Transformer实战(20)------微调Transformer语言模型进行问答任务
0. 前言
问答 (Question Answering, QA) 是一种自然语言处理 (Natural Language Processing, NPL) 任务,其目标是在给定上下文文本的前提下,自动定位并生成对用户提问的准确回答。与视觉问答 (Visual Question Answering, VQA) 需要结合图像信息不同,纯文本 QA 完全依赖于文本上下文。本文将使用 SQuAD v2 数据集,详细讲解如何使用 DistilBERT 完成从数据预处理、模型微调,到模型保存的完整流程。
1. 问答任务
问答任务通常定义为一种自然语言处理 (Natural Language Processing, NPL) 问题:给定一段文本和一个问题,从中找到答案。通常,答案可以从原始文本中找到,解决这一问题的方法多种多样。在视觉问答 (Visual Question Answering, VQA) 中,问题是关于视觉实体或视觉概念的,而不是文本,但问题本身仍以文本形式呈现。下图是一些 VQA 的示例:

大多数用于 VQA 的模型都是多模态模型,能够理解视觉上下文并结合问题生成合适的答案。而单模态的纯文本 QA 仅基于文本上下文和文本问题,并生成相应的文本答案。
2. SQuAD 数据集
SQuAD (Stanford Question Answering Dataset) 是问答领域中最经典的数据集之一。查看 SQUAD 的示例并进行分析:
python
from pprint import pprint
from datasets import load_dataset
squad = load_dataset("squad")
for item in squad["train"][1].items():
print(item[0])
pprint(item[1])
print("="*20)输出结果如下所示:
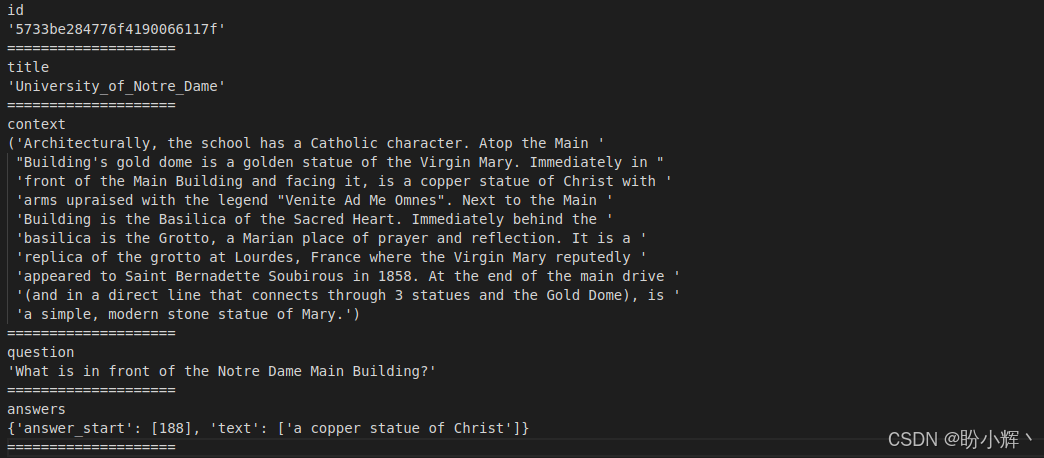
SQuAD 数据集有一个 SQuAD v2 版本,包含更多的训练样本。为了全面了解如何训练一个 QA 模型,我们将使用 SQuAD 数据集进行文本问答训练。
3. 数据集加载与处理
(1) 首先,加载 SQuAD v2:
python
from datasets import load_dataset
squad = load_dataset("squad_v2")(2) 加载 SQuAD 数据集后,查看数据集的详细信息:
python
print(squad)输出结果如下所示,可以看到,数据集包含超过 130000 个训练样本和 11000 多个验证样本。

(3) 与命名实体识别 (Named Entity Recognition, NER) 任务类似,我们需要对数据进行预处理,以确保数据具有正确的格式,便于模型使用。为此,首先需要加载分词器,由于使用的是预训练模型 distilBERT 并针对 QA 问题进行微调,因此需要使用预训练的分词器:
python
from transformers import AutoTokenizer
model = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model) 对于 SQuAD 示例,我们需要向模型输入多个文本,一个是问题,一个是上下文。因此,我们需要让分词器将它们并排放置,并用特殊的 [SEP] 词元分隔它们,因为 distilBERT 是基于 BERT 的模型。
在问答问题中,还存在另一个问题,即上下文长度。上下文的长度可能超过模型的输入大小,但我们不能将其截断为模型所接受的大小。对于某些特定的 NLP 任务,我们可以截断输入,但在 QA 中,有可能答案就包含在被截断的部分,我们将采用文档滑动窗口 (document stride) 来解决这个问题。
(4) 使用分词器 tokenizer 处理上下文长度问题:
python
max_length = 384
doc_stride = 128
example = squad["train"][173]
tokenized_example = tokenizer(
example["question"],
example["context"],
max_length=max_length,
truncation="only_second",
return_overflowing_tokens=True,
stride=doc_stride
)这里的 stride 与文档滑动窗口 (document stride) 相同,用于返回第二部分(像窗口一样)的滑动步长,而 return_overflowing_tokens 参数则告诉模型是否应返回额外的词元。tokenized_example 的结果不仅仅是单个分词后的输出,而是包含两个输入 ID:
python
len(tokenized_example['input_ids'])
# 2可以通过运行以下 for 循环查看完整结果:
python
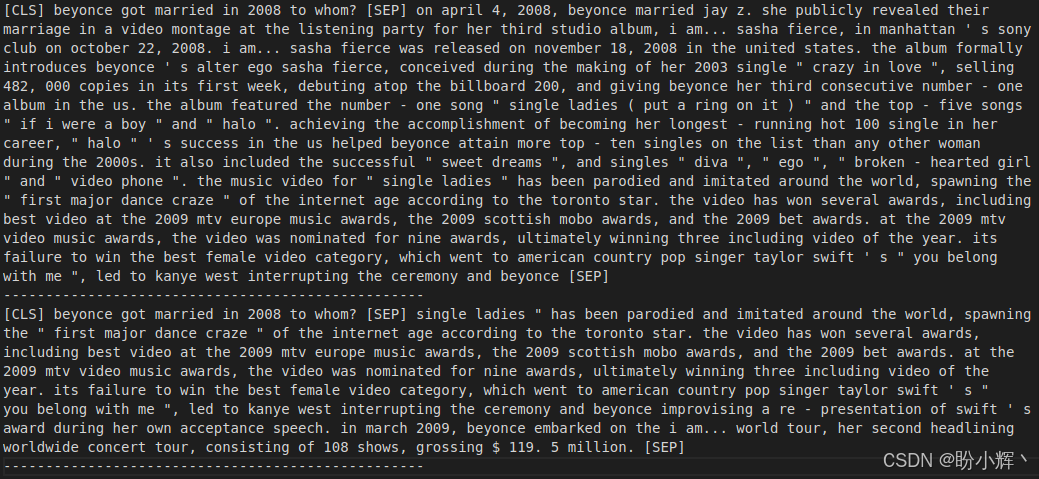
for input_ids in tokenized_example["input_ids"][:2]:
print(tokenizer.decode(input_ids))
print("-"*50) 运行结果如下所示,可以看到,使用 128 个词元的窗口,剩余的上下文会在第二个输入 ID 的输出中再次出现。
另一个问题是结束跨度 (end span),在数据集中并没有给出这个值,而是给出了答案的起始跨度 (start span) 或起始字符。我们可以通过计算答案的长度并将其加到起始跨度上,就能自动得到结束跨度。
(5) 我们已经了解了数据集的相关细节及处理方式,可以将它们组合起来定义预处理函数,函数使用示例作为输入:
python
def prepare_train_features(examples):接下来,对示例进行分词:
python
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)将特征映射到其示例:
python
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
offset_mapping = tokenized_examples.pop("offset_mapping")
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = [] 对于无法回答的示例,应该将其标记为 CLS,并为每个示例添加起始和结束词元:
python
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
sequence_ids = tokenized_examples.sequence_ids(i)
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
token_start_index = 0
while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
token_end_index -= 1
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples将这个函数应用到数据集上:
python
tokenized_datasets = squad.map(prepare_train_features, batched=True, remove_columns=squad["train"].column_names)4. 模型微调
(1) 加载预训练模型进行微调:
python
from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
model = AutoModelForQuestionAnswering.from_pretrained(model) (2) 接下来,创建训练参数:
python
args = TrainingArguments(
f"test-squad",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
num_train_epochs=3,
weight_decay=0.01,
)(3) 如果我们不打算使用数据合并器 (data collator),可以为模型训练器提供一个默认的数据合并器:
python
from transformers import default_data_collator
data_collator = default_data_collator(4) 创建训练器 trainer:
python
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
) (5) 调用 trainer 的 train 方法:
python
trainer.train() 结果如下所示,可以看到模型经过了 3 个 epoch 的训练,输出了验证和训练数据集的损失 (loss):
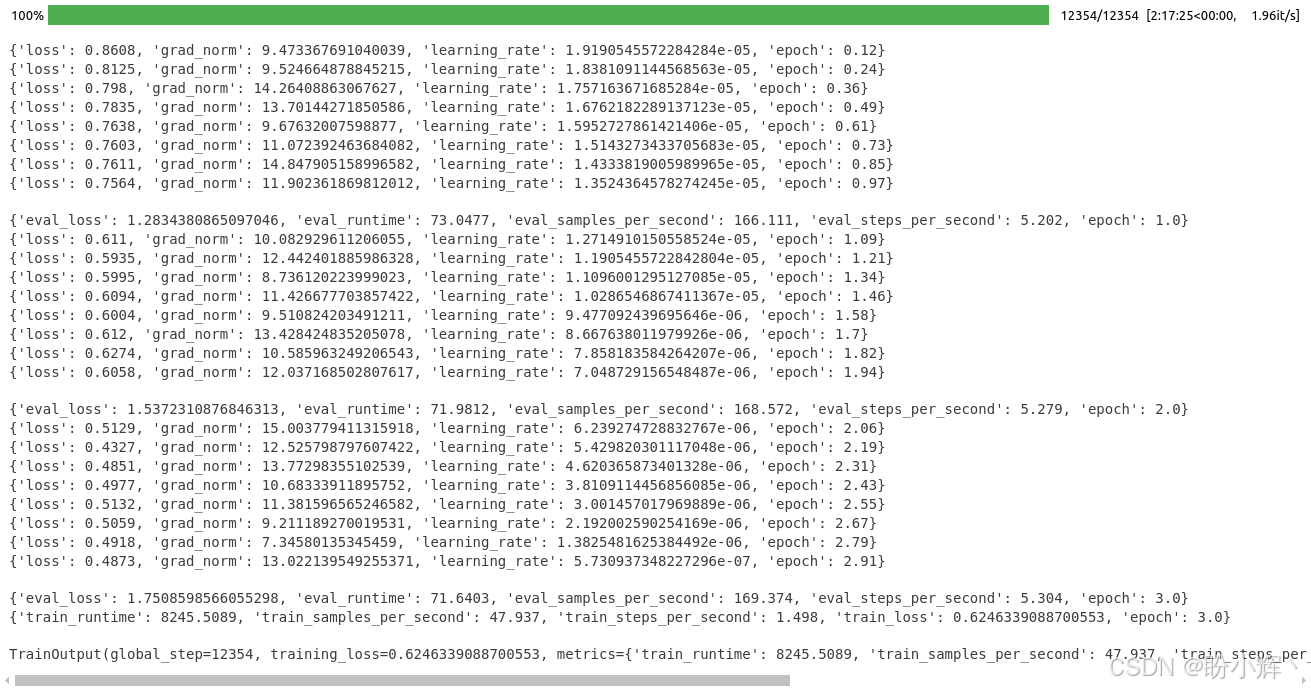
(6) 使用 save_model() 函数保存模型:
python
trainer.save_model("distillBERT_SQUAD")如果想要使用保存的模型或其它经过 QA 训练的模型,Transformers 库提供了一个易于使用的管道 (pipeline)。
(7) 通过使用 pipeline,可以使用任意模型,通过以下代码使用 QA 流水线的模型:
python
from transformers import pipeline
qa_model = pipeline('question-answering', model='distilbert-base-cased-distilled-squad', tokenizer='distilbert-base-cased') 该 pipeline 只需要两个输入来准备模型进行使用:模型和分词器,同时还需要提供管道 (pipeline) 类型,在以上代码中为 "question-answering" 即问答类型。
(8) 提供模型所需的输入,即上下文 context 和问题 question:
python
question = squad["validation"][0]["question"]
context = squad["validation"][0]["context"] 查看问题和上下文:
python
print("Question:")
print(question)
print("Context:")
print(context) 
(9) 使用模型:
python
qa_model(question=question, context=context) 输出结果如下所示:
shell
{'score': 0.9889376759529114, 'start': 159, 'end': 165, 'answer': 'France'}我们已经学习了如何在所选用的数据集上训练问答任务模型,还学习了如何使用管道 (pipeline) 来使用训练好的模型。
5. 多任务问答
我们可以将多种不同的 NLP 任务简化为一个简单的范式------问答 (Question Answering, QA)。例如,对于情感分类任务,我们可以通过基于 QA 的方法来解决,而不是直接将输入分类为不同类别(正面、负面和中立)。我们可以通过以下方式重新定义输入:
Context: "I loved this movie!"
Question: "What best describes the sentiment of this text (Positive,
Negative, Neutral)?"
Answer: "Positive"通过这种方式,不仅可以处理单个 NLP 任务,还可以将其他 NLP 任务与词元分类器结合使用。例如,可以使用不同的问题来处理不同的 NLP 任务,只需要一组问题及其对应的答案。但在本节场景中,并非所有答案都来自给定的上下文,答案也可以来自问题本身。
另一个例子是使用 QA 来解决代词解析问题。例如,使用以下格式,可以用 QA 来进行代词解析:
Context: "Meysam admired Savas. He was always fascinated about
his work."
Question: "What does He refer to in this text?"
Answer: "Meysam"小结
在本节中,我们介绍了文本问答系统构建流程,首先加载并分析 SQuAD 数据,采用"文档滑动窗口"策略处理超长上下文,再通过 mapping 计算 answer 的起止 token 索引;随后使用 Transformers 中的 Trainer 结合 AutoModelForQuestionAnswering 对 DistilBERT 进行微调;训练完成后,保存模型并借助 pipeline("question-answering") 实现快速推理。最后,还介绍了如何将 QA 框架推广到情感分类、代词消解等多种 NLP 任务,实现多任务问答。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类