模块讲解
A. 感知层:把网页"讲给"模型听
-
DOM 片段化:抽取可交互元素(按钮、输入框、链接)的语义与定位;必要时携带周边文本上下文。
-
截图/可视:提供整页或局部截图,辅助模型进行"视觉定位"。
-
页面变更检测 :执行后监测 URL、DOM 树、网络请求或布局变化,作为"动作成功"的信号。
(以上均由框架封装,开发者只写高层目标)Browser Use+1
https://docs.browser-use.com/?utm_source=chatgpt.com
B. 规划器(LLM)
-
把目标拆成步骤:例如"打开站点→登录→搜索→分页抓取"。
-
动作空间约束 :只允许
click / fill / press / wait_for_* / goto等白名单动作,减少"幻想操作"。 -
思考开关 :文档提供
use_thinking、flash_mode等参数,平衡速度与稳健性。Browser Usehttps://docs.browser-use.com/customize/agent/all-parameters?utm_source=chatgpt.com
C. 执行层(Playwright)
-
强等待语义:基于可见性/可点击性/网络空闲的等待,降低脚本脆弱度。
-
多上下文/多标签页 支持,隔离会话与cookies。
-
跨浏览器(Chromium/Firefox/WebKit)与无头/有头模式。
D. 记忆与反馈
-
短期记忆:刚执行过的元素、最近失败的动作与原因。
-
长程记忆 :站点流程经验(如"该站点登录后需两步验证"),用于后续同类任务复用。Browser Use
https://docs.browser-use.com/?utm_source=chatgpt.com
3)最小工作流
-
设定目标(自然语言)
-
感知页面(DOM+截图)→ 生成候选动作
-
执行动作(Playwright)→ 等待页面变更
-
评估(成功?失败原因?)→ 写入记忆
-
迭代 (直到完成或超出安全/步数限制)Browser Use
https://docs.browser-use.com/?utm_source=chatgpt.com
4)与"脚本式自动化"的差异(对照表)
| 维度 | 传统脚本(Selenium/Playwright 手写) | Browser-Use(LLM 代理) |
|---|---|---|
| 开发方式 | 明确写选择器与步骤 | 自然语言目标 + 框架自动找元素 |
| 适应变更 | 选择器易脆弱 | 通过语义/视觉重定位,容错更强 |
| 调试 | 工程师逐步排错 | 结合"思考日志/记忆"回溯原因 |
| 风险 | 需处理大量 wait/异常 | 框架内置等待与失败重试策略 |
(底层同样依赖 Playwright,但上层抽象 与恢复力 更强)Medium![]() https://medium.com/data-and-beyond/browser-use-explained-the-open-source-ai-agent-that-clicks-reads-and-automates-the-web-d4689f3ef012?utm_source=chatgpt.com
https://medium.com/data-and-beyond/browser-use-explained-the-open-source-ai-agent-that-clicks-reads-and-automates-the-web-d4689f3ef012?utm_source=chatgpt.com
5)一个典型任务示例
目标: "去某招聘网站,搜'数据工程师',抓取前 3 页岗位并导出 CSV。"
-
规划:
打开站点 → 接受Cookie → 搜索框填词 → 回车 → 识别列表与下一页 → 循环解析 → 导出 -
执行:对每页进行 DOM 抽取 + 结构化字段映射(职位/公司/地点/薪资/链接)。
-
反馈:若遇登录墙或反爬,自动调整策略(延迟、滚动、换关键词/排序),或请求人类介入。Medium+1
https://medium.com/data-and-beyond/browser-use-explained-the-open-source-ai-agent-that-clicks-reads-and-automates-the-web-d4689f3ef012?utm_source=chatgpt.com
6)重要实现细节
-
动作-结果耦合 :默认"动作直到页面变更 "的策略,避免"点了但没跳"的假阳性。Browser Use
https://docs.browser-use.com/customize/agent/all-parameters?utm_source=chatgpt.com -
可解释性 :保留"思考/计划/执行日志",便于复盘与微调提示。Browser Use
https://docs.browser-use.com/customize/agent/all-parameters?utm_source=chatgpt.com -
安全与合规:限制可访问域、速率与会话隔离;遵守站点 ToS 与 robots 指南。
-
可扩展性 :配合 Web-UI、MCP/Server 或云端托管,批量跑任务与队列调度。GitHub+1
https://github.com/browser-use/web-ui?utm_source=chatgpt.com
7)生态与延伸阅读
-
GitHub / PyPI :项目主页、版本与示例。GitHub+1
https://github.com/browser-use/browser-use?utm_source=chatgpt.com -
官方文档 :配置、参数、最佳实践(如
use_thinking、flash_mode)。Browser Use+1https://docs.browser-use.com/?utm_source=chatgpt.com -
技术解读 :多篇深度文章讲其"LLM 规划 + Playwright 执行"的原理与应用。Medium+3Medium+3Edlitera+3
https://medium.com/data-and-beyond/browser-use-explained-the-open-source-ai-agent-that-clicks-reads-and-automates-the-web-d4689f3ef012?utm_source=chatgpt.com -
相关实现 :更广义的"Web 代理/计算机使用"技术与架构讨论。Fireworks AI
https://fireworks.ai/blog/opensource-browser-agent?utm_source=chatgpt.com