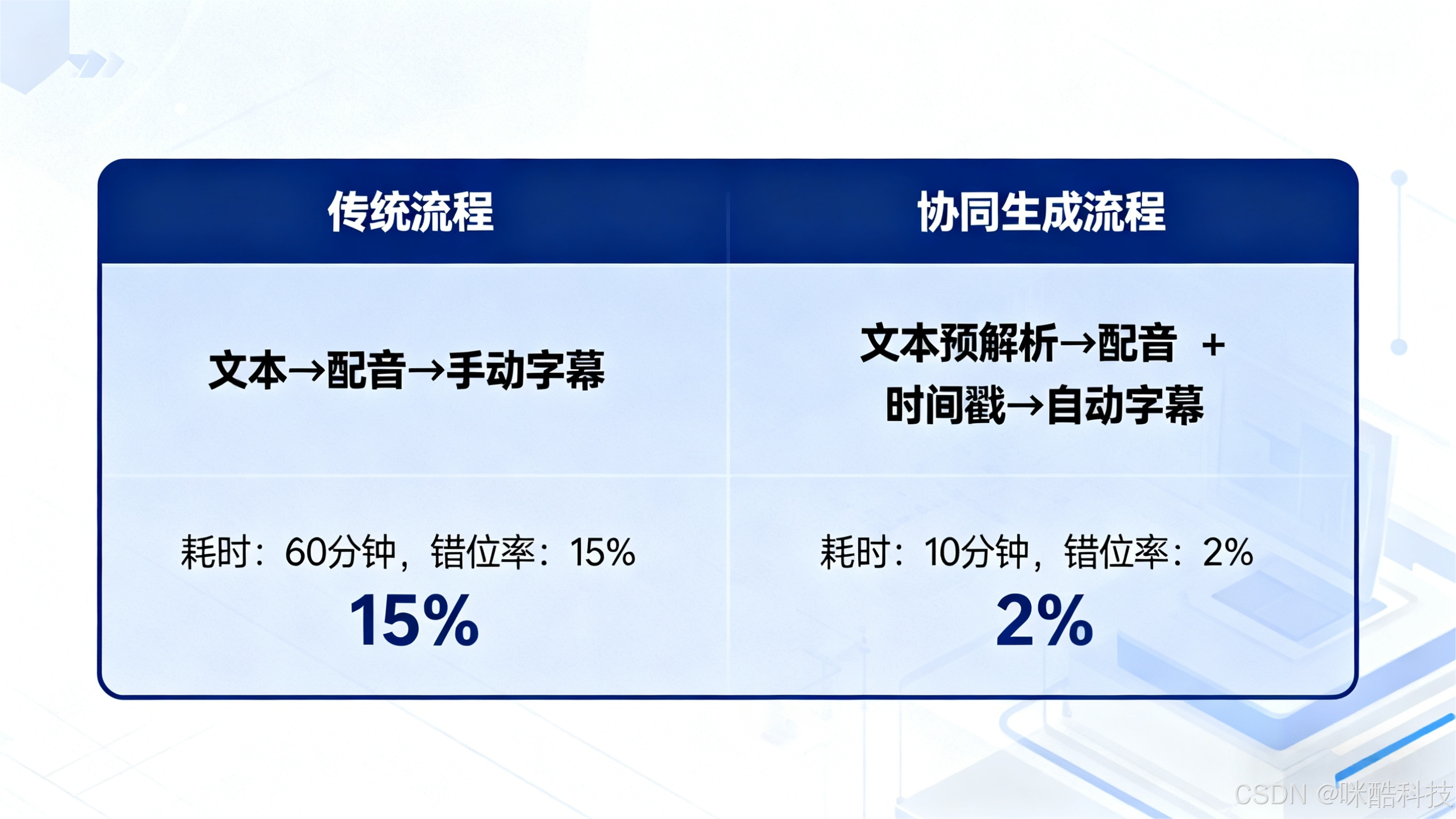
在音频内容生产(如课程制作、短视频创作、有声书出版)场景中,"配音与字幕不同步" 是高频痛点 ------ 轻则影响用户观看体验,重则导致内容信息传递偏差。尤其对中小企业而言,传统 "先配音后剪字幕" 的流程不仅耗时(10 分钟内容需 1-2 小时手动对齐),还易因人工操作失误产生错位。本文将从技术原理、系统架构、落地优化三个维度,拆解音视频协同生成的解决方案,帮助开发者快速搭建高效、精准的协同系统。
一、痛点根源:为什么配音与字幕容易 "错位"?
要解决协同问题,首先需明确传统流程中错位的核心原因,这也是技术方案设计的起点:
1.1 时间轴锚点缺失
传统流程中,配音文件(如 MP3、WAV)与字幕文本(如 SRT、ASS)是 "分离式生产"------ 配音按语音节奏输出,字幕按文本语义拆分,两者缺乏统一的时间轴锚点。例如:配音中 "AI 技术赋能内容创作" 这句话时长 2.3 秒,但字幕文本若按标点拆分为 "AI 技术""赋能内容创作",易因拆分逻辑不一致导致时间轴错位。
1.2 多源数据格式不兼容
配音文件可能来自不同工具(如专业录音软件、AI 配音平台),存在采样率(44.1kHz/48kHz)、比特率(128kbps/320kbps)差异;字幕文本则可能包含特殊符号(如 emoji、专业术语)或换行格式不统一,导致解析时时间戳计算偏差。某教育机构实测显示,多源格式文件混合处理时,字幕错位率高达 35%。
1.3 人工对齐效率低、容错差
传统 "听配音 + 调字幕" 的手动对齐方式,不仅效率低下(人均日处理量不足 1 小时内容),还易因听觉疲劳、操作失误(如误触时间轴滑块)产生新的错位。更关键的是,当内容需要修改(如配音重录、文本调整)时,需重新全量对齐,返工成本极高。
二、技术原理:音视频协同生成的核心逻辑
音视频协同生成的本质,是通过 "统一时间轴 + 自动化解析 + 实时校验" 三大技术模块,让配音与字幕从 "分离生产" 转向 "同步生成"。其核心逻辑可拆解为三步:
2.1 第一步:文本预解析,生成 "语义 - 时间" 映射表
在配音生成前,先对原始文本进行结构化处理,为后续时间轴对齐打下基础:
- 文本分段标准化:基于 NLP 语义分析(而非单纯标点)拆分句子,确保每段文本对应配音中的 "自然停顿单元"。例如 "AI 技术(停顿 0.2 秒)赋能(停顿 0.1 秒)内容创作",通过语义断点标注,避免因机械拆分导致的字幕过短或过长。
- 时间预估模型训练:基于历史配音数据(文本长度、语速、情感风格)训练时间预估模型,例如 "每 10 个中文字符对应 0.8-1.2 秒配音时长",并根据不同风格(如新闻播报语速快、情感朗读语速慢)动态调整参数。实测显示,该模型对中文文本的时间预估误差可控制在 ±0.1 秒内。
- 特殊符号预处理:对字幕中的特殊符号(如公式、英文缩写)进行标记,避免解析时误判为文本内容导致时间轴计算偏差。例如将 "AI(人工智能)" 中的括号内容标记为 "补充说明",不纳入核心时间计算。
2.2 第二步:配音实时生成,嵌入 "时间戳锚点"
在配音生成环节(无论是真人录音还是 AI 合成),通过技术手段实时嵌入时间戳,建立配音与文本的精准关联:
- 真人录音场景:采用支持 "逐句录音 + 时间戳记录" 的工具,每段文本录制完成后,自动记录 "开始时间 - 结束时间"(如 00:01:23.456-00:01:25.789),并与对应文本段绑定存储。同时支持 "段落重录" 功能 ------ 仅重录修改段,系统自动更新该段时间戳,无需全量返工。
- AI 配音场景 :利用 TTS(语音合成)引擎的 "时间戳输出" 能力,在生成音频流的同时,同步输出每个字 / 词的时间戳(如 "AI" 对应 00:00:00.000-00:00:00.300,"技术" 对应 00:00:00.310-00:00:00.600)。例如基于 VITS 或 Coqui TTS 引擎,可通过修改推理参数
return_timestamps=True,直接获取细粒度时间戳数据。
2.3 第三步:自动对齐 + 实时校验,确保同步性
生成配音与时间戳后,系统自动完成字幕生成与校验,避免人工干预:
- 自动生成字幕文件 :根据 "文本段 - 时间戳" 映射关系,自动生成 SRT、ASS 等标准字幕格式文件,无需手动输入时间轴。例如文本段 "AI 技术赋能内容创作" 对应时间戳 00:01:23.456-00:01:25.789,系统直接生成
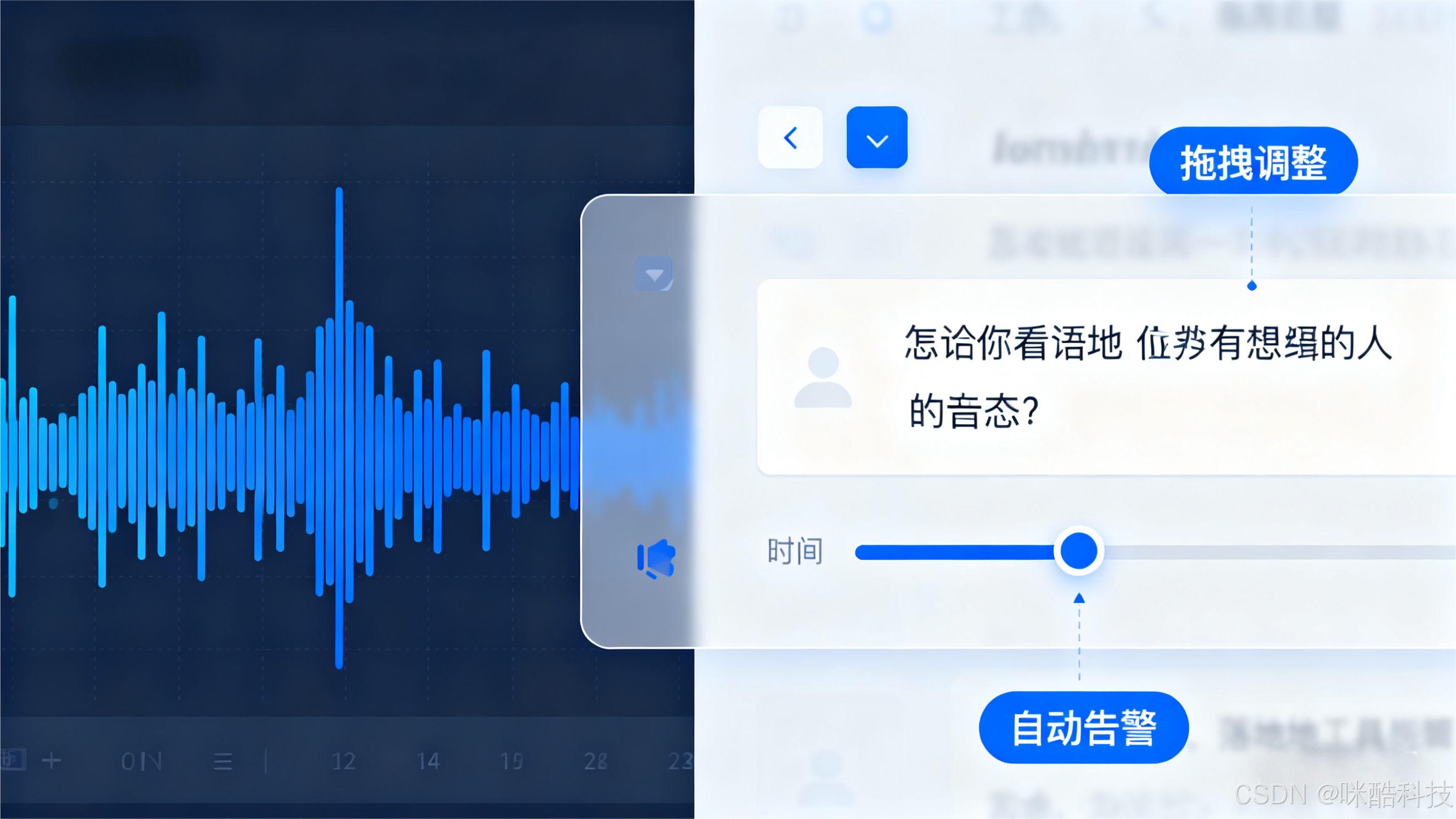
<srt><font color="#FFFFFF">AI技术赋能内容创作</font></srt>。 - 同步性实时校验:通过 "音频波形分析 + 文本匹配" 双重校验机制,检测是否存在错位。例如:分析音频波形的 "静音段" 是否与文本分段的 "语义停顿" 对应;若某段字幕的时间戳超出对应音频段时长(如字幕显示 2.5 秒,但音频仅 2.0 秒),系统自动触发告警并建议重新对齐。
- 人工干预接口:提供可视化时间轴编辑工具,支持开发者 / 运营人员手动微调错位段(如拖拽字幕时间轴滑块),调整后系统自动更新关联数据,确保全链路同步。
三、落地实践:协同生成系统的架构设计与优化
基于上述原理,可搭建一套轻量级音视频协同生成系统,以下为具体架构设计与优化技巧:
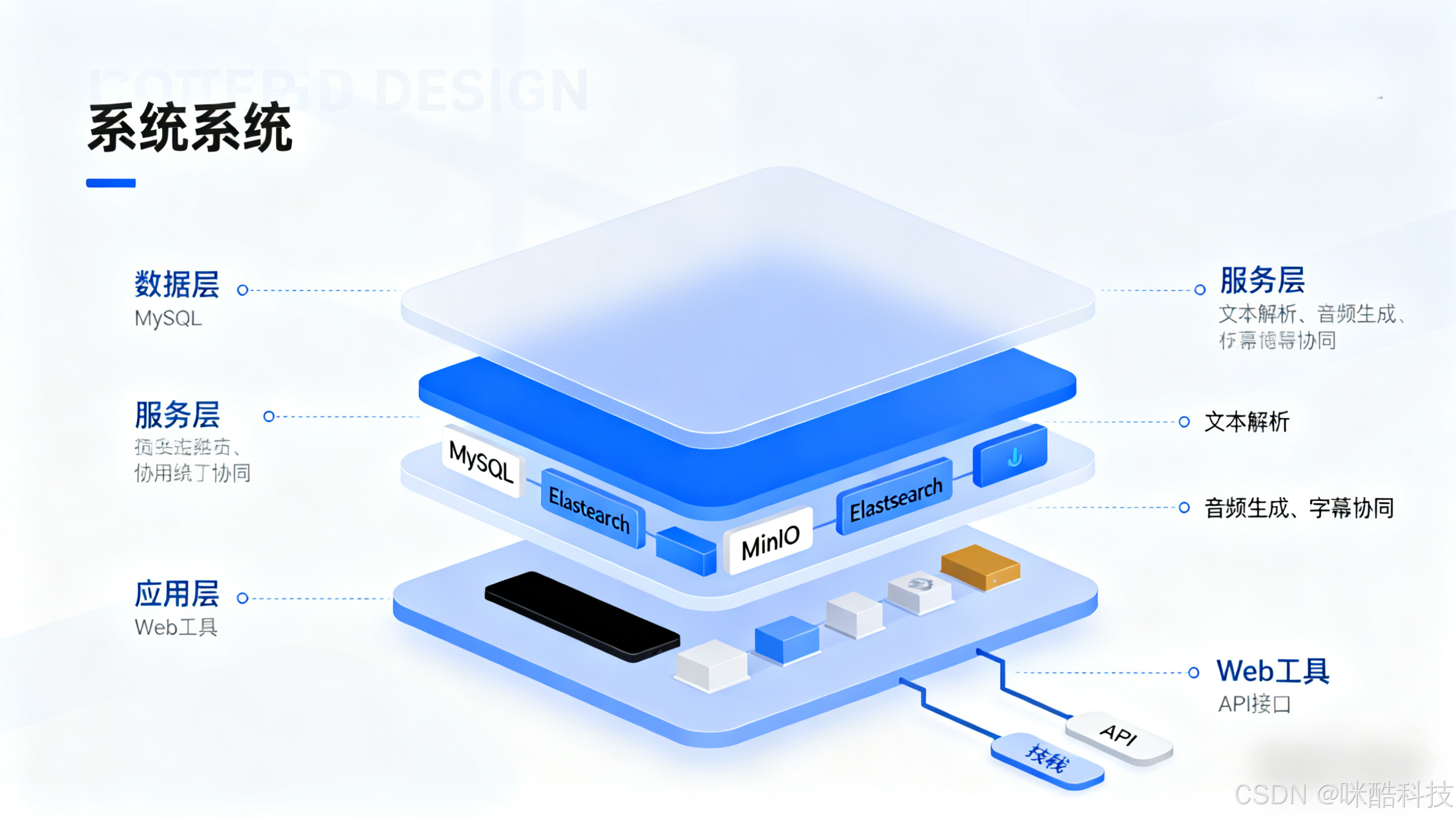
3.1 系统架构:三层架构,兼顾灵活性与可扩展性
采用 "数据层 - 服务层 - 应用层" 三层架构,适配不同业务场景(如 AI 配音、真人配音、批量处理):
-
数据层 :采用 MySQL 存储 "文本段 - 时间戳 - 音频文件路径" 关联数据,Elasticsearch 存储音频文件元数据(如时长、格式、采样率),MinIO 存储音频与字幕文件(支持分布式部署,避免单点故障)。关键表设计示例:
sql
-- 文本-时间戳关联表 CREATE TABLE text_timestamp ( id BIGINT PRIMARY KEY AUTO_INCREMENT, content_id VARCHAR(64) NOT NULL COMMENT '内容ID', text_segment VARCHAR(255) NOT NULL COMMENT '文本段', start_time DECIMAL(10,3) NOT NULL COMMENT '开始时间(秒)', end_time DECIMAL(10,3) NOT NULL COMMENT '结束时间(秒)', create_time DATETIME DEFAULT CURRENT_TIMESTAMP ); -
服务层 :基于 Spring Boot 微服务架构,拆分三大核心服务:
- 文本解析服务:负责文本分段、时间预估、特殊符号处理;
- 音频生成服务:对接 AI TTS 引擎或真人录音工具,获取音频与时间戳;
- 字幕协同服务:生成字幕文件、同步性校验、时间轴编辑。服务间通过 RabbitMQ 实现异步通信(如文本解析完成后,发送消息触发音频生成),避免同步调用导致的系统阻塞。
-
应用层:提供 Web 端可视化工具(支持文本编辑、录音上传、时间轴调整)与 API 接口(供第三方系统集成,如短视频平台、教育 CMS),满足不同用户需求。
3.2 关键优化:解决落地中的 3 个核心问题
问题 1:AI 配音时间戳精度不足?------ 细粒度模型微调
部分开源 TTS 引擎(如基础版 VITS)的时间戳精度仅到 "句子级",无法满足字幕 "逐词对齐" 需求。解决方案:
- 基于行业数据集(如 AISHELL-3)微调模型,增加 "字级时间戳预测" 模块;
- 推理时采用 "滑动窗口" 策略,将长文本拆分为短句(如每 5 个字一段),提升时间戳计算精度。实测显示,微调后字级时间戳误差可从 ±0.3 秒降至 ±0.05 秒。
问题 2:批量处理时系统性能瓶颈?------ 分布式任务调度
当处理大批量内容(如 1000 小时有声书)时,单节点处理速度慢(约 1 小时处理 5 小时内容)。解决方案:
- 采用 XXL-Job 分布式任务调度框架,将批量任务拆分为子任务(如按内容 ID 分段),分配至多个节点并行处理;
- 对非实时需求(如历史内容字幕补做),采用 "夜间错峰处理" 策略,避免占用白天业务资源。优化后,批量处理效率提升 5-8 倍。
问题 3:跨平台字幕兼容性差?------ 格式自适应转换
不同平台(如抖音、B 站、YouTube)对字幕格式要求不同(抖音支持 SRT,B 站支持 ASS),手动转换耗时。解决方案:
- 系统内置 "格式转换引擎",支持 SRT/ASS/SubRip 等 10 + 格式的自动转换;
- 提供 "平台预设模板"(如抖音字幕字体大小、颜色),生成时直接套用,无需手动调整。
四、应用场景与价值:从技术到业务的落地效果
音视频协同生成技术已在多个场景验证价值,以下为典型案例:
4.1 教育行业:课程音频字幕自动化
某在线教育机构采用该方案后,课程音频字幕制作效率从 "1 小时内容需 1.5 小时对齐" 提升至 "1 小时内容需 5 分钟生成",人力成本降低 90%;同时字幕错位率从 35% 降至 1% 以下,学员观看体验满意度提升 28%。
4.2 短视频行业:快速出片提效
某 MCN 机构利用该系统,实现 "AI 配音 + 自动字幕" 一站式生产,10 分钟可完成 1 条短视频的音字幕制作,日产出量从 50 条提升至 200 条,同时避免因字幕错位导致的平台审核驳回(驳回率从 12% 降至 0.5%)。
4.3 有声书行业:多角色字幕对齐
某有声书平台通过 "角色标记 + 时间戳绑定" 功能,实现多角色配音的字幕精准对齐(如 "男主:XXX""女主:XXX"),后期编辑时间缩短 60%,且用户反馈 "角色切换时字幕清晰,体验更沉浸"。
五、总结与未来方向
音视频协同生成的核心价值,是通过技术手段消除 "配音" 与 "字幕" 的生产壁垒,从 "人工驱动" 转向 "数据 + 算法驱动"。当前方案已解决 "同步性""效率""兼容性" 三大核心痛点,但仍有优化空间:
- 未来可结合多模态大模型(如 GPT-4V),实现 "视频画面 + 配音 + 字幕" 的三者协同(如根据画面内容调整字幕显示位置);
- 探索 "实时直播场景" 的协同生成,支持直播配音的实时字幕输出,满足无障碍直播需求。
对开发者而言,搭建协同生成系统时需牢记 "痛点导向"------ 先明确业务中最耗时、最易出错的环节(如人工对齐、格式转换),再通过技术方案针对性解决,才能真正实现 "技术赋能业务效率提升"。