对发表于 FAST 2025 的一篇论文的解读,介绍了一种名为 Archer 的新型移动设备内存压缩技术。其核心目标是在高内存压力下提升系统响应速度、改善用户体验,特别是在突发内存需求场景中。
一、背景与动机
- 移动设备内存有限,系统广泛采用 页级内存压缩(如 ZRAM)来节省空间。
- 然而,在内存紧张时,频繁的压缩/解压操作会消耗大量 CPU 资源、引发上下文切换,导致卡顿。
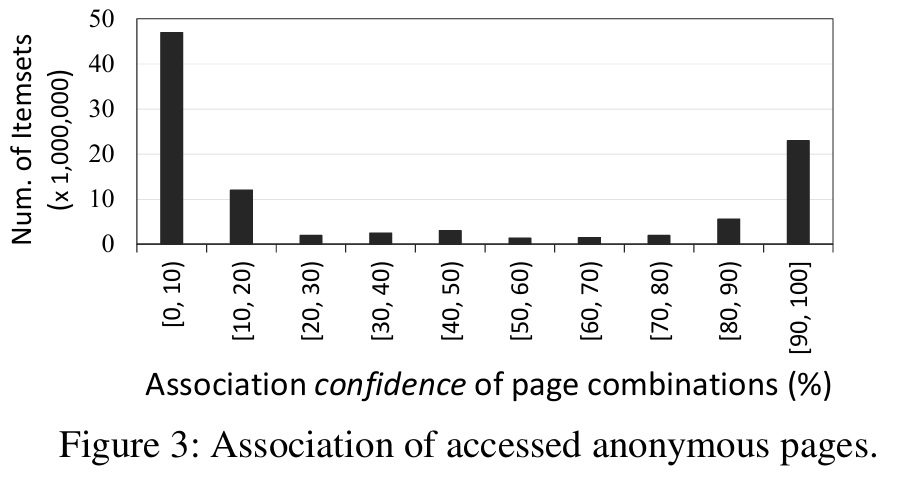
- 作者通过分析发现:约 25% 的匿名内存页之间存在高度访问关联性,这为优化压缩策略提供了机会。
二、Archer 的核心思想
基于页面访问的关联规则,对高度相关的页面进行批量压缩,而非传统的逐页压缩,从而:
- 减少压缩/解压次数
- 降低读取放大(Read Amplification)
- 提升突发内存压力下的响应速度
三、系统架构(三大组件)
- 足迹流生成器(FSG)
- 用 FIFO 队列记录页面访问历史(物理地址)
- 采用"半离线"策略,异步挖掘关联规则,避免影响前台性能
- 频繁模式树列表(FT-List)
- 按应用 UID 分组,每组维护一棵 FP-Tree(频繁模式树)
- 使用改进版 FP-Growth 算法挖掘页面间的关联规则
- 平时走传统 LRU 回收路径;突发内存压力时触发批量压缩
- 自适应压缩区域(ACR)
- 基于 ZRAM 改造,支持 大粒度压缩块(>4KB)
- 多个关联页压缩为一个块,共享一个虚拟句柄(vhandle)
- 缺页时整块解压,其余页面缓存到 swap cache,减少后续开销
四、实验结果(在 Pixel 6 Pro、Pixel 3、华为 P20 上测试)
用户体验显著提升:
- 冷启动速度提升 30--37% ,热启动提升 30--55%
- 拍照速度提升 1.22--1.42 倍
- 短视频帧率提升 1.31--1.39 倍
- 尾延迟大幅降低(冷启动尾延减少 44.9%,热启动减少 60.3%)
性能与开销分析:
- 80% 以上启动过程使用大粒度压缩
- 大块压缩吞吐达 522.6 MB/s(远高于 4KB 粒度的 205.1 MB/s)
- 读取放大率 ≤ 1.08,92.6% 的预解压页面很快被访问
- 能耗仅增加 0.69%
- 内存开销仅百 KB 级别,可接受
五、总结
Archer 是首个将关联规则挖掘 引入内存压缩的系统,通过自适应的大粒度批量压缩,在不修改应用代码的前提下,显著提升了移动设备在内存紧张时的流畅度和响应性能,为未来内存管理提供了新思路。
详细介绍:
本次解读的论文来自FAST 2025。
在移动系统中,内存通常以页为单位进行压缩,从而节省空间。但是在面对一些突发性内存需求时,频繁的压缩与解压操作会消耗大量CPU资源并引发剧烈的上下文切换造成卡顿。本文分析流行应用程序的页面访问特征发现存在大量高度关联的页面,基于此,提出了一种具备页面关联规则感知的自适应内存压缩技术Archer,通过识别关联页面并进行自适应的大粒度批量压缩,无需修改应用程序代码,在内存耗尽的情况下显著缓解响应迟缓问题。
01.背景和动机
随着移动应用对内存需求的不断增长,以及缓存应用数量的持续增加,移动设备上的内存资源日益紧缺。为了在有限内存中运行更多应用,移动系统广泛采用内存压缩技术,当内存不足时,系统会将不活跃的匿名页面压缩到内存中的特定区域。这种页级压缩方法在高内存压力下会导致频繁的压缩与解压操作,消耗大量CPU资源并引入显著的上下文切换开销。
如图3所示,分析流行应用的页面访问足迹发现,大约四分之一的匿名内存页之间存在高度相关性,通过挖掘内存页面之间的关联规则,并将高度关联的页面一起压缩,可以在突发内存需求场景下显著提升系统响应速度,同时最小化读取放大。
02.设计实现
Archer提出了一种面向关联规则的移动设备内存压缩框架。其基本思想是挖掘内存页面之间的内在关联规则,并将高度相关的页面合并压缩。该设计包含三个核心组件,如图4所示:足迹流生成器(footprint stream generator,FSG)、频繁模式树列表(frequent-pattern tree list,FT-List)和自适应压缩区域(adaptive compression region,ACR)。
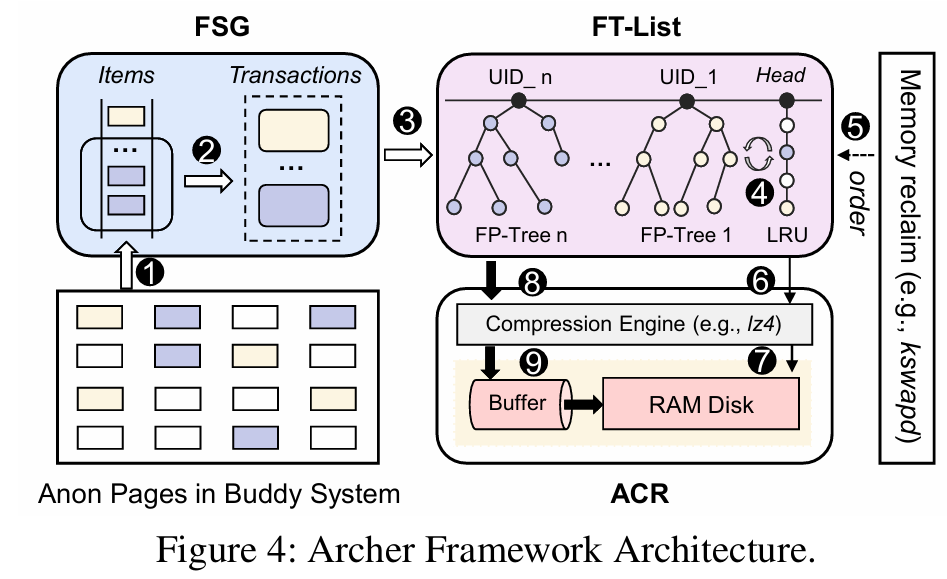
2.1 足迹流生成器(FSG)
FSG维护一个先入先出(FIFO)的循环队列,用于记录页面访问历史。当匿名页面被访问时,Archer获取其物理地址作为"项"插入队列构成一条数据流。同时内核中新增一个守护进程作为独立控制单元,通过滑动窗口将序列项转换为"事务"。生成的事务构成足迹流,并被送往FT-List进行进一步处理。
为了不影响前台性能,FSG采用"半离线"策略:实时收集数据项,但允许延迟并异步进行关联性挖掘。
2.2 频繁模式树列表(FT-List)
FT-List将LRU与FP-Tree(频繁模式树)融合,与FSG协同工作,为后续的联合压缩提供页关联信息支撑。
由于大多数高度相关的内存页面属于同一应用,所以FT-List按App的UID进行分组管理,每个UID维护一颗FP-Tree,使用改进版的FP-Growth算法为每个App构建对应的页关联树,高效地表示和索引页面间的关联关系。
这种融合结构使得Archer能够灵活地切换压缩策略。在常规使用中,Archer进入传统页面回收LRU路径,直接从链表中回收非活跃页面并逐页压缩。当遭遇突发内存需求时,系统从头到尾扫描FT-List,选择关联页面进行打包压缩。
2.3 自适应压缩区域(ACR)
ACR基于ZRAM现有的地址索引方法和结构进行构建。在传统ZRAM中,将压缩区域中的4KB页面称为"槽(Slot)",每个压缩页的内容作为对象管理,每个对象由句柄(handle)索引,handle由页表项PTE指向。当Archer启用后,生成的压缩块通常大于4KB槽,于是将大压缩块拆分为多个对象存储,每个对象仍由句柄索引。这种属于同一个大压缩块的页面,PTE将指向同一个handle,该handle指向一个元数据结构,包含一个存储所有关联页面信息的数组和一个索引该压缩块句柄(vhandle)的指针,如图6所示。
当发生缺页中断时,Archer会让Page Fault处理函数检查页标志来判断目标页面的压缩类型。若目标页为单页压缩,则解压方式与ZRAM相同;否则,Archer通过vhandle找到并解压包含该页的整个压缩块,将其余已解压页面保留在swap cache中。
03.实验测试
将Archer与原始Linux内存压缩机制以及移动系统中的最先进方案进行对比评估,实验在Google Pixel6 Pro、Pixel3和华为P20上进行。
(1)用户体验提升:
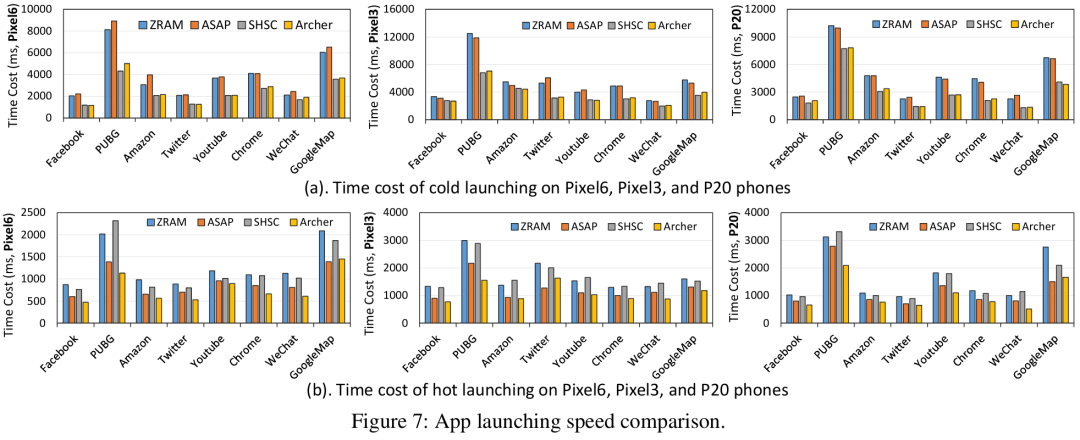
**①应用启动速度:**如图7所示,启用Archer后,相比ZRAM,Pixel6、Pixel3、P20上冷启动速度分别提升37.2%、32.9%、30.6%,热启动速度分别提升55.3%、47.5%和29.6%。
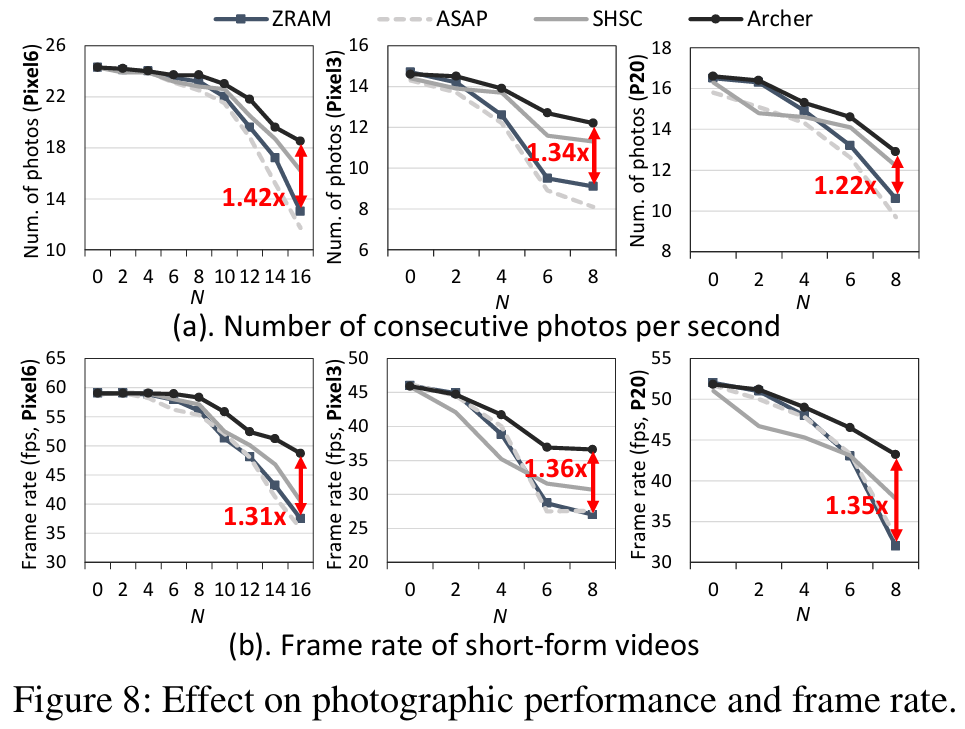
**②拍照性能与帧率:**如图8所示,启用Archer后,系统在内存压力下的性能得到大幅改善,Pixel6、Pixel3、P20拍照速度分别提升1.42、1.34、1.22倍,Pixel6、Pixel3、P20短短视频帧率分别提升1.31、1.36、1.39倍。
**③对尾延迟的影响:**如图9所示,尾部延迟(即每个用例十轮测试中最差情况)显著降低,如在Pixel6上,应用程序的冷启动尾延迟减少44.9%,热启动减少60.3%,连拍和帧渲染的最差性能分别提升1.6倍和1.3倍。
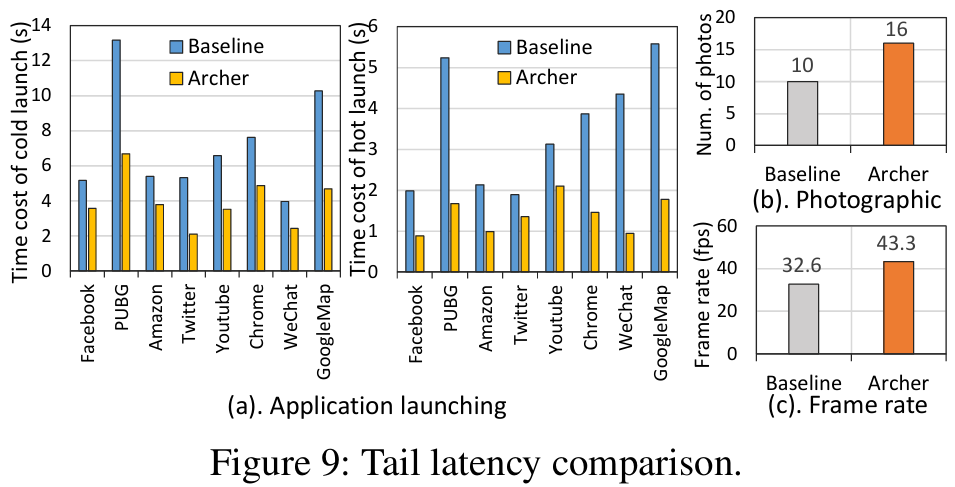
(2)性能收益分析:
离线分析了评估期间的页面数据,发现20%+的关联页面能在突发内存需求场景中发挥关键作用。
**①应用启动期间的页面压缩:**冷启动过程中,压缩页面80.5%是以大粒度压缩;在热启动中,大粒度压缩比例达到83.2%。经过进一步两小时的使用,仍有96.3%的关联页保持高度相关。
**②压缩吞吐量:**Archer的4KB粒度压缩吞吐量为205.1MB/s,接近ZRAM;对于≥512KB的大块压缩,吞吐量提升到522.6MB/s。此外评估了Transformer,Pixel6上启用Archer后延迟降低39.2%。
③敏感性研究 **:**Archer的性能受关联挖掘参数影响较大。图10显示了在Pixel6上不同队列和事务缓冲区大小下的评估结果。当结构大小适中时,帧率随尺寸增大而优化。但尺寸继续增大后,帧率反而下降。综合内存与计算开销,不建议设置过大尺寸。Archer的效果还受滑动窗口宽度(w)、超时阈值∆T、关联规则置信度等参数影响,建议针对各移动设备定制化配置Archer。
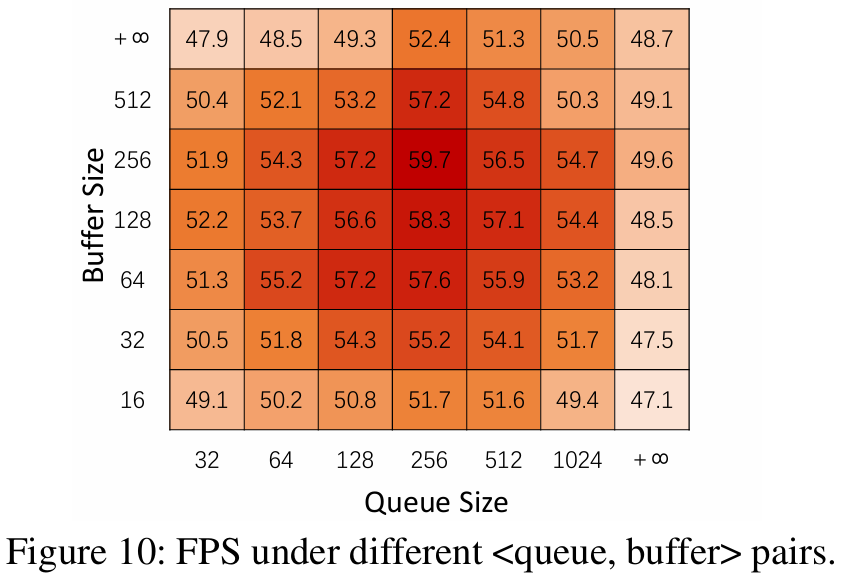
(3)潜在开销分析:
①读取放大:若后续w个足迹或一分钟内未访问其他预压缩页面,则视为读取放大。评估显示,92.6%被批量解压的页面很快被访问,实际测得的读取放大率不超过1.08。解压64页比单页多耗时17.6%,但整个过程仍在亚微秒级完成。更重要的是,预取页面的访问延迟显著降低。综合Archer的整体性能收益和高准确率,批量解压对性能影响很小。
②能耗:Archer对能耗的影响是多方面的。一方面,数据挖掘操作会增加能耗,所以使用节能的FP-Growth算法。另一方面高效的压缩减少了上下文切换和重试操作,从而节省能耗。以剩余电量百分比为指标,在两台Pixel 6手机上进行的1小时应用负载测试表明,启用Archer后,平均能耗仅增加0.69%。
③内存开销:Archer引入的内存开销主要来自映射表、项队列和缓冲区。Archer将所有批量压缩页面均记录为元数据,并且使用循环队列和环形缓冲区防止内存无限增长。内存开销整体处于百KB级别,相对于移动设备GB级的内存容量来说可接受。
04.总结
Archer提出了一种面向页面关联规则内存压缩框架,不仅仅依赖传统方案固定的页级压缩,而是通过灵活的压缩粒度,更有效地适应移动系统中突发内存需求。该框架由足迹流生成器(FSG)、频繁模式树列表(FT-List)和自适应压缩区域(ACR)协同工作,实现了对关联页面的识别、组织与大粒度压缩管理。Archer首次将关联规则挖掘技术引入内存压缩,展示了在移动系统中实施大粒度压缩的巨大潜力,启用Archer后,成功提升了应用平均启动速度以及拍照性能与帧率等用户体验指标