参考资料:朝乐门。数据科学导论 M. 北京:人民邮电出版社,2020.
文章目录
文章目录
-
- 文章目录
- 一.数据科学的基础理论
-
- 1.为什么要学习数据科学
-
- [1.1 大数据时代](#1.1 大数据时代)
- 1.2大数据的4V特征
- [1.3 大数据带来的挑战](#1.3 大数据带来的挑战)
- 2.数据科学的定义
- [**3. 数据科学的知识体系**](#3. 数据科学的知识体系)
- 4.数据科学的基本流程
-
- [4.1 探索性数据分析](#4.1 探索性数据分析)
- 4.2数据分析与洞见
- [4.3 数据产品的提供](#4.3 数据产品的提供)
- [4.4 其他](#4.4 其他)
- 5.数据科学和其它学科的区别
-
- [5.1 学科定位](#5.1 学科定位)
- [5.2 三世界原则](#5.2 三世界原则)
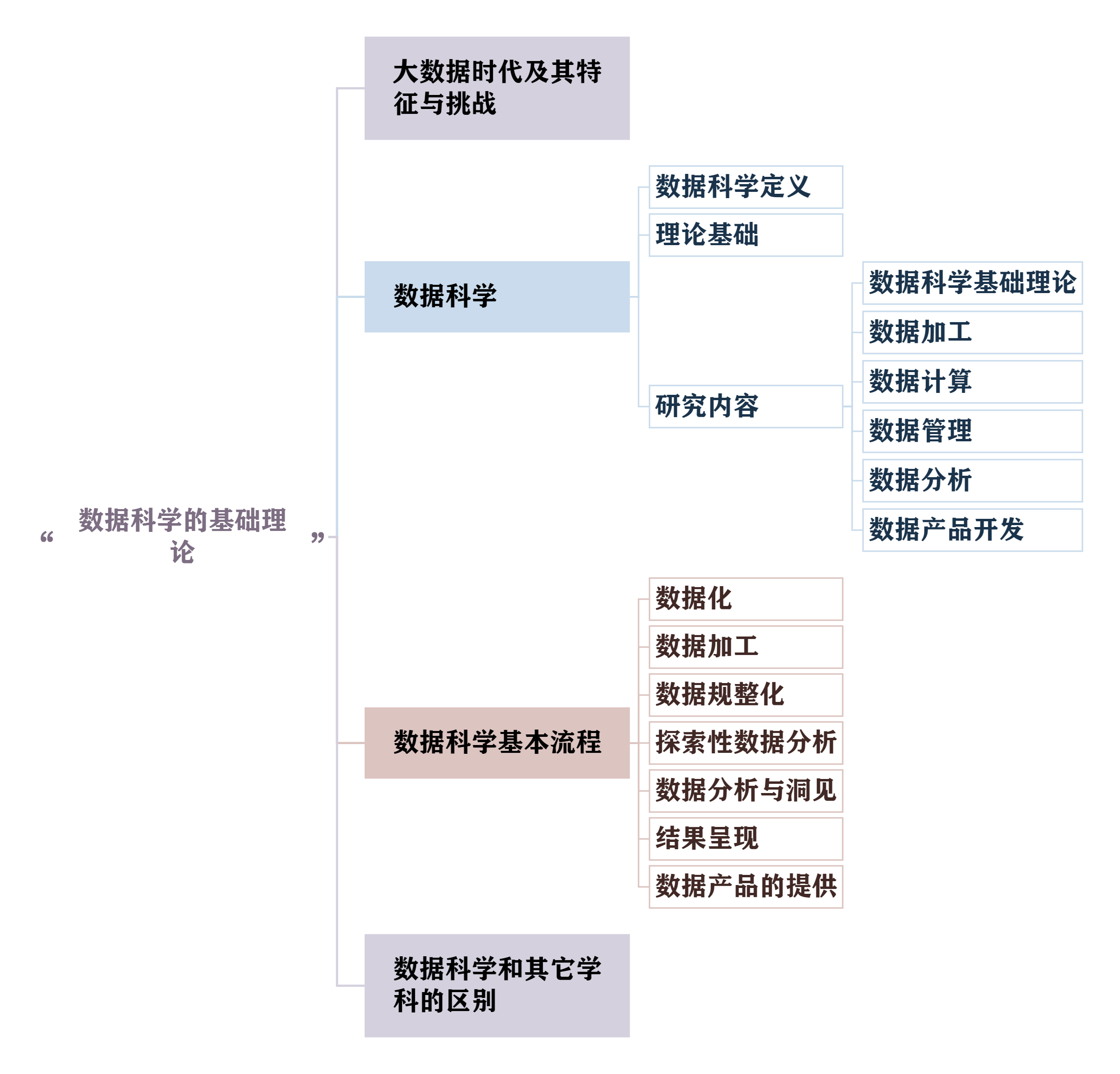
一.数据科学的基础理论
1.为什么要学习数据科学
1.1 大数据时代
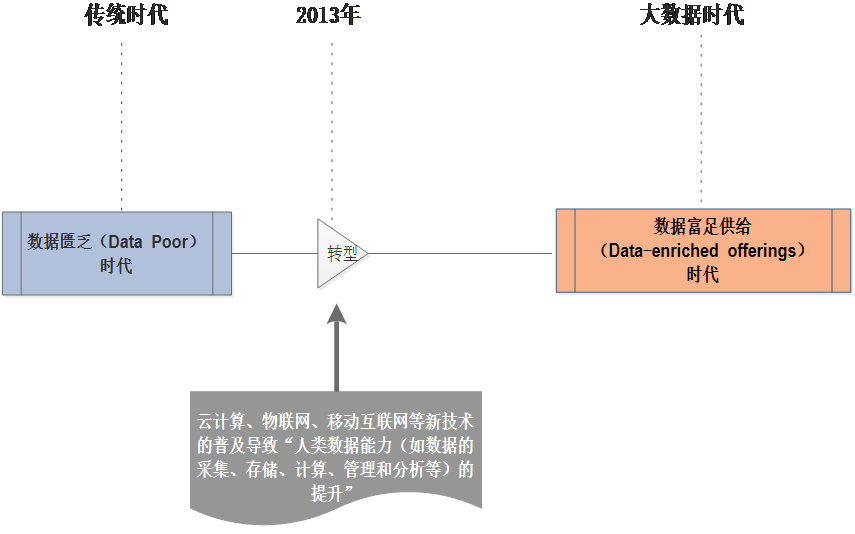
从最开始的数据困乏时代到以2013年出现的云计算、物联网、移动互联网的出现正式进入数据富足供给时代
- 大数据时代的本质是数据富足供给时代
- 数据富足供给时代的前提是:云计算、移动互联网、传感器的普遍应用
1.2大数据的4V特征
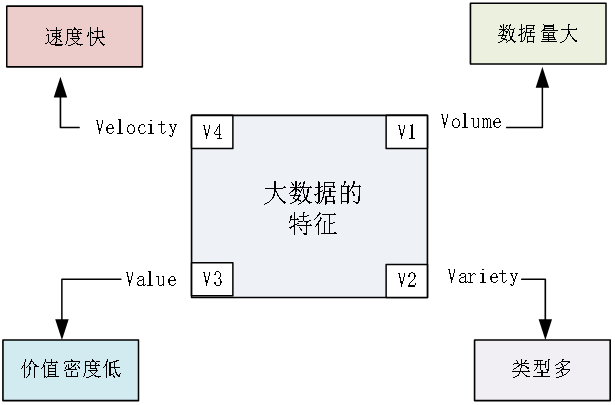
- 大数据定义:大数据是指在云计算、物联网、移动互联网、传感器、以及大型科学和观测仪器等新技术环境下产生的"新数据"
- 大数据特征:
- 数据量大
- 速度快
- 类型多
- 真实性高
- 价值密度低
- Volume(数据量大)
- 核心含义:指大数据的规模达到了传统数据处理工具难以承载的量级,是大数据最直观的特征之一。
- 背景支撑:随着传感器、移动设备、大型科学仪器的普及,人类活动产生的数据量呈指数级增长(如每日产生的社交数据、物联网设备日志、视频流等),传统存储和计算方式已无法高效处理此类规模的数据。
- Variety(数据类型多)
核心含义:打破了传统数据以结构化(如数据库表格数据)为主的单一形态,涵盖了结构化、半结构化、非结构化等多种类型数据。
常见类型举例
- 结构化数据:企业 ERP 系统中的订单数据、用户基本信息表;
半结构化数据:JSON 格式日志、XML 文件;
非结构化数据:视频、音频、图片、社交媒体文本、用户评论等。
- Veracity(数据真实性高)
- 核心含义:大数据多源于真实场景下的 "痕迹数据"(如用户自然的浏览记录、设备实时传感数据),而非传统调研中可能存在主观偏差的 "采访数据"(如问卷、访谈),因此具有更高的客观性和真实性。
- 价值体现:高真实性的数据是后续数据分析、洞见提取的基础,能有效降低因数据偏差导致的决策失误风险。
- Velocity(数据处理速度快)
- 核心含义:大数据具有 "实时产生、实时流转" 的特点,要求数据处理环节(如采集、清洗、分析)具备高速响应能力,以满足实时决策需求。
- 技术关联:这一特征直接推动了云计算(如 Hadoop、Spark 等分布式计算框架)的发展,传统集中式计算因处理速度慢,已无法适配大数据的 "高速流转" 特性。
1.3 大数据带来的挑战

数据科学:关于大数据的科学
2.数据科学的定义
数据科学:关于大数据的科学
3. 数据科学的知识体系
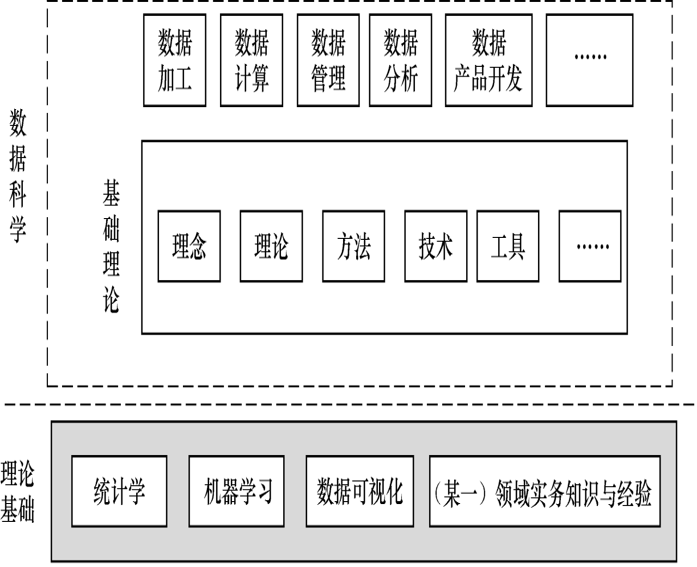
- 从知识体系看,数据科学主要以统计学、机器学习、数据可视化为理论基础。
- 其主要研究包括:数据科学基础理论、数据加工、数据计算、数据管理、数据分析和数据产品开发来解决各领域中的需求与挑战,如图 1-3 所示。
研究内容
-
数据科学基础理论:数据科学基础理论主要包括数据科学中的新理念、理论、方法、技术及工具,以及数据科学的研究目的、理论基础、研究内容、基本流程、主要原则、典型应用、人才培养、项目管理等。
- 新理念:例如后续提到的 "三世界原则"(物理世界、精神世界、数据世界)------ 通过 "数据世界" 的痕迹数据(如用户浏览记录、设备传感数据)解决 "物理世界" 问题,替代传统主观调研;还有 "数据柔术" 理念(将 3C 精神融入数据处理,实现数据到产品的 "艺术化转换")。
-
数据加工 :数据加工 是数据科学中关注的新问题之一,是以提高数据质量、降低数据计算的复杂度、减少数据计算量、以及提高数据处理的准确度为目的 ,数据科学项目 需要对原数据进行一系列加工处理活动,主要包括:数据审计、数据清洗、数据变换、数据集成、数据脱敏、数据归约和数据标注等
-
数据计算 :在数据科学中,计算模式发生了根本性的变化-->从集中式计算、分布式计算、网格计算等传统计算逐渐过渡到云计算 ,代表性的有Google 三大云计算技术(GFS、BigTable 和 MapReduce)、Hadoop MapReduce、Spark 和 YARN 等新技术的出现。数据计算模式的变化意味着数据科学中所关注的数据计算的常见瓶颈、关注焦点、主要矛盾和思维模式发生了根本性变化
云计算打破了传统 "本地硬件 + 集中式计算" 的局限,本质是通过网络(互联网 / 私有网络)将分散的计算资源(服务器、存储、软件等)整合为 "共享资源池",并以 "服务" 形式按需提供给用户------ 用户无需购买、维护硬件,只需根据需求 "租用" 资源,按使用量付费
-
数据管理 :在完成"数据加工"和"数据计算"之后,还需要对数据进行管理与维护,以便再次进行"数据分析"以及数据的再利用和长久存储。在数据科学中,数据管理的方法与技术也发生了重要变革------不仅包括传统关系型数据库,也出现了一些新兴大数据管理技术,如 NoSQL、NewSQL 技术和关系云等
传统数据管理以 "关系型数据库" 为主,仅能处理结构化数据(如表格型数据);但大数据时代下,半结构化(JSON/XML)、非结构化数据(视频 / 文本)占比激增,且数据量突破 PB 级,推动了新兴大数据管理技术的出现。
维度 传统关系型数据库(如 MySQL、Oracle) 新兴大数据管理技术(NoSQL/NewSQL/ 关系云) 适配数据类型 仅支持结构化数据(需预定义表结构) 支持结构化、半结构化、非结构化数据 数据量承载能力 适合 GB 级中小型数据,难以应对 PB 级 支持 PB 级甚至 EB 级海量数据 扩展性 垂直扩展(需升级单台服务器硬件) 水平扩展(通过增加服务器节点扩容) 核心优势 强事务一致性(ACID 原则)、查询效率高 高扩展性、高容错性、适配多类型数据 典型应用场景 企业财务系统、用户账号管理(需强一致性) 社交平台日志存储、电商商品信息管理、物联网数据采集 -
数据分析 :数据科学中采用的数据分析方法具有较为明显的专业性,通常以开源工具为主,这与传统数据分析有着较为显著的差异。目前,R和 Python已成为数据科学家最为普遍应用的数据分析工具。
-
数据产品开发 :数据产品开发也是是数据科学的重要研究任务之一,也是数据科学区别于其他科学的重要研究任务。与传统产品开发不同的是,数据产品开发具有以数据中心,多样性,层次性和增值性等特征,数据产品开发能力也是数据科学家的主要竞争力之一。因此,数据科学的学习目的之一是提高自己的数据产品开发能力。
1.以数据为中心
传统产品开发:核心逻辑是 "满足用户功能需求"(如办公软件需实现 "文档编辑、格式排版" 功能,手机需满足 "通话、拍照" 体验),数据仅作为辅助支撑(如软件的用户使用日志)。
数据产品开发:数据是 "核心驱动力" ------ 产品的功能设计、迭代方向、价值实现均依赖数据:
2.层次性
- 传统产品多为 "单一价值层级"(如手机的核心价值是 "通讯 + 娱乐",无明显层级递进),而数据产品可通过 "层级叠加" 持续提升价值。
3.多样性
- 传统产品开发:形态相对固定(如手机是硬件形态,办公软件是 PC 端 / 移动端软件形态),服务场景单一(如微信核心服务 "社交沟通")。
数据产品开发:形态无固定标准,可根据场景灵活适配,常见形态包括:
工具类:如数据可视化平台(Tableau Public,让用户自主分析数据)、API 接口(如天气数据 API,供企业调用天气数据);
决策支持类:如企业的 "销售预测 Dashboard"(供管理层查看未来销量趋势,辅助决策)、银行的 "风控决策系统"(自动判断贷款申请是否通过);
面向 C 端的体验类:如短视频平台的 "个性化推荐流"、导航 APP 的 "实时路况预测"。
4.增值性:
- 传统产品开发:价值随 "使用次数 / 时间" 可能衰减(如手机用久会卡顿,软件功能可能过时),且 "生产资料不可复用"(如生产手机的芯片,用一次少一次)。
数据产品开发:核心生产资料(数据)具有 "越用越值钱" 的增值属性------ 数据在产品使用过程中会持续积累,而积累的新数据又能反哺产品优化,形成 "数据 - 产品 - 更多数据 - 更好产品" 的正向循环
4.数据科学的基本流程
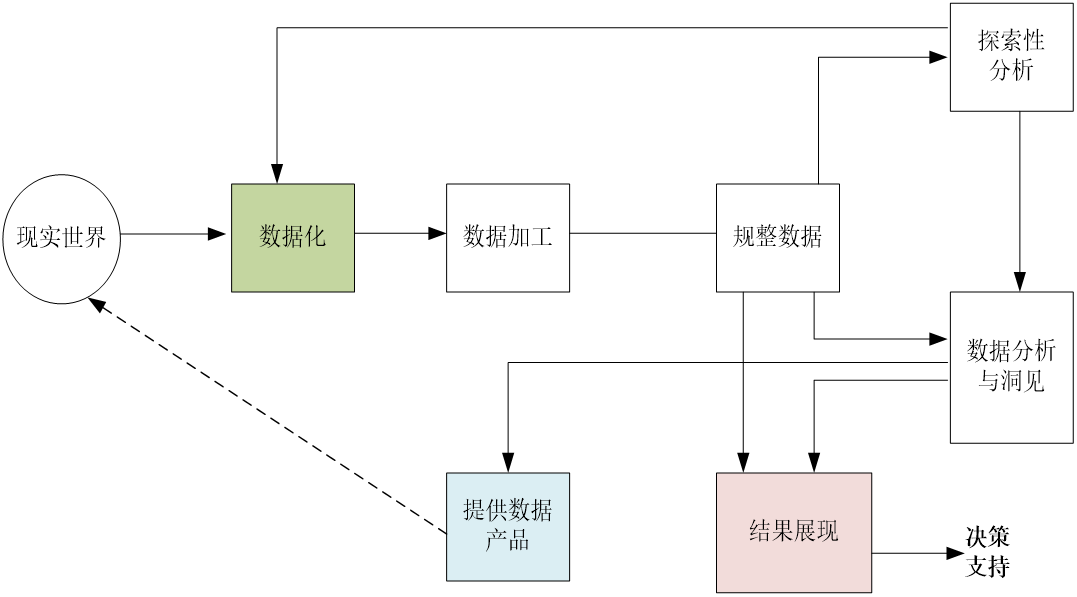
数据科学的基本流程包括:数据化、数据加工、数据规整化、探索性数据分析、数据分析与洞见、结果呈现,以及数据产品的提供
这里主要讲解三个重点的流程
4.1 探索性数据分析
定义:探索性数据分析 (Exploratory Data Analysis,EDA)指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,并通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法
当数据科学家对数据中的信息没有足够的经验,且不知道该用何种传统统计方法进行分析时,经常通过探索型数据分析方法达到数据理解的目的。
就是用图表、计算特征量等方式 "探索数据规律"(如看用户消费分布),帮科学家理解数据、找分析方向;
4.2数据分析与洞见
**定义:**在数据分析中,有三个基本类型,分别是:描述性分析(Descriptive analysis)、预测性分析(Predictive analysis)、规范性分析(Prescriptive analysis)
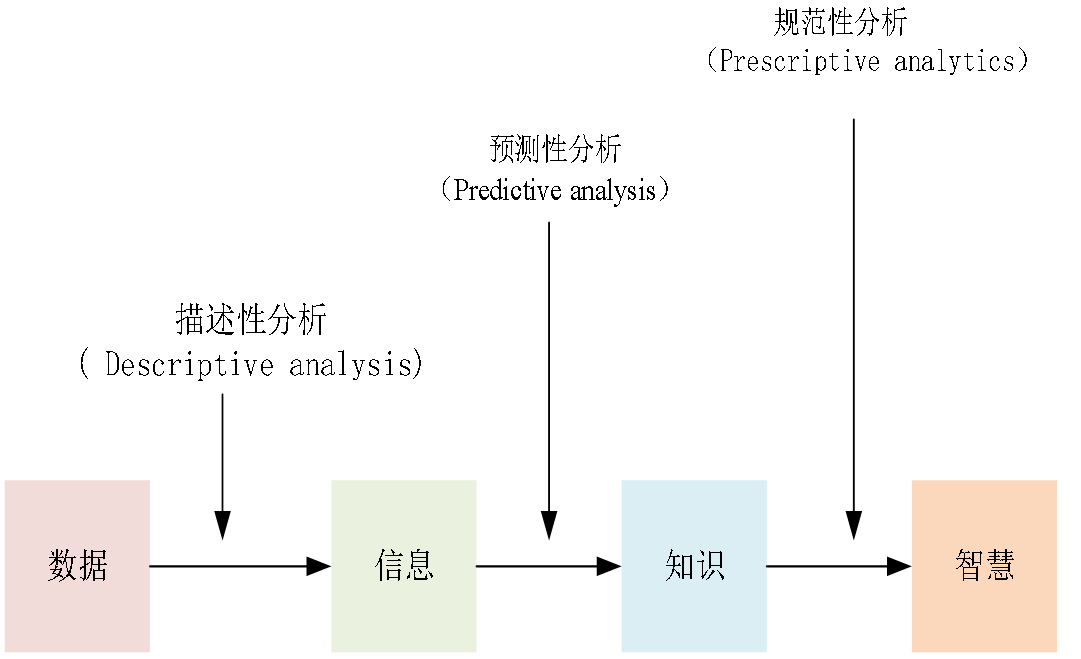
- 描述性分析:是一种将数据转换成信息的分析过程
- 预测性分析:是一种将信息转换为知识的分析过程
- 规范性分析:是一种将知识转换为智慧的分析过程
分三层提炼价值 ------ 描述性分析(讲 "过去发生了什么")、预测性分析(推 "未来可能发生什么")、规范性分析(给 "该怎么做" 的建议);
4.3 数据产品的提供
在机器学习算法/统计模型的设计与应用的基础上,还可以进一步将"干净数据"转换成各种"数据产品",并提供给"现实世界",方便交易与消费
将洞见转化为可复用的产品(如推荐系统、风控模型),落地到实际场景,完成 "数据→价值" 的闭环。
4.4 其他
- 数据化:把物理世界的信息(如用户行为、设备传感数据)转化为可处理的 "数据形式"(如记录成日志、表格),是流程起点;
- 数据加工:对原始数据做清洗(修错误值)、脱敏(去敏感信息)、归约(压缩数据量)等,提升数据质量;
- 数据规整:把加工后的数据整理成统一格式(如统一时间戳、字段名),方便后续分析
- 结果呈现:把分析洞见用可视化图表、报告等形式呈现,让非技术人员(如管理层)易懂
5.数据科学和其它学科的区别
5.1 学科定位
数据科学处于数学与统计知识、3C精神与技能、领域实务三大领域的交叉之处,
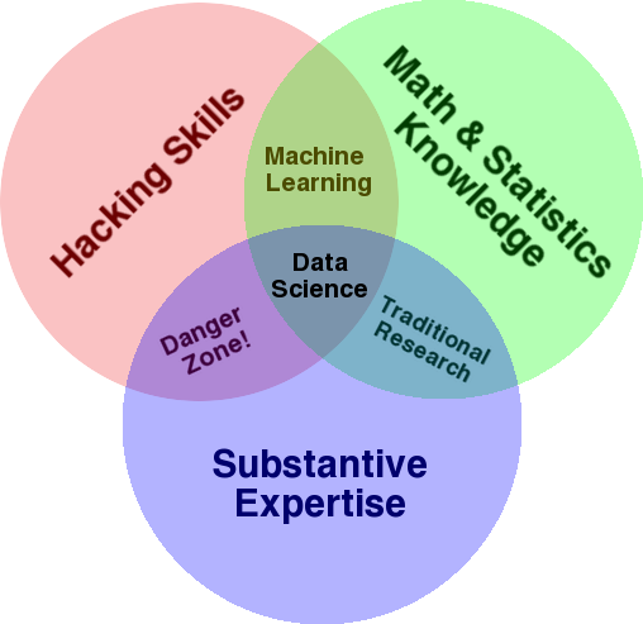
数学与统计知识:底层理论基础
是数据科学的 "逻辑骨架",比如用统计学做数据描述(均值、方差)、假设检验,用数学模型(如回归、机器学习算法)做预测分析,没有这部分,数据分析会变成 "无依据的猜测
3C 精神与技能:核心思维能力
是数据科学家的 "行动指南"------ 用 "好奇性(Curious)" 发现问题(如 "用户流失率为何上升"),用 "批判性(Critical)" 验证假设(如 "数据是否有偏差"),用 "创造性(Creative)" 设计解决方案(如开发新的分析模型),这是区别于 "纯技术工具使用者" 的关键。
领域实务:实际落地场景
是数据科学的 "价值锚点",比如做医疗数据科学需懂医学常识(如病历指标含义),做电商分析需懂零售逻辑(如促销活动规则),没有领域知识,分析结果会 "脱离实际,无法落地"。
5.2 三世界原则
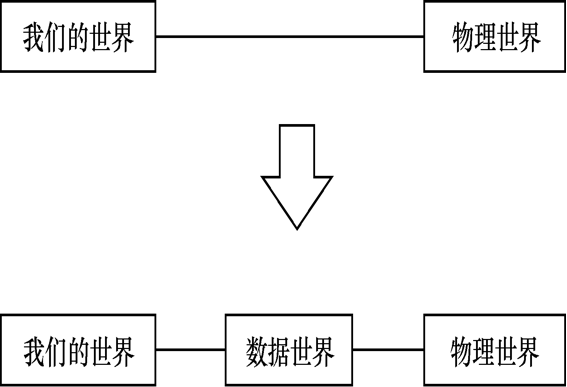
在我们的"精神世界"和"物理世界"之间出现了一种新的世界---"数据世界"。在数据科学中,通常需要研究如何运用"数据世界"中已存在的"痕迹数据"的方式解决"物理世界"中的具体问题,而不是直接到"物理世界",采用问卷和访谈等方法亲自收集"采访数据"。相对于"采访数据","痕迹数据"更具有客观性。