下午看到了Deepseek在huggingface上创建了一个新项目,还是熟悉的味道,选择在长假前发布模型DeepSeek-V3.2-Exp(全员卷王体质啊,还有点人性还是留了一天时间给各个云厂商更新线上的模型)。与以往不一样,这次模型和技术报告居然一起更新了,那么在下载模型的过程中,咱们就顺便看下技术报告,有哪些创新的地方,值不值得放弃中秋国庆假期去深入研究一下。
模型架构
DeepSeek-V3.2-Exp 的架构核心整体是在前段时间发布的 DeepSeek-V3.1-Terminus 模型上改进的,主要创新点(改进点)是在持续学习的过程中引入了一个新的原创注意力机制------DeepSeek Sparse Attention (DSA)。技术报告也提到这个注意力机制主要是为了在长上下文序列的场景下提升训练和推理的计算效率(说白了就是省钱)。报告中也给出了成本节约的对比图。
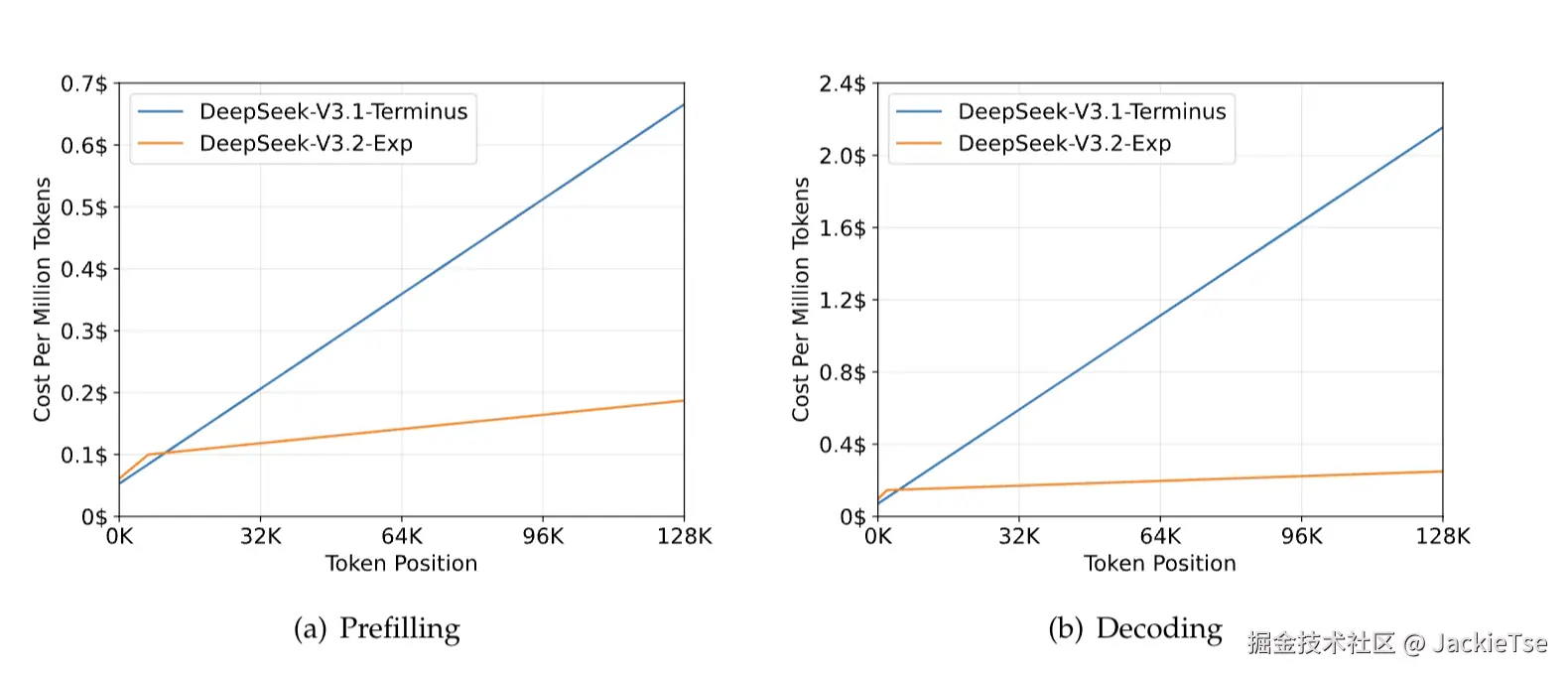
可以从图中看出,在长上下文场景下推理时的成本相对V3.1是大幅下降而且在128K的场景下降成本远超了50%(emmm,所以官网api降价50%的定价原因,应该是从之前他们说的64K常用的长度出发的吧,应了黄教主那句话,"你用得越多越便宜")。 这里还有个细节,V3.2 Exp是基于3.1的持续学习,也就是说通过这个新的注意力机制,Deepseek可以实现对模型低成本的持续训练参数更新,也就是可以通过低成本的持续学习去不断地让模型学习现在正在生产的人类知识,本来已经开始被人嫌弃的RAG方案现在更加雪上加霜~ 没有了成本顾虑,以后就是长上下文的时代。 在报告中也提到了V3.2的模型主要是使用128K的数据进行持续学习的,意味着它能够处理最长达 128K 个 token 的长文本输入,相比较于之前的版本,在长上下文的场景下V3.2会有更好的表现。
Lightning Indexer
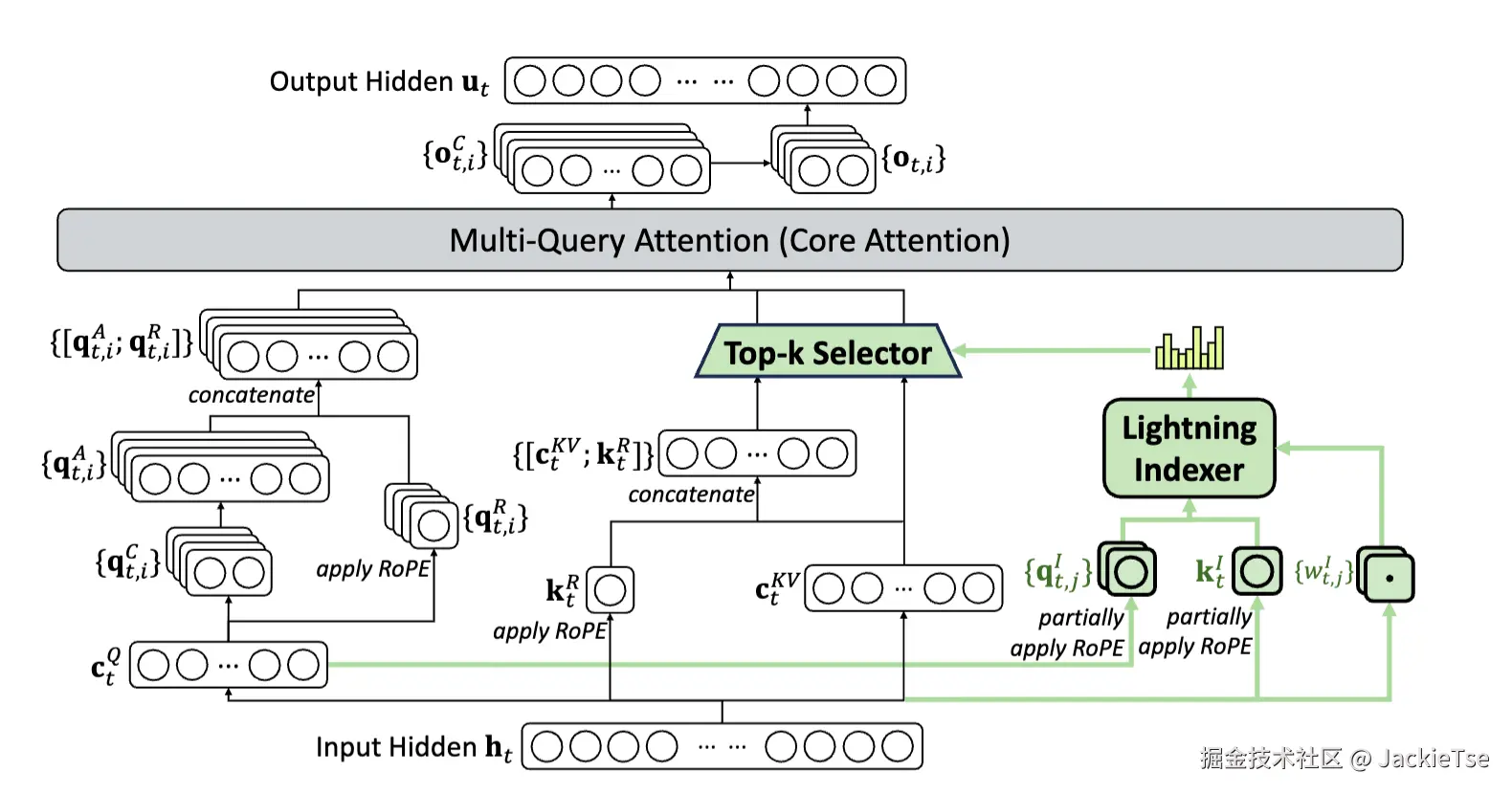
Lightning Indexer 是DSA的关键组件。主要负责计算查询token(query token)于前文token(preceding token)的索引分数,通过分数去确定query token需选择哪些token,目的是降低计算量,提升长上下文场景下模型的训练和推理效率。
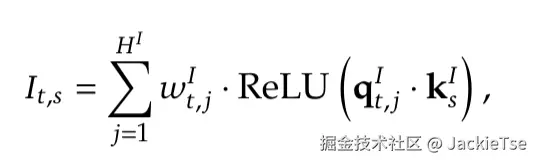
Deepseek团队在技术报告也提到,DSA也是采用 MQA(Multi-Query Attention)模式设计的,为的是与DeepSeek-V3.1-Terminus 兼容以进行持续训练。同时使用ReLU作为激活函数,主要是为了提升计算吞吐量。由于Lightning Indexer的头数Heads较少,且能采用 FP8 精度进行计算,其计算效率非常高。该分数决定了哪些tokens会被选择,分数越高,被选择的可能性越大。也因为MLA和DSA都是基于MQA的模式设计,可以实现KV参数的共享,在这个架构中,Lightning Indexer先通过计算索引分数筛选token,再配合后续的注意力计算模块(MLA),共同完成稀疏注意力机制的功能,使得模型在处理长序列时能更高效地聚焦关键信息。
训练
报告中提到V3.2的模型训练分为了三个阶段:
- 持续预训练(Continued Pre-Training):包括Dense Warm-up Stage 和Sparse Training Stage。Dense Warm-up Stage主要是为DSA注意力机制的核心组件Lightning Indexer提供初始参数,并使其输出与原有密集注意力的分布对齐,避免因新组件引入导致模型性能波动。这一步仅用 1000 步(总计 2.1B token)实现索引器与主注意力的分布对齐,为后续稀疏训练铺垫基础,且未破坏主模型原有的长上下文处理能力。Sparse Training Stage引入 "细粒度token选择机制"(fine-grained token selection mechanism),让主模型与索引器共同适配 DSA 的稀疏注意力模式,同时保持索引器筛选逻辑的准确性。在 15000 步(总计 943.7B token)训练后,可精准定位对查询 token 重要的键值对,且主模型语言建模能力未出现显著退化。
- 后训练(Post-Training):该阶段沿用 DeepSeek-V3.1-Terminus 的训练流水线、算法与数据,仅采用 DSA 稀疏注意力模式,核心目的是 "在稀疏架构下补全多任务能力,验证 DSA 对性能的影响",分为专家蒸馏 (Specialist Distillation)和混合 RL 训练 (Mixed RL Training)两个模块。
- 专家蒸馏是让稀疏架构的模型吸收各领域 "专家模型" 的能力,避免因稀疏化导致特定领域性能下降,同时降低大规模领域训练的成本(针对6大领域:数学、竞赛编程、通用逻辑推理、智能体编码、智能体搜索、写作 / 通用问答),用专家模型生成 "长思维链推理" 和 "直接响应" 两类数据,让主模型通过 "蒸馏" 学习专家知识。
- 混合RL训练是为了融合 "推理、智能体、人类对齐" 三大训练目标,在稀疏架构下平衡多领域性能,同时解决传统多阶段 RL 训练的 "灾难性遗忘" 问题(即训练新任务时忘记旧任务能力)。这个阶段依然是采用GRPO(Group Relative Policy Optimization)算法,将多阶段训练合并为单 RL 阶段。
报告也给出了DSA的效果,除了上面的效率提升(成本下降)以外,也提到了在 BrowseComp(搜索智能体)、SWE Verified(代码智能体)等任务上的训练曲线与 DeepSeek-V3.1-Terminus 高度对齐(这里的重点是,省了一半的成本就实现了与V3.1媲美的效果)
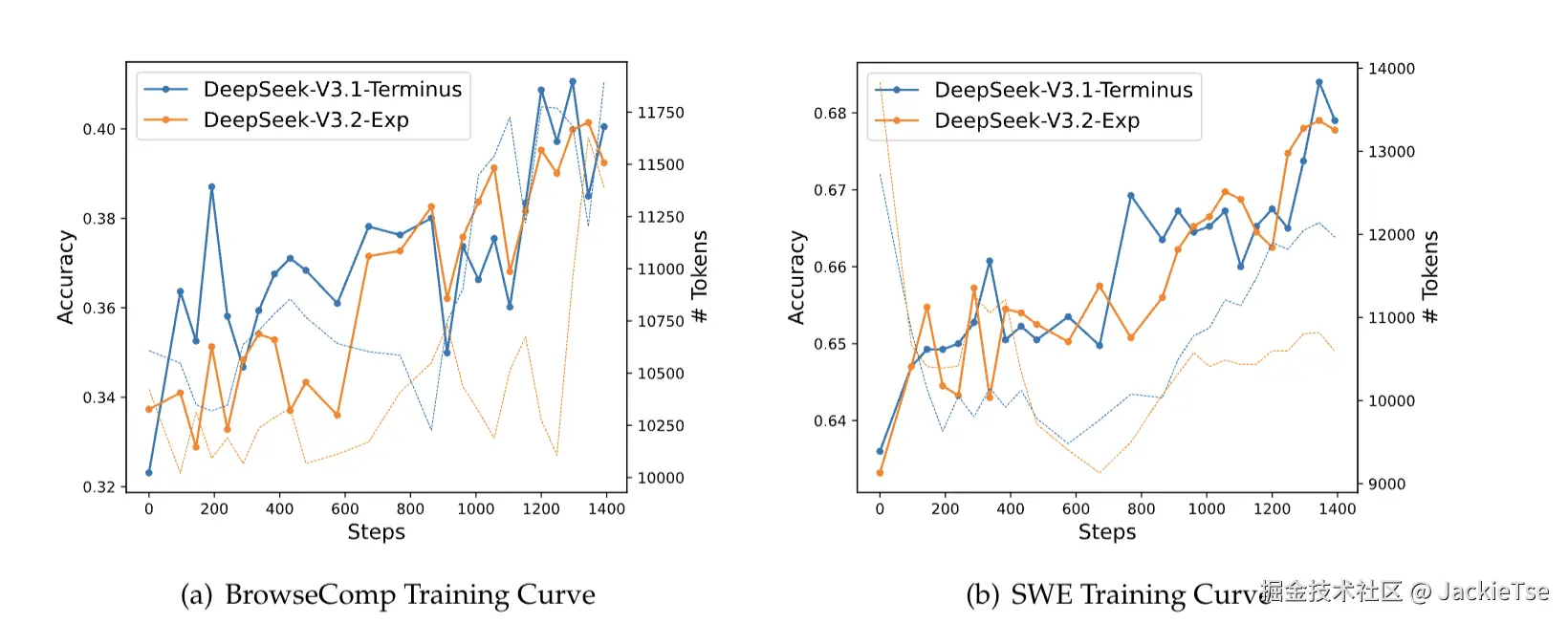
综上,DeepSeek-V3.2-Exp贯彻了Deepseek一贯的节约资源、勤俭持家的作风,并且针对长上下文训练以及那么多排行榜就选了BrowseComp和SWE Verified这两个榜单也说明了Deepseek在Agent基础模型技术上一直持续发力并不是外界说的没有跟进热点关注,相反未来Deepseek在Agent的应用潜力更加可期。