🎯 引言:为什么需要图像标注工具
机器学习 的核心在于让计算机从数据中学习模式,而监督学习需要大量已标注的训练数据。图像标注工具就是将原始图像转换为机器可理解的训练数据的桥梁。
PaddleLabel是百度开源的图像标注平台,支持分类、检测、分割、OCR等多种计算机视觉任务的数据标注,具备Web界面、多人协作(小团队简单协作)、格式转换等企业级功能。
一、环境准备与安装
1.1 系统要求与环境创建
官方地址:doc/CN/install.md
创建独立环境 (避免依赖冲突):
bash
conda create -n paddlelabel python=3.11
conda activate paddlelabel1.2 一键安装PaddleLabel
bash
# 直接安装最新版本
pip install --upgrade paddlelabel为什么不需要安装PaddlePaddle框架?
PaddleLabel是纯标注工具,专注数据标注功能,不包含模型训练。训练时可根据需求选择PyTorch、TensorFlow或PaddlePaddle等框架。
1.3 启动与验证
bash
# 基础启动(如果启动不了报错,看1.4)
paddlelabel
# 或使用缩写
pdlabel
# 高级启动选项
paddlelabel --port 8000 --lan --debug启动参数说明:
--port 8000:指定端口号 (默认17995)--lan:允许局域网访问 (多设备协作)--debug:显示详细日志 (问题定位)
启动成功后自动打开浏览器访问 http://localhost:17995
1.4 包冲突无法启动
这一步有概率包冲突,因此我们要先按照
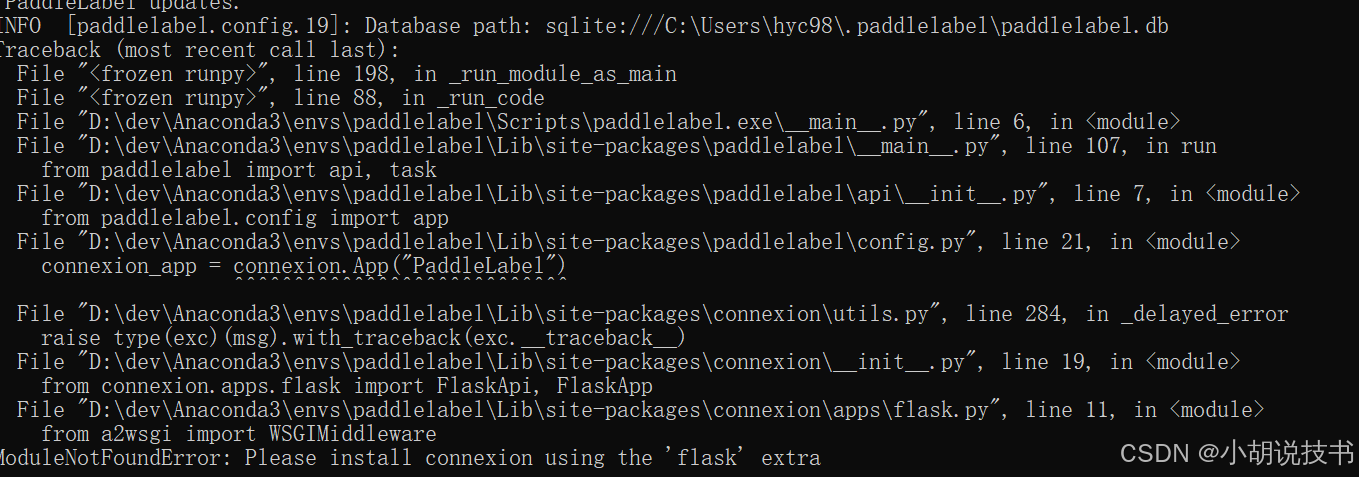
ModuleNotFoundError: Please install connexion using the 'flask' extra包括类型的init什么错误都可以按照以下包安装的方式解决。
bash
pip uninstall paddlelabel connexion marshmallow flask werkzeug -y
pip install marshmallow==3.19.0
pip install connexion==2.14.1
pip install Flask==2.2.5
pip install Werkzeug==2.2.2
pip install a2wsgi==1.8.0
pip install uvicorn==0.18.1
pip install paddlelabel
paddlelabel --port 8000 --lan --debug
其他常用命令
bash
# 查看所有环境列表
conda env list
# 1. 退出当前环境(如果在环境中)
conda deactivate
# 2. 删除环境
conda env remove -n paddlelabel启动成功。
二、计算机视觉任务类型详解
2.1 任务类型认知框架
计算机视觉任务可按输出粒度 和目标复杂度分类:
| 任务类型 | 输出粒度 | 复杂度 | 典型应用 | 标注难度 |
|---|---|---|---|---|
| 图像分类 | 图像级 | 低 | 品质检测、内容审核 | ⭐ |
| 目标检测 | 对象级 | 中 | 自动驾驶、安防监控 | ⭐⭐⭐ |
| 语义分割 | 像素级 | 高 | 医学影像、遥感分析 | ⭐⭐⭐⭐ |
| 实例分割 | 个体级 | 极高 | 机器人抓取、精密制造 | ⭐⭐⭐⭐⭐ |
| 文字识别 | 字符级 | 中高 | 票据识别、文档数字化 | ⭐⭐⭐ |
2.2 分类项目 (Classification)
什么时候使用分类?
当需要判断整张图片属于哪个类别时使用,如质量检测、内容分类、病害诊断等。
单分类 vs 多分类:
- 单分类:一张图只能属于一个类别 (互斥关系)
- 多分类:一张图可属于多个类别 (非互斥关系)
应用场景对比:
单分类示例:
├── 产品质量检测 (合格/不合格)
├── 图像清晰度分类 (清晰/模糊/失焦)
└── 动物种类识别 (猫/狗/鸟/鱼)
多分类示例:
├── 图像属性标注 (室内+明亮+现代风格)
├── 商品标签 (便宜+实用+热销)
└── 内容审核 (政治+暴力+色情)2.3 目标检测项目 (Object Detection)
什么时候使用目标检测?
当需要定位图中物体的具体位置 时使用,输出矩形边界框(Bounding Box)和类别。
核心优势:
- 同时解决"是什么"和"在哪里"问题
- 可检测多个不同类别的目标
- 计算效率高,实时性好
应用场景:
工业应用:
├── 生产线缺陷检测 (裂纹/划痕/污渍位置)
├── 自动光学检测 (元器件位置验证)
└── 智能仓储 (货物识别与定位)
生活应用:
├── 智能相册 (人脸/宠物自动标记)
├── 交通监控 (车辆/行人检测)
└── 零售分析 (顾客行为追踪)2.4 语义分割项目 (Semantic Segmentation)
什么时候使用语义分割?
当需要像素级精确分割时使用,为每个像素分配类别标签,实现精确的区域划分。
技术特点:
- 输出分辨率与输入图像相同
- 每个像素都有明确的类别归属
- 同类别像素被视为一个整体
典型应用场景:
医学影像:
├── CT扫描器官分割 (肝脏/肾脏/肺部区域)
├── X光片病变区域标注
└── 皮肤镜痣的边界分割
遥感图像:
├── 土地利用分类 (建筑/植被/水体/道路)
├── 农作物长势监测
└── 城市规划分析
工业检测:
├── 电路板区域分割 (焊点/导线/芯片区域)
├── 材料表面缺陷精确定位
└── 纺织品质量检测2.5 实例分割项目 (Instance Segmentation)
什么时候使用实例分割?
当需要区分同类别的不同个体时使用,既要像素级精确分割,又要区分个体实例。
与语义分割的关键区别:
- 语义分割:所有"人"像素标记为同一类别
- 实例分割:每个"人"分别标记为person_1, person_2, person_3
应用场景:
精密制造:
├── 重叠零件分离计数
├── 晶圆上芯片个数统计
└── 药片质量检测 (每颗单独分析)
生物医学:
├── 细胞计数与形态分析 (每个细胞独立分割)
├── 病理切片组织分析
└── 显微镜下微生物识别
智能零售:
├── 货架商品盘点 (每个商品单独计数)
├── 水果分拣 (每个果实质量评估)
└── 快餐配菜识别 (每种菜品独立识别)2.6 文字识别项目 (OCR)
什么时候使用OCR?
当需要从图像中提取文字内容时使用,将图像中的文字转换为可编辑的文本。
技术流程:文字检测 → 文字识别 → 结构化输出
应用场景分类:
文档数字化:
├── 合同/票据扫描识别
├── 手写笔记转换
└── 历史文献保护
智能办公:
├── 名片信息提取
├── 表格数据录入
└── 身份证件识别
工业自动化:
├── 产品生产日期读取
├── 仪表数值自动记录
└── 包装标签质量检测三、数据标注格式深度解析
3.1 标注格式选择决策树
分类 检测 语义分割 实例分割 OCR 自建数据集 公开数据集 传统CV 通用项目 百度生态 研究项目 选择标注格式 任务类型 单分类/多分类 数据来源 精度要求 COCO格式 TXT格式 YOLO格式 COCO格式 VOC格式 掩膜格式 EISeg Json COCO格式
3.2 分类项目格式详解
这个在项目里看吧,点击后有对应的示例。
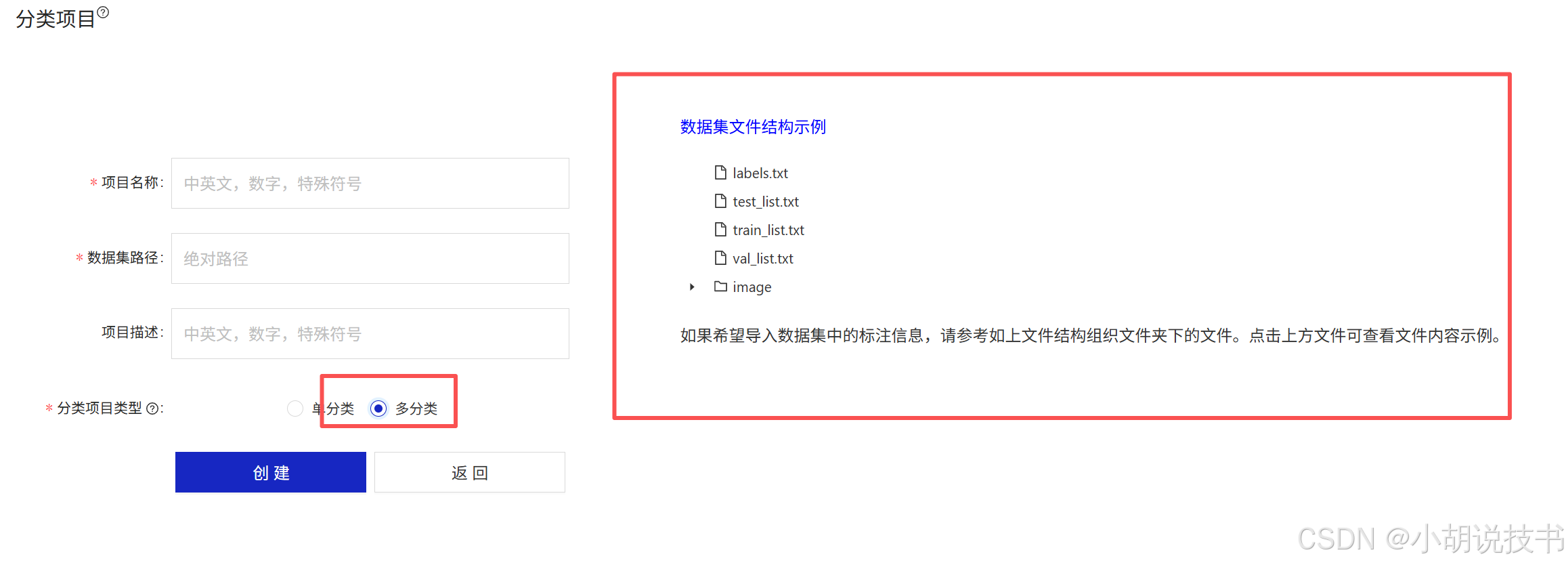
比如文字识别

点击后都有示例。

标注文件格式对比
| 格式类型 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| 文件夹分类 | 小数据集、单分类 | 直观易懂 | 不支持多标签 |
| CSV列表 | 大数据集、多分类 | 灵活性高 | 需要额外解析 |
| JSON格式 | 复杂标注信息 | 扩展性强 | 文件较大 |
3.3 目标检测格式详解
3.3.1 COCO格式 (推荐用于研究/复杂项目)
COCO(Common Objects in Context) 是微软推出的大规模目标检测数据集格式,已成为计算机视觉领域的金标准。
文件结构:
json
{
"images": [
{
"id": 1,
"file_name": "image001.jpg",
"width": 640,
"height": 480
}
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1,
"bbox": [x, y, width, height],
"area": 2400,
"iscrowd": 0
}
],
"categories": [
{
"id": 1,
"name": "person",
"supercategory": "human"
}
]
}优势:
- 工业标准,兼容性最好
- 支持复杂标注信息(分割掩膜、关键点等)
- 丰富的元数据支持
劣势:
- 文件较大,解析复杂
- 对新手不够友好
3.3.2 VOC格式 (传统经典格式)
VOC(Visual Object Classes) 是较早期的目标检测数据集格式,使用XML文件存储标注信息。
文件结构:
xml
<annotation>
<filename>image001.jpg</filename>
<size>
<width>640</width>
<height>480</height>
</size>
<object>
<name>person</name>
<bndbox>
<xmin>100</xmin>
<ymin>50</ymin>
<xmax>300</xmax>
<ymax>400</ymax>
</bndbox>
</object>
</annotation>适用场景:
- 传统计算机视觉项目
- 教学和原型开发
- 需要可读性强的标注文件
3.3.3 YOLO格式 (推荐用于工程项目)
YOLO格式采用归一化坐标,每行代表一个目标,格式简洁高效。
格式说明:
# 每行格式:class_id center_x center_y width height
0 0.5 0.3 0.2 0.4
1 0.7 0.6 0.15 0.25坐标归一化计算:
python
# 原始坐标转YOLO格式
center_x = (xmin + xmax) / (2 * image_width)
center_y = (ymin + ymax) / (2 * image_height)
width = (xmax - xmin) / image_width
height = (ymax - ymin) / image_height优势对比:
| 特性 | YOLO格式 | COCO格式 | VOC格式 |
|---|---|---|---|
| 文件大小 | 最小 | 较大 | 中等 |
| 解析速度 | 最快 | 较慢 | 中等 |
| 坐标系统 | 归一化 | 绝对坐标 | 绝对坐标 |
| 学习难度 | 简单 | 复杂 | 中等 |
| 工业应用 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
四、PaddleLabel平台操作演示
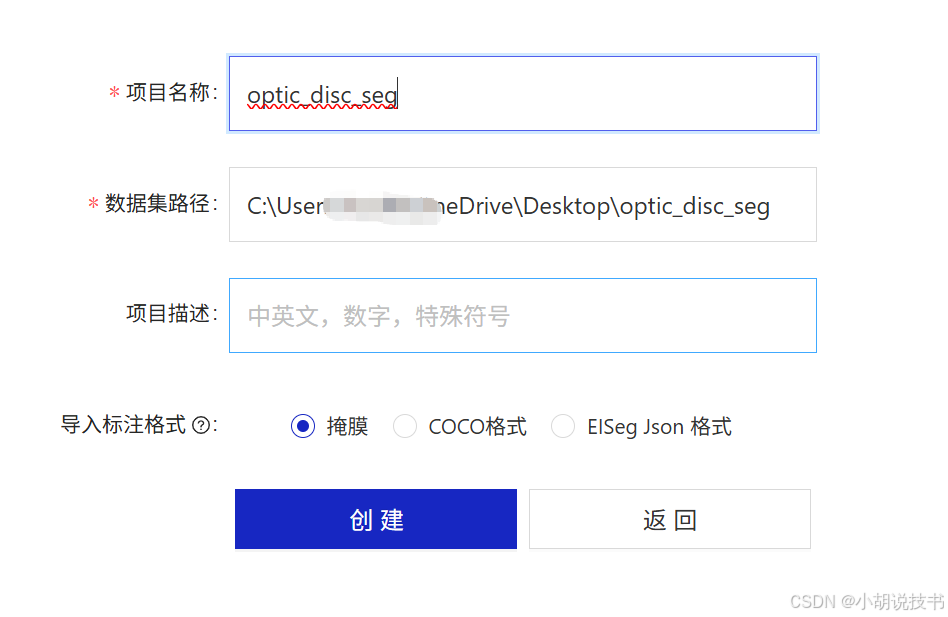
飞桨的数据集:https://paddleseg.bj.bcebos.com/dataset/optic_disc_seg.zip
眼底医疗分割数据集,包含267张训练图片、76张验证图片、38张测试图片。
这个是官方教程:https://paddlecv-sig.github.io/PaddleLabel/CN/manual/manual.html
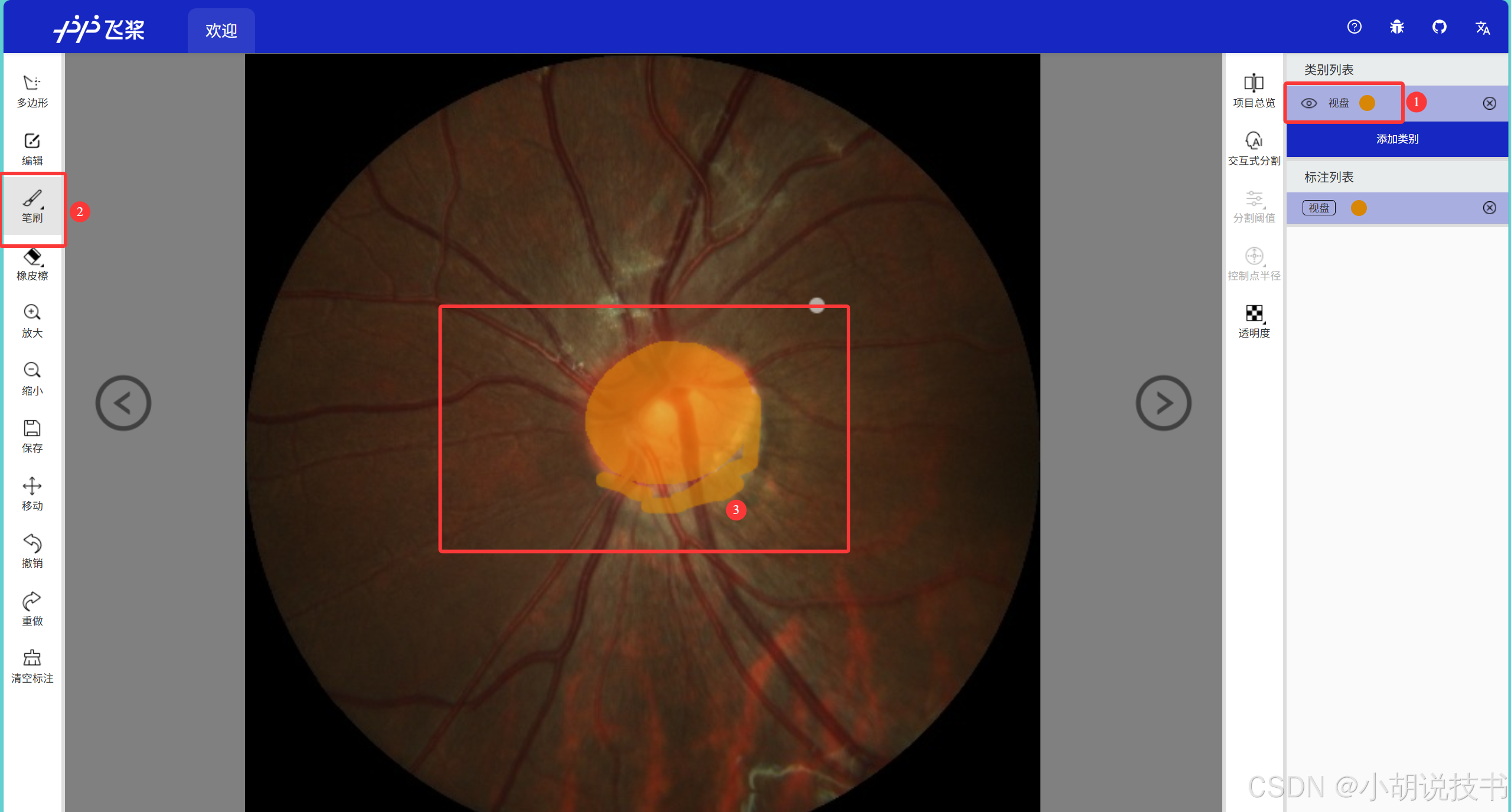
针对眼底图像的视盘分割,接下来的操作步骤如下:
标注操作流程
1. 确认标注类别
右侧面板显示了"标注列表",确认已设置好类别:
- 背景(类别0)
- 视盘(类别1,橙色区域)
2. 选择标注工具
左侧工具栏中选择合适的工具:
- 笔刷工具:用于精细标注边界
- 多功能工具:智能分割辅助
3. 开始标注
方法一:手动精确标注
- 选择"视盘"类别(右侧标注列表)
- 使用笔刷工具沿着橙色视盘边缘描绘
- 确保完全包围视盘区域
方法二:智能辅助标注
- 点击视盘中心区域作为正样本点
- 系统会自动识别相似区域
- 手动调整边界不准确的部分
4. 质量检查
- 放大图像检查边界是否准确
- 使用缩放工具查看细节
- 确保没有遗漏或多标注的区域
5. 保存标注
- 点击左侧"保存"按钮
- 系统会生成对应的掩码文件
标注技巧
- 边界处理:视盘边界要尽量准确,这直接影响模型效果
- 一致性:保持整个数据集标注风格的一致性
- 检查:标注完成后要仔细检查,避免标注错误
完成标注后,这些数据就可以用于训练PaddleSeg的语义分割模型了!
多边形的话,左键确定点,右键完成取消。
添加新的类别
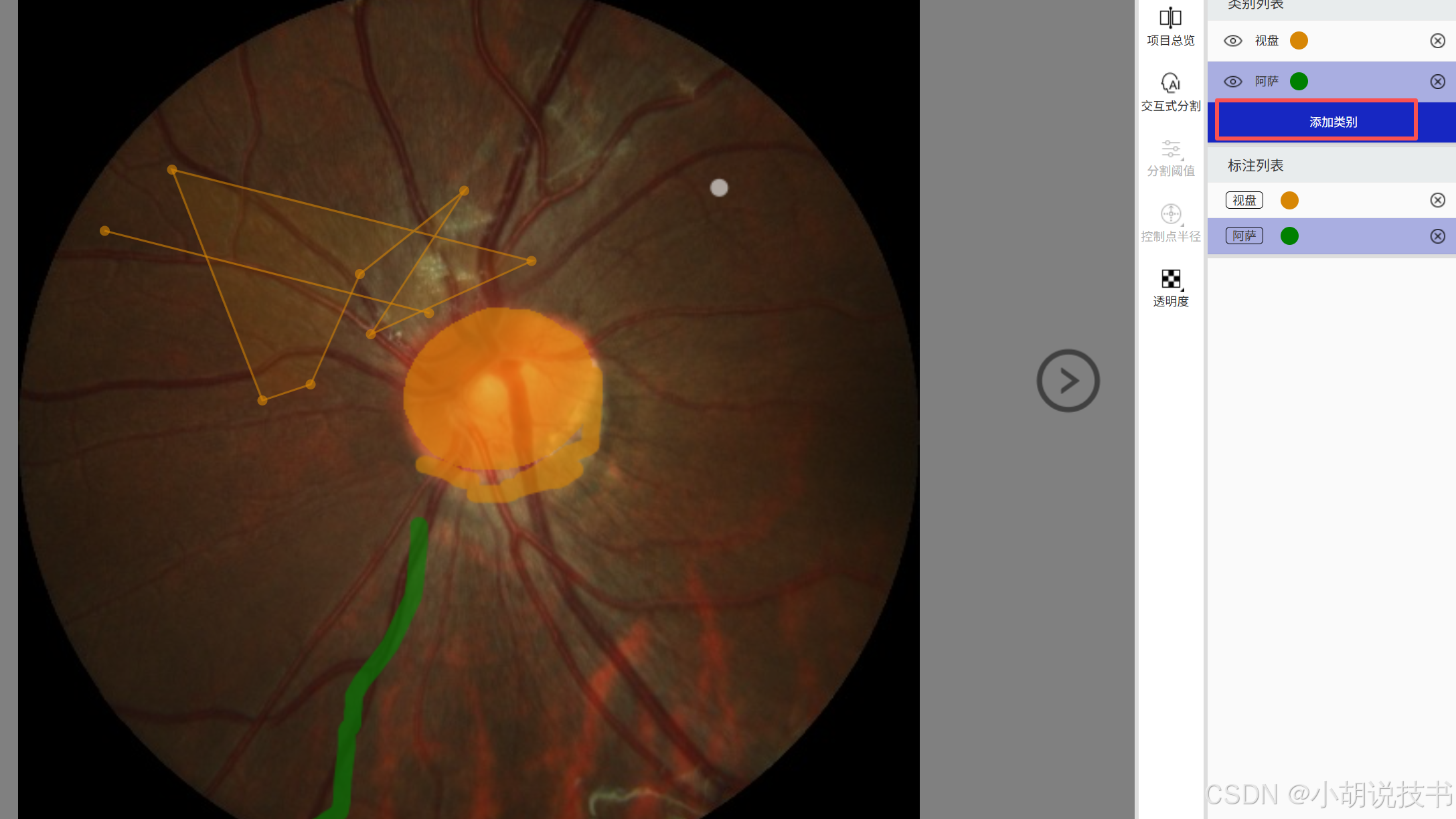
通过这样的实战演示,你可以快速掌握PaddleLabel各项功能的具体操作方法,为实际项目应用奠定坚实基础。记住,熟练掌握这些操作技巧,将大大提高你的标注效率和质量。