| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain |
前情摘要:
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
本文章目录
- 零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
-
- 一、先明确:为什么要懂模块和IO链路?
- [二、LangChain模块 vs Java Spring生态](#二、LangChain模块 vs Java Spring生态)
- 三、LangChain六大核心模块
-
- [1. Models(模型层)](#1. Models(模型层))
- [2. Prompts(提示工程)](#2. Prompts(提示工程))
- [3. Chains(任务链)](#3. Chains(任务链))
- [4. Memory(记忆)](#4. Memory(记忆))
- [5. Indexes(索引)](#5. Indexes(索引))
- [6. Agents(智能体)](#6. Agents(智能体))
- 四、LangChain大模型IO交互链路
- 五、零基础总结:六大模块的"核心用法口诀"
零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
在前一篇文章中,我们认识了LangChain的生态全景,知道它能帮我们连接大模型与工具、快速开发智能应用。但对于零基础开发者来说,想真正上手,还得先搞懂它的"内部构造"------也就是LangChain的核心模块,以及这些模块如何配合大模型完成一次完整的交互(IO链路)。
今天这篇,我们就从"模块拆解"和"链路梳理"两个维度,用你熟悉的Java生态做类比,把LangChain的核心逻辑讲透。毕竟,搞懂"零件"和"工作流程",后续搭应用才会得心应手。
一、先明确:为什么要懂模块和IO链路?
在学Spring时,你会先懂IOC容器、Bean、AOP这些核心概念,再学怎么搭项目------LangChain也一样。搞懂模块和链路,能解决两个关键问题:
- "知道用什么":比如需要"保存对话历史",就知道该用Memory模块;需要"对接DeepSeek和GPT",就知道用Models模块;
- "知道怎么查问题":比如AI没返回预期结果,能顺着IO链路排查------是Prompt写得不好?还是Chain步骤漏了?或是Memory没生效?
二、LangChain模块 vs Java Spring生态
对零基础来说,"类比已知技术"是最快的理解方式。LangChain的每个核心模块,都能在Spring生态里找到对应的"影子",我们用表格直接对标,降低理解门槛:
| LangChain核心模块 | 核心作用 | Java Spring生态类比 | 零基础理解关键点 |
|---|---|---|---|
| Models(模型层) | 统一对接不同大模型(OpenAI/Gemini/DeepSeek) | JDBC接口(对接不同数据库) | 不用记不同大模型的API格式,用Models模块就能"一键切换" |
| Prompts(提示工程) | 管理Prompt模板,动态填充参数 | Thymeleaf(模板引擎) | 像写HTML模板一样写Prompt,比如用{concept}占位,后续填充内容 |
| Chains(任务链) | 串联多个组件(如Models+Prompts),执行连贯任务 | Activiti BPMN(工作流引擎) | 把"查天气→生成建议"拆成两步,用Chain自动执行,不用手动写衔接逻辑 |
| Memory(记忆) | 保存对话历史或任务状态 | HTTP Session(会话管理) | 就像登录后Session记住你的用户名,Memory记住你之前和AI说过的话 |
| Indexes(索引) | 加载/处理外部数据(文档/网页/数据库),供LLM使用 | JDBC+数据库索引 | 把网页内容、Excel文档"读"进来,整理成LLM能理解的格式,像JDBC读数据库数据 |
| Agents(智能体) | 自主决策调用哪个工具/Chain,处理复杂需求 | 策略模式+Drools规则引擎 | 比如用户问"算1+1再解释结果",Agents会自己决定"先调用计算器工具,再用LLM解释" |
三、LangChain六大核心模块
接下来,我们逐个拆解六大模块,每个模块都包含"核心定位+通俗解释+Java类比+代码示例",你可以直接复制代码跑一跑(前提是已安装LangChain,参考上一篇的安装步骤)。
1. Models(模型层)
核心定位 :定义大模型的"通用接口",屏蔽不同厂商API的差异。
通俗解释 :就像JDBC接口,不管你用MySQL还是Oracle,都用Connection、Statement操作;Models模块不管你用OpenAI还是DeepSeek,都用统一的LLM类调用。
代码示例(对接DeepSeek):
python
# 导入Models模块的DeepSeek封装
from langchain_community.llms import DeepSeek
# 初始化大模型(类似JDBC的Class.forName()加载驱动)
llm = DeepSeek(
model="deepseek-chat", # 模型名称(不同大模型这里改名字即可)
api_key="你的DeepSeek API Key" # 替换成你的API Key
)
# 调用模型(统一接口,换OpenAI也这么写)
result = llm.invoke("用一句话解释什么是Java的接口?")
print(result)
# 输出示例:Java的接口是一种抽象类型,定义了类应实现的方法规范,就像一份"契约",只规定做什么,不规定怎么做。2. Prompts(提示工程)
核心定位 :管理Prompt模板,支持动态传参,避免重复写Prompt。
通俗解释 :就像Thymeleaf写Hello, ${name}!,${name}是占位符;Prompts模块用{变量名}做占位符,后续动态填充内容。
代码示例(生成Java概念解释):
python
from langchain.prompts import PromptTemplate
# 1. 定义Prompt模板(类似Thymeleaf的HTML模板)
template = """
你是一个Java专家,请用比喻解释{concept}:
要求:
1. 用{framework}框架做类比
2. 不超过2句话
"""
# 2. 初始化模板(解析占位符)
prompt = PromptTemplate.from_template(template)
# 3. 动态填充参数(类似Thymeleaf渲染时传值)
filled_prompt = prompt.format(
concept="多线程", # 要解释的Java概念
framework="Spring Batch" # 用来类比的框架
)
print(filled_prompt)
# 输出示例:
# 你是一个Java专家,请用比喻解释多线程:
# 要求:
# 1. 用Spring Batch框架做类比
# 2. 不超过2句话
# 4. 结合Models模块调用(后续会用Chain自动串联这步)
result = llm.invoke(filled_prompt)
print(result)
# 输出示例:Java多线程像Spring Batch的并行任务,能同时处理多个任务提升效率,就像Spring Batch用多线程处理批量数据一样。3. Chains(任务链)
核心定位 :串联多个组件(如Models+Prompts),自动执行多步任务,避免手动衔接。
通俗解释 :就像Spring Batch的"读→处理→写"流程,Chain把"填充Prompt→调用Models→返回结果"串成一个流程,你只需要调用run()即可。
代码示例(串联Prompts+Models):
python
from langchain.chains import LLMChain
# 1. 复用前面的llm(Models)和prompt(Prompts)
# 2. 创建Chain(串联两个组件,类似Spring Batch定义Step流程)
chain = LLMChain(llm=llm, prompt=prompt)
# 3. 执行Chain(一步到位,不用手动填充Prompt再调用Models)
result = chain.run(
concept="Spring IOC",
framework="JDBC"
)
print(result)
# 输出示例:Spring IOC像JDBC的连接池,IOC容器管理Bean的创建和依赖注入,就像连接池管理数据库连接,不用手动创建。4. Memory(记忆)
核心定位 :保存对话历史,让AI能"记住"之前的交互内容。
通俗解释:就像HTTP Session保存用户登录状态,Memory保存你和AI的对话,比如你先问"我叫小明",后续AI能在回答中提到"小明"。
代码示例(保存对话历史):
python
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 1. 初始化Memory(类似创建Session)
memory = ConversationBufferMemory()
# 2. 创建对话Chain(集成Memory)
conversation_chain = ConversationChain(
llm=llm,
memory=memory, # 给Chain加"记忆"
verbose=True # 打印对话历史(方便调试)
)
# 3. 第一次交互
conversation_chain.predict(input="你好,我叫小明,是Java初学者。")
# 输出示例:您好小明!作为Java初学者,建议先从基础语法(如变量、循环)和面向对象概念(类、对象)入手,后续再学Spring等框架~
# 4. 第二次交互(AI会记住"小明"和"Java初学者")
result = conversation_chain.predict(input="我该怎么学Spring?")
print(result)
# 输出示例:小明,作为Java初学者,学Spring可以先从Spring Core(IOC、DI)开始,理解Bean的管理逻辑,再结合简单案例练手,比如用Spring做一个简单的用户查询功能,逐步过渡到Spring Boot~5. Indexes(索引)
核心定位 :加载、处理外部数据(网页/文档/数据库),把数据整理成LLM能理解的格式。
通俗解释:就像JDBC连接数据库并查询数据,Indexes模块连接外部数据源(比如Spring官网文档),把内容"读"进来,再切割、整理,供LLM后续分析。
代码示例(加载Spring官网文档):
python
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
# 1. 加载外部数据(类似JDBC连接数据库)
# 这里加载Spring Boot官网文档的某个页面
loader = WebBaseLoader("https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#getting-started")
docs = loader.load() # 读取页面内容
# 2. 处理数据:切割长文本(LLM有 token 限制,太长的内容要拆)
text_splitter = CharacterTextSplitter(
chunk_size=500, # 每个片段500字符
chunk_overlap=50 # 片段间重叠50字符(避免上下文断裂)
)
split_docs = text_splitter.split_documents(docs)
# 3. 查看处理后的数据(后续可结合Models模块,让LLM分析这些文档)
print(f"总共拆成{len(split_docs)}个片段")
print("第一个片段内容:", split_docs[0].page_content[:200]) # 打印前200字符
# 输出示例:总共拆成12个片段;第一个片段内容:Getting Started
# 1.1. What You Will Build
# You will build a simple web application with Spring Boot and add some useful services to it.6. Agents(智能体)
核心定位 :自主决策"调用哪个工具/Chain",比Chain更灵活,能处理需要判断的复杂需求。
通俗解释:就像策略模式------遇到"计算"需求就调用计算器工具,遇到"解释概念"就调用LLM;Agents会根据用户问题,自己选对应的处理方式。
代码示例(调用计算器工具):
python
from langchain.agents import Tool, initialize_agent
from langchain.chains import LLMMathChain # 计算器工具
# 1. 初始化工具(类似Spring中定义Bean)
# 工具1:计算器(处理数学计算)
math_chain = LLMMathChain.from_llm(llm=llm)
tools = [
Tool(
name="Calculator", # 工具名称(Agents会用这个名字调用)
func=math_chain.run, # 工具对应的函数
description="用来计算数学表达式,比如1+1、(3*4)/2等" # 工具描述(Agents靠这个判断要不要用)
)
]
# 2. 初始化Agents(设置决策逻辑)
agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description", # 决策模式:根据工具描述判断是否调用
verbose=True # 打印思考过程(方便看Agents怎么决策)
)
# 3. 执行复杂任务(Agents会自己判断要不要调用工具)
result = agent.run("请计算:Java中int类型占4个字节,一个int数组有10个元素,这个数组总共占多少字节?")
print(result)
# 思考过程示例:我需要计算数组总字节数,int占4字节,10个元素就是4*10,应该调用Calculator工具;
# 输出示例:Java中int类型占4个字节,10个元素的int数组总字节数为4*10=40字节,因此该数组总共占40字节。四、LangChain大模型IO交互链路
懂了单个模块,还要知道它们怎么配合工作。我们结合"用户问'查Spring Boot文档,解释什么是自动配置'"这个需求,拆解IO交互链路(对应之前提到的分层设计):
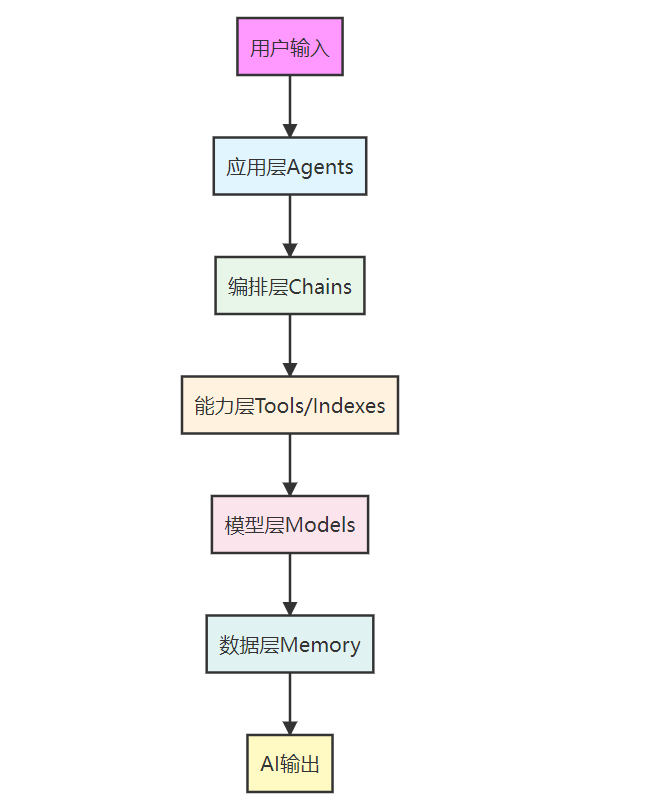
链路分步拆解:
-
应用层(Agents):决策"要做什么"
接收用户输入"查Spring Boot文档,解释什么是自动配置",Agents分析后决定:需要先"用Indexes加载文档",再"用Chain串联'文档内容→LLM解释'"。
-
编排层(Chains):规划"怎么做"
Chains把任务拆成两步:
第一步:调用Indexes模块加载Spring Boot文档中"自动配置"相关内容;
第二步:把加载的内容传给Prompts模板,再调用Models模块生成解释。
-
能力层(Indexes):获取"外部数据"
Indexes模块加载Spring Boot官网文档,切割出"自动配置"相关的文本片段,传给Chains。
-
模型层(Models):生成"核心结果"
Models模块(如DeepSeek)接收Chains传来的"文档片段+Prompt模板",生成对"自动配置"的通俗解释。
-
数据层(Memory):补充"历史信息"
如果之前用户问过"什么是Spring Boot",Memory会把这段历史传给Models,让解释更连贯(比如提到"延续之前说的Spring Boot简化配置的特点,自动配置进一步减少手动配置")。
-
输出结果:把Models生成的解释返回给用户,完成一次IO交互。
五、零基础总结:六大模块的"核心用法口诀"
为了方便你记忆,总结一个零基础能看懂的"用法口诀":
- Models :对接大模型,换模型只改参数;
- Prompts :写Prompt模板,动态传参不重复;
- Chains :串组件成流程,多步任务自动跑;
- Memory:存对话历史,上下文连贯不健忘;
- Indexes:读外部数据,文档网页都能拿;
- Agents:做决策选工具,复杂需求不用愁。
喜欢请点赞收藏。如果有想看的内容,也可以在评论区告诉我~