我自己的原文哦~https://blog.51cto.com/whaosoft/12170501
#UAD
爆拉UniAD近40%,推理提升3倍!UAD:全新纯视觉端到端SOTA
动机来源于对当前E2E AD模型仍模仿典型驾驶堆栈中模块化架构的观察,这些模型通过精心设计的监督感知和预测子任务为定向规划提供环境信息。尽管取得了突破性的进展,但这种设计也存在一些缺点:
1)先前的子任务需要大量高质量的3D标注作为监督,给训练数据的扩展带来了重大障碍;
2)每个子模块在训练和推理中都涉及大量的计算开销。
为此,这里提出了UAD,一种使用无监督agent的E2EAD框架,以解决所有这些问题。首先,设计了一种新颖的角度感知预训练任务,以消除对标注的需求。该预训练任务通过预测角度空间的目标性和时间动态来模拟驾驶场景,无需手动标注。其次,提出了一种自监督训练策略,该策略学习在不同增强视图下预测轨迹的一致性,以增强转向场景中的规划鲁棒性。UAD在nuScenes的平均碰撞率上相对于UniAD实现了38.7%的相对改进,并在CARLA的Town05 Long基准测试中在驾驶得分上超过了VAD 41.32分。此外,所提出的方法仅消耗UniAD 44.3%的训练资源,并在推理中运行速度快3.4倍。创新设计不仅首次展示了相较于监督对手无可争辩的性能优势,而且在数据、训练和推理方面也具有前所未有的效率。
开放和闭环评估的代码和模型将在:https://github.com/KargoBot_Research/UAD 上进行发布。
领域背景介绍
近几十年来,自动驾驶领域取得了突破性的成就。端到端范式,即寻求将感知、预测和规划任务整合到一个统一框架中的方法,已成为一个代表性的分支。端到端自动驾驶的最新进展极大地激发了研究人员的兴趣。然而,之前已在环境建模中证明其效用的手工制作且资源密集型的感知和预测监督子任务,如图1a所示,仍然是不可或缺的。
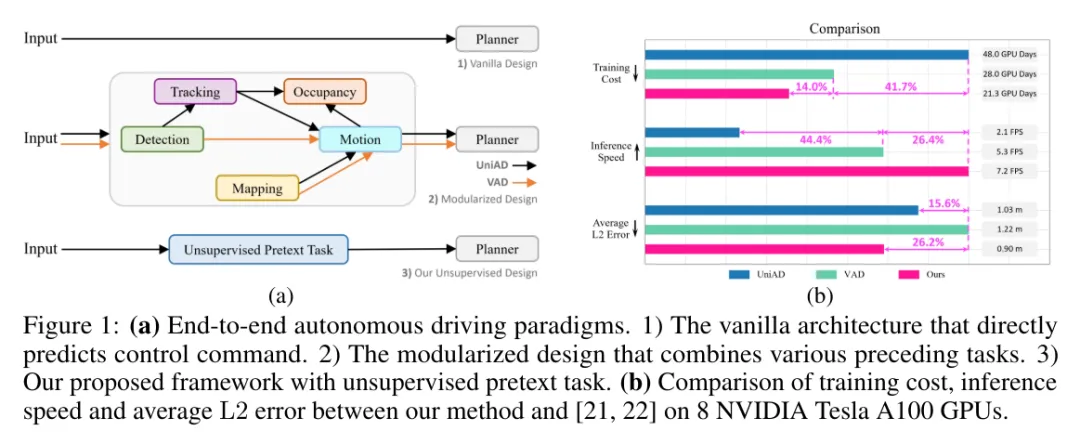
那么,从最近的进展中获得了哪些启示?我们注意到,其中一个最具启发性的创新在于基于Transformer的pipeline,其中查询作为连接各个任务的纽带,无缝地连接了不同的任务。此外,环境建模的能力也得到了显著提升,这主要归功于监督子任务之间复杂的交互作用。但是,每枚硬币都有两面。与原始设计(见图1a)相比,模块化方法带来了不可避免的计算和标注开销。如图1b所示,最近的UniAD方法的训练需要48个GPU day,并且每秒仅运行2.1帧(FPS)。此外,现有感知和预测设计中的模块需要大量高质量标注的数据。人工标注的财务开销极大地阻碍了带有监督子任务的这种模块化方法利用海量数据的可扩展性。正如大型基础模型所证明的,扩大数据量是将模型能力提升到下一个层次的关键。因此,这里也问自己一个问题:在减轻对3D标注的依赖的同时,设计一个高效且稳健的E2EAD框架是否可行?
本文提出一种创新的端到端自动驾驶(UAD)的无监督预训练任务,展示了答案是肯定的。该预训练任务旨在有效地建模环境。该预训练任务包括一个角度感知模块,通过学习预测BEV(Bird's-Eye View,鸟瞰图)空间中每个扇形区域的目标性来学习空间信息,以及一个角度梦境解码器,通过预测无法访问的未来状态来吸收时间知识。引入的角度查询将这两个模块连接成一个整体的预训练任务来感知驾驶场景。值得注意的是,方法完全消除了对感知和预测的标注需求。这种数据效率是当前具有复杂监督模块化的方法无法实现的。学习空间目标性的监督是通过将一个现成的开放集检测器的2D感兴趣区域(ROIs)投影到BEV空间来获得的。虽然利用了其他领域(如COCO)手动标注的公开可用的开放集2D检测器进行预训练,但避免了在我们的范式和目标域(如nuScenes和CARLA)中需要任何额外的3D标签,从而创建了一个实用的无监督设置。此外,还引入了一种自监督的方向感知学习策略来训练规划模型。具体来说,通过为视觉观测添加不同的旋转角度,并对预测应用一致性损失,以实现稳健的规划。无需额外的复杂组件,提出的UAD在nuScenes平均L2误差方面比UniAD高0.13m,在CARLA路线完成得分方面比VAD高9.92分。如图1b所示,这种前所未有的性能提升是在3.4倍的推理速度、UniAD的仅44.3%的训练预算以及零标注的情况下实现的。
总结来说,贡献如下:
- 提出了一种无监督的预训练任务,摒弃了端到端自动驾驶中3D手工标注的需求,使得训练数据扩展到数十亿级别成为可能,而无需承担任何标注负担;
- 引入了一种新颖的自监督方向感知学习策略,以最大化不同增强视图下预测轨迹的一致性,从而增强了转向场景中的规划鲁棒性;
- 与其他基于视觉的端到端自动驾驶方法相比,提出的方法在开放和闭环评估中都表现出优越性,同时计算成本和标注成本大大降低。
UAD方法介绍
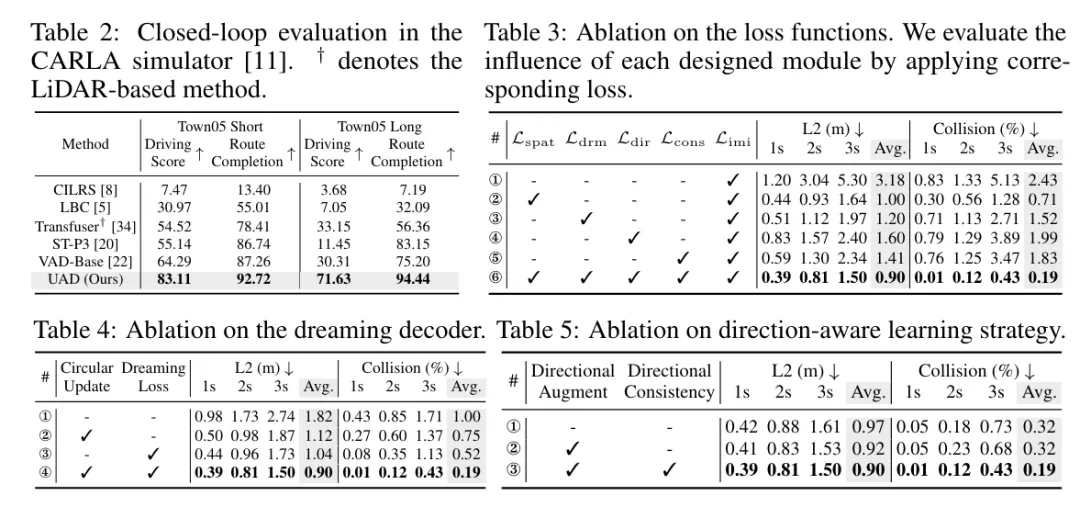
如图2所示,UAD(端到端自动驾驶)框架由两个基本组件组成:1) 角度感知预训练任务,旨在以无监督的方式将E2EAD(端到端自动驾驶)从昂贵的模块化任务中解放出来;2) 方向感知规划,学习增强轨迹的自监督一致性。具体来说,UAD首先使用预训练任务对驾驶环境进行建模。通过在BEV(鸟瞰图)空间中估计每个扇形区域的目标性来获取空间知识。引入的角度查询,每个查询负责一个扇形区域,用于提取特征和预测目标性。监督标签是通过将2D感兴趣区域(ROIs)投影到BEV空间来生成的,这些ROIs是使用现有的开放集检测器GroundingDINO预测的。这种方法不仅消除了对3D标注的需求,还大大降低了训练成本。此外,由于驾驶本质上是一个动态和连续的过程,因此我们提出了一个角度梦境解码器来编码时间知识。梦境解码器可以看作是一个增强的世界模型,能够自回归地预测未来状态。
接下来,引入了方向感知规划来训练规划模块。原始的BEV特征通过添加不同的旋转角度进行增强,生成旋转的BEV表示和自车轨迹。我们对每个增强视图的预测轨迹应用自监督一致性损失,以期望提高方向变化和输入噪声的鲁棒性。这种学习策略也可以被视为一种专门为端到端自动驾驶定制的新型数据增强技术,增强了轨迹分布的多样性。
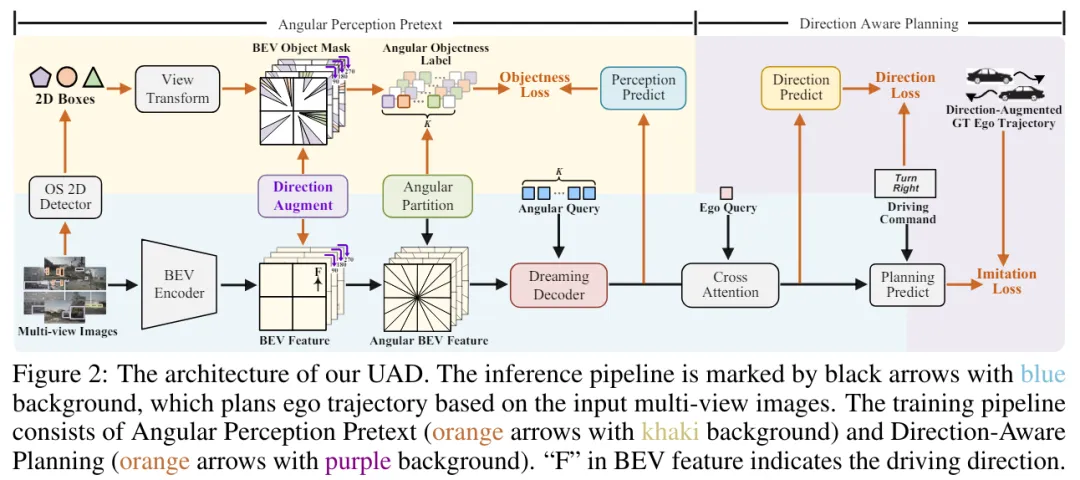
1)角度感知预训练任务
空间表征学习。模型试图通过预测BEV(鸟瞰图)空间中每个扇形区域的目标性来获取驾驶场景的空间知识。具体来说,以多视图图像作为输入,BEV编码器首先将视觉信息提取为BEV特征。然后,被划分为以自车为中心的K个扇形,每个扇形包含BEV空间中的几个特征点。将扇区的特征表示为,其中N是所有扇区中特征点的最大数量,从而得出角度BEV特征。对于特征点少于N的扇区,应用零填充。
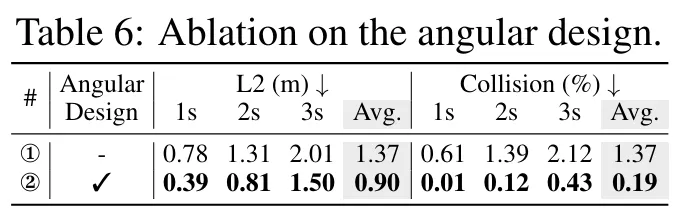
那么,为什么要将矩形的BEV特征划分为角度格式呢?根本原因是,在缺少深度信息的情况下,对应于二维图像中ROI的BEV空间区域是一个扇形。如图3a所示,通过将3D采样点投影到图像上并验证它们在2D ROIs中的存在性,生成了一个BEV对象掩码,表示BEV空间中的目标性。具体来说,落在2D ROIs内的采样点被设置为1,而其他点被设置为0。注意到,在BEV空间中,正扇形不规则且稀疏地分布。为了使目标性标签更加紧凑,类似于BEV特征划分,将M均匀地分为K个等份。与正扇形重叠的段被赋值为1,构成了角度目标性标签。得益于开放集检测的快速发展,通过向二维开放集检测器(如GroundingDINO)输入预定义的提示(例如,车辆、行人和障碍物),方便地获取输入多视图图像的2D ROIs,这种设计是降低标注成本和扩展数据集的关键。
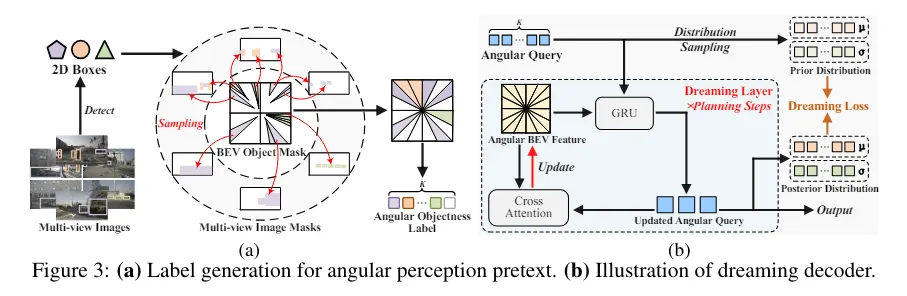
为了预测每个扇区的objectness得分,这里定义了角度查询来汇总。在中,每个角度查询都会通过交叉注意力机制与对应的f进行交互:
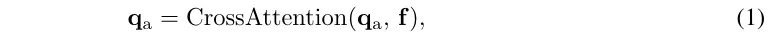
最后,使用一个线性层将映射为目标性得分,该得分由监督,并使用二元交叉熵损失(表示为)进行训练。
**时间表征学习。**这里提出使用角度梦境解码器来捕获驾驶场景的时间信息。如图3b所示,解码器以自回归的方式学习每个扇区的转移动态,类似于世界模型的方式。假设规划模块预测了未来T步的轨迹,那么梦境解码器相应地包含T层,其中每一层都根据学习到的时间动态更新输入的角度查询和角度BEV特征。在第t步,查询首先通过门控循环单元(GRU)从观测特征中捕获环境动态,这生成了(隐藏状态):
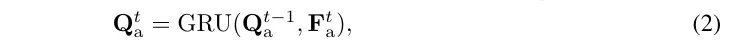
在以前的世界模型中,隐藏状态Q仅用于感知观察到的场景。因此,GRU迭代在t步随着最终观测的获取而结束。在我们的框架中,Q也用于预测未来的自车轨迹。然而,未来的观测,例如是不可用的,因为世界模型的设计初衷是仅根据当前观测来预测未来。为了获得,首先提出更新以提供伪观测,
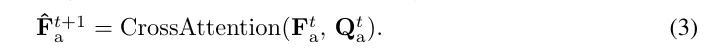
然后,通过方程2以及和作为输入,可以生成。
遵循世界模型中的损失设计,分别将和映射到分布µσ和µσ,然后最小化它们的KL散度。的先验分布被视为对未来动态的预测,而无需观测。相反,的后验分布表示具有观测的未来动态。两个分布之间的KL散度衡量了想象中的未来(先验)和真实未来(后验)之间的差距。我们期望通过优化梦境损失来增强长期驾驶安全性的未来预测能力:
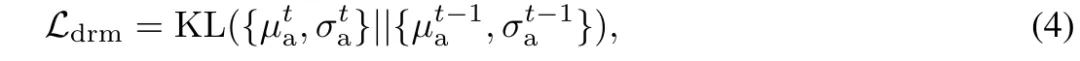
2)方向感知规划
规划头。角度感知预训练的输出包含一组角度查询{}。对于规划,相应地初始化T个自车查询{}来提取与规划相关的信息,并预测每个未来时间步的自车轨迹。自车查询和角度查询之间的交互是通过交叉注意力机制进行的:
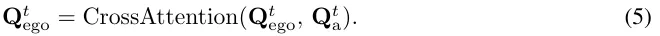
规划头以自车特征(来自)和驾驶指令c作为输入,并输出规划轨迹。
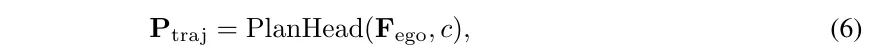
方向增强。观察到训练数据主要由直行场景主导,这里提出了一种方向增强策略来平衡分布。如图4所示,BEV特征以不同的角度r ∈ R = {90◦, 180◦, 270◦}进行旋转,产生旋转后的表示{}。这些增强的特征也将用于预训练任务和规划任务,并由上述损失函数进行监督。值得注意的是,BEV目标maskM和真实自车轨迹Gtraj也会进行旋转,以提供相应的监督标签。
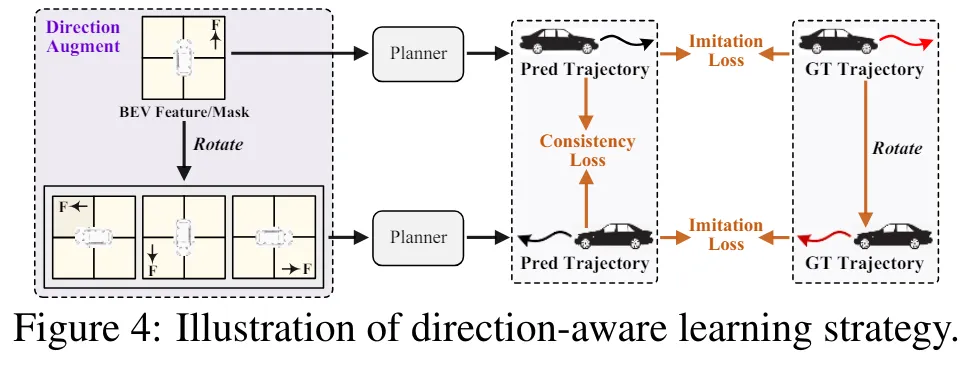
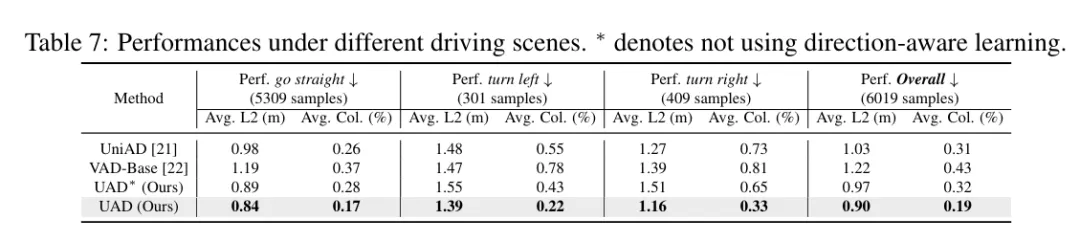
此外,我们提出了一个辅助任务来增强转向能力。具体来说,基于自车查询预测自车意图操作的规划方向(即左、直或右),这将映射到三个方向的概率。方向标签是通过将真实轨迹 Gt_traj(x) 的x轴值与阈值δ进行比较来生成的。具体来说,如果-δ < Gt_traj(x) < δ,则被赋值为直行;否则,对于Gt_traj(x) ⩽ -δ/Gt_traj(x) ⩾ δ,则分别被赋值为left/right。使用交叉熵损失来最小化方向预测和方向标签之间的差距,记作。
方向一致性。针对引入的方向增强,这里提出了一个方向一致性损失,以自监督的方式改进增强的规划训练。需要注意的是,增强的轨迹预测包含了与原始预测相同的场景信息,即具有不同旋转角度的BEV特征。因此,考虑预测之间的一致性并调节由旋转引起的噪声是合理的。规划头应更加鲁棒于方向变化和输入干扰。具体来说,首先将旋转回原始场景方向,然后与应用L1损失。
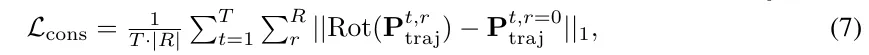
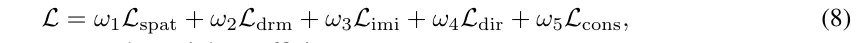
实验对比
在nuScenes数据集上进行了开环评估实验,该数据集包含40,157个样本,其中6,019个样本用于评估。遵循之前的工作,采用了L2误差(以米为单位)和碰撞率(以百分比为单位)作为评估指标。值得注意的是,还纳入了BEV-Planner中提出的与道路边界的交并比(以百分比为单位)作为评估指标。对于闭环设置,遵循之前的工作,在CARLA模拟器的Town05 基准上进行评估。使用路线完成率(以百分比为单位)和驾驶评分(以百分比为单位)作为评估指标。采用基于查询的view transformer从多视图图像中学习BEV特征。开放集2D检测器的置信度阈值设置为0.35,以过滤不可靠的预测。用于划分BEV空间的角度θ设置为4◦(K=360◦/4◦),默认阈值δ为1.2m。等式8中的权重系数分别设置为2.0、0.1、1.0、2.0、1.0。模型在8个NVIDIA Tesla A100 GPU上训练了24个epoch,每个GPU的bs大小为1。
在nuScenes中的开环规划性能。† 表示基于激光雷达的方法,‡ 表示VAD和ST-P3中使用的TemAvg评估协议。⋄ 表示在规划模块中使用自车状态,并遵循BEV-Planner 计算碰撞率。
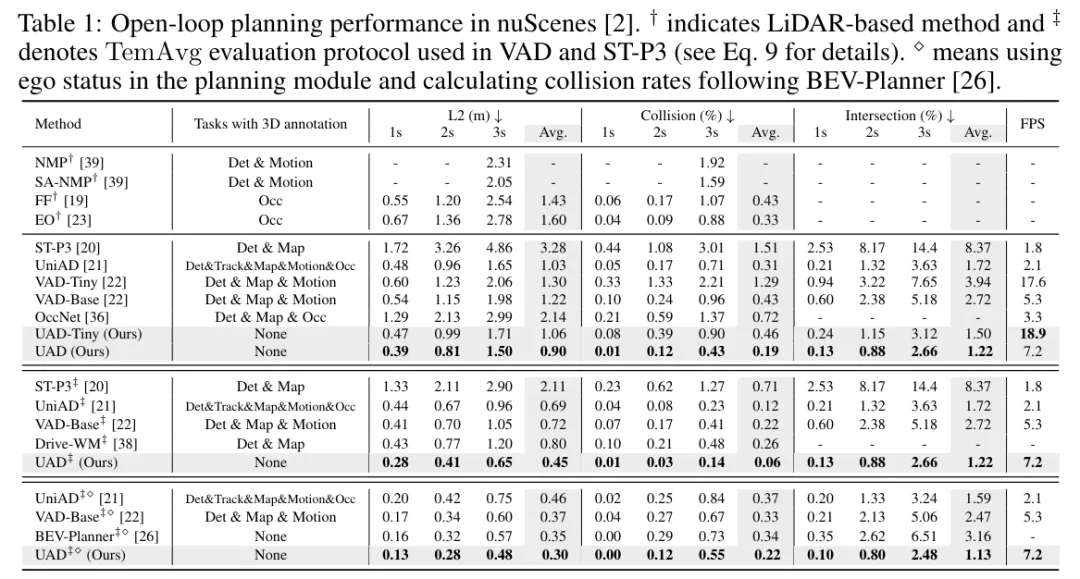
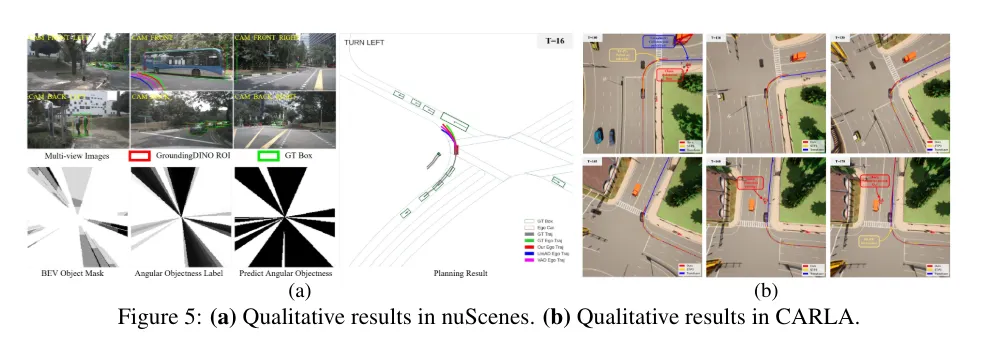
.....
#RenderWorld
爆拉OccWorld!提升纯视觉端到端上限,最新SOTA!
纯视觉端到端自动驾驶不仅比激光雷达与视觉融合的方法更具成本效益,而且比传统方法更可靠。为了实现经济且鲁棒的纯视觉自动驾驶系统,这里提出了RenderWorld,一个仅基于视觉的端到端自动驾驶框架,它使用自监督的高斯-based Img2Occ模块生成3D占用标签,然后通过AM-VAE对标签进行编码,并利用世界模型进行预测和规划。RenderWorld采用高斯溅射(Gaussian Splatting)来表示3D场景,并渲染2D图像,与基于NeRF的方法相比,这大大提高了分割精度并降低了GPU内存消耗。通过将AM-VAE应用于分别编码空气和非空气部分,RenderWorld实现了更细粒度的场景元素表示,从而在基于自回归世界模型的4D占用预测和运动规划方面达到了最先进的性能。
行业背景介绍
随着自动驾驶技术的广泛应用,研究人员逐渐将重点放在了更好的感知和预测方法上,这些方法与系统的决策能力和鲁棒性密切相关。目前大多数框架都是将感知、预测和规划分开进行的。最常用的感知方法是使用视觉和激光雷达融合进行3D目标检测,这使得模型能够更好地预测未来场景并进行运动规划。然而,由于大多数3D目标检测方法无法获得环境中的细粒度信息,它们在后续模型中的规划中表现出非鲁棒性,这影响了系统的安全性。当前的感知方法主要依赖于激光雷达和camera,但激光雷达的高成本和多模态融合的计算需求对自动驾驶系统的实时性能和鲁棒性提出了挑战。
这里介绍了RenderWorld,这是一个用于预测和运动规划的自动驾驶框架,它基于高斯-based Img2Occ模块生成的3D占用标签进行训练。RenderWorld提出了一个自监督的gaussian splatting Img2Occ模块,该模块通过训练2D多视图深度图和语义图像来生成世界模型所需的3D占用标签。为了使世界模型更好地理解由3D占用表示的场景,在向量量化变分自编码器(VQ-VAE)的基础上提出了空气掩码变分自编码器(AM-VAE)。这通过增强场景表示的粒度来提高了我们世界模型的推理能力。
为了验证RenderWorld的有效性和可靠性,分别在NuScenes数据集上对3D占用生成和运动规划进行了评估。综上所述,主要贡献如下:
1)提出了RenderWorld,这是一个纯2D自动驾驶框架,它使用tokens 的2D图像来训练基于高斯的占用预测模块(Img2Occ),以生成世界模型所需的3D标签。2)为了提高空间表示能力,引入了AM-VAE,它通过分别编码空气体素和非空气体素来改进世界模型中的预测和规划,同时减少内存消耗。
相关工作介绍
3D占用率正在成为激光雷达感知的一种可行替代方案。大多数先前的工作都利用3D占用率真实值进行监督,但这在标注上是一个挑战。随着神经辐射场(NeRF)的广泛采用,一些方法试图使用2D深度和语义标签进行训练。然而,使用连续的隐式神经场来预测占用概率和语义信息往往会导致高昂的内存成本。最近,GaussianFormer利用稀疏高斯点作为减少GPU消耗的手段来描述3D场景,而GaussianOcc则利用一个6D姿态网络来消除对真实姿态的依赖,但两者都存在整体分割精度大幅下降的问题。在提出的工作中,采用了一种基于锚点的高斯初始化方法来对体素特征进行高斯化,并使用更密集的高斯点来表示3D场景,从而在避免NeRF基方法中光线采样导致的过度内存消耗的同时,实现了更高的分割精度。
世界模型常用于未来帧预测并辅助机器人做出决策。随着端到端自动驾驶的逐渐发展,世界模型也被应用于预测未来场景和制定决策。与传统自动驾驶方法不同,世界模型方法集成了感知、预测和决策制定。许多当前的方法将相机-激光雷达数据进行融合,并将其输入到世界模型中,用于预测和制定运动规划。其中,OccWorld提出利用3D占用率作为世界模型的输入。然而,OccWorld在利用纯2D输入方面效率较低,且在编码过程中由于信息丢失而难以准确预测未来场景。因此,我们设计了一个Img2Occ模块,将2D标签转换为3D占用标签,以增强世界建模能力。
RenderWorld方法介绍
本节中将描述RenderWorld的总体实现。首先,提出了一个Img2Occ模块,用于占用率预测和3D占用标签的生成。随后,介绍了一个基于空气mask变分自编码器(AM-VAE)的模块,以优化占用率表示并增强数据压缩效率。最后,详细阐述了如何集成世界模型以准确预测4D场景演变。
1)使用多帧2D标签进行3D占用率预测
为了实现3D语义占用率预测和未来3D占用标签的生成,这里设计了一个Img2Occ模块,如图2所示。使用来自多个相机的图像作为输入,首先使用预训练的BEVStereo4D主干和Swin Transformer提取2D图像特征。然后,利用已知的固有参数(i=1到N)和外参,将这些2D信息插值到3D空间中以生成体积特征。为了将3D占用体素投影到多相机语义图上,这里应用了高斯splatting,一种先进的实时渲染pipeline。
在每个体素的中心以可学习的尺度初始化锚点,以近似场景占用率。每个锚点的属性是根据相机与锚点之间的相对距离和观察方向来确定的。然后,这个锚点集被用来初始化一个带有语义标签的高斯集。每个高斯点x在世界空间中由一个完整的3D协方差矩阵Σ和其中心位置µ表示,并且每个点的颜色由该点的语义标签决定。
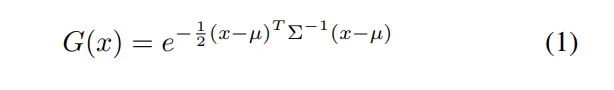
直接优化Σ可能会导致不可行的矩阵,因为它必须是正半定的。为了确保Σ的有效性,我们将其分解为缩放矩阵S和旋转矩阵R,以表征3D高斯椭球体的几何形状:
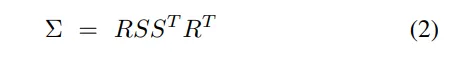
然后,通过计算相机空间协方差矩阵Σ',将3D高斯体投影到2D以进行渲染:
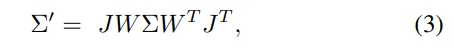
其中J是投影变换的仿射近似的雅可比矩阵,W是视图变换。然后,可以通过对排序后的高斯体应用alpha混合来计算每个像素的语义/深度:
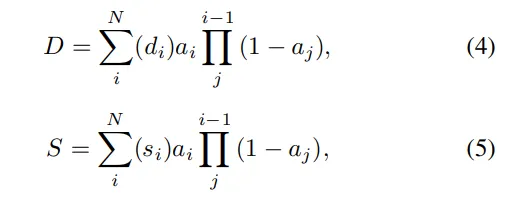
为了计算真实深度与渲染深度之间的差异,利用皮尔逊相关系数,它可以测量两个2D深度图之间的分布差异,遵循以下函数:
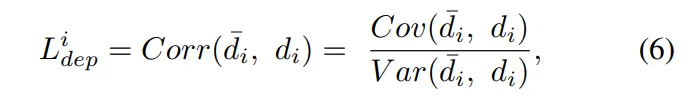
最后,我们构建了损失函数,其中包括用于监督语义分割的交叉熵损失和用于深度监督的,整体损失可以计算如下:
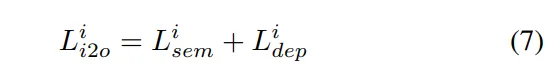
2)空气mask变分自编码器(AM-VAE)
传统的变分自编码器(VAEs)无法对非空气体素的独特特征进行编码,这阻碍了模型以细粒度级别表示场景元素。为了解决这个问题,这里引入了空气掩码变分自编码器(AM-VAE),这是一种新颖的VAE,它涉及训练两个独立的向量量化变分自编码器(VQVAE),以分别编码和解码空气和非空气占用体素。假设o代表输入占用表示,而和分别代表空气和非空气体素。
首先利用一个3D卷积神经网络对占用数据进行编码,输出是一个连续的潜在空间表示,记为f。编码器qϕ(s|o)将输入f映射到潜在空间s。然后使用两个潜在变量和来分别表示空气和非空气体素:
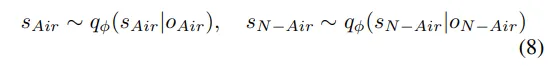
每个编码后的潜在变量或使用可学习的码本或来获得离散tokens ,然后在输入到解码器之前,用与该tokens 最相似的codebook替换它。这个过程可以表示为:
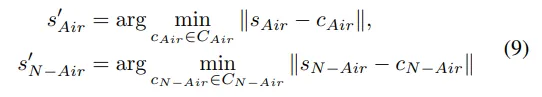
然后,解码器pθ(o|s)从量化的潜在变量和中重建输入占用:
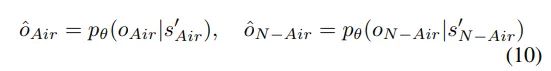
为了促进占用表示中空气和非空气元素的分离,用M表示非空气类别的集合。然后,在修改后的占用中,空气和非空气的指示函数可以定义如下:
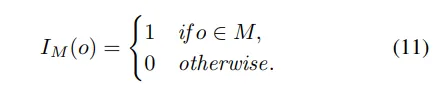
修改后的空气占用和非空气占用由以下等式给出:
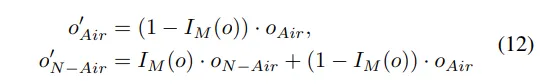
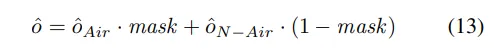
然后,为训练AM-VAE构建了损失函数,它包含重建损失和commitment损失LReg:
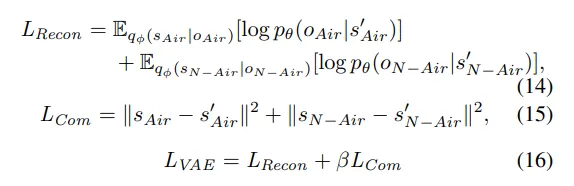
AM-VAE在统一的编码器-解码器设置中,为空气和非空气体素分别使用了不同的码本。这种方法有效地捕获了每种体素类型的独特特征,从而提高了重建准确性和泛化潜力。
3)世界模型
通过在自动驾驶中应用世界模型,将3D场景编码为高级tokens ,我们的框架可以有效地捕获环境的复杂性,从而实现对未来场景和车辆决策的准确自回归预测。
受OccWorld的启发,使用3D占用率来表示场景,并采用自监督的分词器来推导高级场景tokens T,并通过聚合车辆tokens z0来编码车辆的空间位置。世界模型w是根据当前时间戳T和历史帧数t来定义的,然后使用以下公式建立预测:
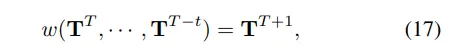
同时,采用了一种时间生成式Transformer架构来有效预测未来场景。它首先通过空间聚合和下采样处理场景tokens ,然后生成一个分层的tokens 集合{T0, · · · , TK}。为了在不同空间尺度上预测未来,采用多个子世界模型w = {w0, · · · , wK}来实现,并且每个子模型wi使用以下公式对每个位置j的tokens 应用时间注意力:
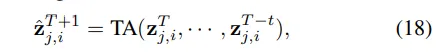
在预测模块中,首先利用自监督的分词器e将3D场景转换为高级场景tokens T,并使用车辆tokens z0来编码车辆的空间位置。在预测了未来的场景tokens后,应用一个场景解码器d来解码预测的3D占用率,并学习一个车辆解码器,用于生成相对于当前帧的车辆位移。预测模块通过生成未来车辆位移和场景变化的连续预测,为自动驾驶系统的轨迹优化提供决策支持,确保安全和自适应的路径规划。
这里实现了一个两阶段训练策略来有效地训练预测模块。在第一阶段,使用3D占用率损失来训练场景分词器e和解码器d:
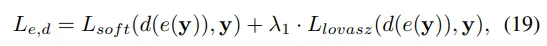
然后,使用学习到的场景分词器e来获取所有帧的场景tokens z,对于车辆tokens ,同时学习车辆解码器,并在预测的位移和真实位移p上应用L2损失。第二阶段的总体损失可以表示为:
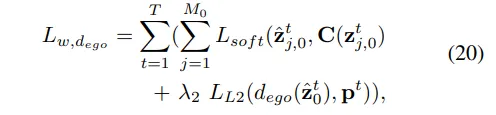
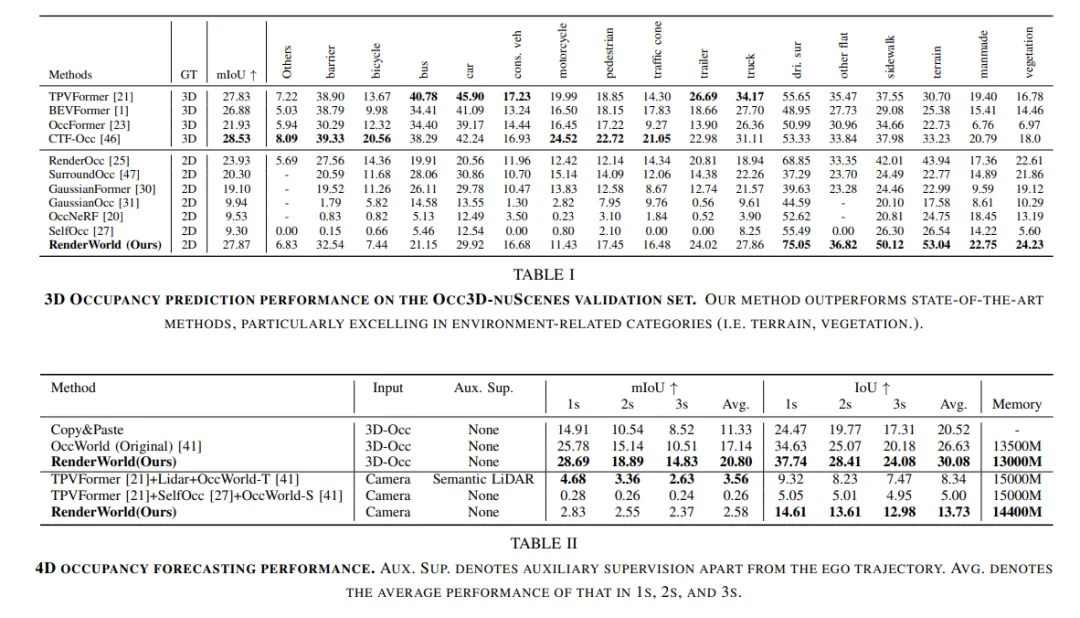
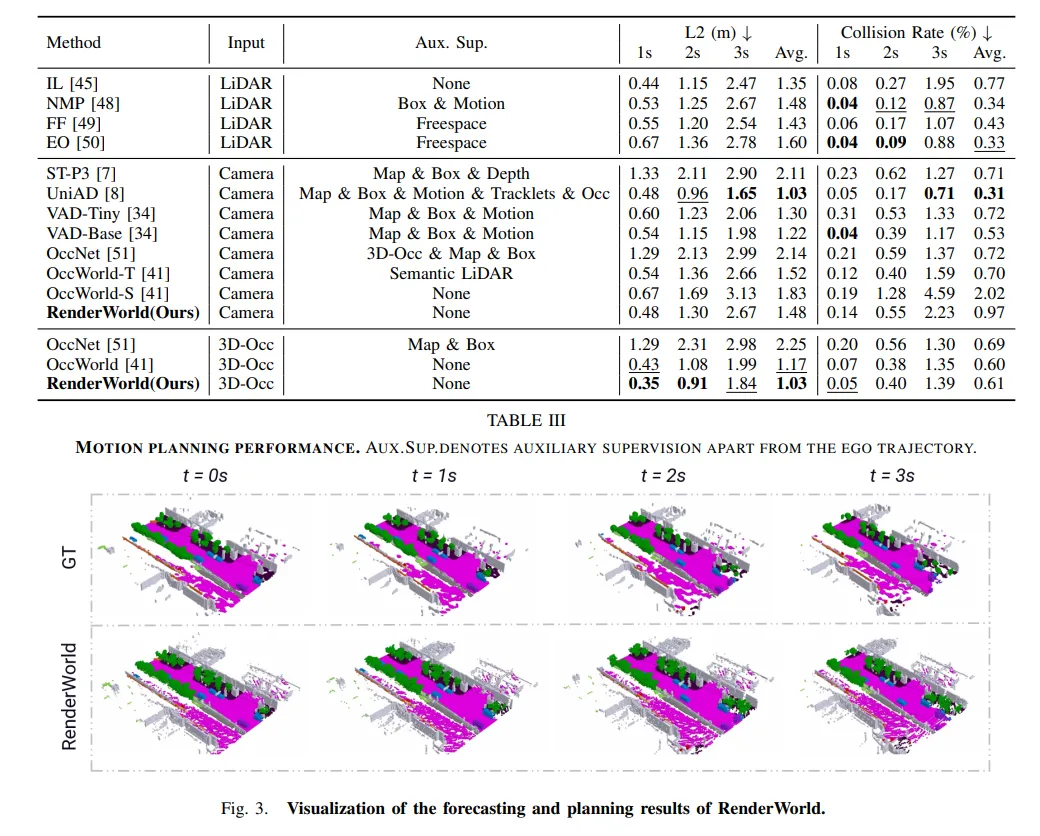
实验对比

....
#纯视觉如何将VLA推向自动驾驶和xx智能巅峰!
视觉-语言-动作(Vision Language Action, VLA)模型的出现,标志着机器人技术从传统基于策略的控制向通用机器人技术的范式转变,同时也将视觉-语言模型(Vision Language Models, VLMs)从被动的序列生成器重新定位为在复杂、动态环境中执行操作与决策的主动智能体。
为此,兰州大学、中科院和新加坡国立大学的团队深入探讨了先进的VLA方法,旨在提供清晰的分类体系,并对现有研究进行系统、全面的综述。文中全面分析了VLA在不同场景下的应用,并将VLA方法划分为多个范式:自回归、扩散模型、强化学习、混合方法及专用方法;同时详细探讨了这些方法的设计动机、核心策略与实现方式。
此外,本文还介绍了VLA研究所需的基础数据集、基准测试集与仿真平台。基于当前VLA研究现状,综述进一步提出了该领域面临的关键挑战与未来发展方向,以推动VLA模型与通用机器人技术的研究进展。通过综合300多项最新研究的见解,本综述勾勒出这一快速发展领域的研究轮廓,并强调了将塑造可扩展、通用型VLA方法发展的机遇与挑战。
- 论文标题:Pure Vision Language Action (VLA) Models: A Comprehensive Survey
- 论文链接:https://arxiv.org/abs/2509.19012
一、引言
机器人技术长期以来一直是科学研究的重要领域。在历史发展进程中,机器人主要依赖预编程指令和设计好的控制策略来完成任务分解与执行。这些方法通常应用于简单、重复性的任务,例如工厂装配线作业和物流分拣。近年来,人工智能技术的快速发展使研究人员能够利用深度学习在多种模态(包括图像、文本和点云)下的特征提取与轨迹预测能力。通过整合感知、检测、跟踪和定位等技术,研究人员将机器人任务分解为多个阶段,以满足执行需求,进而推动了xx智能与自动驾驶技术的发展。然而,目前大多数机器人仍以"孤立智能体"的形式运行------它们专为特定任务设计,缺乏与人类及外部环境的有效交互。
为解决这些局限性,研究人员开始探索整合大型语言模型(Large Language Models, LLMs)与视觉-语言模型(VLMs),以实现更精准、灵活的机器人操作。现代机器人操作方法通常采用视觉-语言生成范式(如自回归模型或扩散模型),并结合大规模数据集与先进的微调策略。我们将这类模型称为VLA基础模型,它们显著提升了机器人操作的质量。对生成内容的细粒度动作控制为用户提供了更高的灵活性,释放了VLA在任务执行中的实际应用潜力。
尽管VLA方法前景广阔,但针对纯VLA方法的综述仍较为匮乏。现有综述要么聚焦于VLMs基础模型的分类体系,要么对机器人操作技术进行整体的宽泛概述。首先,VLA方法是机器人领域的新兴方向,目前尚未形成公认的方法体系与分类标准,这使得系统总结这类方法面临挑战。其次,当前综述要么基于基础模型的差异对VLA方法进行分类,要么对机器人应用领域的整个发展历程进行全面分析,且往往侧重于传统方法,而对新兴技术关注不足。虽然这些综述提供了有价值的见解,但它们要么对机器人模型的探讨较为浅显,要么主要聚焦于基础模型,导致在纯VLA方法的研究文献中存在明显空白。
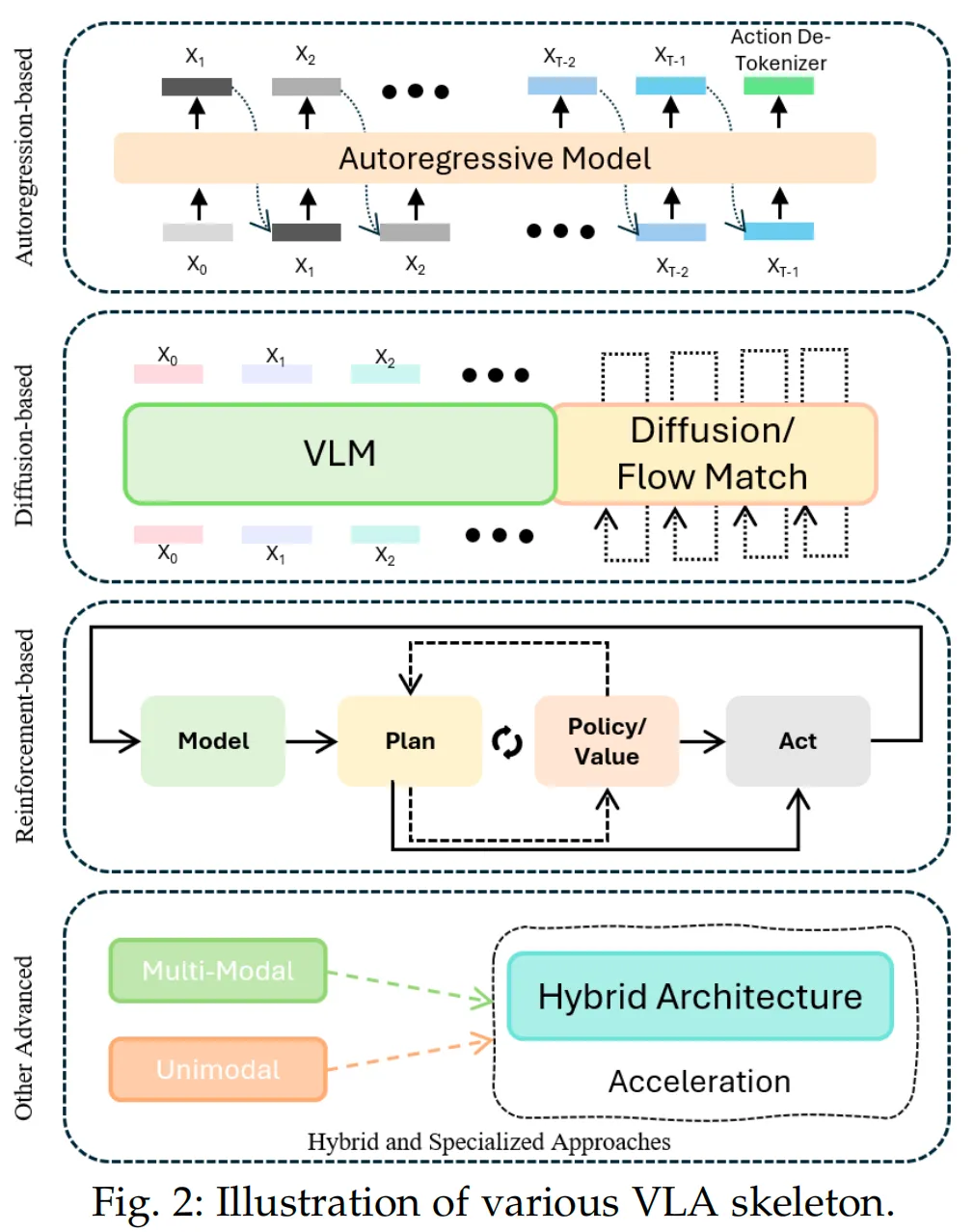
本文对VLA方法及相关资源进行了深入研究,针对现有方法提供了聚焦且全面的综述。我们的目标是提出清晰的分类体系、系统总结VLA研究成果,并阐明这一快速发展领域的演进轨迹。在简要概述LLMs与VLMs之后,本文重点关注VLA模型的策略设计,突出以往研究的独特贡献与显著特征。我们将VLA方法分为五类:自回归型、扩散型、强化学习型、混合型及专用方法,并详细分析了各类方法的设计动机、核心策略与实现机制(如图2所示,本文展示了这些方法的VLA框架结构)。
此外,本文还探讨了VLA的应用领域,包括机械臂、四足机器人、人形机器人和轮式机器人(自动驾驶车辆),全面评估了VLA在不同场景下的部署情况。考虑到VLA模型对数据集与仿真平台的高度依赖,本文还简要概述了这些关键资源。最后,基于当前VLA研究现状,本文指出了该领域面临的关键挑战,并勾勒了未来研究方向------包括数据局限性、推理速度与安全性等问题------以加速VLA模型与通用机器人技术的发展。
本综述的整体结构如图1所示:第2章概述VLA研究的背景知识;第3章介绍机器人领域现有的VLA方法;第4章阐述VLA方法所使用的数据集与基准测试集;第5章与第6章分别讨论仿真平台与机器人硬件;第7章进一步探讨基于VLA的机器人方法面临的挑战与未来方向;最后,对全文进行总结,并对未来发展提出展望。
综上,本文的主要贡献如下:
- 提出了结构清晰的纯VLA方法分类体系,根据其动作生成策略对方法进行分类。这一分类体系有助于理解现有方法,并突出该领域的核心挑战。
- 综述强调了每类方法与技术的显著特征及方法创新,为当前研究提供了清晰的视角。
- 全面概述了用于VLA模型训练与评估的相关资源(数据集、基准测试集与仿真平台)。
- 探讨了VLA在机器人领域的实际应用价值,指出了现有技术的关键局限性,并提出了潜在的进一步研究方向。
二、背景
视觉-语言-动作(VLA)模型的出现,标志着机器人技术从传统基于策略的控制向通用机器人技术迈出了重要一步,同时也将视觉-语言模型(VLMs)从被动的序列生成器转变为能够在复杂动态环境中进行操作和决策的主动智能体。本章将从单模态基础模型的发展、VLA模型的演进,以及通用xx智能的未来方向三个维度,梳理VLA研究的技术背景。
早期:LLM/VLM基础模型
单模态建模的突破为多模态融合奠定了方法学和工程基础。在不同模态领域,一系列里程碑式的模型为VLA的诞生积累了关键技术能力:
计算机视觉领域
计算机视觉领域的核心进展在于建立了从局部卷积到深度表征学习的范式,并通过注意力机制进一步提升了模型的迁移性和泛化能力:
- 卷积神经网络(CNNs):AlexNet首次证明了深度CNN在图像分类任务中的优越性,开启了深度视觉学习的时代;ResNet通过残差连接解决了深度网络训练中的梯度消失问题,进一步推动了网络深度的提升。
- 视觉Transformer(ViT):ViT将自注意力机制引入图像领域,将图像分割为固定大小的"图像块"(image patches)并将其视为序列输入,大幅提升了模型对全局信息的捕捉能力,为跨模态序列建模提供了重要参考。
自然语言处理领域
自然语言处理(NLP)领域的突破源于Transformer架构的提出,该架构支持大规模预训练和模态对齐技术,催生出具备强大推理、指令跟随和上下文学习能力的大型语言模型(LLMs):
- 代表性模型包括BERT(双向Transformer预训练模型,擅长理解任务)、GPT系列(生成式预训练Transformer,从GPT-1到GPT-4,逐步提升了长文本生成和复杂推理能力)、T5(文本到文本统一框架,支持多种NLP任务)。
- 这些模型通过海量文本数据的预训练,掌握了丰富的语义知识和语言逻辑,为后续融合视觉信息、生成动作指令奠定了语言理解基础。
强化学习领域
强化学习领域的进展聚焦于策略优化和序列决策能力的提升,从早期的深度Q网络(DQN)、近端策略优化(PPO),到后来的决策Transformer(Decision Transformer),形成了通过序列建模统一控制任务的新视角。决策Transformer将强化学习中的"状态-动作-奖励"序列视为文本序列进行建模,为VLA中"感知-语言-动作"的统一序列处理提供了思路。
视觉-语言模型
VLMs作为连接单模态学习与xx智能的关键桥梁,经历了从模态对齐到复杂跨模态理解的发展过程:
- 早期对齐模型:ViLBERT、VisualBERT通过双流或单流Transformer架构实现图像与文本的对齐和融合,初步解决了跨模态表征问题。
- 对比学习模型:CLIP(对比语言-图像预训练)通过大规模图像-文本对的对比学习,将两种模态映射到共享嵌入空间,支持零样本和少样本识别与检索,为VLA的"视觉-语言"基础对齐提供了核心技术。
- 指令微调模型:BLIP-2、Flamingo、LLaVA等模型通过指令微调,强化了开放域跨模态理解、细粒度接地(grounding)和多轮推理能力,能够更好地理解人类语言指令与视觉场景的关联,为VLA模型的"动作生成"环节奠定了跨模态理解基础。
现状:VLA模型的发展从LLM/VLM到VLA模型的演进
随着LLM和VLM技术的成熟,研究自然地向"视觉-语言-动作"一体化方向推进。VLA模型将视觉感知、语言理解和可执行控制统一在单一序列建模框架中,其核心设计思路包括:
- 模态token化:将图像(如通过ViT编码为视觉token)、语言指令(如通过LLM编码为文本token)、机器人状态(如关节角度、传感器反馈)和动作(如控制指令)均转换为统一的token格式。
- 自回归动作生成:以视觉token、文本token和状态token为前缀或上下文,自回归生成动作token序列,最终解码为机器人可执行的控制指令,从而闭合"感知-语言-动作"循环。
与传统的"感知-规划-控制"分阶段流水线相比,VLA的优势在于:
- 端到端跨模态对齐,无需手动设计模态间的转换模块;
- 继承VLMs的语义泛化能力,能够理解模糊或开放域语言指令;
- 通过显式的状态耦合和动作生成,提升对环境干扰的鲁棒性和长任务执行能力。
这一演进路径------从单模态到多模态,再到"多模态+可执行控制"------为机器人"看见、理解并行动"提供了方法论基础。
数据与仿真的支撑作用
VLA模型在机器人领域的发展高度依赖高质量数据集和能够仿真真实场景复杂度的仿真平台,二者共同解决了深度学习驱动的机器人技术"数据稀缺"和"实机测试风险高"的核心问题:
(1)数据集:真实与通用的双重支撑
当前VLA模型多基于数据驱动,数据集的规模、多样性和标注质量直接决定模型性能:
- 真实世界数据集:采集过程需大量人力和资金投入,但能反映真实环境的复杂性。例如:
- BridgeData涵盖10个环境中的71项任务,支持跨领域机器人技能迁移;
- Open X-Embodiment(OXE)整合了21个机构的22个机器人数据集,包含527项技能和160266个任务,通过标准化数据格式促进VLA研究的可复现性。
- 互联网视频数据集:为解决真实机器人数据稀缺问题,研究人员利用互联网上的大规模人类操作视频(如日常家务、工业装配视频)作为通用数据,为VLA模型提供辅助监督,提升对"人类动作-语言指令"关联的理解。
- 数据集挑战:现有数据仍存在标注成本高、长尾场景(如罕见物体操作、突发环境变化)覆盖不足的问题,限制了VLA模型的泛化能力。
(2)仿真平台:安全与高效的测试环境
仿真平台通过生成大规模带标注数据、提供可控环境,成为VLA模型训练和评估的关键工具,其核心优势包括:
- 多样化环境与传感器配置:支持自定义场景(如家庭、工厂、户外)和传感器(RGB-D相机、IMU、触觉传感器),仿真真实机器人的感知条件;
- 物理真实性:通过精确的物理引擎(如MuJoCo的刚体动力学、Isaac Gym的GPU加速物理仿真)仿真物体碰撞、力反馈等物理交互,确保生成的"动作-效果"关联符合真实世界规律;
- 代表性平台:
- THOR:提供接近照片级真实感的3D室内场景,支持导航和物体交互任务;
- Habitat:专注于xx智能导航,支持大规模场景和多智能体交互;
- MuJoCo/Isaac Gym:擅长机器人动力学仿真,适用于机械臂操作、四足机器人 locomotion 等任务;
- CARLA:面向自动驾驶,提供真实城市交通场景和多传感器数据生成。
这些数据集和仿真平台共同缓解了真实机器人数据稀缺的问题,加速了VLA模型的训练、评估与迭代。
迈向通用xx智能
VLA模型处于视觉、语言、动作三大领域交叉的前沿,其核心目标是实现"通用xx智能"------即机器人不仅具备认知能力,还能通过物理身体与环境交互,适应多样化任务和场景。
通用xx智能的核心内涵
通用xx智能强调"身体-感知-反馈"的一体化,认为类人智能行为不仅依赖认知处理,还需结合物理身体的运动能力、环境感知能力和实时反馈机制。为适应不同任务需求,通用xx智能可通过多种机器人形态实现:
- 家庭场景的人形机器人、工业场景的灵巧操作机械臂、特殊场景的仿生机器人(如水下机器人、无人机)等。
- 这些机器人需在开放环境中自主理解任务(如"整理桌面""修复设备")、规划动作、应对突发变化,最终实现跨场景、跨任务的通用操作能力。
VLA模型的潜力与挑战
VLA模型通过整合视觉编码器的表征能力、LLM的推理能力、强化学习与控制框架的决策能力,有望弥合"感知-理解-动作"的鸿沟,成为实现通用xx智能的核心路径。目前,VLA已在视觉-语言-动作交互中取得显著进展,但仍面临以下挑战:
- 可扩展性:现有模型难以适应大规模、多样化的真实场景(如从实验室到户外、从单一任务到多任务);
- 泛化性:在训练数据未覆盖的场景(如未知物体、复杂光照)中,动作生成的准确性和安全性下降;
- 安全性:实机部署时,模型可能因环境干扰或指令歧义生成危险动作(如碰撞人类或设备);
- 真实世界部署:仿真环境与真实环境的差异("仿真到现实差距")导致模型在实机上的性能衰减。
尽管存在挑战,VLA仍被广泛认为是xx人工智能的关键前沿方向,其发展正逐步向通用xx智能的愿景迈进。
三、视觉-语言-动作(VLA)模型
近年来,得益于多模态表征学习、生成式建模和强化学习的进展,VLA模型实现了快速且系统性的发展。本章将梳理VLA的主要方法范式,包括自回归模型、扩散模型、强化学习模型,以及混合与专用设计,并分析各范式的核心创新、代表模型与局限性。
视觉-语言-动作研究中的自回归模型
自回归模型是VLA任务中序列生成的经典且高效范式。该类模型将动作序列视为时间依赖过程,基于历史上下文、感知输入和任务指令逐步生成动作。随着Transformer架构的发展,现代VLA系统已证明该范式的可扩展性和鲁棒性。
自回归通用VLA方法
通用VLA智能体的研究核心是将感知、任务指令和动作生成统一在自回归序列建模框架中,通过对多模态输入的token化,实现跨任务的逐步动作生成。其发展历程可概括为三个阶段:
- 早期统一token化:Gato(2022)首次实现对异质模态(视觉、语言、状态、动作)的token化,通过单一Transformer架构进行联合训练,证明了"多模态统一建模"的可行性。
- 大规模真实数据训练:RT-1(2022)基于13万条真实世界演示数据训练,通过FiLM(特征调制)实现多模态融合,提升了实机控制的准确性;RT-2(2023)在PaLM-E基础上扩展动作token,并融入网络级VLM知识,支持开放词汇表抓取(如"拿起红色杯子");PaLM-E(2023)将预训练语言模型知识融入xx控制,可处理视觉问答(VQA)、导航、操作等多任务。
- 跨平台泛化与效率优化:为解决"不同机器人形态适配"问题,Octo(2024)通过150万条视频数据训练开源跨机器人策略,支持无奖励模仿学习;LEO(2024)通过两阶段训练实现3D视觉-语言对齐与VLA微调;UniAct(2025)定义"通用原子动作",解决跨机器人形态的异质性问题。同时,轻量化设计成为趋势:NORA(2025)采用FAST+tokenizer和97万条演示数据,构建轻量级开源VLA;RoboMM(2024)通过模态掩码实现多模态融合,在RoboData数据集上达到最优性能。
此外,近期研究还关注推理能力整合:OneTwoVLA(2025)设计自适应"系统1(快速反应)-系统2(深度推理)"机制,支持长任务规划和错误恢复;UP-VLA(2025)通过统一提示框架融合任务、视觉和动作信息,提升少样本性能。
目前,自回归通用VLA已从概念验证转向强调可扩展性、语义推理和部署效率的阶段,但在安全性、可解释性和人类价值观对齐方面仍存在未解决问题。

基于LLM的自回归推理与语义规划
LLM的融入使VLA系统从"被动输入解析器"转变为"语义中介",支持长任务和组合任务的推理驱动控制。其发展可分为四个方向:
- 自对话推理:Inner Monologue(2022)引入"动作前规划-动作后反思"的自对话推理循环,提升xx任务成功率;Instruct2Act(2023)设计"视觉-语言-任务脚本-动作"流水线,通过语义中介连接语言指令与动作生成;RoboFlamingo(2023)适配OpenFlamingo至机器人领域,实现VLM到VLA的高效迁移。
- 反馈与分层规划:Interactive Language(2022)支持实时语言修正,允许人类在任务执行中调整指令;Hi Robot(2025)采用"粗到细"分层规划,处理长语言指令;Mobility VLA(2024)将长上下文VLM与导航结合,支持多模态指令跟随;NORA(2025)强调轻量化部署,适合资源受限场景。
- 分层控制与链推理:DexGraspVLA(2025)结合VLM规划与扩散模型,实现鲁棒灵巧抓取;CoT-VLA(2025)引入视觉链推理(Visual Chain-of-Thought),通过预测目标提升长任务稳定性;HAMSTER(2025)利用域外数据训练分层VLA,增强泛化能力;InSpire(2025)通过空间推理提示减少虚假关联,提升推理可靠性。
- 平台化与规模化:Gemini Robotics(2025)基于Gemini 2.0构建多任务xx推理平台;(2025)通过异质机器人数据训练,支持开放世界泛化;FAST(2025)设计变长动作token,提升长任务执行效率;LLaRA(2024)通过对话任务增强数据,提升VLM到VLA的迁移能力。
尽管该方向已从语义中介发展为交互式分层规划系统,但仍面临幻觉控制(生成与场景无关的推理结果)、多模态对齐稳定性、实时安全性等挑战。
自回归轨迹生成与视觉对齐建模
该方向通过自回归建模强化"感知-动作"映射,同时确保视觉-语言语义对齐,核心是基于多模态观测解码运动轨迹或控制token,为"指令跟随-动作执行"提供统一机制。
- 早期语言-轨迹映射:LATTE(2022)首次证明直接将语言映射为运动轨迹的可行性,为后续多模态扩展奠定基础;VIMA(2023)通过语言、视觉、动作的统一token化,实现强跨任务泛化(主要在仿真环境中);InstructRL(2023)采用联合视觉-语言编码器与策略Transformer,提升模态对齐精度。
- 视频预测与世界建模:GR-1(2024)、GR-2(2024)将视频生成预训练迁移至机器人领域,GR-2进一步融入网络级视频-语言监督,支持零样本操作;WorldVLA(2025)通过联合视觉-动作建模,缓解自回归误差累积问题;TraceVLA(2025)引入视觉轨迹提示(Visual Trace Prompting),捕捉长任务中的关键线索。
- 跨机器人形态适配:Bi-VLA(2024)设计双臂预测器,支持协同双手机械操作;RoboNurse-VLA(2024)在医疗场景中实现高精度手术抓取;Moto(2025)通过"运动语言token"连接视频预训练与动作执行,提升模型迁移能力;OpenVLA(2024)发布70亿参数开源模型,基于97万条轨迹训练,性能超越RT-2-X,支持跨平台泛化。
- 多模态感知扩展:VTLA(2025)融合视觉-触觉输入与偏好优化,在未知任务中的成功率超过90%;PointVLA(2025)将点云注入预训练VLA,实现轻量化3D推理;GraspVLA(2025)基于GraspVerse预训练GPT风格解码器,支持真实世界抓取迁移;OpenDriveVLA(2025)将2D/3D感知对齐到统一语义空间,生成自动驾驶轨迹。
该方向已从"语言-轨迹直接映射"发展为涵盖多模态预训练、视频驱动世界建模、跨形态适配的生态,但在长任务稳定性、噪声输入下的语义接地、实机部署效率方面仍需改进。
自回归VLA的结构优化与高效推理
为实现VLA模型的规模化部署和实时控制,研究聚焦于减少计算冗余、缩短推理延迟、保持跨场景鲁棒性,主要方向包括:
- 分层与模块化优化:HiP(2023)将任务分解为符号规划、视频预测、动作执行三阶段,支持自回归模型的长任务推理;Actra(2024)通过轨迹注意力和可学习查询优化Transformer,降低计算开销;领域专用优化(如空间VLA的体素网格与空间注意力、VLA-Cache的自适应键值缓存)进一步减少冗余计算。
- 动态自适应推理:DeeR-VLA(2024)基于任务复杂度实现解码早期终止,降低实时控制成本;FAST(2025)将长动作序列压缩为变长token,提升推理效率;BIT-VLA(2025)采用1位量化(1-bit quantization),将内存占用降至30%,同时保持性能。
- 轻量化压缩与并行化:MoLe-VLA(2025)通过混合专家(Mixture-of-Experts)路由实现动态层跳过,降低40%计算成本;PD-VLA(2025)采用并行定点解码,无需重新训练即可加速推理;CLIPort(2021)分离"是什么(what)"和"在哪里(where)"路径,生成动作热力图,提升计算效率。
- 多模态推理与效率融合:OTTER(2025)将语言感知注入视觉编码,增强模态对齐;ChatVLA(2025)通过专家路由和分阶段对齐实现规模化;LoHoVLA(2025)构建统一分层控制,支持超长任务闭环执行。
该方向已从早期分层分解发展为自适应计算、轻量化压缩、多模态感知融合的综合优化体系,为实机部署提供了关键技术支撑,但仍需进一步探索硬件感知协同优化和安全机制。
自回归模型的创新与局限
- 创新点:通过Transformer架构统一多模态感知、语言推理和序列动作生成,支持跨任务泛化;融入LLM实现语义规划,扩展长任务处理能力;通过轨迹生成与视觉对齐,提升动作准确性;结构优化与量化技术降低部署成本。
- 局限:自回归解码存在误差累积和延迟问题;多模态对齐在噪声输入下易失效;大规模模型训练需海量数据和计算资源;推理过程的幻觉、稳定性和可解释性不足;效率优化常以精度或泛化为代价。
视觉-语言-动作研究中的扩散模型
扩散模型(含流匹配、变分自编码器等)作为生成式AI的变革性范式,在VLA框架中展现出独特优势:通过将动作生成建模为"条件去噪过程",实现概率性动作生成,支持从同一观测生成多种有效轨迹。本章从通用方法、多模态融合、应用部署三个维度梳理其发展。
扩散通用VLA方法
扩散模型在VLA中的核心突破是将机器人控制从"确定性回归"转变为"概率性生成",其发展聚焦于表征结构丰富化和生成稳定性提升:
- 几何感知生成:SE(3)-DiffusionFields(2023)将扩散模型扩展到SE(3)位姿空间,学习平滑代价函数,联合优化抓取与运动规划,确保动作的物理一致性;3D Diffuser Actor(2024)通过条件扩散嵌入3D场景信息,提升轨迹生成的空间合理性。
- 视频驱动生成:UPDP(2023)将决策视为"视频生成"任务,以图像为交互接口、语言为指导,利用视频的时间连续性提升长任务规划能力;AVDC(2024)通过光流和运动重建,从无动作标签的视频中学习视觉运动策略;RDT-1B(2025)构建大规模扩散模型,通过时间条件建模支持双手机械操作的零样本泛化。
- 时间一致性优化:TUDP(2025)通过跨时间步的统一扩散 velocity 场和动作判别机制,提升轨迹时间连贯性;CDP(2025)利用历史动作条件和缓存机制,减少动态环境中的动作抖动;DD VLA(2025)将动作分割为离散块,通过离散扩散和交叉熵训练提升生成效率。
该方向已实现从"确定性动作"到"概率性多轨迹生成"的转变,支持几何感知和时间一致的动作生成,但在动态环境中的轨迹稳定性仍需改进。
基于扩散的多模态架构融合
扩散模型与Transformer的结合是该方向的核心趋势------注意力机制天然适配生成式建模,而多模态融合则需解决"异质模态保留独特属性"的挑战:
- 大规模扩散Transformer:Dita(2025)构建可扩展扩散Transformer,直接对连续动作进行去噪;Diffusion Transformer Policy(2025)通过超大规模注意力架构(超小动作头设计),提升连续动作建模精度,自注意力的归纳偏置与机器人行为的组合性高度契合。
- 多模态token对齐:M-DiT(2024)将视觉、语言、位置目标映射为统一多模态token,支持灵活的条件扩散生成;ForceVLA(2025)将6轴力传感视为一级模态,通过力感知混合专家(MoE)融合触觉-视觉-语言嵌入,提升接触密集型操作的准确性。
- 推理与扩散结合:Diffusion-VLA(2025)引入"自生成推理"模块,生成符号化中间表示,连接语言推理与扩散动作生成;CogACT(2024)通过语义场景图整合感知、推理与控制,增强模型对任务逻辑的理解;PERIA(2024)联合微调多模态LLM与图像编辑模型,提升子目标规划能力。
- 预训练模型复用:SuSIE(2023)复用预训练图像编辑扩散模型,通过生成目标图像实现零样本机器人操作;Chain-of-Affordance(2024)将任务解析为"序列可用性子目标",显式建立"感知-动作"对,提升复杂环境中的任务分解能力;(2024)在"观测-理解-执行"循环中,将视频和语言编码为 latent token,支持端到端控制。
该方向已从"单一架构适配"发展为融合推理、多传感输入、预训练知识的认知启发框架,但计算成本高、数据集多样性不足仍是主要瓶颈。
扩散VLA的应用优化与部署
扩散模型的实机部署需解决效率、适应性和鲁棒性三大核心问题,近期研究呈现"智能稀疏化""认知启发设计""防御性AI"三大趋势:
- 效率优化:TinyVLA(2025)通过LoRA微调(仅5%可训练参数)降低训练成本,支持单GPU训练;SmolVLA(2025)通过异步推理在消费级硬件上部署紧凑VLA;VQ-VLA(2025)采用向量量化tokenizer,缩小"仿真到现实"差距;OFT(2025)通过并行解码、动作分块和连续表征学习,优化微调效率。
- 任务适应性:DexVLG(2025)在DexGraspNet上训练大规模抓取模型,支持灵巧手零样本抓取;AC-DiT(2025)通过多模态移动性条件适配扩散Transformer,支持移动操作;ObjectVLA(2025)无需人类演示即可实现开放世界物体操作;SwitchVLA(2025)基于状态-上下文信号建模"执行感知任务切换",适应动态环境。
- 认知启发架构:MinD(2025)整合低频视频预测(战略规划)与高频扩散策略(反应式控制);TriVLA(2025)分离视觉语言推理、动力学感知和策略学习模块,实现36Hz交互频率;Hume(2025)融合双系统价值引导推理与快速去噪,平衡精度与速度;DreamVLA(2025)通过自反思循环(含链推理、错误token、专家层)提升鲁棒性。
- 领域扩展与基础模型:DriveMoE(2025)采用场景/动作专用混合专家架构,提升自动驾驶闭环控制性能;DreamGen(2025)生成神经轨迹,支持人形机器人学习新任务;EnerVerse(2025)通过自回归视频扩散预测xx未来;FP3(2025)构建大规模3D基础扩散策略,基于6万条轨迹预训练;GR00T N1(2025)将多模态Transformer整合为人形机器人基础模型。
- 鲁棒性提升:BYOVLA(2025)在推理时动态编辑无关视觉区域,无需重训练即可增强鲁棒性;GEVRM(2025)基于文本引导视频生成,提升复杂场景中的操作可靠性;VidBot(2025)从单目视频中重建3D可用性(affordance),支持零样本操作。
该方向已从"实验室原型"转向"跨领域实用系统",但在安全关键场景的可靠性、泛化到极端环境的能力方面仍需突破。
扩散模型的创新与局限
- 创新点:将机器人控制重构为生成式问题,支持概率性动作生成;通过多模态融合增强场景理解;轻量化设计和认知启发架构提升部署可行性;在自动驾驶、人形机器人等领域实现专用适配。
- 局限:动态环境中的时间连贯性差;大规模模型需海量数据和计算资源;安全关键场景的可靠性未充分验证;多模态融合可能稀释单模态优势;领域专用适配可能降低迁移性。
视觉-语言-动作研究中的强化学习微调模型
强化学习(RL)微调模型通过融合视觉-语言基础模型与强化学习算法,增强VLA的感知、推理和决策能力。该类模型利用视觉和语言输入生成上下文感知动作,在自动驾驶、机器人操作、xxAI等领域展现出优势,尤其擅长结合人类反馈、适应新任务,性能常超越纯监督范式。

VLA研究中的强化学习微调策略
强化学习在VLA中的应用聚焦于"奖励设计""策略优化""跨任务迁移",其发展可分为以下方向:
- 自监督奖励与表征学习:VIP(2023)从无动作视频中学习与动作无关的"目标条件价值函数",通过嵌入距离隐式评估价值,生成平滑表征;LIV(2023)基于视觉预训练生成密集奖励函数,支持未知任务;PR2L(2024)融合VLM世界知识与RL,提升机器人操作的泛化性;ALGAE(2024)通过语言引导抽象解释RL驱动行为,增强可解释性。
- 跨模态奖励代理与人类反馈:ELEMENTAL(2025)通过VLM语义映射从演示数据中学习奖励代理,支持复杂操作任务的快速定制;SafeVLA(2025)从安全角度优化VLA,引入"约束学习对齐机制":通过安全评论网络(Safety Critic Network)估计风险水平,利用约束策略优化(CPO)框架在最大化奖励的同时,确保安全损失低于预设阈值,显著降低多任务(操作、导航、处理)中的风险事件,尤其适用于语言指令模糊的场景。
- 跨机器人形态适配:NaVILA(2025)通过单阶段RL策略微调VLA,输出连续控制指令,适应复杂地形和动态语言指令;MoRE(2025)将多个低秩自适应模块作为"专家"融入密集多模态LLM,构建稀疏激活混合专家模型,以Q函数形式通过RL目标训练,提升四足机器人VLA的规模化能力;LeVERB(2025)设计分层VLA框架,将视觉-语言处理与动力学级动作处理耦合,通过RL将"潜在词汇"转换为高频动态控制指令,支持人形机器人全身控制(WBC)。
- 离线与在线RL融合:ReinboT(2025)基于离线混合质量数据集,通过预测密集奖励捕捉任务差异,引导机器人生成长期收益最优的决策;SimpleVLA-RL(2025)仅用单条轨迹和二元(0/1)结果奖励训练,无需密集监督或大规模行为克隆数据,性能接近全轨迹监督微调(SFT);ConRFT(2025)结合离线行为克隆(BC)、Q学习(提取有限演示中的策略、稳定价值估计)与在线一致性目标(人工干预确保安全探索),平衡样本效率与策略安全性。
- 领域扩展与效率优化:AutoVLA(2025)在自动驾驶领域引入自回归生成模型,通过"链推理微调"和"组相对策略优化"生成离散可行动作,重建连续轨迹;RPD(2025)通过RL蒸馏从VLA教师模型中学习学生模型,提升推理速度;RLRC(2025)通过"结构化剪枝-SFT+RL恢复-量化"的压缩框架,在降低内存占用、提升推理吞吐量的同时,保持原VLA的任务成功率。
强化学习模型的创新与局限
- 创新点:利用视觉-语言信号生成可迁移的密集奖励代理;结合离线BC与在线RL稳定策略优化;引入安全约束降低开放环境风险;适配四足、人形、自动驾驶等多形态机器人,展现强通用性。
- 局限:奖励工程常存在间接性或噪声,导致学习次优;监督微调与探索的相互作用影响训练稳定性;高维真实环境中的训练计算成本高;安全策略在对抗性指令下的泛化性不足。
其他先进研究方向
除自回归、扩散、强化学习三大基础范式外,VLA研究还涌现出融合多范式、增强多模态理解、适配专用领域、构建基础模型、优化实际部署的先进方向,进一步扩展了VLA的能力边界。
混合架构与多范式融合
针对复杂xx任务的多样性,混合架构通过组合多范式优势(如扩散的物理一致性、自回归的推理能力、RL的适应性),构建更灵活的VLA系统:
- HybridVLA(2025)在70亿参数框架中统一扩散轨迹生成与自回归推理,兼顾动作平滑性与上下文理解;
- RationalVLA(2025)通过 latent 嵌入连接高层推理与低层策略,过滤不可行指令,规划可执行动作;
- OpenHelix(2025)通过大规模实证研究提供标准化混合VLA设计,含开源实现与设计指南;
- Fast-in-Slow(2025)基于"双系统理论",在慢节奏VLM骨干中嵌入低延迟执行模块,平衡实时响应与高层推理;
- Transformer-based Diffusion Policy(2025)构建十亿参数架构,融合扩散与注意力机制,超越传统U-Net设计,捕捉更丰富的轨迹上下文依赖。
先进多模态融合与空间理解
该方向突破"简单特征拼接",通过建模几何、可用性(affordance)和空间约束,提升VLA的3D场景理解与动作 grounding 能力:
- CLIPort(2021)分离"what"(物体识别)与"where"(动作定位)路径,利用CLIP生成动作热力图,增强视觉-动作对齐;
- VoxPoser(2023)通过LLM引导的可组合3D价值图,将指令解析为目标理解与体素空间动作规划;
- 3D-VLA(2024)通过生成式3D世界模型整合感知、语言与动作,实现3D场景中的连贯控制;
- ReKep(2024)基于关系关键点图建模时空依赖,适用于精度敏感任务(如精密装配);
- RoboPoint(2024)预测可用性地图作为规划先验,提升复杂场景中的动作可行性;
- BridgeVLA(2025)将3D观测投影到多视角2D热力图,提升动作预测的样本效率;
- GeoManip(2025)嵌入符号化几何约束,无需任务重训练即可泛化动作(如不同尺寸物体的抓取)。
专用领域适配与应用
VLA框架在安全关键、数字交互、人形控制等专用领域的适配,不仅验证了其通用性,也推动了领域特定技术创新:
- 自动驾驶:CoVLA(2024)构建首个大规模自动驾驶VLA数据集,含5万条语言指令-轨迹对,支持导航与危险规避;AutoRT(2024)通过"观测-推理-执行"框架协调机器人集群,将PaLM-E、RT-2等VLM作为战略规划器;
- GUI交互:ShowUI(2024)将VLA应用于图形界面操作,处理点击、拖拽、表单填写等动作,在GUI-Bench上表现优异;
- 人形全身控制:LeVERB(2025)通过"视觉-语言策略学习潜在动作词汇+RL控制层生成动力学指令"的双层设计,实现150+任务的鲁棒"仿真到现实"迁移;Helix(2024)通过单一统一策略网络,实现人形机器人操作、 locomotion 、跨机器人协作;
- 特殊任务:CubeRobot(2025)采用"视觉链推理(VisionCoT)+记忆流"双循环设计,解决魔方还原任务,中低复杂度场景成功率接近100%;EAV-VLA(2025)设计对抗性补丁攻击,用于测试VLA的鲁棒性(如防止机器人被恶意指令误导);
- 移动操作:MoManipVLA(2025)通过航点优化和双层运动规划,将固定基座VLA迁移至移动机器人(如自主导航+抓取)。
基础模型与大规模训练
基础模型通过海量多模态数据训练,为VLA提供"通用先验",支持跨任务、跨形态泛化,是该方向的核心趋势:
- 大规模数据集:DROID(2025)提供15万+轨迹数据,涵盖1000+物体和任务,含RGBD、语言、低维状态等多模态标注;ViSA-Flow(2025)从大规模人类-物体交互视频中提取语义动作流,预训练生成模型,下游机器人学习仅需少量适配;
- 训练策略优化:Zhang等人(2024)通过2500次滚动实验,分析动作空间、策略头设计、监督信号等微调因素,提供基础VLA适配指南;Chen等人(2025)将链推理融入xx策略学习,推理速度提升3倍;
- 统一基础模型:RoboBrain(2025)提出"感知-推理-规划"统一xx基础模型;VC-1(2024)通过4000+小时视频预训练(MAE初始化Transformer),探索数据规模对VLA性能的影响;CAST(2025)通过反事实语言和动作生成增强数据集多样性,提升模型鲁棒性。
实际部署:效率、安全与人机协作
VLA从研究走向应用,需解决实时推理、鲁棒性、人机交互三大核心问题,相关研究聚焦于"系统优化+安全机制+人类协同":
(1)效率优化
- 推理加速:EdgeVLA(2024)去除末端执行器预测的自回归依赖,采用紧凑LLM,推理速度提升6倍;DeeR-VLA(2024)基于置信度的早期退出机制,降低在线控制成本;CEED-VLA(2025)通过一致性蒸馏和早期退出解码,推理速度提升4倍,同时通过混合标签监督缓解误差累积;
- 轻量化设计:RoboMamba(2024)采用轻量化多模态融合,适用于资源受限设备;BitVLA(2025)通过1位量化降低内存占用;MoLe-VLA(2025)动态跳过冗余层,降低40%计算成本;
- 部署适配:RTC(2025)支持动作分块策略的异步平滑执行;cVLA(2025)通过2D航点预测提升"仿真到现实"迁移能力;ReVLA(2025)实现跨视觉领域(如室内/户外光照)的自适应,增强鲁棒性。
(2)安全与鲁棒性
- 故障检测:SAFE(2025)利用VLA内部特征信号检测多任务故障,泛化至未知场景;
- 对抗性防御:Cheng等人(2024)通过物理脆弱性评估程序(PVEP),发现VLA对 adversarial patches、字体攻击、分布偏移的脆弱性,推动鲁棒感知-控制 pipeline 研发;
- 可解释性:Lu等人(2025)揭示VLA隐藏层中"物体-关系-动作"的符号化编码,为透明决策奠定基础;
- 自适应控制:DyWA(2025)联合建模几何、状态、物理和动作,适应动态部分可观测环境。
(3)人机协作
- 人类反馈融合:Xiang等人(2025)设计协作框架,将有限专家干预融入VLA决策,降低操作员工作量并丰富训练数据;
- 闭环交互:Zhi等人(2025)结合GPT-4V感知与实时反馈控制,动态适应环境变化;
- 任务接地:CrayonRobo(2025)通过物体中心提示实现可解释接地(如"拿起红色杯子"对应视觉中的红色区域);
- 技能复用:历史感知策略学习(2022)和接地掩码方法(2025)支持任务分解与技能库构建,提升协作效率。
其他先进方向的创新与局限
- 创新点:混合架构整合多范式优势;3D空间理解增强动作 grounding;专用领域适配拓展VLA应用边界;基础模型提供通用先验;部署优化解决实时性、安全性与协作问题。
- 局限:混合系统计算成本高、可扩展性差;多模态融合在噪声输入下易失效;领域适配可能导致过拟合;基础模型需海量数据与计算资源;部署中的鲁棒性、可解释性仍需提升。
四、数据集与基准测试
与其他模仿学习方法类似,视觉-语言-动作(VLA)模型依赖高质量的标注数据集。这些数据集要么来自真实场景采集,要么通过仿真环境生成(数据集样本如图4所示)。通常,数据集包含多模态观测数据(如图像、激光雷达点云、惯性测量单元(IMU)数据等),以及对应的真值标签和语言指令。为便于系统理解,本文对现有数据集和基准测试进行分析,并提出一种分类方法------根据数据集的复杂度、模态类型和任务多样性对其进行分类。该分类方法为评估不同数据集对VLA研究的适用性提供了清晰框架,并指出了现有资源中可能存在的空白(代表性研究总结于表5)。
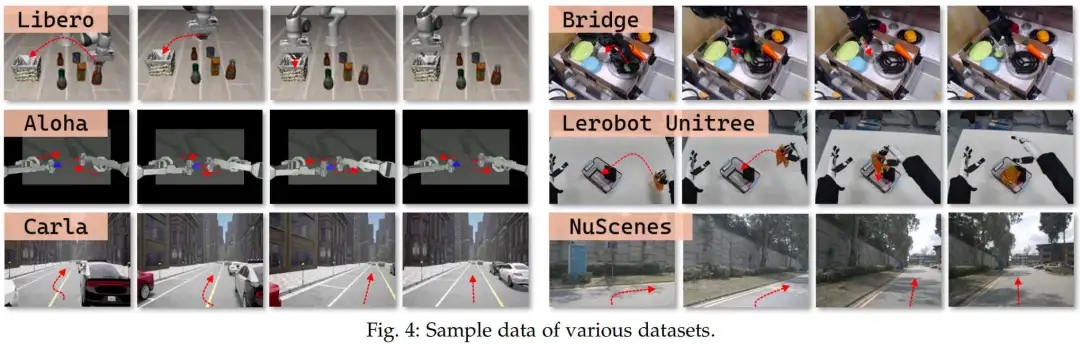
真实世界数据集与基准测试
高质量的真实世界数据集是开发可靠VLA算法的基础。近年来,研究人员已采集了大量高质量、多样化的真实世界机器人数据集,涵盖不同传感器模态、各类任务及多种环境场景。
xx机器人领域的真实世界数据集与基准测试
真实世界xx机器人数据集,指通过机器人在环境中进行感知与动作交互所获取的多模态数据集合。这类数据集专门用于捕捉视觉、听觉、本体感觉和触觉等多模态输入,与相应电机动作、任务意图及环境背景之间的复杂交互关系。它们是训练和评估xx人工智能模型的关键资源------xx人工智能的目标是让机器人在动态环境中通过闭环自适应行为完成任务。通过提供丰富且时间对齐的观测数据与动作数据,这些数据集为模仿学习、强化学习、视觉-语言-动作及机器人规划等领域的算法开发与基准测试提供了基础支持。
当前,xx机器人数据集面临显著的数据成本问题,因为真实世界机器人数据的大规模采集难度较大。采集真实世界机器人数据集面临诸多挑战:不仅需要硬件设备支持,还需实现精准操控。其中,MIME、RoboNet和MT-Opt已采集了涵盖从简单物体推动到复杂家居物品堆叠等多种任务的大规模机器人演示数据集。与以往数据集通常假设每个任务仅有一条最优轨迹不同,这些数据集针对同一任务提供了多个演示样本,并将测试轨迹间的最小距离作为评估指标。该方法极大推动了操纵任务与VLA任务的研究进展。
BridgeData提供了一个大规模跨领域机器人数据集,包含10个环境中的71项任务。实验表明,将该数据集与新领域中少量未见过的任务(如50项任务)联合训练,相比仅使用目标领域数据,任务成功率可提升一倍。因此,许多现代VLA方法均采用BridgeData进行模型训练。
在xx人工智能领域,模型的泛化能力常受限于真实世界机器人数据采集的多样性不足。RT-1提供了一个涵盖广泛真实世界机器人任务的数据集,以同时提升任务性能和对新场景的泛化能力。类似地,Bc-z包含了此前未见过的操纵任务,这些任务涉及同一场景中物体的新组合,为通用策略学习研究提供了支持。部分数据集还为xx人工智能提供了全面的软件平台与生态系统,涵盖手部操纵、移动、多任务处理、多智能体交互及基于肌肉控制等多种场景。
与早期研究相比,RoboHive填补了当前机器人学习能力与潜在发展空间之间的差距,支持强化学习、模仿学习、迁移学习等多种学习范式。值得注意的是,RH20T包含147项任务,涵盖110K个操纵任务片段,提供了视觉、力、音频和动作等多模态数据。每个任务片段均配有人类演示视频和语言描述,因此该数据集特别适用于单样本模仿学习,以及基于已有训练片段向新任务迁移策略的研究。
为推动更具泛化性的操纵策略开发,机器人领域需优先采集大规模、多样化的数据集,涵盖广泛的任务类型与环境场景。已有多个数据集通过多台机器人在不同地区协同采集而成,成为目前地理分布和场景多样性最高的xx机器人数据集之一。此外,Open X-Embodiment(OXE)整合了21家机构协作采集的22个机器人数据集,涵盖527项技能和160266个任务,并提供标准化数据格式,方便研究人员使用(上述数据集概述如表5(A)所示)。
在基准测试评估中,研究人员通常采用"成功率"(完成任务数量占总任务数量的比例)作为核心指标。部分研究还会额外采用"语言遵循率",以评估模型理解和执行语言指令的能力。此外,近年来的VLA模型常通过将训练后的策略迁移到未见过的环境中进行测试,以衡量模型的鲁棒性和泛化性能。
自动驾驶领域的真实世界数据集与基准测试
自动驾驶数据集与xx机器人数据集存在差异,它是人工智能最具变革性的应用领域之一,其感知、规划和控制算法的训练与评估高度依赖大规模数据集。高质量数据集是开发鲁棒且通用的自动驾驶系统的基础,可支持监督学习、基准测试,以及对罕见或安全关键场景的仿真。过去十年间,研究人员已推出多个数据集,提供包含相机图像、激光雷达点云、雷达信号和高清地图在内的多模态传感器数据。这些数据集在地理覆盖范围、传感器配置、驾驶行为多样性和标注丰富度等方面差异显著,成为互补的研究与开发资源。
然而,大多数公开数据集是在开环场景下采集的,且主要反映正常驾驶行为,难以覆盖长尾边缘案例。为解决这一问题,近年来研究人员开始聚焦于生成合成数据、仿真闭环交互,以及构建针对罕见或安全关键事件的专用数据集。数据集设计的持续创新,对推动安全、可扩展且通用的自动驾驶系统发展至关重要。
在评估方面,自动驾驶VLA模型通常采用诸如"L2距离"(衡量与参考轨迹的偏差程度)和"完成率"(量化成功完成驾驶任务的比例)等指标。
仿真数据集与基准测试
为连续控制任务采集大规模真实世界数据面临显著挑战:这类任务需要人类标注者进行实时交互和持续反馈,且数据采集成本高、耗时长,难以实现规模化。而仿真数据则为获取大规模、高质量数据提供了可行途径------研究人员可利用虚拟化引擎生成的仿真数据,对xx机器人或自动驾驶模型进行训练与评估。
xx机器人领域的仿真数据集与基准测试
xx人工智能仿真数据集通常包含合成场景、基于物理的交互过程、导航标注、物体操纵标注、任务执行标注及智能体-环境动态关系数据。这些数据集支持对视觉导航、语义探索、复杂多步骤物体操纵等多种任务的基准测试与训练。典型示例包括Meta-World、RLBench、RoboGen等,它们在真实感、任务多样性和控制精度方面各有取舍。通过支持安全实验和大规模数据采集,仿真数据集为开发鲁棒且通用的xx智能体奠定了基础。随着领域发展,设计更丰富、更真实的仿真数据集(涵盖多样的智能体形态、任务类型和环境场景),仍是推动模型走向真实世界部署的关键。
ROBOTURK是一个用于高质量6自由度操纵状态与动作的仿真数据集,通过移动设备远程操作采集。与传统依赖远程用户在虚拟引擎中演示动作的方法不同,ROBOTURK利用策略学习生成具有不同奖励机制的多步骤机器人任务。通过聚合大量演示样本,该数据集为模型训练和评估提供了精准可靠的数据。
iGibson 0.5推出了一个用于训练和评估交互式导航方案的基准测试。该研究不仅提供了全新的实验仿真环境,还提出了专门的指标来评估导航过程中导航行为与物理交互的协同效果。该基准测试引入"交互式导航评分",包含两个子指标:路径效率和能耗效率。其中,路径效率定义为"最短成功路径长度与机器人实际行驶路径长度的比值(乘以成功指示函数)";能耗效率则衡量导航过程中所需的额外运动学和动力学能耗,反映物理交互的成本。
VIMA推出了名为VIMABENCH的新基准测试,建立了四级评估协议,以评估模型逐步提升的泛化能力------从物体随机放置场景到全新任务场景。类似地,CALVIN和Lota-Bench聚焦于利用多模态机器人传感器数据,在多样化操纵环境中学习长序列、语言条件下的任务。这些基准测试特别适合评估那些通过在大规模交互数据集上训练、并在新场景中测试以实现对未见过实体泛化的方法。此类基准测试的性能通常通过任务成功率来衡量(上述仿真数据集概述如表5(B)所示)。
自动驾驶领域的仿真数据集与基准测试
闭环仿真在确保自动驾驶系统安全性方面发挥关键作用:它能够生成真实世界中难以捕捉或存在危险的安全关键场景。尽管历史驾驶日志为构建新场景提供了宝贵资源,但闭环评估需要对原始传感器数据进行修改,以反映更新后的场景配置。例如,可能需要添加或移除交通参与者,且现有交通参与者和自车的轨迹可能与原始记录存在差异。
UniSim是一款神经传感器仿真器,可将单条记录轨迹扩展为多传感器闭环仿真。它通过构建神经特征网格来重建静态背景和动态交通参与者,并将二者合成,以仿真从新视角获取的激光雷达和相机数据,从而支持添加、移除或重新定位交通参与者。为更好地适应未见过的视角,UniSim还采用卷积网络对原始数据中不可见的区域进行补全。
与真实世界自动驾驶数据集不同,闭环仿真基准测试需要针对交互式驾驶任务设计专用评估指标。常用指标包括"行驶路线偏差"(衡量对规划轨迹的遵循程度)、"违规评分"(对交通规则违规行为进行惩罚)和"完成评分"(评估任务完成情况)。这些指标共同构成了对VLA模型在真实、安全关键驾驶场景中性能的全面评估。
讨论
创新点
本文提出了系统的分类方法、标准化评估指标,以及Open X-Embodiment(OXE)等大规模协作项目------OXE整合了来自多机构的数据集,可促进研究的可复现性和泛化性。这些贡献扩大了任务覆盖范围,丰富了模态组合类型,并提升了跨领域策略迁移能力,推动了xx人工智能研究的规模化发展。
局限性
然而,真实世界数据集的采集成本高、后勤难度大,且常局限于受控实验室环境,场景多样性有限;仿真数据集虽具备可扩展性和安全性,但仍难以完全捕捉真实世界交互的复杂性、噪声和不可预测性。此外,"成功率""轨迹偏差"等基准测试指标,可能无法充分反映模型在语言接地、长序列推理或非结构化环境安全部署等方面的精细能力。要解决这些局限性,不仅需要扩大数据集的多样性和真实感,还需设计更丰富的评估协议,以更好地匹配真实世界自主系统的需求。
五、仿真器
机器人仿真器已成为在多样化交互环境中开发和评估智能机器人系统的必备工具。这类平台通常整合物理引擎、传感器模型(如RGB-D、IMU、激光雷达)和任务逻辑,支持导航、操纵、多模态指令遵循等多种任务。最先进的仿真器可提供具备照片级真实感、物理一致性的可扩展环境,用于通过强化学习、模仿学习或大规模预训练模型训练xx智能体。通过提供安全、可控且可复现的环境,xx仿真器加速了通用机器人智能的发展,同时大幅降低了真实世界实验相关的成本和风险。
THOR是一款仿真器,拥有接近照片级真实感的3D室内场景,人工智能智能体可在其中导航环境、与物体交互以完成任务。它支持模仿学习、强化学习、操纵规划、视觉问答、无监督表征学习、目标检测和语义分割等多个研究领域。与之不同,部分仿真器基于真实空间虚拟化构建(而非人工设计环境),涵盖数千座全尺寸建筑,其中的xx智能体需遵循真实的物理和空间约束。
Habitat及其升级版本Habitat 2.0进一步扩展了这一范式,提供可扩展的仿真平台,用于在具备物理交互能力的复杂3D环境中训练xx智能体。ALFRED推出了一个包含长序列、组合型任务的基准测试,这些任务涉及不可逆的状态变化,旨在缩小仿真基准测试与真实世界应用之间的差距。ALFRED同时提供高层目标和低层语言指令,与现有视觉-语言数据集相比,其任务在序列长度、动作空间和语言变异性方面的复杂度显著提升。
早期结合物理与机器人任务的仿真环境,往往聚焦于狭窄场景,且仅包含小规模简化场景。与之相反,iGibson 1.0和iGibson 2.0是开源仿真平台,支持在大规模真实环境中完成多样化家居任务。它们的场景是真实住宅的复制品,物体分布和布局与物理空间高度一致,从而提升了生态有效性,并缩小了仿真与真实世界机器人学习之间的差距。
先进的仿真器不仅支持多个智能体在同一环境中交互,还能提供丰富的传感器数据和物理输出。理想的仿真器应整合通用物理引擎、灵活的机器人仿真平台和高保真渲染系统,成为机器人仿真和生成模型评估的强大工具。
MuJoCo是一款被广泛采用的开源物理引擎,专为机器人及相关领域(需精准仿真)的研究与开发设计。近年来,基于GPU的仿真引擎逐渐流行,其中最具代表性的是NVIDIA Isaac Gym------它构建于Omniverse平台之上,可在物理真实的虚拟环境中实现对人工智能驱动机器人的大规模开发、仿真和测试。Isaac Gym在学术界和工业界的应用日益广泛,助力加速新型机器人工具的开发和现有系统的优化。
自动驾驶领域也面临类似挑战:大规模真实世界数据的采集和标注成本高、耗时长,且难以采集足够数据覆盖大量罕见边缘案例。为解决这一问题,研究人员开发了包含静态道路元素(如交叉路口、交通信号灯、建筑物)和动态交通参与者(如车辆、行人)的仿真器。CARLA和LGSVL利用游戏引擎渲染真实驾驶场景,支持灵活的传感器配置,并生成适用于驾驶策略训练与评估的信号。这些平台已成为推动自动驾驶研究的关键工具,可提供可控、可复现且经济高效的测试环境。
六、机器人硬件
机器人的物理结构是其实现感知、移动、操纵及与环境交互的基础。其核心组件通常包括传感器、执行器、动力系统和控制单元。其中,传感器(如相机、激光雷达、惯性测量单元和触觉阵列)负责采集外部环境及机器人内部状态的关键信息;执行器(包括电机、伺服电机或液压系统)则将控制信号转化为物理动作,从而实现移动、物体操纵等任务;控制单元一般基于嵌入式处理器或微控制器,作为计算核心整合传感器输入并向执行器下达指令;动力系统通常以电池或外部能源的形式,为机器人的持续运行提供能量支持。
为满足不同应用领域(如工业自动化、服务机器人和自动驾驶)的任务特定需求,硬件设计需在性能、能效、重量和耐用性之间实现平衡。
七、挑战与未来方向
视觉-语言-动作(VLA)模型的挑战
本节总结了推进VLA模型发展过程中面临的开放性挑战与未来方向。尽管近年来VLA模型取得了显著进展,但在发展过程中也逐渐暴露出关键瓶颈。最根本的问题在于,当前的VLA系统大多基于大规模语言模型(LLM)或视觉-语言模型(VLM)的迁移学习构建而成。这些模型虽在语义理解和跨模态对齐方面表现出色,却缺乏与物理世界交互的直接训练和经验。因此,VLA系统在真实环境中常出现"理解指令但无法执行任务"的现象,这反映了一个核心矛盾:语义层面的泛化能力与物理世界中的xx能力相互脱节。如何实现从非xx知识到xx智能的转化,真正弥合语义推理与物理执行之间的鸿沟,仍是当前面临的核心挑战。具体而言,这一矛盾主要体现在以下几个方面:
机器人数据稀缺
机器人交互数据是决定VLA模型性能的关键资源,但现有数据集在规模和多样性上仍存在不足。在真实世界中,跨大量任务和环境收集大规模演示数据受到硬件成本、实验效率和安全问题的限制。现有开源数据集(如Open X-Embodiment)虽推动了机器人学习的发展,但主要集中于桌面操纵和物体抓取任务,任务与环境的多样性不足,严重限制了模型对新场景和复杂任务的泛化能力。
仿真平台(如RLBench)虽能以较低成本生成大规模轨迹数据,但受限于渲染保真度、物理引擎精度和任务建模能力。即便采用域随机化或风格迁移等技术,"虚实差距"(sim-to-real gap)依然存在,许多模型在仿真环境中表现优异,但部署到物理机器人上时却无法正常工作。因此,如何在扩大规模的同时提升机器人数据的多样性和真实性,仍是缓解模型泛化能力不足的首要挑战。
架构异质性
大多数VLA模型尝试对视觉、语言和动作进行端到端建模,但其实现过程中存在明显的架构异质性。一方面,不同研究采用的骨干网络各不相同:视觉编码器可能依赖ViT、DINOv2或SigLIP,语言骨干网络可能基于PaLM、LLaMA或Qwen,而动作头则可能采用离散令牌化、连续控制向量甚至基于扩散的生成方式。这种架构多样性阻碍了模型间的比较与复用,延缓了统一标准的形成。
另一方面,模型内部的感知、推理和控制模块往往耦合松散,导致特征空间碎片化,在不同平台或任务领域间的可移植性较差。部分模型虽在跨任务语言理解方面表现突出,但与底层控制器对接时仍需大量适配工作。这种架构异质性增加了系统集成的复杂性,严重制约了VLA模型的泛化能力和可扩展性。
实时推理约束与成本
当前VLA模型严重依赖大规模Transformer架构和自回归解码机制,这极大地限制了其在实体机器人上的推理速度和执行效率。由于每个动作令牌的生成都依赖于前一个令牌,延迟会不断累积;而动态抓取、移动导航等高频任务则需要毫秒级的响应速度。此外,高维视觉输入和庞大的参数规模带来了极高的计算与内存成本,许多最先进的VLA模型所需的GPU内存远超普通嵌入式平台的承载能力。
即便采用量化、压缩或边-云协同推理等技术,仍难以在精度、实时性和低成本之间实现平衡。这种推理约束与硬件瓶颈的叠加,使得VLA模型的部署陷入"速度过慢"与"成本过高"的两难境地。
人机交互中的伪交互
在人机交互场景中,VLA系统生成动作时往往依赖先验知识或静态训练模式,而非基于环境动态和因果推理的真实交互。当遇到陌生场景或状态变化时,模型通常依赖从数据中学习到的统计相关性,而非通过探测环境或利用传感器反馈来调整动作。这种因果推理能力的缺失,导致VLA系统虽看似能遵循指令,却无法在环境状态与动作结果之间建立真正的因果链,进而难以适应动态环境。
这种"伪交互"现象凸显了VLA模型在因果建模和反馈利用方面的不足,仍是实现xx智能的关键障碍。
评估与基准局限
VLA模型的评估体系同样存在局限。现有基准测试大多设置在实验室或高度结构化的仿真环境中,聚焦于桌面操纵或物体抓取等任务。这类任务虽能衡量模型在特定数据分布下的性能,却无法反映其在开放世界场景中的泛化能力和鲁棒性。一旦将模型部署到户外、工业或复杂家庭环境中,性能往往会大幅下降,暴露出评估体系与真实世界应用需求之间的差距。
这种狭窄的评估范围不仅阻碍了对VLA模型可行性的全面评估,也限制了模型间的横向比较。缺乏统一、权威且多样化的基准测试,正逐渐成为VLA模型向真实世界应用推进的主要瓶颈。
需要注意的是,上述五个方面虽凸显了VLA模型在数据、架构、交互和评估方面的关键不足,但并未涵盖该领域面临的所有挑战。从更长远的角度来看,VLA系统能否真正实现可控性、可信性和安全性,仍是一个核心问题。换言之,VLA的未来发展不仅需要解决性能和泛化问题,还需应对智能体安全部署的深层挑战。这一转变意味着研究人员必须超越单纯的模型优化,推动整个领域的范式革新,以应对长期挑战。
视觉-语言-动作(VLA)模型的机遇
尽管面临严峻挑战,VLA模型的未来仍充满机遇。作为连接语言、感知与动作的关键桥梁,VLA有望突破语义-物理鸿沟,成为实现xx智能的核心路径。克服当前瓶颈不仅可能重塑机器人研究的范式,还能使VLA模型处于真实世界部署的前沿位置。
世界建模与跨模态统一
目前,VLA系统中的语言、视觉和动作仍处于松散耦合状态,这使得模型局限于"指令生成",而非对世界的整体理解。若能实现真正的跨模态统一,VLA模型将能够在单一令牌流中联合建模环境、推理过程和交互行为。这种统一结构将使VLA进化为"原型世界模型",让机器人能够完成从语义理解到物理执行的闭环。这不仅是一项技术突破,更将是迈向通用人工智能的关键一步。
因果推理与真实交互突破
现有大多数VLA模型依赖静态数据分布和表面相关性,缺乏基于因果规律的交互能力。它们通过从先验模式中推测来"仿真交互",而非通过探测环境并利用反馈更新策略。未来,若VLA模型能融入因果建模与交互推理能力,机器人将学会主动探测、验证和调整策略,实现与动态环境的真实"对话"。这一突破将克服"伪交互"问题,标志着智能体从数据驱动智能向深度交互智能的转变。
虚实融合与大规模数据生成
数据稀缺虽是当前的关键局限,但也孕育着巨大机遇。若能通过高保真仿真、合成数据生成和多机器人数据共享,构建虚实融合的数据生态系统,将有可能建立包含数万亿条跨任务轨迹的数据集。正如GPT模型借助互联网规模的语料库实现语言智能的飞跃,此类数据生态系统也可能推动xx智能的跨越式发展,使VLA模型能够在开放世界场景中稳定运行。
社会嵌入与可信生态
VLA模型的终极价值不仅体现在技术能力上,更在于其社会融入度。随着VLA模型进入公共和家庭空间,安全性、可信性和伦理一致性将决定其能否被广泛接受。建立风险评估、可解释性和问责制的标准化框架,将使VLA模型从实验室成果转变为可信的合作伙伴。一旦实现社会嵌入,VLA有望成为下一代人机交互界面,重塑医疗、工业、教育和服务等多个领域。这种社会嵌入不仅是技术落地的里程碑,更是前沿研究转化为真实世界变革力量的重要机遇。
八、结论
近年来,视觉-语言-动作(VLA)模型的研究进展显著,将视觉语言模型的泛化能力扩展到机器人应用领域,包括xx智能、自动驾驶和各类操纵任务。本综述通过分析VLA方法的动机、方法论和应用,系统梳理了该领域的发展脉络;同时提供了统一的架构分类体系,并分析了超过300篇相关文献及支持材料。
首先,本综述根据自回归模型、扩散模型、强化学习、混合结构和效率优化技术,对VLA架构的创新成果进行了分类;随后,探讨了支持VLA模型训练与评估的数据集、基准测试和仿真平台;基于上述全面综述,进一步分析了现有方法的优势与不足,并指出了未来研究的潜在方向。
这些见解共同构成了一份综合参考资料和前瞻性路线图,可为开发可信、持续演进的VLA模型提供指导,进而推动机器人系统中通用人工智能的发展。
参考
1Pure Vision Language Action (VLA) Models: A Comprehensive Survey
....
#全新多IMU快速外参校准方法
两台IMU能与九台IMU相媲美?万事俱备,只欠"外参"
IMU可以与外部感知传感器(如LiDAR和摄像头)协作,这些传感器提供全局观测。由于微机电系统(MEMS)IMU体积小、成本低,SLAM系统可以增加更多的惯性传感器,以便进行故障检测或测量融合。
大多数视觉-IMU融合系统假设每个惯性传感器与系统主体之间的相对位姿是完全标定的。然而仿真实验表明,如果系统不能保证精确的外参,单一IMU能够提供更好的预积分精度。
目前,现有的MIMU外参标定方法需要获得精确的系统轨迹,这通常通过昂贵的转台或外部传感器(例如Kalibr)来估计。尽管这些算法在特定环境中表现良好,但受环境限制或额外设备限制。同时,在线估计传感器噪声仍然是一个挑战,限制了标定精度和计算效率。
本文介绍一种新的方法1,通过建立两个非线性最小二乘问题分别估计惯性传感器之间的相对平移和姿态:
基于原始的陀螺仪测量值优化相对姿态。
受虚拟IMU(VIMU)方法2的启发,生成噪声较小的角加速度测量值,以提高相对位置标定性能。
值得注意的是,该方法不依赖于真实轨迹或外部传感器,同时将惯性噪声的在线估计视为精度的损害,从而避免过拟合问题。
主要贡献包括:
- 提出了一种快速的MIMU外参标定方法。我们在数据集、自制传感器板以及集成RealSense T265和D435i的传感器设备上验证了该方法的优越性,与其他方法相比,具有更高的精度、计算效率和鲁棒性。
- 仿真实验表明,仅融合两台IMU并使用我们的方法进行运动预测,其效果可与融合九台IMU媲美。
- 给出了VIMU方法的一般形式,并提出了其在流形上的传播。实验结果表明,集成该标定方法和流形上的VIMU传播的VIO系统定位精度更高。
多IMU外参快速标定状态变量与坐标系
假设使用两个IMU,分别记为A和B,它们在世界坐标系{W}中移动。IMU的坐标系分别记为{I}、{A}、{B},以及虚拟IMU的坐标系{V}。常见的MEMS IMU输出三轴角速度 和三轴线性加速度 ,其中参考坐标系为{I}。
符号 、、 分别表示传感器测量值的实际值、估计值和真实值。符号
旋转矩阵 表示从{V}到{A}的旋转。同样地,平移矩阵
IMU测量模型
给定IMU的测量模型:其中:
- 和 是随机游走模型的偏置:
- 和 是高斯噪声:
问题描述
给出惯性坐标系下两个IMU的角速度和特定力的关系:
假设在时间 内同步了惯性测量值,待估计的变量是 和
标定解决方案
为了避免欧拉角的万向节锁问题和旋转矩阵的计算复杂性,选择四元数
定义系统状态:
在优化之前,假设已经知道惯性传感器的内参。不评估陀螺仪的失准,因为它已被纳入相对旋转中。
提出的非线性最小二乘优化问题分为两个步骤:相对姿态和相对平移估计。一方面,姿态标定问题独立于线性加速度。另一方面,由于优化了的姿态参数和角速度,平移标定的问题比使用原始惯性测量值时噪声更少。此外,整体计算时间也有所减少。
首先,定义与姿态相关的非线性最小二乘问题:其中, 是与角速度测量相关的残差:相应的协方差矩阵为:
其次,定义与平移相关的非线性最小二乘问题:其中, 是与惯性测量相关的残差:
由于IMU无法测量角加速度 ,我们可以通过虚拟角速度模型的时间导数来估计它:
相应的协方差矩阵为:
将展示虚拟陀螺仪噪声的协方差小于原始值 和 ,偏置协方差也较小。通过将姿态和平移的估计过程分离,该方法节省了时间,并且需要较短的数据采集时间。IMU噪声没有被估计,因为在没有真实轨迹的情况下,无法对噪声施加适当的限制。因此,本方法可以避免过拟合问题。
虚拟IMU方法在流形上的应用
给出虚拟IMU(VIMU)生成方法的一般形式,并完成了提出的方法在相对平移标定中优于使用原始陀螺仪测量值的证明。为了将VIMU与优化的外参集成到视觉-惯性里程计(VIO)系统中,推导了VIMU在流形上的传播。
虚拟IMU一般模型
在融合两个IMU的情况下,建议选择两个传感器之间的中间位置作为VIMU的参考坐标系,而不是任意选择一个姿态。如果VIMU距离B远多于A,或相反,左零空间矩阵 可能是奇异的。以下是两个IMU的VIMU模型一般形式:
其中,矩阵 和 定义在文献【6】中。
虚拟陀螺仪测量的偏置和噪声为:
因此,对等式13的两边取期望,虚拟陀螺仪测量的噪声协方差 和偏置协方差
这证明了虚拟角加速度测量误差更小。因此,提出的方法在相对平移标定中的性能应优于使用原始陀螺仪测量值。同样的推导可适用于其他项。
虚拟IMU在流形上的传播
提出了基于等式13的VIMU在流形上的传播。VIMU的系统状态由姿态、位置、速度和偏置组成:
其中,位姿 属于SE(3)群,
假设VIMU与摄像头同步,并在离散时间 提供测量值。在时间 和
推导了用于更新状态估计的传播方程,基于预积分噪声向量 和VIMU噪声向量 :
从线性化方程(20),我们可以推导出相应的协方差矩阵:
其中, 是VIMU噪声的协方差矩阵。初始条件为 ,而
详细形式如下:
其中,矩阵 和
右雅可比矩阵
尽管在虚拟惯性测量生成和流形传播中引入了一些新项,但增加的计算时间相对较短。一些项可以离线完成,如矩阵 和 ,而其他项(例如 和 )的计算复杂度为 ,其中
实验效果
总结一下
本文介绍了一种多IMU的快速外参标定方法。首先估计相对姿态,然后通过引入VIMU方法提高相对平移精度。验证表明,该方法具有快速、精确、鲁棒的特点,并且不依赖于真实轨迹、外部传感器以及在线噪声估计。给出了VIMU方法的通用形式,并提出了其在流形上的传播。实验结果表明,标定方法能够提高VIO系统的定位精度。
.....
#RoboTwin
结合现实与合成数据的双臂机器人基准
在机器人技术不断演进的当下,复杂自主系统的开发是行业追求的目标之一。双臂协调能力使得机器人能够像人类一样,利用双臂完成更为复杂和精细的操作。 例如在装配任务中,双臂机器人可以同时握住不同的零件,并将它们精确地组装在一起,这是单臂机器人难以实现的。先进工具使用能力则进一步拓展了机器人的功能。机器人可以根据任务需求,选择并使用合适的工具,如使用螺丝刀拧紧螺丝、使用钳子夹取物品等。这种能力与双臂协调相结合,能够让机器人在面对各种复杂任务时,具备更强的适应性和操作能力,从而更好地实现自主系统的复杂功能。**然而,这些领域的进步受到缺乏专门的、高质量的训练数据的严重阻碍。**这些活动往往需要定制的解决方案,难以标准化,并且在传统数据集中通常没有很好的体现。
,时长02:01
图注:Astribot S1机器人双臂协同操作展示。视频来源:https://www.bilibili.com/video/BV1yJ4m1H7V2/?vd_source=60762b2741beebb14f0eaac7c46cc65f
2024 ECCV 中,xx智能的协同智能WORKSHOP (WORKSHOP ON COOPERATIVE INTELLGENCE FOR EMBODIED AI) 最佳论文旨在解决这一关键差距,引入了 "RoboTwin" 。它是一个综合基准,包括现实世界的遥控操作数据和由数字孪生生成的相应合成数据,专门用于涉及双臂机器人工具使用和人机交互的场景。
- 首先使用 AgileX Robotics 开发的开源 COBOT Magic 平台收集数据,该平台配备了四个 AgileX Arms 和四个 Intel Realsense D - 435 RGBD 摄像头,安装在坚固的 Tracer 底盘上,数据涵盖工具使用和人机交互等各种典型任务。
- 从现实世界数据收集到虚拟复制的过程中,创建数字孪生面临挑战。**传统方法依赖昂贵的高保真传感器,本文开发了一种使用人工智能生成内容(AIGC),从单个 2D RGB 图像构建 3D 模型的经济有效的新方法。**该方法能降低成本,提供逼真的视觉效果并支持物理模拟,包括将 2D 图像转换为具有复杂几何形状等的 3D 模型,还通过定义功能坐标轴来增强模型以实现抓取姿态的自动计算。
- 为增强数据集的实用性和相关性,建立了一个利用大型语言模型(LLMs)自动生成专家级训练数据。该方法丰富了数据集,还整合了 LLMs 的多功能性,如利用 GPT4 - V 自动生成任务特定的姿态序列以提高任务执行精度,使用 GPT4 生成的脚本来激活轨迹规划工具以简化编程和加快机器人系统部署。
那么,文章是如何创建数字孪生 (将物理实体或系统的各种特性和行为以数字化的形式进行精确模拟和映射)**的呢?**文章基于 Deemos's Rodin 平台,从单个 2D RGB 图像构建 3D 模型,过程如下:首先将单张 2D 图像转换为包含详细几何形状、表面法线、线框和纹理的 3D 模型。这些特征增强了视觉真实感,并确保与物理模拟的引擎兼容。然后为模型内物体的功能部件指定特定坐标轴。例如对于锤子,一个轴与锤头(功能部分)对齐,另一个轴指示接近方向。抓取姿态沿着指定的接近方向轴垂直于功能部分的表面法线计算,这有助于机器人在操作和使用工具时能以最少的人工干预正确且高效地进行。
为了生成专家数据,首先借助 GPT4 - V 的推理能力编写代码,用于计算关键姿态和物体功能坐标轴之间的关系。GPT4 - V 会分析任务要求并生成符合要求的一系列姿态,确保任务的精确执行。然后通过 GPT4 生成的代码来调用轨迹规划工具,这些代码是基于计算出的姿态生成的。这种自动化操作大幅减少了手动编程所需的时间和人力,有助于机器人系统在不同应用中的快速部署,同时也为机器人学习提供了一种可扩展的高质量数据生成方法。
为了进一步推动该领域的研究和发展,如图 4 所示,**文章引入了一个综合基准,专门用于评估各种场景下的双臂机器人。**这个基准包含了一系列多样的任务,每个任务都呈现出独特的挑战,这些挑战对于评估模拟环境中机器人手臂的灵巧性、协调性和操作效率至关重要,任务范围从简单的物体操作到需要双臂同步运动的复杂协调动作。个基准旨在弥合理论机器人控制模型与其实际应用之间的差距,确保机器人系统能够在动态的现实世界环境中可靠地运行。
为了获取真实世界的数据,文章采用了AgileX Robotics公司的开源Cobot Magic 7平台,该平台配备了4个AgileX arm和4个英特尔Realsense D-435 RGBD摄像头,并建立在Tracer底盘上。这些摄像头一个在支架的高处,以扩大视野,两个在机器人手臂的手腕上,一个在支架的低处,这是可选的。前、左、右摄像头以30Hz的频率同时捕获数据,如图5所示。
文章的数据集任务设计有两个主要亮点:关注人机交互和工具使用。文章设计了17个任务,其中9个任务强调工具使用,5个任务涉及人际互动,6个任务是双臂,每个任务收集了30个轨迹。
文章的实验旨在验证:a) COBOT Magic平台设置的合理性,b)自动生成的专家数据的有效性。文章使用3D Diffusion Policy (DP3)在基准内测试了6个任务,每个任务分别使用从10组、20组和50组专家数据中训练的策略进行测试,以获得成功率。实验结果如表1所示,所有任务的成功率皆随着演示次数的提升而大幅增加。 "Block Handover"任务取得了最显著的改进,在50次演示中达到98%的成功率,远高于10次的50%。这些结果表明,专家演示的数量与任务成功之间存在很强的相关性,突出了自动生成的专家数据在提高COBOT Magic平台上的任务性能方面的有效性。这些数据进一步强调了为复杂任务制定稳健策略时,充分的训练示例的重要性。
总结
- 这篇文章引入了 RoboTwin,它是一个整合了现实世界和合成数据的基准,用于评估双臂机器人,解决了机器人领域专业训练数据严重短缺的问题。
- 数据集是使用 AgileX Robotics 平台开发的,并通过由 Deemos's Rodin 平台提供支持的生成式数字孪生进行了增强。文章建立了一个便捷的从现实到模拟的管道,只需一张现实世界的 RGB 图像就能生成目标物体和相应场景的 3D 模型。该数据集有效加速了机器人系统的训练,能够使机器人在不同任务中的性能得到提升。
- 研究结果展示了这种混合数据方法在提高机器人灵巧性和效率方面的潜力,它是一个可扩展的工具,可能会给机器人研究和应用带来革命性的变化。
......
#大模型/Sora/世界模型之间是什么关系,对自动驾驶的意义是什么?
什么是大模型
人工智能大模型(Artificial Intelligence Large Model,简称AI大模型)是指具有庞大的参数规模和复杂程度的机器学习模型。通常指的是参数量非常大、数据量非常大的深度学习模型。
大模型通常由数百万到数十亿的参数组成,需要大量的数据和计算资源进行训练和推理。
由于其巨大的规模,大模型具有非常强大的表示能力和泛化能力,可以在各种任务中表现出色,如语音识别、自然语言处理、计算机视觉等。
1.1 大模型的优点
1)强大的表示能力
大模型可以学习非常复杂的模式和特征,从而能够处理各种复杂的任务。
2)泛化能力强
由于大模型在大量数据上进行训练,它们可以捕捉到普遍存在的模式,因此在处理新数据时具有较好的泛化能力。
3)多任务学习
一些大模型可以同时处理多个任务,例如图像分类和目标检测,或者自然语言处理中的文本分类和情感分析。
4)预训练和迁移学习
大模型可以在大规模数据上进行预训练,然后在其他数据集上进行微调,以适应特定的任务。这种迁移学习的方法可以大大减少在新任务上的训练时间和数据需求。
通过在大量的标注和未标注的数据上进行预训练,大模型可以从中捕获通用的知识和特征,并将其存储在参数中。
然后通过对特定任务进行微调,大模型可以将预训练的知识迁移到下游任务中,极大地提高了模型的性能和泛化能力。
1.2 大模型的应用
大模型的典型代表有GPT-4、盘古、Switch Transformer等,它们的参数量都达到了千亿甚至万亿的规模。
除此之外,还有代码大模型、视觉大模型、多模态大模型等。
1)语言模型
语言模型是一种自然语言处理领域的深度学习模型,通过语言模型的应用,可以实现机器翻译、文本摘要、问答系统、情感分析等功能。
例如,谷歌的BERT模型可以用于提高搜索引擎的搜索质量和广告质量;OpenAI的GPT系列模型可以用于自动生成文章、对话和摘要等。
2)图像识别模型
图像识别模型是一种计算机视觉领域的深度学习模型,可以用于图像分类、目标检测、人脸识别等任务。
例如,在医疗领域,图像识别模型可以用于诊断疾病和辅助手术;在安防领域,图像识别模型可以用于监控和人脸识别等。
3)语音识别模型
语音识别模型是一种语音信号处理领域的深度学习模型,可以将语音转换成文本,并支持语音到文本的转换、语音搜索、语音控制等功能。
例如,谷歌助手、苹果的Siri、亚马逊的Alexa等智能助手都使用了语音识别技术。
4)推荐模型
推荐模型是一种个性化推荐领域的深度学习模型,可以根据用户的历史行为和偏好,推荐相关的内容和服务。
例如,在电商领域,推荐模型可以根据用户的购物历史和浏览行为,推荐相关的商品和优惠券;在新闻领域,推荐模型可以根据用户的阅读历史和兴趣,推荐相关的新闻和文章。
5)强化学习模型
强化学习模型是一种通过试错来学习行为的深度学习模型,可以用于游戏、自动驾驶等领域。
例如,DeepMind的AlphaGo可以用于玩围棋游戏;OpenAI的Dota2 AI可以用于玩Dota2游戏。
什么是world model
与大模型相比,世界模型是一个更高级别的概念,它涉及到xx智能和现实世界的感知、理解和交互。世界模型试图通过对周围环境进行建模,使人工智能系统能够像人类一样理解和预测环境,从而做出相应的行动。
World Model其本质是对视频中的丰富语义以及背后的物理规律进行学习,从而对物理世界的演化产生深刻理解。
举个例子,在人类的理解中,能够评估出一杯水的重量。当我们拿起一杯水时,大脑其实已经"预测"了应该用多大的力。于是,杯子被顺利拿起。但如果杯子是不透明有盖的而碰巧没有水呢?如果延续杯子有水的理解,我们就会用过大的力去拿杯子,此时发现很轻,我们立刻感觉到不对。对世界的理解里就会加上这么一条:杯子有可能是空的。于是,下次再"预测",就会对不同内容的杯子使用不同的力。
"不断理解,不断预测",这种理解世界的方式,是人类理解世界的方式。这种思维模式就叫做:世界模型。
人经历的事情越多,大脑里就会形成越复杂的世界模型,用于更准确地预测这个世界。这就是人类与世界交互的方式:世界模型。
什么是Sora
OpenAI官方信息从未表示Sora是world model,而是强调它是world simulator。
Sora,美国人工智能研究公司OpenAI发布的人工智能文生视频大模型(但OpenAI并未单纯将其视为视频模型,而是作为"世界模拟器"),于2024年2月15日(美国当地时间)正式对外发布。
Sora可以根据用户的文本提示创建最长60秒的逼真视频,该模型了解这些物体在物理世界中的存在方式,可以深度模拟真实物理世界,能生成具有多个角色、包含特定运动的复杂场景。
Sora有别于其他AI视频模型的优势在于,既能准确呈现细节,又能理解物体在物理世界中的存在,并生成具有丰富情感的角色,甚至该模型还可以根据提示、静止图像甚至填补现有视频中的缺失帧来生成视频。
在原理上,Sora主要通过三个步骤实现视频训练。首先是视频压缩网络,将视频或图片降维成紧凑而高效的形式。其次是时空补丁提取,将视图信息分解成更小的单元,每个单元都包含了视图中一部分的空间和时间信息,以便Sora在后续步骤中进行有针对性的处理。最后是视频生成,通过输入文本或图片进行解码加码,由Transformer模型(即ChatGPT基础转换器)决定如何将这些单元转换或组合,从而形成完整的视频内容。
3.1 Sora的应用
- 视频创作:用户可以根据文本生成高质量视频;
- 扩展视频:可以在给定的视频或图片基础上,继续向前或向后延申视频;
- Video-to-video editing:例如将SDEdit 应用于Sora,可以很容易改变原视频的风格;
- 视频连结/过渡/转场:可以将两个视频巧妙地融合到一起,使用Sora在两个输入视频之间逐渐进行插值,从而在具有完全不同主题和场景构成的视频之间创建无缝过渡;
- 文生图:图像可以视为单帧的视频,故Sora也能实现文生图。
3.2 目前Sora存在的缺点
尽管Sora的功能十分的强大,但其在模拟复杂场景的物理现象、理解特定因果关系、处理空间细节、以及准确描述随时间变化的事件方面OpenAI Sora都存在一定的问题。
(1)物理交互的不准确模拟:
Sora模型在模拟基本物理交互,如玻璃破碎等方面,不够精确。这可能是因为模型在训练数据中缺乏足够的这类物理事件的示例,或者模型无法充分学习和理解这些复杂物理过程的底层原理。
(2)对象状态变化的不正确:
在模拟如吃食物这类涉及对象状态显著变化的交互时,Sora可能无法始终正确反映出变化。这表明模型可能在理解和预测对象状态变化的动态过程方面存在局限。
(3)长时视频样本的不连贯性:
在生成长时间的视频样本时,Sora可能会产生不连贯的情节或细节,这可能是由于模型难以在长时间跨度内保持上下文的一致性。
(4)对象的突然出现:
视频中可能会出现对象的无缘无故出现,这表明模型在空间和时间连续性的理解上还有待提高。
world model是用Sora能准确生成视频一个很重要的核心,比如人在苹果上咬了一口,并不总是能"咬就会有痕",sora"有时"也会出错。但通过训练,sora会越来越准确。
Sora的技术文档里有一句话:
Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
翻译过来就是:
我们的结果表明,大规模视频生成模型是一条很有希望构建物理世界通用模拟器的道路。
OpenAI最终想做的,其实不是一个"文生视频"的工具,而是一个通用的"物理世界模拟器"。
大模型 Sora和世界模型对自动驾驶的意义
基于World Model所提供的丰富语义信息以及对世界强大的理解力,自动驾驶模型的感知与预测能力有望得到显著提升,规划、控制等下游任务也有望迎刃而解。
类比GPT为所有NLP问题提供了一个通用解,特斯拉、Wayve等公司不约而同地在2023年推出World Model,很大程度上是受到了GPT的启发。对于自动驾驶来说,World Model 是一个无需标注、自监督的预训练模型。可生成自动驾驶相关的连续帧视频场景。
目前,World Model或仍处于GPT-1的阶段,但考虑到目前行业整体对"大模型"潜力的强烈共识、算力的升级以及以特斯拉为代表的玩家此前积累的海量数据,World Model从0到1的爆发或较ChatGPT更快(OpenAI从GPT-1至GPT-3.5共历经4年)。
但考虑到更标准化的解决方案和更巨大的资金投入(资金需求或是这一代BEV+Transformer方案的数倍),行业内有望出现少数几家强大的World Model基础模型层平台方,以SaaS或API的方式为主机厂/运营方提供自动驾驶能力,行业格局和合作模式或将发生较大变化。
中短期来看,World Model或将主要应用于数据合成和仿真模拟环节,厂商的车队规模对算法训练的重要性或有所下降,数据闭环的框架也将有所改变。
长期来看,World Model有潜力成为自动驾驶乃至xx智能领域的基础模型。
......
#DINO-WM
提升56%!纽约大学:预训练世界模型实现零样本规划
给定控制动作预测未来结果的能力是物理推理的基础。然而,这类预测模型(通常称为世界模型)的学习已被证明具有挑战性,并且通常是为具有在线策略学习的特定任务解决方案而开发的。我们认为,世界模型的真正潜力在于它们仅使用被动数据就能在不同问题上进行推理和规划的能力。具体来说,要求世界模型具备以下三个特性:1)能够在离线的、预先收集的轨迹上进行训练;2)支持测试时的行为优化;3)促进与任务无关的推理。为了实现这一目标,我们提出了DINO世界模型(DINO-WM),这是一种无需重建视觉世界即可建模视觉动力学的新方法。DINO-WM利用DINOv2预训练的空间block特征,使其能够通过预测未来的块特征来从离线的行为轨迹中学习。这种设计使DINO-WM能够通过动作序列优化来实现观测目标,通过将期望的目标块特征作为预测目标,来促进与任务无关的行为规划。在迷宫导航、桌面推动和粒子操控等多个领域对DINO-WM进行了评估。实验表明,DINO-WM能够在测试时生成零样本行为解决方案,而无需依赖专家演示、奖励建模或预先学习的逆模型。值得注意的是,与先前的最先进工作相比,DINO-WM展现出强大的泛化能力,能够适应各种任务族,如任意配置的迷宫、具有不同形状物体的推动操控以及多粒子场景。
一些介绍
近年来,机器人技术和xx人工智能(embodied AI)取得了巨大进展。模仿学习和强化学习的进步使智能体能够在各种任务中学习复杂行为。尽管取得了这些进展,但泛化仍然是一个主要挑战。现有方法主要依赖于一旦训练完成,在部署过程中以前馈方式运行的策略------即将观测结果映射到动作上,而不进行任何进一步的优化或推理。在这一框架下,要实现成功的泛化,本质上要求智能体在训练完成后具备解决所有可能任务和场景的能力,而这只有在智能体在训练期间见过类似场景的情况下才可能实现。然而,提前学习所有潜在任务和环境的解决方案既不可行也不高效。
与在训练期间学习所有可能任务的解决方案不同,另一种方法是使用训练数据拟合一个动力学模型,并在运行时优化特定任务的行为。这些动力学模型也被称为世界模型,在机器人技术和控制领域有着悠久的历史。最近,一些研究表明,可以使用原始观测数据训练世界模型。这使得能够灵活地使用基于模型的优化来获得策略,因为它避免了显式状态估计的需求。尽管如此,在使用世界模型解决通用任务方面仍然存在重大挑战。
为了理解世界建模中的挑战,让我们考虑学习世界模型的两种主要范式:在线和离线。在在线设置中,通常需要访问环境,以便可以持续收集数据来改进世界模型,进而改进策略以及后续的数据收集。然而,在线世界模型仅在所优化策略覆盖的范围内准确。因此,虽然它可用于训练强大的特定任务策略,但即使在同一环境中,对于每个新任务都需要重新训练。相比之下,在离线设置中,世界模型是在环境中收集的轨迹的离线数据集上进行训练的,这消除了其对任务特定性的依赖,前提是数据集具有足够的覆盖范围。然而,当需要解决任务时,该领域的方法需要强大的辅助信息来克服任务特定域缺乏密集覆盖的问题。这种辅助信息可以是专家演示,结构化关键点,访问预训练的逆模型或密集奖励函数,所有这些都会降低离线世界模型的通用性。构建更好离线世界模型的核心问题是,是否存在不损害其通用性的替代辅助信息?
我们提出了DINO-WM,这是一种新的且简单的方法,用于从轨迹的离线数据集中构建与任务无关的世界模型。DINO-WM在世界紧凑嵌入(而非原始观测本身)上建模世界的动力学。对于嵌入,我们使用DINOv2模型的预训练patch特征,它提供了空间和以对象为中心的表示先验。我们推测,这种预训练表示能够实现稳健且一致的世界建模,从而降低了对任务特定数据覆盖的必要性。给定这些视觉嵌入和动作,DINO-WM使用ViT架构来预测未来嵌入。一旦该模型训练完成,规划解决任务就构建为视觉目标到达,即根据当前观测到达未来期望的目标。由于DINO-WM的预测质量很高,可以在测试时仅使用带有推理时间优化的模型预测控制来达到期望目标,而无需任何额外信息。
DINO-WM在涵盖迷宫导航、滑动操作和粒子操作任务的四个环境套件上进行了实验评估。我们的实验得出了以下发现:
- DINO-WM能够生成高质量的未来世界模型,这可以通过训练后的解码器改进的视觉重建来衡量。在最困难的任务的LPIPS指标上,这比先前最先进的工作提高了56%。
- 利用DINO-WM训练的潜在世界模型,在最困难的任务上实现了任意目标的高达成率,平均比先前的工作提高了45%。
- DINO-WM可以在任务家族内的不同环境变体(例如,导航中的不同迷宫布局或操作中的不同物体形状)上进行训练,并且与先前的工作相比,实现了更高的成功率。
DINO-WM的代码和模型将开源,以确保可重复性,代码:https://dino-wm.github.io。
相关工作一览
在构建世界模型、优化它们以及使用紧凑的视觉表示方面,基于多项工作进行了拓展。为了简洁起见,只讨论与DINO-WM最相关的工作。
基于模型的学习:从动力学模型中学习有着丰富的文献,跨越控制、规划和机器人学等领域。近期研究表明,对动力学进行建模并预测未来状态可以显著增强xxagent在各种应用中的基于视觉的学习,包括在线强化学习,探索,规划,以及模仿学习。其中一些方法最初侧重于状态空间动力学,并且此后已扩展到处理基于图像的输入,这也是本工作的重点。这些世界模型可以在像素空间或潜在表示空间中预测未来状态。然而,在像素空间中进行预测由于需要图像重建和使用扩散模型的开销,计算成本高昂。另一方面,潜在空间预测通常与重建图像的目标相关联,这引发了关于所学特征是否包含足够任务信息的担忧。此外,许多这些模型还包含奖励预测,或将奖励预测作为辅助目标来学习潜在表示,这本质上使世界模型变得与任务相关。在本工作中,我们旨在将任务相关信息与潜在空间预测解耦,努力开发一个灵活且任务无关的世界模型,能够在不同场景中进行泛化。
生成模型作为世界模型:随着近期大规模基础模型的兴起,在自动驾驶领域、控制领域以及通用视频生成领域,已经出现了构建以智能体动作为条件的大规模视频生成世界模型的尝试。这些模型旨在根据文本或高级动作序列生成视频预测。虽然这些模型在数据增强等下游任务中表现出了实用性,但当需要实现精确的视觉指示性目标时,它们对语言条件的依赖限制了其应用。此外,使用扩散模型进行视频生成会使计算成本高昂,进一步限制了它们在模型预测控制(MPC)等测试时优化技术中的应用。本工作旨在构建潜在空间中的世界模型,而不是原始像素空间中的模型,从而实现更精确的规划和控制。
预训练视觉表示:在视觉表示学习领域取得了显著进展,可以轻松地使用捕获空间和语义信息的紧凑特征来完成下游任务。预训练模型,如针对图像的ImageNet预训练ResNet、I-JEPA和DINO,以及针对视频的V-JEPA,还有针对机器人的R3M和MVP,因为它们包含丰富的空间和语义信息,能够快速适应下游任务。虽然其中许多模型使用单个全局特征来表示图像,但视觉Transformer(ViT)的引入使得可以使用预训练的补丁特征,如DINO所示。DINO采用自蒸馏损失,使模型能够有效地学习表示,捕捉语义布局并改善图像内的空间理解。本工作我们利用DINOv2的patch嵌入来训练我们的世界模型,并证明了它作为一种通用编码器,能够处理多个精确任务。
DINO世界模型
概述与问题定义:工作遵循基于视觉的控制任务框架,该框架将环境建模为部分可观察的马尔可夫决策过程(POMDP)。POMDP由元组(O, A, p)定义,其中O表示观测空间,A表示动作空间。环境的动态由转移分布建模,该分布基于过去的动作和观测来预测未来的观测。
本工作的目标是从预先收集的离线数据集中学习任务无关的世界模型,并在测试时间使用这些世界模型进行视觉推理和控制。在测试时间,系统从任意环境状态开始,并被提供一张RGB图像形式的目标观测,这与先前的工作保持一致。系统被要求执行一系列动作,以便达到目标状态。这种方法与在线强化学习(RL)中使用的世界模型不同,后者的目标是优化手头固定任务集的奖励,也与通过文本提示指定目标的文本条件世界模型不同。
1)基于DINO的世界模型(DINO-WM)
在潜在空间中建模环境的动态。更具体地说,在每个时间步t,我们的世界模型包含以下组件:
其中,观测模型将图像观测编码为潜在状态,而转移模型则接收长度为H的过去潜在状态的历史记录。解码器模型接收一个潜在状态,并重构图像观测。我们用θ来表示这些模型的参数。请注意,解码器是完全可选的,因为解码器的训练目标与训练世界模型的其他部分无关。这消除了在训练和测试期间都需要重构图像的需求,与Hafner等人(2024)和Micheli等人(2023)中将观测模型的训练和解码器的训练耦合在一起相比,这降低了计算成本。
DINO-WM仅对环境中从离线轨迹数据中可获得的信息进行建模,这与最近的在线RL世界模型不同,后者还需要任务相关信息,如奖励Hansen等人、Hafner等人,折扣因子Hafner等人、Robine等人,以及终止条件Hafner等人(2024)、Micheli等人(2023)。
观测模型
我们的目标是学习一个适用于多种环境和现实世界的通用世界模型,我们认为观测模型应该,1)与任务和环境无关,2)包含丰富的空间信息,这对于导航和操作任务至关重要。与以往总是为当前任务学习观测模型的工作不同,我们认为,面对新环境时,世界模型不可能总是从零开始学习观测模型,因为感知是一个可以从大量互联网数据中学习的通用任务。因此,我们选择现成的预训练DINOv2模型作为我们世界模型的观测模型,因为它在需要深刻理解空间的目标检测、语义分割和深度估计任务中表现出色。在训练和测试期间,观测模型都保持不变。在每个时间步t,它将图像编码为block嵌入,其中N表示块的数量,E表示嵌入维度。该过程如图2所示。
转移模型
我们为转移模型采用了ViT架构,因为它是处理block特征的自然选择。然而,需要对架构进行一些修改,以便对本体感受和控制器动作进行额外的条件控制。
我们的转移模型接收过去潜在状态和动作的历史记录,其中H是表示模型上下文长度的超参数,并预测下一个时间步的潜在状态。为了正确捕获时间依赖性,即时间t处的世界状态应仅依赖于之前的观测和动作,我们在ViT模型中实现了因果注意力机制,使模型能够在帧级别上自回归地预测潜在状态。对于潜在状态的每个block向量,它关注于。这与过去的工作IRIS不同,后者同样将每个观测表示为向量序列,但在标记级别上自回归地预测,同时关注于以及\[z\^i_t\]\^\
为了模拟agent动作对环境的影响,将世界模型的预测建立在这些动作的基础上。将从原始动作表示使用多层感知器(MLP)映射得到的K维动作向量与每个块向量(对于i = 1, ..., N)进行拼接。当本体感受信息可用时,同样通过将其与观测潜在状态进行拼接来整合它,从而将其纳入潜在状态。
我们使用教师强制(teacher forcing)方法训练世界模型。在训练过程中,将轨迹切分为长度为H + 1的片段,并在每个预测的H帧上计算潜在一致性损失。对于每一帧,我们计算:
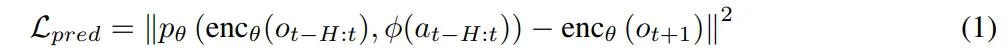
其中,ϕ是动作编码器模型,能够将动作映射到更高维度。请注意,我们的世界模型训练完全在潜在空间中进行,无需重建原始像素图像。
用于可解释性的解码器
为了辅助可视化和可解释性,我们使用转置卷积层的堆叠来将block表示解码回图像像素,这与Razavi等人(2019)的方法类似。给定一个预先收集的数据集,通过一个简单的重建损失来优化解码器θ的参数θ,该损失定义为:
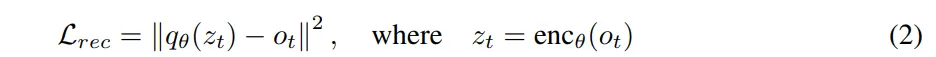
解码器的训练与转移模型的训练完全独立,这带来了几个优势:1)解码器的质量不会影响世界模型在解决下游任务时的推理和规划能力;2)在规划过程中,无需重建原始像素图像,从而降低了计算成本。尽管如此,解码器仍然具有价值,因为它提高了世界模型预测的可解释性。
2)使用DINO-WM进行视觉规划
可以说,为了评估世界模型的质量,它需要能够支持下游的推理和规划。一个标准的评估指标是在测试时间使用这些世界模型进行轨迹优化并测量性能。虽然规划方法本身相当标准,但它作为强调世界模型质量的一种方式。为此,我们的世界模型接收当前观测值和目标观测值,两者均以RGB图像表示。我们将规划定义为寻找一系列动作的过程,这些动作是agent为到达将采取的。为了实现这一点,采用了模型预测控制(MPC),它通过考虑未来动作的结果来促进规划。
我们利用交叉熵方法(CEM),一种随机优化算法,来优化每次迭代中的动作序列。规划成本定义为当前潜在状态与目标潜在状态之间的均方误差(MSE)。
实验对比
我们的实验旨在解决以下关键问题:1)是否可以使用预先收集的离线数据集有效地训练DINO-WM?2)一旦训练完成,DINO-WM是否可用于视觉规划?3)世界模型的质量在多大程度上依赖于预训练的视觉表示?4)DINO-WM是否适用于新的配置,例如空间布局和物体排列的变化?为了回答这些问题,在五个环境套件中训练和评估了DINO-WM,并将其与多种最先进的在潜在空间和原始像素空间中建模世界的世界模型进行了比较。
1)环境和任务
在我们的评估中,考虑了五个环境套件,涵盖了从简单的导航环境到具有不同动力学复杂性的操作环境。对于所有环境,观测空间均为大小为(224, 224)的RGB图像。
a) Point Maze:D4RL套件中的简单二维点迷宫导航环境。具有二维动作空间的点agent在U形迷宫中移动。agent的动力学结合了速度、加速度和惯性等物理属性,使移动更加真实。任务的目标是导航迷宫,从任意起始位置到达任意目标位置。
b) Push-T:环境中有一个推动者agent与T形块进行交互。目标是在25步内将agent和T形块从随机初始状态引导到已知的可行目标配置。任务要求agent和T形块都匹配目标位置。与之前的设置不同,固定的绿色T形块不再表示T形块的目标位置,而仅作为视觉参考锚点。成功完成任务需要对agent和物体之间丰富的接触动力学有精确的理解,这对视觉运动控制和物体操作构成了挑战。我们还引入了一个变体,其中存在多种物体形状。
c) Wall:此自定义二维导航环境包含两个由带门的墙隔开的房间。任务要求agent从一个房间的随机起始位置导航到另一个房间的目标位置,这需要agent穿过门。我们引入了一个环境变体,其中墙和门的位置是随机的,以评估模型对熟悉环境动力学的新配置的泛化能力。
d) Rope Manipulation:此任务使用Nvidia Flex模拟,包含一个XArm与放置在桌面上的绳子进行交互。目标是将绳子从任意起始配置移动到指定的目标配置。
e) Granular Manipulation:颗粒操作使用与绳子操作相同的设置,并操作约一百个颗粒以形成所需的形状。
2)基线(模型/方法)
将DINO-WM与以下常用于控制的最新模型进行了比较:
a) IRIS:IRIS使用离散自动编码器将视觉输入转换为标记(token),并使用GPT Transformer预测未来观测的标记。它结合这些组件,通过想象过程来学习策略和值函数。
b) DreamerV3:DreamerV3学习一个世界模型,将视觉输入解释为分类表示。它基于给定的动作预测未来的表示和奖励,并从其想象的轨迹中训练一个行动者-评论家策略。
c) TD-MPC2:TD-MPC2在潜在空间中学习一个无需解码器的世界模型,并使用奖励信号来优化潜在变量。它是无重建世界建模的强大基线。
d) AVDC:AVDC利用扩散模型根据初始观测和文本目标描述生成任务执行的想象视频。然后,它估计帧之间的光流以捕捉物体运动,并生成机械臂指令。
3)使用DINO-WM优化行为
使用一个训练好的世界模型,我们研究DINO-WM是否可以直接在潜在空间中进行零样本规划。对于PointMaze、Push-T和Wall环境,采样了50个初始状态和目标状态,以测量所有实例的成功率。由于Rope和Granular环境的步长时间因素,在这两个环境中对10个实例评估了Chamfer距离(CD)。在Granular环境中,从验证集中随机采样一个配置,目标是将材料推入一个随机选定位置和大小的方形形状。
如表1所示,在Wall和PointMaze等较简单的环境中,DINO-WM的表现与最先进的世界模型(如DreamerV3)相当。然而,在需要准确推断丰富的接触信息和物体动力学以完成任务的操作环境中,DINO-WM显著优于先前的工作。我们注意到,对于TD-MPC2而言,缺乏奖励信号使其难以学习良好的潜在表示,进而导致性能不佳。一些规划结果的可视化图像可见于图5。
4)预训练视觉表征是否重要?
使用不同的预训练通用编码器作为世界模型的观测模型,并评估它们在下游规划任务中的性能。具体来说,我们使用了以下在机器人控制和一般感知中常用的编码器:R3M、在ImageNet上预训练的ResNet-18以及DINO CLS。
在PointMaze任务中,该任务涉及简单的动力学和控制,观察到使用各种观测编码器的世界模型都实现了接近完美的成功率。然而,随着环境复杂性的增加,需要更精确的控制和空间理解,那些将观测编码为单个潜在向量的世界模型在性能上出现了显著下降。我们认为,与将观测简化为单个全局特征向量的R3M、ResNet和DINO CLS等模型相比,基于patch的表示方法能更好地捕捉空间信息,避免了在操纵任务中丢失至关重要的空间细节。
5)推广到新的环境配置
我们希望能够衡量我们的世界模型不仅在环境中的不同目标之间具有泛化能力,而且在不同的环境本身之间也具有泛化能力。为此,我们构建了三个环境系列,其中世界模型将在未见过的环境中针对未见过的目标进行部署。我们的环境系列包括WallRandom、PushObj和GranularRandom。训练和测试示例的可视化图像如图6所示。
从表3中,我们观察到DINO-WM在WallRandom环境中表现出显著更好的性能,这表明世界模型已经有效地学习了墙壁和门的一般概念,即使它们位于训练期间未见过的位置。相比之下,其他方法难以准确识别门的位置并通过它进行导航。
PushObj任务对所有方法来说仍然具有挑战性,因为模型仅针对四种物体形状进行了训练,这使得难以精确推断物理参数,如重心和惯性。在GranularRandom中,智能体遇到的粒子数量少于训练期间的一半,与训练实例相比,这导致了分布外的图像。尽管如此,DINO-WM仍然准确地编码了场景,并成功地将粒子聚集到指定的方形位置,与基线相比具有最低的Chamfer距离(CD),从而表现出更好的场景理解能力。我们假设这是因为DINO-WM的观测模型将场景编码为补丁特征,使得粒子数量的变化仍然在每个图像补丁的分布范围内。
6)与生成式视频模型的定性比较
鉴于生成式视频模型的显著地位,有理由推测它们可以轻易地作为世界模型使用。为了探究DINO-WM相较于此类视频生成模型的实用性,我们将其与基于扩散的生成模型AVDC的想象轨迹进行了比较。如图7所示,我们发现,在基准数据集上训练的扩散模型生成的未来图像在视觉上大多很逼真,但在物理上却不太合理,因为我们可以看到在单个预测时间步内会发生很大的变化,并且可能难以达到确切的目标状态。未来潜在上更强大的生成模型可能会缓解这一问题。
还将DINO-WM与AVDC的一个变体进行了比较,在该变体中,扩散模型被训练为根据当前观测值和动作生成下一个观测值,而不是根据文本目标一次性生成整个观测序列。
7)解码和解释潜在变量
尽管DINO-WM在潜在空间中运行,且观测模型并未以像素重建为目标进行训练,但训练一个解码器对于解释模型的预测仍然很有价值。我们评估了所有模型预测的未来图像的质量,并发现我们的方法优于其他方法,甚至优于那些其编码器以特定于环境的重建目标进行训练的方法。在图4中展示了开环轨迹的可视化结果。这证明了DINO-WM的鲁棒性,尽管它缺乏明确的像素级监督。这里报告了两个关键指标:世界模型预测未来状态重建的结构相似性指数(SSIM)和学习的感知图像patch相似性(LPIPS)。SSIM通过评估预测图像和真实图像之间的结构信息和亮度一致性来衡量图像的感知质量,值越高表示相似性越大。而LPIPS则通过比较图像的深度表示来评估感知相似性,分数越低表示视觉相似性越近。
......
#VL-SAM
完全无训练的开放式检测分割模型
本文介绍了北大研究团队提出的VL-SAM模型,这是一个完全无训练的开放式检测分割模型,通过结合视觉-语言模型和Segment-Anything模型,使用注意力图作为提示来解决开放式物体检测和分割任务,在长尾实例分割数据集和边缘案例物体检测数据集上表现出良好的性能。
论文: Training-Free Open-Ended Object Detection and Segmentation via Attention as Prompts
创新点
- 提出了一个无需训练框架
VL-SAM,将广义物体识别模型(即视觉-语言模型)与广义物体定位模型(即Segment-Anything模型)结合起来,以解决开放式物体检测和分割任务。 - 设计了一个注意力图生成模块,通过头聚合和正则化的注意力流来聚合
VLM中所有头和层的注意力图,从而生成高质量的注意力图。 - 设计了提示生成模块迭代地从注意力图中迭代地抽样正负点,并将抽样的点发送给
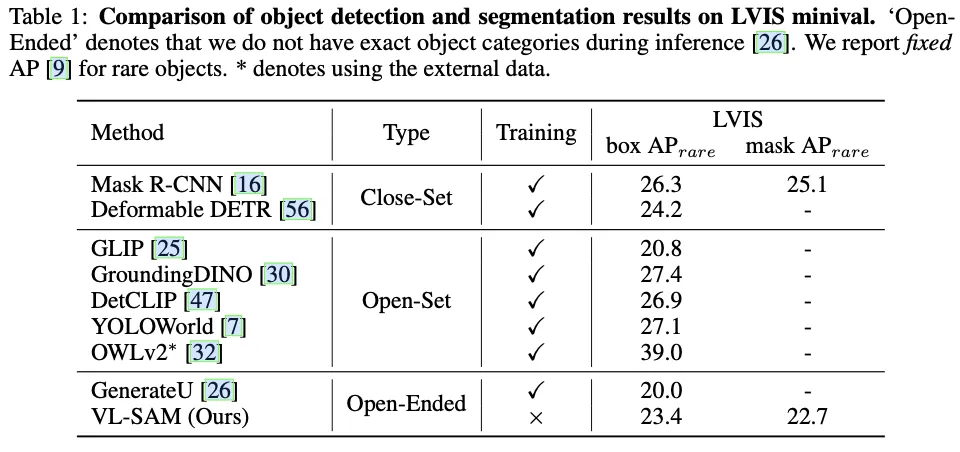
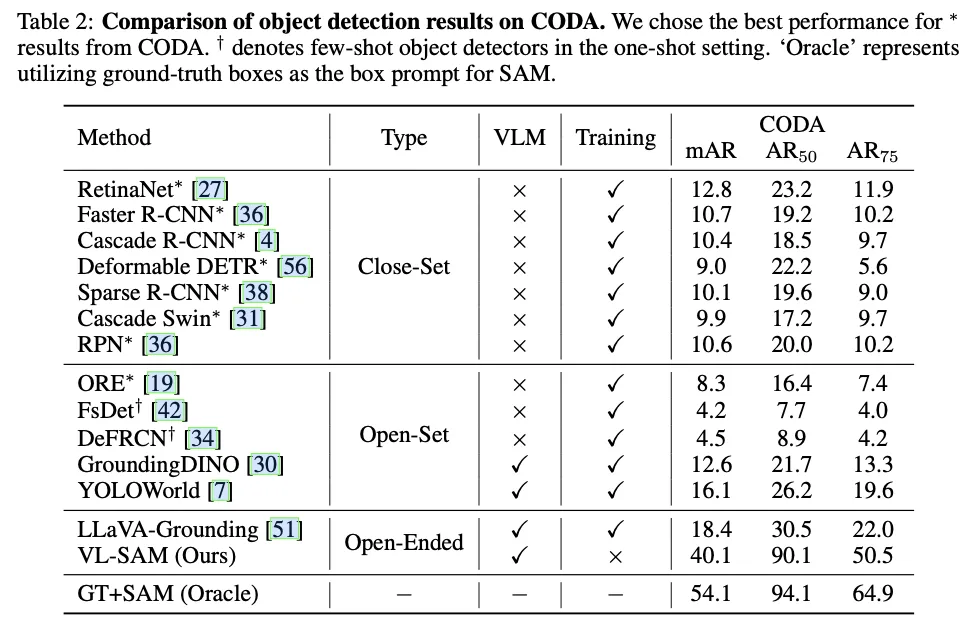
SAM以分割相应的物体。 VL-SAM在长尾实例分割数据集(LVIS)和边缘案例物体检测数据集(CODA)上也表现出了良好的性能,证明了VL-SAM在现实世界应用中的有效性。VL-SAM表现出良好的模型泛化能力,可以结合各种VLM和SAM。
内容概述
现有的基于深度学习的感知模型依赖于大量标注的训练数据来学习识别和定位物体。然而,训练数据无法覆盖现实世界场景中的所有类型的物体。当遇到分布外的物体时,现有的感知模型可能无法识别和定位物体,这可能导致严重的安全问题。
开放世界感知试图在动态和不可预测的环境中提供准确的结果,这些环境包含新颖的物体并涉及场景领域的转变。目前的开放世界感知方法大致可以分为两类:开放集和开放式。开放集方法通常使用预训练的CLIP模型计算图像区域与类别名称之间的相似性,但在推理过程中需要预定义的物体类别作为CLIP文本编码器的输入。开放式则利用大型视觉语言模型(VLMs)强大的泛化能力来识别物体,但VLM的定位能力不如特定的感知模型准确。
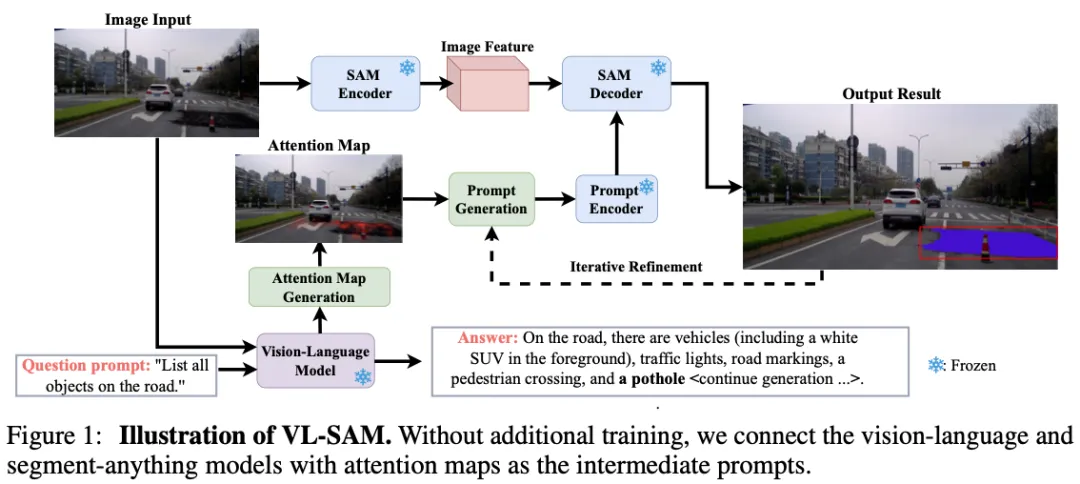
为此,论文提出了VL-SAM,将现有的通用物体识别模型VLM与通用物体定位模型SAM结合起来解决开放式物体检测和分割任务。这是一个无训练的框架,通过注意力图作为中间提示连接这两个通用模型。
给定一个图像输入,首先使用VLM描述场景并列出图像中所有可能的物体。然后,对于每个物体,利用带有头聚合和注意力流的注意力生成模块,从VLM获得高质量的注意力图。最后,从注意力图生成点提示,并将其迭代发送给SAM以获得位置预测。
VL-SAM
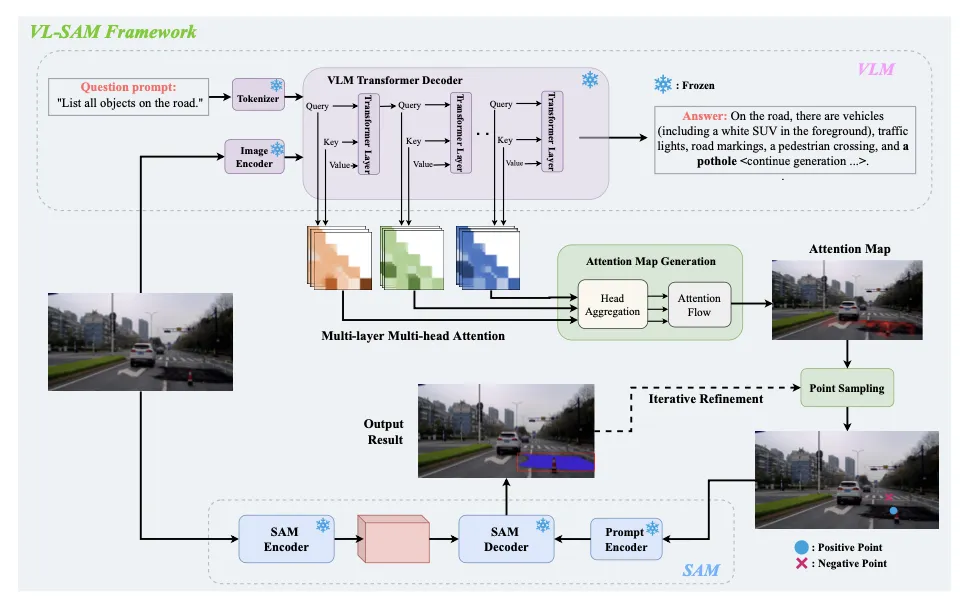
现有模型SAM模型
SAM是一个基于提示的分割模型,由三个组件组成:图像编码器、掩码解码器和提示编码器。SAM以图像和一组提示(包括点、框和掩码)作为输入,多尺度分割掩码。
基于自回归的VLM模型
基于自回归的VLM的主流框架由四个部分组成:图像编码器、文本分词器、投影层和语言解码器。给定图像和文本作为输入,采用下一个符号预测范式。
注意力生成模块
VL-SAM的主要思想是将物体的注意力图用作SAM的分割提示,如何为一个物体生成高质量的注意力图至关重要。
头聚合
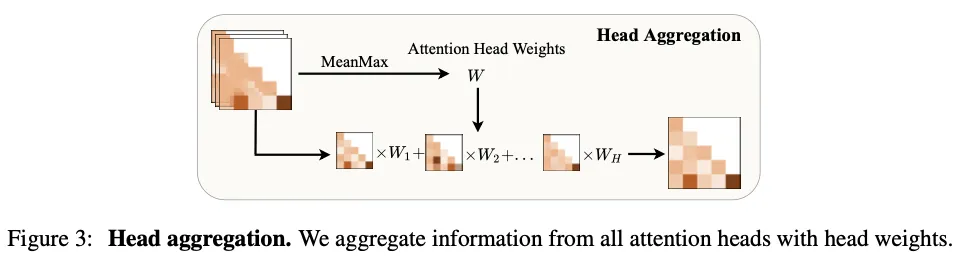
给定一幅图像输入,请求VLM提供图像中所有可能的物体。在这个过程中,缓存来自VLM的所有查询和键。
通过因果掩码和 SoftMax 归一化对查询和键进行相乘, 获得相似性矩阵 , 其中 是查询和键的长度, 是 Transformer 头的数量,
使用均值-最大注意力头权重从所有 Transformer 头中聚合信息, 即选择矩阵 在维度 上的最大相似性权重, 并在维度 上进行平均, 以获得权重 , 表明每个层中每个头的重要性:
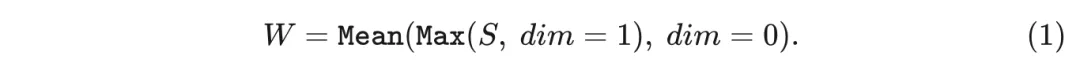
逐点乘以权重 和相似性矩阵
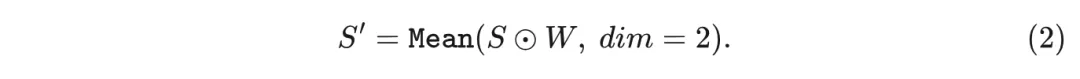
注意力流

注意力流用于以进一步聚合所有层的注意力, 使用注意力展开方法来计算从层 到层
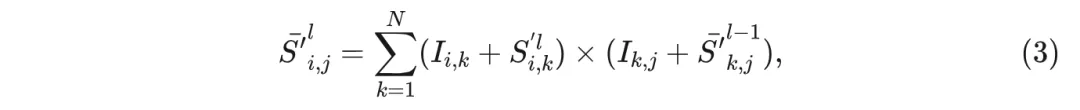
经过注意力展开后,只需要最后一层的注意力图。为了获得生成的token的图像注意力图,从中选择相应的行和列。

由于VLM使用因果掩码进行自回归生成,简单地采用注意力展开方法会导致注意力崩溃。
论文使用一个简单的正则化项来有效地缓解这个问题。对于每一列,假设未掩码的长度为 ,将该列中的每个值乘以
SAM提示生成器
前面产生的注意力图中存在一些不稳定的假阳性峰值。为了过滤这些假阳性区域,首先使用阈值来过滤弱激活区域,并找到最大连通区域作为正区域。剩余区域作为负区域。之后,从正区域中抽取一个具有最大激活值的正点,并从负区域中抽取一个具有最弱激活值的负点,作为SAM的点提示对。
迭代优化
SAM解码器的分割结果可能包含粗糙的边缘和背景噪声,采用两种迭代策略进一步优化分割结果。
- 遵循
PerSAM中的级联后优化,将使用正负对生成的初始分割掩码作为SAM解码器的额外提示输入。 - 使用第一种迭代策略中的分割掩码来过滤注意力图 。然后,从被过滤的注意力图中使用提示生成方法迭代生成正负对,并将它们发送到
SAM解码器,最后使用NMS汇总结果。
多尺度集成
由于 VLM 中图像编码器的低分辨率图像输入, VLM 可能无法识别小物体。为了解决这个问题,遵循 SPHINX 的方法,将图像( )从四个角落分割成四个子图像(
问题提示集成
VLM的输出对输入提示非常敏感。为了获得对输入图像更全面的描述,要求VLM生成十个用于场景描述的问题提示,然后,使用生成的问题提示来进行VL-SAM的物体分割,并对所有问题提示的输出进行集成。
主要实验
#STAR课题组诚邀访问学生
团队简介
STAR(Smart Autonomous Robotics)课题组属于中山大学人工智能学院,由周博宇老师指导。主要方向为空、地自主移动机器人运动规划、三维重建、移动操作、集群系统等。团队科研氛围浓厚,在机器人领域产出扎实丰富,近年来在TRO、RAL、ICRA、IROS等机器人领域顶级期刊和会议发表论文近三十篇,代表论文获得2024 IEEE TRO最佳论文奖,IEEE RAL最佳论文奖,ICRA无人机最佳论文题名等荣誉。在国际机器人顶会ICRA 2024上,团队发表论文6篇(其中3篇RAL)。如果对申请硕士、博士感兴趣,请参照团队主页:sysu-star.com
bilibili:
space.bilibili.com/194364164/
指导老师介绍
- 工作职责
- 以访问学者身份加入课题组,参与课题组的工程项目,并协助课题组科研成果落地;
- 依托课题组的平台与资源,在指导老师的指导下开展科研,参与移动机器人前沿算法的调研、复现和改进,发表顶级会议或期刊;
- 工作要求2.1 基本要求
- 机器人或相关专业(自动化、计算机、机械、电子电气等)的硕士生或优秀本科生(毕业GAP,暑研,毕设等)。
- 良好的编程能力,熟悉C++/python,能使用常见的数据结构和算法进行开发;
- 了解基本的机器人系统软件开发工具(Linux、Git、ROS、CMake);
- 有团队协作精神,乐于分享,有强烈的科研欲望或有一定的科研能力;
- 学习时间至少6个月,可学习一年以上者优先;条件优秀可适当放宽。
2.2 加分项
(1) 软件算法类
- 熟悉经典路径规划与轨迹规划算法,有相关工程开发经验;
- 熟悉主流SLAM算法及其源码框架,有相关工程开发经验;
- 有计算机视觉、机器学习、图形学相关研究经验;
- 有嵌入式软件开发能力。
(2) 硬件类
- 熟悉三维建模和工程制图,熟练掌握至少一种绘图软件;
- 熟悉动力学建模与分析,能运用有限元等方法对机体进行仿真分析与测试;
- 具有丰富的硬件开发经验,能够独立设计模拟、数字电路原理图以及PCB;
- 参加过机械设计竞赛、机器人竞赛,或有完整机器人与机电系统设计、相关产品研发经验。
- 有过机器人或机电系统的一个或多个完整模块(机械、电路、算法等)的设计、调优经验。
(3) 无人机系统类
- 熟悉多旋翼动力学及多旋翼飞控相关理论知识;
- 掌握飞控相关传感器特性,包括IMU、气压计、GPS、磁力计等;
- 熟悉常用开源飞控(如PX4/Ardupilot),有开源飞控二次开发经验。
(4) 其它
- 有机器人或计算机视觉等相关研究经验,有论文(在投或发表均可)
- 作为团队核心成员之一参与过大型机器人比赛(RoboCon、RoboMaster等) 毕业GapYear
- 研究方向
近期研究详细报告:
www.bilibili.com/video/BV16j411L7cY/?spm_id_from=333.999. 0.0
导航与规划
,时长00:07
室内复杂环境全自主高速导航

复杂树林全自主高速导航

无人机吊载系统实时规划
自主探索

无人机室内快速探索建图
轮腿机器人自主探索建图
空中覆盖与重建
无人机快速覆盖3D复杂表面
移动操作

高维度移动操作机器人实时整身运动规划
实时三维重建
混合表征建图
集群系统

去中心化协同探索

- 团队氛围
2023年会
生日分蛋糕
围观Robomaster赛事
镇Lab表情
打保龄球
- 工作地点
课题组位于广东省珠海市唐家湾,中山大学珠海校区人工智能学院。
5.1 校园环境
以下部分图片来自小红书。
学院大楼
5.2 工作环境
超大飞场
5.3 珠海风光
- 工作待遇
- 提供免费住宿,临近校园,生活便利;
- 课题组提供显示器、科研电脑及必要科研设备;
- 拥有优良的工作环境和境内外合作交流机会;
- 薪资根据资历和科研能力面议。
- 联系人及联系方式
- 联系人:周老师
- 邮箱:uv.boyuzhou@gmail.com
请确保在您的申请邮件中充分涵盖以下方面内容
在邮件中注明:1)研究方向、目标与兴趣;2)期望开始和结束日期;3)研究经历/论文/或技能和知识方面的独特性和优势;4)短期/长期目标
附上一份简历(中英文都行)包括:1)学校、专业、GPA和排名;2)研究/工作/实习经历(如果有);3)研究项目/课程项目/比赛项目;4)出版物/专利(如果有);5)算法/软件/硬件方面的技能和相应的熟练程度;
进入初审的候选人一般会在一周内收到邮件回复,届时将安排进一步线上讨论。如果没收到回复,可以试着再发一次邮件,若还是没有回复,说明可能不太适合,很抱歉无法对全部咨询一一回复:)
......
#西交利物浦&港科最新!
- 论文链接:https://www.arxiv.org/abs/2509.10570
- 作者单位:西交利物浦大学,澳门大学,利物浦大学,香港科技大学(广州)
摘要与引言
这篇综述探讨了将大语言模型(LLMs)和多模态大语言模型(MLLMs)等大型基础模型应用于自动驾驶轨迹预测的新范式 。这种方法通过整合语言和情境知识,使自动驾驶系统能更深入地理解复杂的交通场景,从而提升安全性和效率。文章回顾了从传统方法到由LFM 引入的范式转变,涵盖了车辆和行人的预测任务、常用的评估指标和相关数据集 。它详细介绍了LLM的三种关键应用方法:轨迹-语言映射、多模态融合和基于约束的推理,这些方法显著提高了预测的可解释性和在长尾场景中的鲁棒性 。尽管LLM有诸多优势,但也面临计算延迟、数据稀缺和真实世界鲁棒性等挑战 。
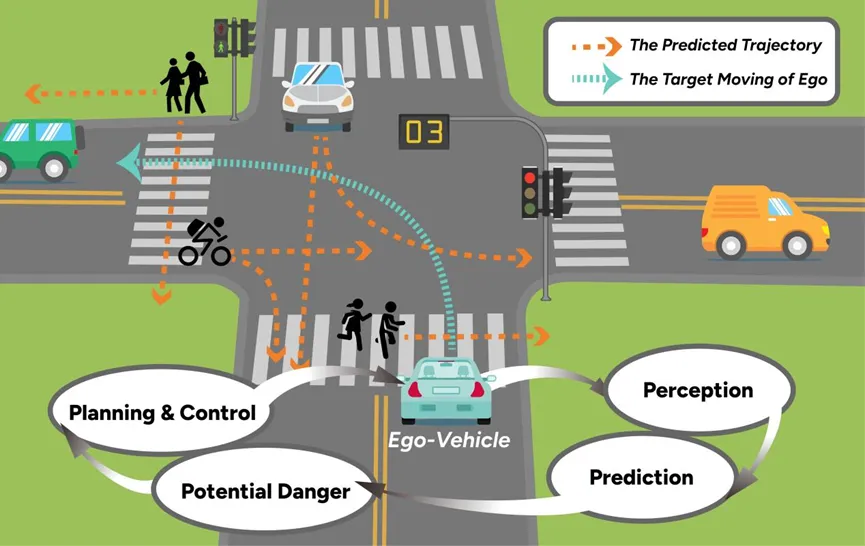
图1展示了自动驾驶中"感知-预测-规划与控制"的闭环过程,突出了LFM如何帮助自动驾驶车辆预测其他交通参与者的轨迹 。
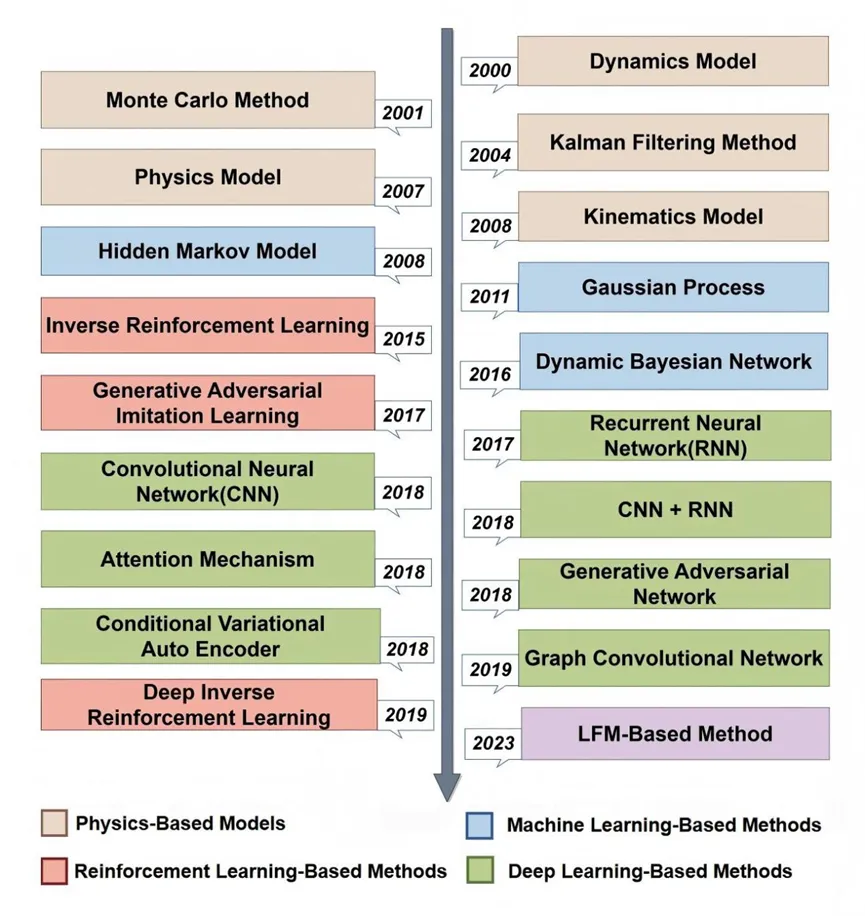
图2则以时间线形式展示了轨迹预测方法的演变,从基于物理模型、机器学习、深度学习到最新的LFM方法 。
轨迹预测概述
针对车辆轨迹预测,传统方法主要包括基于物理学的方法(如卡尔曼滤波器和蒙特卡罗方法)和基于机器学习的方法(如高斯过程和隐马尔可夫模型),这些方法虽然计算高效,但难以处理复杂的交互场景和实现泛化 。深度学习方法通过端到端架构自动提取时空特征,显著提升了长期预测的准确性,并能有效地建模交互、融合多层特征并生成多模态概率输出,尽管如此,它们仍面临计算需求高、可解释性差以及对大规模标注数据的过度依赖等挑战 。
而强化学习方法通过学习奖励函数来生成轨迹,在交互场景建模、长期预测和环境适应性方面表现出色,但其训练过程复杂且不稳定,高度依赖高保真数据,并且存在可解释性有限的"黑盒"问题 。对于行人轨迹预测,这是一项在人车混合环境中提高操作安全性的基础挑战 。
基于物理学的方法(如社会力模型)采用显式规则来模拟行人动态,虽然具有高可解释性和计算效率,但其人工设计的规则难以适应复杂的社会行为,且确定性输出无法捕捉轨迹的不确定性 。
数据驱动方法克服了这些局限性,通过学习隐式交互模式(如使用生成模型和图神经网络)来生成多模态轨迹,但这些模型同样存在决策过程不透明、数据依赖性高以及长期预测可能违反运动学可行性等问题 。最后,混合方法则结合了物理学先验知识和数据驱动学习,通过专家-数据融合或物理引导学习来增强预测的鲁棒性 。
基于LLM的车辆轨迹预测
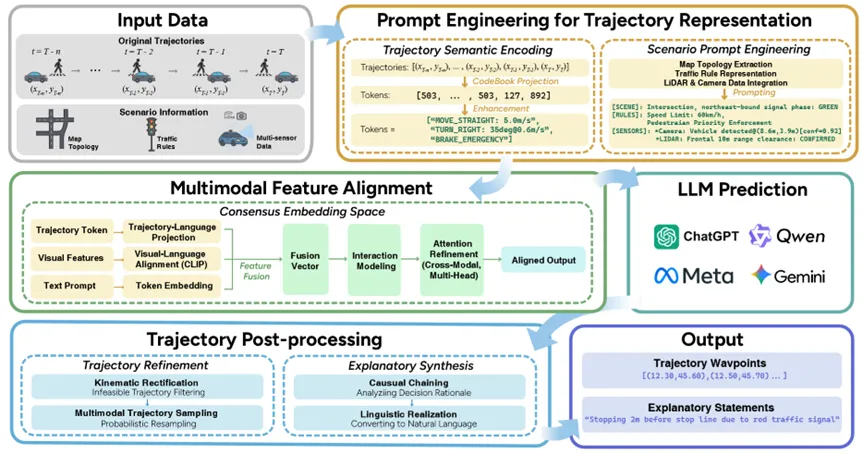
图三展示了以LFM为中心的轨迹预测的体系结构概述
LFMs的兴起为轨迹预测带来了范式层面的变革,其核心在于将连续的运动状态离散化为符号序列,并利用语言模型强大的语义建模与推理能力,实现从"信号级预测"到"语义级推理"的跃升。如图三所示,以LFM为核心的预测框架通常包含多模态对齐、嵌入融合与约束推理三个关键环节。
在感知与场景理解层面,视觉-语言模型(VLMs)通过将图像、点云等感知数据与文本描述进行联合嵌入,实现开放词汇检测和长尾物体识别。例如,DriveVLM通过语言描述增强对"道路施工标志""异型车辆"等稀缺目标的辨识能力,并将检测结果转化为自然语言描述,如"前方车辆打左转向灯",为后续推理提供语义基础。BLIP-2、LLaVA等通用MLLM框架也被广泛应用于驾驶场景描述生成,能够输出如"行人正在斑马线等候,左侧有公交车遮挡"等富含语义的场景摘要,显著提升系统的环境认知深度。
轨迹-语言映射是实现LLM理解运动行为的关键步骤。一方面,通过提示工程(Prompt Engineering)将轨迹数据与场景要素编码为结构化文本,如"自车速度:12m/s,前车距离:20m,意图:左转",使LLM能够基于自然语言进行轨迹推理。另一方面,轨迹离散化技术如VQ-VAE将连续轨迹映射为离散符号序列,Bezier曲线编码则用于压缩车道几何信息,从而构建与LLM词汇表兼容的运动表示。STG-LLM进一步将时空图结构中的节点与边关系转化为token序列,使LLM能够显式建模多智能体之间的交互动力学。
多模态融合架构旨在实现视觉、语言与轨迹信息的统一表示。典型做法是设计共享的场景编码器(如BEV编码器),将图像、LiDAR点云和地图信息映射为统一的token序列,再与语言指令进行交叉注意力融合。DiMA和DrivingGPT等框架通过跨模态 Transformer 实现多源信息的深度融合,支持基于语义指令的条件轨迹生成。此外,一些方法将预测任务重构为视觉问答(VQA)问题,如"基于当前BEV图像,生成左转轨迹",充分利用预训练MLLM的零样本推理能力。
基于推理的预测框架充分利用LLM的常识知识与人式推理能力,通过链式思维(CoT)提示、规则注入等方式,使轨迹生成过程更加透明且符合交通规范。例如,CoT-Drive将预测分解为场景解析、交互分析、风险评估和轨迹生成四个步骤,并输出相应的语义解释,如"由于行人正在通过,建议减速让行"。语言约束也被用于嵌入交通规则,如"在无保护左转中必须确认对向车辆通行情况",有效减少训练数据与真实场景之间的分布差异。这类方法不仅在碰撞率、minADE等指标上显著优于传统模型,更在可解释性与人机互信方面展现出独特价值。
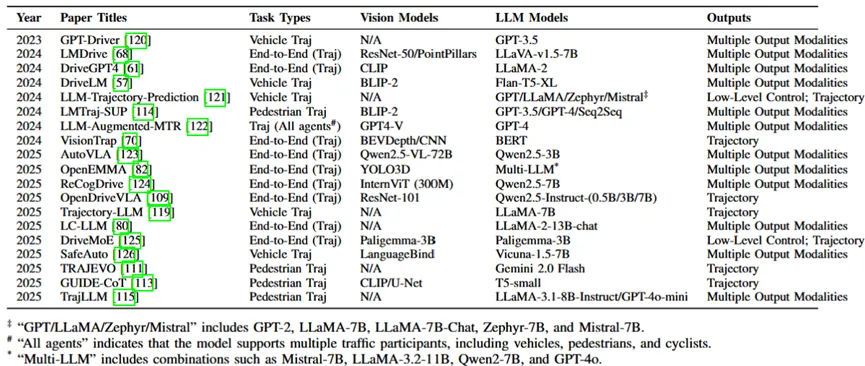
表1展示的是对2023年到2025年用LLM做轨迹预测的开源模型的总结
实验基准和评估指标
文章总结了用于评估基于LLM的轨迹预测方法的各种数据集和评估指标 。
数据集 :文章将现有数据集分为两大类:行人预测数据集 (如ETH/UCY)和车辆轨迹预测数据集(如Waymo、nuScenes和Argoverse)。行人预测领域广泛使用ETH/UCY数据集,包含酒店、校园等场景中的密集行人轨迹,适用于社会行为建模研究;JAAD等数据集则提供丰富的行人动作标注,支持意图感知的预测任务。车辆轨迹预测方面,Waymo Open Motion Dataset(WOMD)以其规模大、场景多样、交互复杂成为主流基准;nuScenes和Argoverse则提供多传感器数据与高精地图,支持多模态感知-预测联合评估。新兴数据集如nuPlan专注于闭环规划与预测的协同评估,InterACTION强调复杂交互场景,推动了预测技术向真实应用场景的靠拢。

图四展示了现有用于轨迹预测的数据集
指标 :对于车辆 ,评估指标包括L2距离 (衡量预测终点与真实终点间的欧氏距离)和碰撞率 。对于行人 ,主要指标为minADE 和minFDE,通常计算K=20个预测值中的最佳结果。实验分析表明,基于LLM的方法在降低碰撞率和提高长期预测准确性方面表现出卓越的性能。
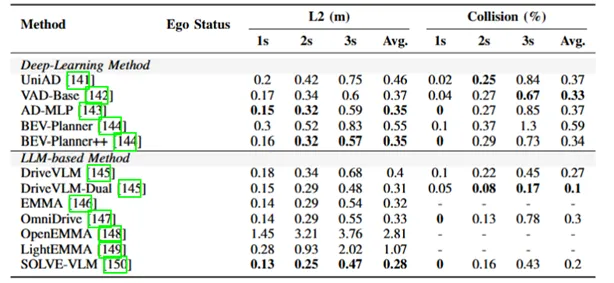
表2展示的是在NuScenes数据集上车辆轨迹预测模型的性能比较
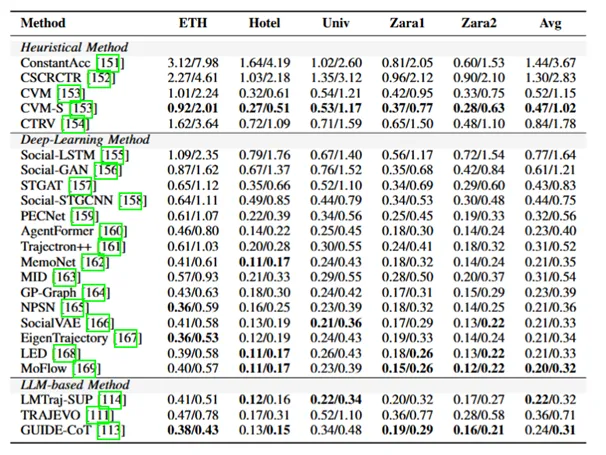
表3展示的是在ETH-UCY 数据集上行人轨迹预测模型的性能比较
讨论与结论
LFMs在轨迹预测中的广泛应用,标志着该领域正从局部模式匹配向全局语义理解转变。其核心优势可归纳为三个方面:第一,语义推理能力使模型能够融入交通规则、社会惯例等先验知识,生成不仅准确且合规的轨迹,提升系统安全性;第二,借助预训练中获得的世界知识,LLM表现出强大的长尾场景泛化能力,如对罕见交通参与者、极端天气条件的适应性;第三,多模态融合机制支持视觉、语言与轨迹信息的统一表示,为构建端到端可解释的自动驾驶系统奠定了基础。
然而,将LLM应用于实际驾驶系统仍面临诸多挑战。实时性方面,自回归解码延迟常超过100毫秒,难以满足车辆控制周期(通常低于50毫秒)的严格要求;数据层面,缺乏大规模高质量的轨迹-文本配对数据,且合成数据与真实场景间存在仿真到现实的差距;鲁棒性方面,恶劣天气、传感器退化等开放环境问题仍是当前模型的薄弱环节。此外,模型偏见、公平性等伦理问题也需在系统设计中被充分考虑。
未来研究应重点围绕以下方向展开:一是发展超低延迟推理技术,如非自回归解码、动态计算分配等,以满足实时控制需求;二是构建面向运动的基础模型,通过大规模轨迹预训练提升模型的运动语义理解与生成能力;三是推进世界感知与因果推理模型的研究,使轨迹预测不仅基于关联模式,更建立在因果机制之上。综上所述,LFMs正推动轨迹预测技术向更安全、可解释、适应性强的新阶段发展,其与自动驾驶系统的深度融合将为实现全场景无人驾驶提供关键支撑。
...
#OmniScene
如何向一段式端到端注入类人思考的能力?港科OmniScene提出了一种新的范式...
如何向一段式端到端注入人类思考的能力?
人类视觉能够将2D观察结果转化为以自身为中心的3D场景理解,这一能力为理解复杂场景和展现自适应行为提供了基础。然而当前自动驾驶系统仍缺乏这种能力---主流方法在很大程度上依赖于基于深度的三维重建,而非真正的场景理解。
**为解决这一局限,港科、理想和清华的团队提出一种全新的类人框架OmniScene。**首先本文引入OmniScene视觉-语言模型(OmniVLM),这是一种结合环视感知与时序融合能力的VLM框架,可实现全面的4D场景理解。其次通过师生结构的OmniVLM架构与知识蒸馏,将文本表征嵌入3D实例特征中以实现语义监督,既丰富了特征学习过程,又明确捕捉了类人的注意力语义信息。这些特征表征进一步与人类驾驶行为对齐,形成更贴近人类认知的"感知-理解-行动"架构。
此外本文提出分层融合策略(HFS),以解决多模态融合过程中模态贡献不平衡的问题。该方法能在多个抽象层级上自适应校准几何特征与语义特征的相对重要性,实现视觉模态与文本模态互补信息的协同利用。这种可学习的动态融合机制,使得异质信息能够被更细致、更有效地挖掘。
本文在nuScenes数据集上对OmniScene进行了全面评估,并与十多种当前主流模型在各类任务上进行基准对比。结果表明,OmniScene在所有任务中均实现了更优性能,为感知、预测、规划和视觉问答(VQA)任务建立了新的基准。值得注意的是,OmniScene在视觉问答性能上实现了21.40%的显著提升,充分证明了其强大的多模态推理能力。
一、引言
近年来,自动驾驶技术取得了显著进展,其核心领域(包括感知、运动预测和规划)均实现了突破。这些技术进步共同为更精准、更安全的驾驶性能奠定了基础。在此背景下,端到端(E2E)自动驾驶作为一种创新范式逐渐受到关注。通过利用大规模数据集,端到端方法能够学习将原始传感器输入直接映射为预测的规划轨迹,从而不再依赖手动的中间处理环节,同时提升了系统的适应性与可扩展性。
然而,传统的端到端自动驾驶系统在生成未来规划轨迹或低级控制指令时,往往未能有效整合感知与场景理解模块。这种整合缺失使其难以融入关键的上下文信息(如交通动态和导航约束),而这些信息对于稳健的自动驾驶至关重要。在复杂且模糊的场景中,这种局限尤为突出------此时单一的感知或简单的预测无法满足场景理解需求,例如处理复杂的交通交互或遵守交通规则等场景。
与之相反,人类视觉会持续将感知输入转化为场景理解,并根据不断变化的驾驶环境(如交通信号灯、行人活动和车道标线)调整注意力焦点。这种具备注意力感知能力的场景理解,是人类拥有卓越驾驶能力的关键所在。因此构建一种能够实现类人场景理解的统一方法,对于自动驾驶系统的智能决策与安全规划至关重要。
近年来,基于注意力感知的规划技术试图通过引入自注意力、空间注意力和局部特征提取模块等机制,增强端到端自动驾驶系统的性能。尽管这些努力取得了一定进展,但现有方法仍常依赖低级特征或静态启发式规则,缺乏明确的类人注意力建模,无法在复杂、动态的环境中实现自适应调整。更重要的是,即便视觉-语言模型(VLMs)的出现带来了强大的语义抽象能力,多模态融合仍停留在表面层面:视觉模态与文本模态通常被独立或依次处理,而非深度整合。这一局限导致互补信息未被充分利用------高层语义、注意力推理与几何上下文未能有效结合以指导规划过程。
因此自动驾驶领域的有效场景理解需要一种与人类认知对齐的多模态融合策略,能够联合聚合3D特征、视觉特征与语义特征,从而在动态驾驶场景中实现更贴近人类的上下文感知与优先级判断。
受上述挑战启发,本文提出OmniScene框架(如图1所示),这是一种旨在通过类人场景理解推动自动驾驶系统发展的创新方案。该方法主要解决以下三个核心问题:
如何实现4D场景理解? 实现鲁棒的4D场景理解需要融合感知表征与概念表征,弥合从视觉传感器提取的原始几何结构与人类认知特有的高层语义解读之间的差距。3D几何特征能够捕捉场景中的空间结构与动态关系,而文本语义特征则可编码环境元素的上下文、意图与抽象推理信息。这种双维度整合模拟了人类解读视觉刺激的过程------在这一过程中,感知信息会持续通过认知推理进行调节,以支持复杂动态环境下的驾驶决策。
在本文方法中,从传感器数据中提取的多视图3D几何特征可重建目标的空间布局与运动状态,为定位、避障和运动规划等任务提供精确基础。与此同时,由大型视觉-语言模型生成的语义特征能够提供更高层次的理解,包括注意力线索、导航目标和潜在风险,为类人判断提供必要的上下文感知。这些互补模态的融合产生了一种统一的表征,使自动驾驶系统不仅能以几何精度"观察"环境,还能以类似人类推理的方式"理解"场景。这种范式提升了场景理解的可解释性与稳健性,使自动驾驶系统能够在复杂交通场景中做出合理且可靠的决策。
如何在场景理解中实现类人注意力? 在场景理解中实现类人注意力,不仅需要被动感知,还需对视觉线索进行选择性优先级排序与上下文解读------这与熟练驾驶员在复杂环境中分配认知资源的方式类似。在本文框架中,这一能力通过OmniScene视觉-语言模型(OmniVLM)实现,该模型专门设计用于处理多视图、多帧视觉输入,以实现全面的场景感知与注意力推理。
借助先进的语义推理能力与大规模多模态知识,OmniVLM能够直接从解析后的传感器输入和跨视角、跨时间帧的环境标注中,生成注意力描述与决策依据。这些输出不仅捕捉了显式的场景元素,还包含了潜在的依赖关系与任务相关优先级,与人类观察和推理过程中形成的精细注意力图谱高度相似。
为实现高效部署,本文设计了师生结构的OmniVLM架构:原始的大规模OmniVLM作为教师模型,将其注意力知识(如空间注意力分布及相应的语义依据)迁移到轻量级的学生模型中。通过知识蒸馏,学生模型能够学习选择性地关注关键区域(如人行横道、交通信号灯和附近行人),同时抑制无关的背景信息------这一过程与人类感知的注意力机制高度一致。最终,OmniVLM实现了稳健且可解释的场景理解,并具备类人注意力行为,同时兼顾几何真实性与语义抽象性。这一设计使注意力感知型驾驶智能体能够在动态且安全关键的场景中,进行精细的上下文敏感推理与自适应驾驶。
如何为端到端自动驾驶实现多模态学习? 通用的3D场景理解侧重于空间中几何结构与目标关系的重建和解读,而自动驾驶则需要更多能力:对空间布局的准确感知必须与语义解读和上下文感知推理紧密结合。在真实驾驶环境中,智能体不仅需要建模各类动态与静态目标的位置和运动,还需理解其语义意义并预测其随时间的演变。
为满足这些需求,本文提出一种超越传统几何分析的分层融合策略(HFS)。该方法将以目标为中心的3D实例表征与多视图视觉输入、文本线索衍生的语义注意力相结合,并通过显式建模时间依赖关系实现整合。这种多层框架能够生成统一的表征,既捕捉细粒度的空间结构,又包含高层的时间语义优先级。通过将4D推理能力与上下文和意图的自适应解读能力相结合,本文方法推动了自动驾驶场景理解技术的发展。
本文在nuScenes数据集上对OmniScene进行了测试。与十多种当前主流模型的对比结果表明,本文方法实现了显著性能提升,充分证明其在增强感知、规划和整体驾驶性能方面的有效性。
二、相关工作回顾
A. 多模态信息融合机制
近年来,基于注意力的融合机制与可学习融合策略已成为多模态信息融合的主流范式,可有效应对模态异质性与模态失衡问题。这些方法在捕捉跨模态交互、动态适配各模态相关性方面已展现出显著成效,因此特别适用于自动驾驶、机器人等复杂任务场景。
基于注意力的融合机制借助注意力的优势对模态间依赖关系进行建模,使模型能够聚焦于信息最丰富的特征。基于Transformer的架构已成为该方法的核心基础,其通过自注意力与交叉注意力机制对不同模态的特征进行融合。例如,TransFuser利用Transformer整合视觉与激光雷达(LiDAR)特征,在三维目标检测与场景理解任务中实现了最优性能;类似地,跨模态注意力网络通过注意力对视觉与文本特征的重要性进行加权,在图像-文本匹配、视觉问答等任务中提升了性能。这些方法在捕捉长程依赖关系与复杂模态交互方面表现出色,但通常需要大量计算资源,这在实时系统中的应用受到了限制。
另一方面,可学习融合机制因其能够根据任务需求动态调整各模态贡献度的特性而受到关注。这类方法引入权重、系数等可学习参数,在训练过程中实现特征的自适应融合。例如,"模态感知融合"(Modality-Aware Fusion)通过设计可学习系数平衡视觉与激光雷达特征的重要性,提升了自动驾驶任务的鲁棒性;另一类典型方法是"动态融合网络"(Dynamic Fusion Networks),其利用门控机制根据当前上下文的相关性对模态进行选择性融合。这些策略在处理模态失衡问题时效果显著------当某一模态因自身信息丰富度或任务相关性而占据主导地位时,可学习机制能动态调整融合过程,确保所有模态都能为最终输出提供有效贡献,进而同时提升模型性能与可解释性。
B. 端到端自动驾驶
端到端自动驾驶系统通过在统一目标函数下对所有模块进行联合训练,最大限度减少了流水线中的信息损失,从而在整体性能上实现了显著提升。近年来,ST-P3、UniAD等统一框架开创了基于视觉的端到端系统,其将感知、预测与规划模块无缝整合,在复杂驾驶场景中实现了最优性能。在这些进展的基础上,VAD、VADv2等后续研究引入了向量化编码方法,提升了场景表示的效率与可扩展性,使系统能更稳健地处理动态环境。
近期,Ego-MLP、BEVPlanner、PARA-Drive等方法探索了模块化架构中的新型设计方向,重点关注自车状态建模与创新性架构设计,以进一步提升驾驶性能。这些方法通过引入更丰富的自车状态表示及其与环境的交互信息,突破了端到端系统的性能边界。
本研究在基于视觉的端到端自动驾驶基础上,融入了类人注意力文本信息。通过利用自然语言描述关键驾驶线索(如"前方有行人横穿马路""前方红灯需刹车"),使模型能够明确捕捉并优先关注与人类注意力对齐的兴趣区域。这一改进不仅提升了系统的可解释性,还确保模型决策与人类推理过程更紧密地对齐,尤其在安全关键场景中效果显著。
C. 自动驾驶中的视觉-语言模型
尽管视觉-语言模型(VLM)在各类通用任务中取得了显著进展,但其在自动驾驶领域的应用仍面临诸多独特挑战。这些挑战源于以下需求:为模型注入驾驶领域专属知识、准确解读复杂交通场景、确保输出满足自动驾驶系统的实时安全性与推理要求。
首要挑战是如何有效融入驾驶领域专属文本提示,以传递驾驶环境中独特的语义信息与注意力线索。与通用视觉-语言任务不同,自动驾驶要求模型理解细微的指令(如"在人行横道前礼让行人""前方红灯需刹车"),并能针对安全关键线索动态调整推理过程。现有基于VLM的系统往往采用通用提示或依赖大规模视觉-语言预训练,难以充分捕捉安全驾驶决策所需的场景专属信息。
此外,将VLM整合到端到端自动驾驶流水线中也面临进一步挑战。Drive-with-LLMs、DriveGPT4等方法已证明利用VLM进行轨迹预测与规划的可行性,但这些方法通常依赖真值感知数据或领域专属微调,限制了其在多样化真实场景中的泛化能力。ELM、DriveVLM等其他研究强调了大规模跨领域预训练的重要性,但在使模型输出与人类决策过程及可解释性对齐方面仍存在挑战。类似地,VLM-E2E探索了在鸟瞰图(BEV)空间中融合多模态驾驶员注意力,但基于BEV的整合可能会丢失细粒度三维空间上下文,削弱语义-几何对齐效果。
另一关键问题是缺乏针对城市与高速公路环境复杂性设计的高质量、驾驶专属视觉-语言数据集。尽管近期研究已开始填补这一空白,但仍需进一步捕捉罕见、长尾或安全关键场景------这些场景对于确保模型稳健性至关重要。综上,尽管VLM为自动驾驶提供了极具潜力的能力,但要推进其应用,需针对性解决领域专属语义、数据稀缺、实时可解释性及整合等问题。本研究旨在通过设计驾驶注意力提示、开发端到端视觉-语言推理新方法,填补安全关键驾驶场景中的这些空白。
三、算法详解
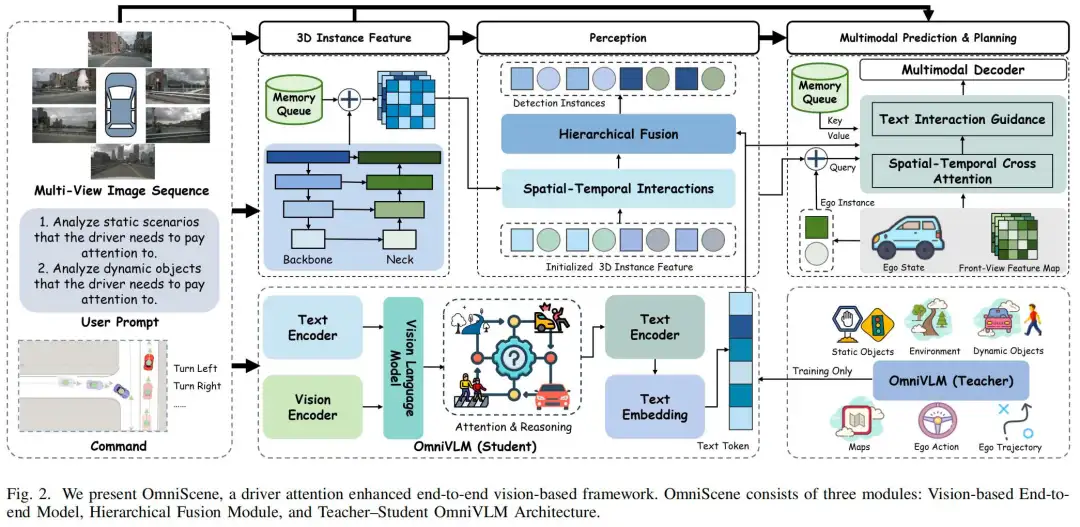
本节将全面介绍OmniScene框架(如图2所示)。该系统的输入包括环视图像、操作指令与用户提示。这些多模态输入首先由学生端OmniVLM模块处理,生成描述观测场景的简洁文本标注;同时,环视图像通过视觉编码层提取视觉特征。生成的文本标注随后输入至分层融合策略(HFS)模块,通过预训练CLIP模型转换为文本特征表示。之后三维实例特征、视觉特征与文本特征进行融合,形成全面的特征表示,为感知、预测、规划等下游任务提供支持。
A. 预备知识
从信息论角度来看,多模态聚合可通过分析最终三维实例表示中捕捉到的视觉与语言互补知识量进行形式化描述。设、、分别表示三维实例、视觉、文本模态的随机变量。聚合效果通过聚合后的三维表示与视觉-文本联合特征间的总互信息衡量,该指标反映了模型整合并保留跨模态语义信息的能力。
多模态聚合的核心目标是提升三维实例与视觉-文本联合特征间的互信息,其可分解为:
其中,衡量三维实例与视觉特征间的共享信息,表示在视觉特征给定的条件下,文本特征提供的额外信息。在理想的聚合过程中,两项均应提升,以实现有效的特征融合。
在嵌入学习过程中,除对比对齐外,还需考虑最小化条件熵------该熵反映了在给定视觉与文本模态的情况下,三维实例的不确定性。条件熵越低,表明融合后的三维表示不确定性越小,聚合效果越优:
需注意的是,最小化该熵可使三维实例能通过视觉与文本线索被高效预测。
此外,为避免信息冗余并确保各模态贡献独特信息,可引入交互信息进行衡量:
该指标反映了模态间关于三维实例的净协同效应。若其值为正,表明模态联合提供的关于实例的整合信息多于单一模态提供的信息。
1)最大化互信息
提升互信息的核心策略是实现多模态特征与三维表示的对齐。分类任务中使用的焦损失(Focal Loss)通过对误分类误差施加更大惩罚,重点关注罕见或关键实例,确保三维特征与视觉特征、文本线索的对齐。这一过程同时增强了语义对应性,有效提升了互信息分量与。
此外,文本条件聚合在将文本语义嵌入学习过程中发挥关键作用。该机制减少了模态间冗余,提升了交互信息,确保通过协同整合丰富三维表示。
2)最小化条件熵
降低对于实现精准三维预测、减少融合表示的模糊性至关重要。L1损失等回归目标可直接最小化预测误差,适用于基于多模态信息的三维边界框与轨迹预测任务。这种对几何与动态不确定性的降低,减少了熵值,进而获得更稳健的三维实例表示。
具体而言,轨迹预测损失通过利用时间视觉线索与文本指令(如"前方车辆转弯")最小化位移误差,降低了运动动力学的不确定性,进一步提升了三维表示的准确性。
3)跨模态目标的统一优化
整体训练目标(公式33)整合了分类损失(如焦损失)、回归损失(如L1损失)与辅助目标,以同时实现最大化与最小化。深度对齐损失等辅助目标在促进跨模态信息一致性整合的同时,避免了模态专属偏差。这一统一框架确保三维表示具备强语义对齐性、低冗余性与低不确定性,为下游任务提供稳健且可解释的多模态学习支持。
B. 师生架构的OmniVLM
1)Teacher--Student架构
图3详细展示了基于教师端OmniVLM的数据生成流程,该流程为学生端模型适配提供基础。流程首先从知识挖掘开始:从Bench2Drive与nuScenes数据集中系统提取真值标注、机动信号与领域专属驾驶规则。在真值标注提取中,动态障碍物的选取范围为:自车前后20米半径内、距离自车约15米的区域,以及自车前方50米半径内、后方30米半径内、距离自车约30米的区域,确保包含每条车道中最近的目标;交通标志标注基于自车前方30米半径内、距离自车约30米的目标;交通信号灯识别范围为自车前方50米半径内、距离自车约30米的区域。这些元素共同捕捉了环境特征的多样性(包括天气条件、动态交通参与者、静态场景细节),为复杂真实驾驶场景的整体建模提供支持。

基于上述结构化知识库,教师端OmniVLM自动生成包含环境上下文、类人注意力焦点与推理步骤的增强文本描述,形成高质量视觉-文本配对数据,为下游学习与模型适配提供支持。
在后续微调阶段,核心任务是利用Bench2Drive与nuScenes的精选数据对,适配轻量级学生端OmniVLM。学生端模型的精简设计大幅降低了计算与内存开销,使其能部署在车载嵌入式系统等资源受限平台上,同时保持场景理解与驾驶决策推理能力。这种师生策略不仅提升了自动驾驶任务的可解释性与运行效率,还确保了在硬件资源有限的实际场景中实现快速推理与动态适配。
本架构的关键设计考量之一是多视图、多帧视觉输入策略。具体而言,系统利用自车上安装的6个摄像头同步采集视频流,实现对周围环境的360度全面覆盖。与仅依赖前视图像、缺乏全局态势感知的传统方法不同,本方法通过时空丰富的视觉上下文捕捉关键的侧方与后方信息,为稳健场景理解提供支持。这种多视图、多帧范式使模型突破了以往方法的条件独立性假设,充分挖掘视觉与语言模态间的协同关系。
为进一步提升类人注意力语义与动态环境建模能力,本研究提出全局多模态对齐策略。该策略联合考虑多视图、多帧视觉特征与细粒度文本信息,通过可学习相似度矩阵实现整合。与单独处理各摄像头视图或帧不同,对齐机制聚合所有视图与时间片段的特征,在统一特征空间中实现多视图-多帧图像嵌入与语义文本嵌入的对齐。基于语义相关性的自适应加权确保构建具备全局性与时间感知性的联合表示。这一策略生成了稳健、抗干扰的场景表示,对安全高效的自动驾驶至关重要。
2)OmniScene标注
基于师生架构,本框架利用学生端OmniVLM的推理能力,从丰富的多视图-多帧视觉数据中提取驾驶员注意力信息,并生成语义场景标注。如图2所示,标注提取过程可形式化描述为:
其中,表示学生端OmniVLM,与分别表示任务专属提示与历史步数,对应自车第个视图摄像头的时间视觉流(前视、左前视、右前视、后视、左后视、右后视),为生成的文本场景描述,提供详细的上下文感知环境信息。
本框架在OmniVLM中整合了目标提示条件与实时多视图视频分析,使模型能选择性关注行人、信号灯状态、移动障碍物等语义显著交通主体,同时抑制背景干扰,生成面向驾驶决策支持优化的场景表示。
在实际实现中,微调后的学生端OmniVLM在复杂场景推理中表现出强劲能力,能生成精准且上下文相关的驾驶标注。模型通过在任务提示引导下解读视觉场景,输出文本描述,为数据集补充驾驶员注意力线索。这些标注大幅提升了驾驶环境的可解释性,增强了下游自动驾驶模型的决策能力。
C. 分层融合策略
类人注意力从视觉观测中捕捉丰富语义线索,为主要编码几何与结构属性的三维实例特征提供互补信息。为实现全面场景理解,本研究提出分层融合策略,实现两种模态的有效整合。该融合策略的细节如图4所示。
1)三维实例初始化
本阶段采用SparseDrive提出的基于稀疏查询的范式,旨在通过环视图像高效初始化场景中的三维目标实例集。
首先初始化个可学习三维查询,每个查询编码其空间位置、尺寸与语义嵌入。这些查询具备可训练性,在训练过程中能自适应迁移至三维空间中的兴趣区域。
给定经过标定的个摄像头视图及对应的图像特征,通过摄像头投影函数将每个三维查询投影至各视图中,并通过双线性插值采样多视图特征:
对采样特征进行聚合:
其中,表示聚合操作。对于每个查询,将聚合后的多视图特征与其查询嵌入融合,得到初始实例表示:
其中,表示拼接操作。
对应用候选预测头(PPH),预测目标得分、三维边界框参数与语义标签:
仅保留得分满足(为预定义阈值)的候选作为有效三维实例。
与密集候选生成相比,这种基于稀疏查询的初始化方式有效降低了计算复杂度,使模型能聚焦于三维空间中的信息区域。查询的可学习性支持端到端优化,为后续时空推理与实例优化提供坚实基础。
2)4D时空融合
为稳健捕捉多个三维实例特征间的时间动态与空间依赖关系,OmniScene对历史实例特征采用解耦交叉注意力机制,并设计解耦自注意力模块。本阶段的输入为历史实例特征序列:
其中,表示时刻第个三维实例的特征嵌入,为每帧实例数量。
首先通过解耦交叉注意力显式建模每个实例在多帧间的时间依赖关系。对于第个实例,当前时刻特征关注其历史特征,从而同时捕捉长程趋势与近期动态。时间更新计算如下:
其中,
为可学习投影矩阵,为特征维度。
基于时间更新后的特征,通过解耦自注意力进一步挖掘当前帧内实例间的空间关系。这使每个实例能聚合其他所有实体的上下文信息,实现局部与全局空间交互的建模。形式化地,对每个实例:
其中,
为空间注意力参数。
通过堆叠用于时间建模的解耦交叉注意力与用于空间聚合的解耦自注意力,OmniScene实现了对时间与空间依赖关系的显式、解纠缠编码。这种分层设计首先在实例层面整合长程时间信息,再在每帧内进行精细空间上下文建模,提升了场景建模的可解释性与表达能力------这对自动驾驶下游任务至关重要。
3)视觉可变形聚合
为进一步增强三维实例特征表示,本研究设计视觉可变形聚合模块:以每个实例的几何先验为引导,自适应从环视图像特征中聚合信息线索。具体而言,对于时刻的第个三维实例,考虑经时空增强后的特征与来自个摄像头视图的多视图视觉特征。
对每个实例,将其三维位置投影至所有个摄像头的图像平面,得到二维坐标集。在每个投影中心周围,基于预测个采样偏移量,采样位置为:
在摄像头的每个采样位置处,提取对应的图像特征:
利用可学习权重融合所有采样特征:
其中,为可学习投影矩阵,权重通过softmax归一化:
为可学习向量。
通过门控机制将聚合后的视觉特征与三维实例特征融合,得到最终增强实例表示:
其中,表示融合操作。
该可变形聚合模块使每个三维实例能自适应关注环视图像中信息最丰富的空间位置,有效利用几何线索与密集视觉上下文。最终实例特征因此整合了丰富的视觉语义,为三维检测、轨迹预测等下游任务提供支持。
4)文本条件聚合
为进一步通过语义上下文丰富三维实例表示,本研究引入文本条件聚合模块。该模块将文本语义信息整合到每个三维实例特征中,使模型能在文本线索引导下实现上下文感知推理。模块输入为增强实例特征与通过预训练文本编码器CLIP得到的文本特征。
对于每个实例,首先将视觉增强特征与文本特征投影至共享嵌入空间:
其中,与为可学习投影矩阵,为融合特征维度。
利用门控注意力机制建模文本条件聚合过程,最终文本增强实例特征计算如下:
其中,门控系数基于与自适应生成:
表示sigmoid激活函数,与为可学习参数,表示向量拼接。
通过文本特征引导,该文本条件聚合模块使模型能自适应地将丰富语义知识注入三维实例表示。
5)深度优化
为进一步提升三维实例表示的几何准确性,在文本条件聚合阶段后引入深度优化模块。该模块利用增强实例特征与来自环视图像的辅助深度线索,对每个实例的估计深度进行校正与优化。
给定文本增强实例特征与第个实例的初始估计深度,通过轻量级回归器预测深度残差校正量:
其中,表示用于深度调整的多层感知机。优化后的深度为:
为进一步规范实例深度,需确保其与从环视图像预测的辅助深度图的一致性。具体而言,对每个实例,将其优化后的三维位置投影至第个摄像头的图像平面,得到对应坐标。视图级深度对齐损失定义为:
该损失确保优化后的实例深度与所有摄像头视图预测的场景几何保持一致。
深度优化模块通过自适应回归深度残差与强制跨视图一致性,有效校正了三维感知中的几何误差。该设计利用了前期阶段聚合的语义、视觉与文本上下文,进一步提升了下游三维理解与预测任务的可靠性。
D. 基于视觉的端到端模型
1)多模态预测与规划
OmniScene的多模态轨迹预测头整合了运动规划原理与学习型轨迹预测方法,能有效捕捉复杂城市场景中智能体的多样化未来行为。
在推理阶段,运动规划头针对多个未来模态与时间步长生成候选未来轨迹集(涵盖自车与其他智能体)。候选运动模态以通过KMeans聚类数据集得到的模板为锚点,存储为运动或规划锚点。这些锚点包含直行、左转、右转、礼让等典型机动模式,作为结构化先验引导预测轨迹的生成与评估。
为提升模型表达能力并解耦智能体间交互,OmniScene可选择性采用解耦注意力机制,实现运动假设与场景上下文的选择性特征融合。这一机制在智能体意图模糊或存在遮挡的场景中,支持稳健推理。
预测模块进一步为每个跟踪智能体维护实例队列,存储跨帧特征嵌入时间缓存。队列由容量、嵌入维度与跟踪阈值参数化,使模型能聚合局部时间动态与外观信息。跟踪功能支持系统在处理新传感输入时无缝更新预测结果,减少漂移并提升长程一致性。
在每个规划周期,通过将当前智能体观测与最接近的运动锚点匹配,并基于场景上下文、实例历史与各机动模式的预测概率优化候选规划,生成未来轨迹。该方法支持多样化多模态假设,使系统能处理真实城市驾驶中常见的罕见、复杂或长尾行为。
2)分层规划选择
分层规划选择模块通过对多模态预测结果与场景约束进行整体推理,为自车与周边智能体筛选出最可行、安全且上下文适配的轨迹。在预测模块生成候选轨迹集后,规划头联合考虑这些假设、动态场景与全局导航目标进行决策。
首先,通过距离度量计算预测路径与各锚点的相似度,将每个候选轨迹投影至通过KMeans等聚类方法得到的机动锚点集:
其中,表示模态在时刻的预测位置,为对应锚点位置。
利用指示函数筛选掉不满足基本可行性的候选轨迹------包括违反可行驶区域约束、与静态障碍物相交或违反路权规则的轨迹:
其中,表示地图,表示周边目标。
对剩余可行轨迹,通过聚合城市驾驶相关的多维度指标计算综合效用得分:
其中,衡量轨迹向规划路线或目标车道的推进程度;通过惩罚加速度或航向突变量化运动舒适性;评估与其他动态智能体发生碰撞或近距离接触的预期概率;为遵守交通规则与地图约束的奖励项。权重通过调优平衡安全、效率、舒适性等驾驶目标。
规划头还参考实例队列中存储的时间上下文(编码历史意图与状态转移),进一步优化得分估计并过滤瞬时异常规划。当系统接收新观测时,持续更新并重新评估所有候选规划,使规划器能动态响应新障碍物与行为线索。
最终,最优轨迹选择如下:
选定的规划用于近期执行,同时系统以高频进行闭环重规划。这种基于效用的分层框架使OmniScene能稳健处理复杂多智能体城市场景,并通过可解释的上下文感知决策,预测常见与长尾交通事件。
3)训练目标
为实现端到端联合优化感知、运动预测与规划,OmniScene采用包含多个任务专属目标的统一损失函数。每个目标均设计了相应的匹配策略与损失形式,以支持有效的多任务学习。
采用匈牙利算法实现真值与预测检测结果的匹配。感知损失为分类焦损失与边界框回归L1损失的加权和:
其中,为检测分类损失,为检测回归损失,、为对应权重。
地图损失定义与感知损失类似:
其中,、分别为地图任务的分类与回归损失,、为对应权重。
深度回归采用L1损失:
其中,、分别表示预测深度与真值深度。
运动预测任务通过最小化多个预测轨迹与真值间的平均位移误差(ADE)实现,选择ADE最小的轨迹作为正样本,其余作为负样本。规划任务需同时预测未来自车状态与预期路径,分类采用焦损失,回归采用L1损失:
其中,各参数用于平衡分类、回归与状态预测损失。
OmniScene的总损失整合上述多任务损失项:
该多任务目标促使模型同时学习检测、地图构建、深度估计与运动规划的有效表示,进而提升自动驾驶规划能力。
四、实验结果设置
A. 数据集
本研究采用nuScenes基准数据集,这是一个用于自动驾驶研究的大规模多模态数据集。该数据集包含1000个多样化的城市驾驶序列,每个序列时长20秒,且以2Hz的频率进行密集标注,涵盖了各类交通场景、道路布局和天气条件。数据通过一套360°全环绕传感器套件采集,该套件包括6个同步摄像头、1个激光雷达(LiDAR)、5个雷达以及1个IMU/GNSS单元,可提供互补的几何信息和语义信息。对于摄像头子系统,每帧图像的内参和外参校准数据均已提供,能够实现精确的多视图空间配准。该数据集包含140万张摄像头图像、超过39万次激光雷达扫描数据,以及针对23个以上目标类别的细粒度3D边界框标注,目标类别包括车辆、行人、自行车和交通元素等。其在规模和传感器多样性上的丰富性,使nuScenes成为评估自动驾驶中感知、预测和规划算法的标准基准数据集。
B. 评价指标
本研究遵循已有的基准协议,对自动驾驶的多项任务进行了全面评估。
- 3D目标检测:采用平均精度均值(mAP)、综合检测得分(NDS)以及多项误差指标进行量化评估,包括平移误差(mATE)、尺度误差(mASE)、方向误差(mAOE)、速度误差(mAVE)和属性预测误差(mAAE)。
- 多目标跟踪:采用平均多目标跟踪精度(AMOTA)、平均多目标跟踪精度(AMOTP)、召回率(Recall)和身份切换次数(IDS)作为评估指标。
- 运动预测:评估基准与相关研究一致,包含四项关键指标:最小平均位移误差(minADE)、最小最终位移误差(minFDE)、遗漏率(MR)和端到端预测准确率(EPA)。
- 规划评估:采用两项主要指标:轨迹L2误差(与相关研究的实现保持一致)和碰撞率。针对以往碰撞评估方法中的两个关键局限性,本研究进行了改进:一是传统的0.5米网格分辨率占用图方法因量化误差无法准确检测与小型障碍物的碰撞;二是现有方法忽略了运动过程中自车航向的动态变化。为解决这些问题,本研究提出的增强型评估协议通过以下两点实现改进:(1)对自车与障碍物进行精确的边界框相交检测,消除网格量化误差;(2)从轨迹点中估计偏航角,以充分考虑车辆朝向的变化。为保证对比公平性,本研究使用相关基线模型的官方权重,通过改进后的碰撞检测框架对其重新评估。该严谨的评估协议能更准确地衡量复杂驾驶场景下的规划性能。
- 视觉问答(VQA)评估:采用CIDEr(CI-r)、BLEU-1(BL-1)、BLEU-4(BL-4)、METEOR(ME-R)和ROUGE-L(RO-L)作为性能基准,从语言质量和视觉-语言对齐度两个维度对模型进行全面评估。
C. 实现细节
模型利用1秒的历史上下文预测未来2秒的轨迹,在nuScenes数据集中,这对应于3帧历史帧和4帧未来帧。教师OmniVLM通过创新性扩展Qwen2.5VL 72B开发而成,而学生OmniVLM则通过增强Qwen2.5VL 7B构建。
在每个历史时间步,模型接收6个多视图摄像头图像,每个图像的分辨率为256×704像素。感知骨干网络对这些图像进行编码,并将其投影到统一的稀疏体素空间中。本研究将以自车为中心、尺寸为100米×100米×6米的场景离散为稀疏柱体,空间分辨率为0.5米×0.5米×0.2米,从而得到高效的稀疏体素表示。
训练过程采用AdamW优化器,使用单周期学习率调度策略,初始学习率为。模型共训练10个epoch,总批量大小为96,在8块Tesla A800 GPU上进行分布式训练。同时,采用混合精度训练以加快计算速度并降低内存消耗。
五、实验结果分析
A. 定量结果
1)感知性能
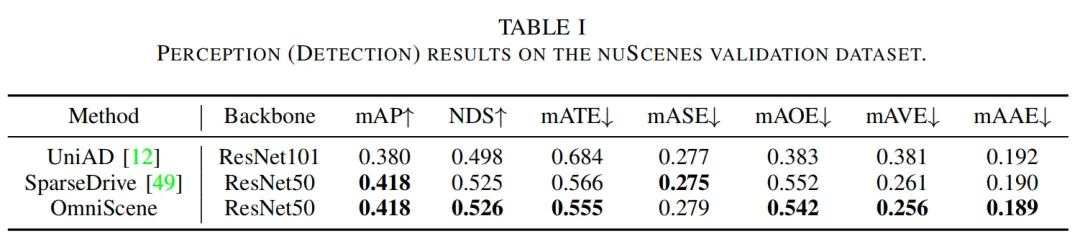
表1和表2展示了在nuScenes验证集上的感知结果,包括检测性能和跟踪性能。所提模型的nuScenes检测得分最高,达到0.526,且平均平移误差(mATE)最低,为0.555米,在检测精度和定位精度上均优于SparseDrive和UniAD。同时,该模型在方向误差(mAOE)、速度误差(mAVE)和属性预测误差(mAAE)上也取得了最低值,且平均精度均值(mAP)和尺度误差(mASE)保持竞争力,进一步验证了其在复杂城市环境中强大的感知能力。
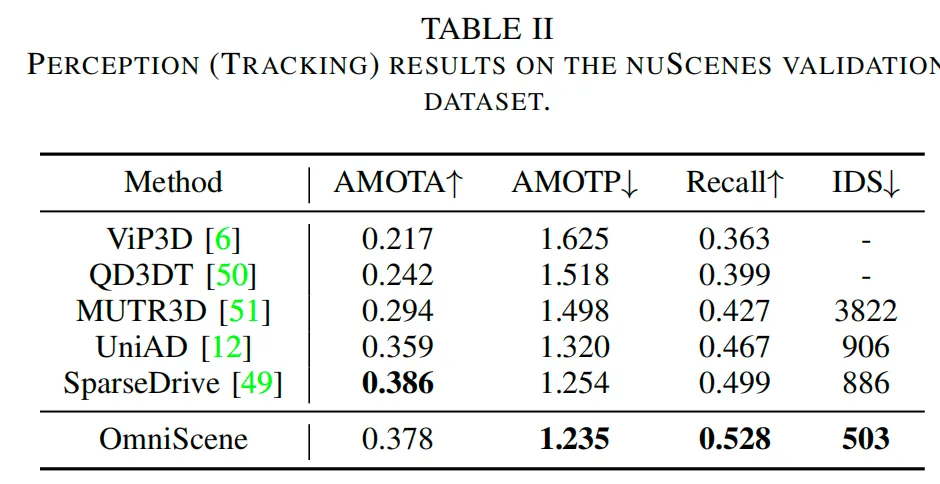
在跟踪任务上,所提模型在平均多目标跟踪精度(AMOTP)、召回率(Recall)和身份切换次数(IDS)上表现最佳:AMOTP为1.235,召回率为0.528,身份切换次数仅为503次,显著优于所有现有基线模型。尽管SparseDrive的平均多目标跟踪精度(AMOTA)略高,但所提方法通过提升召回率和减少身份切换次数,在跟踪鲁棒性上更具优势。这些综合结果表明,该模型在城市自动驾驶场景中能够实现可靠的检测和跟踪性能。
2)预测性能
表3展示了在nuScenes验证集上的预测结果。所提方法在所有指标上均优于现有基线模型:最小平均位移误差(minADE)和最小最终位移误差(minFDE)分别低至0.61米和0.96米,表明轨迹预测精度更高;遗漏率(MR)最低,为0.128,端到端预测准确率(EPA)最高,为0.488,体现出该方法在运动预测中的可靠性和高效性。值得注意的是,该方法在性能上持续超越SparseDrive和UniAD等当前最优方法,充分证明了其在复杂城市驾驶场景中的有效性。
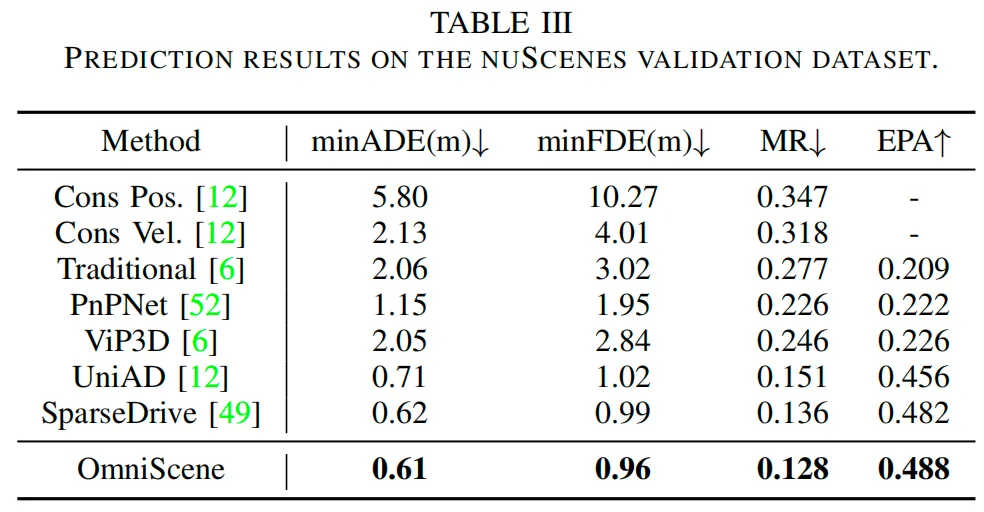
3)规划性能
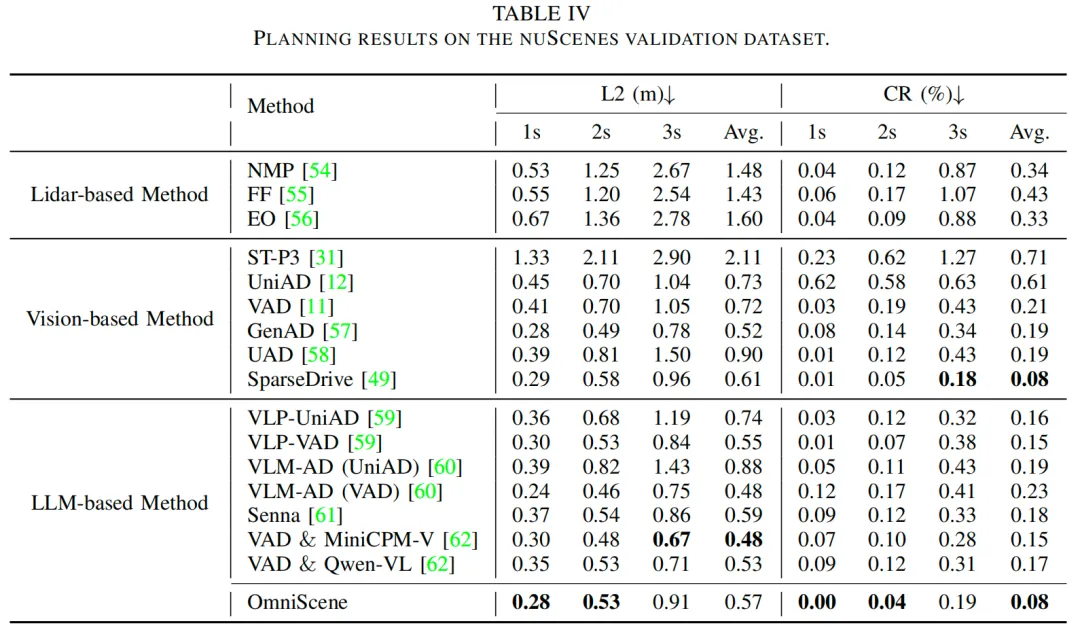
表4展示了在nuScenes验证集上的规划性能,对比对象涵盖基于激光雷达、基于视觉和基于大语言模型(LLM)的多种方法。所提方法在几乎所有指标上均取得最佳结果:轨迹L2误差平均值最低,为0.58米;在所有预测时域下均表现领先,1秒、2秒和3秒时的L2误差分别为0.28米、0.55米和0.91米,优于所有现有方法。在碰撞率方面,该方法在所有时间步均保持最低或接近最低水平:1秒时碰撞率为0%,2秒时为0.04%,表明其在短期规划中的安全性更优;3秒时碰撞率为0.19%,与其他领先方法持平或更优。
与GenAD、UAD、SparseDrive等近期性能优异的基于视觉的方法,以及VLP-VAD、Senna等基于LLM的方法相比,所提方法在精度和安全性上均展现出明显优势。这些结果充分证明了该方法在复杂自动驾驶场景规划任务中的有效性和鲁棒性。
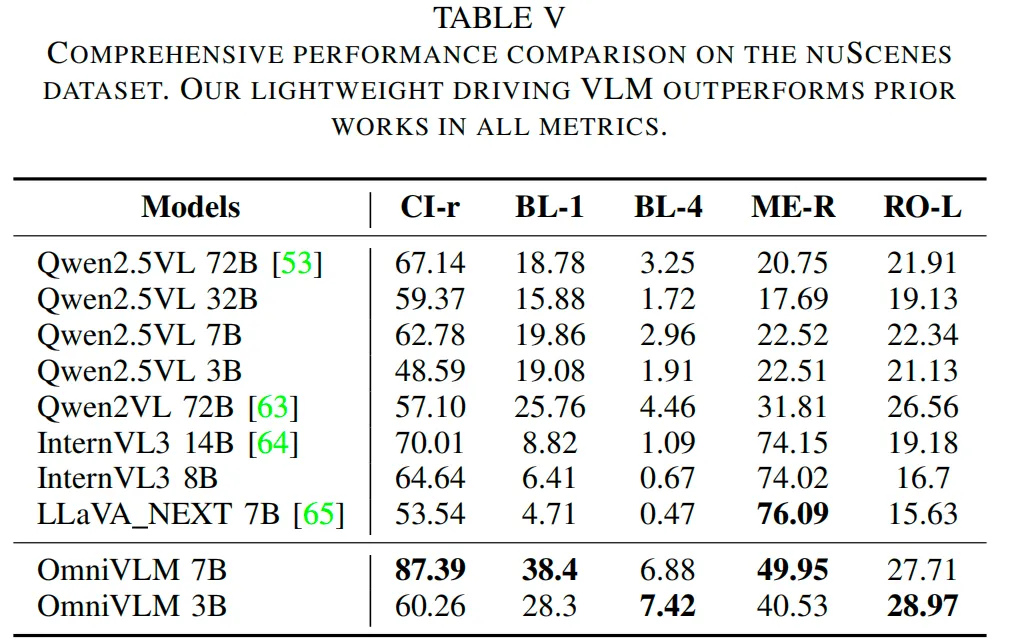
4)视觉问答(VQA)任务性能
表5展示了在nuScenes数据集上的综合性能对比。所提模型在所有评估指标上均较现有基线模型有显著提升:OmniVLM 7B模型的CIDEr(CI-r)得分为87.39,比最佳基线模型(InternVL3 14B,得分70.01)高出24.9%;其BLEU-1(BL-1)得分为38.4,比最佳基线模型(Qwen2VL 72B,得分25.76)高出49.0%。OmniVLM 3B模型的BLEU-4(BL-4)和ROUGE-L(RO-L)得分最高,分别为7.42和28.97,其中BLEU-4得分较Qwen2VL 72B(得分4.46)提升了66.5%,ROUGE-L得分较Qwen2VL 72B(得分26.56)提升了9.1%。在大多数任务中,OmniVLM 3B和7B模型均持续优于Qwen2.5VL、InternVL3等主流模型,充分证明了该方法的鲁棒性和有效性,也凸显了其在复杂城市环境中实现全面场景理解与推理的显著优势。
B. 定性分析
图5展示了十字路口不同驾驶意图下的定性可视化结果。所提OmniScene模型联合利用多视图感知、轨迹预测和文本化驾驶员注意力,对复杂的十字路口场景进行解读。多视图摄像头图像从不同视角捕捉了各类动态智能体和静态障碍物;预测的多模态轨迹对应直行、左转、右转等不同转向意图,展示了可行的未来运动趋势;文本化驾驶员注意力则通过突出影响自车决策的关键目标(如行人、施工人员、停放的公交车)和上下文线索,提供了详细的语义解释。这些全面的可视化结果表明,该方法能够准确感知场景细节、推断驾驶意图,并为复杂城市十字路口场景下安全可靠的运动规划提供可解释的推理依据。
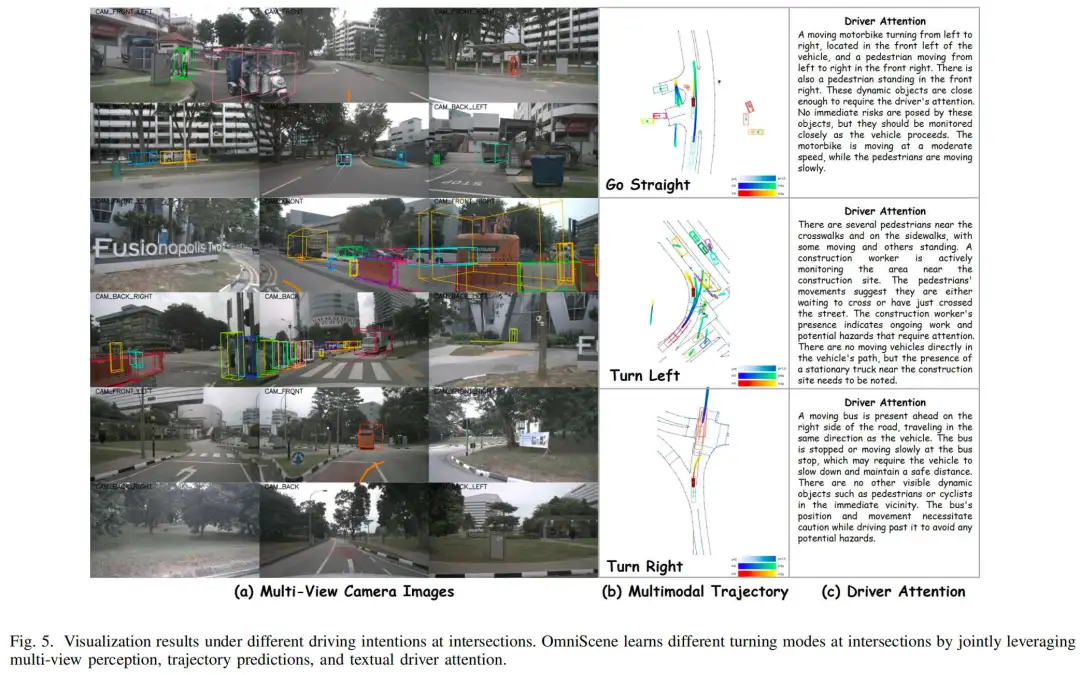
图6展示了SparseDrive、OmniScene与真值(Ground Truth)的定性鸟瞰图(BEV)可视化对比,场景为自车前方出现多名行人、需进行紧急避障操作的复杂情况。多视图摄像头图像捕捉了十字路口处行人与车辆的位置和运动状态。在鸟瞰图中,OmniScene的轨迹预测和障碍物定位能力更优:其预测轨迹与真值高度匹配,且能有效适应动态智能体的存在。与SparseDrive相比,OmniScene提供了更精准的避障路径,体现出其在感知关键障碍物和制定更安全、更可靠的规划决策方面的优势。这些结果凸显了OmniScene在处理行人密集、安全要求高的复杂城市场景中的优越性。
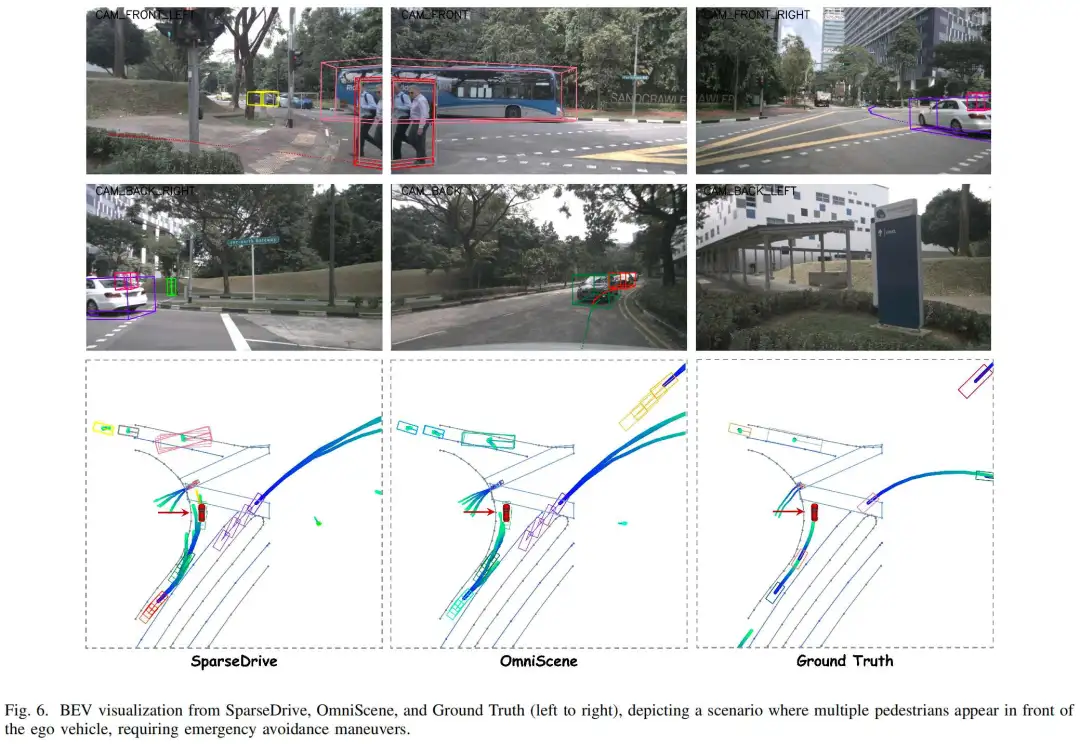
C. 消融实验1)OmniScene中各设计的有效性
在nuScenes验证集上,本研究针对OmniScene的关键架构设计开展了全面的消融实验,评估其在感知、预测和规划任务中的有效性。如表6所示,深度细化(DR)、自车实例初始化(EII)、时空解耦交叉注意力(TDCA、SDCA)、文本条件聚合(TCA)等每个组件,均对整体检测和跟踪性能有逐步提升作用。值得注意的是,时空注意力模块持续提升平均精度均值(mAP)和综合检测得分(NDS),有助于改善目标定位和分类效果;而引入文本条件聚合则显著提升了跟踪稳定性,具体表现为平均多目标跟踪精度(AMOTA)和召回率(Recall)的提升。
表7进一步展示了这些设计对预测和规划结果的影响。集成所有所提模块后,模型在轨迹预测任务中的最小平均位移误差(minADE)和最小最终位移误差(minFDE)最低,且规划精度最高、各时间步的碰撞率均降低。特别是文本条件聚合和交叉注意力机制的引入,使模型能更有效地利用上下文信息,从而实现更安全、更准确的运动规划。
总体而言,消融实验结果清晰表明:在OmniScene中,多模态文本线索、时空注意力模块与细化策略的结合,是其在复杂城市驾驶环境中实现感知-规划全流程均衡且优异性能的关键。
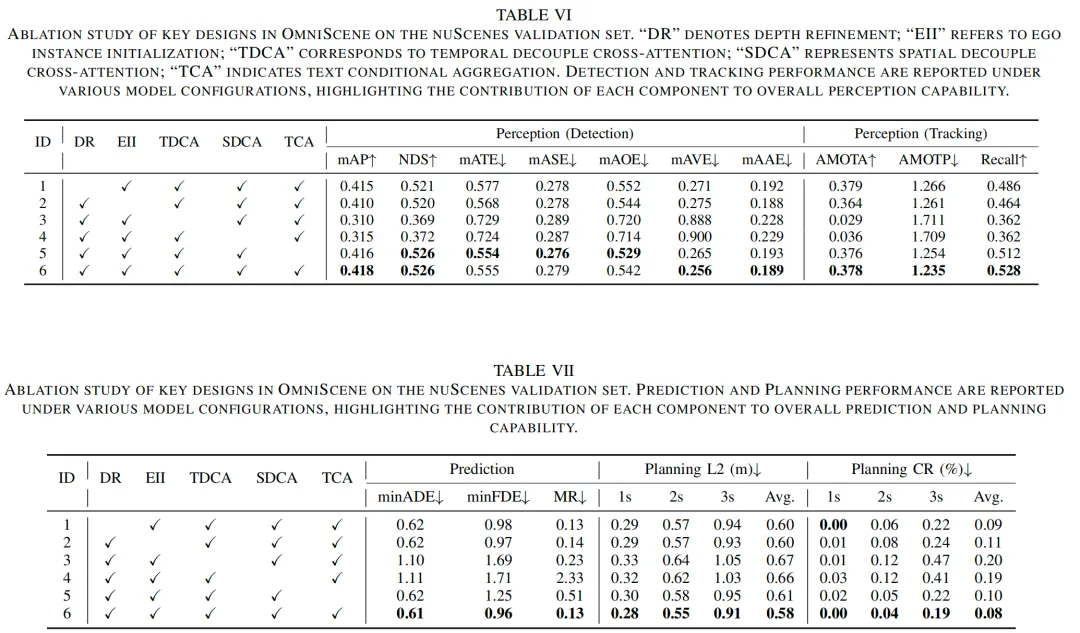
2)多模态运动规划的讨论
表8展示了多模态运动规划中轨迹模式数量的消融实验结果。随着模式数量的增加,规划精度和安全性均会受到影响:当使用6种模式时,模型性能最优,平均L2误差最低(0.58米),平均碰撞率最低(0.08%);若轨迹模式数量较少(如1种或2种),则L2误差和碰撞率会略有上升,表明运动多样性不足;反之,若使用10种模式,L2误差会显著增加至0.70米,说明模式数量过多可能引入预测不确定性,降低规划精度。这些结果表明,选择合适的轨迹模式数量对于平衡预测多样性和规划精度至关重要。
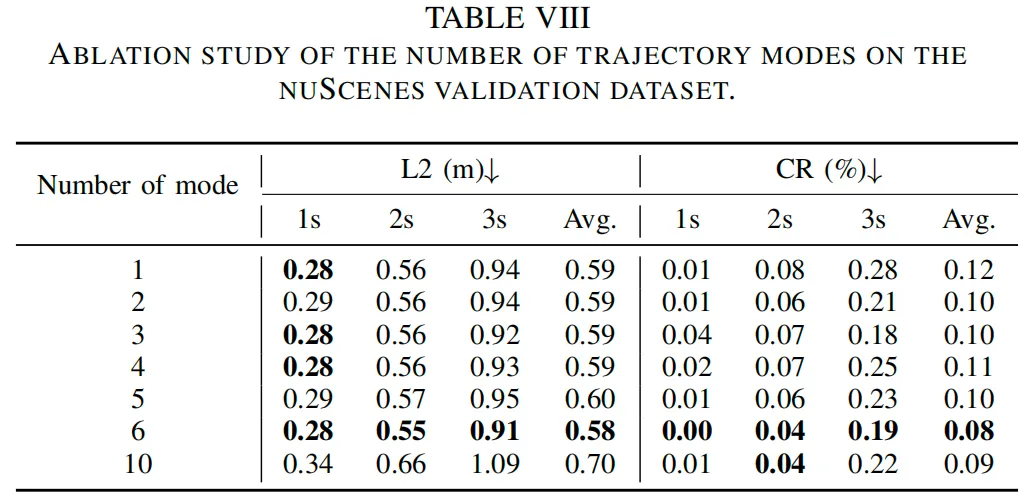
- 在其他端到端模型上的泛化性
为严格评估模型的泛化能力,本研究将文本交互引导模块集成到ST-P3中,通过融合文本特征与鸟瞰图(BEV)特征,使模型在感知和规划过程中能够同时利用语义信息和空间信息。
表9展示了该集成方案的定量结果。本研究系统地评估了感知、预测和规划性能,其中感知任务报告了车辆和行人的交并比(IoU),预测任务报告了交并比(IoU)、全景质量(PQ)、分割质量(SQ)和识别质量(RQ),规划任务则评估了1秒、2秒和3秒时的L2位置误差及对应时间域的碰撞率。
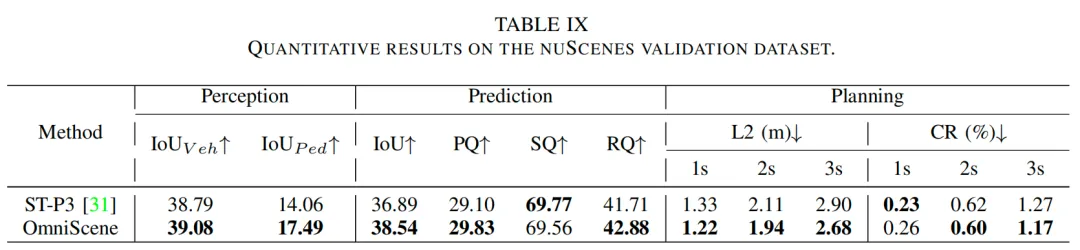
引入文本交互引导模块后,ST-P3在大多数指标上均有显著提升:感知任务中,车辆和行人的交并比(IoU)以及整体IoU均有所提高;预测任务中,交并比(IoU)、全景质量(PQ)和识别质量(RQ)均有性能提升,分割质量(SQ)保持稳定;规划任务中,增强后的模型在所有时间步的L2误差均降低,轨迹预测精度更高,且2秒和3秒时的碰撞率降低,表明其在较长时域内的规划安全性更优。
为进一步直观展示这些改进,图7呈现了nuScenes数据集中的4个复杂场景。在所有场景中,ST-P3的未来预测结果均存在错误,而所提方法生成的轨迹与道路布局高度吻合,预测准确。具体而言,在第1、3和最后一个场景中,ST-P3错误地预测了右转、直行和静止意图,而自车实际正在执行左转、停车和直行操作;相比之下,所提方法借助模块提供的基于注意力的文本监督,准确预测了这些场景下的控制动作。这些结果凸显了仅依赖鸟瞰图(BEV)特征进行未来动作预测的局限性,同时证明了引入文本引导所带来的互补优势。
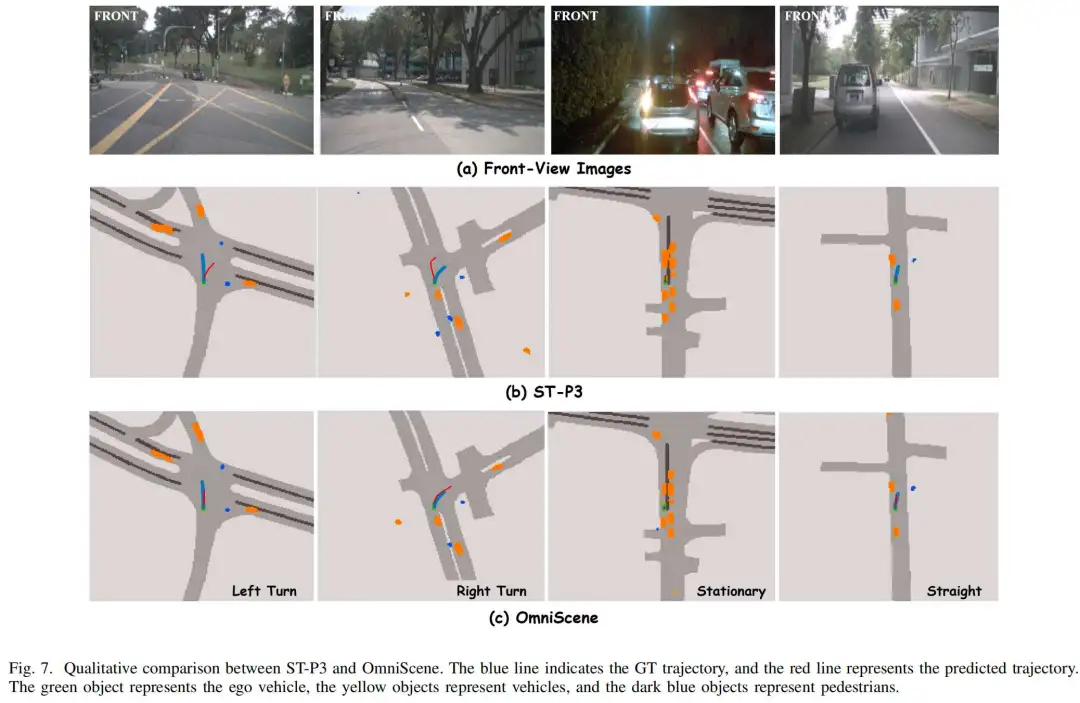
综合来看,定量和定性结果均验证了所提文本交互引导模块在ST-P3上的泛化能力和有效性,凸显了其在提升端到端自动驾驶模型感知和规划性能方面的潜力。
- 实时性能评估
实验设置如下:在单块A800 GPU上测试OmniVLM 7B和3B模型,在两块A800 GPU上评估Qwen25VL 32B模型。如表10所示,OmniVLM 3B模型在输入和输出速度上均较Qwen25VL 32B有显著提升,输入速度提升约3.51倍,输出速度提升约2.33倍,充分体现了其在处理复杂多模态输入和快速生成输出方面的效率优势。在A800平台上,OmniVLM 3B模型表现出色:仅需88毫秒即可处理300个输入令牌,且在输出令牌限制为10-20个时能高效生成结果。尽管Qwen25VL 32B在两块A800 GPU上测试,但其计算效率仍落后于OmniVLM 3B。OmniVLM 3B的总处理时间在113毫秒到139毫秒之间,与路径优化、障碍物检测或碰撞避免等应用的实时性要求高度契合。因此,该模型可作为自动驾驶系统中实时任务的即插即用模块,实现处理速度和通信效率的平衡。
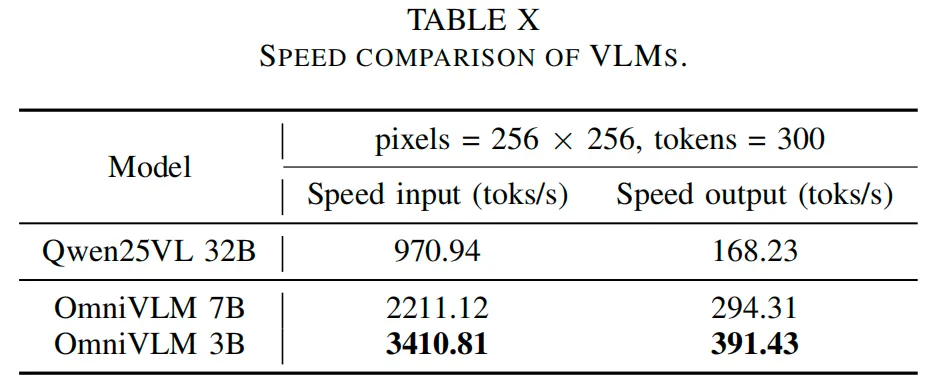
六、结论
本研究提出了OmniScene------一种用于端到端自动驾驶的注意力增强型多模态4D场景理解框架。该框架将几何感知3D推理与视觉-语言建模中的高层4D语义抽象相结合,并通过分层融合和类人注意力机制实现二者的对齐,最终生成统一、可解释的场景表示,从而提升复杂驾驶环境下的感知、预测和规划能力。
借助教师-学生OmniVLM设计,该框架能将细粒度注意力知识高效迁移到轻量级模型中,在不损失性能的前提下实现部署。在nuScenes基准数据集上开展的大量实验表明,相比当前最优基线模型,OmniScene取得了显著的性能提升,充分证明了类人对齐多模态融合在安全关键型推理中的有效性。
未来工作将围绕以下方向展开:一是探索在OmniScene范式内实现更广泛的多模态融合;二是研究在长尾分布和罕见交通场景下提升模型泛化能力的策略。
...
#AnchDrive
一种新端到端自动驾驶扩散策略(上大&博世)
端到端多模态规划已成为自动驾驶领域的变革性范式,能有效应对行为多模态问题及长尾场景下的泛化挑战。
本文提出端到端框架AnchDrive,该框架可有效引导扩散策略(diffusion policy),以降低传统生成模型的高计算成本。
与从纯噪声开始去噪不同,AnchDrive利用丰富的混合轨迹锚点(hybrid trajectory anchors)为规划器初始化。这些锚点来源于两个互补的数据源:一是包含通用驾驶先验知识的静态词汇表,二是一组动态的、具备情境感知能力的轨迹。其中,动态轨迹由Transformer实时解码生成,该Transformer可处理密集型与稀疏型感知特征。随后,扩散模型通过学习预测轨迹偏移分布来优化这些锚点,从而实现精细化调整。这种基于锚点的引导式设计,能够高效生成多样化、高质量的轨迹。在NAVSIM基准测试中的实验表明,AnchDrive达到了新的性能上限(state-of-the-art),并展现出强大的泛化能力。
- 论文标题:AnchDrive: Bootstrapping Diffusion Policies with Hybrid Trajectory Anchors for End-to-End Driving
- 论文链接:https://arxiv.org/abs/2509.20253
一、引言
近年来,端到端自动驾驶算法受到广泛关注,其相较于传统基于规则的运动规划方法,具有更优的可扩展性与适应性。这类方法通过直接从摄像头图像、激光雷达(LiDAR)点云等原始传感器数据中学习控制信号,绕过了模块化设计流程的复杂性,减少了感知误差的累积,并提升了系统整体的一致性与鲁棒性。
早期的端到端规划器(包括UniAD、VAD和Transfuser)依赖自车查询(ego queries)来回归单模态轨迹;而近年来的方法(如SparseDrive)则探索将稀疏感知模块与并行运动规划器相结合。然而,在交叉路口、高速变道等复杂交通场景中,车辆的潜在行为可能具有高度模糊性与多样性。若忽略驾驶行为固有的不确定性,以及环境感知所要求的多模态决策需求,仅依赖单一预测轨迹往往会导致预测结果过度自信,甚至完全失效。
因此,近期研究开始整合多模态建模策略,生成多个符合当前场景约束的轨迹提案,以提升决策覆盖率。VADv2和HydraMDP等方法通过采用预定义的离散轨迹集实现这一目标。尽管这种方式在一定程度上提高了覆盖率,但对固定轨迹集的依赖会将本质上连续的控制过程离散化,进而限制模型的表达性与灵活性。
扩散模型(diffusion models)已成为一种极具潜力的替代方案,其具备的生成能力与自适应能力非常适合多模态轨迹规划。该模型能够直接从自车与周围智能体轨迹的高维联合分布中采样,且在高维连续控制空间中展现出强大的建模能力------这一点已在图像合成、机器人运动规划等领域的成功应用中得到验证。扩散模型能够自然地对条件分布进行建模,因此可轻松整合轨迹历史、地图语义、自车目标等关键上下文输入,从而提升策略生成过程中的一致性与情境相关性。此外,与许多基于Transformer的架构不同,扩散模型在测试阶段可通过可控采样加入额外约束,无需重新训练模型。
尽管存在如DDIM等用于加速采样的改进方法,但传统扩散模型仍需经过多次迭代去噪步骤,导致推理过程中产生较高的计算成本与延迟成本。为解决这一问题,以往研究表明,利用先验信息从非标准噪声分布开始初始化生成过程,可缩短采样路径。基于这一思路,DiffusionDrive提出了一种截断扩散策略(truncated diffusion strategy),将生成过程锚定到一组固定的轨迹锚点上,使采样可从中间状态开始,从而减少所需的迭代次数。然而,此类固定锚点集缺乏灵活性,无法适应需要动态生成锚点的场景。
针对这一局限,本文提出新型端到端多模态自动驾驶框架AnchDrive。该框架采用多头轨迹解码器,结合场景感知信息动态生成一组动态轨迹锚点,以捕捉局部环境条件下的行为多样性。同时,本文从大规模人类驾驶数据中构建了一个覆盖范围广泛的静态锚点集,为模型提供跨场景的行为先验知识。其中,动态锚点能为当前场景提供符合情境的引导,而静态锚点集则可缓解模型对训练分布的过拟合问题,提升模型在未见过环境中的泛化能力。通过利用这一混合锚点集,基于扩散模型的规划器能够在减少去噪步骤的同时,生成高质量、多样化的预测轨迹。
本文在Navsim-v2仿真平台上以闭环方式对AnchDrive进行评估,该平台包含具有反应性的背景交通智能体与高保真度合成多视角图像。在navtest测试集上的实验结果显示,AnchDrive的扩展预测驾驶模型评分(EPDMS)达到85.5,表明其在复杂驾驶场景中能够生成稳健且符合情境的行为。
本文的主要贡献如下:
- 提出端到端自动驾驶框架AnchDrive,该框架采用从混合轨迹锚点集初始化的截断扩散过程。这种整合动态与静态锚点的方法,显著提升了初始轨迹质量,并实现了稳健的规划。在具有挑战性的Navsim-v2基准测试中,该方法的有效性得到了验证。
- 设计了包含密集分支与稀疏分支的混合感知模型。其中,密集分支构建鸟瞰图(BEV)表征,作为规划器的主要输入;稀疏分支则提取实例级线索(如检测到的障碍物、车道边界、车道中心线、停止线等),以增强规划器对障碍物与道路几何结构的理解。
二、相关工作回顾端到端自动驾驶
近年来,端到端自动驾驶算法因其相较于传统基于规则的运动规划方法具有更优的可扩展性和适应性,受到了广泛关注。这类方法通过直接从原始传感器数据(如相机图像或激光雷达点云)中学习控制信号,绕过了模块化设计流程的复杂性,减少了感知误差的累积,并提升了系统整体的一致性和鲁棒性。
早期的端到端规划器(如UniAD、VAD和Transfuser)依赖自车查询来回归单模态轨迹,而近年来的方法(如SparseDrive)则探索了将稀疏感知模块与并行运动规划器相结合的方案。然而,在复杂交通场景下(如交叉路口或高速变道),车辆的潜在行为可能具有高度模糊性和多样性。若忽视驾驶行为固有的不确定性以及环境感知所要求的多模态决策需求,仅依赖单一预测轨迹往往会导致预测结果过度自信,甚至完全失效。
因此,近期研究开始融入多模态建模策略,生成多个符合当前场景约束的轨迹候选方案,以提升决策覆盖范围。VADv2和HydraMDP等方法通过使用预定义的离散轨迹集实现这一目标。尽管这种方式在一定程度上扩大了覆盖范围,但对固定轨迹集的依赖本质上会将原本连续的控制过程离散化,从而限制了模型的表达能力和灵活性。
扩散模型已成为一种颇具潜力的替代方案,其具备的生成能力和自适应能力非常适合多模态轨迹规划。该模型能够直接从自车与周围智能体轨迹的高维联合分布中采样,并且在高维连续控制空间中展现出强大的建模能力------这一点已在图像合成、机器人运动规划等领域的成功应用中得到验证。扩散模型天然具备建模条件分布的能力,这使得整合关键上下文输入(包括轨迹历史、地图语义和自车目标)的过程变得简单直接,进而提升了策略生成过程中的一致性和上下文相关性。此外,与许多基于Transformer的架构不同,扩散模型在测试时可通过可控采样引入额外约束,而无需重新训练。
尽管已有诸如DDIM等用于加速采样的改进方案,但传统扩散模型仍需大量迭代去噪步骤,导致推理阶段的计算成本和延迟较高。为解决这一问题,先前的研究表明,利用先验信息从非标准噪声分布初始化生成过程,可缩短采样路径。基于这一思路,DiffusionDrive提出了一种截断扩散策略,将生成过程锚定于一组固定的轨迹锚点,使采样能从中间状态开始,从而减少所需的迭代次数。然而,此类固定锚点集缺乏灵活性,无法适应需要动态生成锚点的场景。
本文提出的AnchDrive正是为解决这一局限而设计的新型端到端多模态自动驾驶框架。AnchDrive采用多头部轨迹解码器,结合场景感知动态生成一组动态轨迹锚点,以捕捉局部环境条件下的行为多样性。同时,我们从大规模人类驾驶数据中构建了一个覆盖范围广泛的静态锚点集,提供跨场景的行为先验。这些动态锚点能为当前场景提供量身定制的上下文感知引导,而静态锚点集则可缓解模型对训练分布的过拟合,提升对未见过环境的泛化能力。通过利用这一混合锚点集,我们基于扩散的规划器能够在减少去噪步骤的同时,生成高质量、多样化的预测结果。
我们在Navsim-v2仿真平台的闭环设置下对AnchDrive进行了评估,该平台包含具有反应性的背景交通智能体和高保真合成多视角图像。在navtest测试集上的实验表明,AnchDrive的扩展预测驾驶模型得分(EPDMS)达到85.5,证明其在复杂驾驶场景中能够生成稳健且符合上下文的行为。
本文的主要贡献如下:
- 提出AnchDrive这一端到端自动驾驶框架,该框架采用从混合轨迹锚点集初始化的截断扩散过程。这种整合动态锚点与静态锚点的方法,显著提升了初始轨迹质量,并实现了稳健的规划。我们在具有挑战性的Navsim-v2基准测试中验证了其有效性。
- 设计了包含密集分支与稀疏分支的混合感知模型。密集分支构建鸟瞰图(BEV)表征,作为规划器的主要输入;稀疏分支则提取实例级线索(如检测到的障碍物、车道边界、中心线和停止线),以增强规划器对障碍物和道路几何结构的理解。
用于轨迹预测的扩散模型
扩散模型在轨迹预测中的应用已展现出捕捉多模态行为的巨大潜力。在行人预测领域,开创性工作(如MID)将预测重构为反向扩散过程,而LED则引入加速技术以直接学习多模态分布。然而,这些模型并未充分解决车辆运动的复杂性------车辆运动涉及复杂的交互作用以及对交通规则的遵守。
为填补这一空白,后续研究将这些原理适配于车辆轨迹预测。DiffusionDrive引入了动作条件去噪策略,以生成多样化且符合场景的轨迹。在此基础上,DriveSuprim实现了一种从粗到细的框架:首先生成轨迹先验,然后通过基于环境语义和导航意图的条件扩散对其进行优化。这些分层方法提升了采样效率,并为建模丰富的轨迹分布提供了规范化途径,克服了回归类方法中常见的"均值坍缩"问题,为运动规划奠定了稳健的基础。
三、算法详解
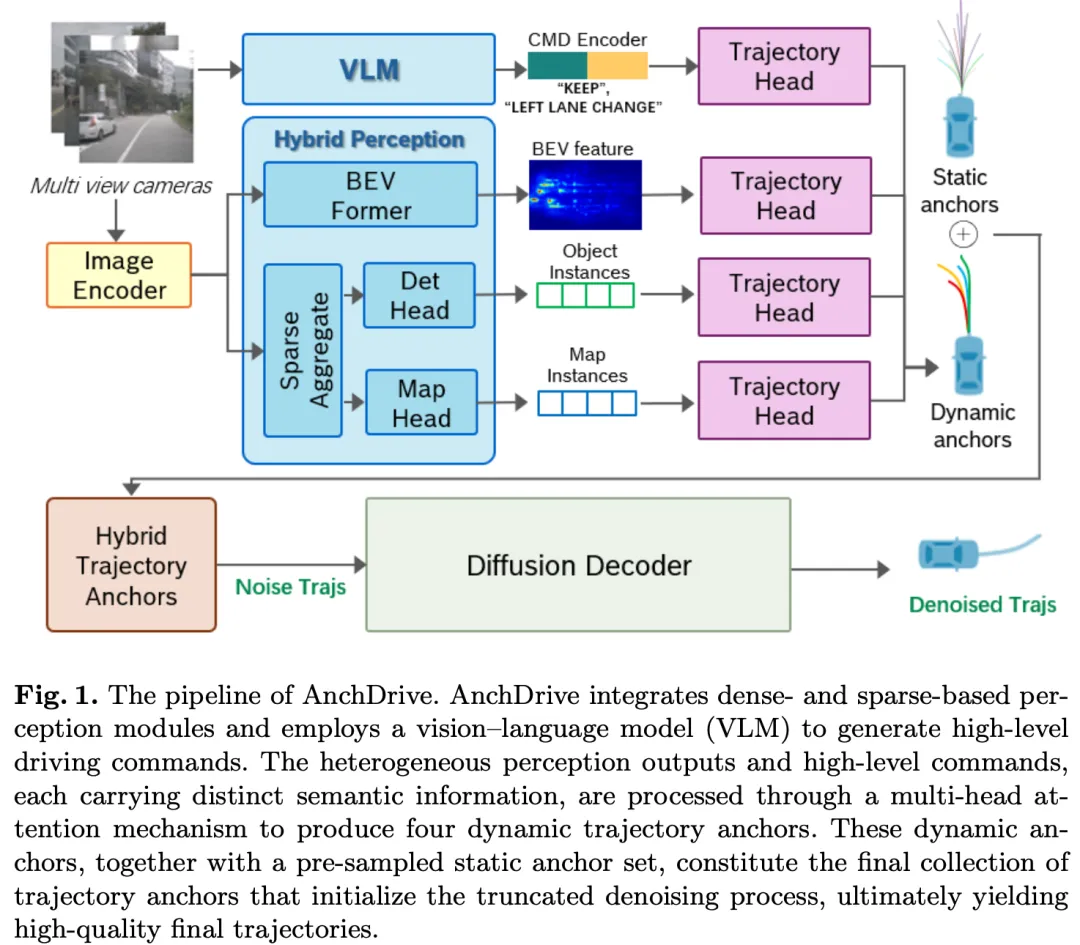
本节将拆解模型架构,并详细分析其各组成部分。模型整体架构如图1所示。
混合感知
感知模块的设计理念是将环境的隐式上下文与显式结构信息协同结合,为下游规划任务提供对场景全面且稳健的理解。为此,我们的架构包含两个并行分支:用于隐式特征提取的密集感知分支,以及用于显式实体识别的稀疏感知分支。
密集感知分支
密集感知分支旨在构建周围环境的整体统一表征。该分支采用基于投影的方法,将多视角相机图像的特征转换为单一的BEV视角。我们生成一个128×128网格的BEV特征图,覆盖自车坐标系下64×64米的区域。这种密集特征图作为主要的上下文输入,为后续规划模块提供了丰富的、关于场景纹理和空间关系的隐式引导。
稀疏感知分支
与之互补的是,稀疏感知分支负责从场景中精确提取关键的实例级实体。该分支采用基于采样的策略,执行两项关键任务:3D目标检测和在线高精地图矢量化。其输出具有结构化和显式的特点,具体包括:1)带属性(如位姿、尺寸、朝向和速度)的3D目标边界框;2)矢量化地图元素(如车道边界、路缘和停止线),每个元素均用点序列表示。这些结构化输出随后通过多层感知机(MLP)编码,生成独特的目标嵌入和地图嵌入。
这种双分支设计的核心优势在于其协同作用。密集BEV为规划器提供了对场景的整体隐式理解,而稀疏分支的显式输出则承担双重作用:不仅作为强有力的特征输入,提升规划器对特定实体(如障碍物和车道)的感知能力,还可直接用于下游任务(如精确碰撞检测和可行驶区域验证)。这种融合了学习到的隐式模式与显式几何约束的混合范式,克服了单模态感知的局限性,为规划决策提供了更丰富、更可靠的基础。
扩散策略
诸如去噪扩散概率模型(DDPM)之类的扩散模型,已成为一类强大的深度生成模型,擅长捕捉复杂的多模态数据分布。这种能力使其天然适合建模自动驾驶行为中固有的不确定性和多模态特性。扩散模型的核心原理包含两个阶段:向数据逐步添加噪声的固定前向过程,以及通过去噪重建数据的学习反向过程。
在前向过程中,干净轨迹会在T个离散时间步内被逐步添加高斯噪声,直至变为纯噪声。任意时间步t的带噪轨迹(记为)可通过以下公式直接采样得到:
其中
式中,服从均值为0、协方差矩阵为单位矩阵的高斯分布;是预定义的噪声调度表,用于控制每个时间步的信噪比。
反向过程的目标是训练一个去噪网络,该网络基于当前带噪轨迹、时间步,以及关键的上下文条件来预测添加的噪声ε。在本文应用中,条件包含从感知模块提取的信息,如BEV特征、道路拓扑和动态障碍物。这一设计将去噪器转化为条件策略。在推理阶段,该策略通过从初始状态开始,在条件的引导下迭代应用学习到的去噪函数,生成轨迹,最终恢复出干净且可行的轨迹。
用于初始化扩散的混合轨迹锚点
传统扩散模型在实时自动驾驶中部署的主要障碍,在于其从纯噪声开始的迭代去噪过程会产生高昂的计算成本。为解决这一局限,我们提出一种初始化扩散策略,该策略利用一组高质量、上下文感知的轨迹锚点。我们的方法并非遍历完整的去噪链,而是从精心挑选的锚点集初始化过程,仅执行最终的优化阶段,从而在保持生成轨迹保真度的同时,显著提升推理效率。
这种混合锚点集通过动态整合两个互补来源构建而成:
动态轨迹锚点
为生成兼具上下文相关性和驾驶意图一致性的锚点,我们设计了一个多头部解码器,该解码器处理四个异质输入流(每个流编码不同的语义信息):(1)整体BEV场景表征;(2)显著实例的稀疏、目标中心特征;(3)捕捉道路拓扑的高精(HD)地图特征;(4)来自视觉-语言模型(VLM)的高层导航指令。这些输入通过多头注意力机制整合后,传递至四个并行的轨迹头部,每个头部生成一个独特的动态锚点。这种架构支持多样化的意图建模------例如,一个头部可能优先遵循VLM发出的"左转"指令,而另一个头部则专注于避开附近的障碍物。
静态锚点与混合集融合
为缓解模型对频繁出现的训练场景的过拟合,并提升对新环境的泛化能力,我们额外采用了一个从大规模人类驾驶数据中预采样的静态锚点集。该集合编码了关于多样化驾驶行为的广泛先验知识。在推理阶段,动态生成的锚点与该静态锚点集融合,形成最终的、全面的轨迹锚点集合,该集合同时实现了广泛的覆盖范围和高度的多样性。
基于锚点的轨迹优化
这种融合后的锚点集作为扩散模型的初始化输入。模型并非从头合成轨迹,而是预测真值与最近的高质量锚点之间的残差偏移------这一过程类似于YOLO等目标检测框架中的锚框优化。
该设计具有三个显著优势:(1)效率------从高质量锚点初始化可大幅减少去噪步骤,满足实时规划严苛的延迟要求;(2)性能------通过将生成能力集中于细粒度优化(而非从头生成),模型实现了更高的轨迹精度;(3)鲁棒性------动态锚点(场景特定适配)与静态锚点(通用先验覆盖)之间的协同作用,显著提升了模型在复杂驾驶场景中的鲁棒性和多模态预测性能。
四、实验结果分析
本节首先展示AnchDrive在NAVSIM v2 navtest基准测试集上的性能表现,接着通过消融实验验证所提模块的有效性,最后提供一系列可视化案例以阐明本方法的优势。
实现细节
实验基于NAVSIM基准测试数据集开展,该数据集是面向规划任务的驾驶数据集,源自OpenScene重新分发的nuPlan数据集。NAVSIM提供8个摄像头的360度视野覆盖以及5个传感器融合生成的激光雷达(LiDAR)点云数据,标注频率为2Hz,标注内容包括高清(HD)地图和目标边界框。该数据集侧重于包含动态驾驶意图的复杂场景,排除了静止或恒速行驶等简单场景。
评估过程采用NAVTEST基准测试集中的扩展预测驾驶模型分数(Extended Predictive Driver Model Score, EPDMS)作为评价指标。EPDMS整合了多个基于规则的子分数,可对驾驶质量进行全面评估,其数学定义如下:
其中,函数用于处理人类参考驾驶员完全遵守某条规则的情况,以避免潜在的除零问题,其定义为:
上述子分数分为两类:一类是乘法惩罚分数集合,分别对应"无责任碰撞""可行驶区域合规性""行驶方向合规性"和"交通信号灯合规性";另一类是加权平均分数集合,分别对应"碰撞时间""自车进度""历史舒适性""车道保持"和"扩展舒适性"。
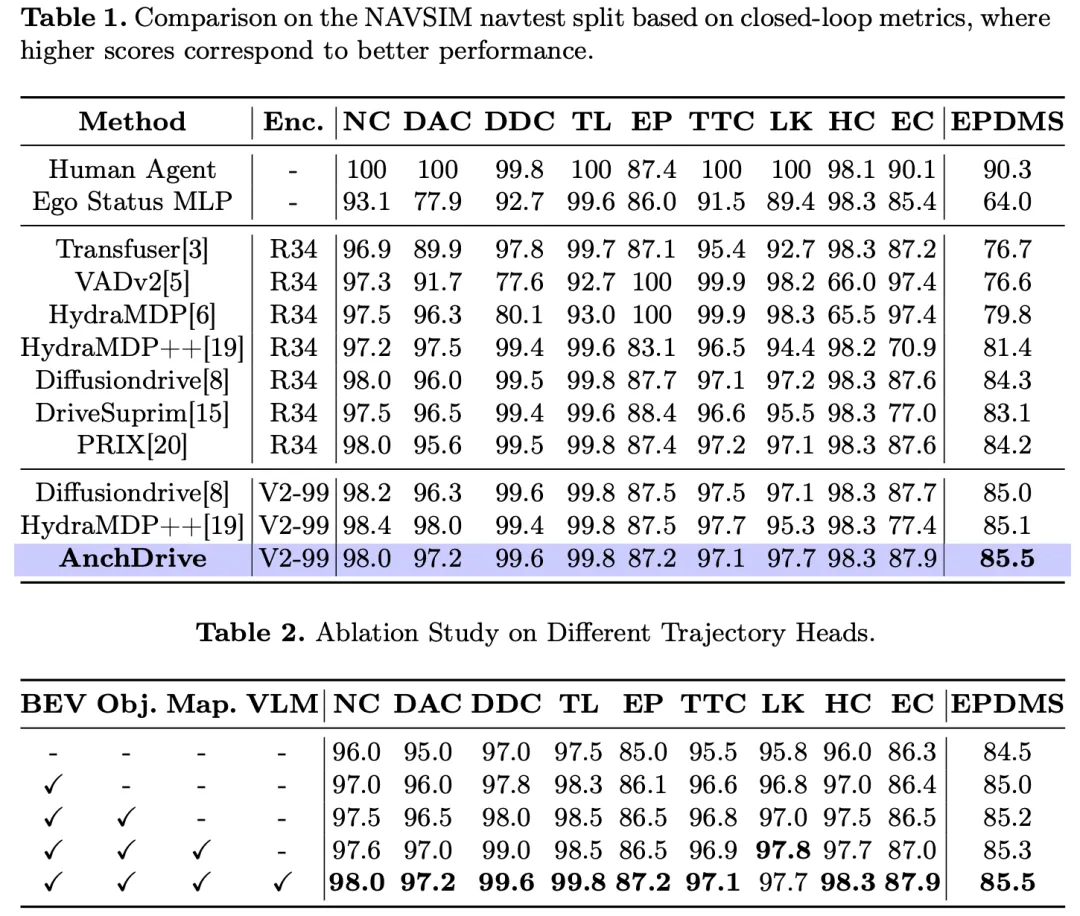
定量对比
在NAVSIM navtest数据集分割上,我们将AnchDrive与当前主流方法进行了基准测试对比。在所有仅使用摄像头(Camera-Only)的方法中,AnchDrive取得了85.5的EPDMS最高分,展现出卓越的性能。
相较于依赖大型预定义锚点词汇表的VADv2方法,AnchDrive的EPDMS分数显著提升了8.9,同时将轨迹锚点数量从8192个大幅减少至仅20个,缩减比例达400倍。这一性能优势同样适用于Hydra-MDP及其改进版本Hydra-MDP++等采用大型词汇表采样范式的方法,AnchDrive的EPDMS分数分别比这两种方法高出5.7和4.1。
此外,与同样采用截断扩散策略的基准方法DiffusionDrive(R34骨干网络)直接对比时,AnchDrive的EPDMS分数提升了1.2,且在所有子分数指标上均优于该基准方法。值得注意的是,上述所有结果均由完全端到端的模型实现,模型直接从数据中学习,未依赖任何手工设计的后处理步骤。
消融实验
表2呈现了针对动态锚点生成器各组件贡献的系统性消融实验结果。实验以不包含任何动态轨迹头的模型作为基线,当引入第一个基于BEV特征的轨迹头后,EPDMS分数实现了0.5的基础性提升。随后,融入基于目标特征的轨迹头后,NC(无责任碰撞)分数得到显著提高,这表明模型能从以目标为中心的锚点引导中有效学习避撞行为。进一步加入基于地图特征的轨迹头后,DAC(可行驶区域合规性)和DDC(行驶方向合规性)等指标均有所提升,这凸显了显式地图感知在增强模型对道路语义和结构依从性方面的关键作用。
最终,通过整合来自视觉语言模型(VLM)的高级驾驶指令,模型性能获得额外提升,EPDMS分数达到最终的85.5。
我们还针对截断扩散模型的去噪步骤数量开展了消融实验,表3的结果揭示了一个关键发现:对于从高质量候选锚点初始化的扩散过程而言,更多的去噪步骤并不一定能保证性能的单调提升,反而会不可避免地增加推理延迟。因此,为在规划性能与计算效率之间取得最佳平衡,最终版本的AnchDrive模型选择2步去噪步骤。
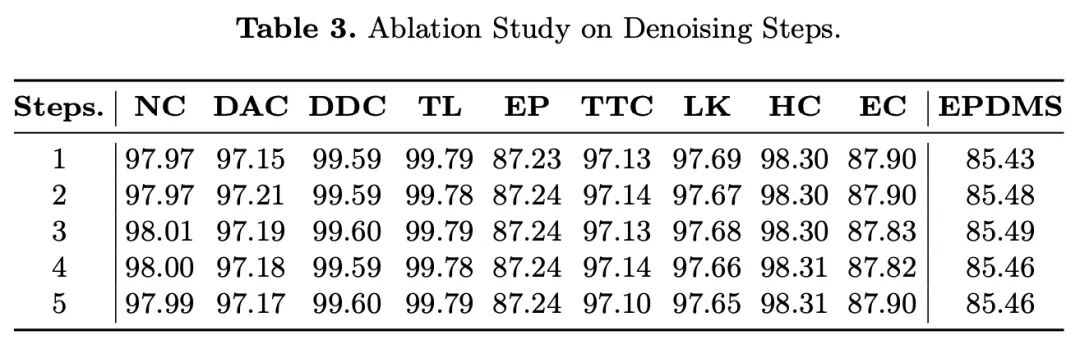
可视化
为评估AnchDrive的泛化能力与优越性,图2展示了在典型驾驶场景中的定性结果。右侧面板(b)呈现了静态锚点集的分布情况,该静态锚点集通过对nuPlan数据集进行k均值聚类得到,涵盖了多种常见的人类驾驶动作。左侧面板(a)所示的两个场景中,动态轨迹头生成的动态锚点与具体场景上下文高度相关,且所有动态生成的锚点均与真实轨迹(Ground Truth)距离较近。这种高质量的初始化使扩散模型能够高效地将锚点优化为最终轨迹,且该最终轨迹与真实轨迹几乎完全吻合。这些结果充分证明了AnchDrive在轨迹规划中的准确性与安全性,尤其在复杂的城市驾驶场景中表现突出。
五、结论
本文提出了AnchDrive------一种新型端到端自动驾驶框架,旨在高效生成多样化且安全的行驶轨迹。该框架的核心创新在于采用截断扩散策略,其扩散过程并非从纯噪声开始,而是从紧凑且高质量的混合轨迹锚点集"热启动"。
这种独特的混合锚点集通过融合两类互补的锚点生成:一类是动态锚点,由BEV特征、目标特征、地图特征和VLM指令等实时场景上下文生成;另一类是静态锚点集,包含通用驾驶先验知识。该方法使AnchDrive能够充分利用扩散模型强大的轨迹优化能力。
实验结果表明,AnchDrive在具有挑战性的NAVSIM v2基准测试集上达到了当前最佳(SOTA)性能,显著优于依赖大型固定锚点集的现有方法,同时也展现出相对于同类扩散基方法的明显优势,为运动规划领域建立了一种高效且强大的新范式。
...
#对比之后,VLA的成熟度远高于世界模型
首先需要指出VLA和世界模型都是端到端的一种,尽管很多人都认为一段式端到端比分段式优秀,但无论是产业界还是学术界,90%以上都是分段式端到端,纯粹的VLA和世界模型非常罕见。
代表VLA阵营出战的是高德地图的模型,地平线的SENNA模型,还有加州大学洛杉矶分校的AutoVLA。代表世界模型出战的有和特斯拉中国FSD很接近的上海AI实验室的GenAD模型,做重卡自动驾驶的中科慧拓的GenAD模型,华为和浙江大学合作的Drive-OccWorld,还有理想汽车的World4Drive,理想汽车尽管推崇VLA,但对世界模型的研究水平也是极高的。
端到端测试方式
目前,端到端自动驾驶领域常见的性能测试有两大类,一类是在模拟器比如CARLA中进行,规划的下一步指令可以被真实的执行,采用的是合成数据。第二类主要是在已经采集的现实数据上进行端到端研究,主要是模仿学习,参考UniAD,数据都是真实采集的。开环的缺点就是无法闭环,不能真正看到自己的预测指令执行后的效果。由于不能得到反馈,开环自动驾驶的测评极其受限制,现在文献中常用的两种指标分别是:3秒内平均L2 距离:通过计算预测轨迹和真实轨迹之间的L2距离来判断预测轨迹的质量,3秒内平均Collision Rate: 通过计算预测轨迹和其他物体发生碰撞的概率,来评价预测轨迹的安全性。数据集大部分是沿用nuScenes。
除了开环测试,闭环仿真测试主要有三家,一家是基于CARLA的,一家是nuPlan的(nuPlan既可开环,也可闭环),还有最近用的比较多的NAVSIM,NAVSIM的数据集是来自nuPlan的。
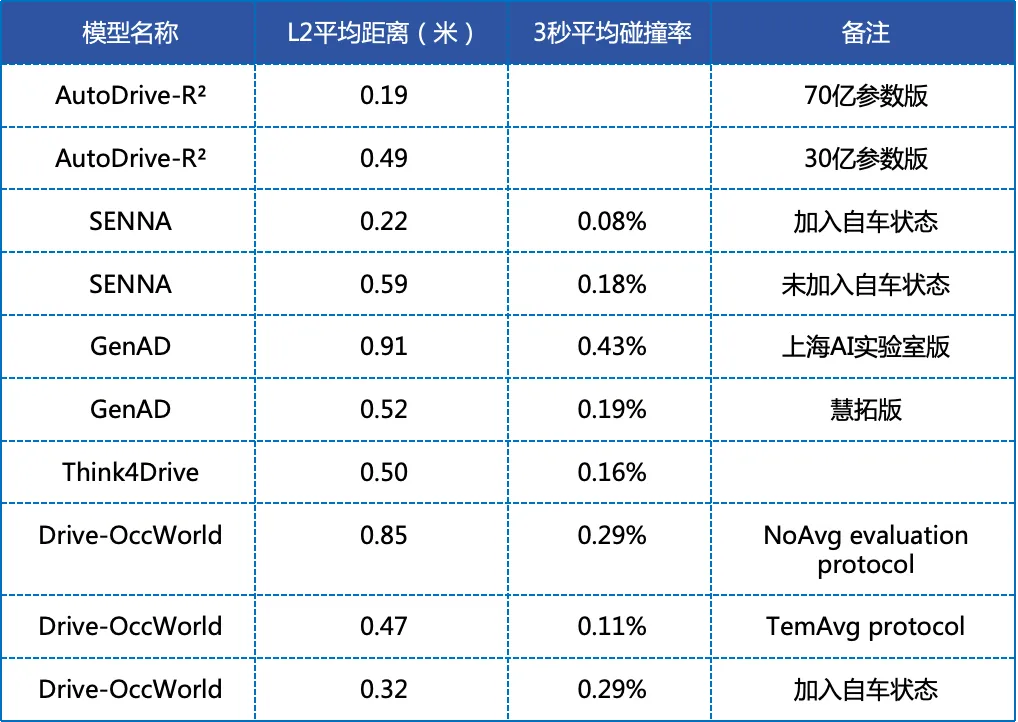
最常见的是基于nuScenes数据集的开环测试
从上表数据看,显然VLA阵营完全碾压世界模型阵营。再有就是世界模型的论文都比较早,都是2024年初的论文,因为近期几乎没有有关世界模型做自动驾驶轨迹输出的论文,用世界模型生成长尾训练视频和可控训练视频的论文倒是很多,目前最强的地平线的Epona,VLA论文则是最新的,9月份的。最后华为和浙大合作的Drive-OccWorld只是拿世界模型来预测Occ,外加了端到端规划器,不算纯粹的自动驾驶世界模型。
我们重点来看上海AI实验室的GenAD和华为浙大合作的Drive-OccWorld。
上海AI实验室的GenAD论文名称为GenAD: Generalized Predictive Model for Autonomous Driving,可能是最接近特斯拉中国FSD的模型,其最大特色是训练数据完全来自互联网,绝大部分来自YouTube,无任何标注,而马斯克曾经说过特斯拉中国FSD的训练视频数据完全来自网络。
上海AI实验室认为使用标注数据训练,也就是监督学习,还叫基于规则的,这样很难具备泛化能力。
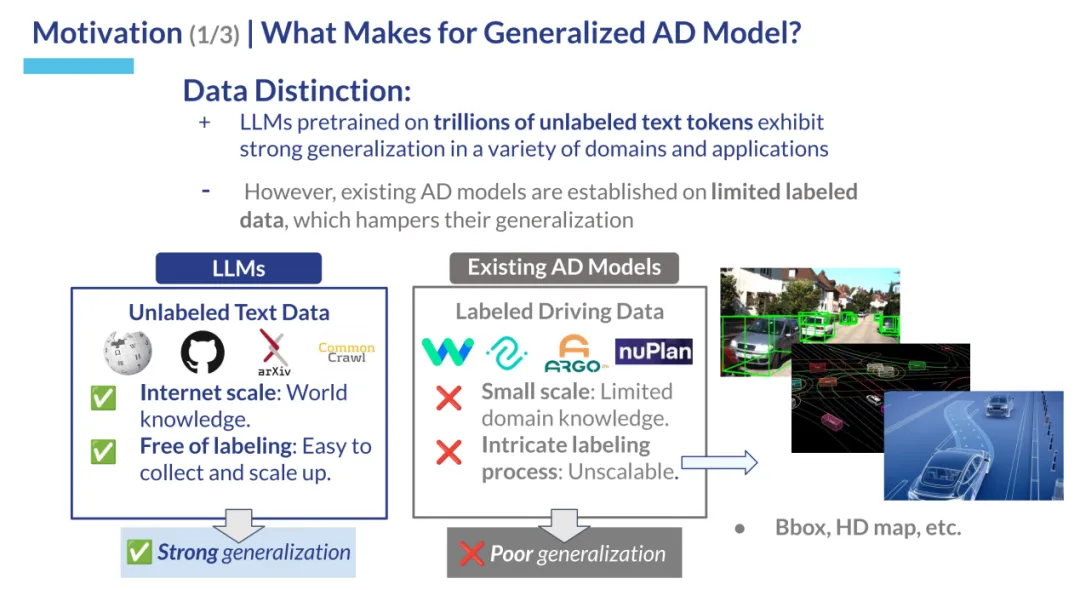
使用监督学习,难以获得强力的泛化能力

使用3D标签学习,容易忽略关键细节

海量在线驾驶视频,无3D标注,这样才能获得最强泛化能力
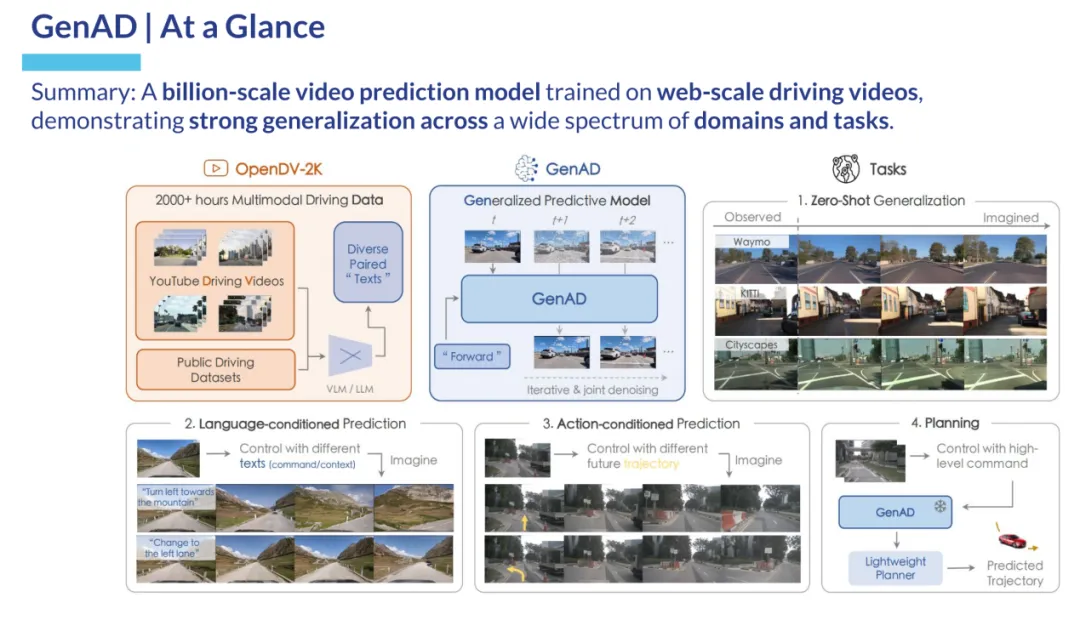
GenAD框架
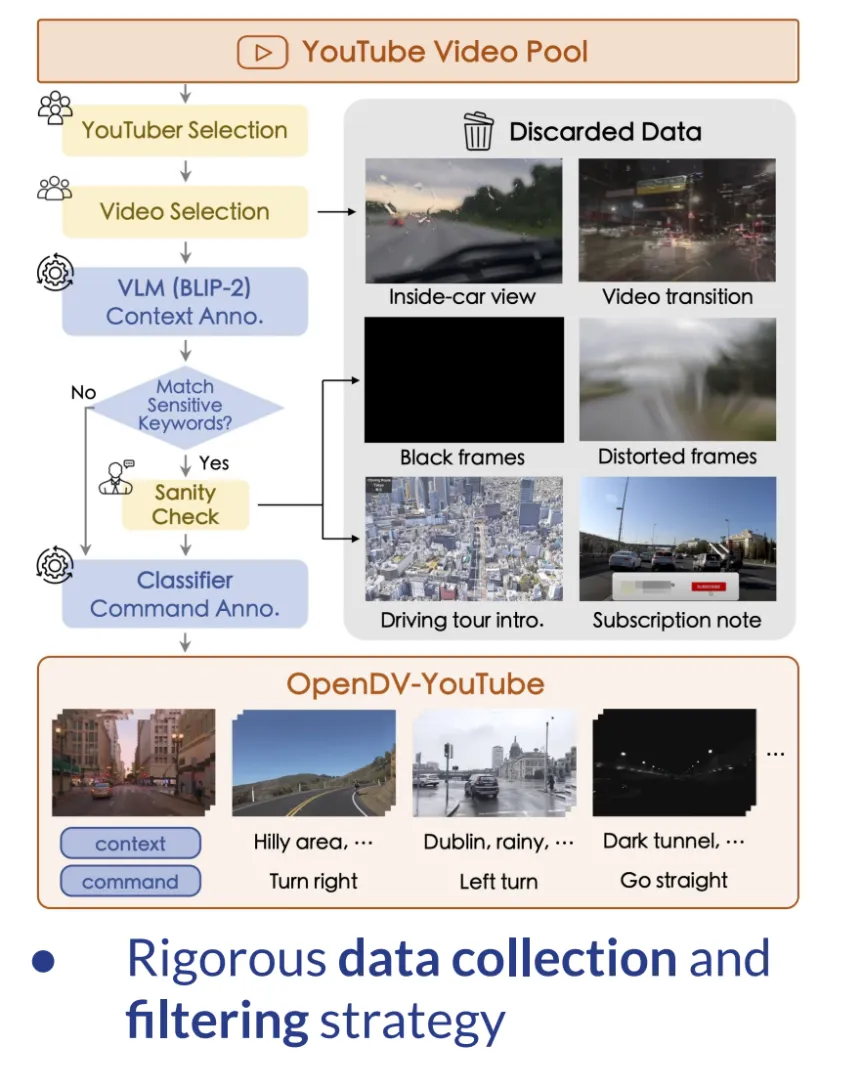
数据也不是直接拿来就用,需要经过精密过滤
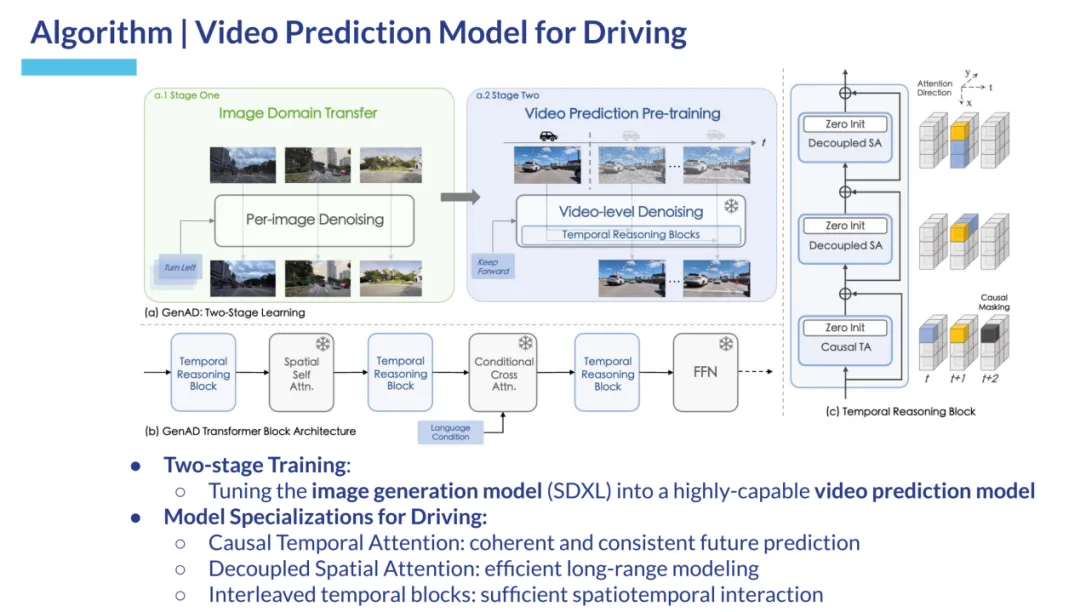
GenAD的两级训练,和特斯拉一样也是基于扩散模型,但也有Trasnformer
这种纯粹世界模型,非监督学习,很难加入人工规则也就是交通规则,必须添加一个基于高精度地图和交通规则的任务头(task head)输入,这就需要人工标注数据,不能算纯粹的世界模型了。
华为与浙大的Drive-OccWorld,论文名称为Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving,8位作者6位来自浙江大学,2位来自华为,不过与华为绝大部分论文不同的是,这2位都来自华为技术,而非常见的华为诺亚方舟实验室。
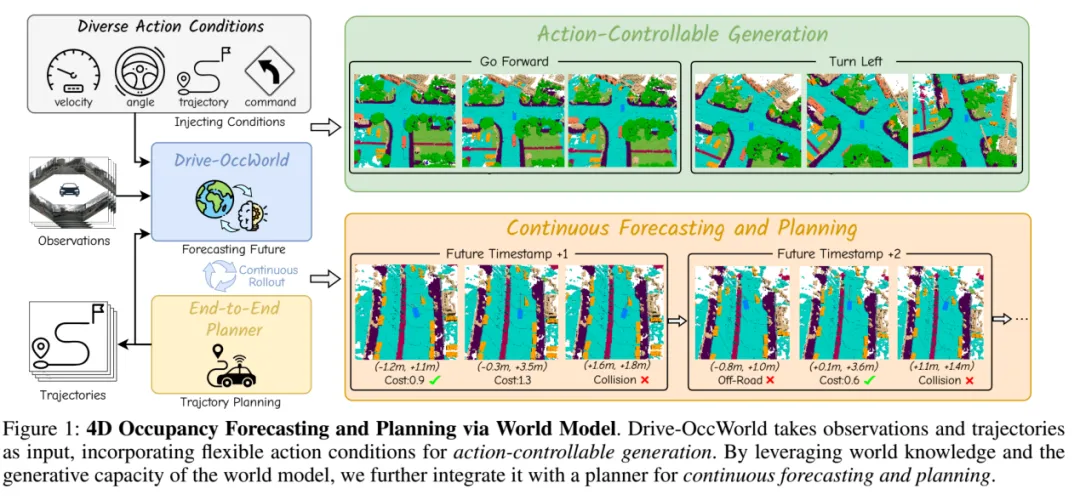
世界模型输出两个任务头,一是基于动作可控的Occ语义化栅格占用网络生成,二是基于Occ的轨迹预测,同时将真实的未来阶段轨迹输入世界模型,来不断修正世界模型。
经典的MDN-RNN世界模型
这与华为的世界模型非常接近,MDN 结合了常规的深度神经网络和高斯混合模型GMM。它在网络的输出部分引入高斯分布模型的不确定性,每个输出都是一种高斯混合分布,而非一个确定值或者单纯的高斯分布,高斯混合分布可以解决高斯分布不好解决的多值映射问题。以回归问题为例,输入和输出均是可能有多个维度的矢量。目标值的概率密度可以表示成多个核函数的线性组合。实际很接近强化学习,我们一般用的监督学习,输出单个确定值,自然需要标注训练数据,而强化学习输出概率值。最后观测和历史信息一块儿送给C得到动作,基于动作会和环境交互产生新的观测....,这样可以持续进行下去。
Drive-OccWorld包括三个组件:
(1)历史编码器WE ,它将历史相机图像作为输入,提取多视图几何特征,并将其转换为BEV嵌入。根据之前的工作,使用视觉BEV编码器作为历史编码器。
(2)具有语义和运动条件归一化的记忆队列WM ,它在潜在空间中采用简单而高效的归一化操作来聚合语义信息并补偿动态运动,从而积累更具代表性的BEV特征。
(3)世界解码器WD,其通过具有历史特征的时间建模来提取世界知识,以预测未来的语义栅格占有和流动Flow。灵活的动作条件可以注入WD,以实现可控生成。集成了基于occ的规划器P,用于连续预测和规划。
语义条件归一化概况
通过结合语义和动态信息来增强历史BEV嵌入。
端到端轨迹规划则借鉴ST-P3的代价函数聚合图。
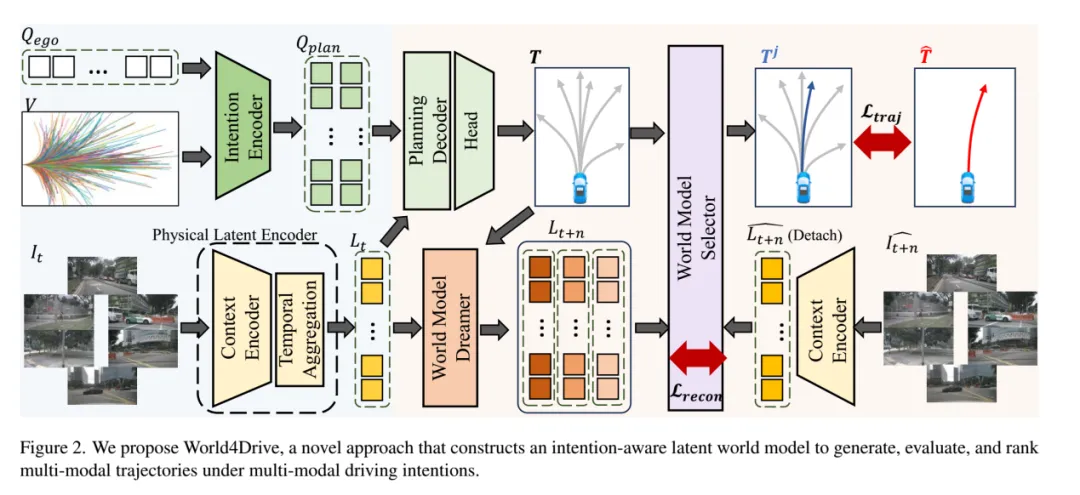
理想汽车的World4Drive框架
World4Drive包含两个关键模块:
驾驶世界编码模块中包括意图编码器和物理潜在编码器两部分。具体而言,意图编码器首先对轨迹词典中的轨迹按照终点进行K-means聚类得到意图点P,进而结合正弦位置编码得到意图查询,最后利用自注意力层获得意图感知的多模态规划查询。
上下文context编码器管线
使用了IDEA的Grounded SAM算法,获得基于深度的语义分割图,毫无疑问这需要大量3D标注数据。
世界模型选择器管线
采用交叉注意力机制将场景上下文信息引入到规划查询中,然后通过多层感知机层来得到多模态的轨迹T,在得到多模态的轨迹之后,将多层感知机作为动作编码器输出为感知意图动作令牌A。通过将动作令牌A与上文得到的世界潜在特征L沿通道的维度进行拼接,并且采用多层的交叉注意力模块预测未来结果。给定预测出来的未来感知潜在变量和真实未来潜在变量,计算二者之间的距离。其中距离最小的模态被选择作为最终的模态。
VLA的成熟度远高于世界模型,且VLA更加简洁,世界模型经过传统融合激光雷达的感知算法增强后,性能还算不错,但这也丧失了世界模型无需标注数据,泛化性能强的优点。一般来说世界模型的参数比较低,大约在10亿以下,相对VLA,部署世界模型的成本要低不少。不过加入了扩散的世界模型也非常消耗运算和存储资源,部署成本比VLA要高很多。
免责说明:本文观点和数据仅供参考,和实际情况可能存在偏差。本文不构成投资建议,文中所有观点、数据仅代表笔者立场,不具有任何指导、投资和决策意见。
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...
#xxx
...