IOT-Tree Server是个开源物联网软件,可以作为组态软件成为自动化系统的上位软件。她提供了接入、数据组织管理、控制逻辑和人机交互多个方面的功能。IOT-Tree消息流功能是在规整接入各种设备数据之后,提供的功能块组合配置支持(直观快速),通过她你可以在大部分场合快速实现数据的处理------存储、转换、发送等。
如果你对IOT-Tree Server还不熟悉可以参考如下文档:
使用开源IOT-Tree Server进行工业现场自动化控制
https://gitcode.com/jasonzhu8888/iot-tree
https://github.com/bambooww/iot-tree
1 语音识别节点功能目标
此节点实现目标是对简单的语音转换为JSON格式指令输出,配合消息流其他节点可以实现语音控制等功能------这个在智能家居等需要语音控制的场合用处很大。
节点输入语音流,并根据设置的语言库对输入音频数据进行识别并转换为文字。同时,为了能够更好的支持简单语音指令,可以限定被识别的语音在特定的单词(或词组)范围内,并且可以对每个单词(词组)进行另外的关键字(key)命名。这样不仅可以提供识别准确度,还可以使得识别结果直接是以key组成的JSON结构------这样更方便后续的处理。
此节点与麦克风输入节点的byte\[\]输出数据配合使用。
2 语音识别模型设置
此节点使用vosk语音识别模型实现,使用前你需要在IOT-Tree部署实例中,添加语言模型。
2.1 添加语言模型到系统中
IOT-Tree安装包为了控制大小,没有把语言模型打包装入其中,安装部署IOT-Tree之后,请访问下载地址,下载你需要的语言模型。并在IOT-Tree安装目录/data下面建立目录 ./vosk/models/。 解开模型目录放置到此目录下,并在此目录下建立一个文件: list.json。
例如下图里面配置了两个模型:
vosk-model-small-cn-0.22
vosk-model-small-en-us-0.15最终目录如下:─vosk/
└─models/
├─vosk-model-small-cn-0.22/
├─vosk-model-small-en-us-0.15/
└─list.json编辑list.json如下内容:{
"models":[
{"n":"en_us","t":"American Engish","dir":"vosk-model-small-en-us-0.15"}
,{"n":"cn_zh","t":"中文普通话","dir":"vosk-model-small-cn-0.22"}
]
}确保格式符合JSON格式要求,保存之后,需要重新启动IOT-Tree运行实例。
3 语音识别节点设置
3.1 添加消息流和语音识别节点
在IOT-Tree项目管理主界面左下角添加一个消息流,并且点击打开此消息流编辑界面。选择左边节点列表"音频"分类"语音识别"节点,拖拽到编辑区,就完成了节点添加。
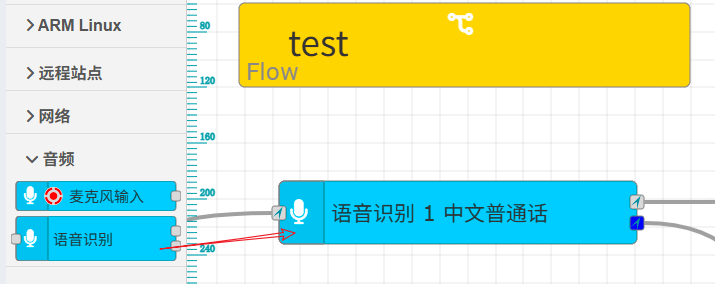
3.2 节点的输出说明

节点有两个输出点,第一个是普通的识别结果输出,也即是payload是简单的由识别出的单词组合而成的一个字符串。如:
`open air conditiong
`而第二个输出时设置了限制指令之后的结构化输出。格式如下:
`[{"key":"k1","word":"xxxx"},{"key":"2","word":"yyy"},...]
`整体是个JSON数组,里面每个对象都是一个单词对应的key。后续处理就可以基于唯一的key进行动作确定和目标定位。
限制指令参数说明
IOT-Tree使用本节点最大的目标是实现语音控制指令输出,而本节点推荐使用的是几十兆的小模型,以避免占用太多资源(对于大模型来说,最好在高性能服务器上部署,形成语音识别Server,然后通过http等方式api进行调用)。
同时,控制指令由现场控制需求决定,语音单词肯定是有限的,如果能够限定语音识别在一个有限的单词集合内,不仅可以减少识别干扰,同时还可以提升识别成功率和识别性能。
更进一步,动作、被控对象相关的单词很可能有多个(多种说法),用户语音输入时如何更准确的定位到特定被控对象,也需要有个对应关系。
由此,本节点在参数设置时,增加了"限制指令"选项。通过此选项,你可以通过key来唯一区分动作和被控目标,同时针对一个key还可以设置一个或多个语音单词进行关联;并且在识别之后的输出也会把相关的唯一key也作为数据输出。这样能够更好的为后续的控制逻辑(状态机)等提供一个更准确的数据结构
3.3 语音识别具体设置
双击节点,在打开的对话框中,选择语言模型(此列表由上面的list.json配置),使能"限制指令"之后,你可以填写关键字到语音单词/词组的映射关系,每个关键字可以有多个语音单词/词组。界面如下:
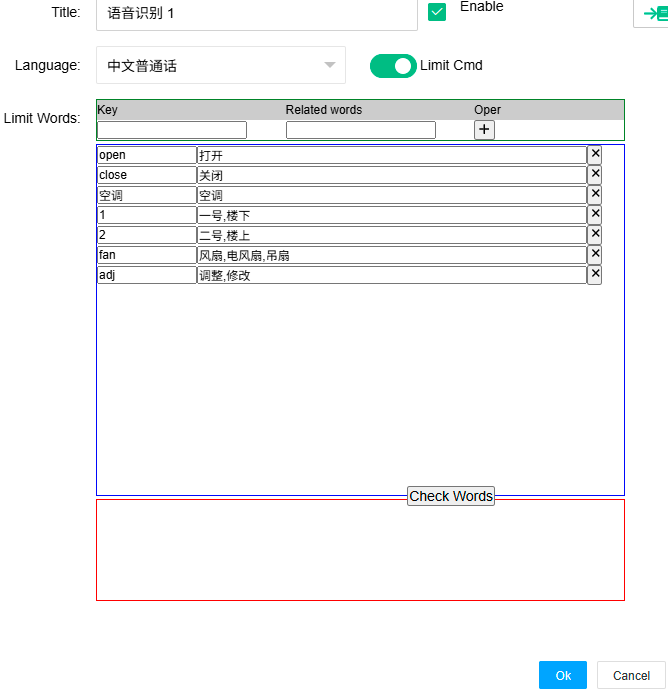
下方是单词检查结果区,点击"Check Words",可以返回当前填写的单词哪些是模型中不存在的。这是因为语言模型由于体积大小限制对支持的单词是有限的,我们针对某个key定义的语言单词(Word)都必须在模型中存在。如果有不存在的单词,你只需要根据提示进行调整处理。
由于本节点内部使用轻量级语音识别相关模型,如果一些组合单词如"空气压缩机"在模型中就可能找不到对应的语音识别特征数据,但如果拆开成"空气"、"压缩机"两个单词就可以找到对应内容,且识别时也会输出两个单词。为了更好的支持这种组合对象,本节点内部实现了一套匹配算法,运行组合单词映射到单独一个key中,使得小模型有了更大的能力。
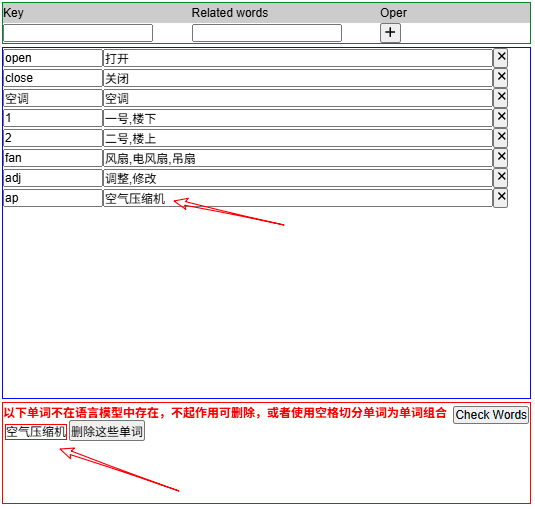
以识别"空气压缩机"这个对象为例,我们设置了如下限定参数:
Key=ap
Related words=空气压缩机点击按钮"Check Words"之后,模型返回此单词不存在。
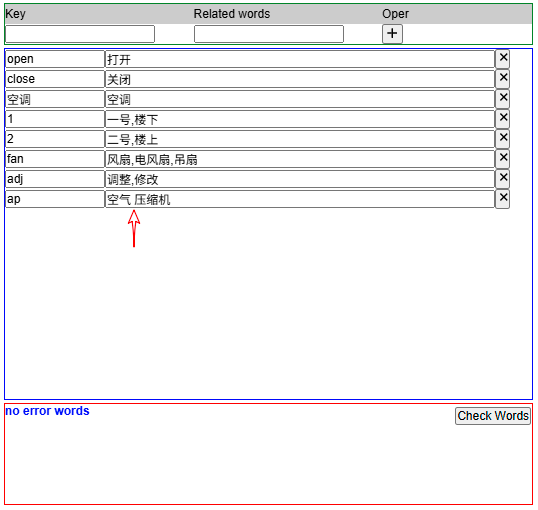
此时,你可以在空气后面增加一个空格字符,使之变成两个词的组合,再次点击按钮"Check Words",就发现可以通过了。
4 添加"麦克风输入"节点完整识别网络
在此节点前,添加"麦克风输入"节点,然后与此建立消息关联,这样就完成了完整的识别网络。当然,我们还可以添加几个Debug节点,用来查看识别结果,如下图:
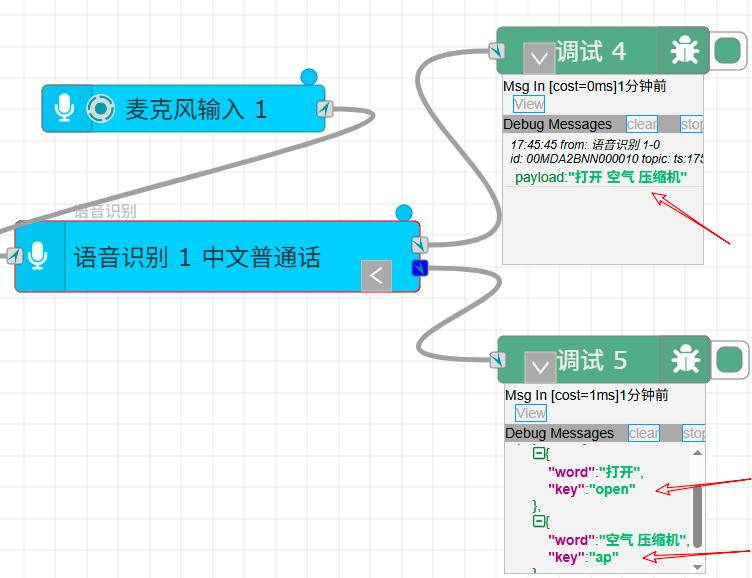
5 启动消息流运行测试结果
启动项目或启动这个消息流。然后我们在麦克风中说出"打开空气压缩机"这个语音命令,可以看到如下输出结果。其中端子1输出的仅仅是单词组合,而端子2输出了更准确的基于Key的结果,这是我们需要的结果(可以很方便的做后续处理)。
重要说明
语音识别很容易受周边噪声干扰,如果希望使用效果好,请使用更理想的输入设备,并且尽量避免周边影响。
请尽可能在识别网络中定义指令接收之后的状态,然后通过提示确认(问答或画面图示等方式),确保指令下达之前是准确可靠的。
在一些重要的涉及安全的控制场合,如果无法做到指令发送前的准确反馈确认机制------无法100%确保安全可靠,不建议使用此交互机制。