vLLM对于部署过大模型的人来说应该都不算陌生, 它能极大提升LLM的服务吞吐量,显著降低推理成本。vLLM成功的核心秘诀在于一项名为 PagedAttention 的技术及其配套的调度策略,对于不熟悉底层的人来说,这些概念可能非常晦涩难懂。幸好,DeeoSeek一位研究员开源了一个学习项目,nano-vLLM ,仅使用约1200行Python代码就实现了vLLM的核心功能,相比原生的vLLM来说更容易学习其核心思想。得益于轻量化的设计,nano-vLLM在Qwen3的推理速度上比vLLM更快。
一、大模型的推理瓶颈,不仅是计算,更是显存管理
一般情况下,LLM推理慢是因为矩阵计算量太大,这是模型自身参数量决定的,无法避免。但在实际并发场景中,真正的瓶颈往往是 显存带宽和管理。
LLM推理是一个自回归的过程,即逐个生成token。为了避免重复计算,模型需要将先前所有token的Key和Value状态缓存起来,这就是我们常说的KV Cache。
随着生成序列的增长,KV 缓存会变得越来越大。当多个请求并发时,管理这些动态增长且大小不一的KV缓存就成了一个巨大的挑战。
传统KV缓存管理的局限
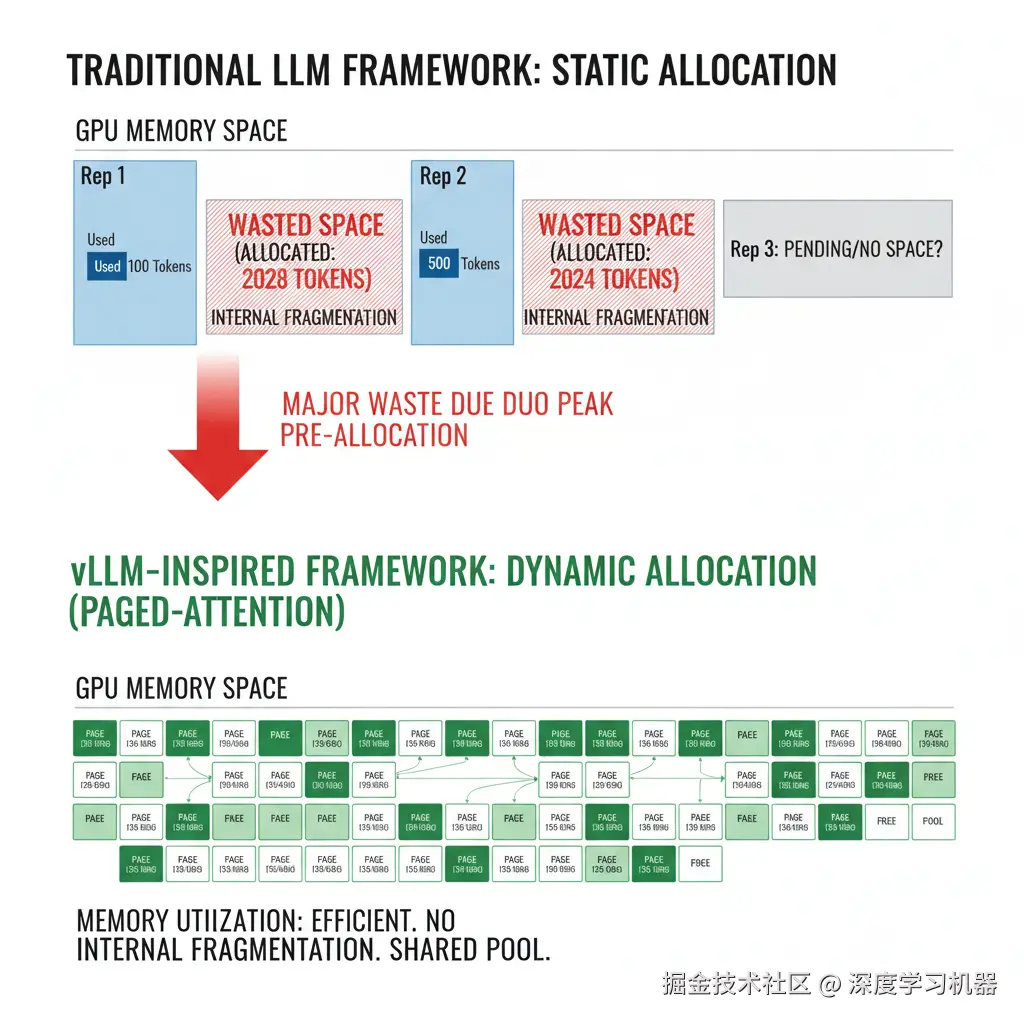
在vLLM出现之前,主流框架通常为每个请求预先分配一块连续的 显存空间,其大小按该请求可能生成的最大 token 数量来计算。这种方式虽简单,却带来了严重的浪费:
(1) 内部碎片化
大部分请求实际生成的token数远小于预设的最大值。被浪费的空间位于已分配的块内部,无法被其他请求使用。
yaml
显存空间: [Req 1: Alloc 2048, Used 100 | WASTED ] [Req 2: Alloc 1024, Used 500 | WASTED ](2) 外部碎片化:
不同请求生命周期不同,导致显存中产生许多不连续的小空闲块。当一个需要较大连续空间的新请求到来时,即使总空闲显存足够,也可能因找不到一块足够大的连续空间而失败。
这两种浪费共同导致GPU显存利用率低下,系统能同时处理的并发请求数(即吞吐量)也大打折扣。
二、vLLM的方法:像操作系统一样管理显存
vLLM从一个经典领域------操作系统 中获得了灵感。操作系统通过虚拟内存 和分页 机制,将物理内存划分为固定大小的"页",并将程序的虚拟地址空间映射到物理页上,从而解决了内存碎片问题。 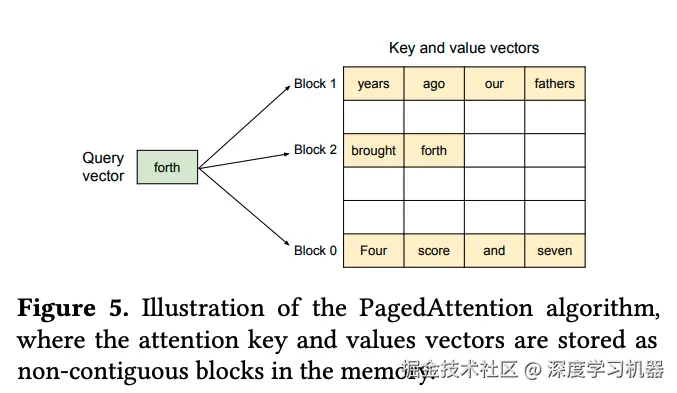
vLLM将这个思想应用到了KV缓存的管理上,提出了PagedAttention。
核心思想:显存块化与逻辑映射
PagedAttention的核心是将KV缓存不再存储于连续空间,而是分割成一个个固定大小的物理块。每个物理块可以存储固定数量token的K和V状态。
在nano-vllm中,这个机制被清晰地呈现出来:
(1) 物理块
这是显存管理的最小单位。在nanovllm/engine/block_manager.py中定义,它包含了引用计数ref_count、hash等属性。
python
# nanovllm/engine/block_manager.py
class Block:
"""代表一个物理 KV 缓存块。"""
def __init__(self, block_id):
self.block_id = block_id # 物理块的唯一标识符
self.ref_count = 0 # 引用计数,用于实现块的共享
self.hash = -1 # 块内容的哈希值,用于前缀缓存
self.token_ids = [] # 块中存储的 token ID(2) 块表
为每个请求维护一个块表,记录了该序列的逻辑块到物理块的映射关系。
less
逻辑上 (对用户而言),一个请求的KV缓存是连续的:
Sequence 1: [Token1, Token2, Token3, Token4, Token5, Token6]
物理上 (在显存中),它被分散存储在不同的Block中:
Physical Memory: [B0]...[B5]...[B7]...[B23]...[B99]
Sequence 1 的块表(Block Table)记录了这个映射关系:
(假设每个 Block 存 2 个 Token)
Block Table for Seq 1: [Block 7, Block 23, Block 5](3) 注意力计算
在计算Attention时,GPU Kernel不再从一个连续内存区域读取KV值,而是根据block_table,从分散在显存各处的物理块中"采集"所需的K和V,然后进行计算。nano-vllm 在 nanovllm/layers/attention.py 中通过 flash_attn 库实现了这一点。
python
# nanovllm/layers/attention.py
class Attention(nn.Module):
def forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):
context = get_context()
# ... store kv cache ...
if context.is_prefill:
# Prefill 阶段,使用 block_table 从非连续内存中构建序列
o = flash_attn_varlen_func(..., block_table=context.block_tables)
else:
# Decode 阶段,同样使用 block_table 增量更新
o = flash_attn_with_kvcache(..., block_table=context.block_tables)
return o通过这种方式,PagedAttention彻底解决了内部和外部碎片化问题,显存利用率得到了极大提升。
优化点一:写时复制,实现缓存共享
PagedAttention 还带来一个巨大好处:高效的内存共享。
在并行采样,即一个prompt生成多个输出或束搜索等场景中,多个输出序列会共享一个相同的前缀。传统方法需要为每个输出复制一份完整的前缀KV缓存,这会造成巨大的显存浪费。
而在PagedAttention机制下,我们可以让多个序列的块表指向相同的、存储着前缀KV缓存的物理块。这些共享物理块的ref_count会增加。
less
Seq A (Prompt): "Translate to French: Hello"
Seq B (Prompt): "Translate to French: Hello"
# 两个序列共享存储 Prompt 的物理块
Seq A Block Table: [Block 1, Block 8] (ref_count of B1, B8 is 2)
Seq B Block Table: [Block 1, Block 8]
# 之后,Seq A 开始生成自己独有的 token "Bonjour"
# BlockManager 会为它分配一个新块 Block 99
Seq A Block Table: [Block 1, Block 8, Block 99]
# 同时,Seq B 开始生成 "Salut"
# BlockManager 为它分配另一个新块 Block 101
Seq B Block Table: [Block 1, Block 8, Block 101]nano-vllm的BlockManager通过ref_count实现了这一点。当释放序列时,只有当一个块的ref_count降为0,此时它才会被真正归还到空闲列表。
python
# nanovllm/engine/block_manager.py
class BlockManager:
def deallocate(self, seq: Sequence):
"""释放一个序列占用的所有物理块。"""
for block_id in reversed(seq.block_table):
block = self.blocks[block_id]
block.ref_count -= 1
if block.ref_count == 0: # 只有引用计数为0才真正释放
self._deallocate_block(block_id)
# ...优化点二:基于哈希的前缀缓存
除了写时复制,PagedAttention还解锁了另一项强大的内存共享技术:跨请求的前缀缓存。
想象一个场景:多个不同的用户请求,可能都包含一个相同的、很长的System Prompt,或者都在引用同一篇长文。如果为每个请求都重新计算和存储这个公共前缀的KV缓存,无疑是巨大的浪费。
nano-vllm的BlockManager通过哈希机制解决了这个问题:
- 计算哈希 :当一个物理块被token填满时,
BlockManager会计算这个块中所有token ID的哈希值,并将这个哈希值与物理块ID存入一个全局字典hash_to_block_id中。 - 分配时检查缓存 :当一个新序列需要分配块时,
BlockManager会逐块计算其token的哈希值,并到hash_to_block_id字典中查找。 - 缓存命中 :如果找到了匹配的哈希,并且经过验证(对比块内的
token_ids)确认不是哈希冲突,那么就意味着这个块的内容我们之前已经计算并存储过了。此时,无需分配新块和重新计算,直接让当前序列的块表指向这个已存在的物理块,并将其引用计数ref_count加一即可。
这个过程在 BlockManager.allocate 方法中有清晰的体现:
python
# nanovllm/engine/block_manager.py
class BlockManager:
def allocate(self, seq: Sequence):
# ...
for i in range(seq.num_blocks):
token_ids = seq.block(i)
# 计算块内容的哈希值
h = self.compute_hash(token_ids, h) if len(token_ids) == self.block_size else -1
# 在全局缓存字典中查找
block_id = self.hash_to_block_id.get(h, -1)
# 检查哈希冲突
if block_id == -1 or self.blocks[block_id].token_ids != token_ids:
cache_miss = True
if cache_miss:
# 未命中,分配新块
block_id = self.free_block_ids[0]
block = self._allocate_block(block_id)
else:
# 命中,复用旧块
seq.num_cached_tokens += self.block_size
block = self.blocks[block_id]
block.ref_count += 1
# ... 将块存入序列的块表 ...通过这种方式,vLLM 实现了极致的内存共享,无论是来自同一请求的分支,还是来自不同请求的公共前缀,都能被高效复用,进一步压榨了 GPU 显存的利用潜力。
优化点三:智能调度与连续批处理
有了 PagedAttention 高效的内存管理,vLLM 就能实现一种更灵活的调度策略------连续批处理(Continuous Batching)。
- 传统静态批处理:等待一个批次内的所有请求都生成完毕后,才能开始下一个批次。GPU 会在等待最慢请求时产生空闲。
scss
|-- Batch 1 (R1, R2, R3, R4) --|--> GPU IDLE <--|-- Batch 2 (R5, R6, R7, R8) --|- 连续批处理:请求可以随时加入,也可以随时结束。一旦某个请求完成,调度器会立刻释放其资源,并马上检查等待队列,看是否有新请求可以"见缝插针"地利用刚释放的资源开始处理。
lua
|-- Iter 1: R1, R2, R3, R4 --|
|-- Iter 2: R1, R3, R4, R5(new) --| (R2 finished)
|-- Iter 3: R1, R4, R5, R6(new) --| (R3 finished)
(GPU 一直保持高负载运转)nanovllm/engine/scheduler.py中的Scheduler类模拟了这一过程:
它维护着waiting和running两个队列。其核心的schedule()方法是整个系统的关键:
- 优先Prefill :首先尝试从
waiting队列中调度新请求。Prefill阶段计算量大,应尽快处理。它会检查资源是否足够(block_manager.can_allocate),如果够,就分配块并将其移入running队列。 - 然后Decode :如果没有新的prefill请求,则处理
running队列中的现有序列,为它们生成下一个 token。 - 抢占 :如果decode时发现没有足够的空闲块来追加token,调度器可以执行抢占操作,将一个正在运行的序列暂停(移回
waiting队列并释放其资源),以服务于更高优先级的请求。
以下是代码中的关键细节:
python
# nanovllm/engine/scheduler.py
class Scheduler:
def schedule(self) -> tuple[list[Sequence], bool]:
# --- Prefill 阶段 ---
# 优先处理等待队列中的新序列
while self.waiting and num_seqs < self.max_num_seqs:
seq = self.waiting[0]
# 检查加入新序列后是否会超出批次容量或物理块不足
if (num_batched_tokens + len(seq) > self.max_num_batched_tokens or
not self.block_manager.can_allocate(seq)):
break
# ... 调度该序列,分配块 ...
self.block_manager.allocate(seq)
# ...
if scheduled_seqs:
return scheduled_seqs, True # 返回 Prefill 批次
# --- Decode 阶段 ---
# 处理运行队列中的序列
while self.running and num_seqs < self.max_num_seqs:
seq = self.running.popleft()
while not self.block_manager.can_append(seq):
# 资源不足,执行抢占
self.preempt(...) # 抢占一个序列以释放资源
# ... 调度该序列 ...
return scheduled_seqs, False # 返回 Decode 批次三、推理流程解析
LLMEngine 是整个推理流程的"总指挥官",它在 step() 函数中将所有组件串联起来,不断循环,驱动整个系统向前: 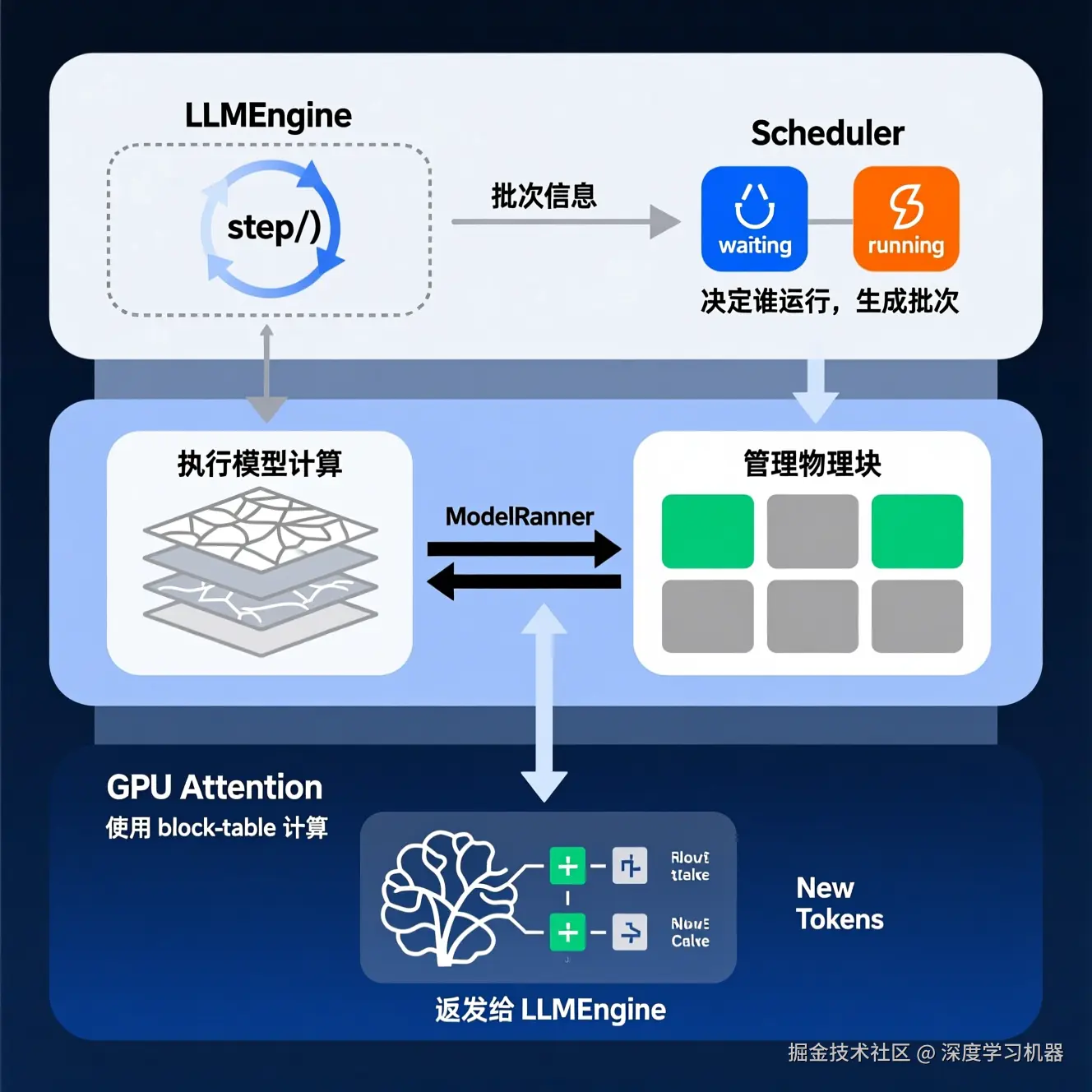
每一次 step():
scheduler.schedule():调度器决定当前批次要处理哪些序列。model_runner.run():模型运行器根据调度结果,在 GPU 上执行模型前向传播,得到新 token。scheduler.postprocess():调度器更新序列状态,将新生成的 token 追加进去,并释放已完成序列的资源。
这个循环不断进行,直到所有请求都处理完毕。
结论
通过nano-vllm这个麻雀虽小五脏俱全的项目,我们可以清晰地看到vLLM加速大模型推理的核心逻辑:
- 引入 PagedAttention:将 KV 缓存块化管理,通过块表映射逻辑与物理地址,从根本上解决了内存碎片问题,大幅提升显存利用率。
- 实现内存共享:利用写时复制和前缀缓存思想,让多个序列可以几乎零成本地共享庞大的前缀KV缓存。
- 执行连续批处理:基于灵活的内存管理,实现高效的智能调度,让 GPU 始终保持高负载运转,最大化吞吐量。
这三者环环相扣,共同造就了vLLM在LLM推理服务领域的卓越性能。对于LLM推理加速感兴趣的读者,强烈建议亲自阅读和运行nano-vllm项目,在实践中加深自己的理解。