LangChain:开启大语言模型时代的钥匙
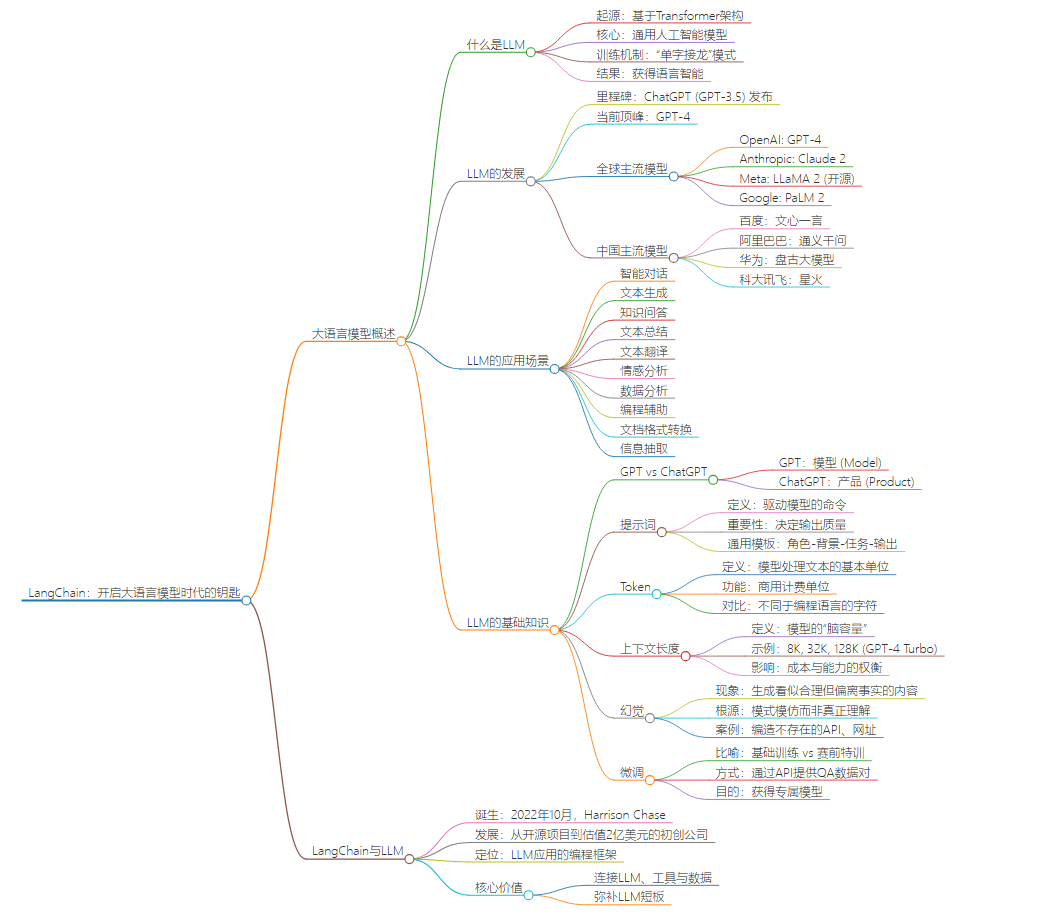
大语言模型(Large Language Model, LLM)概述
什么是LLM
- 起源:基于Transformer架构,大规模神经网络程序
- 核心:通用人工智能模型
- 训练机制:"单字接龙"模式
- 结果:获得语言智能
LLM的发展
- 里程碑:ChatGPT (GPT-3.5) 发布
- 当前顶峰:GPT-4
- 全球主流模型
- OpenAI: GPT-4
- Anthropic: Claude 2
- Meta: LLaMA 2 (开源)
- Google: PaLM 2
- 中国主流模型
- 百度:文心一言
- 阿里巴巴:通义千问
- 华为:盘古大模型
- 科大讯飞:星火
LLM的应用场景
- 智能对话
- 文本生成
- 知识问答
- 文本总结
- 文本翻译
- 情感分析
- 数据分析
- 编程辅助
- 文档格式转换
- 信息抽取

LLM的基础知识
GPT vs ChatGPT
- GPT:模型 (Model)
- ChatGPT:产品 (Product)
提示词(Prompt)
- 定义:驱动模型的命令
- 重要性:决定输出质量
- 通用模板:角色-背景-任务-输出
- 模板示例:

Token:大语言模型的基本单位
- 定义:模型处理文本的基本单位
- 功能:商用计费单位
- 对比:不同于编程语言的字符
上下文长度(Context Length)
- 定义:模型的"脑容量"
- 示例:8K, 32K, 128K (GPT-4 Turbo)
- 影响:成本与能力的权衡
幻觉
- 现象:生成看似合理但偏离事实的预测
- 根源:模式模仿而非真正理解
- 案例:生成内容编造不存在的API、网址
微调(Fine-tune)
- 比喻:基础训练 vs 赛前特训
- 方式:通过API提供QA数据对
- 目的:获得专属模型
LangChain与LLM
- 诞生:2022年10月,Harrison Chase
- 发展:从开源项目到估值2亿美元的初创公司
- 定位:LLM应用的编程框架
- 核心价值
- 连接LLM、工具与数据
- 弥补LLM短板
思维导图: