前言
Qwen3-Omni 是一种原生的端到端多语言全模态基础模型。它能够处理文本、图像、音频和视频,并提供实时的文本和自然语音响应。新架构基于MoE的Thinker--Talker设计,加上AuT预训练以生成强大的通用表示,保证低幻觉和高效的生成能力。
这篇文章主要梳理模型对多模态输入内容的处理,关注多模态内容如何进行融合。虽然只是了解输入内容的处理,但是涉及的模块组件也比较多了,这个模型与单模态文本生成模型有着显著的区别,模型架构更像是一个系统,每个组件负责不同的数据处理,有各自的模组。
先看推理代码示例,为避免干扰与乏味会尽量精简代码。官方video输入推理示例,使用场景是视频描述
python
import os
import torch
import warnings
import numpy as np
......
from qwen_omni_utils import process_mm_info
from transformers import Qwen3OmniMoeProcessor
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# 加载模型与输入内容处理器
def _load_model_processor():
if USE_TRANSFORMERS:
from transformers import Qwen3OmniMoeForConditionalGeneration
......
model = LLM(
model=MODEL_PATH, trust_remote_code=True, gpu_memory_utilization=0.95,
tensor_parallel_size=torch.cuda.device_count(),
limit_mm_per_prompt={'image': 1, 'video': 3, 'audio': 3},
max_num_seqs=1,
max_model_len=32768,
seed=1234,
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
return model, processor
def run_model(model, processor, messages, return_audio, use_audio_in_video):
......
from vllm import SamplingParams
sampling_params = SamplingParams(temperature=1e-2, top_p=0.1, top_k=1, max_tokens=8192)
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
audios, images, videos = process_mm_info(messages, use_audio_in_video=use_audio_in_video)
inputs = {'prompt': text, 'multi_modal_data': {}, "mm_processor_kwargs": {"use_audio_in_video": use_audio_in_video}}
if images is not None: inputs['multi_modal_data']['image'] = images
if videos is not None: inputs['multi_modal_data']['video'] = videos
if audios is not None: inputs['multi_modal_data']['audio'] = audios
outputs = model.generate(inputs, sampling_params=sampling_params)
response = outputs[0].outputs[0].text
return response, None
model, processor = _load_model_processor()
video_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/cookbook/video1.mp4"
messages = [
{
"role": "user",
"content": [
{"type": "video", "video": video_path},
{"type": "text", "text": "Describe the video."}
]
}
]
display(Video(video_path, width=640, height=360))
response, audio = run_model(model=model, messages=messages, processor=processor, return_audio=RETURN_AUDIO, use_audio_in_video=USE_AUDIO_IN_VIDEO)
Print(response)根据官方的使用示例可以知晓推理使用的模型类是Qwen3OmniMoeForConditionalGeneration
python
class Qwen3OmniMoeForConditionalGeneration(Qwen3OmniMoePreTrainedModel, GenerationMixin):
config_class = Qwen3OmniMoeConfig
def __init__(self, config: Qwen3OmniMoeConfig):
super().__init__(config)
self.thinker = Qwen3OmniMoeThinkerForConditionalGeneration._from_config(config.thinker_config)
self.has_talker = config.enable_audio_output
if self.has_talker:
self.enable_talker()
self.post_init()初始化会引入Qwen3OmniMoeThinkerForConditionalGeneration类,用于思考。如果开启语音输出会导入Qwen3OmniMoeTalkerForConditionalGeneration类。官方文档中提到的两段式,第一段思考,第二段是音频生成。
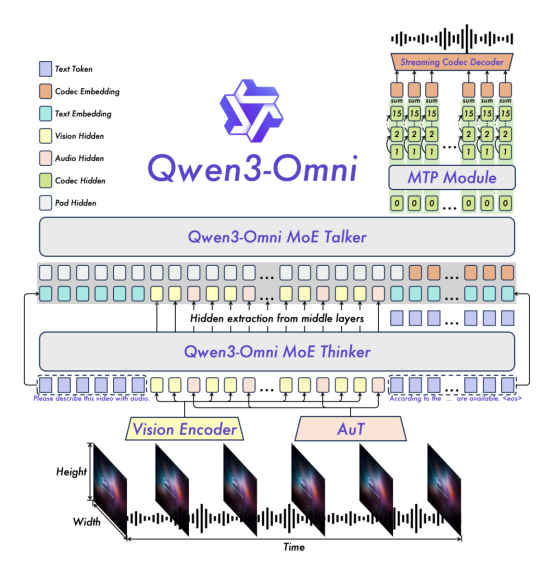
Qwen3OmniMoePreTrainedModel是一个基础的Omni类,大部分模块类均基于它。配置类Qwen3OmniMoeConfig也是Qwen3OmniMoePreTrainedModel的一个配置属性。用于存储Qwen3OmniMoeForConditionalGeneration的配置。根据指定的子模型配置实例化Qwen3Omni模型,定义模型架构。配置对象继承自PretrainedConfig,可用于控制模型输出。参数:thinker_config:底层思维子模型的配置。talker_config:底层谈话者子模型的配置。code2wav_config:底层code2wav子模型的配置。enable_audio_output:是否启用音频输出并加载谈话者和code2wav模块。
多模态内容处理:
从模型外部接口generate推理函数入口开始梳理代码,input_ids是包含了多模态数据处理过的dict 类型数据,其中含有文本、图片、音频、视频
python
def generate(
self,
input_ids: Optional[torch.Tensor] = None,
speaker: str = "Ethan",
use_audio_in_video: bool = False,
return_audio: Optional[bool] = None,
thinker_max_new_tokens: int = 1024,
thinker_eos_token_id: int = 151645,
talker_max_new_tokens: int = 4096,
talker_do_sample: bool = True,
talker_top_k: int = 50,
talker_top_p: float = 1.0,
talker_temperature: float = 0.9,
talker_repetition_penalty: float = 1.05,
**kwargs,
):
# ......
# thinking推理多模态输入
thinker_result = self.thinker.generate(input_ids=input_ids, **thinker_kwargs)
# 后续处理,推理张量转成音频输出Thinker实例即class Qwen3OmniMoeThinkerForConditionalGeneration类继承GenerationMixin与nn.Module,通过generate处理输入信息后调用到类的forward函数处理。
模型调用自身forward函数流程,在父类GenerateMixIn中调用generate函数,内部根据生成配置选择具体的解码方法:
generation_mode = generation_config.get_generation_mode(assistant_model)
decoding_method = getattr(type(self), GENERATION_MODES_MAPPINGgeneration_mode)
获取采样方式,然后调用对应采样的函数prepare_inputs_for_generation准备传入模型前的数据,然后调用模型自身,触发torch的调用__call__ 至forward函数
python
def forward(
self,
input_ids=None,
input_features=None,
pixel_values=None,
pixel_values_videos=None,
image_grid_thw=None,
video_grid_thw=None,
attention_mask=None,
audio_feature_lengths=None,
position_ids=None,
past_key_values=None,
inputs_embeds=None,
use_audio_in_video=None,
......
video_second_per_grid=None,
**kwargs,
) -> Union[tuple, Qwen3OmniMoeThinkerCausalLMOutputWithPast]:
#......
if inputs_embeds is None:
# 1. 提取出 embeddings
inputs_embeds = self.get_input_embeddings()(input_ids)
visual_embeds_multiscale = None
visual_pos_masks = None
# 依次对音频、图片、视频占位符替换合并
if input_features is not None:
audio_features = self.get_audio_features(
input_features,
feature_attention_mask=feature_attention_mask,
audio_feature_lengths=audio_feature_lengths,
)
audio_features = audio_features.to(inputs_embeds.device, inputs_embeds.dtype)
# get_placeholder_mask能获取音频、图片、视频mask
_, _, audio_mask = self.get_placeholder_mask(input_ids, inputs_embeds=inputs_embeds)
# 使用 masked_scatter 操作将音频特征嵌入到文本输入嵌入的对应位置。
inputs_embeds = inputs_embeds.masked_scatter(audio_mask, audio_features)
if pixel_values is not None:
# 图片占位符处理
image_embeds, image_embeds_multiscale = self.get_image_features(pixel_values, image_grid_thw)
image_embeds = image_embeds.to(inputs_embeds.device, inputs_embeds.dtype)
image_mask, _, _ = self.get_placeholder_mask(
input_ids, inputs_embeds=inputs_embeds, image_features=image_embeds
)
inputs_embeds = inputs_embeds.masked_scatter(image_mask, image_embeds)
if pixel_values_videos is not None:
# 视频占位符处理
video_embeds, video_embeds_multiscale = self.get_video_features(pixel_values_videos, video_grid_thw)
video_embeds = video_embeds.to(inputs_embeds.device, inputs_embeds.dtype)
_, video_mask, _ = self.get_placeholder_mask(
input_ids, inputs_embeds=inputs_embeds, video_features=video_embeds
)
inputs_embeds = inputs_embeds.masked_scatter(video_mask, video_embeds)
# ......
# model参数是Qwen3OmniMoeThinkerTextModel类,进入forward推理函数进入token推理生成
outputs = self.model(
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_router_logits=output_router_logits,
cache_position=cache_position,
deepstack_visual_embeds=visual_embeds_multiscale,
visual_pos_masks=visual_pos_masks,
**kwargs,
)根据Qwen3OmniMoeThinkerTextModel继承nn.Module执行forward 函数按层推理
python
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Cache] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
......
visual_pos_masks: Optional[torch.Tensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> Union[tuple, BaseModelOutputWithPast]:
# ......
hidden_states = inputs_embeds
# 做旋转位置编码
position_embeddings = self.rotary_emb(hidden_states, position_ids)
# self.layers对应一序列text解码层nn.ModuleList(
# [Qwen3OmniMoeThinkerTextDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
#)
for layer_idx, decoder_layer in enumerate(self.layers):
layer_outputs = decoder_layer(
hidden_states,
attention_mask=attention_mask,
position_ids=text_position_ids,
past_key_values=past_key_values,
cache_position=cache_position,
position_embeddings=position_embeddings,
**kwargs,
)
hidden_states = layer_outputs
......
hidden_states = self.norm(hidden_states)
return BaseModelOutputWithPast(
last_hidden_state=hidden_states,
past_key_values=past_key_values,
)对上述代码Qwen3OmniMoeThinkerTextDecoderLayer代码结构查看,层的包含注意力层、全连接层、归一化层:
python
class Qwen3OmniMoeThinkerTextDecoderLayer(GradientCheckpointingLayer):
def __init__(self, config, layer_idx):
super().__init__()
self.hidden_size = config.hidden_size
self.self_attn = Qwen3OmniMoeThinkerTextAttention(config, layer_idx)
if (layer_idx not in config.mlp_only_layers) and (
config.num_experts > 0 and (layer_idx + 1) % config.decoder_sparse_step == 0
):
self.mlp = Qwen3OmniMoeThinkerTextSparseMoeBlock(config)
else:
self.mlp = Qwen3OmniMoeThinkerTextMLP(config, intermediate_size=config.intermediate_size)
self.input_layernorm = Qwen3OmniMoeThinkerTextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = Qwen3OmniMoeThinkerTextRMSNorm(config.hidden_size, eps=config.rms_norm_eps)