17 Web 应用防火墙:怎样拦截恶意用户的非法请求?
Web应用防火墙(Web Application Firewall, WAF)通过对HTTP(S)请求进行检测,识别并阻断SQL注入、跨站脚本攻击、跨站请求伪造等攻击,保护Web服务安全稳定。
Web安全是所有互联网应用必须具备的功能,没有安全防护的应用犹如怀揣珠宝的儿童独自行走在盗贼环伺的黑夜里。我们准备开发一个Web应用防火墙,该防火墙可作为Web插件,部署在Web应用或者微服务网关等HTTP服务的入口,拦截恶意请求,保护系统安全。我们准备开发的Web应用防火墙名称为"Zhurong(祝融)"。
需求分析
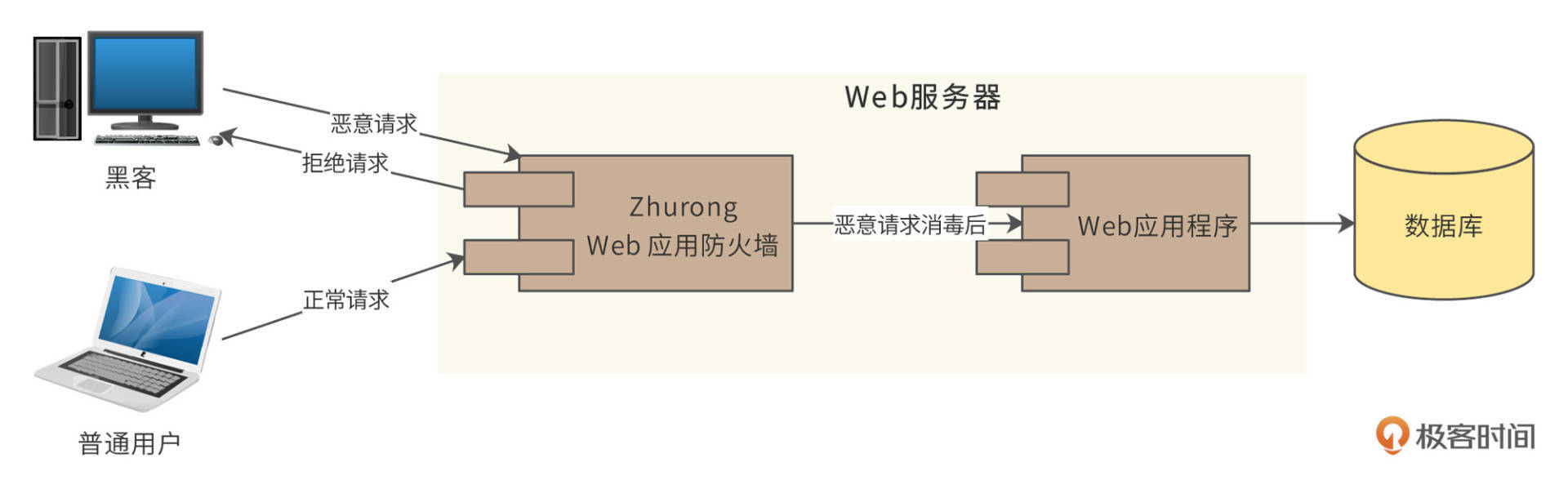
HTTP请求发送到Web服务器时,请求首先到达Zhurong防火墙,防火墙判断请求中是否包含恶意攻击信息。如果包含,防火墙根据配置策略,可选择拒绝请求,返回418状态码;也可以将请求中的恶意数据进行消毒处理,也就是对恶意数据进行替换,或者插入某些字符,从而使请求数据不再具有攻击性,然后再调用应用程序处理。如下图:
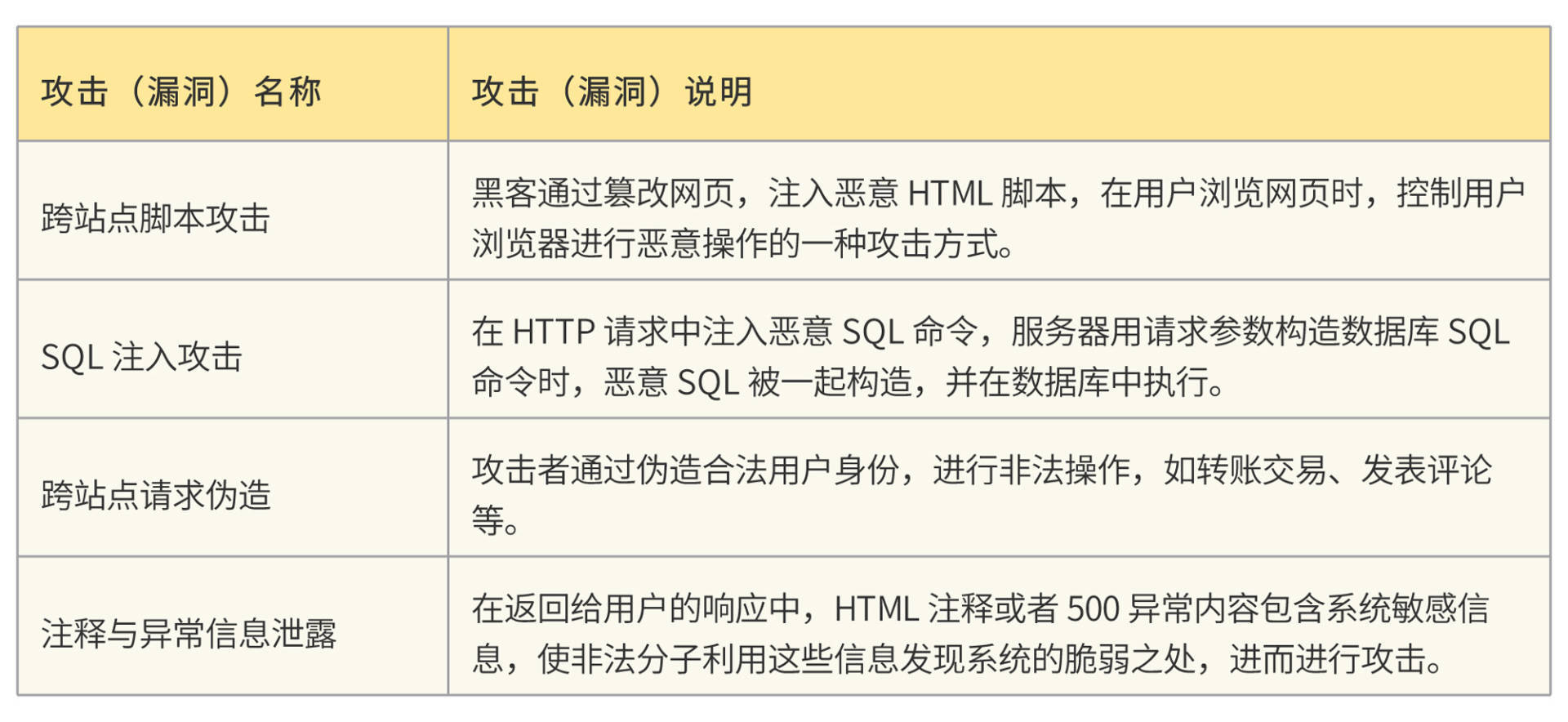
Zhurong需要处理的攻击和安全漏洞列表:
概要设计
Zhurong能够发现恶意攻击请求的主要手段,是对HTTP请求内容进行正则表达式匹配,将各种攻击类型可能包含的恶意内容构造成正则表达式,然后对HTTP请求头和请求体进行匹配。如果匹配成功,那么就触发相关的处理逻辑,直接拒绝请求;或者将请求中的恶意内容进行消毒,即进行字符替换,使攻击无法生效。
其中,恶意内容正则表达式是通过远程配置来获取的。如果发现了新的攻击漏洞,远程配置的漏洞攻击正则表达式就会进行更新,并在所有运行了Zhurong防火墙的服务器上生效,拦截新的攻击。组件图如下:
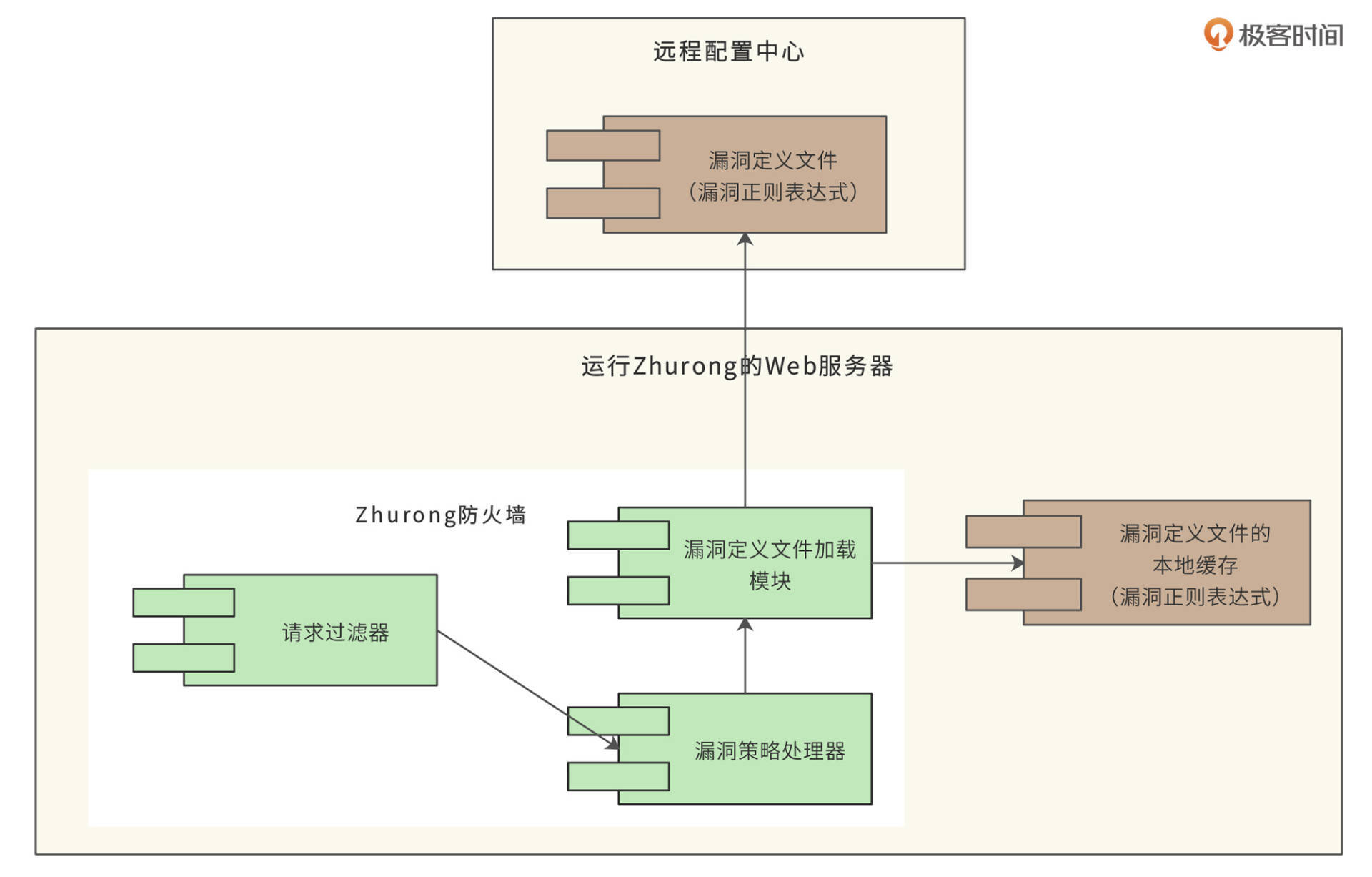
HTTP请求先到达请求过滤器,请求过滤器提取HTTP请求头和HTTP请求体中的数据,这个过滤器其实就是Java中的Filter。过滤器调用漏洞策略处理器进行处理,而漏洞策略处理器需要调用漏洞定义文件加载模块获得漏洞定义规则,漏洞定义文件加载模块缓存了各种漏洞定义规则文件,如果缓存超时,就从远程配置中心重新加载漏洞定义规则。
漏洞定义规则文件是Zhurong的核心,该文件定义了攻击的正则表达式,过滤器正是通过使用这些正则表达式匹配HTTP请求头和HTTP请求体的方式,识别出HTTP请求中是否存在攻击内容。同时,漏洞定义规则文件中还定义了发现攻击内容后的处理方式:是拒绝请求,跳转到出错页面,还是采用消毒的方式,将攻击内容字符进行替换。
漏洞规则定义文件采用XML格式,示例如下:
xml
<?xml version="1.0"?>
<recipe
attacktype="Sql"
path="^/protectfolder/.*$"
description="Sql injection attacks">
<ruleSet
stage = "request"
condition = "or">
<action
name="forward"
arg="error.html"/>
<rule
operator = "regex"
arg = "paramNames[*]"
value = "select|update|delete|count|*|sum|master|script|'|declare|
or|execute|alter|statement|executeQuery|count|executeUpdate" />
</ruleSet>
<ruleSet
stage = "response"
condition = "or">
<action
name ="replace"
arg = " " />
<rule
operator = "regex"
arg = " responseBody "
value = "(//.+\n)|(/**.+*/)|(<!--.*-->)"/>
</ruleSet>
</recipe>recipe是漏洞定义文件的根标签,属性attacktype表示处理的攻击类型,有以下几种。
- SQL: SQL注入攻击
- XSS: 跨站点脚本攻击
- CSC: 注释与异常信息泄露
- CSRF: 跨站点请求伪造
- FB: 路径遍历与强制浏览- path表示要处理的请求路径,可以为空,表示处理所有请求路径。
ruleSet是漏洞处理规则集合,一个漏洞文件可以包含多个ruleSet。stage标签表示处理的阶段,请求阶段:request,响应阶段:response。condition表示和其他规则的逻辑关系,"or"表示"或"关系,即该规则处理完成后,其他规则不需要再处理;"and"表示"与"关系,该规则处理完成后,其他规则还需要再处理。
action表示发现攻击后的处理动作。"forward"表示表示跳转到出错页面,后面的"arg"表示要跳转的路径;"replace"表示对攻击内容进行替换,即所谓的消毒,使其不再具有攻击性,后面的"arg"表示要替换的内容。
rule表示漏洞规则,触发漏洞规则,就会引起action处理动作。operator表示如何匹配内容中的攻击内容,"regex"表示正则表达式匹配,"urlmatch"表示URL路径匹配。"arg"表示要匹配的目标,可以是HTTP请求参数名、请求参数值、请求头、响应体、ULR路径。"value"就是匹配攻击内容的正则表达式。
详细设计
Zhurong可以处理的攻击类型有哪些?它们的原理是什么?Zhurong对应的处理方法又是什么?详细设计将解决这些问题。
XSS跨站点脚本攻击
XSS 攻击即跨站点脚本攻击(Cross Site Script),指黑客通过篡改网页,注入恶意 JavaScript脚本,在用户浏览网页时,控制用户浏览器进行恶意操作的一种攻击方式。
常见的 XSS 攻击类型有两种,一种是反射型,攻击者诱使用户点击一个嵌入恶意脚本的链接,达到攻击的目的。如图:
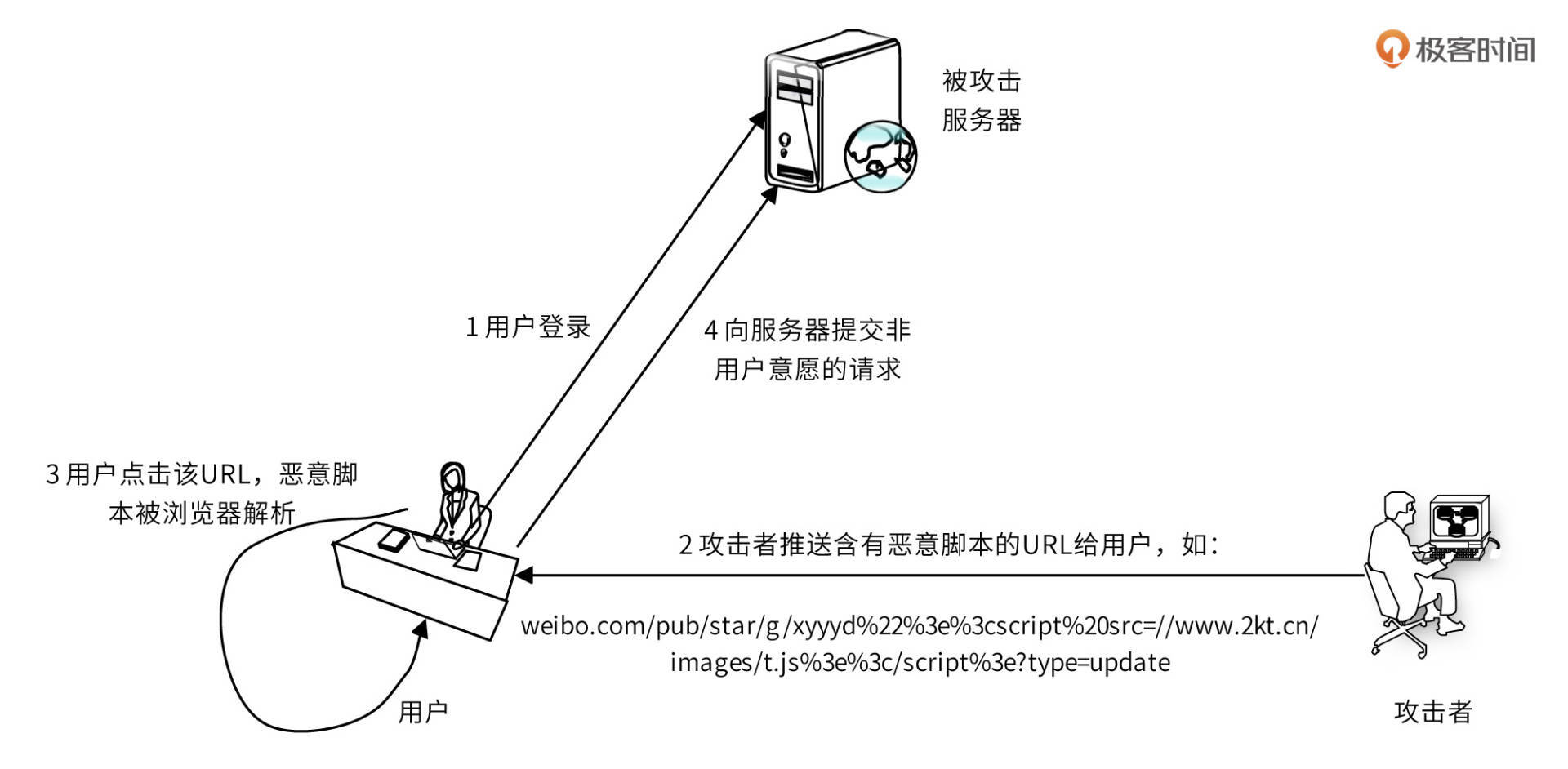
攻击者发布的微博中有一个含有恶意脚本的 URL(在实际应用中,该脚本在攻击者自己的服务器 www.2kt.cn上,URL 中包含脚本的链接),用户点击该 URL,会自动关注攻击者的新浪微博 ID,发布含有恶意脚本 URL 的微博,攻击就被扩散了。
另外一种 XSS 攻击是持久型 XSS 攻击,黑客提交含有恶意脚本的请求,保存在被攻击的 Web 站点的数据库中,用户浏览网页时,恶意脚本被包含在正常页面中,达到攻击的目的。如图:
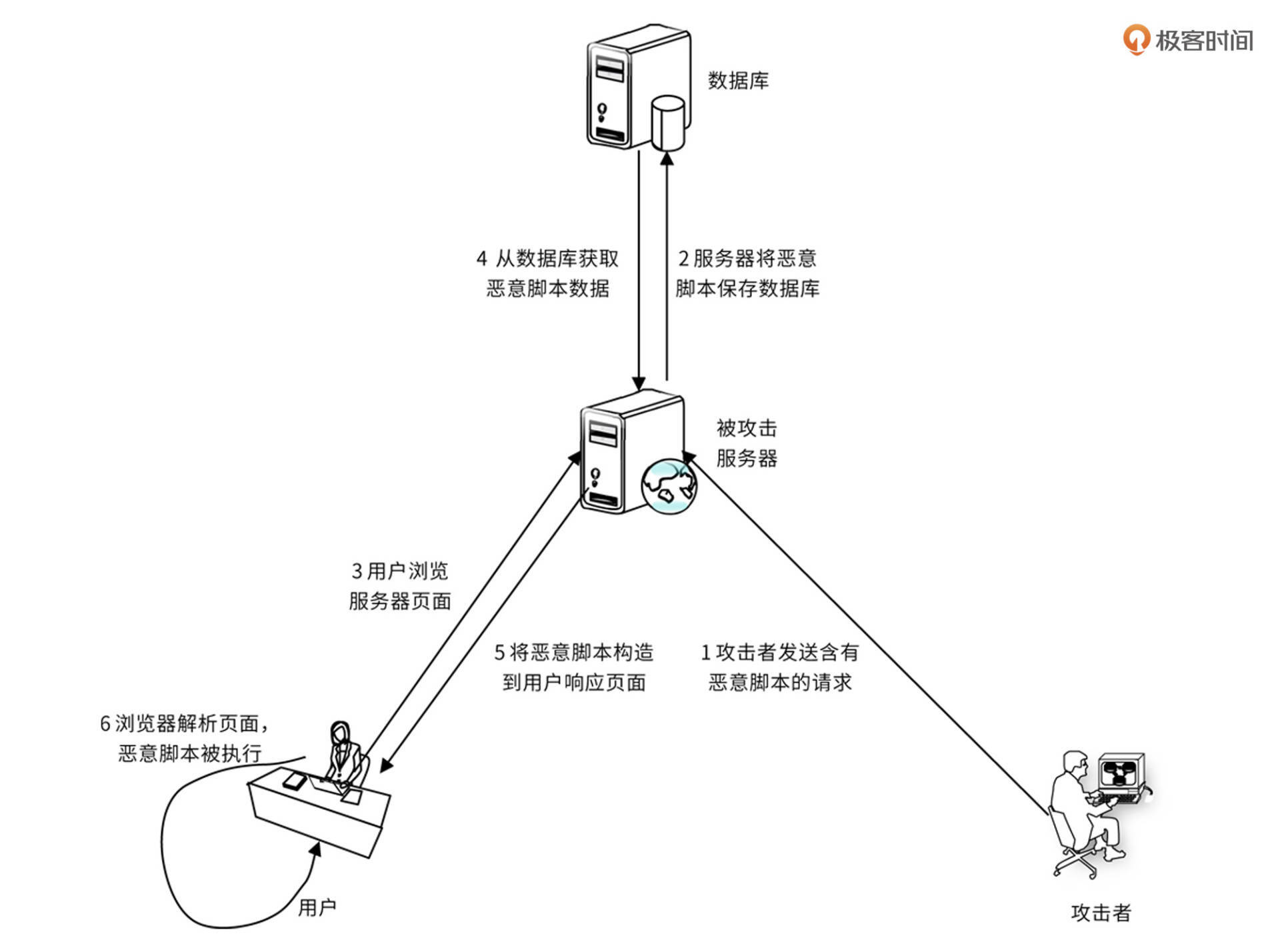
此种攻击经常使用在论坛、博客等 Web 应用中。
Zhurong采用正则表达式匹配含有XSS攻击内容的请求,正则表达式如下:
"(?:\b(?:on(?:(?:mo(?:use(?:o(?:ver|ut)|down|move|up)|ve)|key(?:press|down|up)|c(?:hange|lick)|s(?:elec|ubmi)t|(?:un)?load|dragdrop|resize|focus|blur)\b\W*?=|abort\b)|(?:l(?:owsrc\b\W*?\b(?:(?:java|vb)script|shell)|ivescript)|(?:href|url)\b\W*?\b(?:(?:java|vb)script|shell)|background-image|mocha):|type\b\W*?\b(?:text\b(?:\W*?\b(?:j(?:ava)?|ecma)script\b|[vbscript])|application\b\W*?\bx-(?:java|vb)script\b)|s(?:(?:tyle\b\W*=.*\bexpression\b\W*|ettimeout\b\W*?)\(|rc\b\W*?\b(?:(?:java|vb)script|shell|http):)|(?:c(?:opyparentfolder|reatetextrange)|get(?:special|parent)folder)\b|a(?:ctivexobject\b|lert\b\W*?\())|<(?:(?:body\b.*?\b(?:backgroun|onloa)d|input\b.*?\\btype\b\W*?\bimage)\b|
在XSS攻击字符前后加上" "字符串,使得攻击脚本无法运行,同时在浏览器显示的时候不会影响显示内容。
SQL注入攻击
SQL 注入攻击的原理如下:

攻击者在 HTTP 请求中注入恶意 SQL 命令(drop table users;),服务器用请求参数构造数据库 SQL 命令时,恶意 SQL 被一起构造,并在数据库中执行。
如果在Web页面中有个输入框,要求用户输入姓名,普通用户输入一个普通的姓名Frank,那么最后提交的HTTP请求如下:
http://www.a.com?username=Frank服务器在处理计算后,向数据库提交的SQL查询命令如下:
Select id from users where username='Frank';但是恶意攻击者可能会提交这样的HTTP请求:
http://www.a.com?username=Frank';drop table users;--即输入的uername是:
Frank';drop table users;--这样,服务器在处理后,最后生成的SQL是这样的:
sql
Select id from users where username='Frank';drop table users;--';事实上,这是两条SQL,一条select查询SQL,一条drop table删除表SQL。数据库在执行完查询后,就将users表删除了,系统崩溃了。
处理SQL注入攻击的rule正则表达式如下。
(?:\b(?:(?:s(?:elect\b(?:.{1,100}?\b(?:(?:length|count|top)\b.{1,100}?\bfrom|from\b.{1,100}?\bwhere)|.*?\b(?:d(?:ump\b.*\bfrom|ata_type)|(?:to_(?:numbe|cha)|inst)r))|p_(?:(?:addextendedpro|sqlexe)c|(?:oacreat|prepar)e|execute(?:sql)?|makewebtask)|ql_(?:longvarchar|variant))|xp_(?:reg(?:re(?:movemultistring|ad)|delete(?:value|key)|enum(?:value|key)s|addmultistring|write)|e(?:xecresultset|numdsn)|(?:terminat|dirtre)e|availablemedia|loginconfig|cmdshell|filelist|makecab|ntsec)|u(?:nion\b.{1,100}?\bselect|tl_(?:file|http))|group\b.*\bby\b.{1,100}?\bhaving|load\b\W*?\bdata\b.*\binfile|(?:n?varcha|tbcreato)r|autonomous_transaction|open(?:rowset|query)|dbms_java)\b|i(?:n(?:to\b\W*?\b(?:dump|out)file|sert\b\W*?\binto|ner\b\W*?\bjoin)\b|(?:f(?:\b\W*?\(\W*?\bbenchmark|null\b)|snull\b)\W*?\()|(?:having|or|and)\b\s+?(?:\d{1,10}|'[^=]{1,10}')\s*?[=<>]+|(?:print]\b\W*?\@|root)\@|c(?:ast\b\W*?\(|oalesce\b))|(?:;\W*?\b(?:shutdown|drop)|\@\@version)\b|'(?:s(?:qloledb|a)|msdasql|dbo)')从请求中匹配到SQL注入攻击内容后,可以设置跳转错误页面,也可以选择消毒replace,replace表如下:
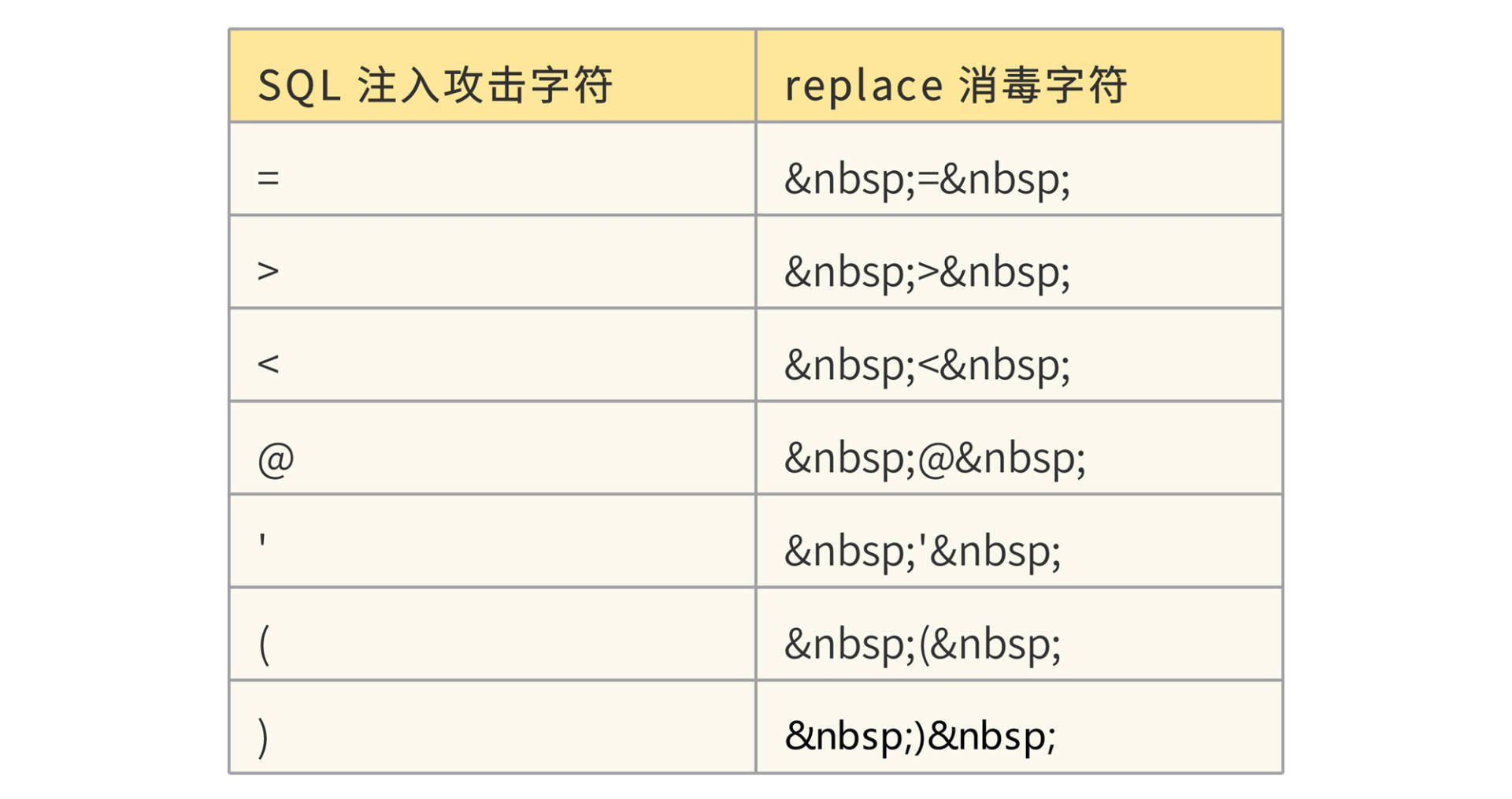
CSRF跨站点请求伪造攻击
CSRF(Cross Site Request Forgery,跨站点请求伪造),攻击者通过跨站请求,以合法用户的身份进行非法操作,如转账交易、发表评论等,如图:
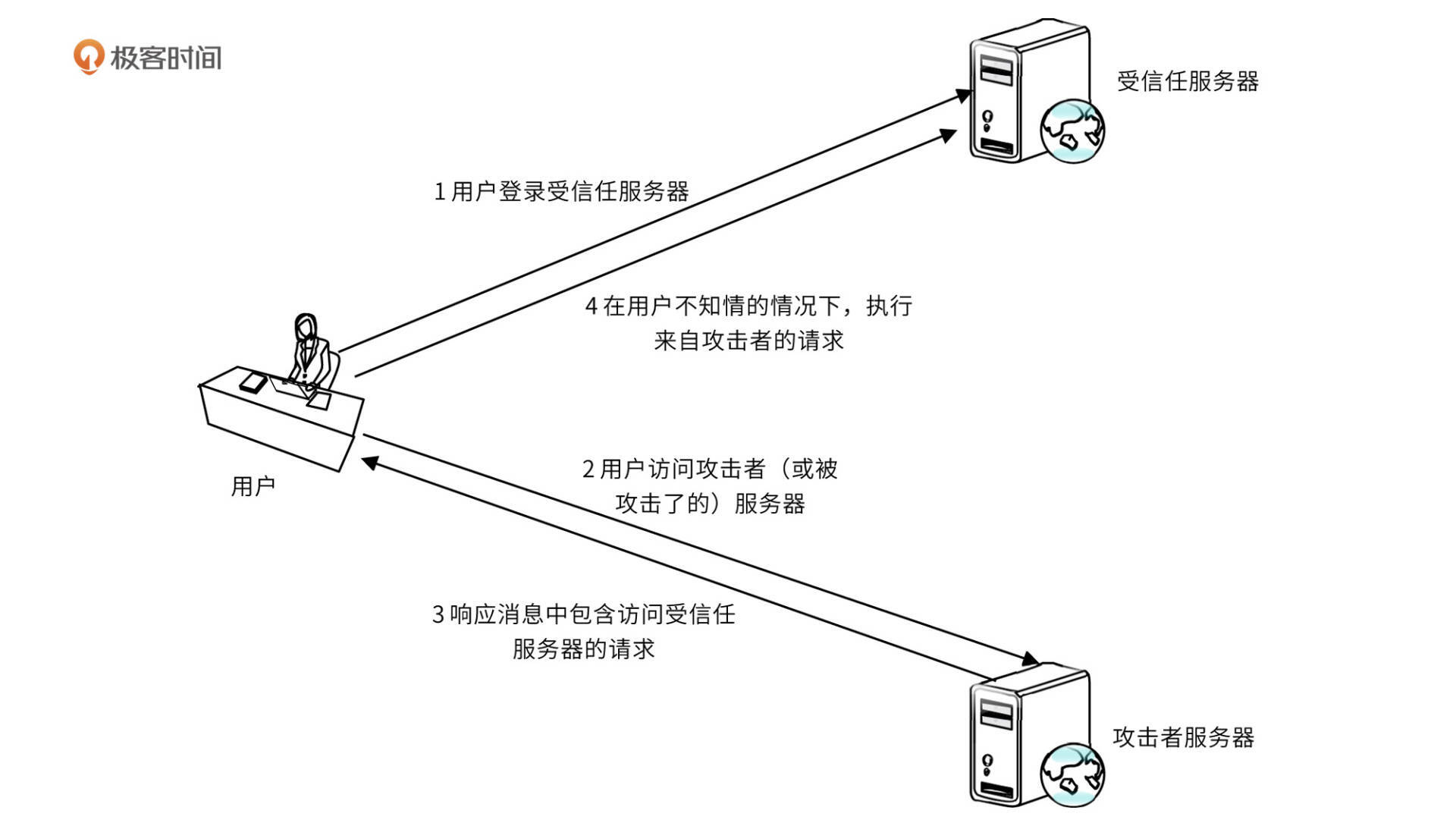
CSRF 的主要手法是利用跨站请求,在用户不知情的情况下,以用户的身份伪造请求。其核心是利用了浏览器 Cookie 或服务器 Session 策略,盗取用户身份。
Zhurong的防攻击策略,是过滤器自动在所有响应页面的表单form中添加一个隐藏字段,合法用户在提交请求的时候,会将这个隐藏字段发送到服务器,防火墙检查隐藏字段值是否正确,来确定是否为CSRF攻击。恶意用户的请求是自己伪造的,无法构造这个隐藏字段,就会被防火墙拦截。
注释与异常信息泄露
为调试程序方便或其他不恰当的原因,有时程序开发人员会在前端页面程序中使用 HTML 注释语法进行程序注释,这些 HTML 注释就会显示在客户端浏览器,给黑客造成攻击便利。
此外,许多 Web 服务器默认是打开异常信息输出的,即服务器端未处理的异常堆栈信息会直接输出到客户端浏览器,这种方式虽然对程序调试和错误报告有好处,但同时也给黑客造成可乘之机。黑客通过故意制造非法输入,使系统运行时出错,获得异常信息,从而寻找系统漏洞进行攻击。
匹配HTML注释的正则表达式如下:
"<!--(.|
|
)*-->"如果匹配到HTML注释,就用空字符串replace该注释。
对于异常信息泄露,Zhurong会检查响应状态码。如果响应状态码为500系列错误,则会进一步匹配响应体内容,检查是否存在错误堆栈信息。
小结
这篇设计文档也是改编自某全球IT企业的内部设计文档,这个产品和该企业的Web服务器捆绑销售,已经在全球范围内售卖了十几年。这个产品也是中国分公司成立之初最成功的产品,帮助中国分公司奠定了自己在总公司的地位。而这个产品的最初版本,则是一个架构师带领一个开发小组花了几个月的时间就开发出来的。
人们常说软件工程师的职业生涯只有十几年,甚至只有几年。事实上,很多商业软件的生命周期都不止十几年,也就是说,在你的职业生涯中,只要开发出一款成功的软件,光是为这个软件修修补补、维护升级,你也能干个十几年,几十年。
但是很遗憾,就我所见,大多数软件工程师在自己的职业生涯中都没有经历过成功。要么就是加入一个已经成功的项目修修补补,要么就是在一个不温不火的项目里耗了几年,最后无疾而终。事实上,经历过成功的人会明白什么样的项目将会走向成功,所以不会守着一个成功的项目养老,而是不断追求新的成功;而没有经历过成功的人则在曲曲折折中走向自己的中年危机。
我们这个专栏挑选的设计,都是基于一些已经成功了的案例。成功的东西有一种成功的味道,正是这种味道带领成功者走向成功。希望你在学习技术的同时,也能嗅到成功的味道。
思考题
还有哪些常见的Web安全漏洞,如何进行防护?
18 加解密服务平台:如何让敏感数据存储与传输更安全?
在一个应用系统运行过程中,需要记录、传输很多数据,这些数据有的是非常敏感的,比如用户姓名、手机号码、密码、甚至信用卡号等等。这些数据如果直接存储在数据库,记录在日志中,或者在公网上传输的话,一旦发生数据泄露,不但可能会产生重大的经济损失,还可能会使公司陷入重大的公关与法律危机。公司上下辛苦十几年,一夜回到解放前。
所以,敏感信息必须进行加密处理,也就是把敏感数据以密文的形式存储、传输。这样即使被黑客攻击,发生数据泄露,被窃取的数据也是密文,获取数据的人无法得到真实的明文内容,敏感数据依然被保护着。而当应用程序需要访问这些密文的时候,只需要进行数据解密,即可还原得到原始明文数据。加解密处理既保证了数据的安全,又保证了数据的正常访问。
但是,这一切的前提是加密和解密过程的安全。加密、解密过程由加密算法、加密密钥、解密算法、解密密钥组成。下图是一个对称加密、解密过程。对称加密密钥和解密密钥是同一个密钥,调用加密算法可将明文加密为密文,调用解密算法可将密文还原为明文。
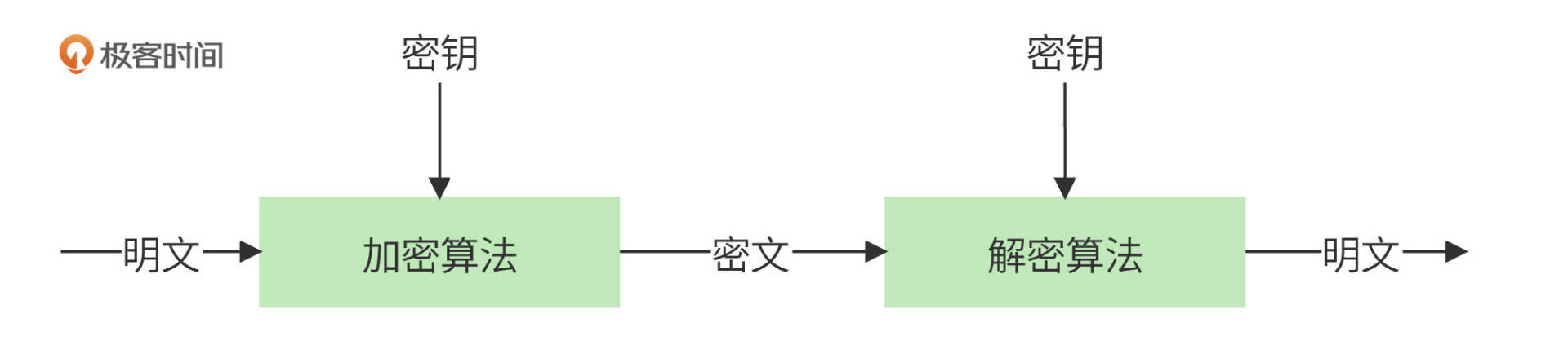
所以,如果窃取数据的人知道了解密算法和密钥,即使数据是加密的,也可以轻松对密文进行还原,得到原始的明文数据。而很多时候,解密算法和密钥都以源代码的方式保存在代码仓库里,黑客如果窃取了源代码,或者内部人泄露了源代码,那么所有的秘密就都不是秘密了。
此外,在某些情况下,我们的系统需要和外部系统进行对称加密数据传输,比如和银行加密传输信用卡卡号,这时候涉及到密钥交换,即我方人员和银行人员对接,直接传递密钥。如果因密钥泄露导致重大经济损失,那么持有密钥的人员将无法自证清白,这又会导致没有人愿意保管密钥。
因此,我们设计了一个加解密服务系统,系统名称为"Venus",统一管理所有的加解密算法和密钥。应用程序只需要依赖加解密服务SDK,调用接口进行加解密即可,而真正的算法和密钥在系统服务端进行管理,保证算法和密钥的安全。
需求分析
一般说来,日常开发中的加解密程序存在如下问题:
- 密钥(包括非对称加解密证书)保存在源文件或者配置文件中,存储分散而不安全。
- 密钥没有分片交换机制,不能满足高安全级密钥管理和交换的要求。
- 密钥缺乏版本管理,不能灵活升级,一旦修改密钥,此前加密的数据就可能无法解密。
- 加密解密算法程序不统一,同样算法不同实现,内部系统之间密文不能正确解析。
- 部分加解密算法程序使用了弱加解密算法和弱密钥,存在安全隐患。
为此,我们需要设计开发一个专门的加解密服务及密钥管理系统,以解决以上问题。
Venus是一个加解密服务系统,核心功能是加解密服务,辅助功能是密钥与算法管理。此外,Venus还需要满足以下非功能需求:
- 安全性需求- 必须保证密钥的安全性,保证没有人能够有机会看到完整的密钥。因此一个密钥至少要拆分成两片,分别存储在两个异构的、物理隔离的存储服务器中 。在需要进行密钥交换的场景中,将密钥至少拆分成两个片段,每个管理密钥的人只能看到一个密钥片段,需要双方所有人分别交接才能完成一次密钥交换。
- 可靠性需求- 加解密服务必须可靠,即保证高可用。无论在加解密服务系统服务器宕机、还是网络中断等各种情况下,数据正常加解密都需要得到保障。
- 性能需求- 加解密计算的时间延迟主要花费在加解密算法上,也就是说,加载加解密算法程序、获取加解密密钥的时间必须短到可以忽略不计。
根据以上加解密服务系统功能和非功能需求,系统用例图设计如下:
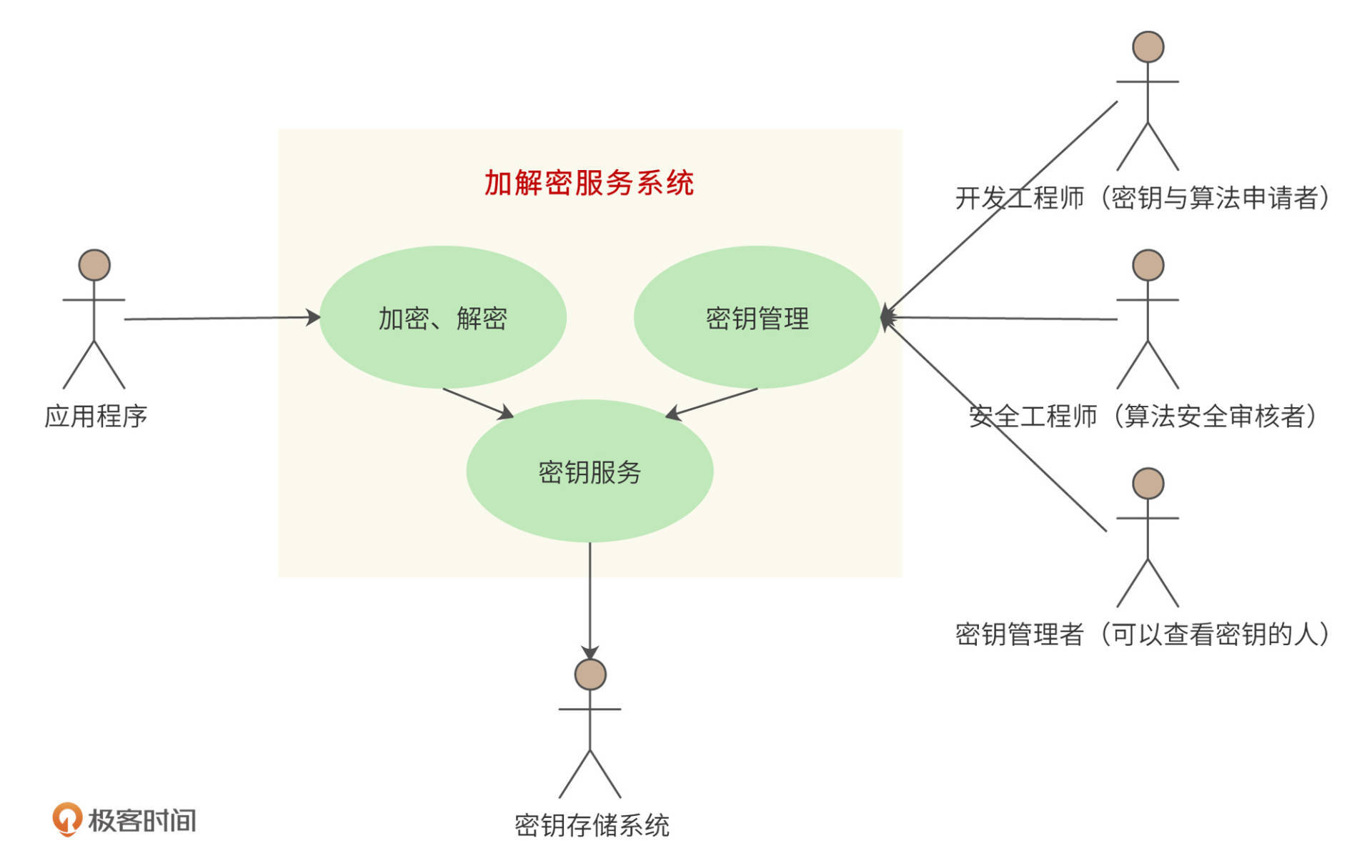
系统主要参与者(Actor)包括:
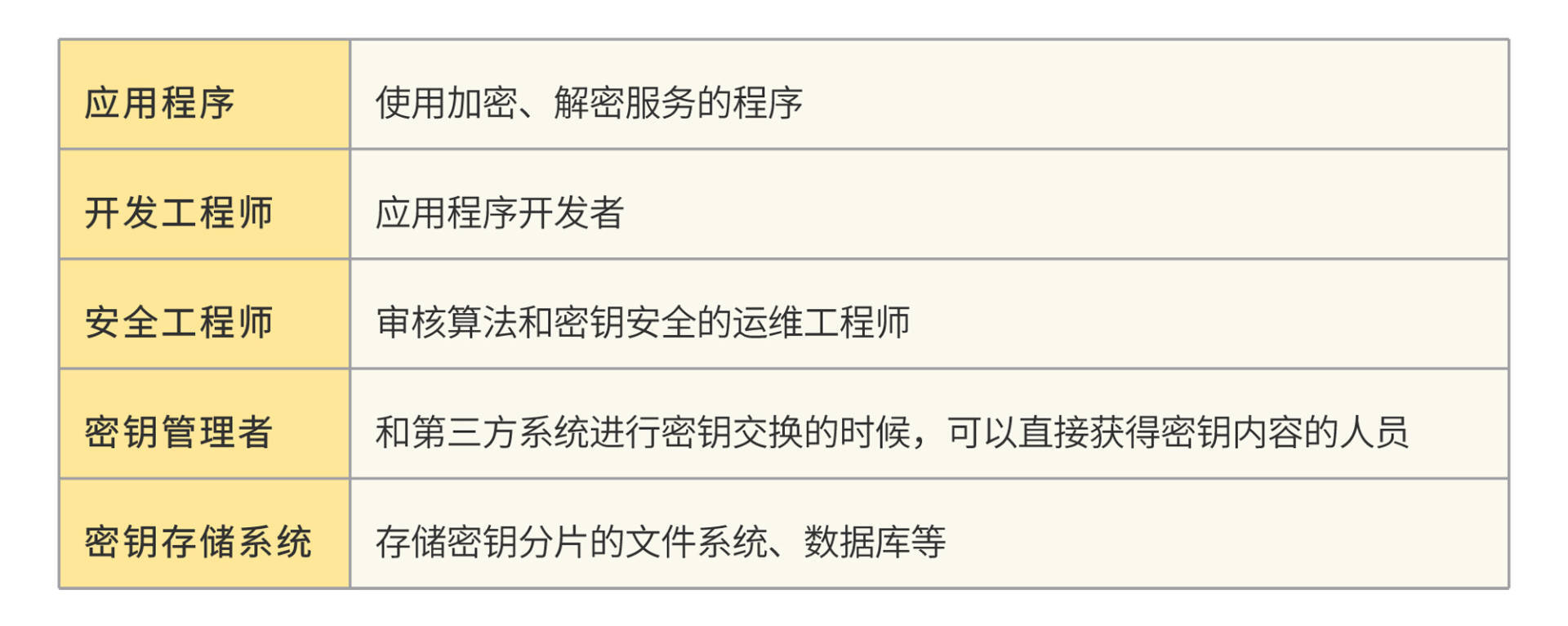
系统主要用例过程和功能包括:
- 开发工程师使用密钥管理功能为自己开发的应用申请加解密算法和密钥;
- 安全工程师使用密钥管理功能审核算法和密钥的强度是否满足数据安全要求;
- (经过授权的)密钥管理者使用密钥管理功能可以查看密钥(的一个分片);
- 应用程序调用加解密功能完成数据的加密、解密;
- 加密解密功能和密钥管理功能调用密钥服务功能完成密钥的存储和读取;
- 密钥服务功能访问一个安全、可靠的密钥存储系统读写密钥。
总地说来,Venus应满足如下需求:
- 集中、分片密钥存储与管理,多存储备份,保证密钥安全易管理。
- 密钥申请者、密钥管理者、密钥访问者,多角色多权限管理,保证密钥管理与传递的安全。
- 通过密钥管理控制台完成密钥申请、密钥管理、密钥访问控制等一系列密钥管理操作,实现便捷的密钥管理。
- 统一加解密服务API,简单接口,统一算法,为内部系统提供一致的加解密算法实现。
概要设计
针对上述加解密服务及密钥安全管理的需求,设计加解密服务系统Venus整体结构如下:
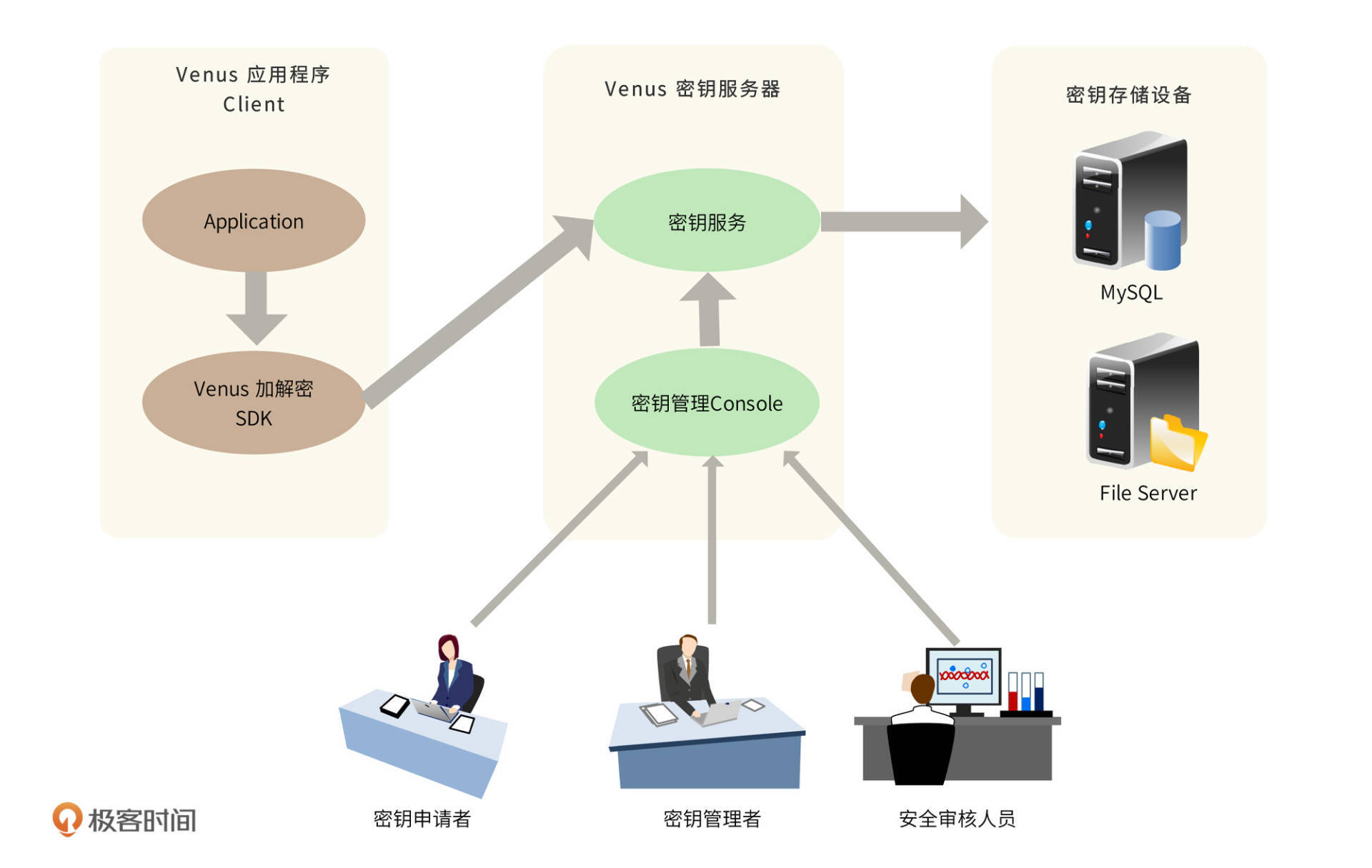
应用程序调用Venus提供的加解密SDK服务接口,对信息进行加解密,该SDK接口提供了常用的加密解密算法并可根据需求任意扩展。SDK加解密服务接口调用Venus密钥服务器的密钥服务,以取得加解密密钥,并缓存在本地。而密钥服务器中的密钥则来自多个密钥存储服务器,一个密钥分片后存储在多个存储服务器中,每个服务器都由不同的人负责管理。密钥申请者、密钥管理者、安全审核人员通过密钥管理控制台管理更新密钥,每个人各司其事,没有人能查看完整的密钥信息。
部署模型
Venus部署模型如图:
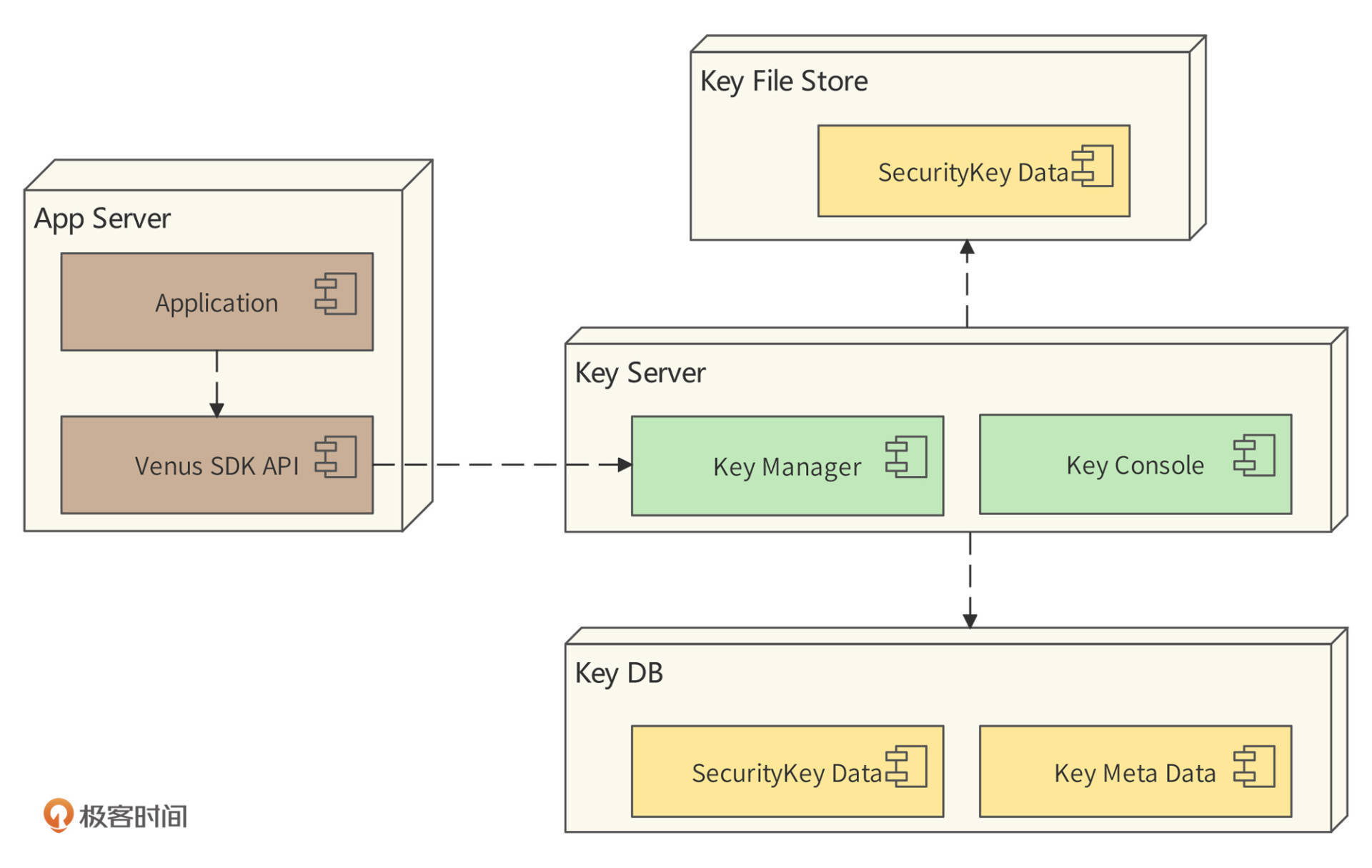
Venus系统的核心服务器是Key Server服务器,提供密钥管理服务。密钥分片存储在文件服务器File Store和数据库DB中。
使用Venus加解密服务的应用程序(Application)部署在应用程序服务器(App Server)中,依赖Venus提供的SDK API进行数据加解密。而Venus SDK 则是访问密钥服务器(Key Server)来获取加解密算法代码和密钥。
安全起见,密钥将被分片存储在文件服务器(Key File Store)和数据库服务器(Key DB)中。所以Key Server服务器中部署了密钥管理组件(Key Manager),用于访问数据库中的应用程序密钥元信息(Key Meta Data),以此获取密钥分片存储信息。Key Server服务器根据这些信息访问File Store和DB,获取密钥分片,并把分片拼接为完整密钥,最终返回给SDK。
此外,密钥管理控制台(Key Console)提供一个web页面,供开发工程师、安全工程师、密钥管理者进行密钥申请、更新、审核、查看等操作。
加解密调用时序图
加解密调用过程如下时序图所示。
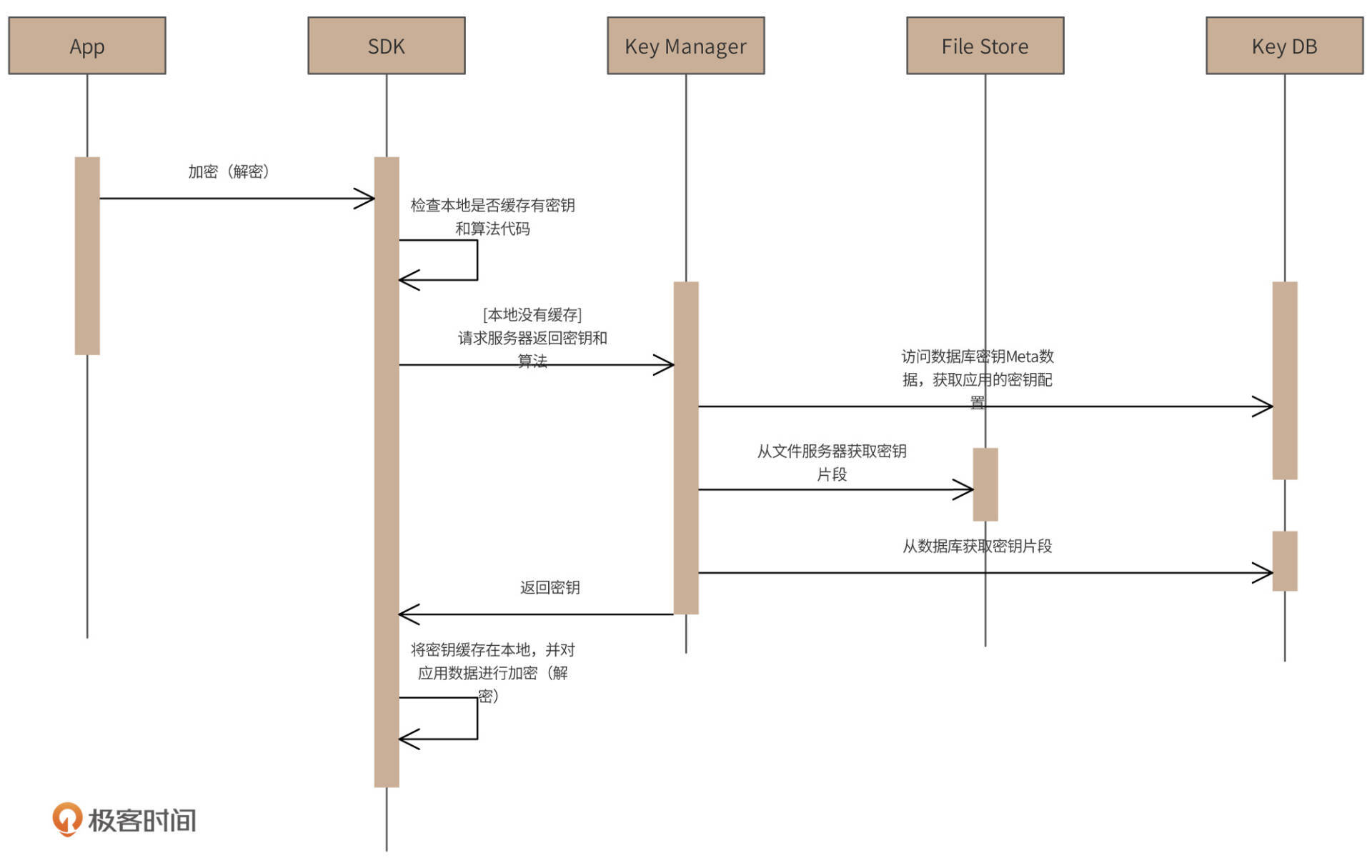
- 应用程序App调用Venus SDK对数据进行加密(解密)。
- SDK检查在本地是否有缓存加解密需要的密钥和加解密算法代码,如果有缓存,就直接使用该算法和密钥进行加解密。
- 如果本地没有缓存密钥和算法,请求远程服务器返回密钥和算法。
- 部署在Venus服务器的Key Manager收到请求后,访问数据库,检查该应用配置的密钥和算法Meta信息。
- 数据库返回的Mata信息中包括了密钥的分片信息和存储位置,Key Manager访问文件服务器和数据库,获取密钥分片,并将多个分片合并成一个完整密钥,返回给客户端SDK。
- SDK收到密钥后,缓存在本地进程内存中,并完成对App加解密调用的处理。
通过该设计,我们可以看到,Venus对密钥进行分片存储,不同存储服务器由不同运维人员管理。就算需要进行密钥交换,那么参与交换的人员,每个人也只能获得一个密钥分片,无法得到完整的密钥,这样就保证了密钥的安全性。
密钥缓存在SDK所在的进程(也就是应用程序App所在的进程)中,只有第一次调用时会访问远程的Venus服务器,其他调用只访问本进程缓存。因此加解密的性能只受加解密的数据大小和算法的影响,不受Venus服务的性能影响,满足了性能要求。
同时,由于密钥在缓存中,如果Venus服务器临时宕机,或者网络通信中断,也不会影响到应用程序的正常使用,保证了Venus的可靠性。但是如果Venus服务器长时间宕机,那么应用重新启动,本地缓存被清空,就需要重新请求密钥,这时候应用就不可用了。那么Venus如何在这种情况下仍然保证高可用呢?
解决方案就是对Venus服务器、数据库和文件服务器做高可用备份。Venus服务器部署2-3台服务器,构建一个小型集群,SDK通过软负载均衡访问Venus服务器集群,若发现某台Venus服务器宕机,就进行失效转移。同样,数据库和文件服务器也需要做主从备份。
详细设计
Venus详细设计主要关注SDK核心类设计。其他的例如数据库结构设计、服务器密钥管理Console设计等,这里不做展开。
密钥领域模型
为了便于SDK缓存、管理密钥信息以及SDK与Venus服务端传输密钥信息,我们设计了一个密钥领域模型,如下图:
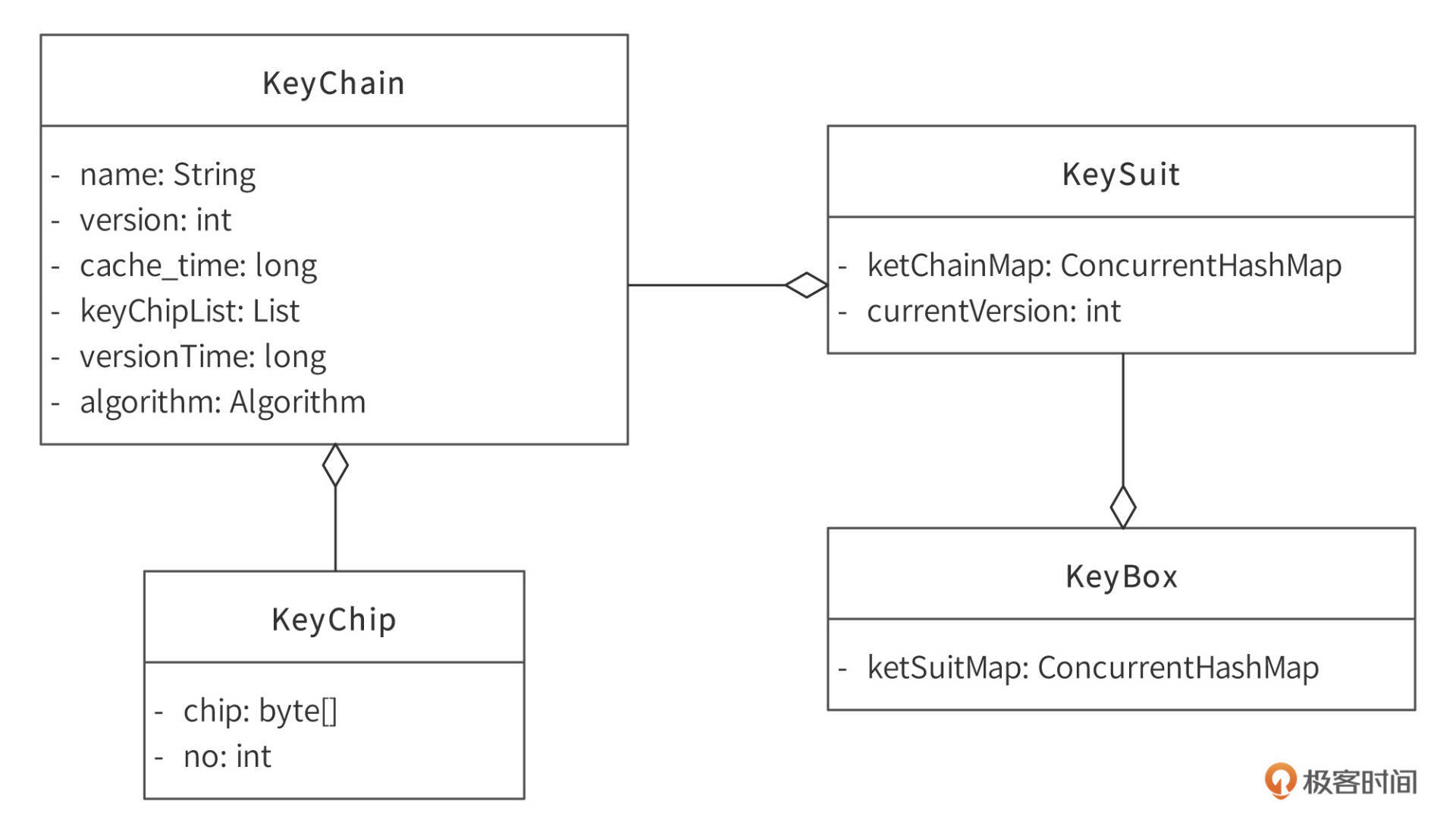
- 一个应用程序使用的所有密钥信息都记录在KeyBox对象中,KeyBox对象中有一个keySuitMap成员变量,这个map的key是密钥名称,value是一个KeySuit对象。
- KeySuit类中有一个keyChainMap成员变量,这个map类的key是版本号,value是一个KeyChain对象。Venus因为安全性需求,需要支持多版本的密钥。也就是说,对同一类数据的加密密钥过一段时间就会进行版本升级,这样即使密钥泄露,也只会影响一段时间的数据,不会导致所有的数据都被解密。
- KeySuit类的另一个成员变量currentVersion记录当前最新的密钥版本号,也就是当前用来进行数据加密的密钥版本号。而解密的时候,则需要从密文数据中提取出加密密钥版本号(或者由应用程序自己记录密钥版本号,在解密的时候提供给Venus SDK API),根据这个版本号获取对应的解密密钥。
- 具体每个版本的密钥信息记录在KeyChain中,包含了密钥名称name、密钥版本号version、加入本地缓存的时间cache_time、该版本密钥创建的时间versionTime、对应的加解密算法algorithm,当然,还有最重要的密钥分片列表keyChipList,里面按序记录着这个密钥的分片信息。
- KeyChip记录每个密钥分片,包括分片编号no,以及分片密钥内容chip。
核心服务类设计
应用程序通过调用加解密API VenusService完成数据加解密。如下图:
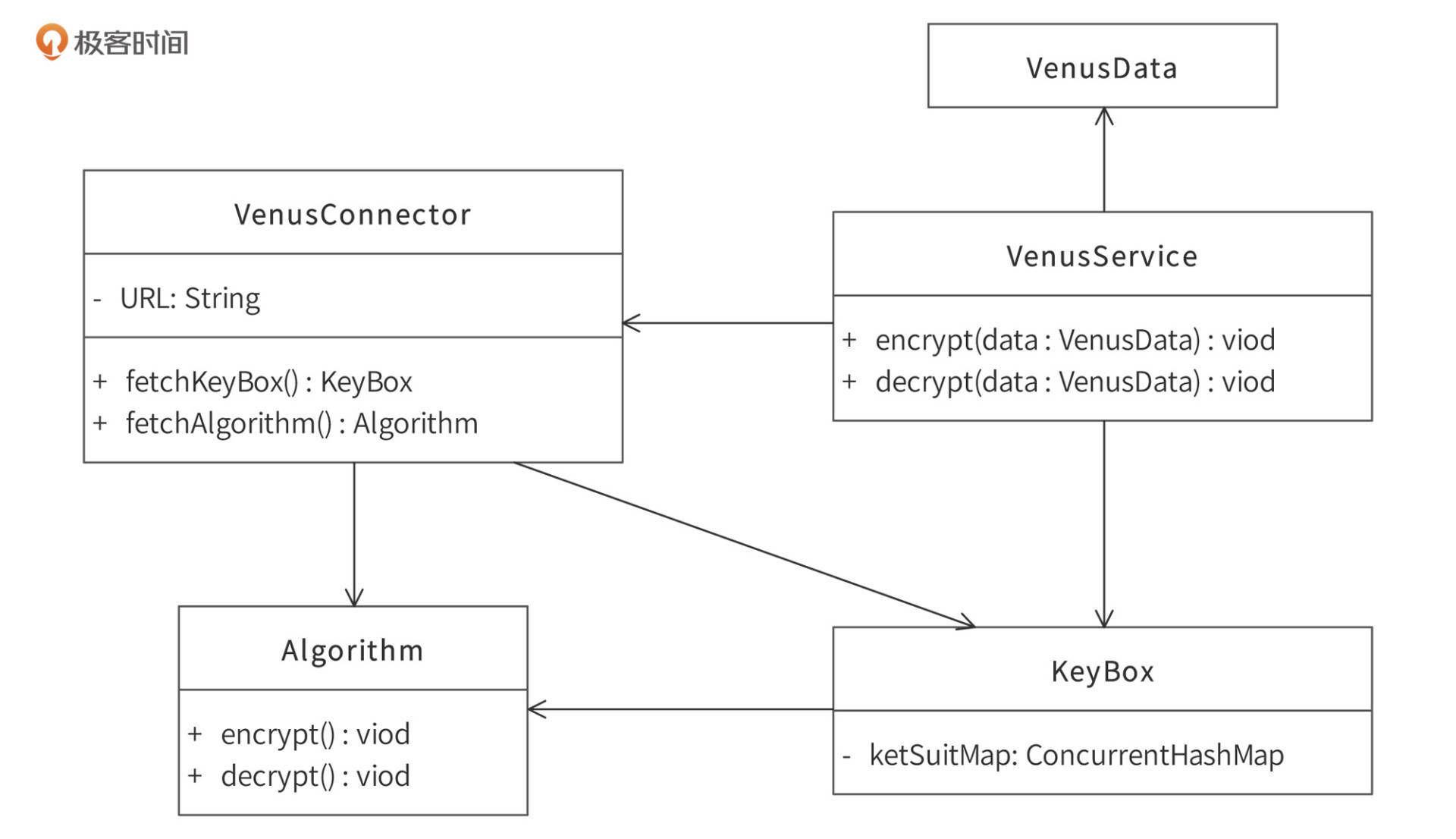
- Venus SDK的核心类是VenusService,应用程序调用该对象的encrypt方法进行加密,decrypt方法进行解密。应用程序需要构造VenusData对象,将加解密数据传给VenusService,VenusService加解密完成后创建一个新的VenusData对象,将加解密的结果写入该对象并返回。VenusData成员变量在后面详细讲解。
- VenusService通过VenusConnector类连接Venus服务器获取密钥KeyBox和算法Algorithm,并调用Algorithm的对应方法完成加解密。
以加密为例,具体处理过程时序图如下:
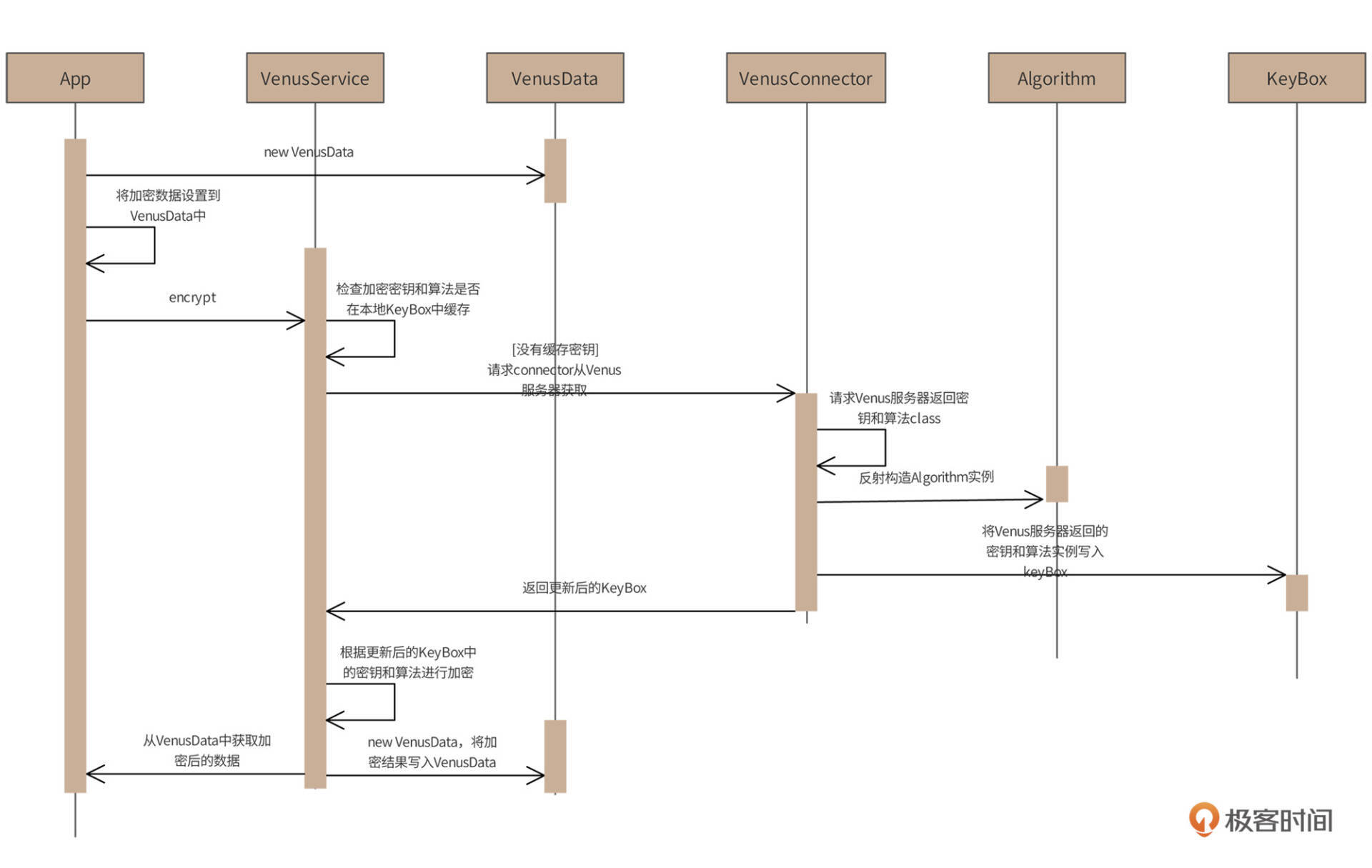
首先,应用程序App创建VenusData对象,并将待加密数据写入该对象。接着,App调用VenusService的encrypt方法进行加密,VenusService检查加密需要的密钥和算法是否已经有缓存,如果没有,就调用VenusConnector请求服务器,返回密钥和算法。VenusConnector将根据返回的算法字节码来构造加密算法的实例对象,同时根据返回的密钥构造相关密钥对象,并写入KeyBox,完成更新。
下一步,VenusService会根据更新后的KeyBox中的密钥和算法进行加密,并将加密结果写入VenusData。最后,应用程序App从返回的VenusData中获取加密后的数据即可。
加解密数据接口VenusData设计
VenusData用于表示Venus加解密操作输入和输出的数据,也就是说,加解密的时候构造VenusData对象调用Service对应的方法,加解密完成后返回值还是一个VenusData对象。
VenusData包含的属性如下图:
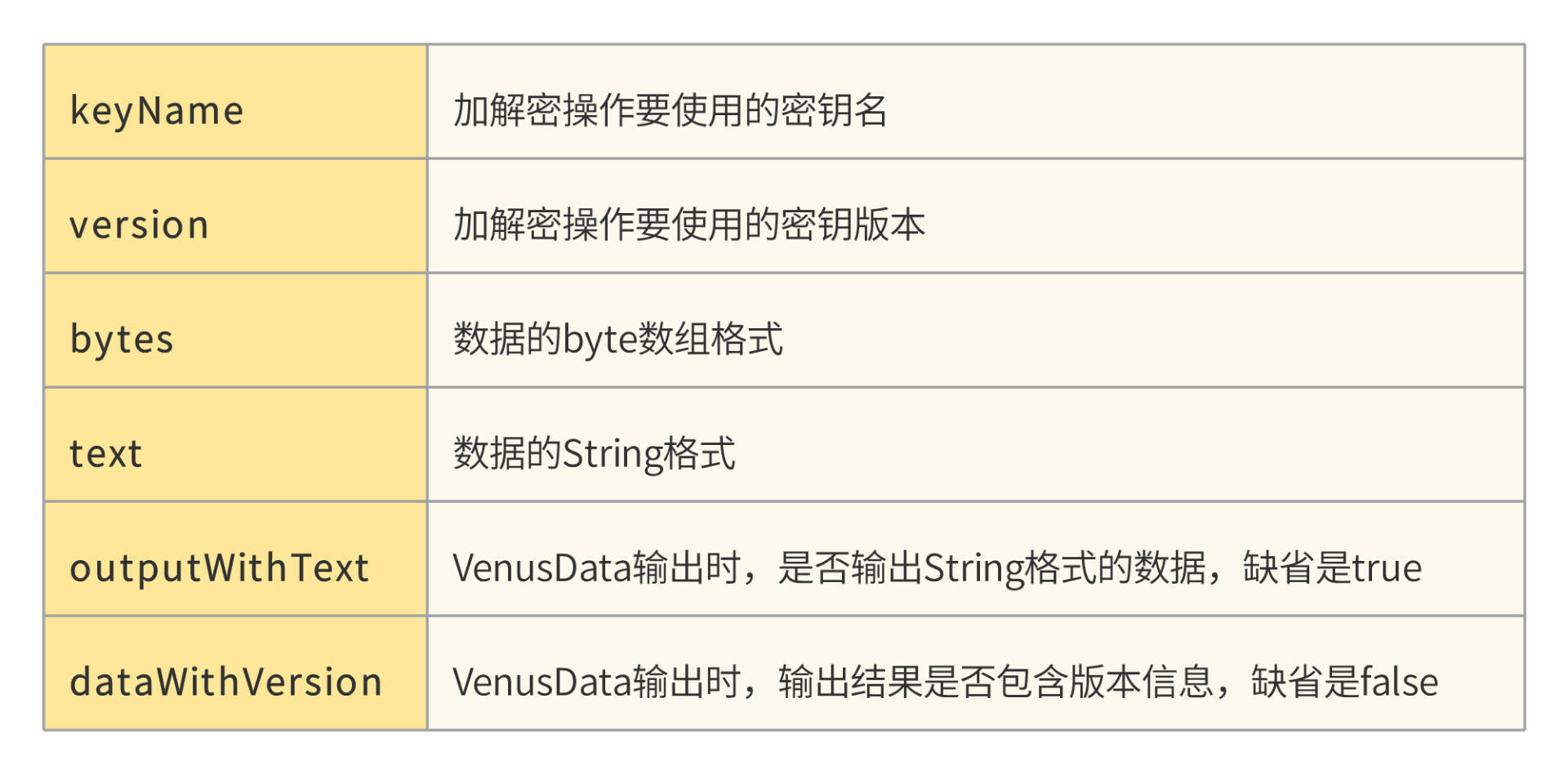
VenusData用作输入时:
- 属性bytes和text只要设置一个,即要么处理的是二进制bytes数据,要么是Striing数据,如果两个都设置了,Venus会抛出异常。
- 属性version可以不设置(即null),表示Venus操作使用的密钥版本是当前版本。
- 属性outputWithText表示输出的VenusData是否处理为text类型,缺省值是true。
- 属性dataWithVersion表示加密后的VenusData的bytes和text 中是否包含使用密钥的版本信息,这样在解密的时候可以不指定版本,缺省值是false。
如果dataWithVersion设置为true,即表示加密后密文内包含版本号,这种情况下,VenusService需要在密文头部增加3个字节的版本号信息,其中头两个字节为固定的magic code:0x5E、0x23,第三个字节为版本号(也就是说,密钥版本号只占用一个字节,最多支持256个版本)。
VenusData用作输出时,Venus会设置属性keyName(和输入时的值一样)、version、 bytes、 outputWithText、dataWithVersion(和输入时的值一样),并根据输入的 outputWithText决定是否设置text属性。
测试用例代码demo
java
public static void testVenusService() throws Exception {
// 准备数据
VenusData data1 = new VenusData();
data1.setKeyName("aeskey1");
data1.setText("PlainText");
// 加密操作
VenusData encrypt = VenusService.encrypt(data1);
System.out.printf("Key Name: %s, Secret Text: %s, Version: %d.\n", encrypt.getKeyName(),
encrypt.getText(), encrypt.getVersion());
// 准备数据
VenusData data2 = new VenusData();
data2.setKeyName("aeskey1");
data2.setBytes(encrypt.getBytes());
data2.setVersion(encrypt.getVersion());
// 解密操作
VenusData decrypt = VenusService.decrypt(data2);
System.out.printf("Key Name: %s, Plain Text: %s, Version: %d.\n", decrypt.getKeyName(),
decrypt.getText(), decrypt.getVersion());
}小结
随着国家信息安全法规的逐步完善以及用户对个人信息安全意识的增强,互联网信息安全也变得越来越重要了。据估计,我国每年涉及互联网信息安全的灰色产业达1000亿,很多应用在自己不知情的情况下,已经被窃取了信息并进行交易了。
Venus是根据某大厂真实设计改编的,如果你所在的公司还没有类似安全的加解密服务平台,不妨参考Venus的设计,开发实现一个这样的系统。
思考题
在你的工作中使用了哪些加密算法,算法以及密钥是否安全?有什么改进的思路吗?
19 许可型区块链重构:无中心的区块链怎么做到可信任?
过去几年,区块链正变成一个日渐热门的词汇,除了广为人知的比特币等数字货币,基于区块链的分布式账本和智能合约技术也越来越受到企业的重视,越来越多的企业也开始使用区块链技术进行跨企业的业务协作。2018 年 6 月 25 日,香港支付宝和菲律宾钱包 Gcash 利用区块链技术实现了跨境转账,仅 3 秒就实现跨境汇款到账,而以前则需要十几分钟到几天的时间。
一般我们把对所有公众都开放访问的区块链叫做"公有链",而把若干企业构建的仅供企业间访问的区块链叫做"联盟链 ",有时候也称作"许可型区块链"。上面提到的支付宝转账就是使用联盟链技术,目前比较有影响力的联盟链技术是 IBM 发起的 Hyperledger Fabric 项目,若干基于 Hyperledger Fabric 的联盟链应用已经落地。比如邮储银行的资产托管、招商银行的跨境结算都使用了 Hyperledger Fabric 技术。
而在公有链领域,目前看来,生态最完整、开发者社区最活跃、去中心化应用最多的公有链技术莫过于 Ethereum 以太坊。在智能合约和去中心化应用开发支持方面,以太坊的生态堪称业界最完备的典范,也受到了最多区块链开发者的支持。
相比于Fabric,使用以太坊开发区块链应用更加简单、易于上手,但是以太坊作为一个公有链技术,目前还无法应用于企业级的联盟链场景。所以我们准备在以太坊的代码基础上,进行若干代码模块的重构与开发。开发一个基于以太坊的企业级分布式账本与智能合约平台,即一个许可型区块链。这个许可型区块链产品名称为"Taireum"。
需求分析
所谓区块链(block chain),就是将不断产生的数据按时间序列分组成一个一个连续的数据区块(block),然后利用单向散列加密算法,求取每个区块的Hash值,并且在每个区块中记录前一个区块的Hash值,这些区块就通过Hash值串成一个链条,被形象地称为区块链。如果你想了解区块链更多的背景知识,可以参考我的这篇专栏文章《区块链技术架构:区块链到底能做什么?》。
以太坊(Ethereum)是一个去中心化的、开源的、有智能合约功能的公共区块链平台。以太币(ETH)是以太坊的原生加密货币,它是市值第二高的加密货币,仅次于比特币。而以太坊则是业界使用最多的区块链技术。
相比于比特币,以太坊最大的技术特点是支持智能合约,它是一种存储在区块链上的程序,由链上的计算机节点分布式运行,是一种去中心化的应用程序,也是区块链企业级应用必需的技术要求。
但是以太坊是一种公有链技术,并不适合用于企业级的场景,原因主要有三个:
- 在准入机制上,使用以太坊构建的区块链网络允许任何节点接入,也意味着区块数据是完全公开的。而联盟链的应用场景则要求仅联盟成员接入网络,非成员拒绝入网,并且数据也仅供联盟成员访问,对非联盟成员保密。
- 在共识算法上,以太坊使用工作量证明(PoW)的方式对区块打包进行算力证明,除非恶意节点获取了以太坊整个网络 51% 以上的计算能力,否则无法篡改或伪造区块数据,以此保证区块数据安全可靠。但是工作量证明需要花费巨大的计算资源进行算力证明,造成算力的极大浪费,也影响了区块链的交易吞吐能力。而在联盟链场景下,由于各个参与节点是经过联盟认证的,背后有实体组织背书,所以在区块打包的时候不需要进行工作量证明,这样可以大大减少算力浪费,提高交易吞吐能力。
- 在区块链运维管理上,以太坊作为公有链,节点之间通过 P2P 协议自动组网,无需运维管理。而联盟链需要对联盟成员进行管理,对哪些节点可被授权打包区块也需要进行管理,以保证联盟链的有效运行。
那么要如何做,才能既利用以太坊强大的智能合约与技术生态资源,简单高效地进行企业级区块链应用开发,又能满足联盟链对安全、共识、运维管理方面的要求?
Taireum需要在以太坊的基础上进行如下重构:
- 重构以太坊的 P2P 网络通信模块,使其需要进行安全验证,得到联盟许可才能加入新节点,进入当前联盟链网络。
- 重构以太坊的共识算法。只有经过联盟成员认证授权的节点才能打包区块,打包节点按序轮流打包,无需算力证明。
- 开发联盟共识控制台CCC(Consortium Consensus Console),方便对联盟链进行运维管理,联盟链用户只需要在 web console 上就可以安装部署联盟链节点,投票选举新的联盟成员和区块授权打包节点。
概要设计
Taireum 复用了以太坊强大的智能合约模块,并对共识算法和网络通信模块进行了重构改造,重新开发了联盟共识控制台,从而使其适用于企业级联盟链应用场景。使用 Taireum 部署的联盟链如图:
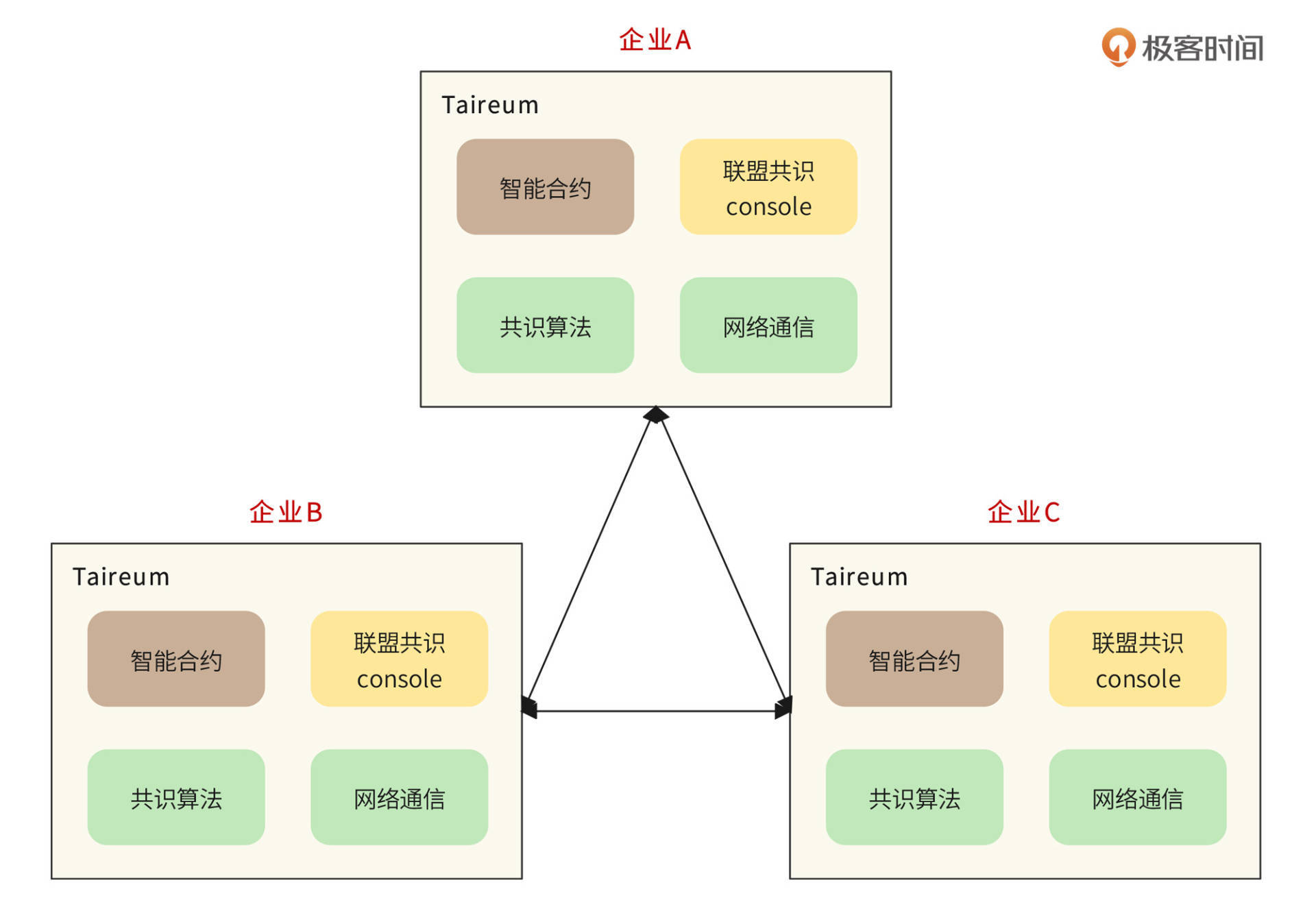
企业 A、企业 B、企业 C 合作建立一个联盟链,数据以区块链的方式存储在三家企业的节点上,实现分布式记账,并根据(基于智能合约的)联盟共识授权某些节点对区块数据进行打包。其他企业未经许可无法连接到该联盟链网络上,也不能查看区块链数据。
Taireum部署模型如下:
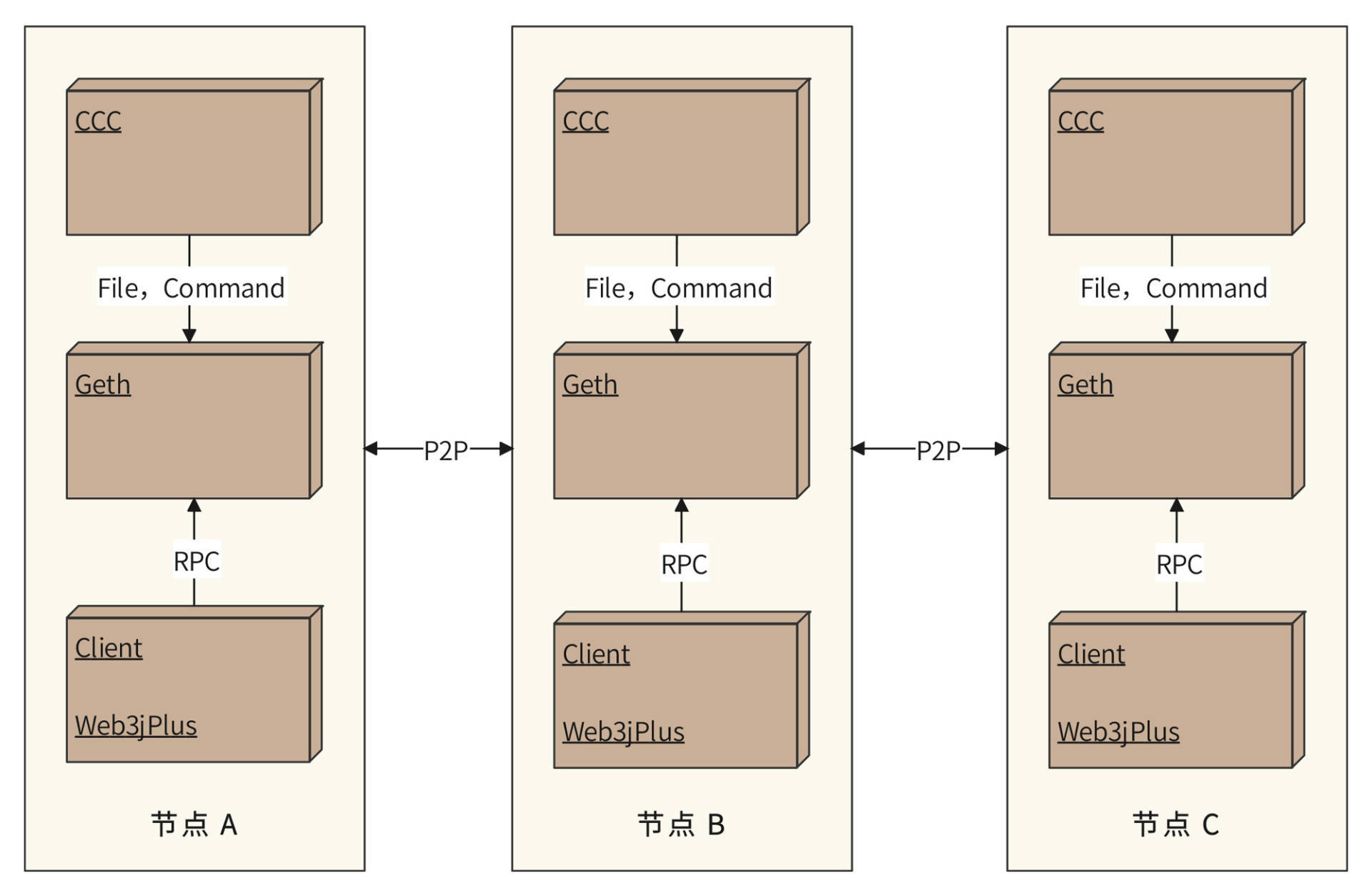
- Taireum中每个联盟企业都是一个Taireum节点,都需要完整地部署Taireum+CCC控制台, Client使用我们提供的web3jPlus sdk与Geth进行RPC通信。
- Geth是Tairem编译出来的区块链运行程序,里面包含重写的Tai共识算法,重构后的P2P网络模块,以及原始的以太坊代码。
- 不同节点之间的Geth使用P2P网络进行通信。
详细设计
针对以太坊不适合企业级应用的部分,Taireum将进行重构,详细设计如下。
Taireum联盟共识控制台
联盟共识控制台是Taireum为联盟链运维管理开发的web组件,企业可以非常方便地使用联盟共识控制台来部署联盟链运行节点、管理联盟成员和授权节点打包区块。
每个参与联盟链的企业节点都部署自己独立的联盟共识控制台。出于安全目的,每个企业节点的联盟共识控制台彼此独立,互不感知。他们需要通过调用联盟共识智能合约,对联盟管理事务进行协商,以达成共识。合约主要方法签名代码如下:
csharp
contract CCC {
//初始化合约,传入联盟创建者信息
//联盟创建者将成为联盟第一个成员和第一个拥有打包区块权限的节点
function CCC (string _companyname,string _email,string _remark,string _enode) public{
}
//联盟新成员申请
function applyMember(string _companyname,string _email,string _remark,string _enode,address _account) public{
}
//投票成为联盟成员
function VoteMember(uint _fromcompanyid,uint _tocompanyid) public {
}
//投票授权打包区块, 前提必须已经是联盟成员
function VoteMine(uint _fromcompanyid,uint _tocompanyid) public {
}
}联盟共识智能合约目前的版本主要包括投票选举申请加入联盟的新成员,及投票选举联盟链新的区块打包节点。该智能合约由联盟链创立者在第一次启动联盟共识控制台的时候自动创建,是联盟链成员进行联盟管理和协商共识的最主要方式。
既然联盟成员节点部署的联盟控制台彼此独立、互不通信,那么联盟其他成员如何获得联盟共识智能合约的地址呢?
Taireum的做法是:联盟链创立者节点的联盟共识控制台第一次成功部署联盟共识智能合约时,就把这个合约的地址发给共识算法模块。共识算法在封装区块头的时候,将合约地址写入区块头的miner中。下图是记录有联盟共识智能合约地址的区块头。
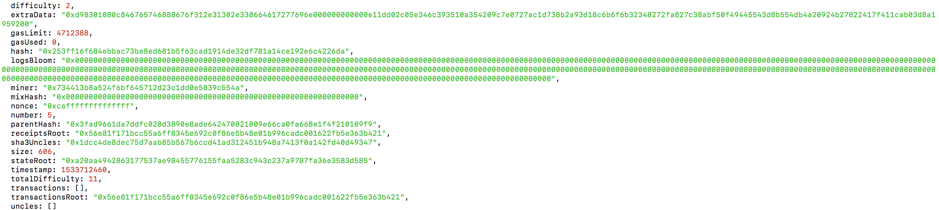
其中,extraData记录经过椭圆曲线加密的区块打包者地址信息,其他节点通过解密得到打包节点地址,并验证该地址是否有权限打包节点;miner中记录联盟共识智能合约地址;nonce记录一个magic code "0xcaffffffffffffff",表示该区块获得了共识合约地址并写入了当前区块(普通区块nonce magic code为"0x00ffffffffffffff")。
这样,联盟链成员节点加入联盟链,同步区块链数据后,就可以从区块头中读取联盟共识智能合约的地址,然后通过联盟共识控制台调用该合约,参与联盟管理及协商共识。
Taireum联盟新成员许可入网
以太坊作为一个公有链,任何遵循以太坊协议的节点都可以加入以太坊网络,同步区块数据,参与区块打包。同时,以太坊作为开源项目,用户也可以下载源代码,自己部署多个以太坊节点,组成一个自己的区块链网络。但是只要这些节点可以通过公网访问,就无法阻止其他以太坊节点连接到自己的区块链网络上,获取区块数据,甚至打包区块。这在联盟链的应用场景中是绝对不能接受的,联盟链需要保证联盟内数据的隐私和安全。
Taireum重构了以太坊的P2P通信模块,只有在许可列表中的节点才允许和当前联盟成员节点建立连接,其他的连接请求在通信模块就会被拒绝,以此保证联盟链的安全和私密性。
许可列表即Taireum成员列表,通过前述的联盟共识智能合约管理。P2P通信模块通过联盟共识控制台调用智能合约,获得联盟成员列表,检查连接请求是否合法。
Taireum联盟新成员许可入网流程:
- 新成员下载Taireum,启动联盟共识控制台,然后在联盟共识控制台启动Taireum节点,获得节点enode url。
- 将enode url及公司信息提交给当前联盟链某个成员,该成员通过联盟共识智能合约发起新成员入网申请。
- 联盟其他成员通过智能合约对新成员入网申请进行投票,得票数符合约定后,新成员信息被记入成员列表。
- 新成员节点通过网络连接当前联盟链成员节点,当前成员节点p2p通信模块读取智能合约成员列表信息,检查新成员节点enode url是否在成员列表中,如果在,就同意建立连接,新成员节点开始下载区块数据。
Taireum授权打包区块
Taireum根据联盟链的应用特点,放弃了以太坊ethash工作量证明算法。在借鉴clique共识算法的基础上,Taireum重新开发了Tai共识算法引擎,对联盟投票选出的授权打包节点排序,轮流进行区块打包。
Tai共识算法引擎执行过程如下:
- 联盟成员通过联盟共识智能合约投票选举授权打包区块的节点(在合约创建的时候,创建者即联盟链创始人默认拥有打包区块的权限)。
- Tai共识算法通过联盟共识控制台访问智能合约,获得授权打包区块的节点地址列表,并排序。
- 检查父区块头的extraData,解密取出父区块的打包者签名,查看该签名是否在授权打包节点地址列表里,如果不在就返回错误。
- 根据当前区块的块高(block number),对授权打包区块的节点地址列表长度取模,根据余数决定对当前区块进行打包的节点,如果计算出来的打包节点为当前节点,就进行区块打包,并把区块头难度系数设为2,如果非当前节点,随机等待一段时间后打包区块,并把区块头难度系数设为1。难度系数的目的是尽量使当前节点打包的区块被加入区块链,同时又保证当前打包节点失效的情况下,其他节点也会完成区块打包的工作。
Taireum源码:https://github.com/taireum/go-taireum。
小结
区块链也是一个分布式系统,但是不同于我们前面讨论过的各种传统分布式系统。传统分布式系统的各个分布式服务器节点是只属于某一个组织的,叫做中心化数据存储,数据的准确性和安全性靠的是这个组织的保证,使用者需要信任这个组织,比如我们相信支付宝不会偷偷把我们余额里的钱转走。
而区块链的分布式服务器节点并不只属于某一个组织,区块链并没有中心,而且使用区块链也不需要信任某个组织,因为任何数据篡改都会导致区块链条的中断。
区块链的这种特性可以实现无中心的跨组织交易。传统上,平行的组织之间交易需要通过更上一级的组织作为中心记录交易数据,比如商业银行之间的转账,要靠中央银行的数据中心来完成。如果没有更上一级的组织呢,就很难进行交易了。而使用区块链技术,即使没有中心,这些组织也可以进行交易,同时很多上级组织也变得没有那么必要了。
所以区块链会使我们的社会变得更加自组织,也将会给全社会的生产关系带来更深刻的变革。
思考题
今天我想和你讨论两个问题,你也可以任选其一。
- 许可型区块链的应用场景还有哪些?
- 你是否看好区块链未来的发展?为什么?