引言
在移动互联网时代,用户界面(UI)作为连接用户与数字世界的桥梁,其重要性不言而喻。每一次应用程序的启动与页面的加载,本质上都是一次 UI 的呈现过程,其设计质量不仅直接影响用户体验,更与业务转化效果紧密相连。
近年来,学术界和产业界也开始关注 UI 领域的专用模型,例如苹果的 Ferret UI、微软的 OmniParser,以及论文中提出的 Web2Code、DCGen 等方法。然而,这些研究大多聚焦于单一任务:要么侧重于理解 UI,要么侧重于生成 UI。
支付宝体验技术部正式发布并开源首个将 UI 理解与 UI 生成两大核心能力统一起来的 UI 领域垂类多模态大模型 UI-UG(A Unified MLLM for UI Understanding and Generation), 这一创新不仅填补了行业空白,更在理解和生成场景中均展现出卓越性能。
UI-UG-7B 模型现已正式开源:
-
HuggingFace:huggingface.co/neovateai/U...
-
Github:github.com/neovateai/U...
模型介绍:UI 智能新范式
UI 理解与生成:天生一对的孪生任务
为什么选择将理解与生成结合?UI-UG 的核心思想是:这两项任务并非孤立存在,而是相辅相成、信息共享的共同体。
在 UI 生成过程中,模型需要深刻理解参考图片的布局、色彩、文字内容和元素类别;而在 UI 理解任务中,对 UI 高层次结构信息的认知,恰恰又受益于生成任务所训练出的结构化思维。后续的实验数据也印证了这一观点:将理解与生成混合训练,效果显著优于各自单独训练。
UI-UG 四大核心能力
UI-UG 大模型具备全面覆盖 UI 核心场景的四大能力:指代(Referring)、检测(Grounding)、描述(Captioning)、生成(Generation)。
指代(Referring):精准描述图片指定区域内容,包括识别 UI 元素类型(如按钮、图标、弹窗)、提取 OCR 文字、识别颜色值等。例如,可准确回答"描述一下这个区域的 UI 类型"。
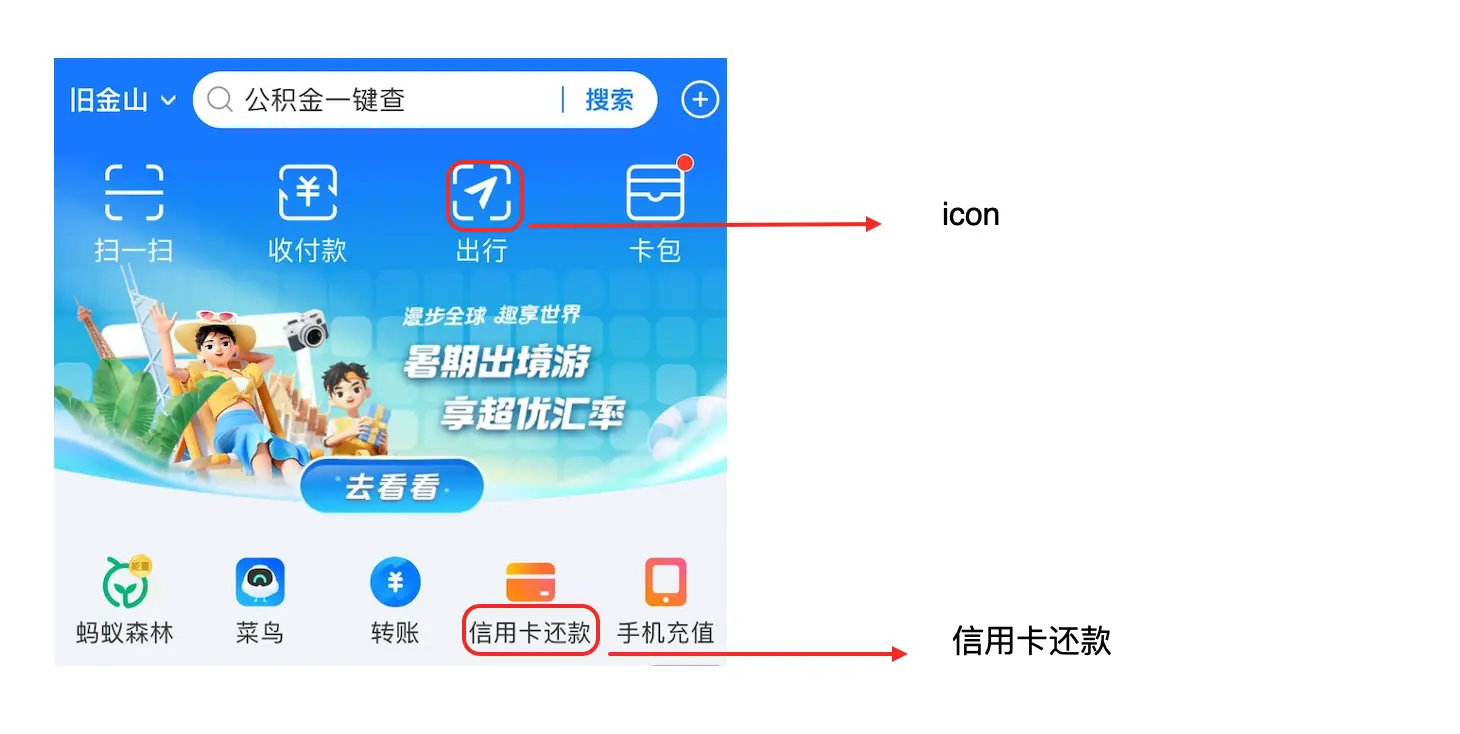
检测(Grounding):全面检测图片中所有 UI 元素,或定位特定类型元素。同时也能识别基础组件(文本、图片、icon 等)及交互元素(关闭按钮、返回按钮等),为自动化操作提供基础。
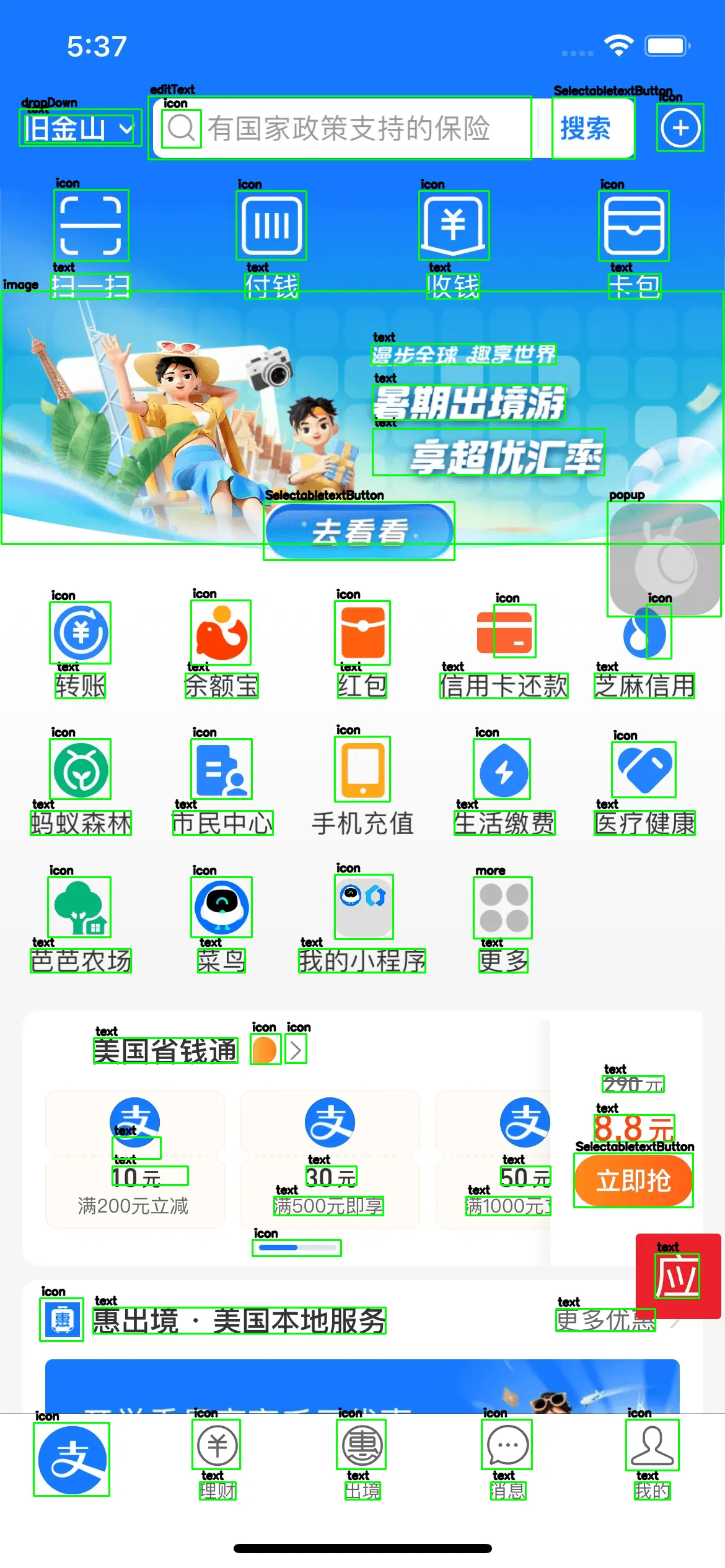
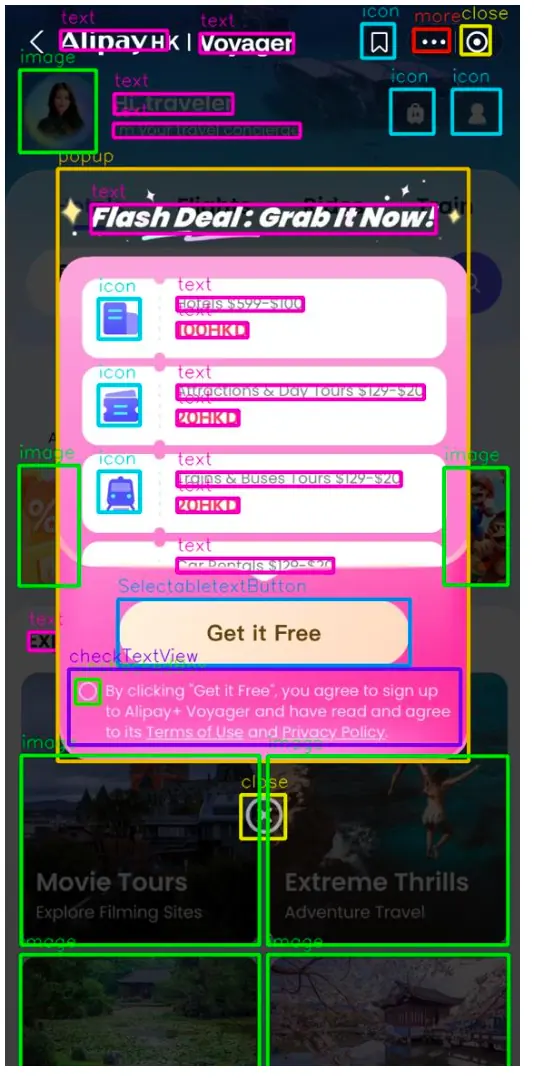
描述(Captioning):结构化描述整张 UI 图片内容,输出遵循特定格式规范,为后续分析和生成提供信息基础。
生成(Generation):基于文本描述和参考图片,生成特定 UI DSL 代码。支持动态数据绑定与渐进式渲染,可生成带 Mock 字段的灵活模板。在支付宝内部实测中,卡片级 UI 生成速度最快可达 5 秒,效率提升显著。

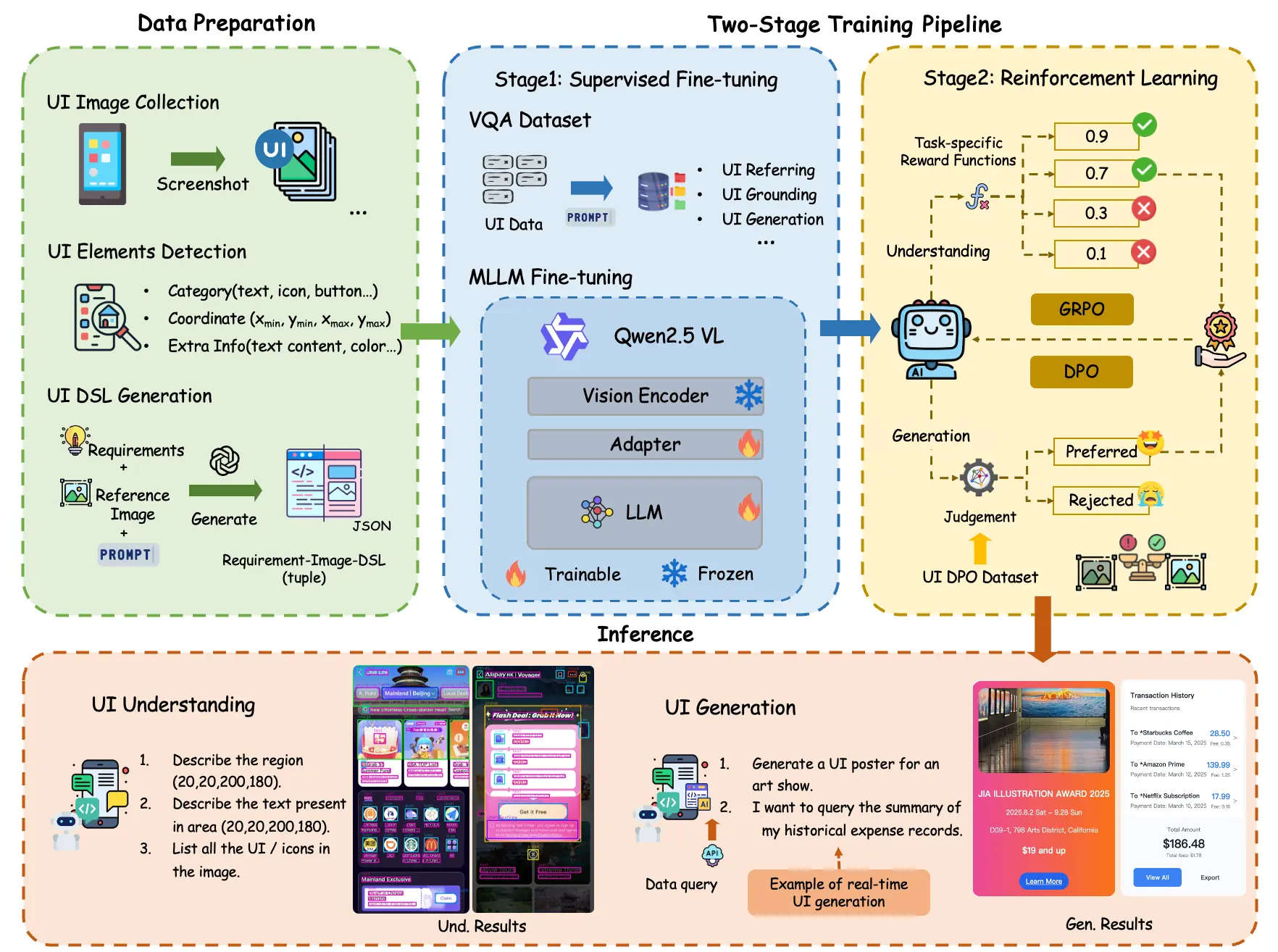
技术突破:数据、训练与优化的三重创新
UI-UG 的整个工作流主要数据准备和两阶段的训练(监督微调 SFT 和强化学习 RL),在数据、训练和优化多阶段有了创新。
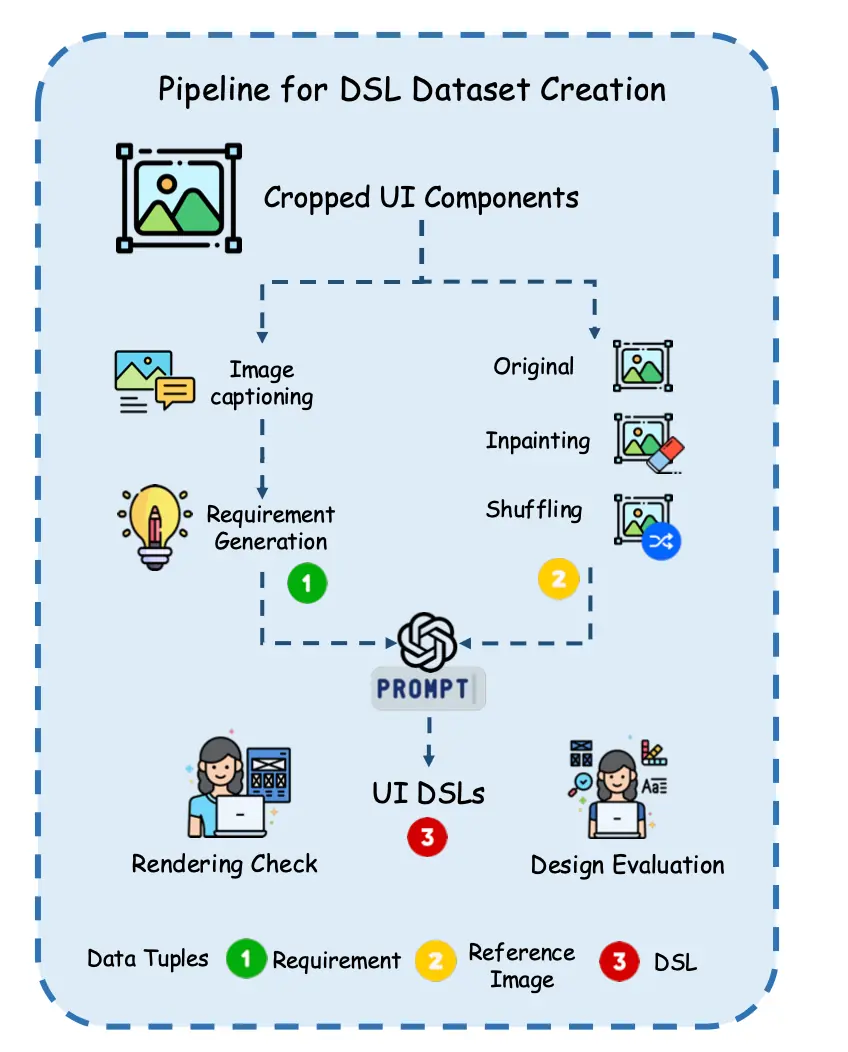
数据构建:贴合真实场景的多元数据集
面对 UI 分辨率提升和设计复杂度增加带来的挑战,UI-UG 放弃了过时的开源数据集,基于海量业务场景构建全新数据:
数据包括超 30,000 张 UI 页面,涵盖多业务领域,并通过视觉 Embedding 模型编码去重确保多样性。扩展 UI 类型定义,新增弹窗、复选框等高频组件,特别强化对交互元素的标注。采用 CV 模型预标注 + 人工校验模式,高效构建高质量 UI 元素数据集。
针对 UI 生成任务,UI-UG 创新设计了一条数据构造流水线:将页面裁剪为卡片级组件,用能力强的通用多模态模型(如 Qwen2.5-VL-72B)生成组件描述,模拟用户需求并生成 UI。UI 生成任务采用了 UI DSL(而非端到端代码)方案,兼顾多端适配能力与流式渲染优势。在数据集准备过程中,通过文本擦除和风格混合技术,增强模型风格迁移能力。
两阶段训练:从基础学习到精准优化
监督微调(SFT)阶段:基于 Qwen2.5-VL-7B 模型,冻结 ViT 模块,专注训练 LLM 和视觉-语言适配器。使用 18 万条 VQA 数据,在 8 块 A100 GPU 上训练 3 轮。
强化学习阶段:针对 SFT 阶段的不足进行专项提升:
-
指代任务:采用 GRPO 方法,聚焦 8 类难样本组件(如可选文本按钮、关闭按钮),优化分类准确率和格式遵循性。
-
定位任务:采用 GRPO 方法,创新使用双 IoU 奖励机制,同步优化召回率与精确率。
-
生成任务:采用 DPO 方法,基于四大维度(视觉结构、色彩美学、文本一致性、交互性)构建 8000 组对比偏好数据进行偏好学习,显著提升生成质量。
最终模型依次经过 DPO(生成)、GRPO(指代)、GRPO(定位)优化,完成强化学习训练。
实验验证:超越通用模型,领跑垂直领域
在实验的部分,我们从 UI 理解和 UI 生成两个任务出发,与其他模型做了对比。对比的模型包括通用多模态大模型(包括 GPT-4o、Claude 3.7 Sonnet、Gemini 2.5 Pro 等闭源模型,以及 Qwen2.5-VL 系列的开源模型)和一些知名的 UI领域专用模型(苹果的 Ferret-UI2 和微软的 OmniParser V2)。同时我们也对我们自己的模型进行了消融实验对比,包括不同的数据准备、SFT 的优化策略,以及使用强化学习前后的表现差异等。
UI 理解任务全面领先
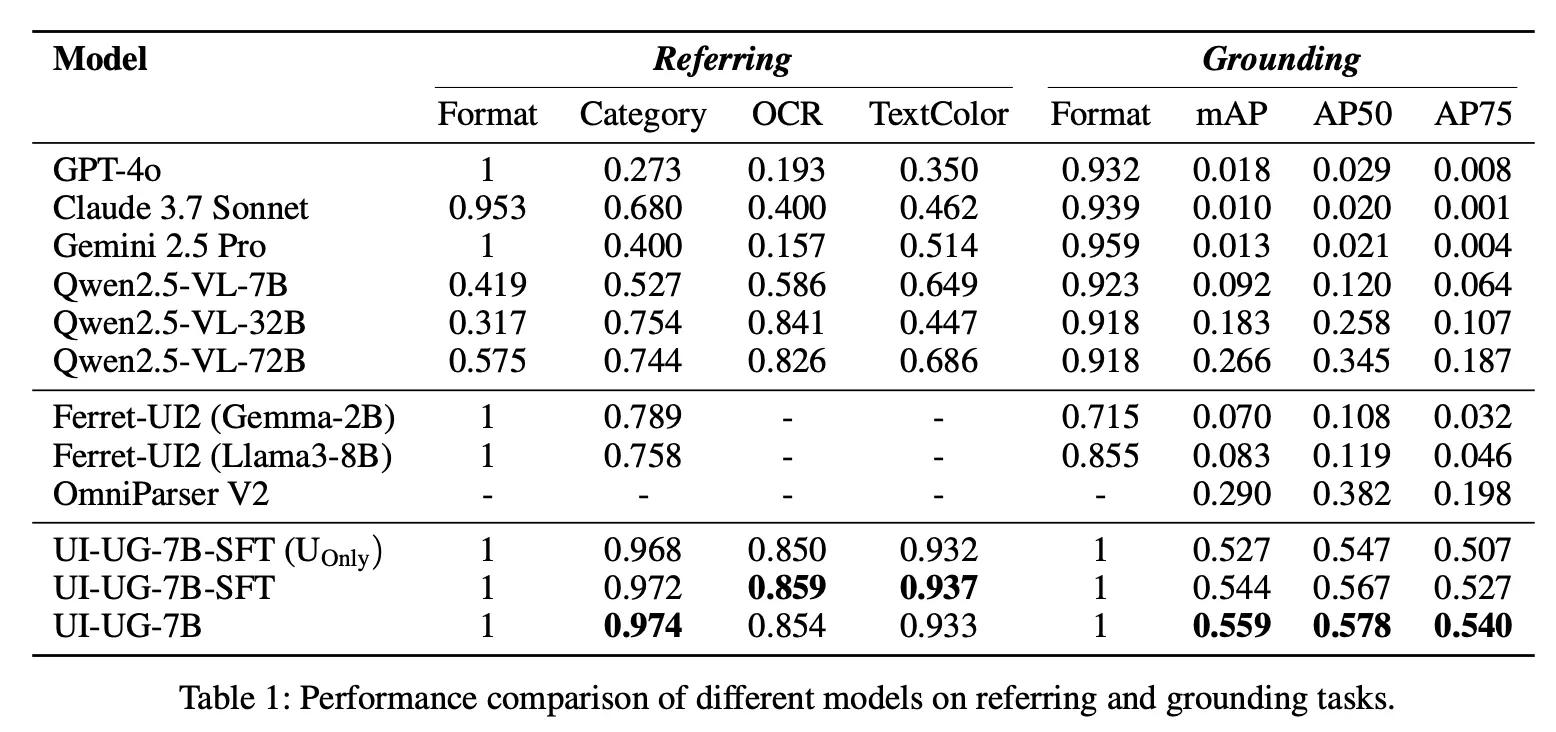
在指代任务中,UI-UG 在元素分类、OCR 识别、颜色识别准确率上均达 SOTA:
-
显著超越 GPT-4o、Claude 3.7、Gemini 2.5 等闭源模型(后者在区域感知和罕见元素识别上表现极其薄弱)
-
Referring 任务明显优势领先同为 UI 专用的 Ferret-UI2,检测 mAP 值超 OmniParser V2 等传统视觉模型
在定位任务中,UI-UG 同样达到 SOTA 水平。另外强化学习带来显著提升:检测 mAP 提升 4.6%,边界框精度优化明显。可视化对比显示,UI-UG 对细小元素和复杂布局的识别能力显著优于竞品。
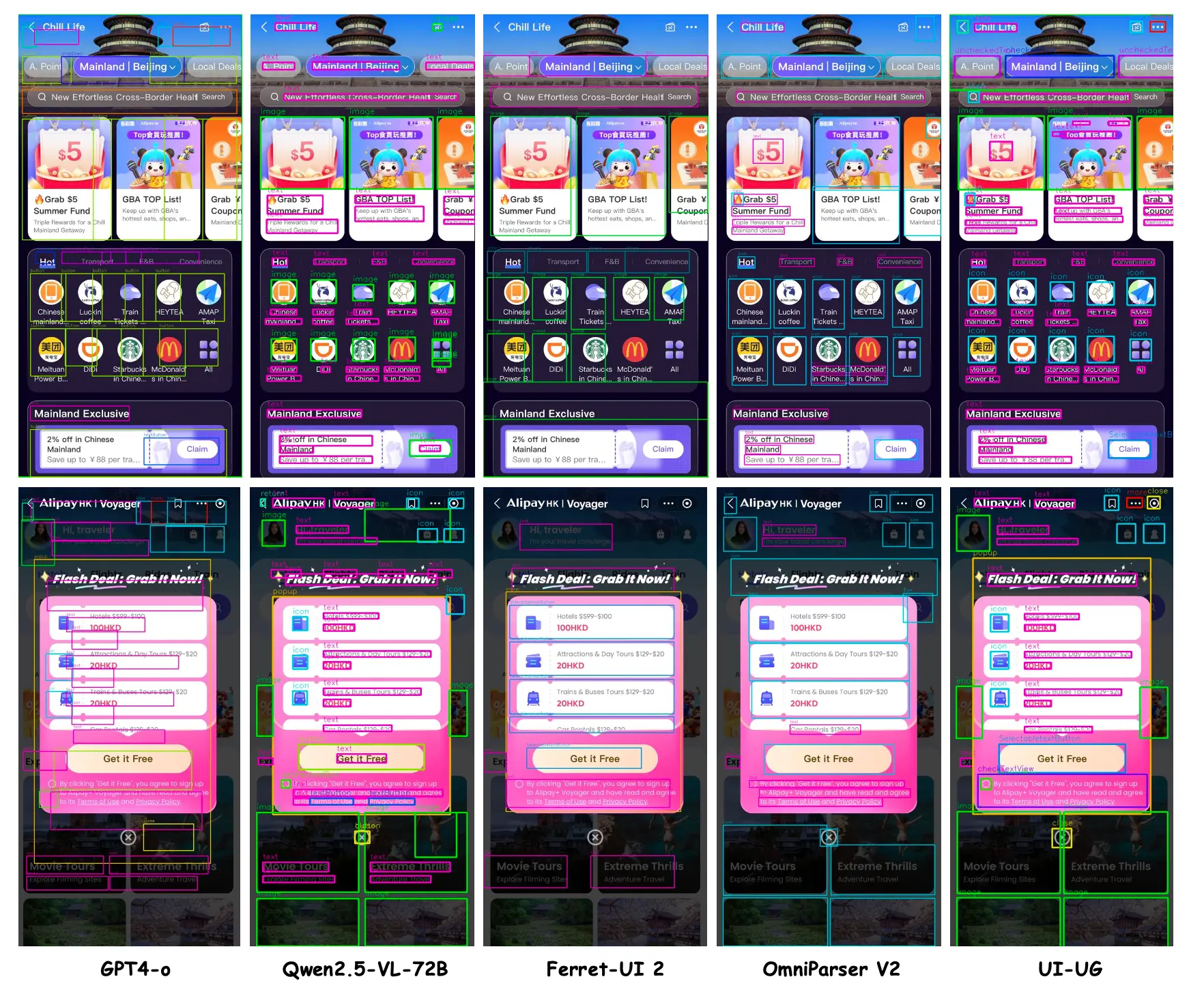
UI 生成任务效率与质量获得平衡
在六维生成评估体系(格式正确率、视觉相似性、MLLM as Judge 的四大 UI 生成维度)中:
-
格式稳定性得分第一,保障了工业级可用性
-
DPO 训练使生成质量评分提升 14.5%(36.7 → 42.02)
-
UI 生成质量接近数据源模型 Qwen2.5-VL-72B,但速度提升4-6倍
-
部署在 2 块 Nvidia L20 GPU 上,平均响应时间 5-6 秒(其他通用大模型需 20-30 秒)
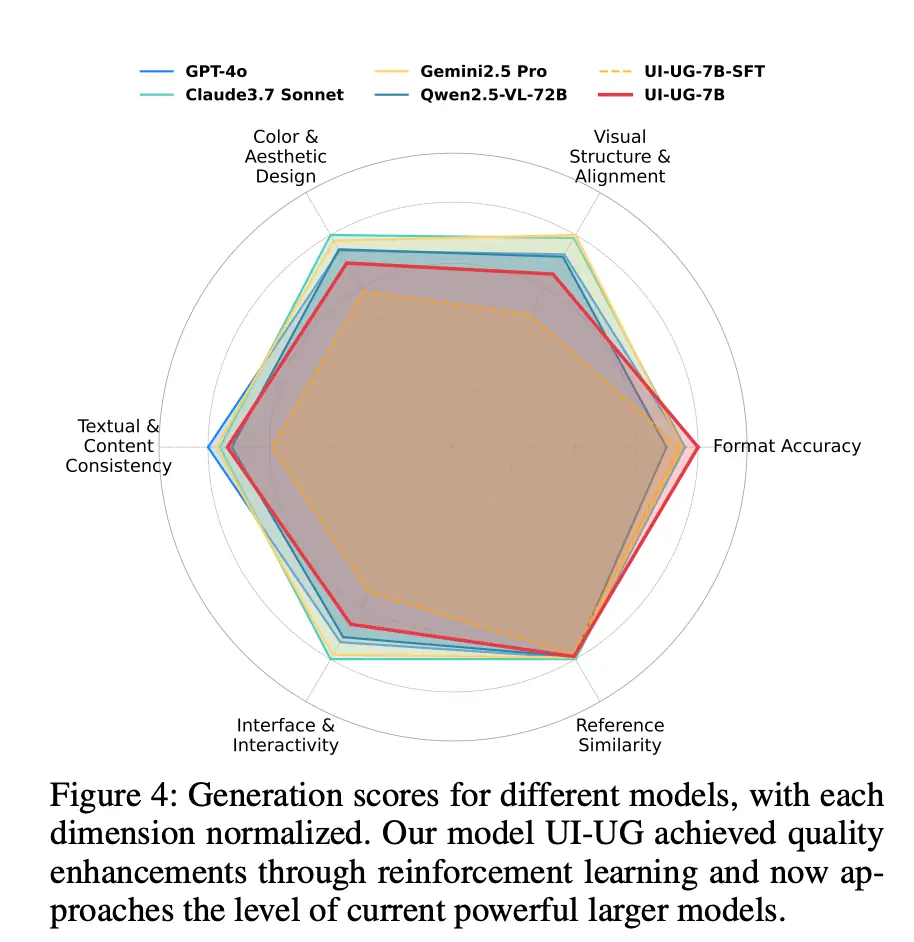
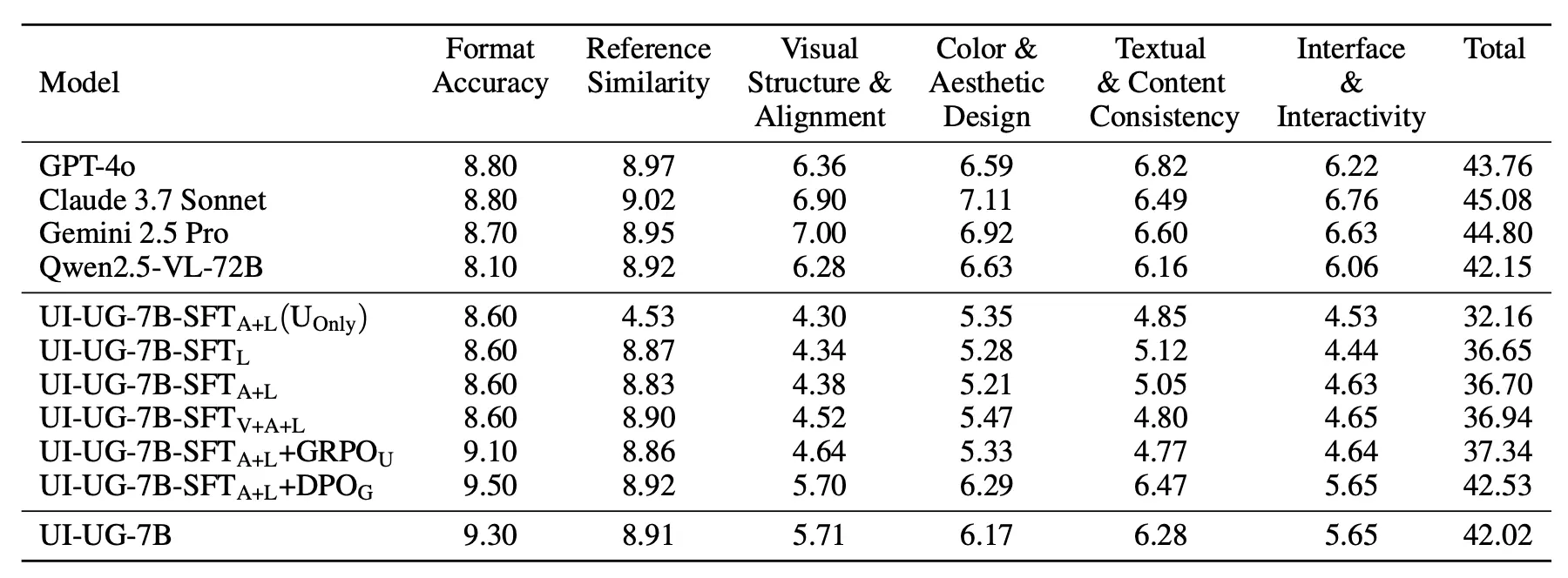
关键洞察:协同训练的价值验证
消融实验证明技术路线的科学性:
-
Adapter+LLM 微调策略实现最佳平衡
-
混合训练数据下,UI 理解任务和 UI 生成任务均有提升
-
GRPO/DPO 在各自主攻任务上带来明显的指标提升
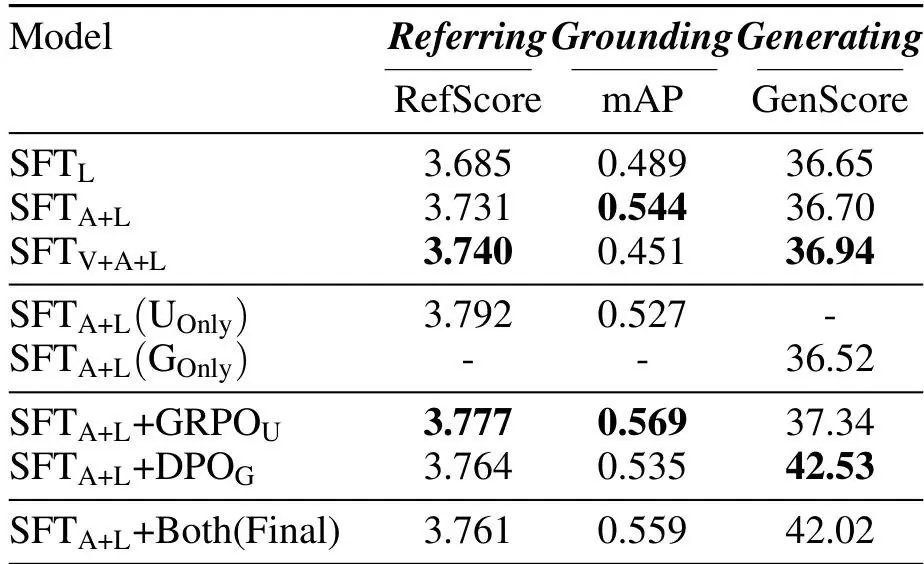
展望未来:持续进化之路
未来 UI-UG 也将继续进化迭代,目前主要计划的方向包括:
-
更细:支持层级化组件、复合布局、可交互状态;
-
更轻:探索更小级别的模型和量化方案,让"一句话生成 UI"有望在线生成;
-
更懂你:支持描述式检测(Captioned Grounding)和多轮对话编辑生成能力;
-
更开放:已开源,欢迎社区一起贡献迭代,共建生态。
作为首个 UI 理解与生成统一模型,UI-UG 不仅为前端研发者提供了高效的 AFF(AI For Frontend)工具,未来还希望在 GUI Agent、对话式 UI 生成等场景开启全新想象空间。随着模型的持续迭代,人机交互体验将迎来更智能的未来。