
导读:
开源无国界,在本期 "StarRocks 全球用户精选案例" 中,我们走进印度即时零售品牌 Zepto。
这家以 "10 分钟送达" 闻名的公司,业务已覆盖 50+ 城市、45,000+ 商品,品类横跨生鲜杂货、电子产品、美妆个护、服饰、玩具等。凭借前沿技术与战略布局的前置仓网络,Zepto 在短短几年间彻底改变了印度的即时零售格局。
随着规模扩张,Zepto 借助 StarRocks 从 Postgres MVP 升级为生产级实时分析平台,单表每日导入 3000 万+ 行数据,在品牌看板上实现亚秒级查询,帮助品牌合作伙伴从"日报表"迈向 准实时洞察,快速响应市场、智慧决策。
在 Zepto 的用户体验中,品牌始终占据着核心位置。我们依托丰富多元的商品目录,不仅满足了消费者的多样化偏好,也为品牌提供了跨城市的广泛触达。每天,Zepto 处理着数百万条数据,从商品浏览到城市级销售,全方位呈现产品在不同区域的表现。
然而,真正的挑战不是"有没有数据",而是"如何把数据转化为可执行的洞察"。这正是 Zepto Brand Analytics 发挥作用的地方。它专为快节奏的即时零售场景而生,能够快速、直观地帮助品牌识别趋势、优化表现,并实时做出更明智的决策。在瞬息万变的市场里,唯有敏捷才能赢得先机。
"如何在不让合作品牌久等、又不对数据过度简化的情况下,提供实时、可执行的洞察?"
基于这个问题,Zepto 推出了 Brand Analytics ------ 一个专为品牌打造的数据看板,提供丰富的数据,包括:
-
销售走势
-
库存情况
-
搜索趋势与用户转化
-
子品类层面的表现
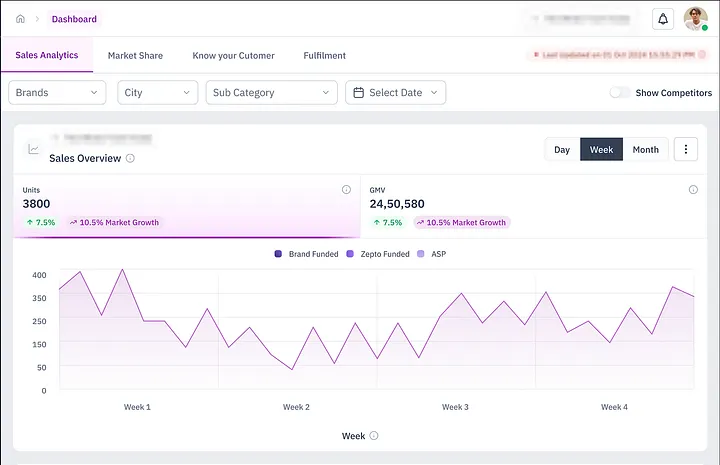
MVP 阶段:用 PostgreSQL 快速起步
就像大多数初创团队一样,我们在起步阶段选择了轻量灵活的方式。Brand Analytics 的第一个版本搭建在 PostgreSQL 上 ,让我们能够快速上线产品,并从一批早期合作品牌中收集反馈。
当时,我们已经能在品牌、城市、商品等维度上追踪 GMV、销量等核心指标。彼时的核心销售表仅有几百万行数据,PostgreSQL 能轻松应对。
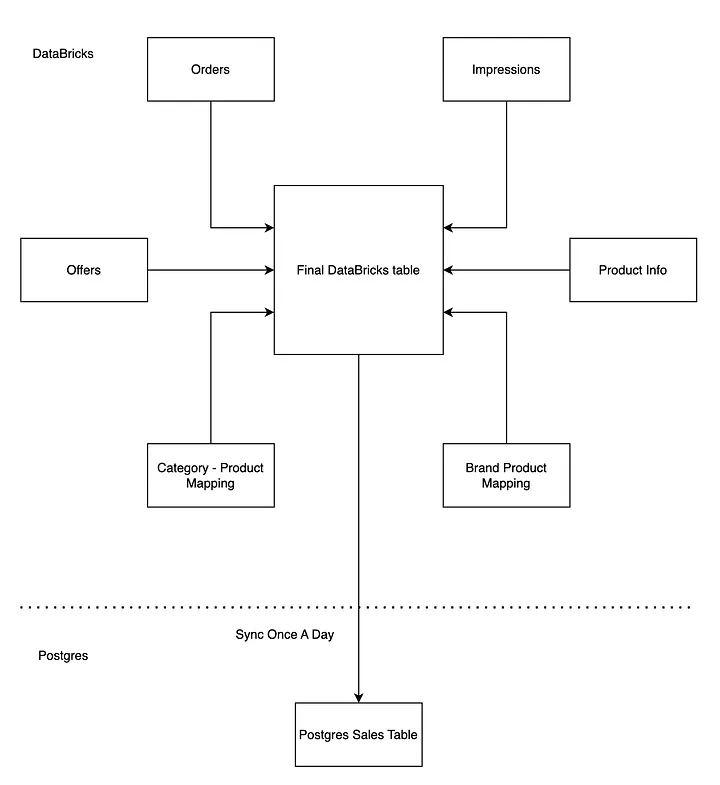
我们的分析团队选择了 Databricks 来管理和维护数据表。它既具备笔记本的灵活性,又拥有大数据处理的强大扩展能力,能轻松应对复杂查询和高效管道的构建。同时,Databricks 与 Delta Lake 深度集成,为 Lakehouse 架构提供了坚实的基础。
在最初阶段,我们的架构设计十分简洁:将订单、曝光、商品信息等多张表在 Databricks 中进行关联,生成一张统一的销售表,类似星型模型。随后,通过每日定时任务把数据同步至 Postgres。我们的首要目标是快速上线验证概念,以便第一时间收集品牌的使用反馈。对于早期需求来说,每日同步已经足够。
不过,直接让 Databricks 驱动前端界面并不可行 ------ 它的响应时间过长,并发能力有限,难以保障用户体验。即便只是阶段性的过渡方案,Postgres 满足了我们对快速响应的需求。
快进:成长的阵痛
短短一段时间里,业务发生了翻天覆地的变化:
-
加入平台的品牌越来越多
-
合作伙伴高度依赖分析看板来做业务决策,使用量激增
-
商品目录急速扩张,SKU 和品类呈指数级增长
很快,我们的数据量突破了 2 亿行交易记录,并且仍在快速增加。这时候,Postgres 开始力不从心。
作为主要面向 OLTP 工作负载的数据库,Postgres 在应对品牌伙伴需要运行的那类复杂、大规模分析查询时,逐渐表现吃力。
所以,我们需要一个专为大规模数据分析而构建的 OLAP 系统,来支撑高速、复杂的查询场景。
分析愿景清单
在转型之际,我们清楚地意识到必须升级架构,并明确了几项关键要求:
-
能够支持复杂的多表关联,而不必牺牲数据模型的规范化
-
面向外部用户看板,提供亚秒级响应速度
-
与 Kafka 和 Databricks 等上游数据管道实现无缝衔接
候选方案:ClickHouse、Apache Pinot 与 StarRocks
在选择新一代 OLAP 数据库时,我们对几款热门方案进行了基准测试。结果发现:
-
ClickHouse 的查询速度很快,但在复杂的多表关联上显得吃力
-
Apache Pinot 在低延迟写入方面表现出色,但在我们需要的复杂查询场景下存在局限
-
StarRocks?它不仅满足了所有核心需求,还带来了更多惊喜
为什么选择 StarRocks?
StarRocks 之所以在众多候选中脱颖而出,原因在于:
-
**Join 性能极快:**StarRocks 在多表 Join 的优化上表现惊艳,能够高效处理复杂查询。这正是我们核心场景的关键胜负手。
-
**在 3 亿+ 行数据上实现 P99 < 500ms:**在模拟实际业务场景的基准测试中,StarRocks 即使在大规模数据下,也能持续保持亚秒级的查询性能
-
**原生支持 Kafka 与 S3(Parquet):**StarRocks 与我们现有的数据生态无缝衔接。无论是 Kafka 的 Routine Load,还是 S3/Parquet 的支持,都让我们几乎无需对数据管道做大幅调整,就能从原型快速切入生产环境。
StarRocks 在生产环境中的落地实践
选择 StarRocks 只是开始,要真正发挥它的价值,我们需要在架构层面做出关键抉择。
两种架构模式:存算一体与存算分离
StarRocks 提供两种存储架构选项:
-
存算一体:数据由 StarRocks 本地存储和管理
-
存算分离:StarRocks 可直接从对象存储(如 S3)中查询数据
-
📖 延伸阅读:++Architecture Deep Dive++
在充分评估之后,我们决定采用存算一体架构 ------ 让 StarRocks 完全负责数据的本地存储与管理。
为什么选择存算一体
-
性能优先 ------ 我们的分析看板面向品牌用户,响应速度直接决定用户体验。本地存储意味着更快的查询响应。
-
数据规模可控 ------ 当前数据量还在数十 TB 以内,使用本地存储并未遇到容量或扩展瓶颈。
当然,如果业务已经达到 PB 级数据量,并且更看重弹性与计算/存储分离,那么存算分离架构或许是更好的选择。
将数据导入 StarRocks
为了支撑分析看板,我们需要将多源数据导入 StarRocks。随着产品不断成熟,我们的导入方式也逐步演进,目前主要依赖两条数据管道:
1. 通过 Pipe Load 从 Databricks 加载数据(S3 / Parquet)
在早期,我们的数据流非常简单:每天从 Databricks 表批量同步到 Postgres。
而在引入 StarRocks 后,借助 Pipe Load,我们能够让系统持续扫描指定的 S3 路径,并自动加载新生成的 Parquet 文件。(补充说明:Databricks 会将数据以 Parquet 文件的形式存储在 S3 的文件夹中)
下面是一条典型的 CREATE PIPE 命令示例:
sql
CREATE PIPE <pipe_name>
PROPERTIES (
"AUTO_INGEST" = "TRUE"
) AS
INSERT INTO <tablename>
SELECT * FROM FILES (
"path" = "s3://<bucket-name>/<folder-name>/*.parquet",
"format" = "parquet",
"aws.s3.region" = "<region>",
"aws.s3.access_key" = "<>",
"aws.s3.secret_key" = "<>"
);PIPE 使用小技巧
-
设置"AUTO_INGEST" = "TRUE",即可在新 Parquet 文件落盘到 S3 时实现自动同步
-
删除操作不会自动同步:可通过软删除模式(例如设置 is_deleted 标记)来实现
-
主键的选择至关重要 ------ StarRocks 会在主键表上执行 upsert
作为参考,我们的核心销售表已超过 3 亿行数据,而绝大多数查询都会涉及 2--3 张表的 Join。
延伸阅读:: ++Pipe Load Docs++
2. Routine Load × Kafka:解锁实时分析
随着产品不断成熟,用户对数据的要求也越来越高。我们很快意识到:每天一次的批量更新已经远远不够。品牌迫切需要实时洞察 ------ 比如能即时查看当天的销售和曝光数据,从而快速决策、紧跟市场变化。
这正是 StarRocks 真正发挥价值的时刻。借助 Routine Load,我们直接接入 Kafka 流,让数据更新几乎以实时的方式不断写入 StarRocks。
Routine Load 的价值所在:
-
精确一次导入保证 ------ 数据干净、一致,避免重复或遗漏
-
配置简单 ------ 轻松接入 Kafka 主题
-
原生支持 ------ 无需第三方连接器或额外管道
借助 Routine Load,我们能够将 Kafka 的数据流直接写入 StarRocks,实现真正的准实时看板,性能与实时性兼得。
目前,仅在一个核心表上,我们每天就通过 Kafka Routine Load 导入 3000 万+ 行数据 ------ 而这只是多个高数据量表中的一个,更多表正在陆续接入
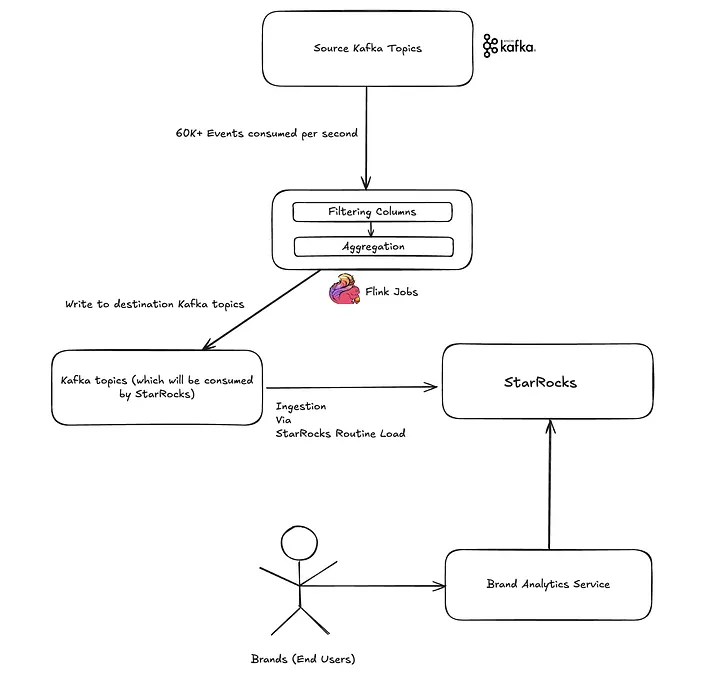
实时分析管道如何运作?
为了给品牌伙伴提供快速、可靠的洞察,我们搭建了一条流式数据管道。流程大致如下:
第一步:事件采集
整个流程从数据接入开始 ------ 每秒都有超过 6 万条事件从 Kafka 源源不断涌入,其中曝光主题数据量最大,其次是商品和订单交付事件。
为了承载如此庞大的流量,我们的平台团队构建了一个高度可扩展的事件管道,已经在整个公司范围内广泛应用。
👉延伸阅读:++Voyager++
第二步:Apache Flink 实时处理
接下来由 Apache Flink 接管,对事件流进行实时处理:
-
过滤掉不必要的列
-
在一个 x 分钟的窗口内(当前为 5 分钟)对指标进行聚合,以优化存储和查询
-
将聚合结果写入目标 Kafka 主题,供 StarRocks 消费
第三步:数据进入 StarRocks
处理完成的事件流,通过 Routine Load 机制导入 StarRocks。只需几秒钟,这些数据便可直接被查询 ------ 无需延迟、无需批处理,真正的实时就绪。
第四步:为品牌带来即时洞察
最新数据进入 StarRocks 后,Brand Analytics 服务便能在 SKU、品牌、区域等多个维度上执行快速的查询。指标几乎实时刷新,让品牌合作伙伴能更聪明地决策,更快把握趋势,并始终保持领先。
文档: ++Routine Load with Kafka++
成效
借助 StarRocks + Kafka + Flink,我们实现了从"每日数据"到"准实时分析"的飞跃。这让品牌合作伙伴能够更快响应市场、更合理的制定规划、并实现更智慧的增长。
总结
打造一个稳健且可扩展的品牌分析平台并不轻松,但有了 StarRocks,这一过程变得更加顺畅、高效。
我们取得的成果包括:
-
随着数据和用户规模的增长,从 Postgres MVP 平滑升级为生产级分析架构
-
在面向品牌用户的看板中,实现亚秒级查询性能
-
通过 S3 Pipes 与 Routine Load,无缝接入 Databricks 与 Kafka 流式数据
-
单表每日导入超过 3000 万行数据
-
采用存算一体架构,在低延迟与高性能之间找到最佳平衡
凭借 StarRocks 与事件管道的结合,我们完成了从"日报表"到"准实时洞察"的跨越 ------ 真正帮助品牌合作伙伴 更快响应市场、更聪明制定决策。
未来规划
在接下来的内容中,我们将分享更多干货:
-
StarRocks 与其他数据库的性能对比 ------ 基准测试结果,以及在不同工作负载下的差异表现
-
实践中的关键挑战与解决之道 ------ 我们如何攻克难题,提升数据工作流与整体效率
致谢
感谢 Syed Shah、Rajendra Bera、Ashutosh Gupta、Harshit Gupta 和 Deepak Jain 在该项目中的重要贡献。