DeepSeek刚刚开源了一个3B的 OCR模型:什么是DeepSeek-OCR?单张A100-40G每天可以处理20万+页文档
有这么小的开源模型,却没有一个可以用来评测体验的算力显卡怎么办?
------本文教你白嫖云GPU,不用买卡也能跑。
📌 优质平台:https://gpu.spacehpc.com/user/register?inviteCode=52872508
DeepSeek 再开源:发布 3B MoE OCR 模型,视觉压缩高达20倍
强!DeepSeek刚刚放出了一个3B OCR模型:DeepSeek-OCR,单张A100-40G每天可以处理20万+页文档。
这不是传统OCR,而是把整页图像压缩进LLM上下文 ,让大模型像"看懂"文档一样处理PDF、PPT、书籍结构化信息、图表等等------等于是把整幅图=几千字的视觉token塞入Transformer上下文。
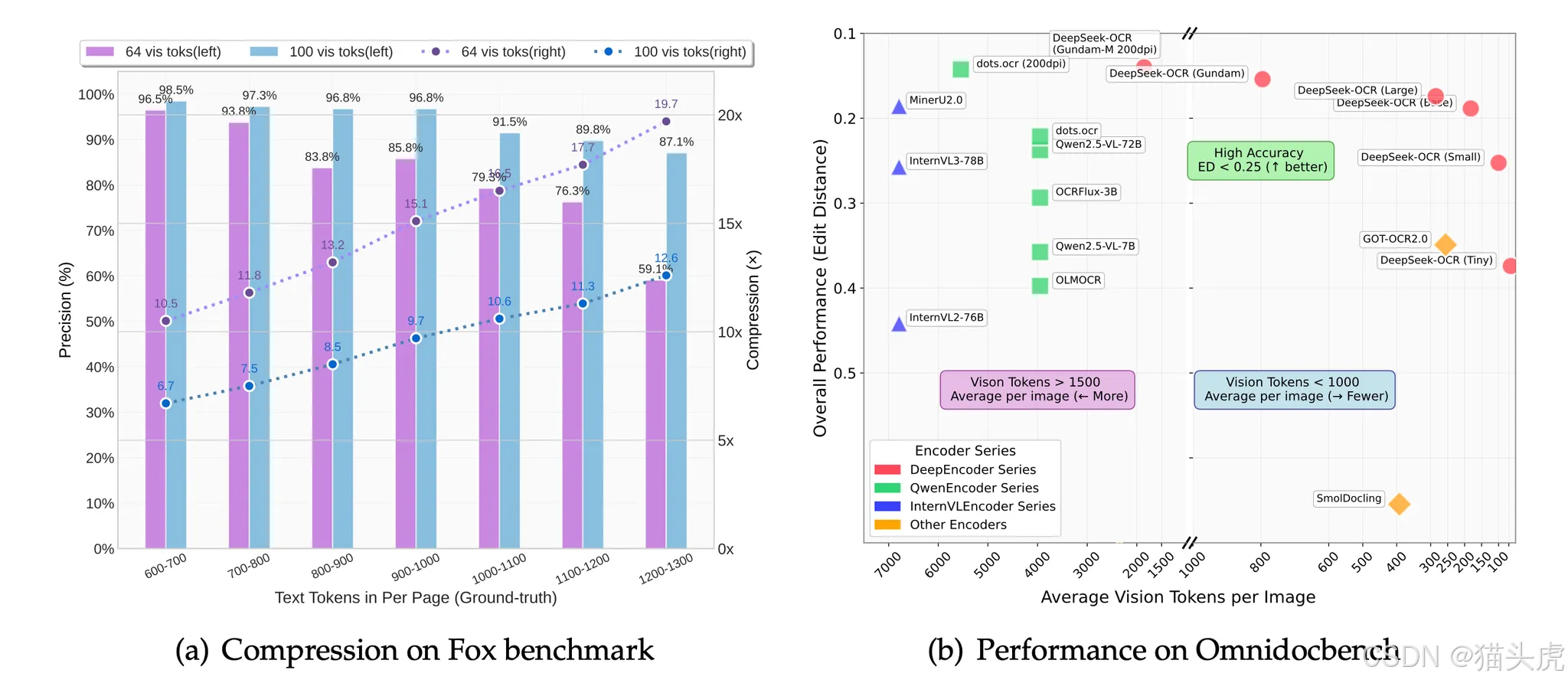
为什么这个模型重要?
传统OCR只能做"识别",而DeepSeek-OCR做的是视觉压缩 + 上下文语义理解,可以被看作视觉版RAG的上游处理器:
| 能力 | 优势 |
|---|---|
| 压缩 | 一张图压缩成64--128个视觉token |
| 速度 | 单A100 40G → 20万页/天 |
| 精度 | 10倍压缩仍可达97% |
| 弹性 | 20倍压缩仍保持60% 可读性 |
| 输入 | 支持 512~1280 可变扫描分辨率 |
| 功能 | 通用OCR / 图表解析 / 文档结构化 / Markdown生成 / REC定位 |
对于版式简单的书籍、PPT,64或100个视觉Token就能达到非常高精度。
支持能力
- ✅ 文档结构转换(PDF → Markdown/HTML)
- ✅ 图表理解(OneChart类似能力)
- ✅ 文本定位(REC)
- ✅ 表格抽取
- ✅ 多语言OCR
- ✅ 动态分辨率(Gundam模式)
- ✅ GPU记忆友好:小显存也能跑
开源地址(仓库/模型)
| 资源 | 链接 |
|---|---|
| GitHub | https://github.com/deepseek-ai/DeepSeek-OCR |
| HuggingFace | https://huggingface.co/deepseek-ai/DeepSeek-OCR |
模型安装 & 推理(Huggingface Transformers)
Requirements(python 3.12.9 + CUDA 11.8):
torch==2.6.0
transformers==4.46.3
tokenizers==0.20.3
einops
addict
easydict
pip install flash-attn==2.7.3 --no-build-isolation推理Demo
python
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file,
output_path = output_path,
base_size = 1024, image_size = 640,
crop_mode=True, save_results = True, test_compress = True)模式说明:
| 模式 | base_size | image_size | crop_mode |
|---|---|---|---|
| Tiny | 512 | 512 | ❌ |
| Small | 640 | 640 | ❌ |
| Base | 1024 | 1024 | ❌ |
| Large | 1280 | 1280 | ❌ |
| Gundam | 1024 | 640 | ✅ |
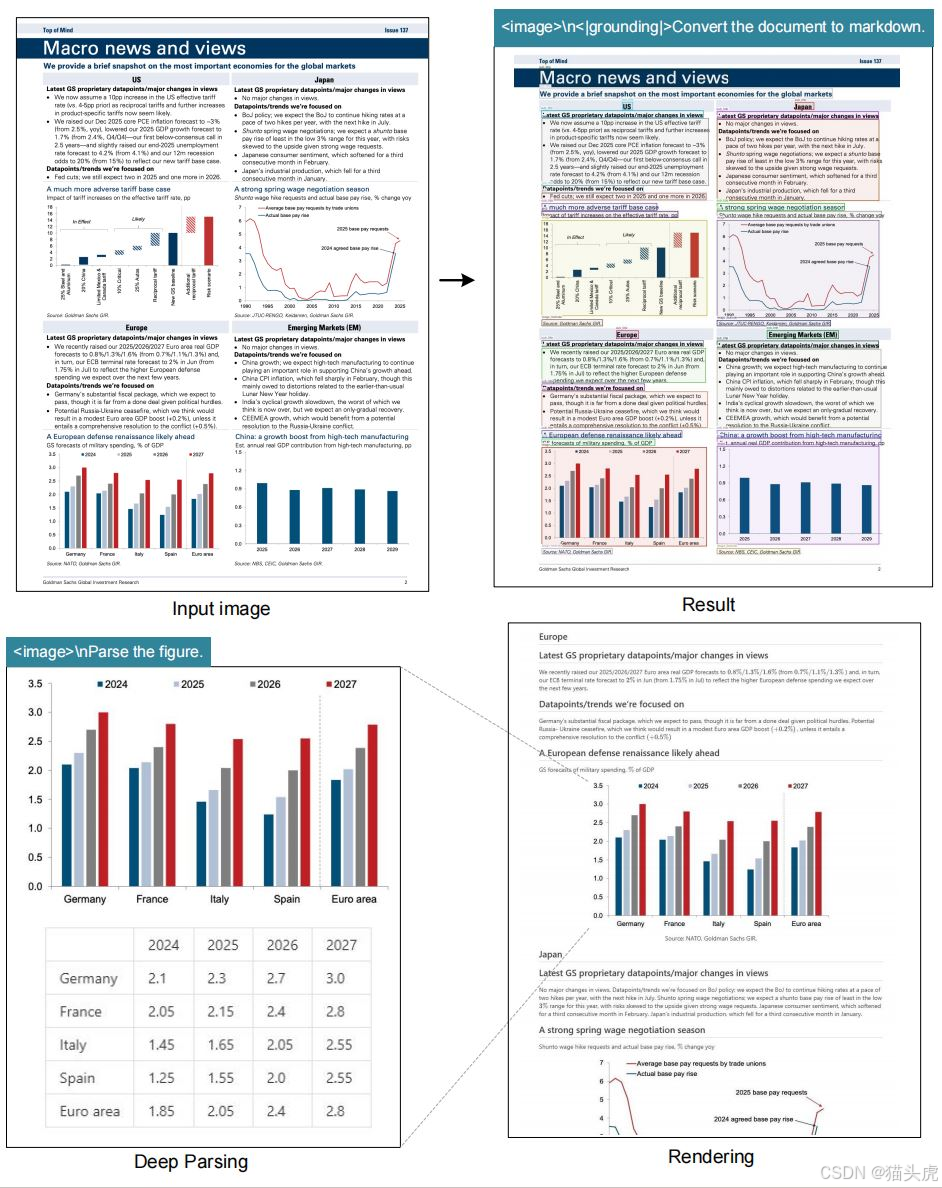
Visualizations(效果展示)



没显卡怎么白嫖体验?(重点)
可以直接上云平台:
📌 推荐平台:
https://gpu.spacehpc.com/user/register?inviteCode=52872508

支持免费A100/4090等卡,足够测试DeepSeek-OCR。
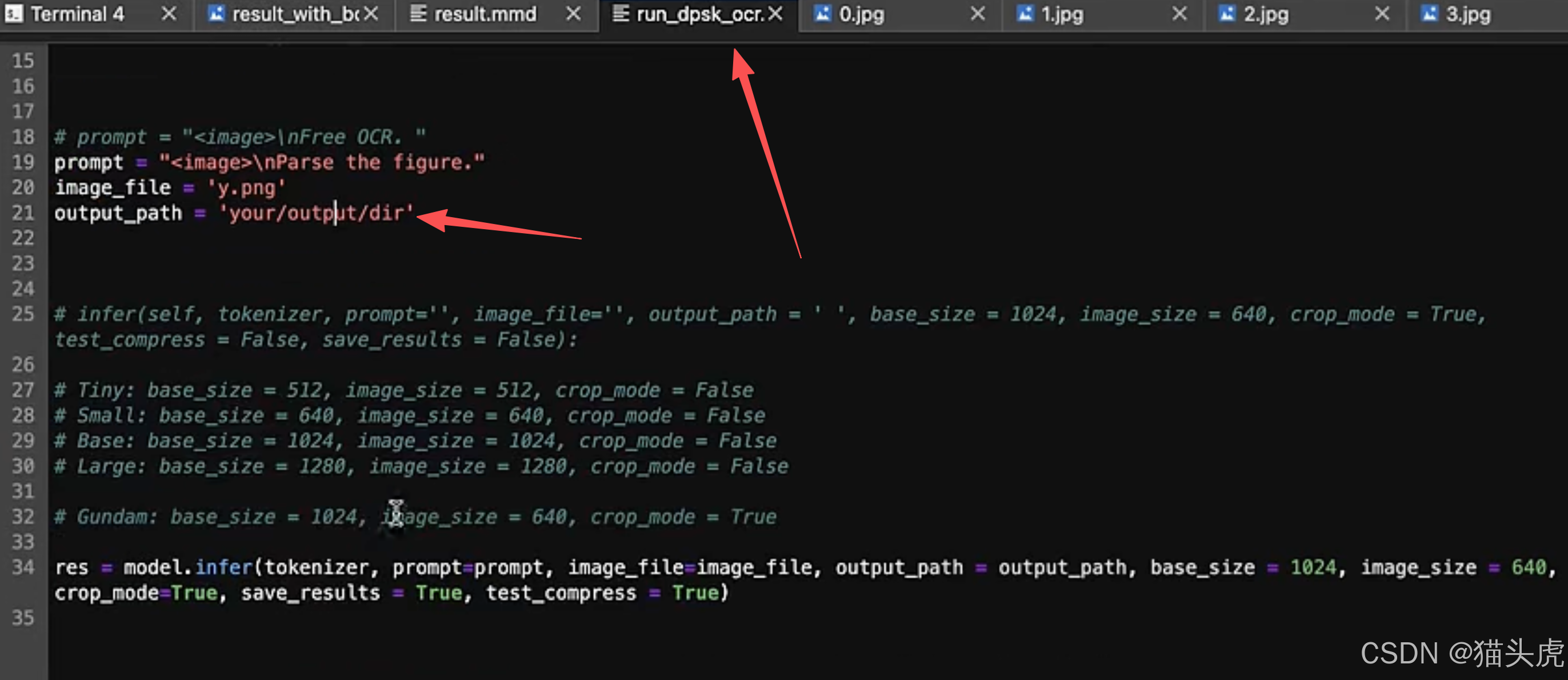
修改输出路径即可:
结语:这是视觉RAG的新基座模型
DeepSeek-OCR的出现不是"又一个OCR",而是朝着Vision-to-Context迈出的关键一步。
它不输出文本流,而是输出可以直接输入LLM的"上下文视觉Token",这意味着:
未来的大模型将具备真正的视觉理解与文档逻辑阅读能力。
下一步我们只需要把DeepSeek-OCR前置,再接上LLM(DeepSeek-V3 / Qwen2.5 / GLM等),就能做PDF端到端问答 / 复杂表格抽取 / 具备文档连续语义的RAG系统。