这篇文章我们来学习一下如何基于完全分布式模式来部署Hadoop,在安装Hadoop之前,我们先说明需要准备的东西。
1,VMware Workstation Pro17.5
2,Centos9Stream镜像
3,JDK安装包
4,Hadoop安装包
以上所需我们可以看出,我们将基于Centos9Sream来部署Hadoop,废话不多说,我们现在就开始了,大家可以完全跟着我一起安装。
1,安装虚拟机
先点击"创建新的虚拟机"
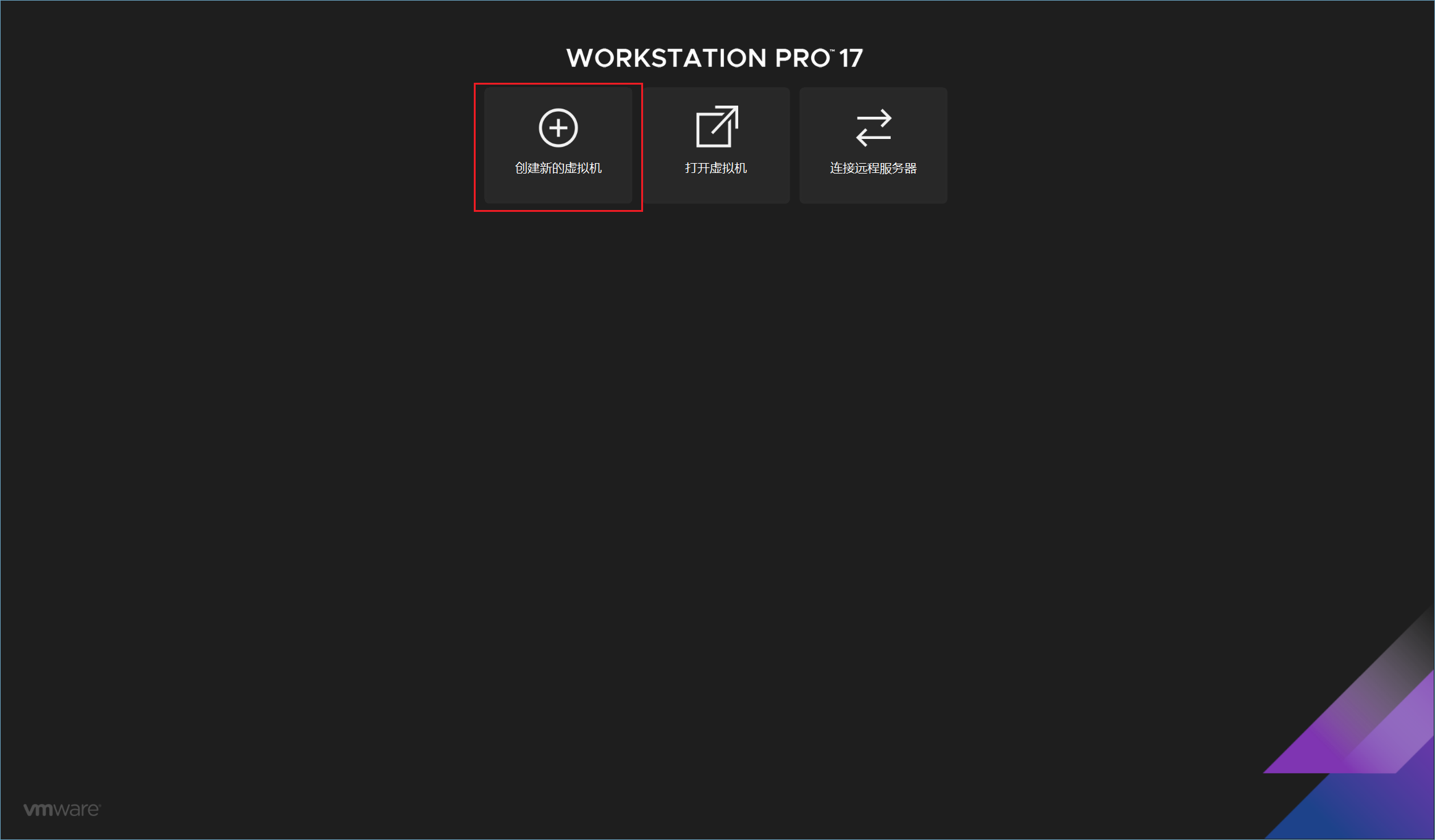
选择"自定义"然后点击"下一步"
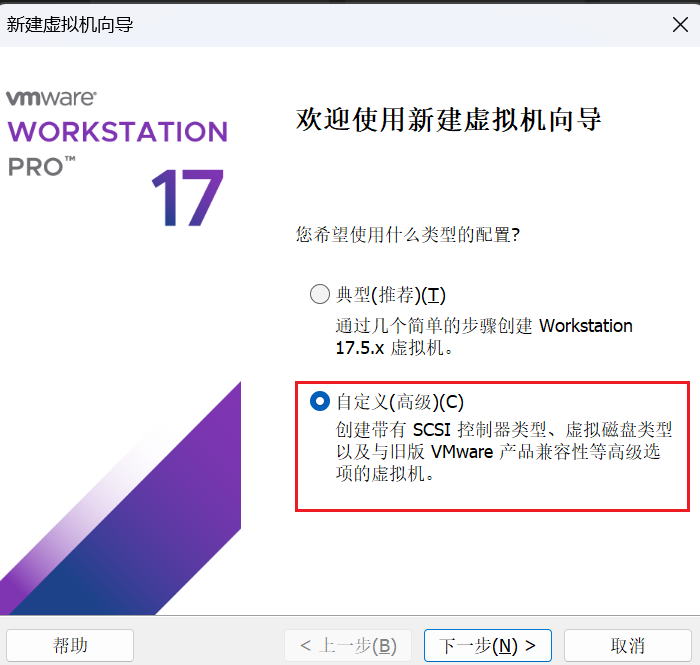
默认即可,接着点击"下一步"
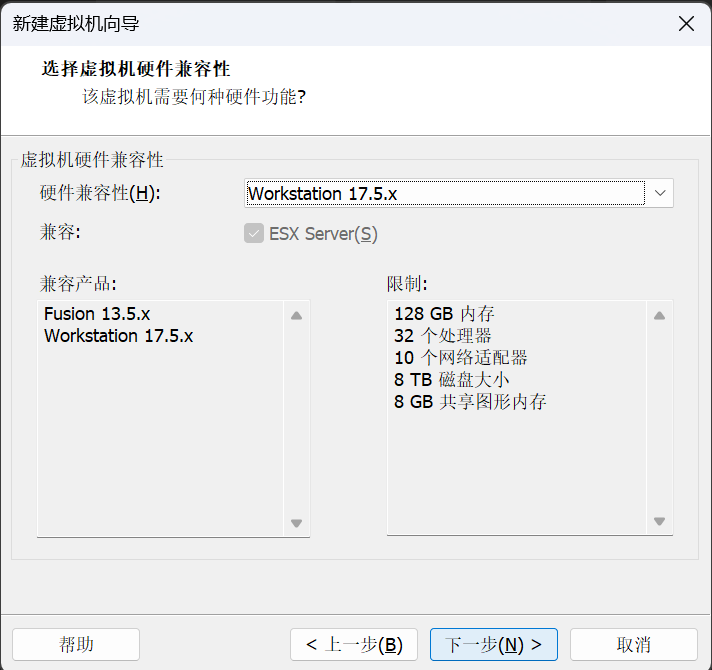
选择"稍后安装操作系统",然后继续点击"下一步"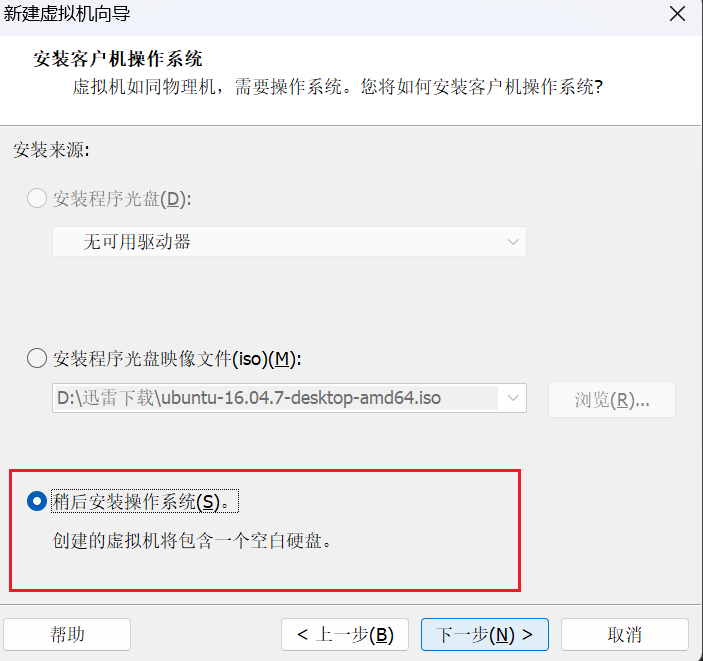
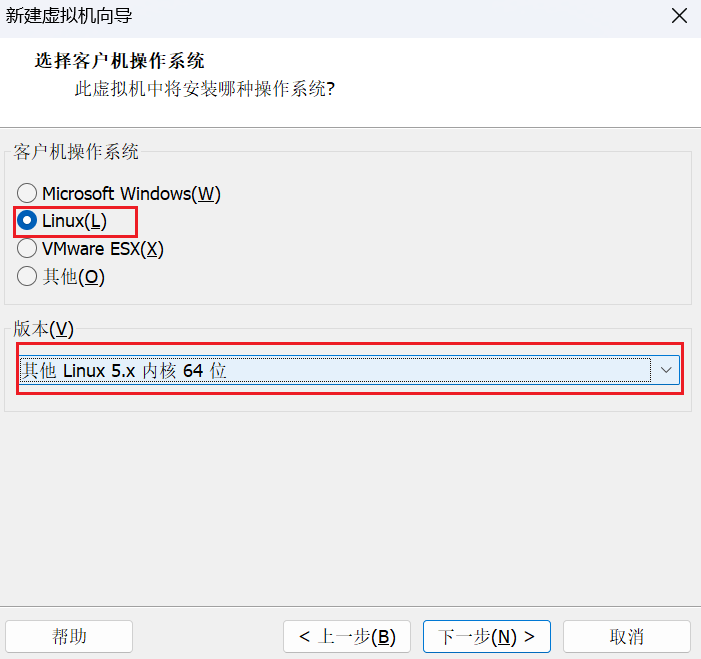
我们选择"Linux"操作系统,对于Centos9Stream我们需要选择"其他Linux5.x内核64位"
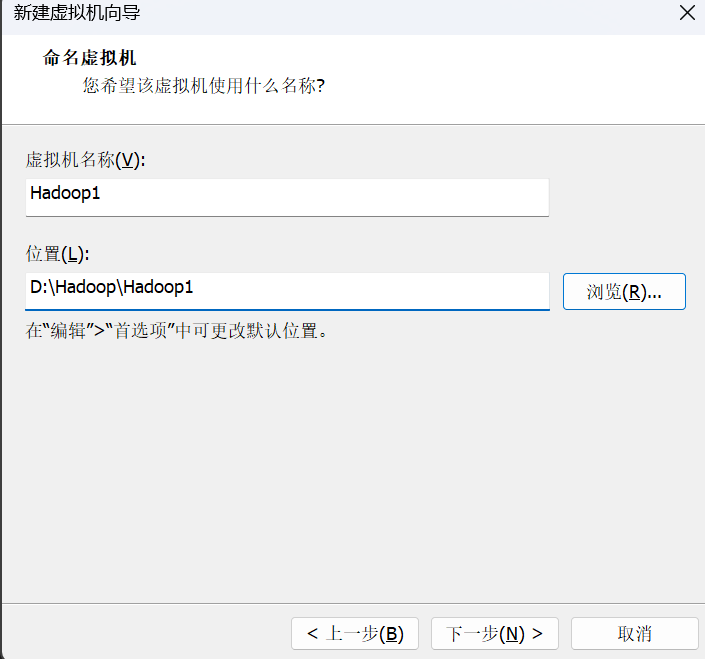
然后是选择安装位置并给虚拟机命名,建议大家按照到C盘以外的其他盘符并且为了方便管理也建议大家可以放到同一个文件夹里面,虚拟机名称可以自定义,也可以和我一样。
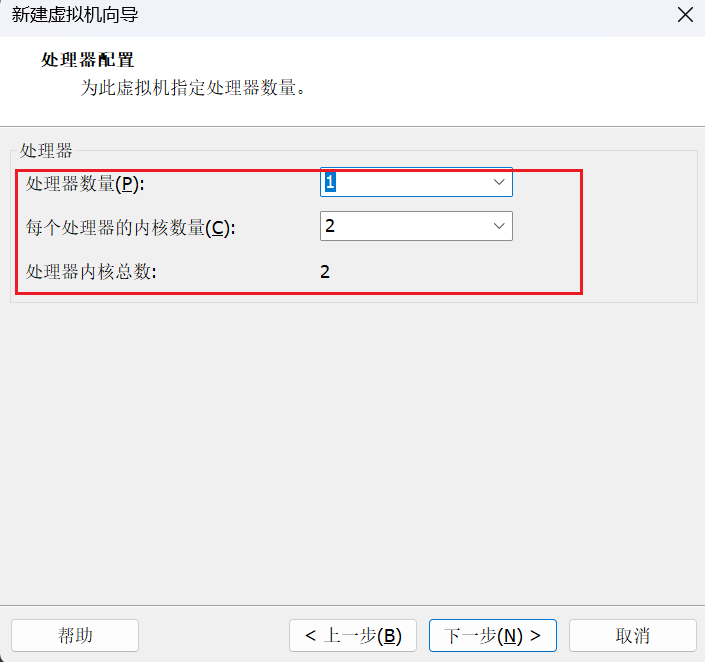
这个就和我选择的一样就可以,然后继续点击"下一步"。
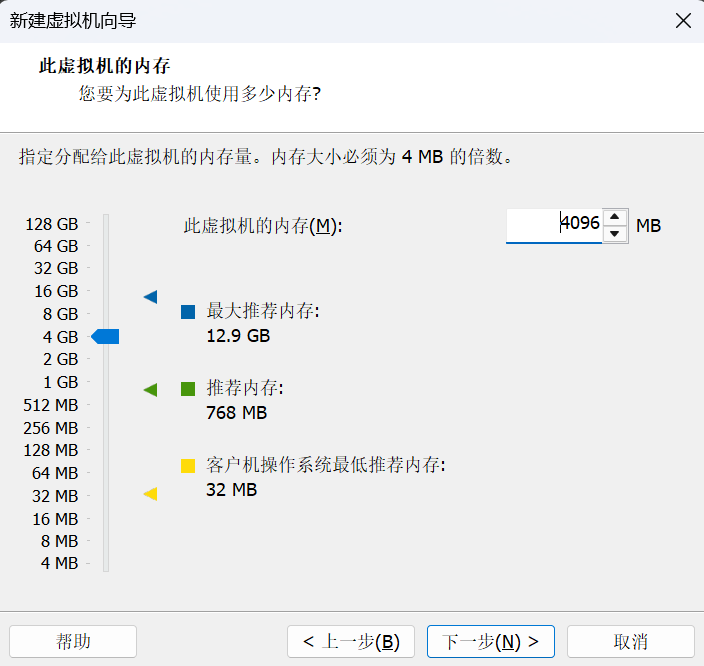
这个也可以和我选择一样,一般情况下大家的电脑是够用的,然后我们继续点击"下一步"
 以后大家只要和我选择的一样就可以,一直点击"下一步"。
以后大家只要和我选择的一样就可以,一直点击"下一步"。
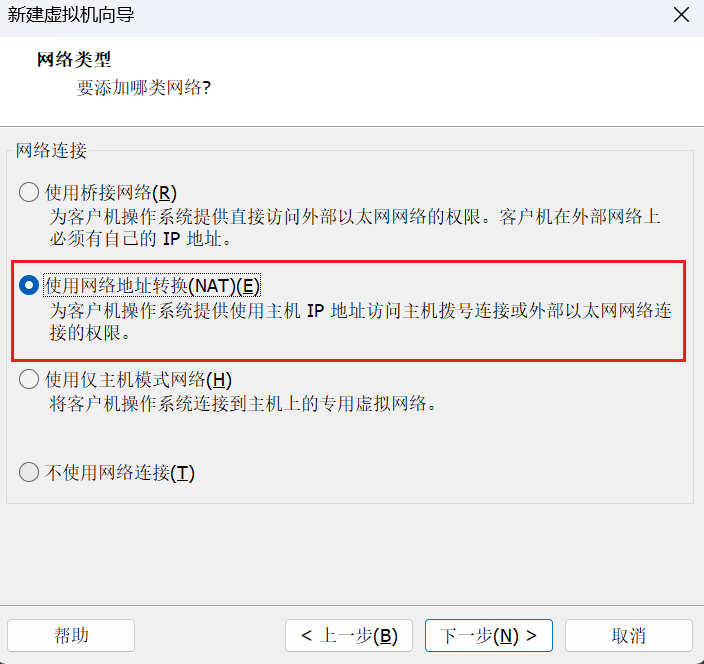
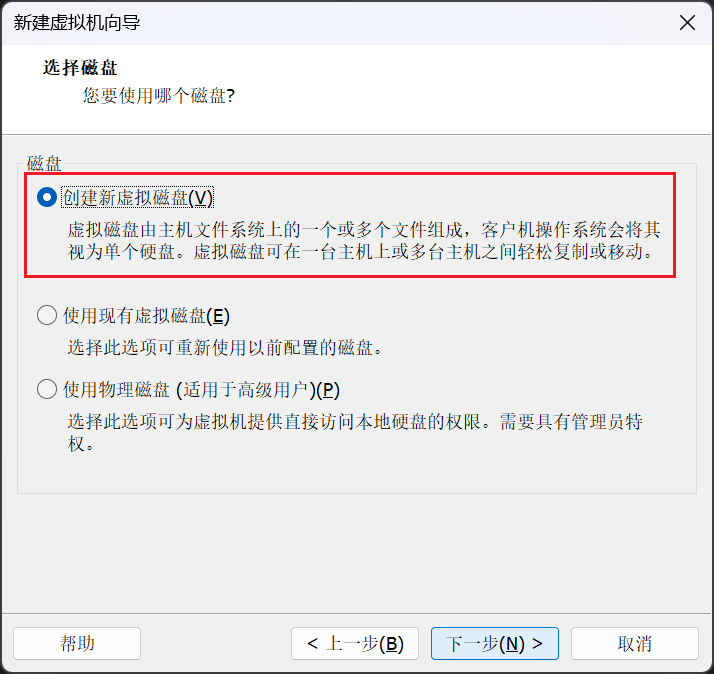
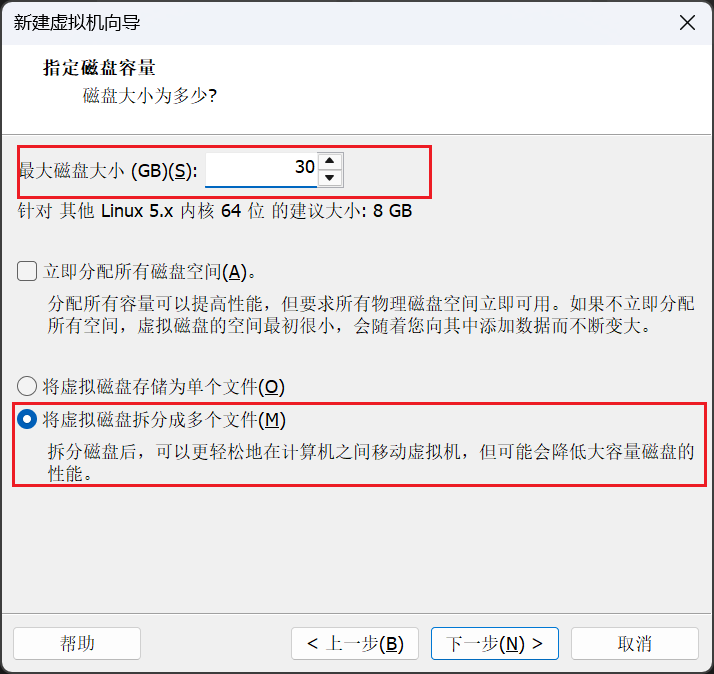
这里大家可以选择30GB,然后其余和我选择一样就好。接着我们一直点击"下一步",并且最后点击完成。
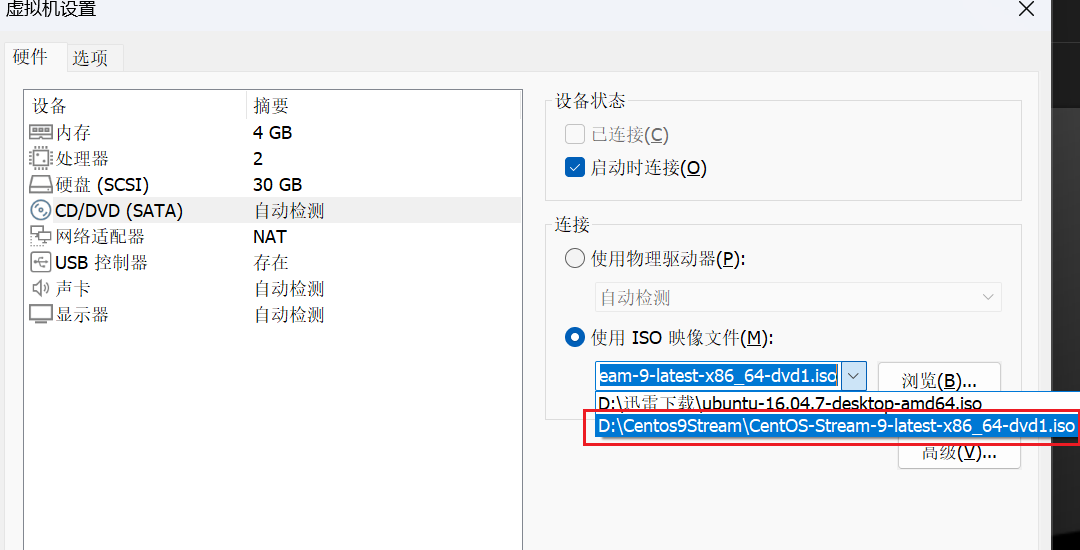
我们选择我们下载好的镜像文件,然后点击"确定"。
然后点击"开启此虚拟机"。
接下来大家只需要和我选择的一样就可以。
该步骤中大家和我选择一样,然后我们再去配置root密码。
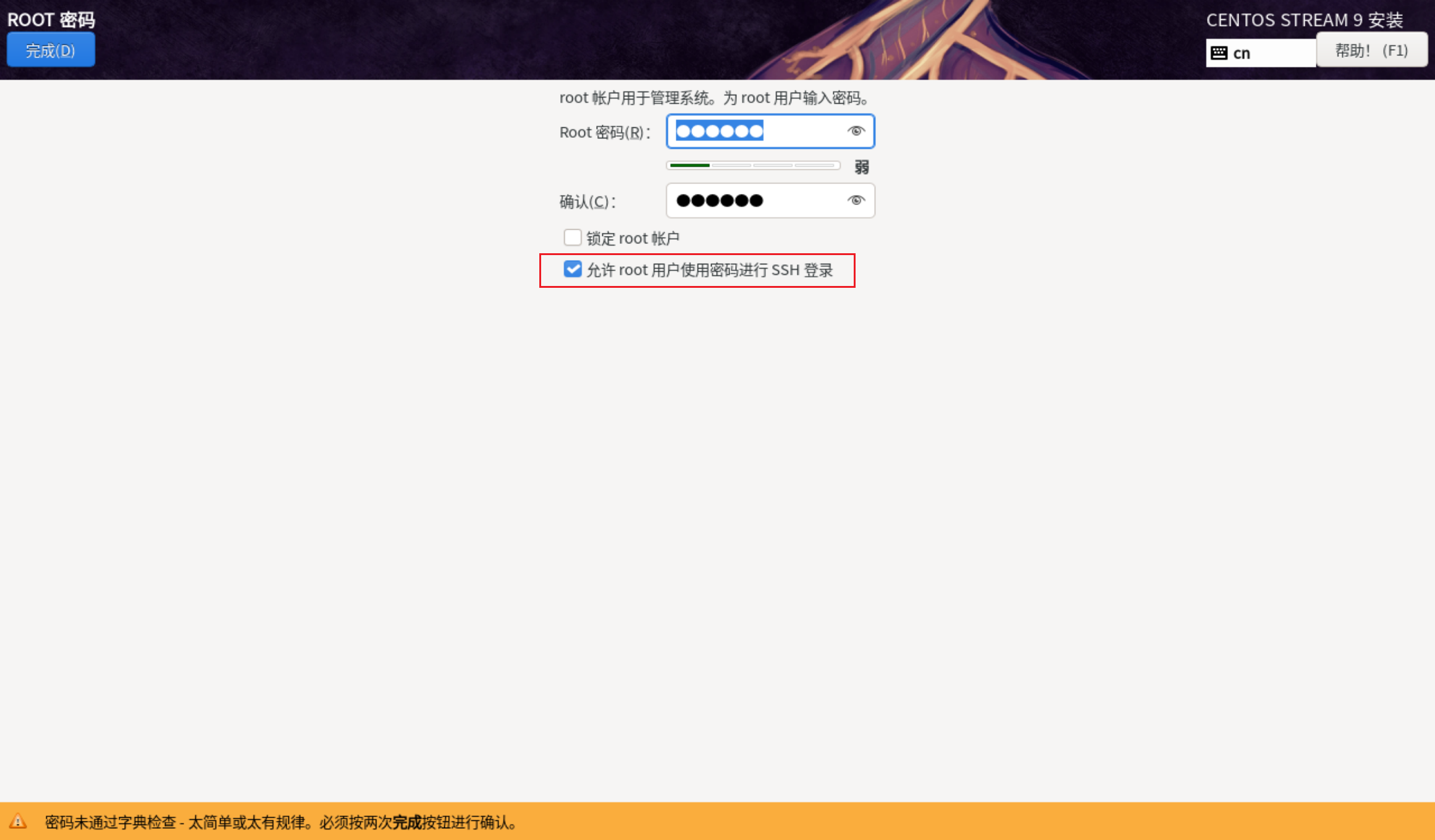
 大家自己设置一个密码,务必要记住(虽然忘记也有方法解决)然后点击完成。并且开始安装,安装的时间有点长,请大家耐心等待。
大家自己设置一个密码,务必要记住(虽然忘记也有方法解决)然后点击完成。并且开始安装,安装的时间有点长,请大家耐心等待。
安装完成后,我们点击"重启系统"。

然后输入账号密码,密码输入的时候是看不见的,大家只需要输入正确即可,然后回车。
登录正确后是这样的。然后我们需要关闭虚拟机并且进行虚拟机的克隆操作(建议大家使用power命令完成关机操作)。

在VMware Worstation的主界面选择并右击虚拟机Hadoop1,依次选择"管理" -> "克隆"选项进入欢迎使用克隆虚拟机向导界面。以下大家只需要和我选择一样,然后一直点击下一步即可。
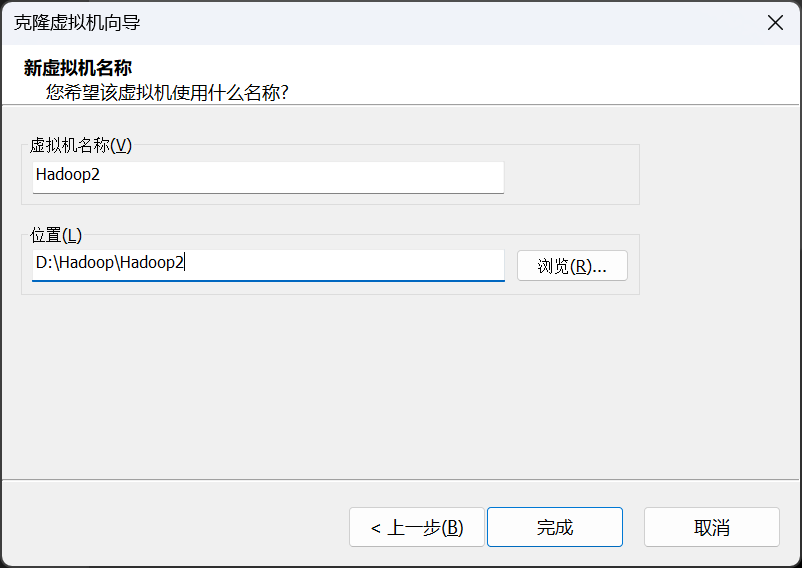
大家按照相同步骤继续安装Hadoop3即可,全部安装完成后我们将三台虚拟机同时打开,接下来我们将完成虚拟机配置。
2,虚拟机的配置
我们需要分别将三台虚拟机命名为hadoop1,hadoop2,hadoop3,我只发一个命名图片其余都一样。大家将三台虚拟机都命名完后重启(命令:reboot)后生效。
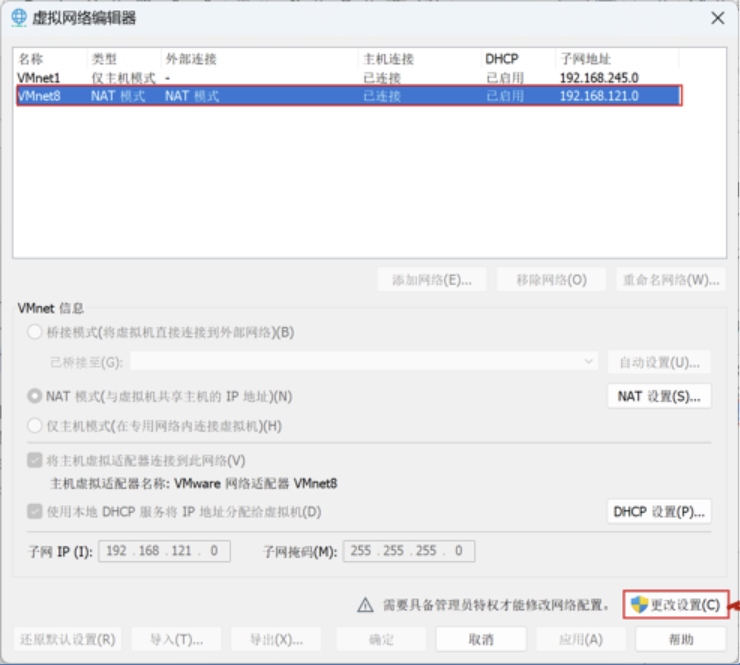
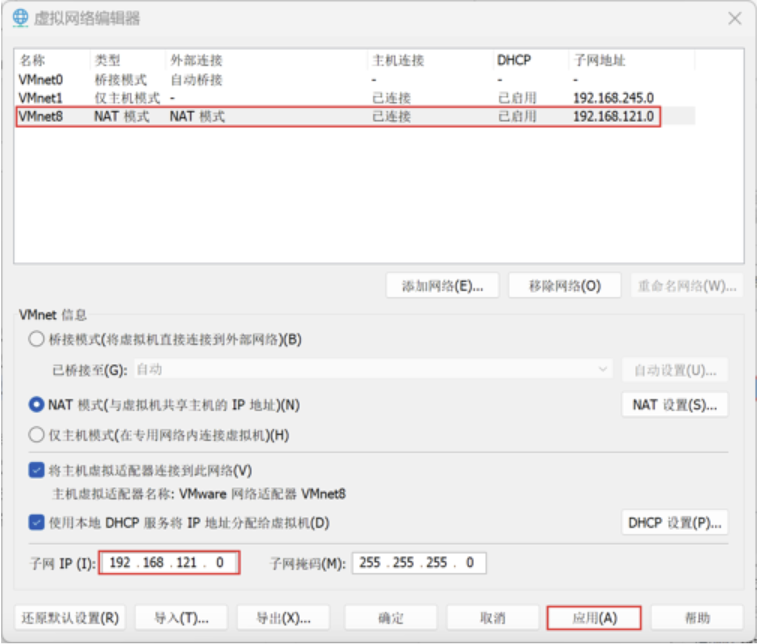
然后我们来配置配置VMware Workstation网络,在VMware Workstation主界面,依次单击"编辑"一"虚拟网络编辑器选项,配置VMware Workstation网络
修改映射文件,分别在虚拟机Hadoop1、Hadoop2和Hadoop3执行"vi/etc/hosts命令编辑映射文件hosts,在配置文件中添加如下内容:(这里需要点vi或者vim命令相关基础,大家可以先了解一下)然后保存文件。
192.168.121.160 hadoop1
192.168.121.161 hadoop2
192.168.121.162 hadoop3
接下来我们需要在三台虚拟机上都完成该配置(我们以Hadoop2为例),我们编辑Hadoop2的网络配置文件ens33.nmconnection。执行以下命令: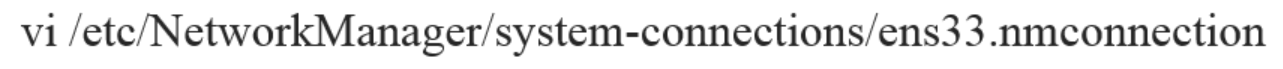
vi /etc/NetworkManager/system-connections/ens33.nmconnection大家如果是一直跟着我的就只需要和我配置一样就好,如果是自己配置的话,大家需要配置自己的IP地址。
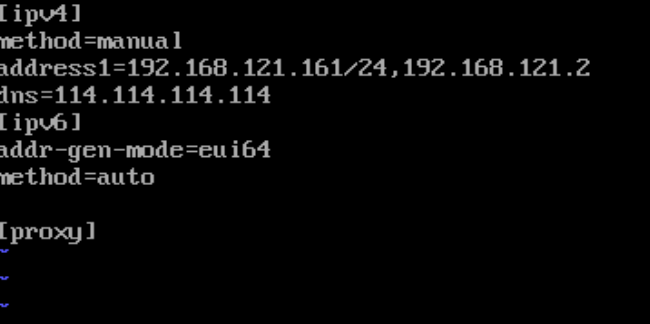
接下来修改虚拟机Hadoop2和Hadoop3的uuid,uuid的作用是使分布式系统中的所有元素都有唯一的标识码。

sed -i '/uuid=/c\uuid='`uuidgen` /etc/NetworkManager/system-connections/ens33.nmconnection然后在三台虚拟机分别执行命令
nmcli c reload
nmcli c up ens33出现以下结果是成功的。

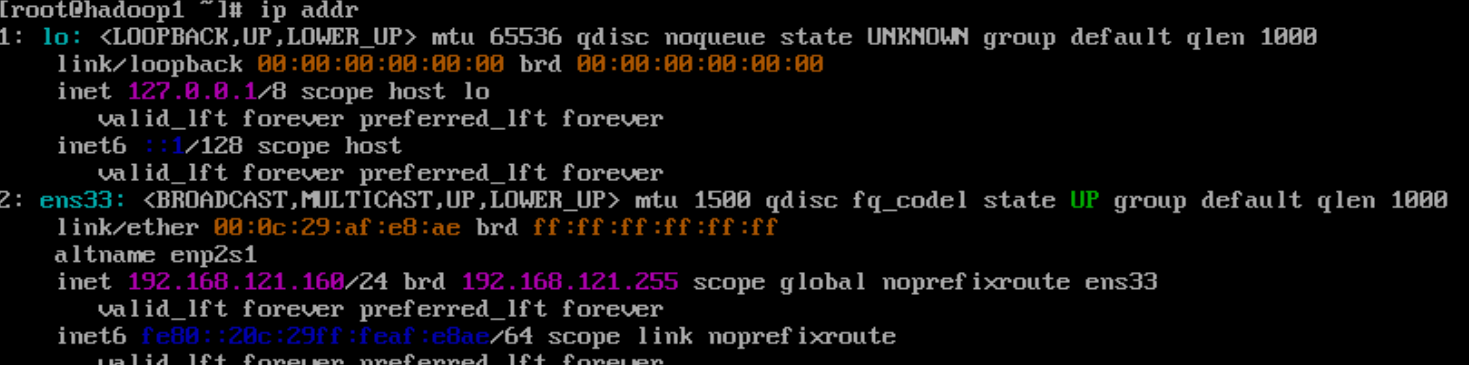
使用命令 ip addr 查看网络信息是否正确(经验证其余两台虚拟机也是正确的)
保证个人计算机连网状态,执行"ping www.baidu.com"命令,检测虚拟机的网络连接是否正常,检测完成后可以通过组合键"Ctr +C"退出检测。(经验证其余两台虚拟机也是没问题的)

接下来我们就可以使用一些远程连接软件对我们的虚拟机进行远程连接了(如finalshell,xshell,MobaXterm等),接下来我将以MobaXterm为例进行连接。大家只需要下载完成后打开跟着我一步一步操作即可。
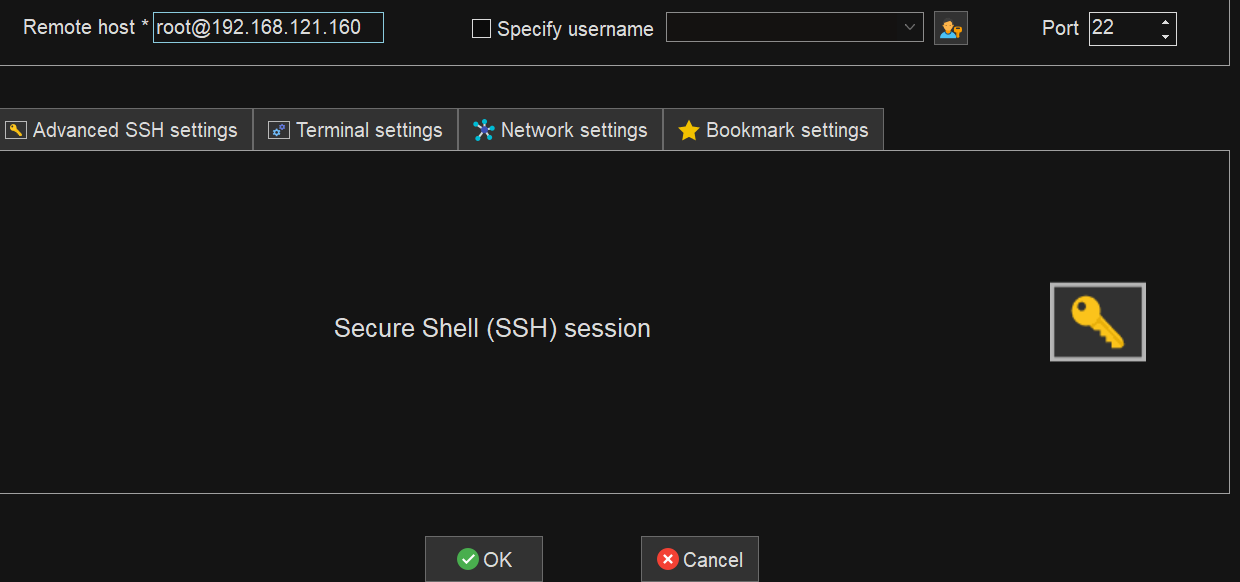
然后输入密码,回车即可。
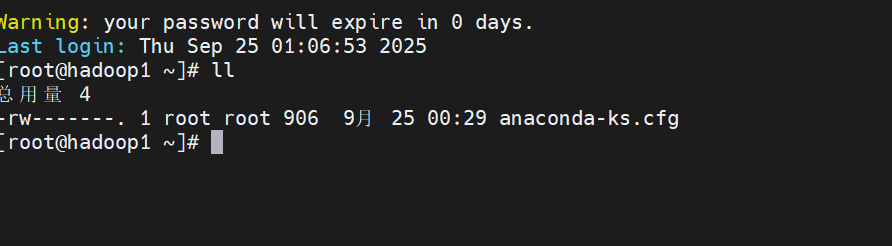
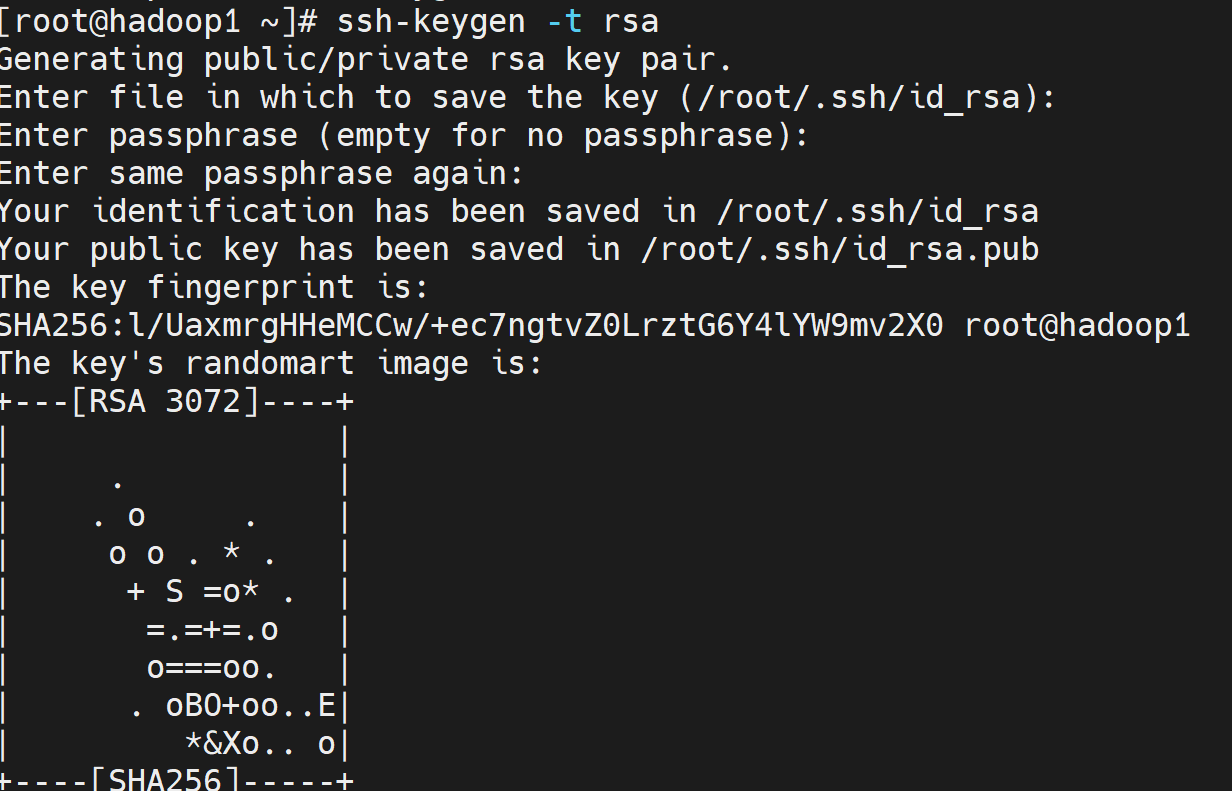
现在我们来配置虚拟机SSH免密登录功能。在虚拟机Hadoop1中执行"ssh-keygen -t rsa"命令,生成密钥。然后回车四次。
在hadoop1上执行以下命令:

ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3需要输入yes+回车+输入密码,然后回车,出现以下结果正确。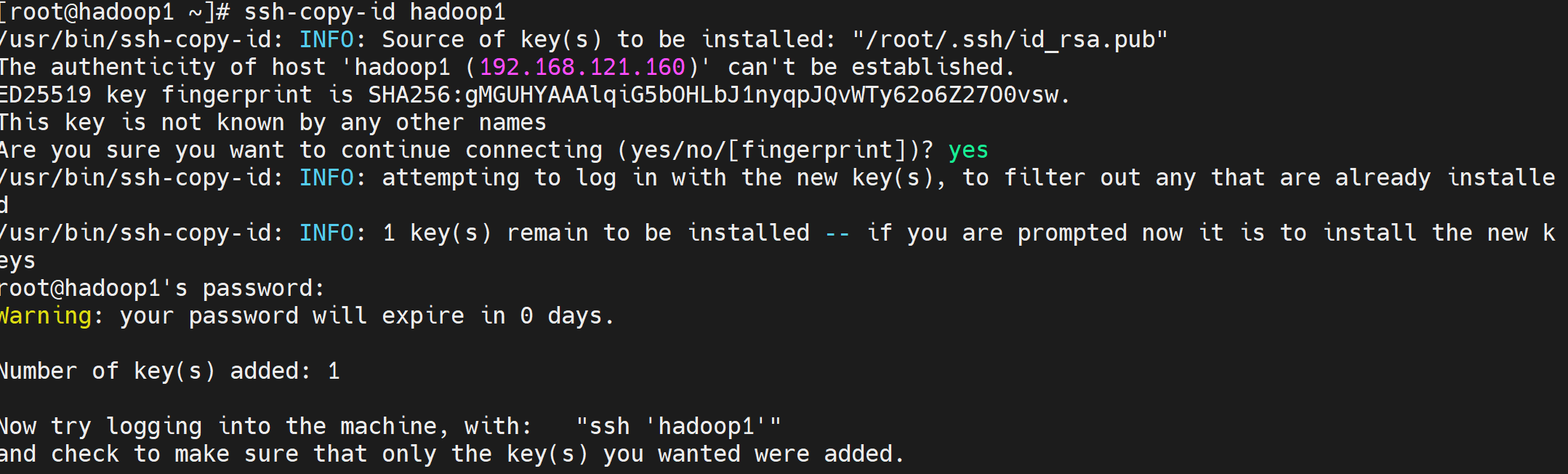
然后可以使用命令"ssh hadoop2"尝试登录。出现以下结果即为成功。(经验证其余虚拟机都是成功的)

3,软件安装
因为hadoo的运行依赖jdk,所以接下来我们需要安装JDK,我们使用的Hadoop版本为3.3.0,支持的最低JDK版本是1.8,所以我们先来安装jdk1.8。我们先在三台虚拟机的根目录上分别创建四个文件夹(export,servers,software,data)
然后我们可以将我们所需要的软件都上传到software文件夹里面。

上传完成后,我们就开始正式安装jdk和hadop了。大家完全跟着我执行命令就好。
tar -zxvf jdk-8u211-linux-x64.tar.gz -C /export/servers
tar -zxvf hadoop-3.3.0.tar.gz -C /export/servers
cd /export/servers
mv jdk1.8.0_211 jdk
mv hadoop-3.3.0 hadoop然后我们给jdk和hadoop配置环境变量并将以下内容添加到文件末尾,保存文件并更新环境变量,
vi /etc/profile
// 以下是需要添加的内容
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
// 保存并退出后执行以下命令
source /etc/profile可以看出我们已经都安装成功了。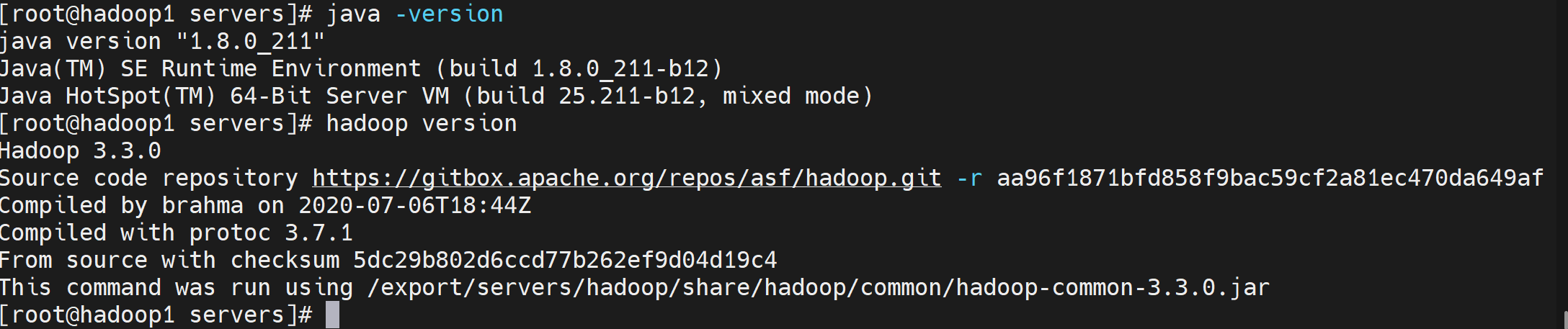
然后执行以下命令(执行完成后我们就可以在hadoop2和hadoop3的/export/servers目录中看到jdk了,后续我们配置完hadoop文件后在传hadoop):
scp -r /export/servers/jdk root@hadoop2:/export/servers
scp -r /export/servers/jdk root@hadoop3:/export/servers
scp -r /etc/profile root@hadoop2:/etc/
scp -r /etc/profile root@hadoop3:/etc/接下来,我们来配置Hadoop的运行时环境,首先我们来配置hadoop-env.sh文件
cd /etc/hadoop
vi hadoop-env.sh
// 将以下内容放到hadoop-env.sh文件的末尾并保存退出
export JAVA_HOME=/export/servers/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root然后,我们分别来编辑"core-site.xml","hdfs-site.xml","mapred-site.xml","yarn-site.xml"文件。
vi core-site.xml
// 以下内容放到core-site.xml文件的<configuration></configuration>内部保存并退出
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<property>
<name>hadoop.http.staticuser.user </name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
vi hdfs-site.xml
// 以下内容放到hdfs-site.xml文件的<configuration></configuration>内部保存并退出
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
vi mapred-site.xml
// 以下内容放到mapred-site.xml文件的<configuration></configuration>内部保存并退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
vi yarn-site.xml
// 以下内容放到yarn-site.xml文件的<configuration></configuration>内部保存并退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
vi workers
// 删除掉文件中原有内容并将以下内容放到workers内部保存并退出
hadoop1
hadoop2
hadoop3然后我们将配置好的hadoop分发到其余的两台虚拟机,这样我们就不用单个每个都配置一遍了。
scp -r /export/servers/hadoop root@hadoop2:/export/servers
scp -r /export/servers/hadoop root@hadoop3:/export/servers最后,我们对Hadoop进行格式化文件系统的操作(只需要在hadoop1执行)
hdfs namenode -format看到以下结果表示格式化成功。

然后,我们只需要在hadoop1开启Hadoop
start-all.sh这是最后一步,我们需要在三台虚拟机上分别执行命令:"jps",查看结果是否和我一样,如果和我一样的话,那就安装成功了,如果不一样的话,查看配置文件是不是有问题,然后删除掉data文件夹中关于hadoop的内容,然后重新格式化。
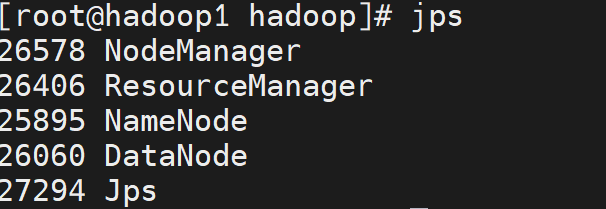
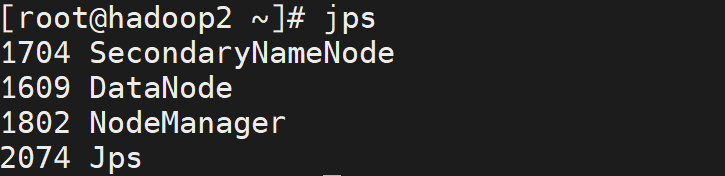

最后的最后,我们可以关闭三台虚拟机的防火墙,然后WebUI查看Hadoop的运行状态。
systemctl stop firewalld
systemctl disable firewalld
// 在浏览器的地址栏输入 http://192.168.121.160:9870查看结果是否和我一样
// 在浏览器的地址栏输入 http://192.168.121.160:8088查看结果是否和我一样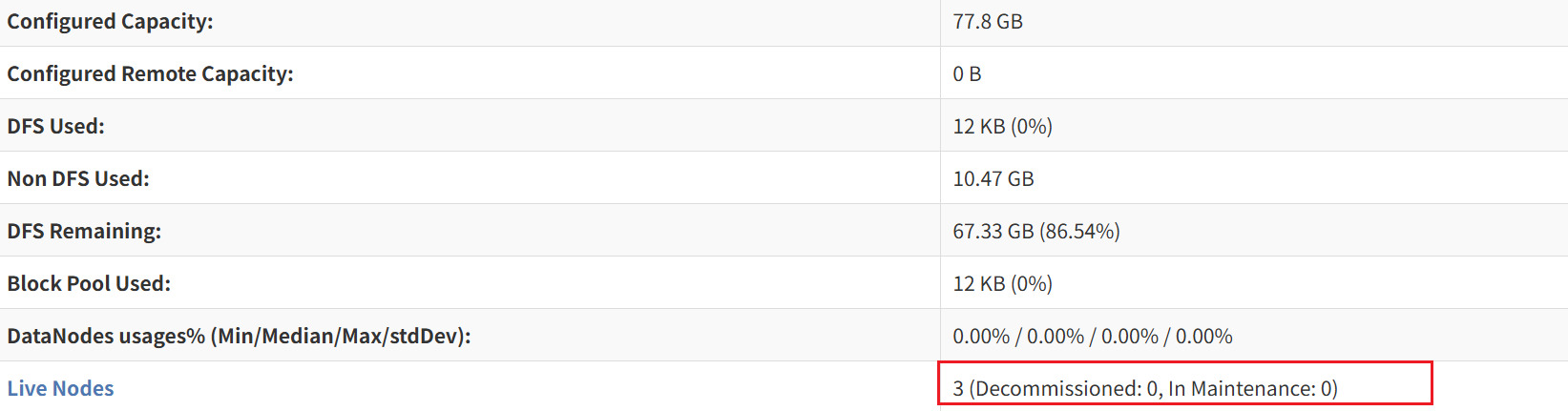
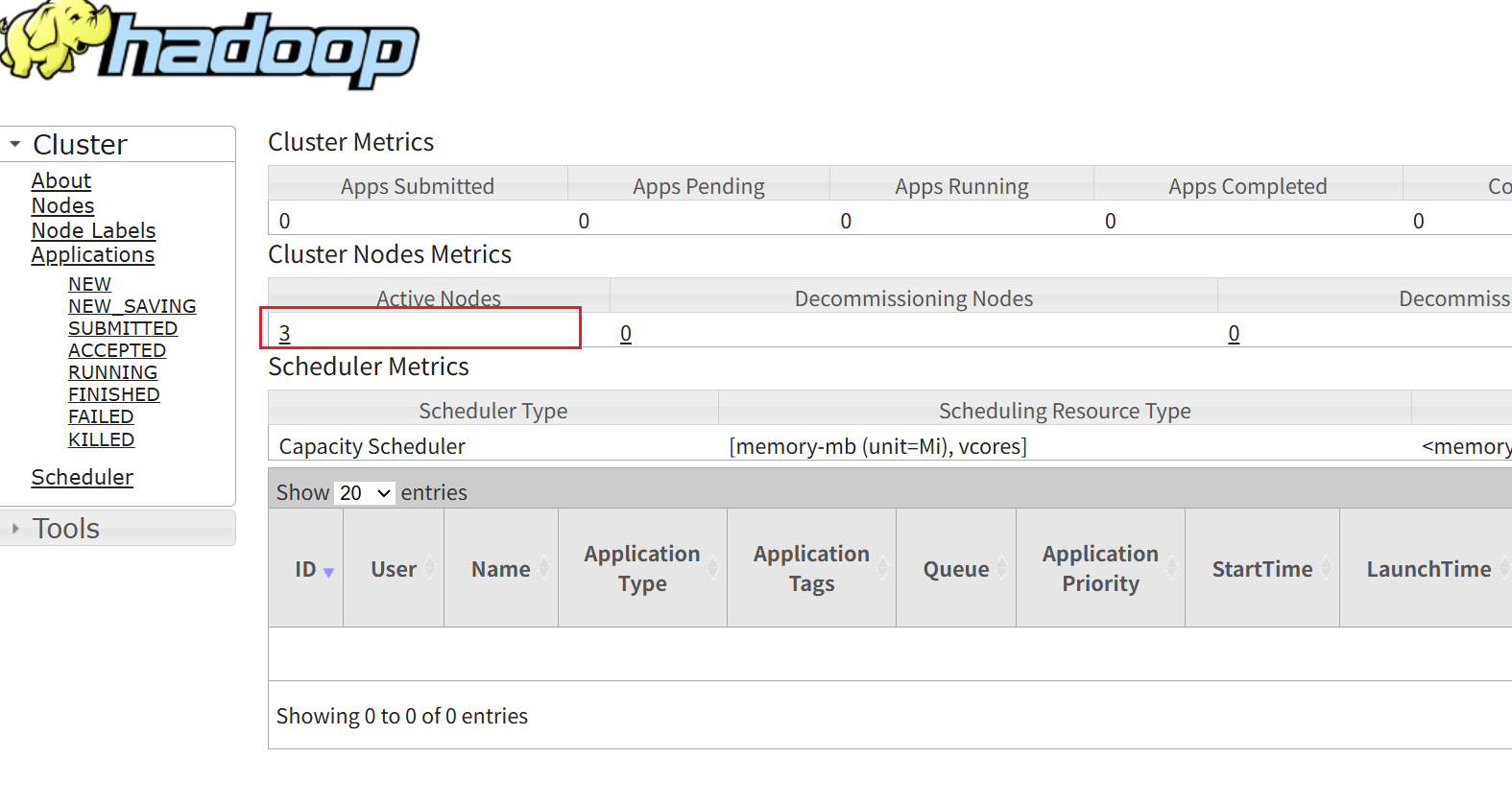
那么我们Hadoop的安装部署就先告一段落,大家可以关注我,接下来会分享一些安装中可能出现的错误的解决方案已经安装配置其他环境的教程。大家在安装中遇见问题可以发到评论区,大家一起讨论。如果需要的话可以直接和我要配置好的Hadoop文件,这样大家就不需要花时间配置。