在数据分析工作中,Excel 的计算统计类函数是实现数据量化分析、挖掘数据价值的核心工具。这类函数能够快速完成数据求和、计数、极值查找、排名、平均值计算等关键统计任务,帮助我们从海量数据中提炼关键信息,为决策提供数据支撑。
无论是日常工作中的销售业绩汇总、学生成绩统计,还是复杂的多条件数据筛选分析,掌握计算统计类函数都能大幅提升数据分析效率,避免手动计算的繁琐与误差。以下将详细介绍 16个核心计算统计类函数。
一、先明确:计算统计类函数解决什么问题?
在数据分析场景中,我们常面临以下需求,而计算统计类函数正是这些需求的 高效解决方案:
数据汇总、条件筛选统计、极值与排名、数据分布分析、随机数据生成,接下来的函数将针对性解决这些问题,助力快速完成数据统计分析。
二、16个核心计算统计类函数
1. SUM:基础数据求和
作用:对单个值、单元格引用或单元格区域中的数值进行求和,是 Excel 中最基础的汇总函数,适用于所有需要累加的场景。
语法:=SUM(数值1/单元格1/区域1, 数值2/单元格2/区域2, ...)(最多可包含 255 个参数)
实战场景:统计某店铺 1-6 月的总销售额。
已知 A 列是月份,B 列是对应销售额。
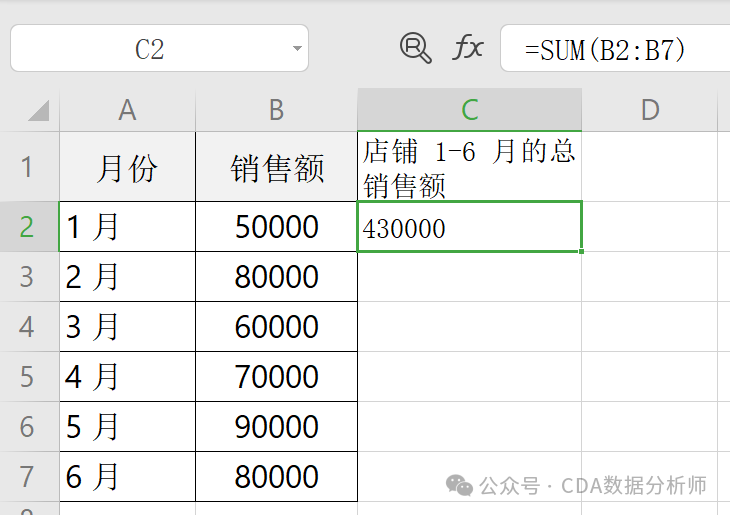
操作:在C2单元格输入 =SUM(B1:B6),按下回车后。
注意事项:
SUM 函数仅对数值型数据求和,若区域中包含文本,比如未统计,会忽略该单元格;
若需对不连续区域求和,可输入 =SUM(B1,B3,B5:B6)(用英文逗号分隔不同区域 / 单元格)。
2. SUMIF:单条件数据求和
作用:对满足指定单个条件的单元格区域进行求和,适用于按一个规则筛选后汇总的场景。
语法:=SUMIF(条件判断区域, 条件, 需要求和的区域)
注:如果条件判断区域与需要求和的区域一致,可省略第三个参数
实战场景:统计某产品的总销售额。
已知 A 列是产品名称,B 列是对应销售额。
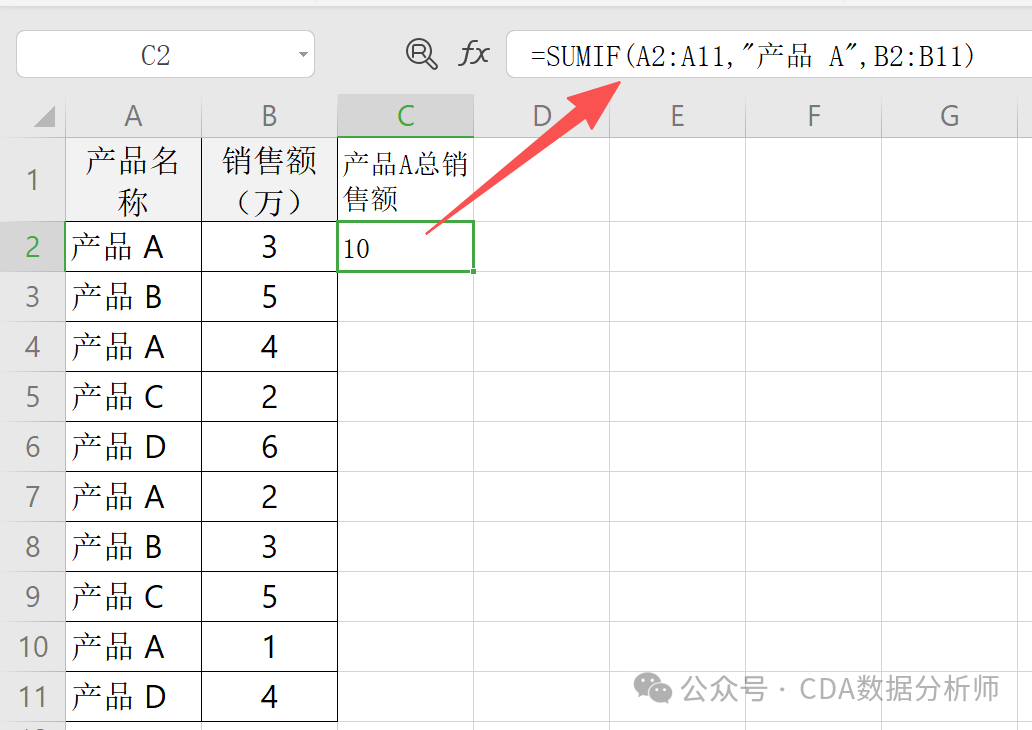
操作:在 C2单元格输入 =SUMIF(A1:A10, "产品A", B1:B10)。
注意事项:
条件需用英文引号包裹,若条件是大于 / 小于某个值,需写成 ">10000",比如统计销售额超 1 万的总和:=SUMIF(B1:B10, ">10000");
支持通配符:* 代表任意多个字符,? 代表单个字符。例如统计产品开头的所有产品销售额:=SUMIF(A1:A10, "产品*", B1:B10)。
3. SUMIFS:多条件数据求和
作用:对同时满足多个条件的单元格区域进行求和,是 SUMIF 的升级版本,适用于复杂的多规则筛选汇总场景。
语法:=SUMIFS(需要求和的区域, 条件1判断区域, 条件1, 条件2判断区域, 条件2, ...)
(注:参数顺序固定,先写 "求和区域",再依次写 "条件区域 + 条件")
实战场景:统计产品 A且 销售额超过 3 万的订单总金额。
已知 A 列是产品名称,B 列是销售额。
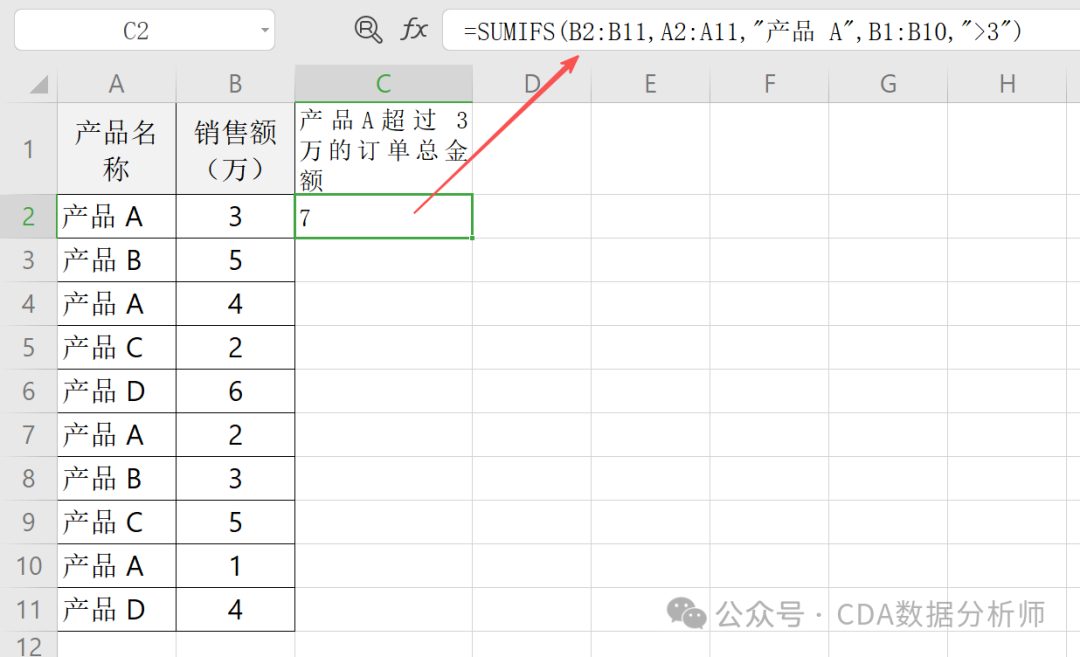
操作:在C2单元格输入=SUMIFS(B2:B11,A2:A11,"产品 A",B1:B10,">3")。
注意事项:
多个条件是同时满足的关系 逻辑与,若需满足任一条件,需用两个 SUMIF 相加,比如 =SUMIF(...) + SUMIF(...);
条件区域与求和区域的 行数 / 列数必须一致,否则会返回错误值。
4. SUMPRODUCT:多列数据乘积求和
作用:先对多个对应区域的单元格进行乘积运算,再将所有乘积结果求和,特别适用于 数量 × 单价 = 总价,销量 × 提成比例 = 提成金额等场景。
语法:=SUMPRODUCT(区域1, 区域2, 区域3, ...)
实战场景:计算某店铺所有商品的 总销售额。
已知 A 列是商品名称,B 列是销量,C 列是单价。
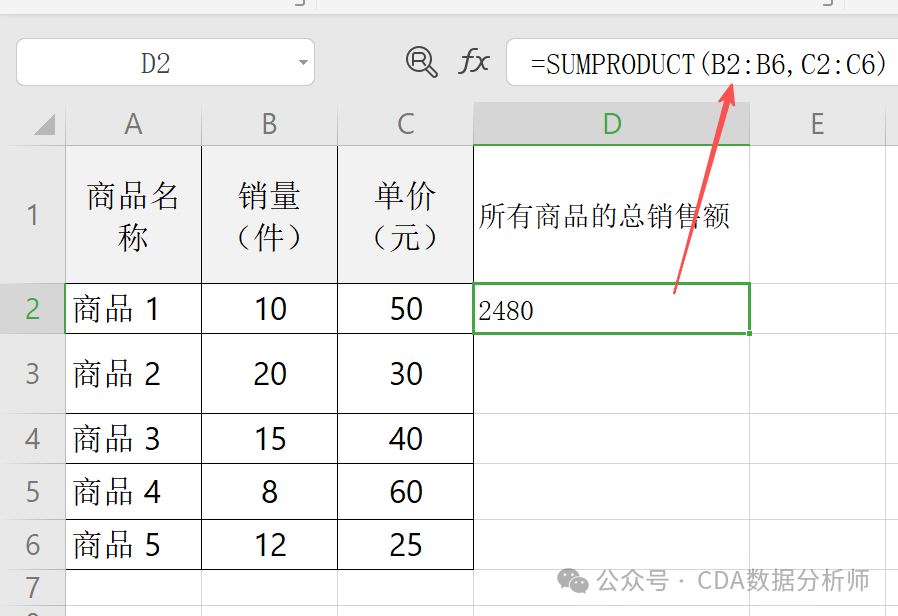
操作:在 D2 单元格输入=SUMPRODUCT(B1:B5, C1:C5),计算过程为10×50 + 20×30 + 15×40 + 8×60 + 12×25。
注意事项:
区域中若包含文本,会被当作0处理,导致结果偏小,需确保区域内均为数值;
可结合条件使用,例如统计销量> 10 件 的商品总销售额:=SUMPRODUCT((B1:B5>10)*B1:B5*C1:C5)。
5. COUNT:基础数据计数
作用:统计指定区域内数值型数据的单元格个数,不包含文本、空白单元格或逻辑值TRUE/FALSE,适用于统计有效数值数量的场景。
语法:=COUNT(单元格1/区域1, 单元格2/区域2, ...)
实战场景:统计某班级已提交数学作业的人数。
已知 A 列是学生姓名,B 列是作业提交情况。
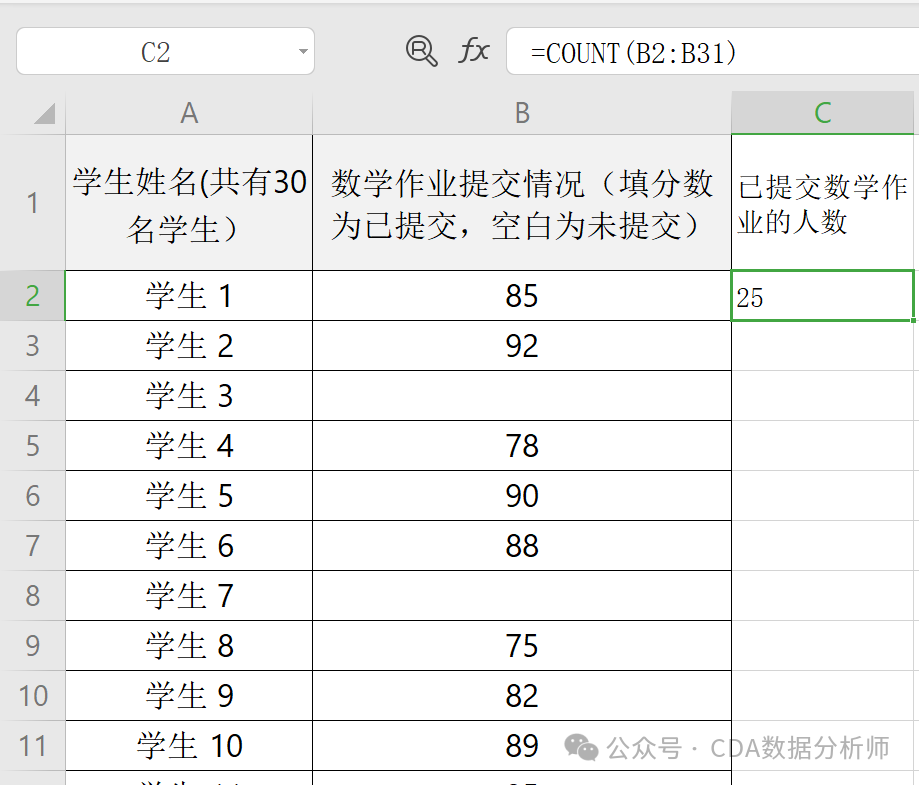
操作:在 C2 单元格输入 =COUNT(B1:B30)。
注意事项:
COUNT 仅统计 数值,若单元格内是文本,会被忽略;
若需统计 所有非空白单元格,含文本,需使用 COUNTA 函数,语法与 COUNT 一致。
6. COUNTIF:单条件数据计数
作用:统计指定区域内满足单个条件的单元格个数,适用于按一个规则筛选后计数的场景,如统计某分数段的人数、某类商品的数量。
语法:=COUNTIF(条件判断区域, 条件)
实战场景:统计某班级数学成绩80 分及以上的人数。
已知 A 列是学生姓名,B 列是数学成绩。
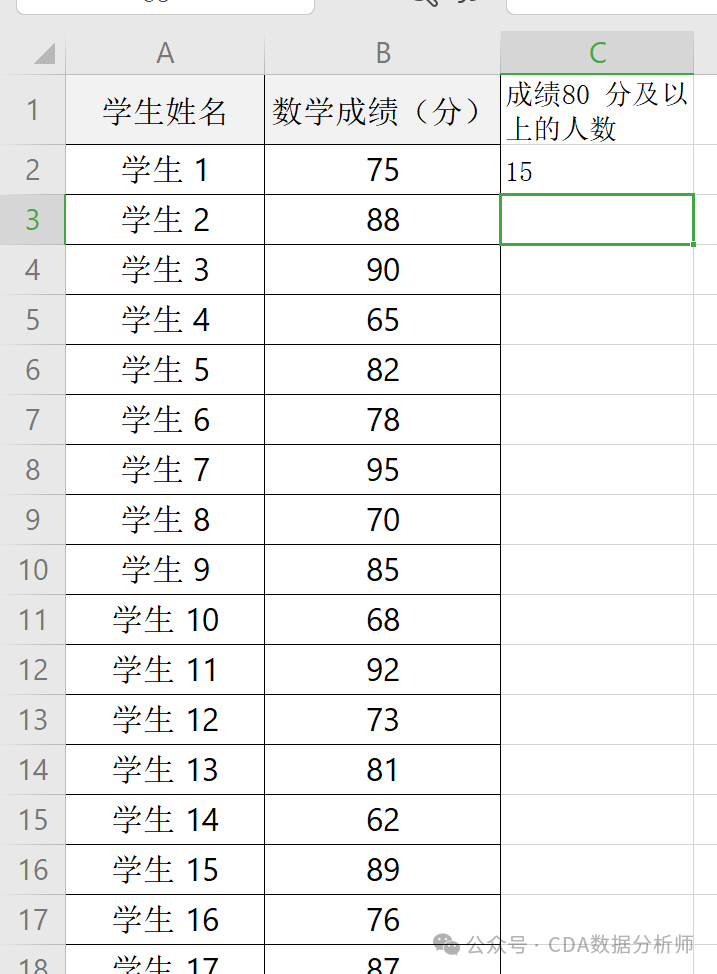
操作:在 C2单元格输入=COUNTIF(B1:B30,">=80")。
注意事项:
条件写法与 SUMIF 一致,支持文本匹配和通配符;
若条件是等于某个数值,可省略引号,比如=COUNTIF(B1:B30, 80) 统计成绩恰好为 80 分的人数。
7. COUNTIFS:多条件数据计数
作用:统计指定区域内同时满足多个条件的单元格个数,是 COUNTIF 的升级版本,适用于多规则筛选计数场景。
语法:=COUNTIFS(条件1判断区域, 条件1, 条件2判断区域, 条件2, ...)
实战场景:统计某班级数学成绩 80 分及以上且 语文成绩 75 分及以上的人数。
已知 A 列是学生姓名,B 列是数学成绩,C 列是语文成绩。
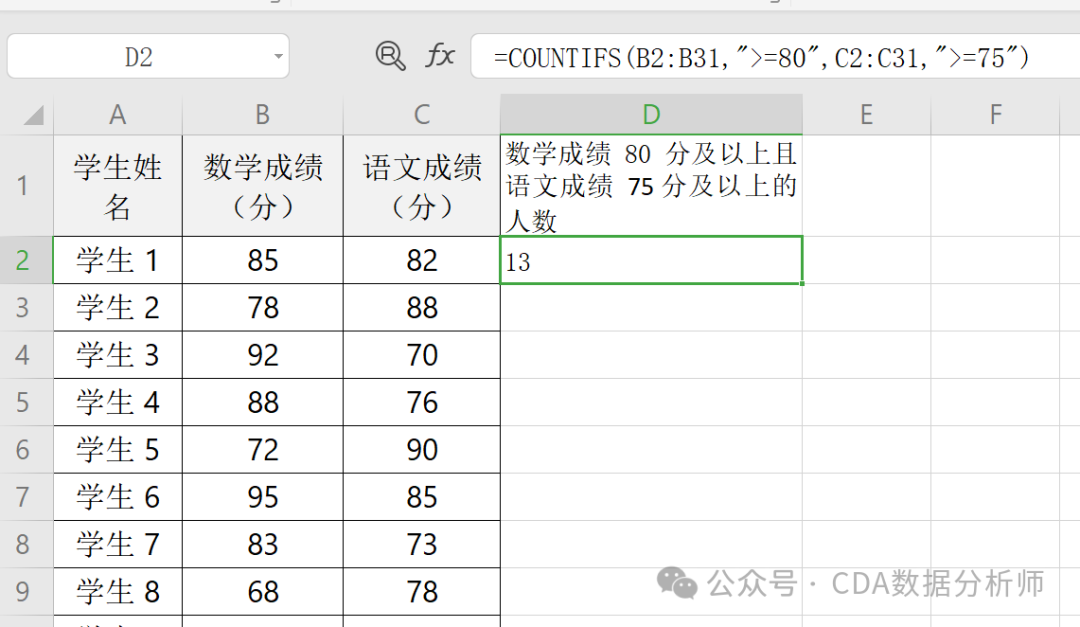
操作:在 D2单元格输入 =COUNTIFS(B1:B30, ">=80", C1:C30, ">=75")。
注意事项:
多个条件是逻辑与关系,若需逻辑或关系,需用两个 COUNTIF 相加减去重复计数,比如 =COUNTIF(...) + COUNTIF(...) - COUNTIFS(...);
条件区域可以不同,例如统计部门为销售部且工资> 8000的人数:=COUNTIFS(A1:A100, "销售部", B1:B100, ">8000")。
8. MAX:查找数据最大值
作用:从指定区域或数值中找出最大的数值,适用于快速定位极值,如找出最高销售额、最高分、最大订单量等。
语法:=MAX(数值1/单元格1/区域1, 数值2/单元格2/区域2, ...)
实战场景:找出某店铺 1-6 月销售额中的最高值。
已知 A 列是月份,B 列是销售额。
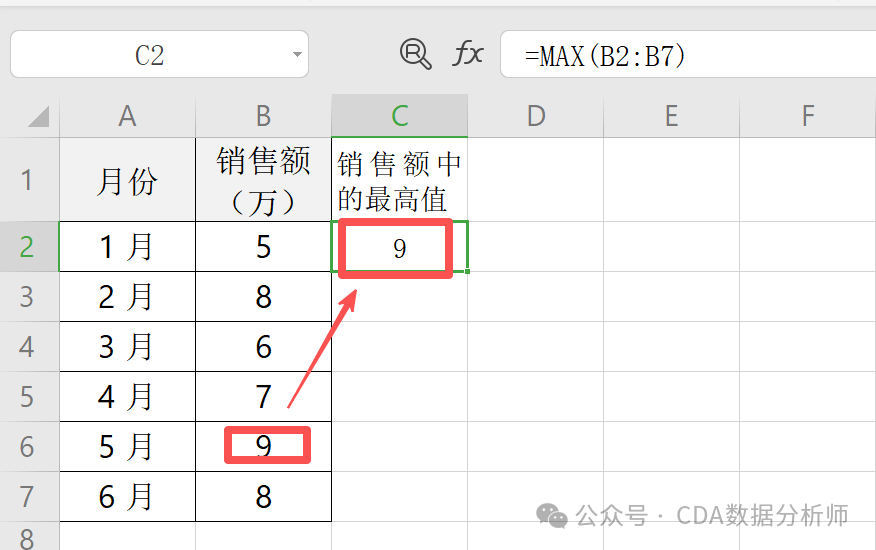
操作:在 C2 单元格输入 =MAX(B1:B6)。
注意事项:
MAX 函数忽略文本和空白单元格,若区域中包含#DIV/0!等错误值,会直接返回错误;
若需找出文本型数值,比如单元格格式为文本的8000的最大值,需先将文本转为数值,否则MAX 会忽略该值。
9. MIN:查找数据最小值
作用:从指定区域或数值中找出最小的数值,与 MAX 功能相反,适用于定位最低值,如最低销售额、最低分、最小库存等。
语法:=MIN(数值1/单元格1/区域1, 数值2/单元格2/区域2, ...)
实战场景:找出某店铺 1-6 月销售额中的最低值。
已知 A 列是月份,B 列是销售额。
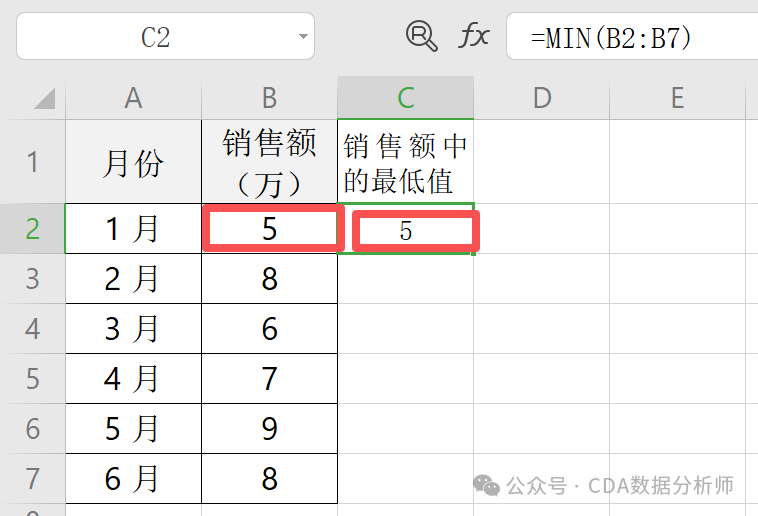
操作:在 C2 单元格输入 =MIN(B1:B6)。
注意事项:
与 MAX 一致,忽略文本和空白单元格,若存在错误值则返回错误;
若需排除0 值找最小值,可结合 IF 函数:=MIN(IF(B1:B100>0, B1:B100)),输入后按 Ctrl+Shift+Enter 确认数组公式。
10. RANK:数据排名
作用:返回指定数值在指定区域中的排名,默认从大到小排序,若存在相同数值,会返回相同排名,适用于业绩排名、成绩排名等场景。
语法:=RANK(需要排名的数值/单元格, 排名参考区域, 排名方式)
(注:排名方式为可选参数,0 或省略代表降序排名,1 代表升序排名)
实战场景:对某店铺各商品的销售额进行降序排名。
已知 A 列是商品名称,B 列是销售额。
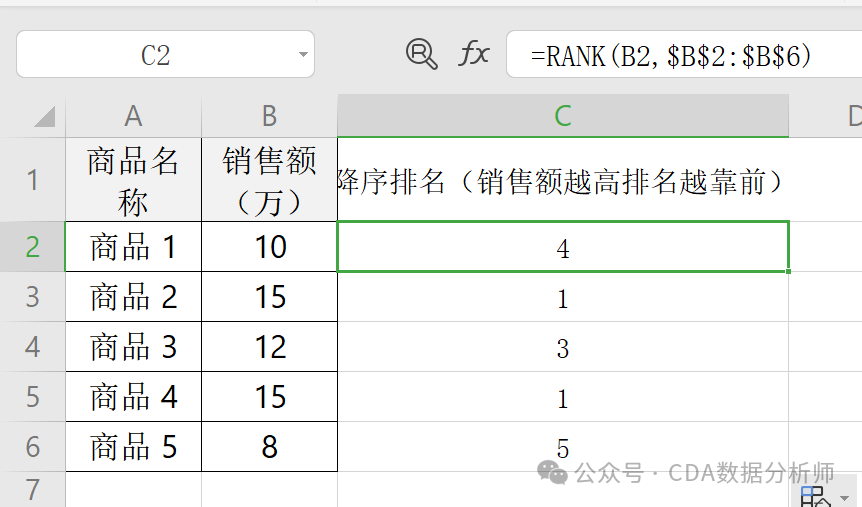
操作:在 C2单元格输入 =RANK(B1, B1:B5)。
注意事项:
排名参考区域需锁定,否则下拉时区域会偏移,导致排名错误;
若需无重复排名,需使用 RANK.EQ 函数结合 COUNTIF:=RANK.EQ(B1, B1:B5) + COUNTIF(B1:B1, B1) - 1。
11. RAND:生成 0-1 随机小数
作用:无需参数,随机生成一个大于等于 0 且小于 1的小数,每次刷新表格时会重新生成新的随机数,适用于生成随机样本、模拟概率等场景。
语法:=RAND()
实战场景:为某班级 30 名学生生成 随机抽奖编号。
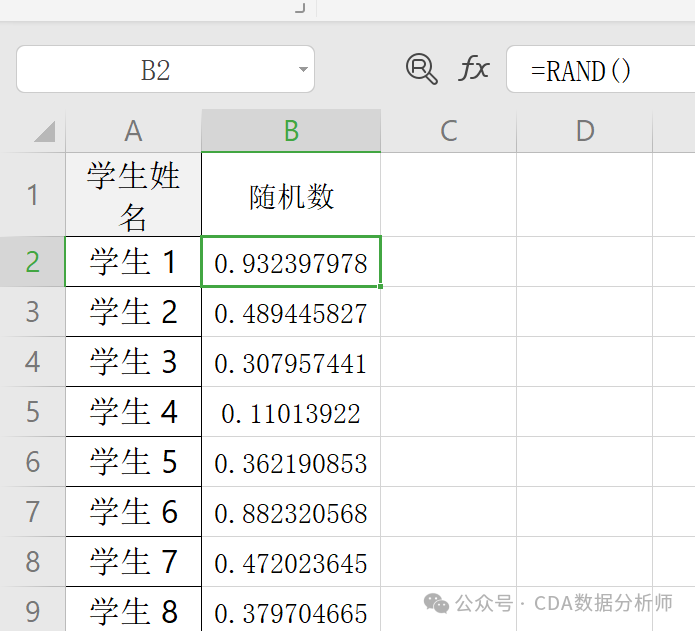
操作:在 B1 单元格输入 =RAND()。
注意事项:
RAND 生成的是易变随机数,刷新表格会改变结果,若需固定随机数,可复制结果后 选择性粘贴→数值;
若需生成指定范围的随机小数,比如 1-10 之间,可使用 =RAND()*(10-1)+1,公式:RAND()*(最大值-最小值)+最小值。
12. RANDBETWEEN:生成指定范围随机整数
作用:生成介于两个指定整数之间的随机整数,解决 RAND 只能生成 0-1 小数的局限,适用于生成随机 ID、随机分配组别等场景。
语法:=RANDBETWEEN(最小值, 最大值)
实战场景:将某班级 30 名学生随机分配到 1-5 组。
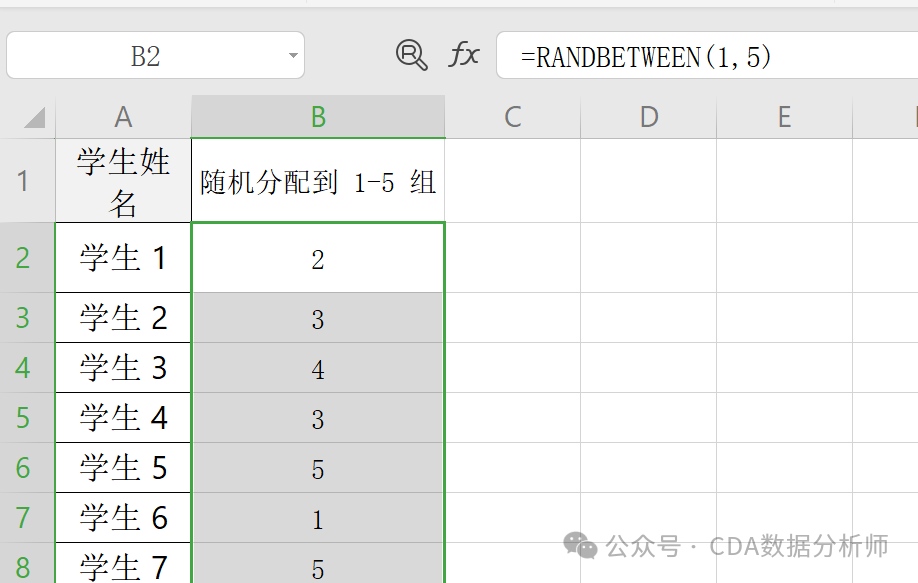
操作:在 B2 单元格输入 =RANDBETWEEN(1,5)。
注意事项:
最小值必须小于等于最大值,否则会返回错误值;
与 RAND 一致,随机数会随表格刷新变化,需固定时需选择性粘贴→数值;
若需生成不重复的随机整数,需结合 INDEX 和 SMALL 函数,公式较复杂,可借助 数据→排序→随机排序功能简化操作。
13. AVERAGE:计算数据平均值
作用:计算指定区域的数值的算术,适用于统计平均成绩、平均销售额、平均客单价等场景。
语法:=AVERAGE(数值1/单元格1/区域1, 数值2/单元格2/区域2, ...)
实战场景:计算某班级 30 名学生的数学平均成绩。
已知 A 列是学生姓名,B 列是数学成绩。
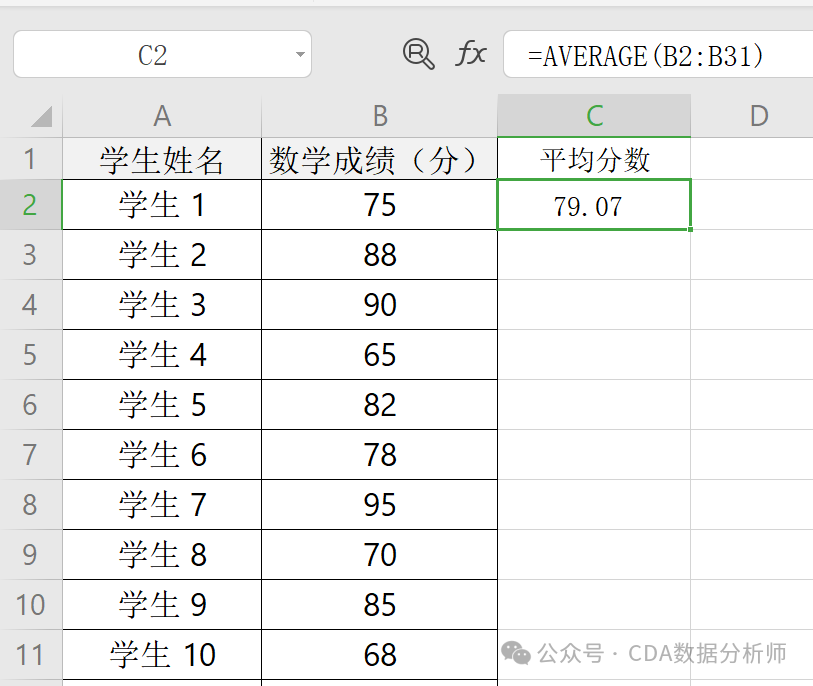
操作:在 B31 单元格输入 =AVERAGE(B1:B30)。
注意事项:
AVERAGE 忽略文本和空白单元格,若需 包含空白单元格会视为 0计算平均值,需使用 AVERAGEA 函数;
若需排除极值计算平均,比如去掉最高分和最低分,可结合 SUM、MAX、MIN 和 COUNT:=(SUM(B1:B30)-MAX(B1:B30)-MIN(B1:B30))/(COUNT(B1:B30)-2)。
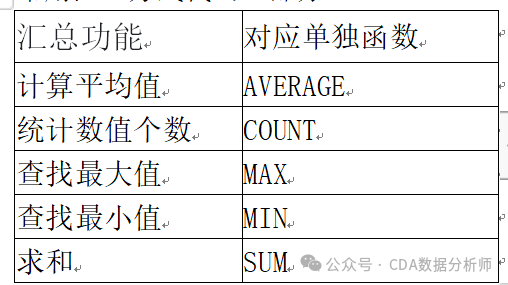
14. SUBTOTAL:多功能汇总函数
作用:一个函数实现求和、计数、平均值、最大值、最小值等 11 种汇总功能,并且能自动忽略隐藏行的数据,适用于需要灵活切换汇总方式或处理筛选后数据的场景。
语法:=SUBTOTAL(汇总方式代码, 区域1, 区域2, ...)
常用汇总方式代码(部分):
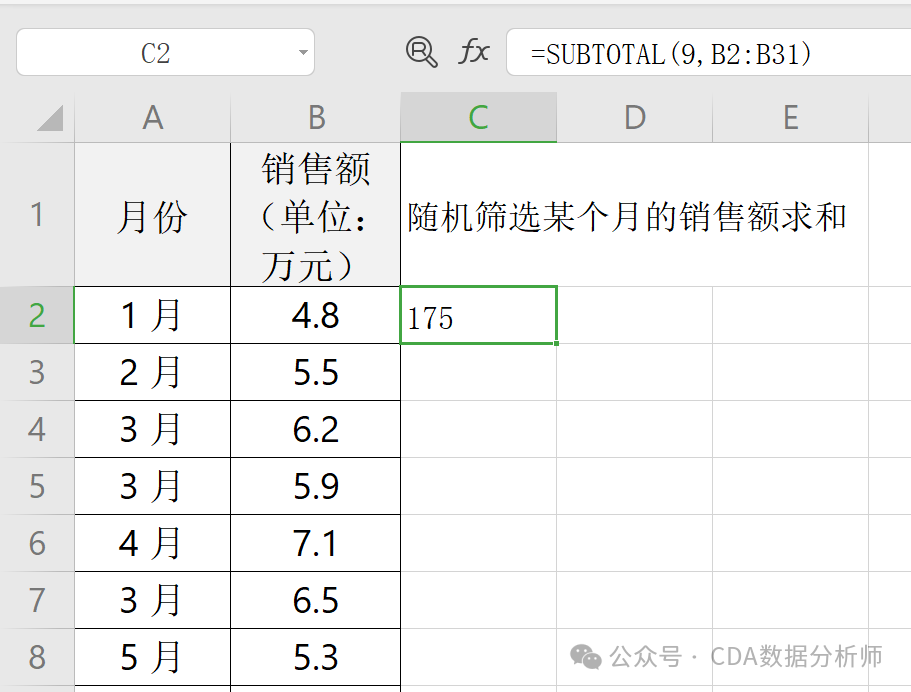
实战场景:统计某店铺筛选后的销售额总和与平均值。
已知 A 列是月份,B 列是销售额。
求和:在C2单元格输入 =SUBTOTAL(9, B2:B11);
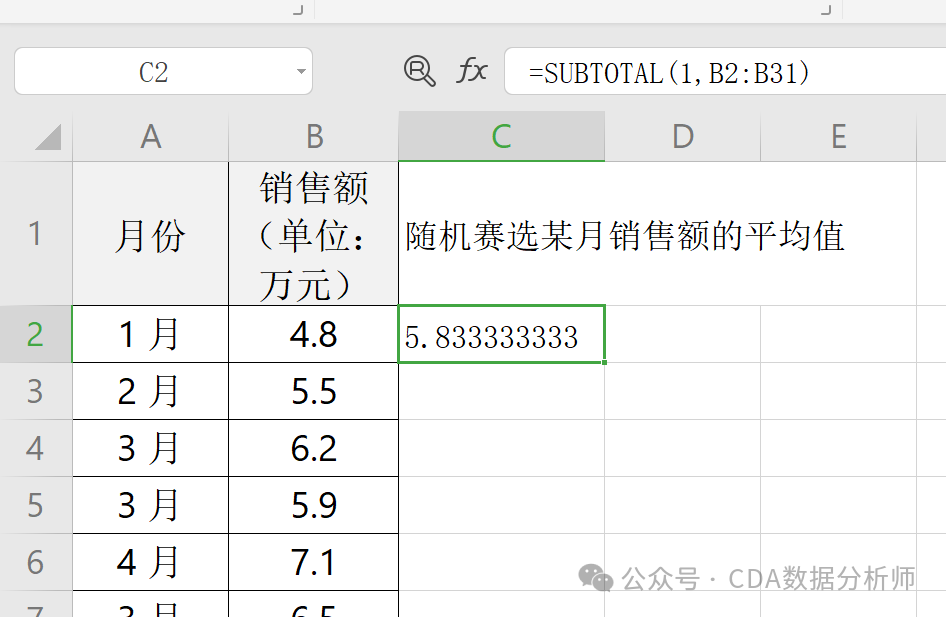
求平均:在 C2 单元格输入
=SUBTOTAL(1, B1:B100)。
注意事项:
代码1-11包含隐藏行数据,101-111忽略隐藏行数据;
若区域中包含其他 SUBTOTAL 函数的结果,会自动忽略该结果,避免重复汇总。
15. INT:数值向下取整
作用:将数值向下取整为最接近的整数,即不大于该数值的最大整数,适用于需要舍弃小数部分的场景,如计算可购买商品的整数数量、员工实际出勤天数。
语法:=INT(数值/单元格)
实战场景:计算某客户用 100 元购买单价 15 元的商品,最多可购买的整数数量。
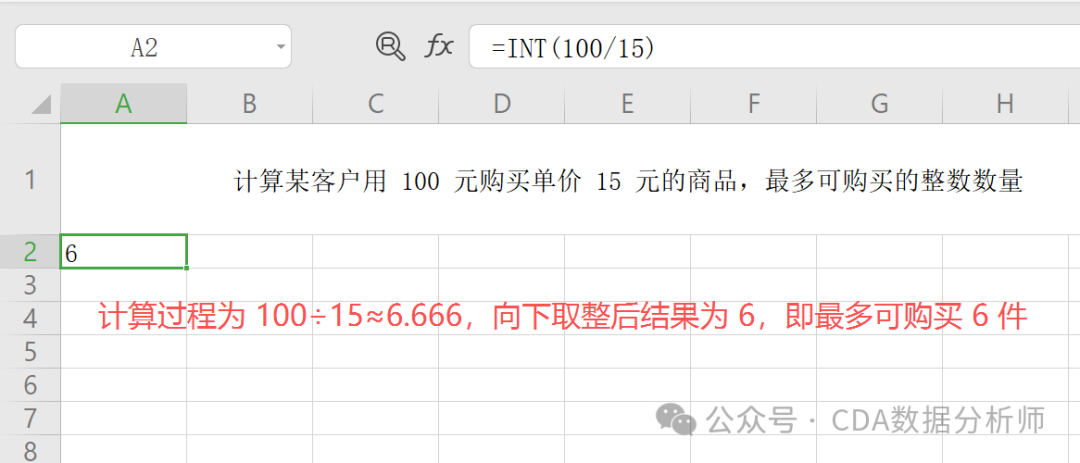
操作:在 A2 单元格输入 =INT(100/15)。
注意事项:
对负数取整时,结果仍向下,比如 =INT(-6.6) 结果为 -7,而非 -6;
若需 四舍五入取整,需使用 ROUND 函数;若需 向上取整,无论小数部分是否大于 0.5,需使用 CEILING 函数。
作用:将数值 按指定小数位数进行四舍五入,适用于需要保留固定小数位数的场景,如金额保留 2 位小数、百分比保留 1 位小数。
语法:=ROUND(需要四舍五入的数值/单元格, 保留的小数位数)
(注:保留小数位数为正数时保留对应小数位,为 0 时取整,为负数时对整数部分四舍五入)
实战场景:将某商品的单价 39.678 元保留 2 位小数,销量 123 件按十位取整。
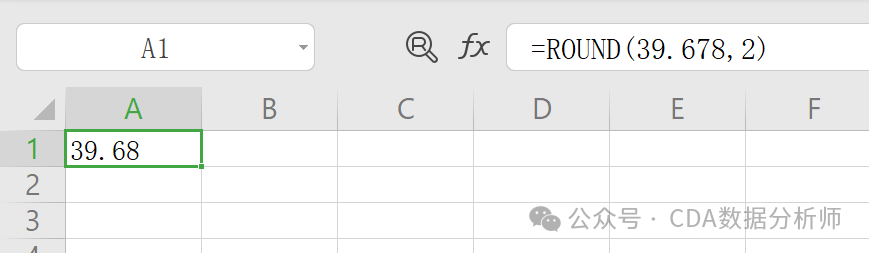
保留 2 位小数:输入 =ROUND(39.678, 2);
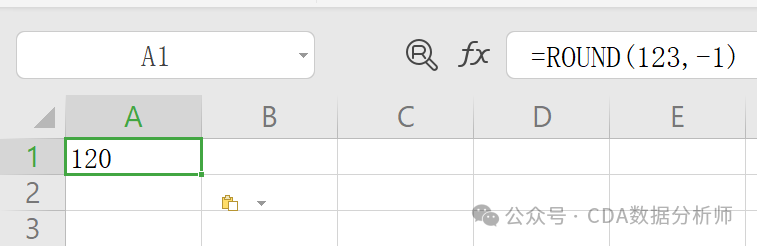
按十位取整:输入 =ROUND(123, -1)。
注意事项:
若需四舍五入到整数,保留小数位数填 0,比如 =ROUND(15.6, 0) 结果为16;
若需向上四舍五入到指定小数位,比如无论第三位小数是否大于 5,均进 1,需使用 ROUNDUP 函数;若需向下四舍五入,需使用 ROUNDDOWN 函数。
Excel是最常用的数据处理工具,也是CDA数据分析师一级的重要考点,如果想提升自己的Excel水平,可以考过CDA数据分析师一级,这里面有很多模拟题,进行训练和提高。
CDA数据分析师证书,与CPA注会、CFA特许金融师并驾齐驱,其权威性与实用性不言而喻。在互联网行业中,应用数据分析是非常适配的,该行业数据量庞大、发展快。CDA数据分析师在互联网行业的数据岗中认可度非常高,一般都要求考过CDA数据分析师二级,CDA二级中包含了模型搭建的详细内容,对于数据岗的工作来说特别有帮助。
CDA数据分析师之所以备受青睐,离不开它广泛的企业认可度。众多知名企业在招聘数据分析师时,都会明确标注CDA持证人优先考虑。像是中国联通、德勤、苏宁等大型企业,更是将CDA持证人列为重点招募对象,甚至为员工的CDA考试提供补贴,鼓励他们提升数据处理与分析能力。这足以证明,CDA证书在求职过程中,能为你增添强大的竞争力,使你从众多求职者中脱颖而出。
CDA数据分析师在银行业的数据岗中认可度非常高,一般都要求考过CDA数据分析师二级,CDA二级中包含了模型搭建的详细内容,对于数据岗的工作来说特别有帮助,一些企业可以给报销考试费。