摘要
Apache Flink 是一个开源的流处理框架,以其高吞吐、低延迟、精确一次处理的特性成为实时计算领域的领导者。本文将从Flink的核心架构、编程模型、容错机制到实际应用场景,全面解析这一新一代大数据计算引擎的技术原理与实践应用,为读者提供从入门到精通的完整指南。
1 流计算演进与Flink的诞生
1.1 大数据计算模式的演进
大数据处理技术经历了从批处理 到流处理的重大转变。传统的批处理系统如Hadoop MapReduce虽然能够处理海量数据,但存在固有的延迟问题,无法满足实时性要求高的业务场景。
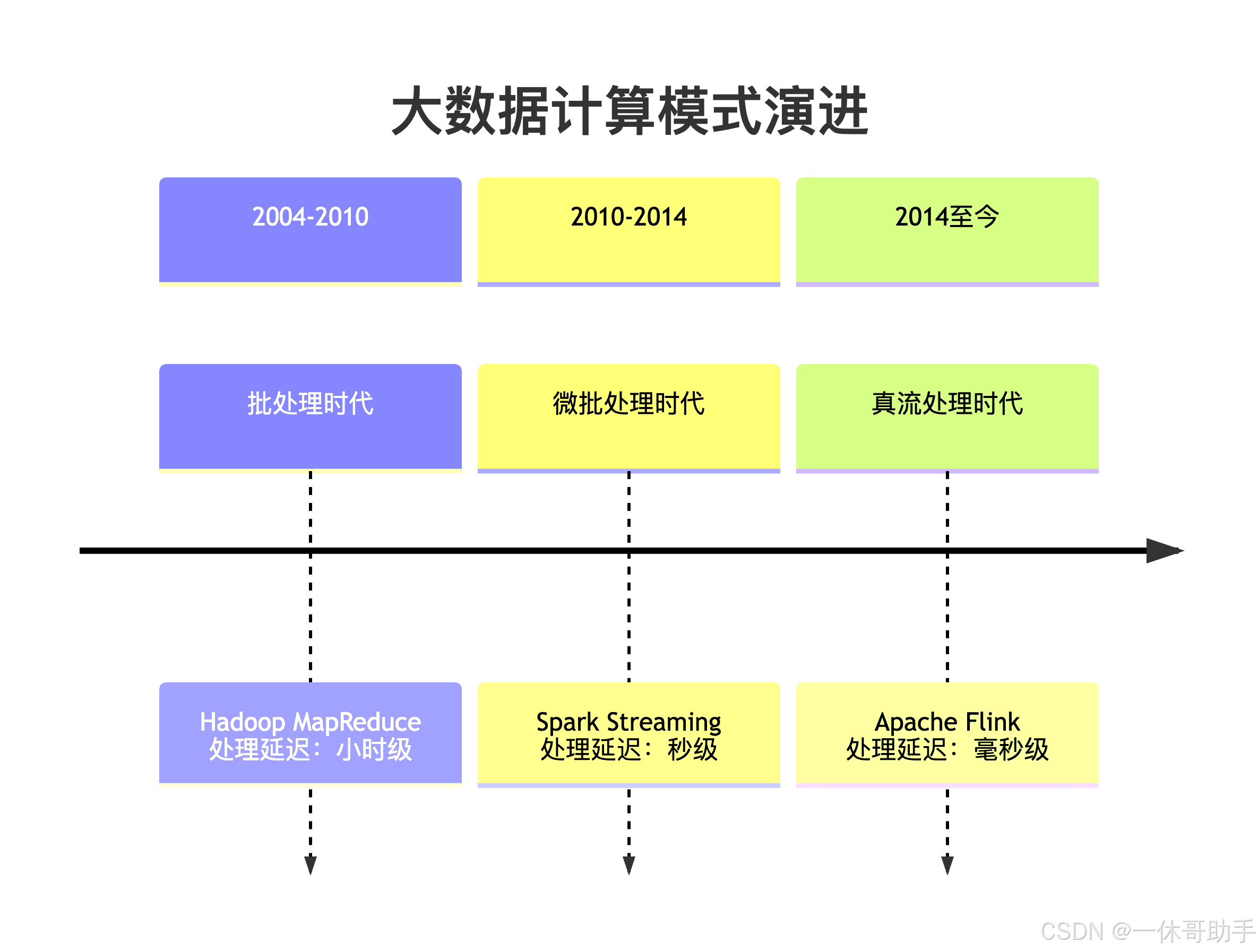
1.2 Flink的发展历程
Apache Flink起源于柏林理工大学的研究项目Stratosphere,2014年成为Apache孵化器项目,2015年晋升为顶级项目。Flink的命名源于德语单词"敏捷",体现了其设计理念------快速、灵活地处理数据流。
Fink的核心里程碑:
- 2014年:进入Apache孵化器
- 2015年:成为Apache顶级项目,发布1.0版本
- 2016年:引入Table API和SQL支持
- 2018年:实现流批一体处理
- 2020年:推出PyFlink,支持Python API
- 2022年:Flink 1.16发布,增强云原生支持
1.3 为什么选择Flink?
与其他流处理框架相比,Flink具有显著优势:
- 真正的流处理:非微批处理架构,实现毫秒级延迟
- 事件时间处理:支持基于事件时间的窗口计算,处理乱序事件
- 精确一次语义:保证数据处理的精确一致性
- 状态管理:内置强大的状态管理机制
- 流批一体:统一的编程模型处理流数据和批数据
2 Flink核心架构解析
2.1 整体架构设计
Flink采用经典的主从架构,包含多个协同工作的组件:
客户端 作业管理器 资源管理器 分发器 任务管理器 任务槽 任务槽 任务 任务
2.1.1 作业管理器(JobManager)
作业管理器是Flink集群的"大脑",负责:
- 接收用户提交的作业
- 将作业图转换为执行图
- 调度任务到任务管理器
- 协调检查点和恢复操作
2.1.2 任务管理器(TaskManager)
任务管理器是工作节点,负责:
- 执行具体的计算任务
- 管理任务槽资源
- 维护本地状态存储
- 与作业管理器通信报告状态
2.1.3 客户端(Client)
客户端不是运行时组件,主要负责:
- 准备和提交作业到作业管理器
- 维护作业的依赖关系
2.2 任务执行模型
Fink的任务执行采用数据流图模型,将计算逻辑表示为有向无环图(DAG):
数据源 Map操作 KeyBy分组 窗口聚合 数据汇
执行图层次结构:
- StreamGraph:根据API调用生成的最初图结构
- JobGraph:优化后的图,包含算子链
- ExecutionGraph:并行化后的执行计划
- 物理执行图:实际在集群上执行的任务图
2.3 内存管理优化
Flink实现了自主的内存管理机制,避免JVM垃圾回收带来的性能波动:
java
// Flink内存配置示例
MemorySize taskHeapSize = MemorySize.ofMebiBytes(1024); // 任务堆内存
MemorySize managedMemorySize = MemorySize.ofMebiBytes(512); // 托管内存
MemorySize networkBufferSize = MemorySize.ofMebiBytes(128); // 网络缓冲区
// 序列化机制优化
TypeInformation<String> typeInfo = BasicTypeInfo.STRING_TYPE_INFO;
Serializer<String> serializer = typeInfo.createSerializer(executionConfig);3 Flink编程模型与API体系
3.1 多层API架构
Flink提供了多层次API,满足不同复杂度的开发需求:
SQL & Table API 声明式编程 DataStream/DataSet API 核心API 状态化流处理 底层构建块
3.2 DataStream API详解
DataStream API是Flink最核心的编程接口,用于处理无界数据流:
java
// 完整的Flink流处理示例
public class RealTimeProcessingJob {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 设置检查点间隔(开启精确一次语义)
env.enableCheckpointing(5000); // 5秒一次
// 定义数据源(从Kafka读取)
DataStream<String> stream = env
.addSource(new FlinkKafkaConsumer<>(
"input-topic",
new SimpleStringSchema(),
properties))
.name("kafka-source");
// 数据转换处理
DataStream<Tuple2<String, Integer>> processed = stream
.flatMap(new Tokenizer()) // 分词
.keyBy(value -> value.f0) // 按单词分组
.window(TumblingProcessingTimeWindows.of(Time.seconds(10))) // 10秒滚动窗口
.sum(1) // 求和
.name("word-count");
// 输出到外部系统
processed.addSink(new FlinkKafkaProducer<>(
"output-topic",
new SimpleStringSchema(),
properties))
.name("kafka-sink");
// 执行作业
env.execute("Real-time Word Count");
}
// 分词器实现
public static class Tokenizer extends
RichFlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
String[] words = value.toLowerCase().split("\\W+");
for (String word : words) {
if (!word.isEmpty()) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}3.3 Table API & SQL
Flink Table API提供了关系型编程模型,大大简化了流处理任务的开发:
java
// Table API 示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 创建数据源表
tableEnv.executeSql(
"CREATE TABLE user_actions (" +
" user_id STRING, " +
" action_type STRING, " +
" action_time TIMESTAMP(3), " +
" WATERMARK FOR action_time AS action_time - INTERVAL '5' SECOND" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'user-actions'," +
" 'properties.bootstrap.servers' = 'localhost:9092'," +
" 'format' = 'json'" +
")"
);
// 执行SQL查询
Table result = tableEnv.sqlQuery(
"SELECT " +
" user_id, " +
" COUNT(*) as action_count, " +
" TUMBLE_END(action_time, INTERVAL '1' HOUR) as window_end " +
"FROM user_actions " +
"GROUP BY user_id, TUMBLE(action_time, INTERVAL '1' HOUR)"
);
// 转换为DataStream输出
DataStream<Result> resultStream = tableEnv.toDataStream(result, Result.class);
resultStream.print();4 Flink核心特性深度解析
4.1 时间语义与窗口机制
Flink提供了丰富的时间概念和窗口类型,满足复杂业务需求:
4.1.1 时间语义
处理时间 数据到达系统时间 事件时间 数据产生时间 注入时间 数据进入Flink时间
事件时间 是Flink的核心优势,通过水印机制处理乱序事件:
java
// 水印生成示例
DataStream<Event> withTimestampsAndWatermarks = stream
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner((event, timestamp) -> event.getCreationTime())
);4.1.2 窗口类型
Flink支持多种窗口类型,适应不同场景:
表:Flink窗口类型对比
| 窗口类型 | 特点 | 适用场景 |
|---|---|---|
| 滚动窗口 | 固定大小,不重叠 | 定期统计(每分钟PV) |
| 滑动窗口 | 固定大小,可重叠 | 移动平均计算 |
| 会话窗口 | 动态大小,基于活动间隔 | 用户会话分析 |
| 全局窗口 | 无界数据,需要触发器 | 自定义聚合逻辑 |
java
// 窗口应用示例
DataStream<SensorReading> sensorData = ...;
// 滚动窗口:每5分钟统计一次
DataStream<SensorAvg> tumblingWindow = sensorData
.keyBy(SensorReading::getSensorId)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.aggregate(new AverageAggregate());
// 滑动窗口:每1分钟输出过去5分钟的平均值
DataStream<SensorAvg> slidingWindow = sensorData
.keyBy(SensorReading::getSensorId)
.window(SlidingEventTimeWindows.of(Time.minutes(5), Time.minutes(1)))
.aggregate(new AverageAggregate());4.2 状态管理与容错机制
4.2.1 状态类型
Fink提供了完善的状态管理机制:
Flink状态 算子状态 键控状态 列表状态 联合列表状态 广播状态 值状态 列表状态 映射状态 聚合状态
键控状态使用示例:
java
public class CountingFunction extends RichFlatMapFunction<String, Tuple2<String, Long>> {
private ValueState<Long> countState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Long> descriptor =
new ValueStateDescriptor<>("count", Long.class);
countState = getRuntimeContext().getState(descriptor);
}
@Override
public void flatMap(String value, Collector<Tuple2<String, Long>> out) throws Exception {
Long currentCount = countState.value();
if (currentCount == null) {
currentCount = 0L;
}
currentCount++;
countState.update(currentCount);
out.collect(new Tuple2<>(value, currentCount));
}
}4.2.2 检查点与保存点
Flink通过分布式快照算法实现容错:
- 检查点:定期生成的故障恢复点,自动管理
- 保存点:用户触发的全局状态快照,用于版本升级等场景
java
// 检查点配置
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每5秒生成一个检查点
env.enableCheckpointing(5000);
// 精确一次语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 检查点超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同时保留的检查点数量
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);4.3 精确一次语义实现
Flink通过两阶段提交协议实现端到端的精确一次语义:
JobManager TaskManager1 TaskManager2 外部系统 发起检查点 制作本地快照 预提交事务 预提交确认 快照完成 通知全局提交 提交事务 提交确认 JobManager TaskManager1 TaskManager2 外部系统
5 Flink部署与运维
5.1 部署模式详解
Flink支持多种部署模式,适应不同环境需求:
5.1.1 独立集群部署
bash
# 下载Flink
wget https://archive.apache.org/dist/flink/flink-1.16.0/flink-1.16.0-bin-scala_2.12.tgz
tar -xzf flink-1.16.0-bin-scala_2.12.tgz
cd flink-1.16.0
# 启动集群
./bin/start-cluster.sh
# 提交作业
./bin/flink run ./examples/streaming/WordCount.jar5.1.2 YARN部署
bash
# Session模式
./bin/flink run -m yarn-cluster -yn 2 -ys 1024 -yjm 1024 ./examples/streaming/WordCount.jar
# Per-Job模式(已弃用,推荐Application模式)
./bin/flink run-application -t yarn-application \
-Djobmanager.memory.process.size=1024m \
-Dtaskmanager.memory.process.size=1024m \
./examples/streaming/WordCount.jar5.1.3 Kubernetes部署
yaml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: word-count
spec:
image: flink:1.16.0
flinkVersion: v1_16
image: flink:1.16.0-scala_2.12
serviceAccount: flink
jobManager:
resource:
memory: "2048Mi"
cpu: 1
taskManager:
resource:
memory: "2048Mi"
cpu: 1
replicas: 2
job:
jarURI: local:///opt/flink/examples/streaming/WordCount.jar
parallelism: 25.2 监控与调优
5.2.1 关键监控指标
- 吞吐量:每秒处理记录数
- 延迟:记录从产生到处理的时间
- 背压:数据流动受阻情况
- 检查点:持续时间、大小、间隔
5.2.2 性能调优策略
java
// 性能优化配置示例
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度设置
env.setParallelism(4);
// 缓冲区超时(吞吐量与延迟的权衡)
env.setBufferTimeout(100);
// 对象重用模式(减少序列化开销)
env.getConfig().enableObjectReuse();
// 时间特性(使用事件时间)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);6 Flink应用场景与实践案例
6.1 实时ETL与数据管道
Flink在实时数据管道中表现出色,替代传统的批处理ETL:
java
// 实时ETL示例:数据清洗和转换
public class RealTimeETLJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka读取原始数据
DataStream<String> rawData = env.addSource(
new FlinkKafkaConsumer<>("raw-data", new SimpleStringSchema(), props));
// 数据清洗和转换
DataStream<CleanData> cleanData = rawData
.filter(new DataQualityFilter()) // 数据质量过滤
.map(new DataTransformer()) // 数据转换
.keyBy(CleanData::getUserId)
.process(new Deduplication()) // 数据去重
.name("data-cleansing");
// 输出到多个目标系统
cleanData.addSink(new ElasticsearchSink<>(esSinkConfig)); // 到Elasticsearch
cleanData.addSink(new JDBCSink(jdbcUrl, username, password)); // 到关系数据库
env.execute("Real-time ETL Pipeline");
}
}6.2 实时风控与异常检测
利用Flink的复杂事件处理能力实现实时风控:
java
// 实时风控示例:检测异常交易模式
public class FraudDetectionJob {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Transaction> transactions = ...;
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getUserId)
.process(new FraudDetectionPattern())
.name("fraud-detection");
// 复杂模式:检测短时间内多次大额交易
public static class FraudDetectionPattern
extends KeyedProcessFunction<String, Transaction, Alert> {
private transient ValueState<Long> lastTransactionTimeState;
private transient ValueState<Double> totalAmountState;
@Override
public void open(Configuration parameters) {
// 状态初始化
}
@Override
public void processElement(Transaction transaction, Context ctx,
Collector<Alert> out) throws Exception {
// 风控逻辑实现
if (isSuspiciousPattern(transaction)) {
out.collect(new Alert(transaction, "SUSPICIOUS_PATTERN"));
}
}
}
}
}6.3 实时数仓与OLAP分析
Flink + Apache Doris构建实时数仓架构:
业务数据库 CDC采集 Flink ETL 实时聚合 Apache Doris BI工具 实时报表
7 Flink生态系统与集成
7.1 连接器生态
Flink拥有丰富的连接器生态系统:
表:常用Flink连接器
| 类型 | 连接器 | 特点 |
|---|---|---|
| 消息队列 | Kafka | 高性能,精确一次支持 |
| 数据库 | JDBC | 通用关系数据库连接 |
| 数据湖 | Apache Iceberg | 湖仓一体支持 |
| 搜索引擎 | Elasticsearch | 实时索引更新 |
| 文件系统 | HDFS/S3 | 大数据存储支持 |
7.2 与其它技术的集成
7.2.1 Flink + Apache Kafka
java
// 精确一次的Kafka集成
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-consumer");
properties.setProperty("isolation.level", "read_committed");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"input-topic",
new SimpleStringSchema(),
properties);
// 从最早位置开始读取(故障恢复时)
consumer.setStartFromEarliest();7.2.2 Flink + Apache Hive
java
// Hive集成示例
String name = "myhive";
String defaultDatabase = "mydatabase";
String hiveConfDir = "/opt/hive-conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
tableEnv.useCatalog("myhive");8 Flink未来发展与趋势
8.1 云原生演进
Flink正在向云原生架构演进:
- 容器化部署:更好的Kubernetes集成
- 弹性伸缩:基于负载的自动扩缩容
- 多租户支持:资源隔离和配额管理
8.2 流批一体深化
流批一体技术继续深化:
- 统一存储:同一份数据支持流批处理
- 统一计算:相同的SQL语义处理历史和实时数据
- 统一服务:一致的查询接口
8.3 AI与流计算融合
机器学习与流计算的深度集成:
- 在线学习:模型在数据流上实时更新
- 流式特征工程:实时特征提取和计算
- 智能流处理:AI增强的流处理逻辑
9 结论
Apache Flink作为第三代流处理引擎的领导者,通过其先进的架构设计 、完善的状态管理 和强大的容错机制,为实时数据处理提供了业界领先的解决方案。无论是简单的数据ETL还是复杂的事件驱动应用,Flink都能提供高性能、高可靠的处理能力。
随着流处理技术的普及和实时性要求的提高,Flink在实时数仓 、风控系统 、IoT数据处理 等场景中的应用将越来越广泛。其流批一体的理念 和云原生架构的方向,也代表了大数据技术发展的未来趋势。
对于技术团队而言,掌握Flink不仅意味着能够构建更高效的实时数据处理系统,更是面向未来技术竞争的重要能力。随着Flink生态的不断完善和社区的持续活跃,这一技术必将在数字化转型中发挥更加重要的作用。
参考文献
- Apache Flink官方文档
- "Stream Processing with Apache Flink" - Fabian Hueske, Vasiliki Kalavri
- Flink Forward大会技术分享
- Apache Flink源码分析
- 实时计算技术架构实践
- 流批一体技术白皮书