github地址:https://github.com/SYSTRAN/faster-whisper
-
faster-whisper = 本地语音转文字引擎。
-
实时转码 没测试 可能需要将音频切片 例如2-3秒 5秒调用一次
apt update
安装python和pip
apt install -y build-essential curl git python3 python3-venv python3-pip
创建目录
mkdir -p /usr/local/develop/asr-faster
cd /usr/local/develop/asr-faster
建立虚拟环境并启用
python3 -m venv .venv
source .venv/bin/activate
安装 Python 包(PyAV 自带 FFmpeg,无需系统装 ffmpeg)
pip install faster-whisper fastapi uvicornstandard python-multipart
pip show faster-whisper #可以看到已经安装完成了
cat > server.py << 'PY'
from fastapi import FastAPI, UploadFile, Form
from fastapi.responses import JSONResponse
from faster_whisper import WhisperModel
import tempfile, os, time, pathlib
环境变量可在 run.sh / systemd 中配置
MODEL_NAME = os.getenv("ASR_MODEL", "large-v3") # 可选:tiny/base/small/medium/large-v3/distil-large-v3 等
DEVICE = os.getenv("ASR_DEVICE", "cpu") # "cpu" 或 "cuda"
DTYPE = os.getenv("ASR_DTYPE", "int8") # CPU 推荐 int8;GPU 推荐 float16 或 int8_float16
BEAM_SIZE = int(os.getenv("ASR_BEAM", "5"))
app = FastAPI(title="ASR - faster-whisper", version="1.0.0")
预创建模型缓存目录(若设置了 HF_HOME)
hf_home = os.getenv("HF_HOME")
if hf_home:
pathlib.Path(hf_home).mkdir(parents=True, exist_ok=True)
加载模型(首次会自动下载到 HuggingFace 缓存)
t0 = time.time()
model = WhisperModel(MODEL_NAME, device=DEVICE, compute_type=DTYPE)
load_latency = round(time.time() - t0, 3)
@app.get("/")
def root():
return {
"status": "ok",
"model": MODEL_NAME,
"device": DEVICE,
"dtype": DTYPE,
"beam_size": BEAM_SIZE,
"load_latency_sec": load_latency
}
@app.post("/asr")
async def asr(
file: UploadFile,
lang: str = Form("auto"), # "zh" 或 "auto"(自动识别)
vad: bool = Form(True), # 端点检测
word_ts: bool = Form(False) # 单词级时间戳(True 会慢一些)
):
t0 = time.time()
把上传音频落地到临时文件(PyAV/Faster-Whisper 可直接读取文件路径)
suffix = os.path.splitext(file.filename or "")-1
with tempfile.NamedTemporaryFile(suffix=suffix, delete=False) as tmp:
tmp.write(await file.read())
tmp_path = tmp.name
try:
segments, info = model.transcribe(
tmp_path,
language=None if lang == "auto" else lang,
beam_size=BEAM_SIZE,
vad_filter=vad,
word_timestamps=word_ts
)
if word_ts:
out = \[\]
for seg in segments:
out.append({
"start": seg.start,
"end": seg.end,
"text": seg.text,
"words": {"start": w.start, "end": w.end, "word": w.word} for w in seg.words or \[]
})
text_joined = "".join(s"text" for s in out)
else:
text_joined = "".join(s.text for s in segments)
out = None
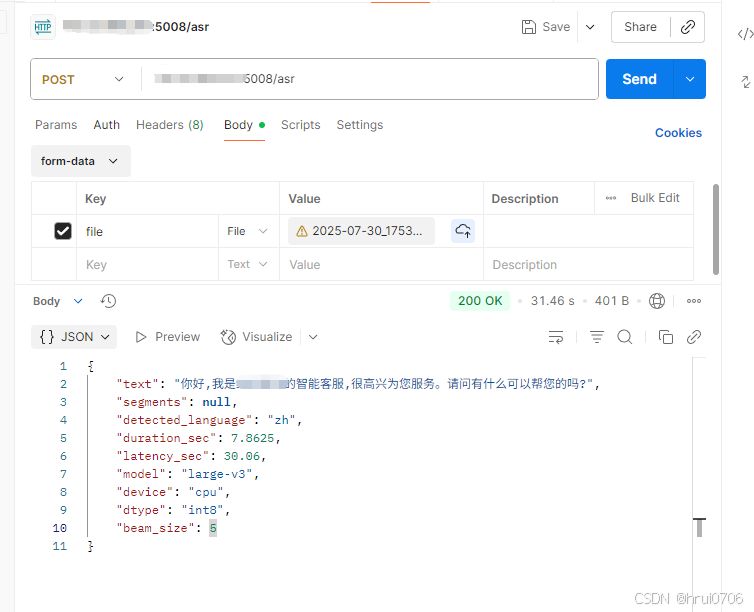
return JSONResponse({
"text": text_joined,
"segments": out, # 仅当 word_ts=True 时返回字级时间戳
"detected_language": info.language,
"duration_sec": info.duration,
"latency_sec": round(time.time() - t0, 3),
"model": MODEL_NAME,
"device": DEVICE,
"dtype": DTYPE,
"beam_size": BEAM_SIZE
})
finally:
try:
os.remove(tmp_path)
except Exception:
pass
PY
后台启动
nohup uvicorn server:app --host 0.0.0.0 --port 5008 >asr.log 2>&1 &
关闭
ps -ef|grep uvicorn
kill -9 xxxx
退出当前虚拟环境
deactivate
重新进入
cd /usr/local/develop/asr-faster
source .venv/bin/activate
uvicorn server:app --host 0.0.0.0 --port 5008
或者
nohup uvicorn server:app --host 0.0.0.0 --port 5008 >asr.log 2>&1 &
关闭5008对外开放
ufw status
ufw enable
.py中我改成了auto这里可以不穿
curl \
-F "file=@test.wav" \ # 上传文件 test.wav
-F "lang=zh" \ # 指定识别语言为中文
-F "vad=true" \ # 开启端点检测(去掉长时间静音)
http://<服务器IP>:5008/asr