1. 为什么要关心"有状态 + 时间敏感"?
在真实业务中,流处理不仅是"看一条算一条"。我们需要:
- 维护跨事件的上下文 (比如过去 10 分钟每个用户的 PV、某设备是否已经告警过等)→ 有状态
- 面对乱序、延迟、窗口与触发器、定时器回调等时间维度的复杂性 → 时间敏感
Flink 的运行时(Runtime)为此提供了**一致性(Exactly-Once)的状态与事件时间(Event Time)**优先的时间模型,再通过不同层级的 API 抽象把这些能力向上暴露出来。
2. 三个层级的 API 抽象:从"可塑性"到"表达性"
Flink 提供从低到高的三层抽象。可以简单理解为:越低层越灵活,越高层越声明式。
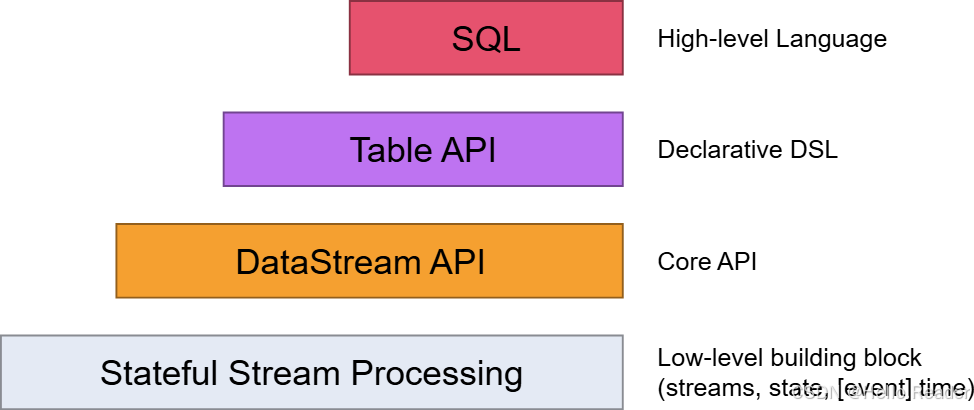
2.1 最低层:ProcessFunction(嵌入 DataStream API)
-
能力:有状态 + 定时器(事件时间 / 处理时间回调) + 任意自定义逻辑
-
适用场景:需要精细控制,例如:
- 复杂乱序处理、对齐多流、定制窗口/触发逻辑
- 需要 Keyed State / Operator State 细粒度管理
-
代价:代码量大、抽象层低,需要自己保证语义与可维护性
2.2 核心层:DataStream API(有界/无界)
- 能力:常见的转换(map、flatMap、filter)、聚合、连接、窗口、状态等
- 适用场景:大多数流处理/ETL/实时分析
- 特点:与 ProcessFunction 可混用(按需"降级"到低层处理关键环节)
2.3 声明式层:Table API
- 能力:表 为中心的 DSL(select、join、group by、aggregate...),优化器自动做规则优化
- 适用场景:更快开发 、更多逻辑在声明侧完成 、又需要适度扩展(UDF/UDAF/UDTF)
- 特点:表达性 < DataStream 、但编码量更少、可维护性更高
- 与 DataStream 可互转,便于"混合编程"
2.4 最高层:SQL
- 能力:与 Table API 同等语义与表达力 ,用 SQL 语句表达
- 适用场景:团队已 SQL 化、需要极简开发与优化器加持
- 特点:与 Table API 紧密互操作(SQL 在 Table 上运行)
3. 选型建议:用"80/20"原则做决策
| 诉求/场景 | 优先选择 | 说明 |
|---|---|---|
| 需要高度定制的时间/状态/乱序逻辑 | DataStream + ProcessFunction | 可精准控制状态与定时器,掌握可控性 |
| 通用 ETL、指标聚合、维表关联 | Table API / SQL | 开发快、可读性强、优化器友好 |
| 同一作业既有复杂逻辑又有通用分析 | 混合:Table/SQL ↔ DataStream | 在关键环节降级到 ProcessFunction,其他部分走声明式 |
| 希望后期维护成本更低 | Table API / SQL | 规则复杂时更建议 SQL + UDF 组合 |
4. 实战示例
以下示例以 Java 为主(Flink 最常用语言之一),并穿插解释状态/时间要点。若你偏好 Scala/Python,迁移成本很低(API 名称相似)。
4.1 DataStream + KeyedProcessFunction:手写状态与事件时间定时器
目标 :对每个用户计算 10 分钟内的点击数;当 10 分钟"窗口结束"时输出结果。使用事件时间 与Watermark。
java
// 依赖:Flink 1.17+(示例),略去环境构建与 source/sink 初始化
DataStream<Event> events = env
.fromSource(kafkaSource, WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofMinutes(2))
.withTimestampAssigner((e, ts) -> e.getEventTimeMillis()), "kafka")
.name("user-events");
events
.keyBy(Event::getUserId)
.process(new KeyedProcessFunction<String, Event, UserCount>() {
// Keyed State:为每个 key 维护滚动计数与"窗口结束时间戳"
private transient ValueState<Long> countState;
private transient ValueState<Long> windowEndState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Long> countDesc =
new ValueStateDescriptor<>("count", Long.class);
countState = getRuntimeContext().getState(countDesc);
ValueStateDescriptor<Long> endDesc =
new ValueStateDescriptor<>("windowEnd", Long.class);
windowEndState = getRuntimeContext().getState(endDesc);
}
@Override
public void processElement(Event value, Context ctx, Collector<UserCount> out) throws Exception {
// 1) 累加
Long cnt = countState.value();
countState.update((cnt == null ? 0L : cnt) + 1);
// 2) 注册事件时间定时器(基于某个对齐策略:举例为"事件时间的整 10 分钟边界")
long eventTs = value.getEventTimeMillis();
long windowEnd = alignTo10MinBoundary(eventTs);
Long registeredEnd = windowEndState.value();
if (registeredEnd == null || registeredEnd != windowEnd) {
// 清理旧定时器(如果有)
if (registeredEnd != null) {
ctx.timerService().deleteEventTimeTimer(registeredEnd);
}
// 注册新的窗口结束定时器(+1ms 保证在窗口右边界触发)
ctx.timerService().registerEventTimeTimer(windowEnd + 1);
windowEndState.update(windowEnd);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<UserCount> out) throws Exception {
// 定时触发:输出并清空状态
Long cnt = countState.value();
Long windowEnd = windowEndState.value();
if (cnt != null && windowEnd != null && timestamp == windowEnd + 1) {
out.collect(new UserCount(ctx.getCurrentKey(), windowEnd, cnt));
}
countState.clear();
windowEndState.clear();
}
private long alignTo10MinBoundary(long ts) {
long tenMin = 10 * 60 * 1000L;
return ts - (ts % tenMin) + tenMin - 1; // 窗口右闭边界举例(-1 表示本段最后一毫秒)
}
})
.name("per-user-10m-count")
.sinkTo(clickhouseSink);要点解析
- Watermark 决定 事件时间定时器触发时机(允许乱序 2 分钟)。
- 使用
ValueState维护每个key的计数与"当前对齐的窗口结束时间"。 - 这种写法体现了 ProcessFunction 的灵活性:窗口对齐策略、清理策略、触发语义都可按需定制。
4.2 Table API:声明式写 ETL + 聚合
目标:相同逻辑下,改用 Table API,降低编码量并交由优化器处理连接/下推等。
java
// 1) 将 DataStream 注册成动态表(带事件时间与 Watermark)
Table eventTable = tableEnv.fromDataStream(
events,
Schema.newBuilder()
.column("userId", DataTypes.STRING())
.column("eventTime", DataTypes.TIMESTAMP_LTZ(3))
.columnByExpression("ts", "TO_TIMESTAMP_LTZ(eventTime, 3)") // 若已有则略
.watermark("ts", "ts - INTERVAL '2' MINUTE")
.build()
);
// 2) 按 10 分钟滚动窗口聚合
Table result = eventTable
.window(Tumble.over(lit(10).minutes()).on($("ts")).as("w"))
.groupBy($("userId"), $("w"))
.select($("userId"), $("w").end().as("window_end"), $("userId").count().as("cnt"));
// 3) 写出
tableEnv.executeSql(
"CREATE TABLE sink (... WITH (...))"
);
result.executeInsert("sink");要点解析
- 声明式窗口(Tumble/Slide/Session)让时间语义更直接。
- 优化器可对算子进行合并、谓词下推、Join Reorder 等,减少手工优化负担。
- 需要特殊行为时,仍可把某段逻辑"降级"为 UDF/UDTF/UDAF。
4.3 SQL:同一逻辑用 SQL 实现
sql
-- 1) 定义源表(带 watermark 的事件时间列)
CREATE TABLE events (
userId STRING,
eventTime TIMESTAMP_LTZ(3),
WATERMARK FOR eventTime AS eventTime - INTERVAL '2' MINUTE
) WITH (...);
-- 2) 10 分钟滚动窗口聚合
CREATE TABLE sink (... ) WITH (...);
INSERT INTO sink
SELECT
userId,
WINDOW_END AS window_end,
COUNT(*) AS cnt
FROM TABLE(
TUMBLE(TABLE events, DESCRIPTOR(eventTime), INTERVAL '10' MINUTES)
)
GROUP BY userId, WINDOW_START, WINDOW_END;要点解析
- 语义与 Table API 一致,表达最简。
- 与数据平台/BI/规则引擎协作更顺畅。
4.4 DataStream ↔ Table 的无缝互转
- DataStream → Table:用于把已有 Kafka/自定义 Source 数据转成表做 SQL/聚合
- Table → DataStream:需要在下游"回到代码世界"做特殊处理时
java
// DataStream -> Table
Table t = tableEnv.fromDataStream(events, /* 带 schema & watermark */);
// Table -> DataStream(Append 或 Retract 视查询类型而定)
DataStream<Row> out = tableEnv.toDataStream(result);5. 时间与状态的"坑"与最佳实践
-
选对时间语义
- 实时计算默认用 事件时间(Event Time),确保乱序/重放语义正确
- 没有可靠时间戳时才退而求其次用 处理时间(Processing Time)
-
Watermark 策略要保守
- 乱序容忍度(比如 2 分钟)与延迟、吞吐、准确率三者要平衡
- 业务乱序剧烈时,可结合 迟到数据策略(allowedLateness) 与旁路补偿
-
状态治理
- 合理的 State TTL ;按 Key 分布预估 状态量级
- RocksDB 后端适合超大状态;热点 Key 要留意倾斜
- 定期 savepoint/checkpoint ,演进时注意 状态 schema 兼容
-
窗口/触发器语义一致性
- Table/SQL 的窗口更"规范化";手写 ProcessFunction 要明确边界与对齐规则
-
可观测性
- 指标:Busy Time、BackPressure、Checkpoint Duration/Alignment
- DataSkew、Watermark Lag、Record Lag 需要监控告警
6. 混合编程范式示例(推荐套路)
- 总体用 SQL/Table API 写流式 ETL、指标聚合、维表 Join
- 对于个别复杂环节 (如:自定义乱序对齐、复杂 Debounce / Suppress 逻辑),降级到 DataStream + ProcessFunction
- 通过 DataStream ↔ Table 互转把"复杂节点"嵌入到声明式主干中
- 好处:80% 逻辑声明式、20% 难点可控,既保留开发效率也具备工程弹性
7. 小结与行动清单
- 记住三层抽象:ProcessFunction(最低层可塑性)→ DataStream(核心)→ Table/SQL(最高层声明式)
- 优先 Table/SQL 拿下 80% 需求;关键点再降级到 DataStream/ProcessFunction
- 以事件时间为先,保守设置 Watermark,治理状态 TTL 与后端
- 搭建可观测性与回滚策略(Checkpoint/Savepoint)