文章目录
- 一、引言
- 二、选型维度
- 三、当前主流技术路线对比
- [四、为什么 Apache IoTDB 成为 黑马?](#四、为什么 Apache IoTDB 成为 黑马?)
- 五、实战和资源获取
- 六、结语
一、引言
过去,我们关注的是电商的订单、社交网络的用户关系,这些数据是离散的、事务性的。但随着工业4.0、新能源车联网以及智慧能源的爆发,一种新的数据洪流正在席卷服务器:时序数据。
一个有数百台风力发电机的新能源场站,每一台风机内部都有数千个传感器。不分昼夜,毫秒级的频率记录叶片转速、发电机温度、风速风向、电压电流等信息。不再是简单的一条记录,而是带有时间戳的、持续不断的数据脉冲。
这时候,通用数据库开始 汗流浃背 。
很多技术团队在项目初期,习惯性用 MySQL 或 PostgreSQL 关系型数据库来存储设备数据。设备少、频率低的时候,看起来都很好。但设备接入量从几百台扩展到几万台,或者采集频率从分钟级提升到秒级,问题就来了:
- 写入瓶颈: 数据库为保证事务的ACID特性(特别是强一致性),每秒百万级的数据点写入的I/O 锁竞争激烈,写入速度断崖式下跌。
- 存储成本: 时序数据是海量的,写多读少。传统数据库存储一年的传感器数据,膨胀的磁盘占用量会让存储预算瞬间爆炸。
- 查询低效: 想查询"某台设备过去一个月每5分钟的平均温度趋势",数亿行的大表进行聚合查询,等待时间长达数分钟,对实时监控大屏来说是不可接受的。
数据是有"保鲜期"的。 物联网和工业互联网场景下,数据的价值随着时间的推移迅速衰减。如果不能实时写入、实时查询,这些数据就成无意义的"数字垃圾"。
所以,面对这种高并发写入、海量存储需求以及基于时间维度的复杂查询,通用的关系型数据库已经不再适用。要一种专门为"时间"而生的基础设施:时序数据库(Time Series Database, TSDB)。
一款合适的 TSDB,不再是架构设计的"锦上添花",而是决定项目能否在低成本下平稳运行的必要。像压缩饼干一样极致压缩数据,也能像流水线一样吞吐海量写入。
面对市面上琳琅满目的时序数据库产品,该如何透过营销词藻,选出最适合自己的那一款?这篇文章从实战角度为你拆解。
二、选型维度
市面上琳琅满目的时序数据库产品,各种宣传口径让人眼花缭乱。选型要回归到最核心的业务需求和技术痛点。
2.1、极致的写入性能和压缩比
这是时序数据库最核心的竞争力,也是区分"真时序"和"伪时序"的重要指标。
- 写入性能: 物联网场景的数据写入是"洪水猛兽"式的。一台设备每秒采集几十个点位,成千上万台设备同时在线,数据库要处理每秒数百万甚至千万级别的数据点写入。还有,这些数据可能不是严格按时间顺序到达(乱序数据 ),甚至会有部分延迟数据。一个优秀的时序数据库必须能高效处理这些挑战,确保数据不丢失、不阻塞,并且写入延迟极低。如果写入性能不达标,再好的分析都只是空中楼阁。
- 压缩比: 时序数据最大的特点就是量大。如果存储成本居高不下,性能再好,企业也很难承受。一个高效的时序数据库,会采用各种先进的压缩算法,把原始数据进行极致压缩。经常会看到,原本1TB的原始数据,经过时序数据库存储后,能压缩到100GB甚至更低,实现10:1甚至更高的压缩比。不仅是节省了硬盘空间,更是大幅降低企业的TCO(总拥有成本)。
2.2、端边云协同能力
现代物联网架构已经不再是简单的"设备直连云端"模式,而是普遍采用"端侧采集-边缘计算-云端汇总"的多级架构。这种架构的出现,是为应对物联网场景中网络不稳定、带宽受限、实时性要求高以及数据隐私等。
- 边缘侧的计算资源有限,网络环境复杂多变,长时间断网的情况。这就要求时序数据库必须有轻量化部署的能力,能在资源受限的边缘设备稳定运行。
- 边缘侧的数据在本地进行初步处理和存储后,要可靠地同步到云端进行长期存储和全局分析。优秀的时序数据库是开箱即用的边云数据同步机制,能处理网络中断后的续传、数据一致性校验等问题,确保数据在不同层级之间安全、高效、可靠流转。
2.3、生态兼容性和查询灵活
数据库不只是存储数据的容器,更是数据价值挖掘的基础。一个易用、开放的数据库能大大降低开发和运维的门槛。
- 查询语言: SQL(Structured Query Language)是最熟悉、最强大的数据查询语言。如果一个时序数据库支持类SQL的查询语法,降低学习成本,快速上手,用已有的SQL技能进行数据分析。非SQL的查询语言虽然在某些特定场景下更高效,但也会带来更高的学习曲线和生态割裂感。
- 生态集成: 时序数据要跟大数据生态的其他组件协同工作。好的时序数据库有丰富的API接口、连接器或插件,能够跟主流的大数据平台、BI工具、消息队列等无缝集成,形成一个完整的解决方案。
三、当前主流技术路线对比
很长一段时间里,时序数据库(TSDB)这个概念刚刚兴起,技术圈的目光几乎全部聚焦在国外开源产品。随着国内工业互联网场景的爆发式增长,发现这些产品面对中国海量、复杂的工业场景有点 "水土不服"。
InfluxDB: 提起时序数据库,InfluxDB 是一个绕不开的名字。入局早、社区大、生态完善,几乎是 TSDB 的代名词。很多初创项目,InfluxDB 是默认的首选。
- 优势: 生态非常丰富,Telegraf 插件体系让数据采集变得非常简单,上手快。
- 缺点1: InfluxDB 最受诟病的一点是 单机版开源,集群版闭源(商业化)。业务规模扩大,单机撑不住,要做高可用集群就得掏昂贵的授权费,要么只能自己魔改或者迁移。
- 缺点2: InfluxDB 采用倒排索引机制,标签(Tag)数量过多,内存消耗会呈指数级爆炸,写入性能骤降甚至 OOM(内存溢出)。
Prometheus: Kubernetes 和微服务的普及,Prometheus 成了运维监控领域的绝对标准。很多团队因为熟悉 Prometheus,就想直接用在物联网设备监控。
- 优势: 跟 K8s 结合完美,强大的 PromQL 查询语言,非常适合监控服务器、容器等 IT 基础设施。
- 缺点1: Prometheus 是基于 Pull(拉取) 模式设计的,适合服务器这种稳定的端点。但物联网设备在防火墙后,或者网络不稳定,更适合 Push(推送) 模式。
- 缺点2: Prometheus 的设计初衷是短期监控,不擅长处理跨度长达数年的历史数据归档和分析。用它来存工业历史数据,真是"小马拉大车"。
因为国外产品在集群开源性 、超大规模时间线支持 以及端边云协同 上的缺失,国内涌现出一批优秀的时序数据库,其中以 Apache IoTDB 和 TDengine 为代表。
这一代国产数据库不再是 "套壳",而是从底层存储引擎开始重构:
- 放弃通用的 KV 存储、倒排索引,针对物联网"设备-测点"的树形结构设计原生的文件存储格式,彻底解决时间线膨胀带来的性能崩塌问题。
- 像 Apache IoTDB 这样的顶级项目,坚持核心功能全开源,包括集群版和单机版。
- 同等硬件配置下,国产 TSDB 在写入吞吐量和压缩比上,能达到 InfluxDB 的数倍甚至十倍以上。
构建一个连接数万台设备、要存储数年数据、且要求高可用集群的工业级物联网平台,必须转向更懂工业、架构更先进的国产自研方案。
这些国产方案,Apache IoTDB 凭借独特的"端-边-云"一体化架构,成为越来越多行业龙头的标准配置。
四、为什么 Apache IoTDB 成为 黑马?
Apache IoTDB 不是横空出世,而是由清华大学跟与多家工业企业深度合作,历经多年打磨,最终捐献给 Apache 基金会并成为顶级项目。从一开始就瞄准工业物联网的复杂场景,设计理念和技术架构,完美契合。
IoTDB 最令人称道的,莫过于独树一帜的树形数据模型。
- 工业物联网的数据具有天然的层级关系。IoTDB 的树形模型能把这种物理结构直接映射到数据库的逻辑结构中,路径如
root.factoryA.workshopB.deviceC.sensorD。这种设计直观、高效,不用像其他数据库那样通过复杂的 Tag 组合来模拟层级,彻底解决 InfluxDB 等产品面对高基数场景的内存爆炸问题。
图例说明
Root 根节点
Storage Group 存储组
Device 设备
Measurement 测点/物理量
root
ln: root.ln
集团层
sgcc: root.sgcc
电网层
wf01: root.ln.wf01
风电场1
wf02: root.ln.wf02
风电场2
d1: root.sgcc.d1
供电所1
status: root.ln.wf01.status
运行状态
temperature: root.ln.wf01.temperature
温度
speed: root.ln.wf02.speed
风速
voltage: root.sgcc.d1.voltage
电压
current: root.sgcc.d1.current
电流
- TsFile:专为时序数据打造的存储格式。 IoTDB 放弃通用的存储引擎,而是自研高效的 TsFile 存储格式。TsFile 专门针对时序数据的特性进行了深度优化。能把同一时间序列的数据紧密存储在一起,并采用多种高级压缩算法,实现极高的压缩比。
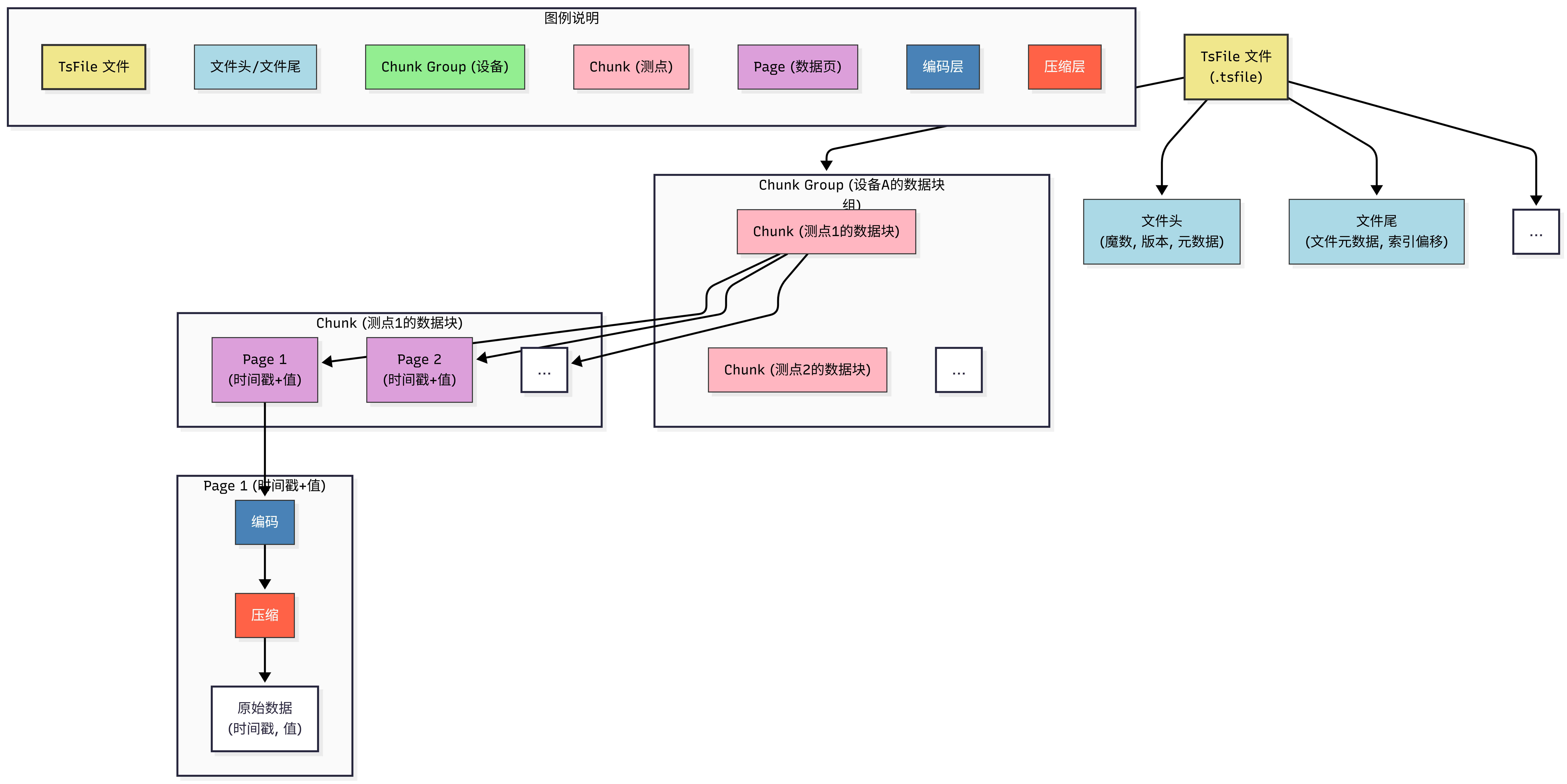
IoTDB 在性能上的表现也非常惊艳。
- 得益 TsFile 及内置的压缩算法,IoTDB 在实际应用的数据压缩比能达到 10:1 甚至更高。原本要10TB硬盘才能存储的数据,现在只要1TB,降低硬件采购和运维成本。对于动辄存储数年、甚至十年工业历史数据的企业来说,这笔成本节约是天文数字。
- 标准硬件配置,IoTDB 能轻松支持千万级设备接入,并实现每秒百万级甚至千万级的数据点写入。优秀的乱序数据处理能力,也确保在网络不稳定或数据采集系统出现异常时,数据依然能稳定写入,不丢失。
端边云"一处研发,随处运行" 是 IoTDB 区别于其他时序数据库。
- 全场景覆盖: IoTDB 不只是云端数据库,还提供轻量级的边缘端版本。可以把 IoTDB 部署在资源受限的边缘网关、工控机上,实现数据在源头的实时存储和处理。
- TsFile Sync:无缝的边云数据同步: IoTDB 内置强大的 TsFile Sync 工具,能实现边缘端和云端之间的数据双向同步。即使边缘网络长时间中断,数据也会在本地缓存,待网络恢复后自动、可靠地同步到云端。这种"断点续传"、"离线自治"的能力,完美解决工业现场网络环境复杂、不稳定带来的数据传输难题,真正实现"一处研发,随处运行"。
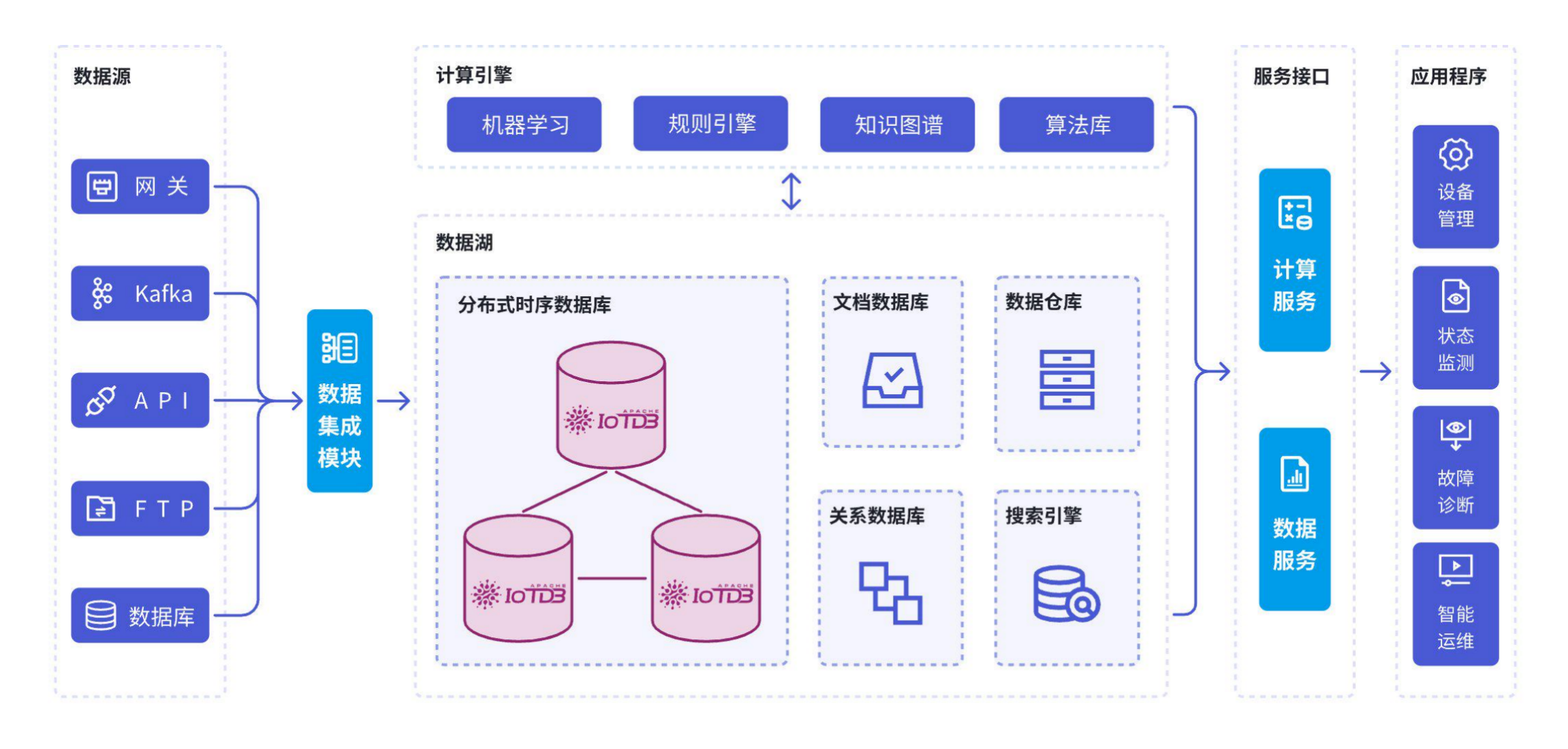
真正的开源和企业级支持:
- 作为 Apache 基金会的顶级项目,IoTDB 秉承 Apache 项目的开放、透明和社区驱动原则。所有核心代码完全开源,包括单机版和集群版,企业可以自由使用、修改和贡献。
- 虽然是纯粹的开源项目,但 IoTDB 背后有专业的商业化公司:天谋科技(Timecho) 提供企业级的技术支持、定制开发和解决方案服务。用 IoTDB 既能享受到开源的自由和灵活性,又能获得专业的商业保障,确保系统稳定运行和长期演进。
五、实战和资源获取
不要一上来就试图把整个公司的核心业务全部迁移到新的数据库上,那是"豪赌",不是工程。
第一步:边缘试点。
- 挑选一个非核心、但数据量有一定规模的边缘场景。
- 部署单机版 IoTDB,跑通数据采集、写入和基础查询流程。
- 重点观察写入速度是否平稳、磁盘占用是否显著下降(对比之前的存储方案)。
第二步:双写验证。
- 业务层开启"双写"模式,一份数据写入旧系统,一份写入 IoTDB。
- 运行一周到一个月,对比两者的查询结果一致性、查询延迟以及系统资源消耗。
第三步:逐步切换与集群扩展。
- 验证无误后,把读流量逐步切向 IoTDB。
- 随着接入设备量的增加,用 IoTDB 的集群能力进行横向扩展,实现高可用。
很多工程师用 IoTDB 时,容易带着关系型数据库的惯性思维,发挥不出它的威力。
- 忘掉 MySQL 的"主键"和"外键"。用 IoTDB 的树形结构,直接把设备层级映射为存储路径。
- 创建时间序列时,尽量精准定义数据类型(INT32, FLOAT, BOOLEAN 等)。虽然 IoTDB 支持自动推断,但显式定义能带来更好的压缩效果和查询性能。
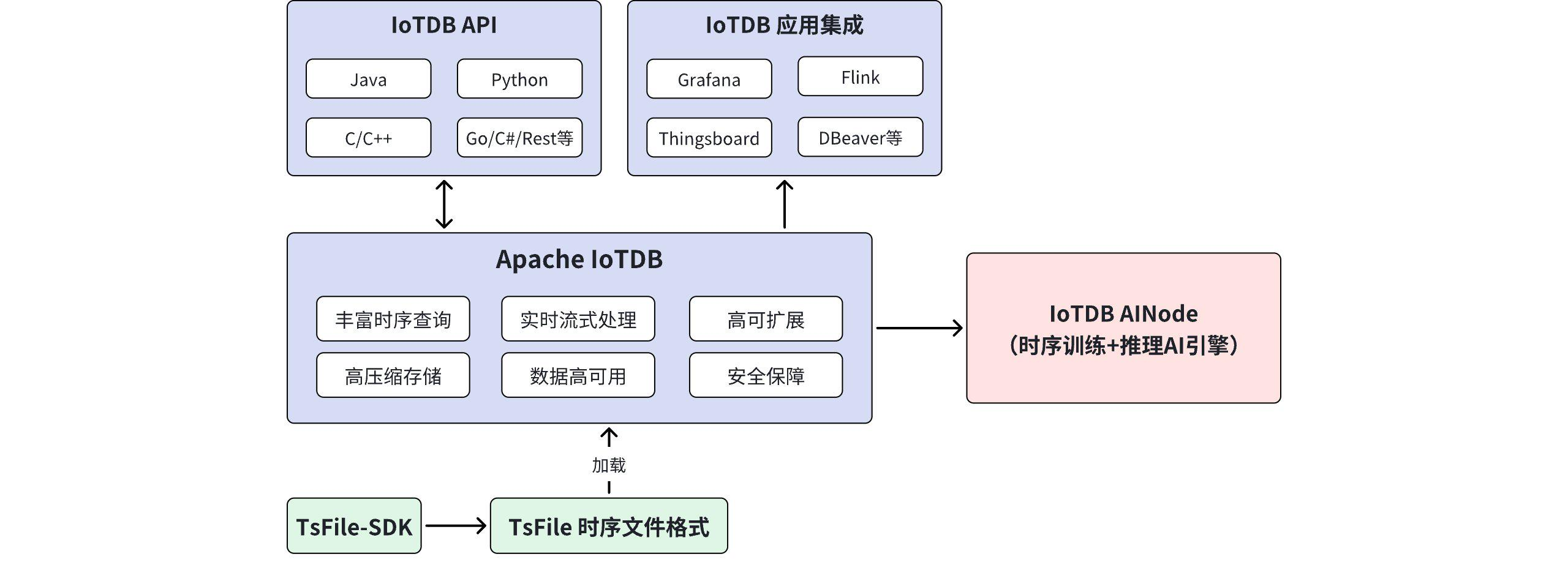
实际应用编程:
C++ 实现:
cpp
#include "Session.h"
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
int main(int argc, char **argv)
{
Session *session = new Session("127.0.0.1", 6667, "root", "root");
session->open();
std::vector<std::pair<std::string, TSDataType::TSDataType>> schemas;
schemas.push_back({"s0", TSDataType::INT64});
schemas.push_back({"s1", TSDataType::INT64});
schemas.push_back({"s2", TSDataType::INT64});
int64_t val = 0;
Tablet tablet("root.db.d1", schemas, /*maxRowNum=*/ 10);
tablet.rowSize++;
tablet.timestamps[0] = 0;
val=100; tablet.addValue(/*schemaId=*/ 0, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=200; tablet.addValue(/*schemaId=*/ 1, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=300; tablet.addValue(/*schemaId=*/ 2, /*rowIndex=*/ 0, /*valAddr=*/ &val);
session->insertTablet(tablet);
tablet.reset();
std::unique_ptr<SessionDataSet> res = session->executeQueryStatement("select ** from root.db");
while (res->hasNext()) {
std::cout << res->next()->toString() << std::endl;
}
res.reset();
session->close();
delete session;
return 0;
}Java的实现:
java
package org.apache.iotdb;
import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
public class SessionExample {
private static Session session;
public static void main(String[] args)
throws IoTDBConnectionException, StatementExecutionException {
session =
new Session.Builder()
.host("172.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s3", TSDataType.FLOAT));
Tablet tablet = new Tablet("root.db.d1", schemaList, 10);
tablet.addTimestamp(0, 1);
tablet.addValue("s1", 0, 1.23f);
tablet.addValue("s2", 0, 1.23f);
tablet.addValue("s3", 0, 1.23f);
tablet.rowSize++;
session.insertTablet(tablet);
tablet.reset();
try (SessionDataSet dataSet = session.executeQueryStatement("select ** from root.db")) {
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
}
}
session.close();
}
}Apache IoTDB 拥有一个非常活跃的开源社区。遇到问题不要死磕,用社区资源是解决问题最快的方式。
- 官网(文档最全): https://iotdb.apache.org/ ------ 快速上手指南,详细的配置参数说明,应有尽有。
- 代码仓库(GitHub): https://github.com/apache/iotdb 。
获取安装包: 直接在官网下载编译好的二进制包,解压即用,不用复杂的编译过程。
下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com
六、结语
一款对的时序数据库,不只是选择一个存储工具。Apache IoTDB 凭借专为工业设计的架构、极致的性能和开放的生态,是最好的选择。
-
官方网站: https://iotdb.apache.org/ ,最新文档、下载安装包、查看 API 指南。*
-
Timecho 官网: https://www.timecho.com/
