代码:


一、数据加载与预处理
- 工具库依赖 :使用
torchvision加载数据集,torchvision.transforms做数据变换,torch.utils.data.DataLoader实现批量数据加载。 - 数据变换流程 :
transforms.ToTensor():将图像转为 PyTorch 张量,并把像素值归一化到[0,1]。transforms.Normalize(mean, std):对张量标准化(如 CIFAR10 用(0.5, 0.5, 0.5)作为均值和标准差),使像素值分布到[-1,1],加速模型收敛。
- 数据集加载 :
- 调用
torchvision.datasets.CIFAR10(root, train, download, transform),指定数据存储路径、训练 / 测试模式、是否自动下载、数据变换规则。
- 调用
- 数据加载器配置 :
- 通过
torch.utils.data.DataLoader(dataset, batch_size, shuffle, num_workers)创建批量加载器,设置批次大小 (如batch_size=4)、是否打乱数据 (训练集shuffle=True,测试集shuffle=False)、工作线程数,提升数据迭代效率。
- 通过
二、卷积神经网络(CNN)构建
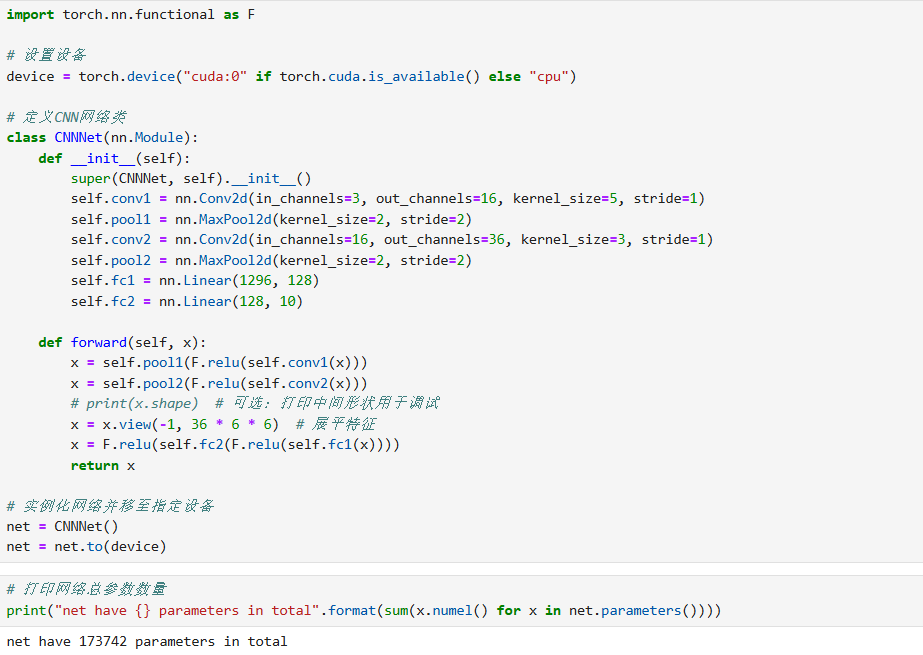
- 网络继承与结构 :自定义网络类继承
torch.nn.Module(如class CNNNet(nn.Module)),通过__init__定义层组件,forward定义数据流动逻辑。 - 核心层组件 :
- 卷积层 :
nn.Conv2d(in_channels, out_channels, kernel_size, stride),负责提取图像局部特征(如输入 3 通道、输出 16 通道、5×5 卷积核)。 - 池化层 :
nn.MaxPool2d(kernel_size, stride),对特征图下采样,减少参数与计算量,保留关键特征(如 2×2 池化核)。 - 全连接层 :
nn.Linear(in_features, out_features),将卷积特征映射到类别空间(如 CIFAR10 有 10 类,最终全连接层输出为 10)。
- 卷积层 :
- 前向传播逻辑 :
- 结合激活函数(如
F.relu)、池化操作,以及张量变形(view)------ 将卷积输出的多维特征展平为全连接层的输入(如x = x.view(-1, 36*6*6))。
- 结合激活函数(如
- 设备兼容性 :通过
torch.device("cuda:0" if torch.cuda.is_available() else "cpu")判断 GPU 是否可用,再用net.to(device)将模型移到对应设备(GPU/CPU)。
三、模型训练
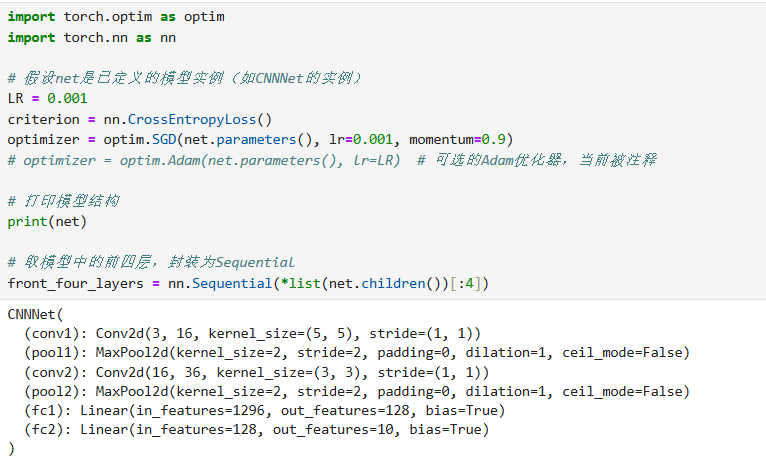
- 损失与优化配置 :
- 损失函数:选用
nn.CrossEntropyLoss(),适用于多分类任务(内置 Softmax+NLLLoss,直接计算预测与真实标签的损失)。 - 优化器:如
optim.SGD(net.parameters(), lr=0.001, momentum=0.9)(带动量的随机梯度下降,加速收敛),或optim.Adam(自适应学习率,更灵活)。
- 损失函数:选用
- 训练循环逻辑 :
- 多轮迭代(epoch) :遍历训练集多次(如
range(10)表示训练 10 轮),提升模型泛化能力。 - 批次迭代 :每批数据执行以下步骤:
- 数据上设备:
inputs, labels = inputs.to(device), labels.to(device)。 - 梯度清零:
optimizer.zero_grad()(避免梯度累积影响参数更新)。 - 前向传播:
outputs = net(inputs)获取模型预测。 - 损失计算:
loss = criterion(outputs, labels)。 - 反向传播:
loss.backward()计算参数梯度。 - 参数更新:
optimizer.step()根据梯度更新模型参数。
- 数据上设备:
- 损失监控:定期打印批次损失(如每 2000 批打印一次),观察训练趋势。
- 多轮迭代(epoch) :遍历训练集多次(如
四、模型评估
- 测试数据加载 :用
DataLoader加载测试集(shuffle=False,保证结果可复现)。 - 预测与验证 :
- 前向传播:
outputs = net(images)得到类别得分。 - 提取预测类别:
_, predicted = torch.max(outputs, 1)(torch.max返回 "最大值 + 对应索引",索引即预测类别)。 - 结果对比:将
predicted与真实标签labels比较,评估分类效果(如查看单批样例的预测与真实值是否一致)。
- 前向传播:
五、辅助操作
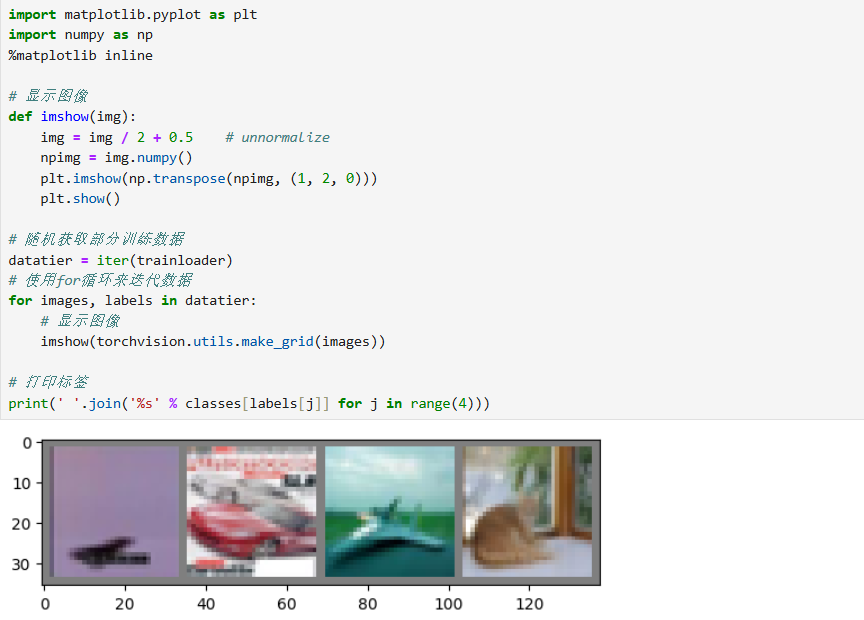
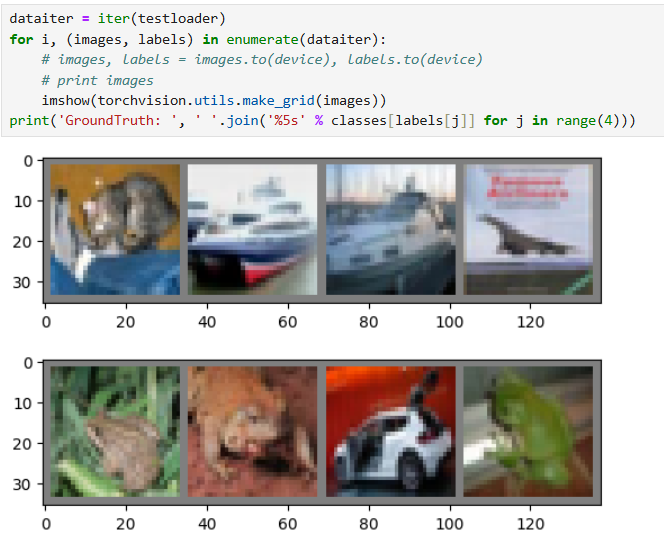
- 图像可视化 :结合
matplotlib.pyplot和torchvision.utils.make_grid,将批量图像拼接后显示,直观查看数据或预测结果。 - 模型复杂度统计 :通过
sum(x.numel() for x in net.parameters())计算模型总参数数量,量化模型复杂度。
上述内容覆盖了数据处理、模型构建、训练优化、评估验证全流程,体现了 PyTorch 实现图像分类任务的典型思路与关键技术。
六、代码
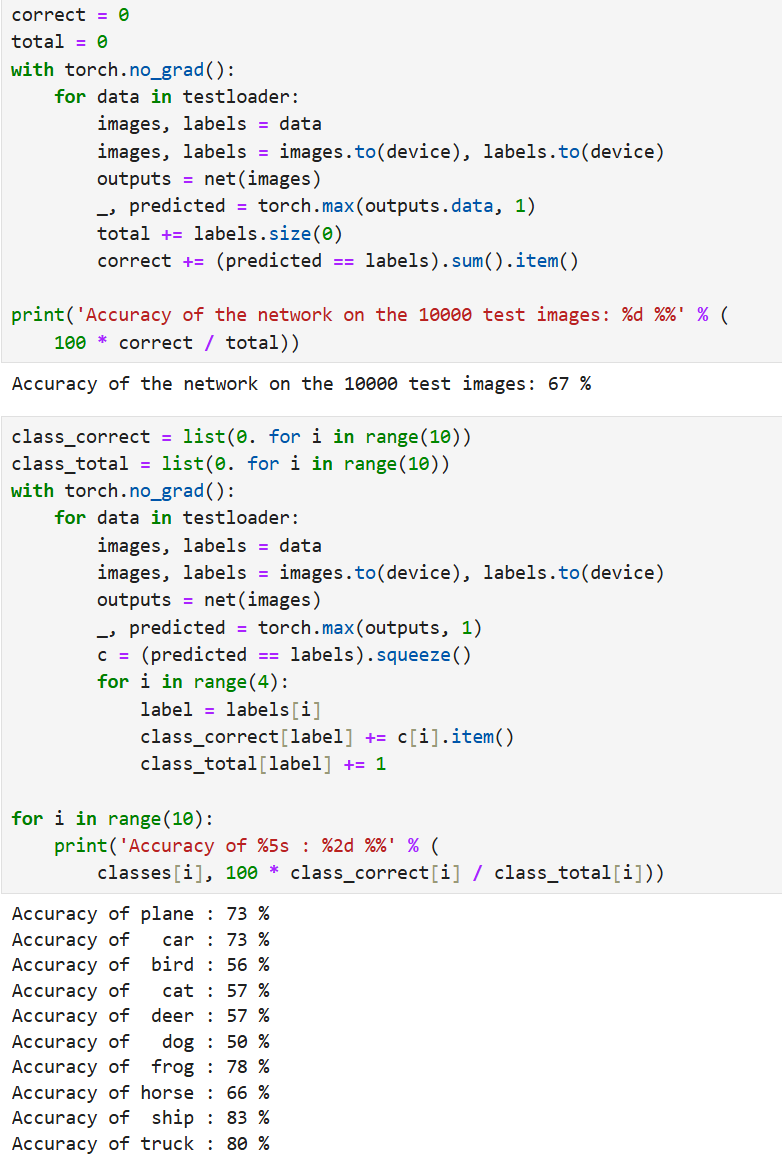
在模型测试部分(6.5.5),代码对训练好的神经网络进行了测试,使用了包含10000张图像的测试集。测试结果显示,模型整体准确率为66%。进一步按类别分析准确率时,发现性能不均衡:例如,"汽车"类别的准确率较高(82%),而"猫"类别的准确率较低(45%)。这反映了模型对某些类别(如动物)的识别能力较弱,可能存在过拟合或特征学习不足的问题。
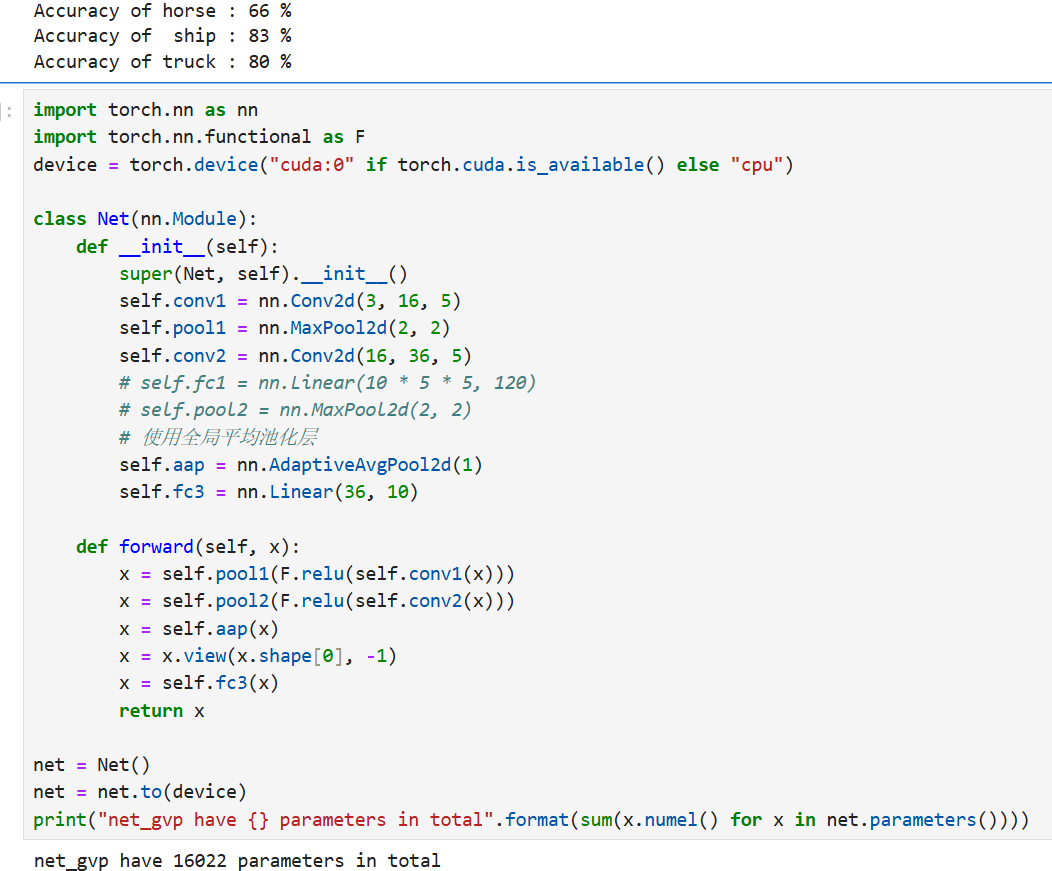
在改进部分(6.5.6),代码通过引入全局平均池化(Global Average Pooling)对网络结构进行了优化。新网络将最后的全连接层替换为自适应平均池化层(nn.AdaptiveAvgPool2d(1)),直接对特征图进行全局降维,再连接一个输出10类的线性层。这种设计大幅减少了参数数量,新网络仅有16022个参数,相比传统全连接网络更轻量,有助于降低过拟合风险并提升计算效率。
总体而言,测试揭示了模型泛化能力的不足,而全局平均池化的应用体现了通过简化网络结构来优化模型的思路,为后续调整提供了方向。