目录
一、认识Redis
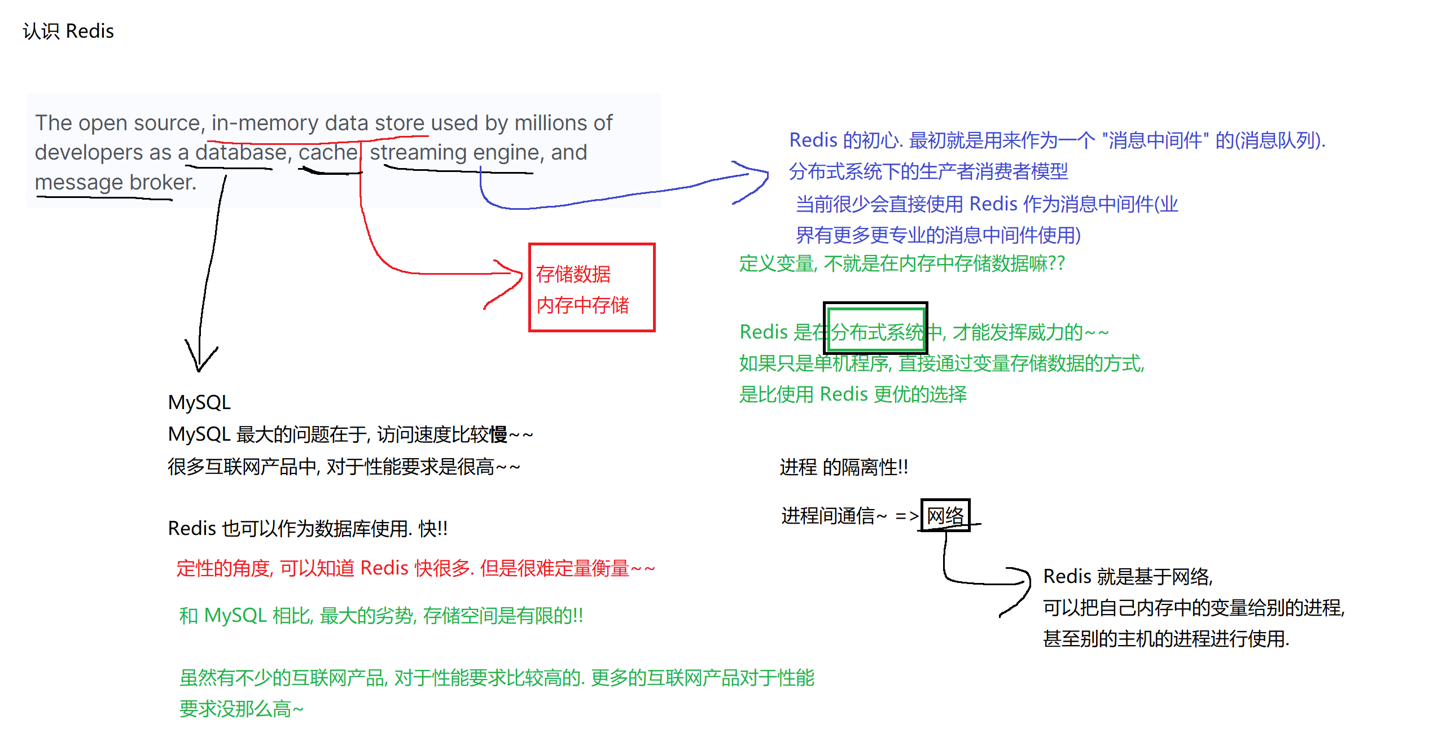

Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。
对于内存存储:平时我们定义一个变量也是在内存当中,那为什么不直接使用变量来存储数据?
因为在分布式系统中,Redis才能体现它的作用,在单机架构当中使用变量存储数据是比使用Redis更优的,但是对于分布式(多台服务器),如何访问到别的进程的内存呢?这当然不能直接访问,由于进行有独立性隔离性,这就基于进程间通信,redis是基于网络来交换内存中的数据的
一句话总结就是:单机架构的内存共享依赖 "本地可控的进程间通信(IPC)",而分布式架构的内存共享依赖 "不可靠的网络通信"------ 后者的 "不可靠性" 和 "复杂性",正是分布式场景下不能直接用变量、必须依赖 Redis 等中间件的核心原因。
1.1Redis的三个应用场景
1.一开始Redis的初心是做消息队列(消息队列(Message Queue,简称 MQ)是一种基于 "生产者 - 消费者" 模式的中间件 ,核心作用是在分布式系统中实现消息的异步传递、解耦和缓冲 ------ 简单理解,它就像一个 "分布式邮箱":一方(生产者)把 "消息"(数据 / 指令)放入邮箱,另一方(消费者)从邮箱中取出消息并处理,双方无需直接通信,也无需同时在线。)(现在很少使用Redis做消息中间件了,有更多更专业的,Kafka等)
**2.**Redis作为数据库:
Mysql优点:1.数据持久化和可靠性高:基于磁盘存储,支持事物和锁等能够保证数据的一致性 和安全性
2.支持复杂查询与关系模型:用户--订单--商品的关联
3.强一致性与事物支持:提供严格的事务隔离级别(读未提交、读已提交、可重复 读、串行化),确保多操作的原子性(如转账时 "扣款" 和 "到账" 必须同时成功 或失败)。
4.成熟的生态与工具链:有完善的备份恢复工具(mysqldump)、监控工具 (Prometheus + Grafana)、管理工具(Navicat),以及丰富的驱动支持各种编 程语言。
Mysql缺点:1.性能瓶颈(尤其是高并发的读写):磁盘 I/O 速度远低于内存,面对高并发(如 每秒数万次请求)时,读写性能会显著下降,即使有索引优化,也难以应对极端 流量。
Redis优点:1.超高读写性能:数据存储在内存中,读写速度极快(每秒可达 10 万 + 操作), 适合作为缓存减轻 MySQL 压力,或存储高频访问数据(如商品库存、热点新 闻)。
Redis缺点:1.内存成本高,存储容量有限:内存价格远高于磁盘,Redis 存储容量受限于服务器 内存,不适合存储海量数据(如历史订单、大文件)。
2.持久化存在风险。
**3.**Redis作为缓存:Mysql和Redis结合:比如读写分离,一般来说读比写 8:2或者9:1,就可以把写交给mysql,把读交给redis,读先到redis中读,如果读不到再去mysql中读,而且把读到的数据放在redis中,下一次读就可以快速的读,写就使用mysql,保证数据的一致性和安全性
但会把系统架构的复杂度增加,而且还有Redis和Mysql之间数据同步的问题
1.2关于分布式系统
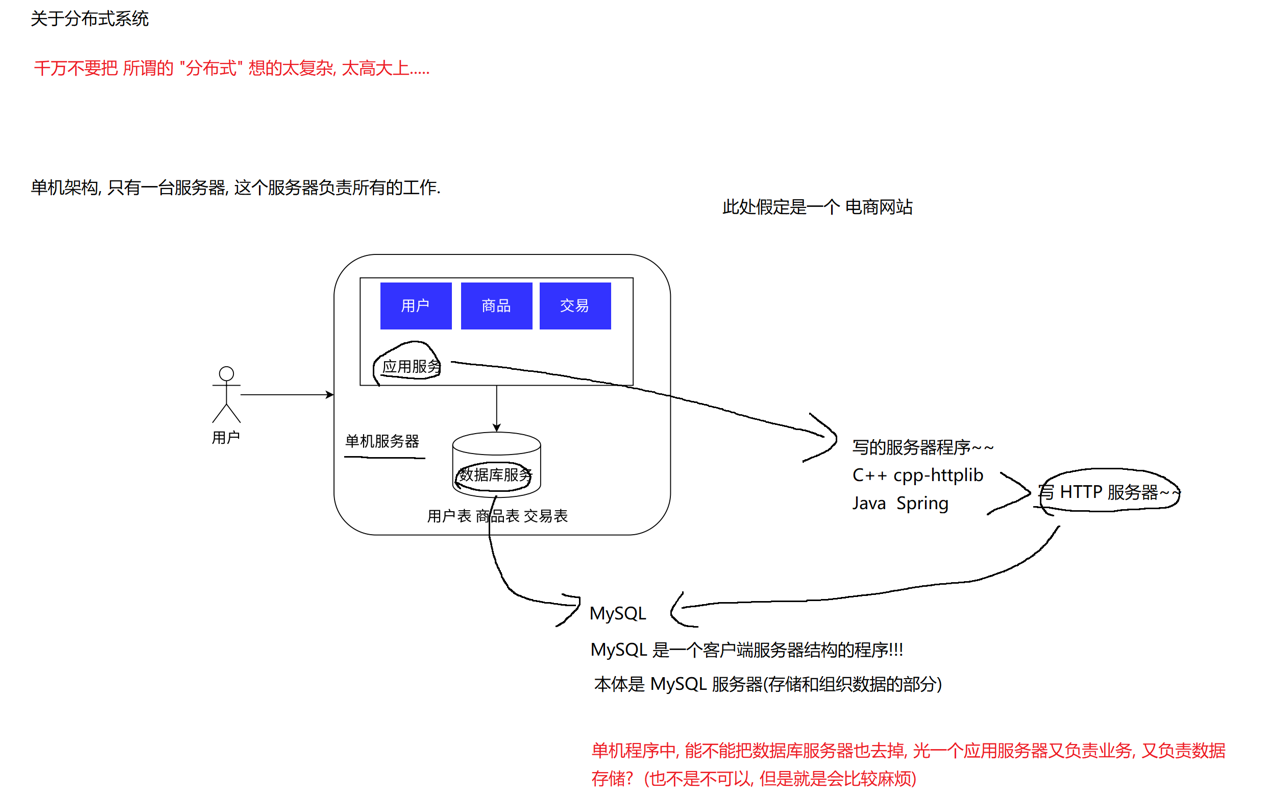


单机架构:适合请求量小,数据量小的情况,一份硬件资源给数据库和应用服务两个用
要理解分布式架构,需要先明确其核心目标:解决单机架构的瓶颈(性能、容量、可用性),通过 "多机器协同" 支撑高并发(如百万用户同时访问)、大数据(如 TB 级用户数据)、高可用(如机器故障不影响服务)的场景。
分布式架构中,"应用服务器" 和 "数据存储" 的关系是 **"完全拆分、独立集群、网络协同"**------应用服务器集群专注于业务逻辑,通过横向扩展(加机器)应对高并发;数据层(分布式存储集群)专注于数据管理,通过 "分片 + 冗余" 应对大数据和高可用。这种架构完全解决了单机架构的瓶颈,但代价是引入了更复杂的设计(如分布式事务、故障转移),适合需要支撑大规模业务的场景(如我们日常使用的电商 APP、社交软件、在线支付系统)。
1.21应用服务和数据库服务分离
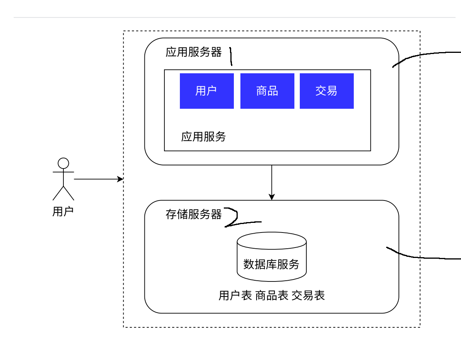
之前这里是在同一台服务器,即单机程序
现在应用服务器和存储服务器分离,应用服务器里可能包含很多的业务逻辑,比较消耗cpu和内存
对于数据库服务器需要更大的磁盘空间,更快的数据访问速度
对此我们可以对服务器进行不同的配置,达到更高的性价比
1.22引入更多的应用服务器节点并且加入负载均衡
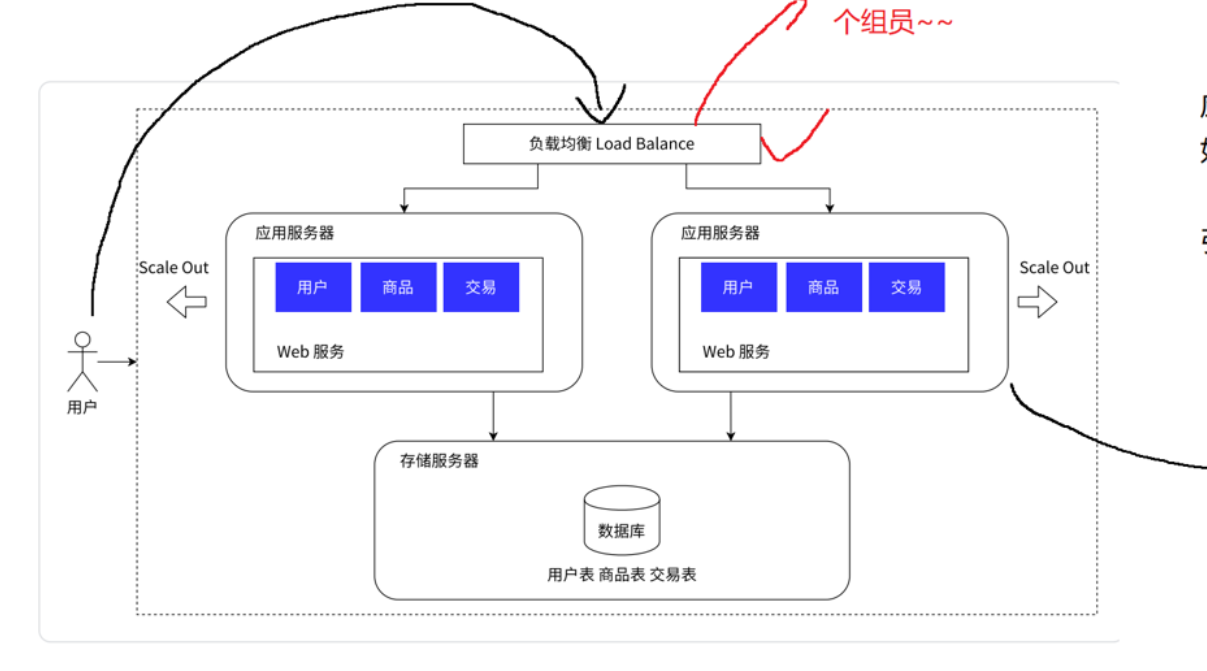
如果应用服务器比较吃cpu和内存,硬件资源可能就会被吃没,这时候就需要引入更多的应用服务器解决上诉问题,注意这里不是两台服务器,实际上可能更多
通过负载均衡来分担请求量,比如原先可能一台需要承接1w的请求,但现在只需要5q,这就有点像"多线程",对于负载均衡来说,他就是一个单独的服务器,它有很多的具体的算法
此时又有人提出:那负载均衡器不也承受了大量的请求吗?他是否能扛得住???
负载均衡器:对于请求量的承担能力,远超过应用服务器的,因为应用服务器是处理请求,但负载均衡器是分配请求,两个的任务不一样,请求处理/业务处理的消耗的资源多,请求分配只要分配到某台应用服务器就行,但是也可能会出现请求量达到负载均衡器都扛不住,此时就需要引入更多的负载均衡器
增加应用服务器,确实能够处理更改的请求量,但是存储服务器承担的请求量也变多了
解决方案:开源+节流
1.23数据库的读写分离
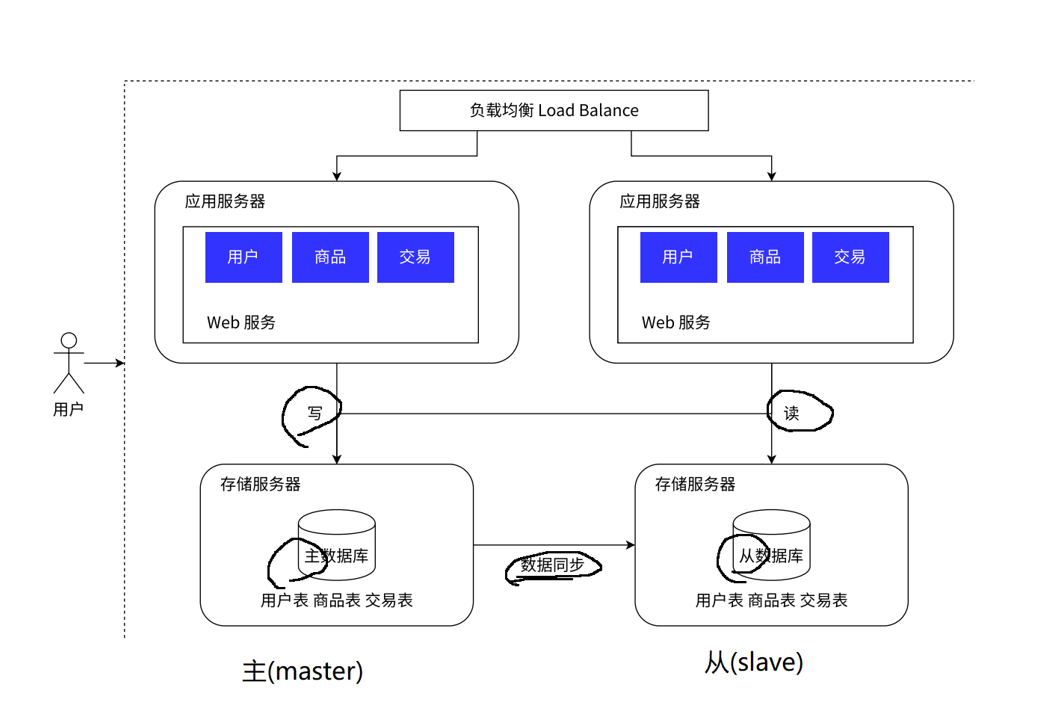
实际的应用场景中,读的频率是远比写要高的
主服务器一般是一个,从服务器可以有多个,同时从数据库通过负载均衡的方式,让应用服务器进行访问
但是数据库有个天然的问题,就是响应速度慢
解决方案:把数据区分"冷热",热点数据放到缓存中,缓存访问速度往往比数据库快很多
1.24引入缓存,冷热数据分离
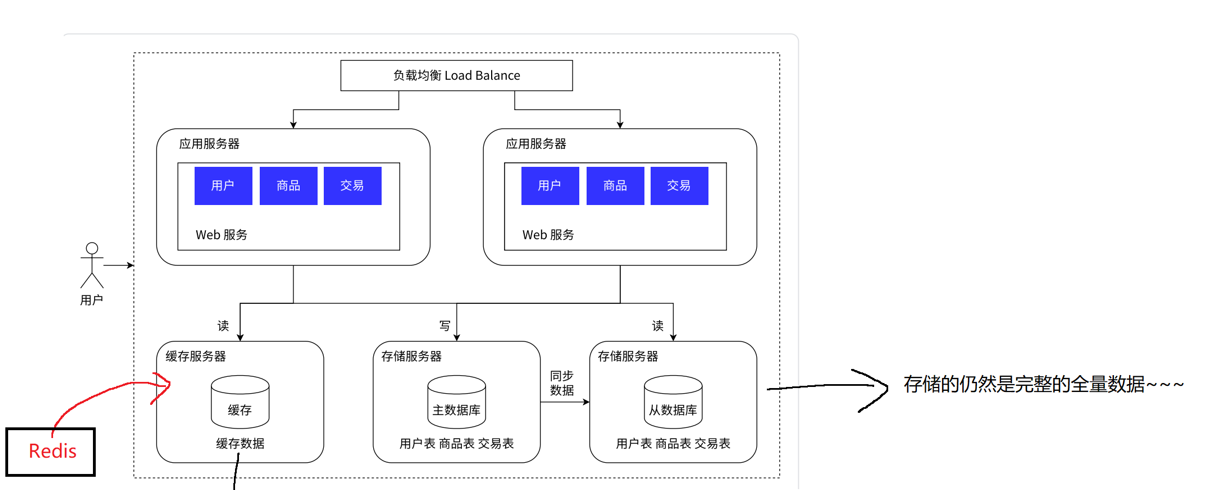
此时主从数据库还是存储的完整的全量数据
缓存要想快,就注定了小,不能存储大量的数据
只是将一小部分的热点数据放到缓存中
有相应的解决方案,就会有相应的问题出现:比如数据库之间要有同步机制,如果写成功了,缓存失败了呢?如果缓存成功了,写失败了呢?(后续学习Redis会讲解)
如果数据量巨大?服务器能存储的空间又是有限的,比如几十个TB,但是对于现在流行的短视频来说是一台主机存不下的,此时就需要多台主机,并且引入分库分表
1.25引入分库分表,数据库能够进一步扩展存储空间
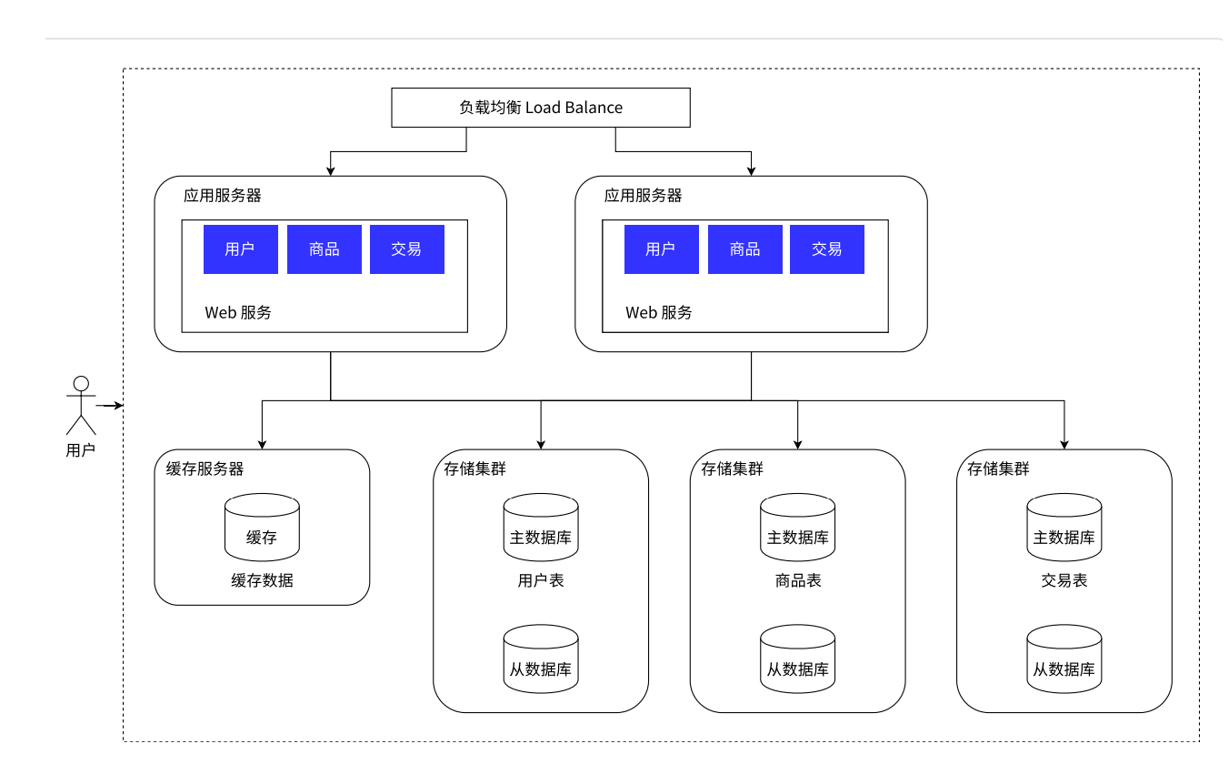 引入存储服务器之后我们能够存储更多的数据量,针对数据库还可以进行拆分(分库分表)
引入存储服务器之后我们能够存储更多的数据量,针对数据库还可以进行拆分(分库分表)
每个数据库服务器存储一个或者一部分数据库,如果某个表特别大,大到一台主机存不下,还需要针对表进行拆分,具体分库分表如何实践?还是要结合实际的业务场景来展开的
1.26引入微服务,从业务上进一步拆分应用服务器
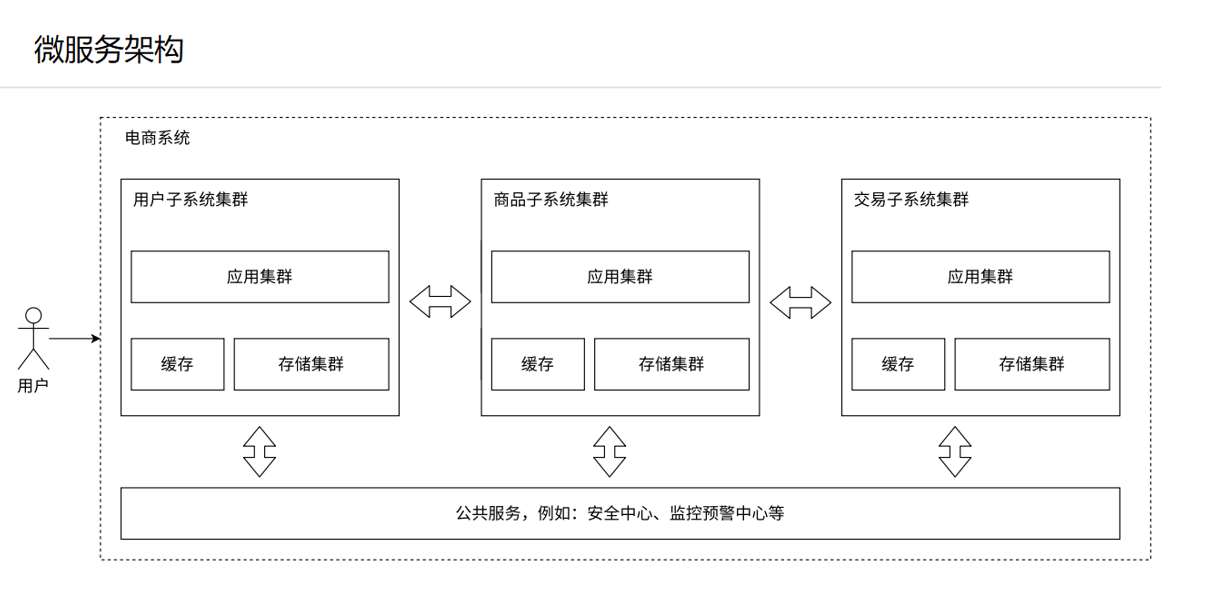
对于之前的服务器,一个应用服务器里面可能有很多的业务,就会导致代码越来越多,越来越复杂,为了方便代码的维护,需要将复杂的服务器进行拆分成更多、功能更单一、但是更小的服务器,这就叫微服务-----服务器的种类和数量就增加了
这样的拆分其实有利于人的管理,不同组别的人,只要处理好某个功能就行,这样便于代码的维护

对于之前,我们的监控中心可能比较小,但是如果分布式的规模巨大,维护成本也上来了,监控中心必然也上来

至此,我们简单的了解了整个分布式系统,简单到复杂,如何一步步承载更高的并发量,后续将讲解Redis缓存部分如何处理的