随着智能监控和健康管理的普及,抽烟识别成为一个典型的计算机视觉场景。本文将介绍如何在前端实现抽烟识别,不依赖后端,实现实时图像检测与可视化展示。
1. 背景与问题定义
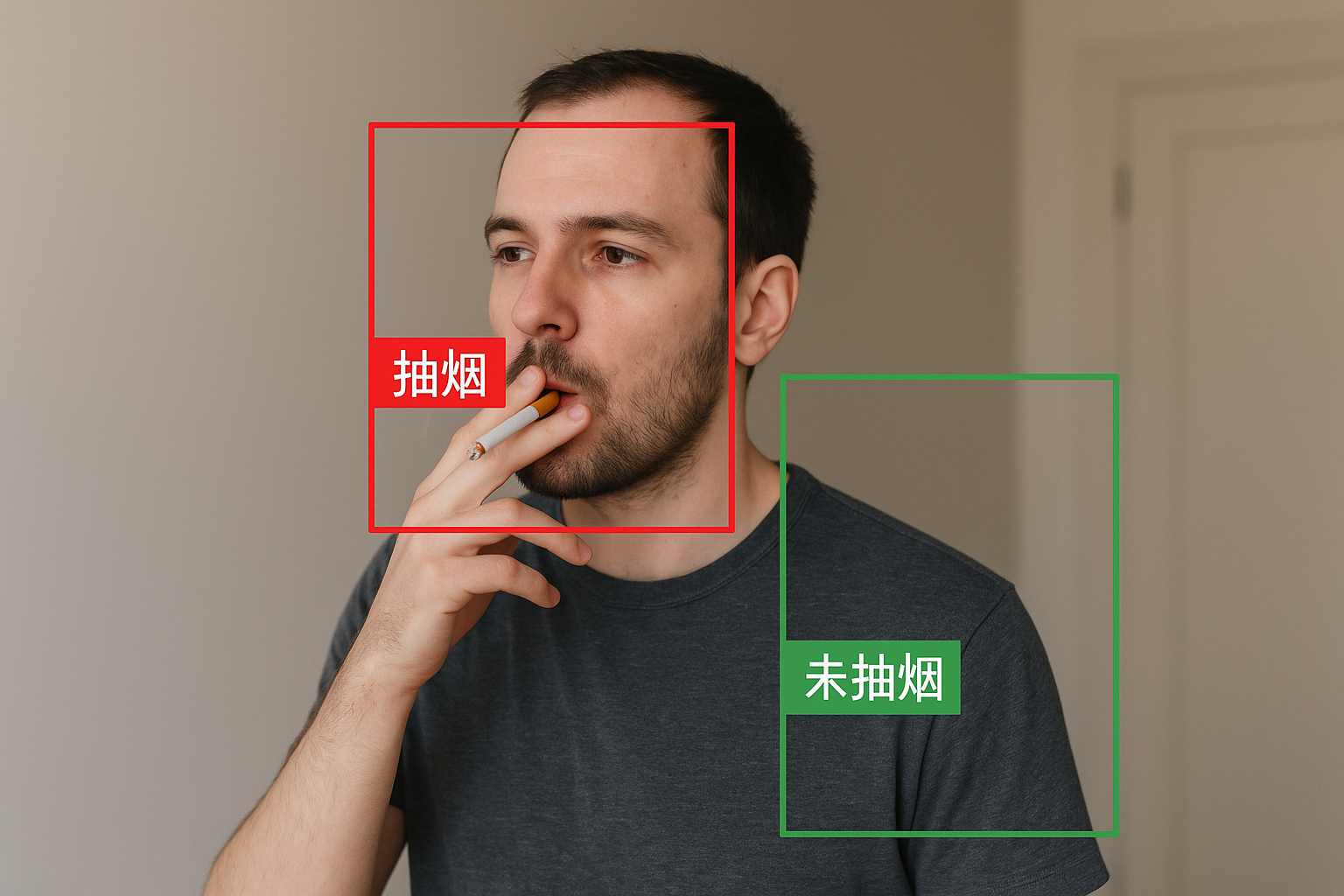
什么是抽烟识别?
抽烟识别是指通过图像或视频判断画面中是否有人在吸烟。常见应用场景包括:
-
智慧办公场景监控
-
公共场所安全管理
-
健康管理与戒烟监测
问题拆解:
-
输入:摄像头拍摄的图像或视频帧
-
输出:是否有人在抽烟(True/False)
-
可扩展:烟雾检测、吸烟动作检测、多人物体识别
2. 前端可行方案
作为前端开发者,我们可以选择以下方案:
-
TensorFlow.js / ONNX.js
-
可以直接在浏览器加载模型进行推理
-
优点:无需后端即可部署,实时处理
-
-
WebRTC + 前端摄像头采集
- 获取实时视频流,输入模型进行识别
-
Canvas 可视化
- 对检测区域进行标注,显示识别结果
-
与后端模型接口结合
- 对于大型模型或高精度识别,可以将图片发送到后端 API 进行识别
3. 算法思路
抽烟识别主要涉及目标检测 + 图像分类:
-
训练模型
-
数据集:包含抽烟和不抽烟的图片
-
模型选择:
-
图像分类:MobileNet、ResNet(前端可用 MobileNet 轻量化模型)
-
目标检测:YOLO、SSD(检测手、烟或烟雾)
-
-
导出模型:TensorFlow.js 模型或 ONNX 模型
-
-
前端调用
-
加载模型并将摄像头画面转换为 Tensor
-
输出概率进行判断
-
示例:
javascript
const prediction = await model.predict(tensor);
if(prediction[0] > 0.5) {
console.log('检测到抽烟');
} else {
console.log('未检测到抽烟');
}4. 前端实现示例
下面给出一个前端端到端实现示例,使用 TensorFlow.js 和 摄像头实时画面:
javascript
<video id="video" autoplay playsinline width="400"></video>
<canvas id="canvas" width="400" height="300"></canvas>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script>
async function init() {
// 加载预训练模型
const model = await tf.loadGraphModel('model/model.json');
const video = document.getElementById('video');
const canvas = document.getElementById('canvas');
const ctx = canvas.getContext('2d');
// 获取摄像头
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
video.srcObject = stream;
video.onloadeddata = () => detectFrame();
async function detectFrame() {
// 将摄像头画面转换为模型输入
const tensor = tf.browser.fromPixels(video)
.resizeNearestNeighbor([224, 224])
.expandDims(0)
.toFloat()
.div(255);
const prediction = await model.predict(tensor).data();
// 清空画布
ctx.clearRect(0, 0, canvas.width, canvas.height);
// 在画布上显示识别结果
ctx.font = "20px Arial";
ctx.fillStyle = prediction[0] > 0.5 ? "red" : "green";
ctx.fillText(prediction[0] > 0.5 ? "抽烟" : "未抽烟", 10, 30);
requestAnimationFrame(detectFrame);
}
}
init();
</script>效果说明:
-
摄像头画面实时检测
-
Canvas 显示识别结果
-
可进一步在画面上标注抽烟人物或烟雾区域
5. 可视化与优化
-
多帧检测取平均:减少误报
-
标记检测区域:可在 Canvas 上画框
-
轻量化模型:保证浏览器端实时识别
-
多人物检测:目标检测模型可同时识别多个人
6. 总结
-
前端完全可以做轻量化抽烟识别
-
高精度或复杂场景建议结合后端
-
可拓展到烟雾检测、多人环境、吸烟动作识别等场景
-
前端结合 TensorFlow.js、WebRTC、Canvas 可以实现完整端到端应用