
如图所示,主节点重启后出现了这样的错误
1、重启主节点的所有服务
kubeadm安装
sudo systemctl restart kubelet
sudo systemctl status kubelet
是 active (running),就说明没问题。
kubectl get pods -n kube-system
看到 apiserver、scheduler、controller-manager、etcd等 Pod 都处于 Running状态。之后,你的主节点 kubectl get nodes等命令就应该可以正常工作了。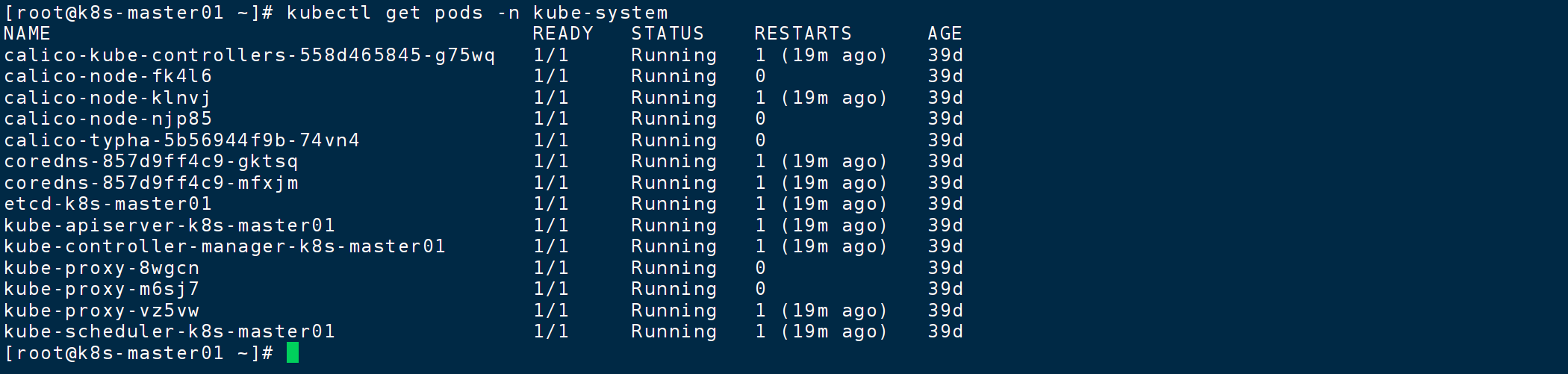
2、原因
我是配置文件出问题了
3、处理
查看主节点文件
ls /etc/kubernetes/admin.conf
将这个文件分发给从节点
scp /etc/kubernetes/admin.conf root@192.168.125.103:~/
从节点 操作
ls -la ~/.kube/
mv ~/admin.conf ~/.kube/config
chmod 600 ~/.kube/config出现下面就OK了
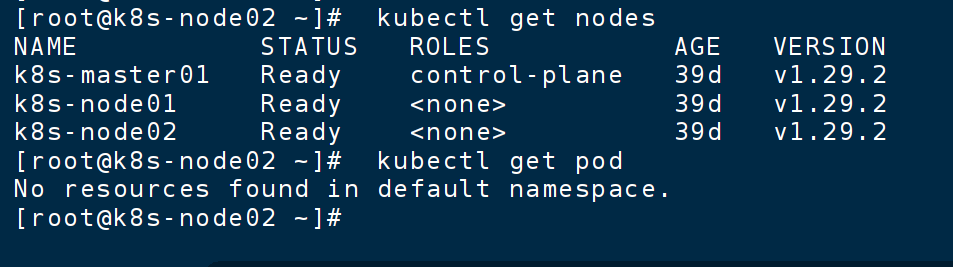
第1步:在 Kubernetes 主节点(Master)上操作
登录到你的 Kubernetes 主节点服务器。
找到集群的配置文件 。集群初始化后,默认的配置文件位于
/etc/kubernetes/admin.conf。这个文件包含了访问集群所需的所有信息(API Server地址、证书、密钥)。
bash
复制
ls /etc/kubernetes/admin.conf你应该能看到这个文件。
使用
scp命令将配置文件安全复制到k8s-node01节点。
你需要知道
k8s-node01节点的 IP 地址。执行以下命令,将
<k8s-node01-ip>替换为你节点的实际IP地址(例如192.168.1.101)。
bash
复制
scp /etc/kubernetes/admin.conf root@<k8s-node01-ip>:~/
命令解释 :
scp(secure copy) 会将主节点上的/etc/kubernetes/admin.conf文件复制到k8s-node01节点的 root 用户的家目录 (~/) 下。系统可能会提示你输入
k8s-node01节点的 root 密码。第2步:回到
k8s-node01节点上操作现在,配置文件已经复制到了
k8s-node01节点的~/(即/root/)目录下,我们需要把它放到正确的位置并设置正确的权限。
创建
.kube目录。首先,需要创建
kubectl默认会去寻找配置文件的目录。
bash
复制
mkdir -p ~/.kube将复制过来的配置文件移动到正确位置并重命名。
kubectl默认使用的配置文件是~/.kube/config。
bash
复制
mv ~/admin.conf ~/.kube/config设置严格的文件权限(非常重要!)。
该配置文件中包含敏感的认证密钥,必须限制为只有所有者可读。
bash
复制
chmod 600 ~/.kube/config第3步:验证配置
现在,所有配置已经完成。让我们来测试一下。
在
k8s-node01节点上执行:
bash
复制
kubectl get nodes如果一切顺利,你现在应该能看到集群中所有节点的状态列表(包括 master 和 node01),而不是之前那个可怕的
connection refused错误。