文章目录
- 1.引言
- 2.常见数据结构
- [3.核心认知:数据类型与编码方式的 "分离设计"](#3.核心认知:数据类型与编码方式的 “分离设计”)
-
- [3.1 复杂度不变,实现动态适配](#3.1 复杂度不变,实现动态适配)
- [3.2 编码方式的 "切换触发条件"](#3.2 编码方式的 “切换触发条件”)
- [4.查看底层编码 ------object encoding](#4.查看底层编码 ——object encoding)
- [5. 常用数据类型的编码优化逻辑](#5. 常用数据类型的编码优化逻辑)
-
- [5.1 String(字符串):3 种编码适配不同场景](#5.1 String(字符串):3 种编码适配不同场景)
- [5.2 Hash(哈希):压缩列表 vs 哈希表](#5.2 Hash(哈希):压缩列表 vs 哈希表)
- [5.3 List(列表):压缩列表 vs 双向链表](#5.3 List(列表):压缩列表 vs 双向链表)
- [5.4 Set(集合):整数集合 vs 哈希表](#5.4 Set(集合):整数集合 vs 哈希表)
- [5.5 ZSet(有序集合):压缩列表 vs 跳表](#5.5 ZSet(有序集合):压缩列表 vs 跳表)
- 6.小结
1.引言
提到 Redis 的数据结构,多数人会立刻想到 String、Hash、List 等常用类型。但鲜有人知的是:Redis 在底层实现时,并不会严格绑定某一种数据结构 ------ 为了兼顾性能与空间效率,它会根据数据的实际特征动态选择 "编码方式"。这种 "表面类型与底层编码分离" 的设计,正是 Redis 能在复杂场景下保持高效的核心原因之一。本文将带你拆解 Redis 数据结构的编码优化逻辑,看懂 "数据结构背后的真相"。
2.常见数据结构
当前版本的redis支持10个数据类型,其中5个比较常用
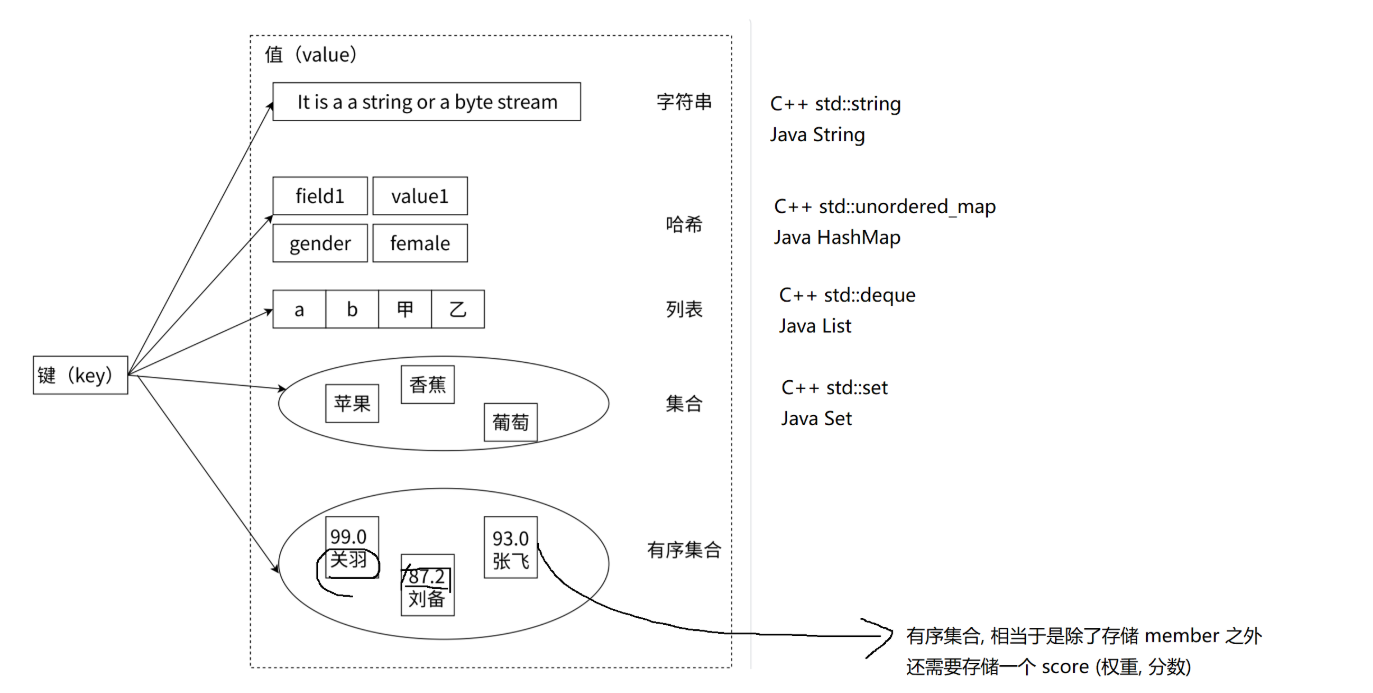
3.核心认知:数据类型与编码方式的 "分离设计"
3.1 复杂度不变,实现动态适配
Redis 的设计坚守一个基本原则:无论底层采用何种编码,用户操作数据结构的时间复杂度、空间复杂度都与抽象类型承诺一致。
例如,Hash 类型对外承诺 "键值对的增删改查为 O (1)",底层无论用 "压缩列表" 还是 "哈希表" 实现,都能保证这一复杂度;但两种编码的空间占用、操作效率在不同数据规模下差异巨大 ------ 这正是编码优化的价值所在。
3.2 编码方式的 "切换触发条件"
编码方式的切换由 Redis 自动完成,无需用户干预,触发条件通常与 "数据量大小" 或 "元素特征" 相关:
- 小数据量场景:优先选择 "空间紧凑" 的编码(如压缩列表),节省内存;
- 大数据量 / 高频操作场景:自动切换到 "操作高效" 的编码(如哈希表、跳表),保证性能。
这种 "自适应切换" 让 Redis 既能高效存储海量小数据,又能应对大数据的高频访问,实现 "内存与性能的平衡"。
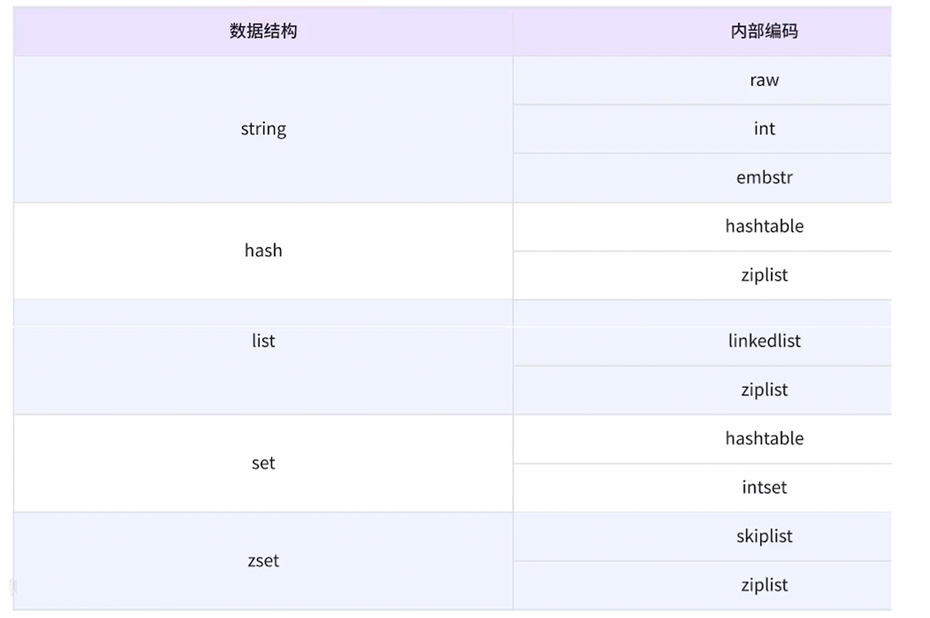
4.查看底层编码 ------object encoding
要验证 Redis 的编码优化逻辑,最直接的方式是使用object encoding命令 ------ 它能返回指定 Key 对应的 Value 的实际底层编码。
- 语法:
object encoding key
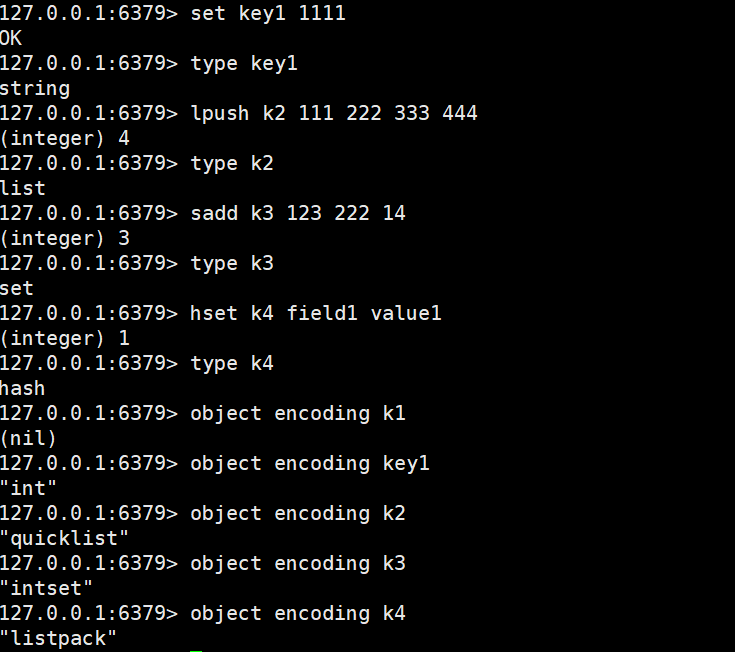
5. 常用数据类型的编码优化逻辑
5.1 String(字符串):3 种编码适配不同场景
String 是 Redis 最基础的类型,底层支持 3 种编码,核心围绕 "字符串长度" 与 "是否可修改" 优化:
| 编码类型 | 适用场景 | 核心优势 |
|---|---|---|
int |
字符串为 64 位以内的整数(如set num 123) | 直接用整数存储,比字符串格式更省内存 |
embstr |
字符串长度≤44 字节(默认)的短字符串 | 字符串与 Redis 对象元数据存储在同一块内存,减少内存碎片 |
raw |
字符串长度 > 44 字节的长字符串 | 单独存储字符串内容,避免元数据与长字符串占用连续内 |
示例:
bash
127.0.0.1:6379> set num 123456
OK
127.0.0.1:6379> object encoding num
"int" # 整数编码
127.0.0.1:6379> set short_str "hello redis" # 11字节
OK
127.0.0.1:6379> object encoding short_str
"embstr" # 短字符串编码
127.0.0.1:6379> set long_str "this is a very long string...(超过44字节)"
OK
127.0.0.1:6379> object encoding long_str
"raw" # 长字符串编码5.2 Hash(哈希):压缩列表 vs 哈希表
Hash 用于存储 "键值对集合",编码切换的核心是 "键值对数量" 与 "元素大小":
| 编码类型 | 适用场景 | 核心优势 |
|---|---|---|
| ziplist(压缩列表) | 键值对数量≤512 个(默认),且每个键 / 值长度≤64 字节 | 连续内存存储,无哈希表的指针开销,极省内存 |
| hashtable(哈希表) | 键值对数量 > 512 个,或任一键 / 值长度 > 64 字节 | 支持 O (1) 的增删改查,适合高 |
- 优化逻辑:小哈希表用压缩列表节省内存(如存储用户基本信息,字段少且短);当数据增长后,自动切换到哈希表保证操作效率(如存储商品的多维度属性,字段多且长)。
5.3 List(列表):压缩列表 vs 双向链表
List 是 "有序元素集合",编码优化围绕 "元素数量" 与 "长度":
| 编码类型 | 适用场景 | 核心优势 |
|---|---|---|
| ziplist(压缩列表) | 元素数量≤512 个(默认),且每个元素长度≤64 字节 | 连续内存存储,遍历效率高,内存占用少 |
| linkedlist(双向链表) | 元素数量 > 512 个,或任一元素长度 > 64 字节 | 支持高效的头部 / 尾部插入删除,适合大列表 |
- 注意:Redis 3.2 版本后引入quicklist(快速列表)编码,它是 "压缩列表 + 双向链表" 的混合结构 ------
将大列表拆分为多个小压缩列表,既保留压缩列表的内存优势,又解决长列表的遍历效率问题,目前已成为 List 的默认编码。
5.4 Set(集合):整数集合 vs 哈希表
Set 是 "无序、唯一元素集合",编码优化针对 "元素是否为整数":
| 编码类型 | 适用场景 | 核心优势 |
|---|---|---|
| intset(整数集合) | 所有元素均为 64 位以内的整数(如sadd nums 1 2 3) | 按整数大小有序存储,支持二分查找,内存占用极低 |
| hashtable(哈希表) | 包含非整数元素(如add names zhangsan lisi) | 用哈希表的键存储集合元素(值为 null),支持 O (1) 的存在性判断 |
5.5 ZSet(有序集合):压缩列表 vs 跳表
ZSet 是 "按分数排序的唯一元素集合",编码优化围绕 "元素数量" 与 "长度":
| 编码类型 | 适用场景 | 核心优势 |
|---|---|---|
| ziplist(压缩列表) | 元素数量≤128 个(默认),且每个元素长度≤64 字节 | 按分数有序存储,连续内存,省空间 |
| skiplist(跳表) | 元素数量 > 128 个,或任一元素长度 > 64 字节 | 结合跳表与哈希表,支持 O (logN) 的排序与查找,适合大数据排序场景(如排行榜) |
6.小结
Redis 的数据结构设计,藏着 "平衡取舍" 的工程智慧:对外提供简单统一的抽象类型,让开发者无需关心底层细节;对内通过动态编码优化,在不同场景下实现 "内存与性能的最优解"。
核心要点可归纳为三点:
- 分离设计:数据类型是 "抽象接口",编码方式是 "底层实现",复杂度承诺不变,实现动态适配;
- 工具关键:object encoding命令是窥探底层的窗口,建议在开发调试时多使用,建立 "类型 - 编码" 的对应认知;
- 场景适配:小数据用 "紧凑编码"(压缩列表、整数集合)省内存,大数据用 "高效编码"(哈希表、跳表)保性能,切换由 Redis 自动完成。