在企业数据架构逐步走向实时化与一体化的过程中,如何高效处理"大量历史 + 少量新增"的业务数据,已成为建设统一数仓与实时数仓时绕不开的关键挑战。
传统全量刷新方式在面对亿级历史数据时,往往面临刷新延迟高、计算成本大、链路复杂等问题。为了解决这些痛点,业界逐渐形成了一种新的数据处理范式------Dynamic Table(动态表),它通过声明式语法自动维护物化结果,并支持高效的增量刷新能力。
阿里云 Hologres 作为高性能实时数仓引擎,原生提供了 Dynamic Table,并基于有状态增量计算模型,在多表关联、聚合等复杂场景下展现出显著性能优势。本文将深入解析 Hologres Dynamic Table 的技术原理与实践价值。
为什么需要增量刷新能力?

典型业务场景
在电商、互联网、金融等行业,以下场景极为常见:
实时运营分析
-
订单、支付、退款等多源数据,按用户、商品、活动等维度进行关联与聚合,形成实时运营看板;
-
运营与业务团队希望以分钟级、甚至更高频率刷新核心指标。
用户与商品特征构建
-
将用户信息、行为数据、订单数据、商品信息、支付信息等多张表进行 Join,生成统一的特征宽表;
-
这些宽表通常是推荐、风控、画像等应用的输入,需要稳定、快速地更新。
资金与交易监控
- 交易流水、账户信息、风控结果等数据源不断产生新的记录;需要以较短的刷新间隔计算聚合指标或风控特征。
这些场景的共同特点是:
历史数据规模庞大(亿级),但每次新增或变更的数据量很小(通常 <1%)。
传统数据加工的局限
在缺少增量引擎的情况下,常见做法是:
-
使用一条或多条 SQL 定义目标宽表或汇总表;
-
定时执行全量计算(如 INSERT OVERWRITE、CTAS),每次从基表完整扫描数据、执行多表 Join、再进行聚合;
-
通过调度系统编排上游任务和下游任务之间的依赖。
这种模式存在若干明显不足:
-
刷新时延受限: 数据规模增大后,每次全量扫描和计算耗时较长。当业务希望从"每小时刷新"提升到"每 5 分钟刷新"时,往往需要成倍增加计算资源,也可能遇到物理资源上限。
-
计算成本较高:即使每次只有 1% 左右的数据发生变化,全量模式仍需对 100% 数据进行扫描和计算,CPU、IO 和网络资源利用效率不高。
-
链路复杂,维护成本高:为降低单任务压力,工程实践中常将复杂逻辑拆解为多层中间表,形成较长的任务链路。链路越长,依赖越多,维护难度和变更风险也随之上升。
因此,在"历史数据量大、实时数据实时产生"的场景下,引入真正高效的增量刷新机制,是提升数据时效与降低资源利用率的关键。
二、什么是 Dynamic Table?Hologres 的增量刷新如何工作?
Dynamic Table是当前一种主流的声明式数据处理架构,该架构可以自动处理并存储一个或者多个基表(Base Table)对象的数据关联、聚合结果,内置不同的数据刷新策略,业务可以根据需求设置不同的数据刷新策略,实现数据从基表对象到Dynamic Table的自动流转,满足业务统一开发、数据自动流转、处理时效性等诉求。
增量(incremental)、全量(full)是Dynamic Table的两种不同刷新方式,底层实现原理具有显著的差异:
-
全量刷新是指每次执行刷新时,都以全量的方式进行数据处理,并将基表的关联、聚合结果物化写入Dynamic Table,其技术原理类似于INSERT OVERWRITE。
-
增量刷新 模式下,每次刷新时只会读取基表中新增的数据,根据中间聚合状态和增量数据计算最终结果并更新到Dynamic Table中。相比全量刷新,增量刷新每次处理的数据量更少,效率更高,从而可以非常有效地提升刷新任务的时效性,同时降低计算资源的使用。
增量Dynamic Table的计算遵循如下计算模式:
-
增全量刷新阶段:Dynamic Table的第一次刷新会把已有的所有历史数据都进行计算,即相当于把所有历史数据都当作增量来进行计算。这一阶段一般耗时比较长。
-
增量刷新阶段:在增全量刷新完成后,以后的每次Dynamic Table刷新仅针对增量数据进行计算。理论上这些刷新应该耗时较短。
在增量 Dynamic Table 的实现上,业界存在不同的技术路径。一种常见的做法是采用无状态增量计算模型:每次刷新时,系统仅基于源表的变更数据,重新推导整个查询逻辑,而不持久化任何中间计算状态。这种方式虽然节省存储,但在面对复杂查询(如多表关联、去重聚合等)时,往往需要反复扫描大量历史数据,导致刷新效率低下,甚至在某些场景下增量计算的开销反而超过全量。
相比之下,Hologres 采用了有状态增量计算模型 :在首次全量构建 Dynamic Table 时,同步生成并持久化关键的中间状态(例如聚合结果、多表 Join 的中间产物等)。后续的增量刷新只需将新增或变更的数据与这些状态表进行高效合并,无需重复处理历史数据。这种设计以有限且可控的额外存储开销为代价,显著提升了复杂场景下的刷新性能和资源利用率,尤其适合"海量历史 + 少量增量"的典型业务负载 。 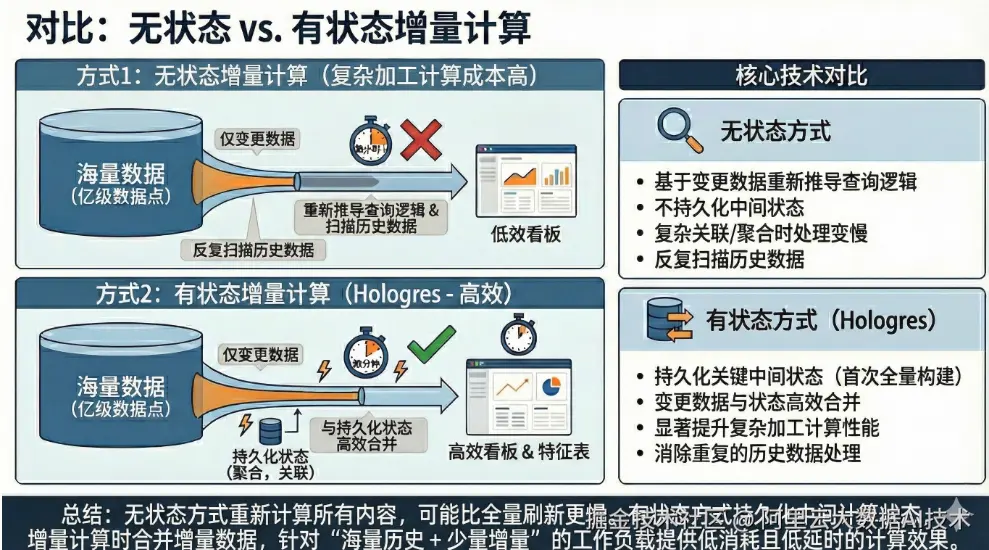
三、Hologres 增量刷新的实战优势
我们通过三个典型场景验证 Hologres 的性能表现(测试环境:Hologres 15CU Serverless,竞品采用相似规格)。
对于增量数据,本实验模拟两种场景:
-
Append only:即源表的增量数据只有新增(Insert),没有修改(update和delete)。这在日志、埋点数据表中非常常见。
-
Retraction(回撤):源表的增量数据包含Insert、Update和Delete的数据。这适用于数据库类的表。
对于Append only的源表,很多增量计算算子都可以大幅简化,状态表也可以大幅缩小。所以在性能环节,可以看到Append only源表的增量计算性能会更好。
场景 1:单表聚合(COUNT DISTINCT + SUM)
该场景使用的工作负载如下所示:

Hologres建表SQL如下:
sql
CREATE DYNAMIC TABLE DT_ORDER_DETAIL_AGG with (
auto_refresh_mode = 'incremental',
auto_refresh_enable = 'false',
freshness = '1 minutes'
)AS
SELECT
PRODUCT_ID,
COUNT(DISTINCT USER_ID) AS UV,
SUM(LINE_AMOUNT) AS SUM_LINE_AMOUNT,
MAX(QUANTITY) AS MAX_QUANTITY
FROM ORDER_DETAIL
GROUP BY PRODUCT_ID;测试结果如下表所示(完整测试SQL见附录):
| 刷新 | 源表行数 | 某国际知名产品无状态增量计算刷新耗时(s) | Hologres刷新耗时(s) | |||
|---|---|---|---|---|---|---|
| Retraction | Appendonly | Retraction | Appendonly | Retraction | Appendonly | |
| 增全量刷新 | ORDER_DETAIL: 10M | 1.5 | 1.3 | 4.6 | 3.9 | |
| 增量第一次 | 每张表 UPDATE 0.5% INSERT 0.5% | 每张表 INSERT 1.0% | 7.8 | 2.4 | 0.59 | 0.48 |
| 增量第二次 | 8.1 | 2.7 | 0.49 | 0.41 | ||
| 增量第三次 | 7.8 | 2.9 | 0.45 | 0.3 |
可以看到Hologres增全量刷新阶段较慢,但后面的每次增量刷新都很快,符合预期。
无状态增量刷新性能较差的主要原因是无状态增量执行计划变得更加复杂,包含36个计算节点,且变更数据触及了大量分区,需要从源表重新扫描计算所有的数据。在有回撤数据时,处理数据变更前后因果关系会导致计算逻辑会变得更加复杂,进一步变慢,增量计算显得没有意义。
Hologres增量刷新快的核心原因是每次增量计算都是基于上次计算生成的状态表(State),这极大的简化了增量计算逻辑。此例中Hologres中各表存储大小如下所示(源表是Retraction的情况),结果表很小,而因为min/max/count distinct这两种聚合函数与sum/count这类不同,状态表需要存储对应列的所有原始数据,所以相比结果表要大很多。
| 源表 | 结果表 | 状态表 | |
|---|---|---|---|
| 存储 | 252 MB | 1 MB | 93 MB |
场景 2:两表 Join(订单 + 明细)
两表Join是大数据处理中一种较为简单的基本场景,测试使用的具体工作负载如下图所示 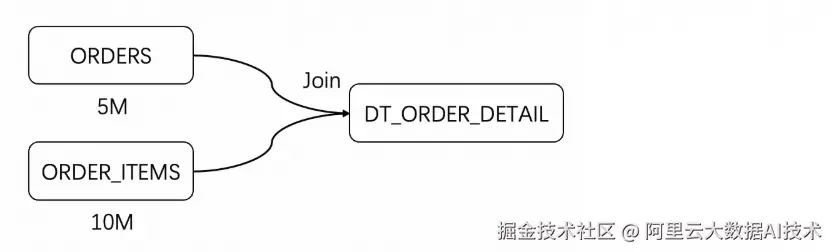
Hologres建表SQL如下:
sql
CREATE DYNAMIC TABLE DT_ORDER_DETAIL
WITH (
auto_refresh_mode = 'incremental',
auto_refresh_enable = 'false',
freshness = '1 minutes'
) AS
SELECT
o.ORDER_ID,
o.ORDER_DATE,
o.ORDER_STATUS,
oi.ORDER_ITEM_ID,
oi.PRODUCT_ID,
oi.QUANTITY,
oi.UNIT_PRICE,
oi.LINE_AMOUNT
FROM ORDERS o
JOIN ORDER_ITEMS oi
ON o.ORDER_ID = oi.ORDER_ID;测试结果如下表所示(完整测试SQL见附录),无状态增量刷新引擎在数据含有回撤的时候执行计划包含50个节点,源表大部分分区的数据被反复读取参与聚合,导致性能不佳。而数据不包含回撤(Appendonly)时,无状态增量刷新执行计划相对简单,含有35个节点,且新增数据不会触及太多分区,表现良好,体现出了增量计算的意义。
| 源表行数 | 某国际知名产品无状态增量计算(s) | Hologres刷新耗时(s) | ||||
|---|---|---|---|---|---|---|
| Retraction | Appendonly | Retraction | Appendonly | Retraction | Appendonly | |
| 增全量刷新 | ORDERS : 5M ORDER_ITEMS: 10M | 10 | 8.7 | 9.2 | 6.29 | |
| 增量第一次 | 每张表 UPDATE 0.5% INSERT 0.5% | 每张表 INSERT 1.0% | 22 | 1.1 | 2.2 | 0.68 |
| 增量第二次 | 19 | 2.2 | 1.1 | 0.50 | ||
| 增量第三次 | 22 | 1.7 | 1.9 | 0.51 |
Hologres中各表存储大小如下所示,在这种场景下状态表存了源表的部分列数据,实际存储小于源表。
| 源表 | 结果表 | 状态表 | |
|---|---|---|---|
| 存储 | 370 MB | 350 MB | 228 MB |
场景 3:五表复杂 Join(订单 + 用户 + 商品 + 支付等)
多表Join是一种相对更常见、真实的场景,测试具体使用的工作负载如下: 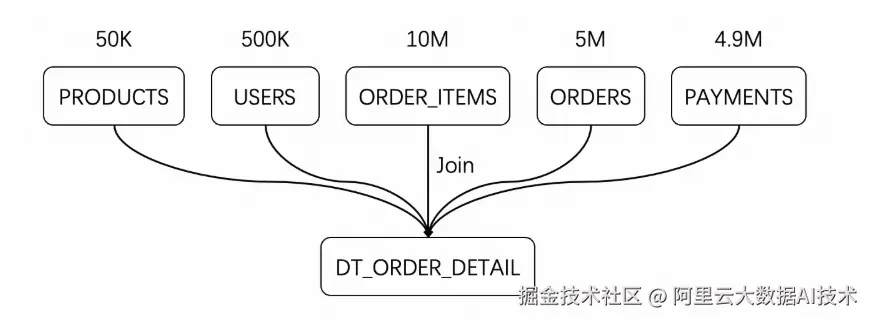
Hologres的测试脚本如下:
sql
CREATE DYNAMIC TABLE DT_ORDER_DETAIL
WITH (
auto_refresh_mode = 'incremental',
auto_refresh_enable = 'false',
freshness = '1 minutes'
) AS
SELECT
o.ORDER_ID,
o.ORDER_DATE,
o.ORDER_STATUS,
u.USER_ID,
u.USER_NAME,
u.EMAIL,
u.STATUS AS USER_STATUS,
oi.ORDER_ITEM_ID,
oi.PRODUCT_ID,
p.PRODUCT_NAME,
p.CATEGORY,
p.PRICE AS PRODUCT_PRICE,
oi.QUANTITY,
oi.UNIT_PRICE,
oi.LINE_AMOUNT,
pay.PAYMENT_ID,
pay.PAY_AMOUNT,
pay.PAY_METHOD,
pay.PAY_TIME
FROM ORDERS o
JOIN USERS u
ON o.USER_ID = u.USER_ID
JOIN ORDER_ITEMS oi
ON o.ORDER_ID = oi.ORDER_ID
JOIN PRODUCTS p
ON oi.PRODUCT_ID = p.PRODUCT_ID
LEFT JOIN PAYMENTS pay
ON o.ORDER_ID = pay.ORDER_ID;测试结果如下表所示(完整测试SQL见附录),无状态增量计算引擎无论是只包含插入还是有回撤,性能都相对较差,原因也是类似的。五表Join的场景下,增量计算的执行节点超过140个,会大量读取源表数据。
| 源表行数 | 某国际知名产品无状态增量计算(s) | Hologres刷新耗时(s) | ||||
|---|---|---|---|---|---|---|
| Retraction | Appendonly | Retraction | Appendonly | Retraction | Appendonly | |
| 增全量刷新 | ORDER_ITEMS : 10M PAYMENTS : 4.9M ORDERS : 5M PRODUCTS : 50K USERS: 500K | 23 | 23 | 30 | 22 | |
| 增量第一次 | 每张表 UPDATE 0.5% INSERT 0.5% | 每张表 INSERT 1.0% | 55 | 26 | 3.9 | 2.8 |
| 增量第二次 | 58 | 27 | 3.2 | 1.8 | ||
| 增量第三次 | 60 | 26 | 2.9 | 1.8 |
Hologres中各表存储大小如下所示,状态表会存储每一次Join的中间结果
| 源表 | 结果表 | 状态表 | |
|---|---|---|---|
| 存储 | 594 MB | 1218 MB | 1094 MB |
四、有状态增量计算:为何更高效?
基于前面的实验结果,不难看出,无状态增量计算方案适用条件其实比较苛刻,在很多场景中基于少量数据的增量计算开销甚至会超过第一次的全量计算,丧失了增量计算的意义。
而相比较之下,Hologres的有状态增量计算方案可以适用于大多数的场景,通常只需要满足增量数据较少这一个条件即可。下图以单表聚合场景(sum(value) group by key)为例,展示了有状态方案的基本原理,增量计算过程中可以从状态表中直接获取历史数据的聚合结果,而不需要基于历史表的原始数据重新计算。此外在读取状态表数据时,也进一步引入了OLAP查询中常用的runtime filter优化,在增量数据较少的场景中,大幅减少状态表数据读取量,使刷新性能得到了显著的提升。
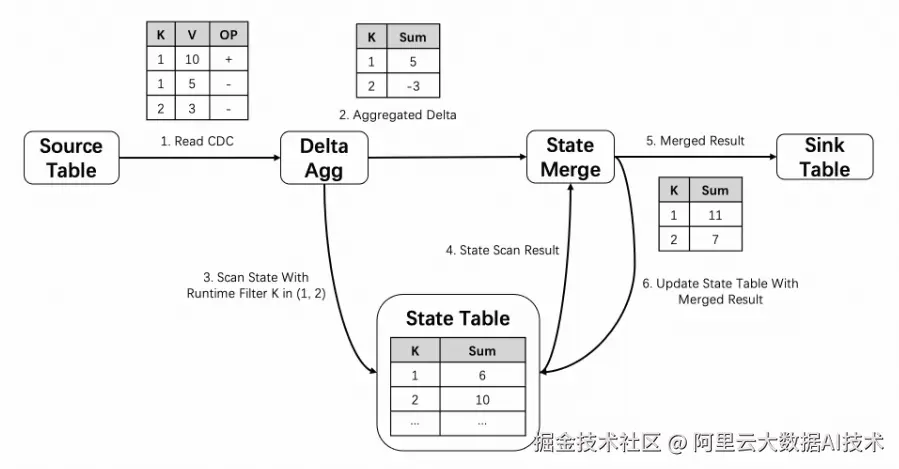
有状态方案一个显著的缺点是与无状态方案相比会需要占用额外的存储空间用于状态表的存储。如上述实验数据所示,实际额外存储大小通常与涉及到的源表、结果表的大小相关。
这一缺点通常是可以接受的,因为在业务实践操作中,这部分存储一般是可控的,不会无限增长。这是因为:
-
分区表的场景中,只有活跃分区需要状态表,历史分区转全量刷新后不再需要状态表(这个过程是自动的,分区不再活跃后会自动清理状态表)。因此只有最近的一两个分区才需要状态表,这极大地减少了状态表的存储空间。因此Hologres Dynamic Table增量计算状态表没有Flink常见的状态膨胀问题。
-
非分区表场景中,可以为状态表配置合适的TTL,丢弃一些不再需要的历史状态减少存储空间
总结:Hologres Dynamic Table 的核心价值
面对企业日益增长的实时分析需求,Hologres 的 Dynamic Table 通过有状态增量计算引擎,从根本上解决了传统方案在复杂查询下"增量不增效"的痛点。它不仅大幅缩短了数据刷新延迟,还显著降低了计算资源消耗和运维复杂度,真正实现了"写一次 SQL,自动高效更新"的体验。无论你是构建实时看板、用户画像宽表,还是风控特征管道,Hologres 都能以稳定、高性能、低成本的方式支撑你的核心数据链路。
附录
无状态 & 有状态增量计算底层原理对比分析
从上面的实验结果来看,Hologres的有状态实现方案在大多数的场景中是要优于无状态增量计算引擎的,本小节将对两者的底层计算原理进行对比分析,说明造成这种性能差异的根本原因。
符号说明
R:表示一个关系表
Δ(Expr):表示一个关系计算表达式的增量变化
Pre(R):表示一个关系表在某次增量变化之前的快照
Post(R):表示一个关系表在某次增量变化之后的快照
State(Expr):表示某一个关系计算表达式的持久化状态
⋈:表示关联操作(Join)
Agg(Expr):表示对某一个关系计算表达式做聚合运算
Merge(Expr):聚合运算的特例,每一个分组只有两行数据
多表Join场景
无状态实现Hologres Dynamic Table:高效增量刷新,构建实时统一数仓的核心利器
无状态多表Inner Join的增量计算公式如下(原理可参考论文),根据实际执行计划推测某无状态增量计算引擎的多表Join增量计算应该也是基于该公式实现的
Δ(R_1 ⋈ ⋯ ⋈ R_n) = Δ(R_1) ⋈ Post(R_2) ⋈ Post(R_3) ⋈ ... Post(R_n) ∪ Pre(R_1) ⋈ Δ(R_2) ⋈ Post(R_3) ⋈ ... Post(R_n) ∪ Pre(R_1) ⋈ Pre(R_2) ⋈ Δ(R_3) ⋈ ... Post(R_n) ... ∪ Pre(R_1) ⋈ Pre(R_2) ⋈ Pre(R_3) ... Δ(R_n)
该方案主要会有如下弊端:
-
Join次数较多,会有至少 N ∗ (N − 1)次
-
每一路Union的 N−1次Join中,只有一个是增量数据级的 Δ(R),其他路都是源表数量级的 Pre、Post,这种场景中Join Filter效果不好保证,可能会多扫描很多数据
-
当增量数据含有回撤时,需要调控不同Union之间的输出顺序来确保因果关系,会使上面的计算流程变得更重
有状态实现
Hologres的有状态多表Join计算公式原理大致如下,因为所有的中间计算结果状态会通过状态表( State)持久化保存下来,因此可以按照两表Join的公式做简单展开
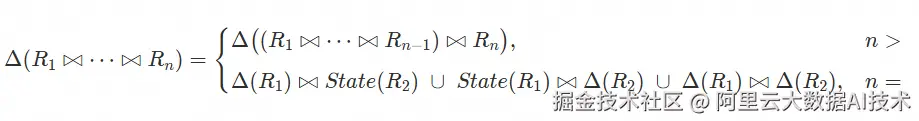
有状态方案以额外的存储开销为代价换来了:
-
更少的Join次数,忽略 Δ(R_1) ⋈ Δ(R_2)这种轻量级的Join,只有 2 ∗ (N − 1)次Join 操作
-
更少的数据读取, Δ 和 StateJoin的Filter下推简单高效,通常只需要读取 State表中的少数行
-
更简单的回撤处理逻辑,只需要在同一层内调整数据输出顺序确保因果关系
单表聚合场景
单表聚合场景相对较为简单,无状态、有状态两种方案的计算公式原理分别如下:
某无状态增量计算引擎: Δ(Agg(R)) = Agg( Agg(Δ(R)) ⋈ R )
Hologres有状态: Δ(Agg(R)) = Merge( Agg(Δ(R)) ⋈ State(R) )
公式大体是比较相似的,主要区别是Hologres的有状态方案持久化存储了历史数据的聚合结果,因此有以下优势:
-
不需要重新计算历史数据的聚合结果
-
State表数据量极小,Join 操作可以显著减少读取数据量