EMO: Real-Time Emotion Recognition from Single-Eye Images for Resource-Constrained Eyewear Devices
EMO系统的四大核心组件
-
特征提取器 (Feature Extractor)
- 一个卷积神经网络(CNN),使用改进的ResNet18,前7层是第一个阶段,在这里插入一个检查点判断是否和上一个输入特征相似,相似可以直接走快速转发器做出判定结果。
结构详解 输出尺寸 (HxW) 通道数 计算说明 conv1 3x3 卷积 64x64 16 输入: 64x64x3 (RGB图像) 操作: 使用16个3x3的卷积核,步长(Stride)为1,填充(Padding)为1。 输出: (64-3+2)/1+1 = 64 。所以输出为 64x64x16。(对比ResNet18:此处是7x7卷积+池化,输出56x56x64) conv1_x 3个残差块 64x64 16 每个残差块包含2层3x3卷积,共3个这样的块。 结构: 3x3,16−>3x3,163x3, 16 -> 3x3, 163x3,16−>3x3,16 由于使用了快捷连接(Shortcut)和Padding,尺寸保持不变 。 输出: 经过3个块后,仍然是 64x64x16。 conv2_x 3个残差块 32x32 32 这是第一个下采样层。 每个块的第一个卷积层步长(Stride)设为2 ,从而实现高宽减半(64/2=32)。同时通道数翻倍(16->32)。 输出: 32x32x32。 conv3_x 3个残差块 16x16 64 继续下采样。步长(Stride)=2,高宽再减半(32/2=16)。通道数再翻倍(32->64)。 输出: 16x16x64。 conv4_x 3个残差块 8x8 128 继续下采样。步长(Stride)=2,高宽再减半(16/2=8)。通道数再翻倍(64->128)。 输出: 8x8x128。 pooling 全局平均池化 1x1 128 将每个特征图(8x8)取平均值 ,压缩成一个数字。 操作: 输入8x8x128 -> 输出1x1x128。 这一层将空间信息全部压缩,后续可以直接连接全连接层进行分类。 -
个性化分类器 (Personalized Classifier)
-
一个为每个用户量身定制的情绪分类器。现有的个性化解决方案通常为每个用户建立一个专用的模型。这些解决方案不仅具有非常高的模型训练成本,而且每个用户的训练数据不足。
-
EMO采用了一个非常巧妙的思路:将特征提取和情绪分类这两个步骤分离开。
- 特征提取(Generic - 通用): 使用一个通用的CNN模型 (第4.1节设计的)。这个模型在所有用户 的庞大集合数据上进行训练,学会了如何从眼部图像中提取出有意义的、与情绪相关的低级和高级视觉特征 (如纹理、形状、轮廓)。这个步骤是通用的,不针对任何特定用户。
- 情绪分类(Personalized - 个性化): 分类器是为每个用户单独定制 的。它不采用传统的"全连接层+Softmax"结构(那需要大量数据训练),而是采用了一种基于特征匹配(Feature-Matching) 的轻量级方法。
-
步骤拆解:
-
特征提取:
features(i)=FE(frames(i))features_(i) = FE(frames_(i))features(i)=FE(frames(i))将每组表情图像帧送入通用的特征提取器(FE),得到一组对应的特征向量。每个特征向量代表一帧图像的高级抽象表示。
-
清洗异常值(第4行):
features(i)clear=IsolationForest(features(i))features_{(i)}^{clear} = IsolationForest(features_{(i)})features(i)clear=IsolationForest(features(i))使用孤立森林(Isolation Forest) 算法。这个算法能高效地识别出数据集中的异常点(Outliers)。
- 为什么要做这一步? 用户在模仿表情时,可能会有眨眼、表情不到位、或者中间过渡帧。这些帧的特征向量会偏离其对应表情的主流特征集群。清洗掉这些"噪音"数据点,能使后续计算的中心点更纯净、更代表用户的真实表情。
-
计算情绪中心点:
center(i)=KMeans(features(i)clear)center_{(i)} = KMeans(features_{(i)}^{clear)}center(i)=KMeans(features(i)clear)使用K-Means 聚类算法(这里K=1)对清洗后的特征向量集群进行计算,得到该集群的中心点(Centroid) ,即 centericenter_icenteri。这个点就是用户做第i种表情时,最典型、最标准的特征向量。
-
计算情绪半径:
radiusi=max(Similarity(centeri,f))for f infeatures(i)clearradius_i = max( Similarity(center_i, f) ) for\ f\ in features_{(i)}^{clear}radiusi=max(Similarity(centeri,f))for f infeatures(i)clear对于清洗后的每一个特征向量 fff,计算它与中心点 centericenter_icenteri 的相似度(Similarity) (使用余弦距离),然后取其中的最大值 作为 radiusiradius_iradiusi。
- 这代表了什么? radiusiradius_iradiusi 定义了该用户表达情绪i时,其所有有效特征向量分布范围的边界 。任何与 centericenter_icenteri 的相似度高于这个边界值(即距离更近)的特征向量,都可以被认为是属于情绪i的。
初始化完成后,系统进入实时工作状态。对于每一帧新来的图像(frameuframe^uframeu):
- 提取特征: FE(frameu)FE(frame^u)FE(frameu) 得到其特征向量。
- 计算匹配分数: 对于7种情绪中的每一种(i),计算一个标准化后的匹配分数 SiS_iSi:
Si=sim(FE(frameu), centeri)radiusi S_i = \frac{\text{sim}(FE(frame^u),\; center_i)}{radius_i} Si=radiusisim(FE(frameu),centeri)
- 分子 sim(...)sim(...)sim(...): 计算当前帧特征向量与情绪i的中心点的相似度(余弦距离,值越大越相似)。
- 分母 radiusiradius_iradiusi: 除以该情绪的"半径"进行标准化。这步非常关键!它消除了不同情绪其特征分布范围大小不一的影响,使得分数在不同情绪之间具有可比性。
- 做出决策: 比较7个 SiS_iSi 值,选择最大值 对应的那种情绪 iii 作为当前帧的识别结果。
-
-
-
快速转发器 (Fast Forwarder)
-
评估连续的两帧图像 在情绪特征上是否足够相似。如果相似,它就触发"快进"机制,让当前帧跳过后续所有的处理步骤,直接赋予它和上一帧相同的情绪标签。
-
使用孪生网络 来解决这个"语义相似度"比较的问题。快速转发器一共11层,前7层和特征提取器共用,提取特征。后面4层网络将中间特征进一步提炼成用于比较的128维高级语义特征向量 ,每帧图像的语义特征计算结果都会被缓存 ,用于计算当前帧的特征向量与上一帧缓存的特征向量之间的余弦相似度(Cosine Similarity)。
-
如果相似度 高于 阈值 θFFθ_FFθFF,则触发快速转发 。当前帧跳过特征提取器的后半部分和分类器,直接被赋予与上一帧相同的情绪标签。
-
动态阈值(θ_FF): 阈值不是固定的,而是在用户初始化时自动计算 的(公式2):
θFF=α×Ei sim(SN(framei),SN(framei+1)) \theta_{FF} = \alpha \times \mathbb{E}_{i} \; \text{sim}\big(SN(\text{frame}i), SN(\text{frame}{i+1})\big) θFF=α×Eisim(SN(framei),SN(framei+1))它计算了用户做表情时连续帧之间相似度的平均值 ,并用一个超参数 ααα(设为0.75)进行缩放。这是一个个性化的阈值,适应不同用户的表达习惯。
-
损失函数 - 对比损失(Contrastive Loss): 用于训练孪生网络(公式3):
Loss=12(y(1−s)2+(1−y)max(margin−(1−s),0)2) \text{Loss}=\tfrac{1}{2}\big(y(1-s)^2 + (1-y)\max(\text{margin} - (1-s),0)^2\big) Loss=21(y(1−s)2+(1−y)max(margin−(1−s),0)2)- y=1y=1y=1 表示正样本(希望相似),损失为 12(1−s)2\tfrac12(1-s)^221(1−s)2,当 s→1s\to1s→1(相似度高)损失趋近 0。
- y=0y=0y=0 表示负样本(希望不相似),损失对 (1−s)(1-s)(1−s) 与 margin 的差值进行惩罚,目的是把负对的 (1−s)(1-s)(1−s) 推到 ≥ margin ,即让它们的相似度 sss 小于等于 1−margin1-\text{margin}1−margin。
它的核心思想是:
- 对于"正样本对" (确实是同一情绪的两帧),让网络学习使它们的特征向量相似度接近1。
- 对于"负样本对" (是不同的情绪的两帧),让网络学习使它们的特征向量相似度低于一个边界值(margin)。
-
联合训练(Joint Training): 由于共享前7层,孪生网络和主特征提取器是一起训练 的。这确保了前半部分提取的特征对最终的情绪分类任务 和快速转发相似度比较任务都是有效的。
-
-
帧采样器 (Frame Sampler)
-
根据分类器或快速转发器的反馈 ,有选择地决定将哪些帧发送给后面的特征提取器进行处理。
-
基于两个对人类表情的深刻洞察:
- 一个情绪表达通常会持续至少 750毫秒
- 快速转发器计算出的相似度(SFFS_FFSFF)是衡量当前情绪短期稳定性的完美指标。相似度高,说明情绪稳定;相似度低,说明情绪可能正在变化。
-
帧采样器是一个决策器,它根据系统的历史反馈 来决定要跳过多少帧(NskipN_skipNskip)。它的输入包括:
- 上一次的识别方式: 是由个性化分类器 完整识别的,还是由快速转发器跳转的?
- 快速转发器的相似度(SFFS_FFSFF): 如果触发了快速转发,这个值反映了当前情绪的稳定程度。
- 情绪是否变化: 上一次识别结果相比再上一次,情绪标签有没有改变?
它的输出是:要跳过的帧数(NskipN_skipNskip)。
-
算法2
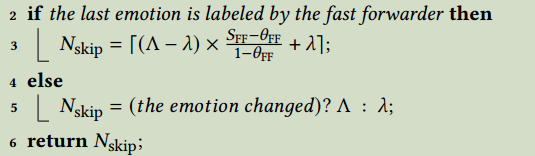
情况一:上一帧触发了快速转发(情绪稳定)
这是最常见的情况。上一帧因为和上上一帧相似而跳过了计算,说明情绪处于稳定状态。
- 决策逻辑: 此时,跳过的帧数 NskipN_skipNskip 是一个动态值 。它根据快速转发器的相似度 SFFS_FFSFF 来计算:
Nskip =⌈(Λ−λ)×SFF−θFF1−θFF+λ⌉N_{\text {skip }}=\left\lceil(\Lambda-\lambda) \times \frac{S_{\mathrm{FF}}-\theta_{\mathrm{FF}}}{1-\theta_{\mathrm{FF}}}+\lambda\right\rceilNskip =⌈(Λ−λ)×1−θFFSFF−θFF+λ⌉ - 公式解读:
- ΛΛΛ(大写Lambda):采样间隔上限(用户可设,默认为10帧)。这是最多能跳过的帧数。
- λλλ(小写lambda):采样间隔下限(用户可设)。这是最少要跳过的帧数。
- SFFS_FFSFF:快速转发器算出的相似度。
- θFFθ_FFθFF:快速转发器的触发阈值。
- 这个公式的作用是: 将相似度 SFFS_FFSFF 映射到区间 λ,Λλ, Λλ,Λ 之间。
- 当 SFFS_FFSFF 非常高(接近1),远高于阈值 θFFθ_FFθFF 时,说明情绪极其稳定 ,公式计算结果会接近上限 ΛΛΛ,系统会跳过较多帧。
- 当 SFFS_FFSFF 只是刚刚超过阈值 θFFθ_FFθFF 时,公式计算结果会接近下限 λλλ,系统会跳过得比较保守。
情况二 & 三:上一帧未触发快速转发(情绪可能变化)
else...else...else... 这里又分为两种子情况:
- 情况二:情绪未变化(theemotionchanged?falsethe emotion changed? falsetheemotionchanged?false)
- 场景: 上一帧走了完整的处理流程,但分类器给出的结果和之前一样。这意味着情绪没有发生本质变化 ,但可能处于一种快速波动的状态(例如,肌肉微调),导致快速转发器认为不相似。
- 决策: Nskip=λN_skip = λNskip=λ (设置为下限)
- 原因: 为了捕捉这种快速的、细微的变化,系统需要保持较高的采样率,所以只跳过最少的帧数(λλλ)。
- 情况三:情绪发生变化(theemotionchanged?truethe emotion changed? truetheemotionchanged?true)
- 场景: 上一帧走了完整的处理流程,并且分类器给出了一个新的情绪标签 。这意味着情绪刚刚完成了一次转换。
- 决策: Nskip=ΛN_skip = ΛNskip=Λ (设置为上限)
- 原因: 基于"情绪具有持续性"的观察,系统认为一个新情绪出现后,会至少持续一段时间 (750ms)。因此,在转换发生后,系统可以非常自信地跳过大量(ΛΛΛ帧)后续帧,因为它们极大概率还是同一个新情绪。
- 决策逻辑: 此时,跳过的帧数 NskipN_skipNskip 是一个动态值 。它根据快速转发器的相似度 SFFS_FFSFF 来计算:
-
具体实现
第一阶段:预训练(Pre-training) - "学习通用人脸表情"
这个阶段的目标是:让网络先学会从人脸图像中识别情绪,为后续学习更难的眼部情绪识别打下坚实的基础。
训练步骤:
- 输入一张完整人脸图片。
- 通过网络(CNN + 临时分类器)得到情绪预测概率分布。
- 使用交叉熵损失函数(公式4) 计算预测值与真实标签的差异。
- 通过反向传播,更新整个CNN和临时分类器的权重。
- 最终成果: 得到一个已经学会了"如何看懂情绪"的通用特征提取器。它的前几层学会了提取边缘、纹理等低级特征,后几层学会了组合这些特征形成与情绪相关的高级语义特征。
第二阶段:微调(Fine-tuning) - "专注眼部表情与相似度"
这个阶段的目标是:让预训练好的网络适应"眼部图像"这个特定领域 ,并同步训练孪生网络进行相似度比较。
同时训练两个部分:
- 主特征提取器(CNN):从预训练权重开始,继续微调。
- 孪生网络(Siamese Network):从零开始训练。
训练步骤:
说明:
- 训练四元组(Tetrad): 每次迭代,随机从数据集中选择两张图片 (F1F1F1, F2F2F2)和它们对应的标签(L1L1L1, L2L2L2)。这两张图可以来自同一个人,也可以是不同的人;可以是相同情绪,也可以是不同情绪。
- 共享特征提取: 将F1F1F1和F2F2F2输入网络共享的前7层 ,得到两个中间特征向量 Feature1Feature1Feature1 和 Feature2Feature2Feature2。
- 路径一:更新主特征提取器(针对分类任务)
- 将 Feature1Feature1Feature1 送入CNN的后半部分和临时分类器,得到预测结果。
- 使用交叉熵损失(L1) ,根据其真实标签 L1L1L1 计算误差。
- 通过反向传播,更新整个CNN(包括共享的前7层和后续层) 的权重。这一步确保网络提取的特征对于最终的情绪分类任务始终是最优的。
- 路径二:更新孪生网络(针对相似度任务)
- 将 Feature1Feature1Feature1 和 Feature2Feature2Feature2 送入孪生网络的后续4层,得到两个128维的高级特征。
- 计算这两个高级特征的余弦相似度。
- 使用对比损失(Contrastive Loss,公式3) 计算误差。
- 如果 L1L1L1 == L2L2L2(相同情绪),则目标是最小化它们的距离(相似度→1)。
- 如果 L1L1L1 != L2L2L2(不同情绪),则目标是最大化它们的距离直到超过一个边界值(相似度→0)。
- 通过反向传播,更新孪生网络后续4层 以及共享的前7层 的权重。这一步确保共享层提取的特征对于相似度比较任务也是最优的。