当AI与数字孪生深入工厂的每个角落,当"数据是石油"成为所有制造业者的共识,一个更根本的问题也随之浮现:我们坐拥的数据矿藏,为何难以转化为驱动增长的真实动能?数据的洪流之下,为何依然是决策的沙漠?
制造跃迁四十年,数据卡点待破局
回顾过去40年,中国制造业经历了四次重要跃迁:
工业化早期 (1978-1995)靠资源、劳动力与外向加工;工业化中期 (1995-2010)规模化制造崛起,成为全球制造中心;信息化阶段 (2010-2015)精益生产与ERP/MES普及;数字化转型期 (2015-2020)数据成为关键资源;智能制造时代(2020至今)AI、大模型、数字孪生进入制造现场。
用一句话总结演进路径:
制造业从"以产量为核心"走向"以数据为核心"。
那么,制造业的数据究竟从何而来,又是如何流动的?
纵观制造企业的实践,数据来源虽丰,但大抵可分为两类。第一类是企业内部信息化系统产生的数据,它们如同企业的"神经网络",记录着每一个业务动作、工艺参数与设备运行,构成了最庞大、最连续、最结构化的数据资源池。第二类则来自企业内外协同过程,包括内部从研发到生产、从计划到仓储的端到端数据流转,也包括外部与供应商、客户在订单、交付、物流等方面的数字化协同。
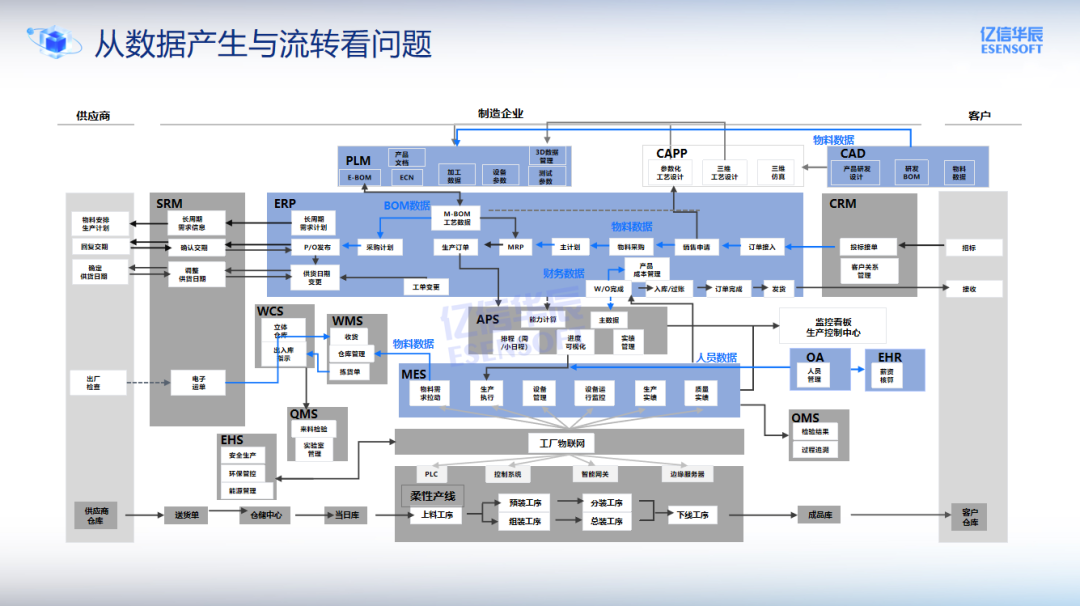
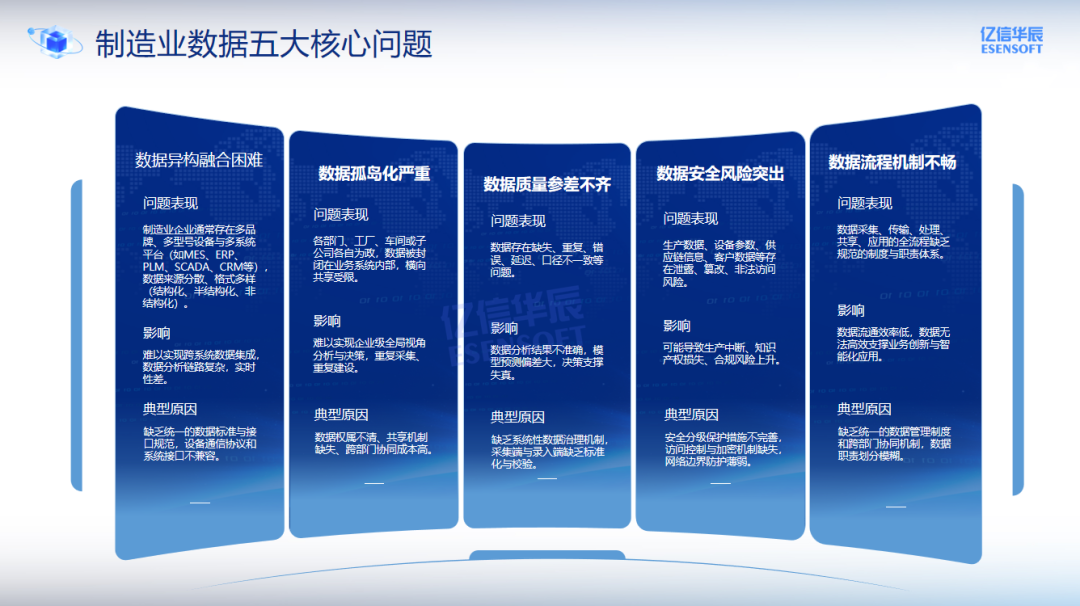
尽管数据的重要性已成为共识,制造业在数据化道路上仍面临5大共性"卡点":数据异构融合困难 ,不同系统、协议、格式导致数据难以打通;数据孤岛化严重 ,工厂、部门、系统间各自为政;数据质量参差不齐,缺失、错误与口径不一直接影响成本与决策精度;数据安全风险突出,导致生产中断、知识产权损失、合规风险上升;数据流程机制不畅,导致数据责任不清、共享困难、价值链条断裂,难以形成有效的数据运营闭环。
从"数据资源"到"数据动能"的三步走
如何突破这些瓶颈,实现从"数据资源"向"数据动能"的转变?亿信华辰认为,企业可以分三步走:
第一步:夯实底座(数据资源化)
第二步:打通链路(数据资产化)
第三步:形成闭环(数据动能化)
以上三步构成了制造业数据动能化的核心路径------从"存量积累"到"价值流动",再到"生态共生"。具体来看:
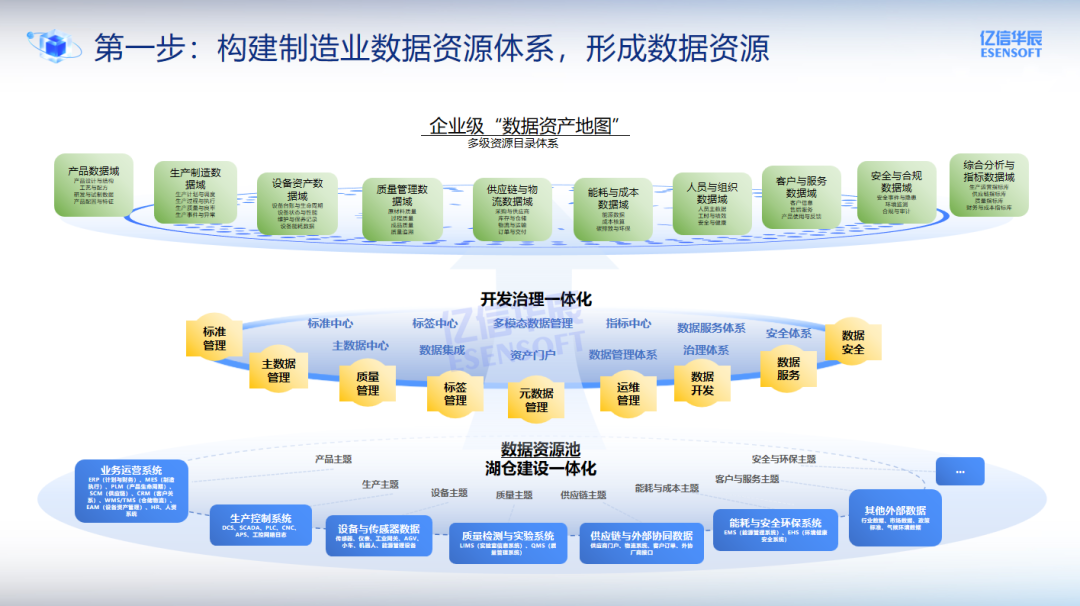
第一步是夯实底座,构建制造业数据资源体系,形成数据资源。
这一步是打好基础,通过"湖仓一体化"构建数据存储底座,再以"开发治理一体化"提升数据质量与安全,最后借"资源目录体系"实现数据的归集与管理,让数据真正"找得到、用得上、可信赖"。
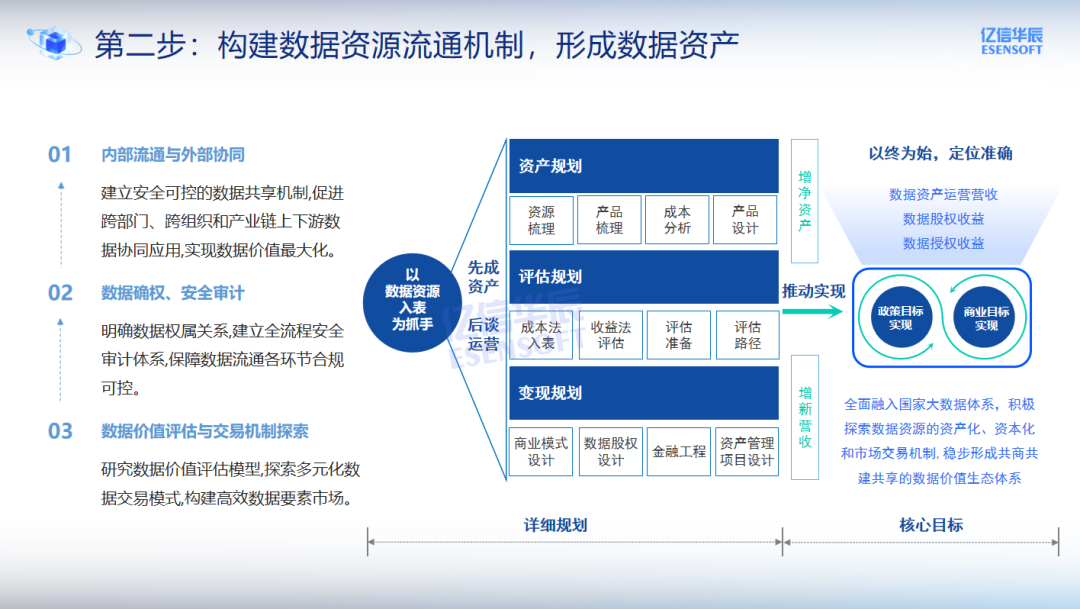
第二步是打通链路,构建数据资源流通机制,形成数据资产。
这一步是让数据流动起来。在企业内部,要打破部门与系统壁垒,实现全流程互联;在产业层面,要推动上下游之间的数据共享,实现"数据共赢"。同时,需建立数据确权、分级分类与安全审计机制,为数据的市场化运营奠定基础。
第三步是形成闭环,构建数据驱动的智能制造场景。
从研发、生产、供应链到销售与服务,在每个环节中嵌入由数据与算法驱动的智能应用。这意味着数据必须与算法、技术紧密结合,否则即便拥有海量数据,也可能陷入"看得见,用不上"或"算得动,算不准"的困境,甚至出现"数据空转"------为智能而智能,却无实际价值。
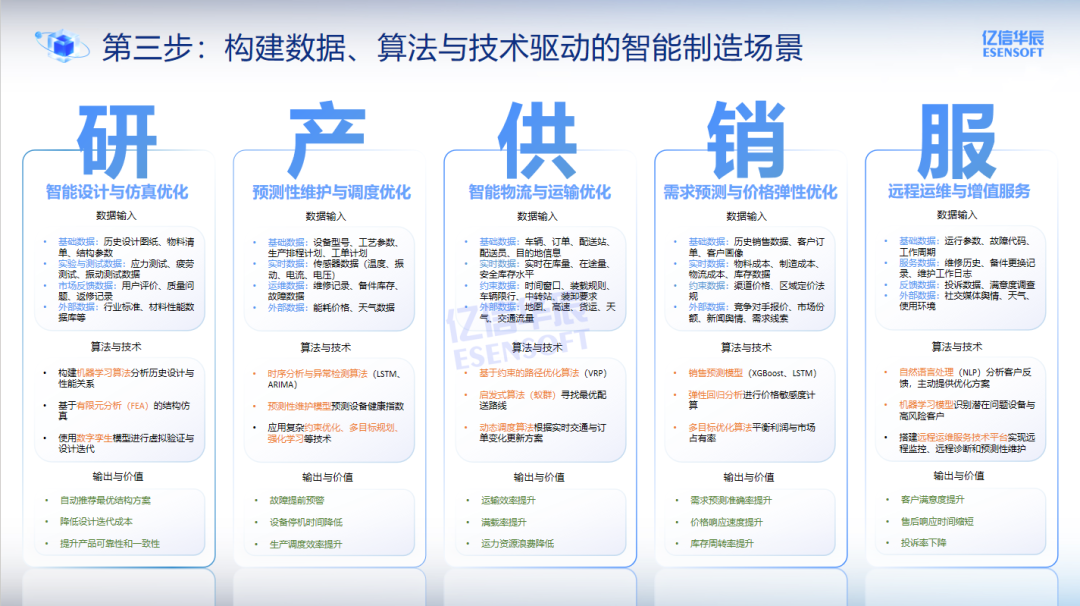
关键在于实现"场景与能力的平衡"。企业不能盲目追求高难度、全覆盖,而应基于自身的信息化水平,选择合适场景,围绕高成本、高敏感、可量化ROI的环节优先攻坚,并坚持"试点验证---价值复用---逐步推广"的路径。智能应用并非越多越好、越新越好,真正的价值来自于:场景选对、数据打好、算法用准、持续运营。
构建可持续的数据动能体系:四层并进
而要实现这一目标,绝不能仅靠技术单点突破或某个部门独自推动。制造业要构建可持续的数据动能体系,必须依靠 "战略、技术、业务、管理"四层并进的系统工程。

第一,战略层:定方向、划边界、立机制。
企业要从战略上明确:数据是资源,更是生产要素,是未来增长的核心动力。这意味着需要:制定企业级的数据战略与总体路线图,明确数据在研发、生产、供应链、服务中的战略定位,组建 CDO 或数据委员会,形成跨部门统一协调机制,将数据价值纳入企业 KPI 与业务考核中。许多领先的制造企业,如宁德时代、美的、三一重工,都是从"战略牵引"开始做数据动能的。
第二,技术层:搭底座、强治理、建能力。
技术层是整个数据动能体系的地基,没有这层能力,所有场景都无法真正落地。包括三个关键能力:
1)搭建数据治理体系,包括主数据、元数据、数据质量、数据分级分类等,这是国家政策正在强力推进的核心要求。
2)搭建数据中台与数据湖仓体系,实现跨部门、跨工厂的数据汇聚、加工、共享,从"系统烟囱"走向"数据共享服务"。
3)建立AI算法与智能平台能力,包括质量预测、排产优化、预测性维护、数字孪生、工艺优化等能力。因为没有算法,就没有"动能"。
第三,业务层:抓场景、出价值、建闭环。
业务层是数据动能体系真正释放价值的地方,必须做到"价值驱动,而不是技术驱动"。我们通常建议从五大关键价值链切入:
-
研发:仿真优化、工艺知识库、参数推荐
-
生产:预测性维护、能耗优化、良率提升
-
供应链:智能排产、智能补货、运输优化
-
销售:需求预测、渠道优化
-
服务:远程运维、备件预测、设备健康评分
每个场景都遵循"闭环原则":业务问题 → 数据 → 模型 → 决策 → 执行 → 反馈。只有真正带来 ROI 的场景,才值得扩展。
第四,管理层:保安全、强制度、育人才。
这一层是保障体系,也是很多企业智能化转型中最容易忽略的部分。管理层需要做的包括:建立数据安全与隐私保护的全链路机制,完成数据所有权、使用权、责任权三权分离,将数据治理纳入制度、流程和审计体系;同时要建立数据人才体系,提升业务人员数据素养,让他们会提需求、会用数据。
战略层决定往哪走,技术层决定能不能干,业务层决定值不值,管理层决定走多远。这四层协同,正是国家在《制造业数字化转型行动方案》与《数字中国建设总体布局规划》中反复强调的推进逻辑:数字化转型需要顶层设计、技术支撑、业务牵引和制度保障的协同推进。
全栈能力:从数据采集到智能应用
归根结底,制造业需要的不是某一个工具或一类技术,而是一套覆盖"数据采集→治理→汇聚→分析→智能→应用"的完整能力链条。只有基础与应用相匹配、场景与能力相平衡,制造企业才能跨越从"资源"到"动能"的价值鸿沟,真正让数据成为高质量发展的核心引擎。
在这方面,亿信华辰的产品体系是全栈式、覆盖式的,能够助力企业从数据资源阶段,一路走到数据动能阶段。
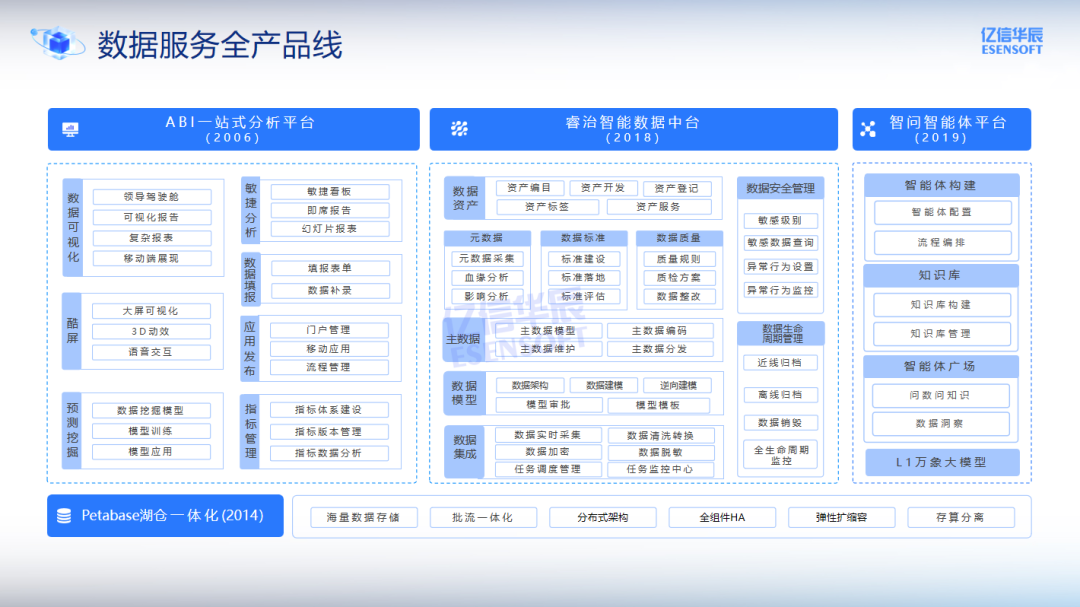
第一,用 Petabase 构建企业的湖仓一体化数据底座。湖仓一体化是现在业内最主流的数据体系架构,它既能支持结构化数据,又能支持半结构化、时序数据、图数据等全类型数据。通过 Petabase,帮助客户实现:全域数据汇聚、批流一体处理、多引擎协同、万级并发、海量存储、高性能分析与建模、一句话,就是帮助企业把"散乱的数据资源"沉淀成"规范化的数据底座"。
第二,用睿治智能数据中台,实现"开发+治理一体化"。数据多,并不等于数据能用。要让数据成为资产,需要治理体系。这是从"数据资源"走向"数据资产"的关键一步。
第三,用ABI一站式分析平台,让数据真正服务业务决策。ABI 不只是一个报表工具,而是一个企业级经营分析平台。让数据进入会议室,让数据进入管理层,让数据进入每一次决策。
第四,通过"智问"智能体平台,与企业共同探索智能化应用场景。帮助企业真正迈向"智能决策""智能协同""智能运营"的阶段。
我们正迎来一个数据驱动制造的新时代------这条路没有终点,只有不断优化的循环。让数据流动起来,让制造智能起来,是中国制造迈向高质量未来的必然选择。