本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
从Token到向量,探索AI理解语义的奇妙转变
朋友们,欢迎回到我的大模型学习之旅!在上一篇文章中,我们一起攻克了Token 这个概念,知道了它是大模型处理文本的基本单位。今天,我们要继续深入,探索一个更加神奇的概念------Embedding(嵌入)。
如果说Token是给文字"分装",那么Embedding就是给文字"安家"。让我们开始这段奇妙的旅程吧
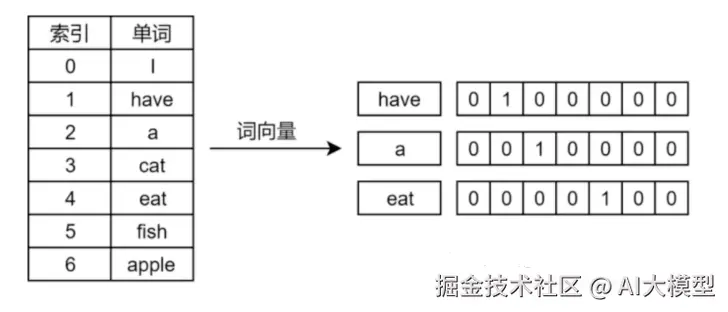
Embedding将离散的词语映射到连续的向量空间中,使语义相近的词在空间中彼此靠近
一、从生活场景理解Embedding:文字的"地图坐标"
想象一下,你正在整理一个巨大的图书馆:
传统方式:按书籍的编号顺序排列
A-001:《人工智能导论》A-002:《机器学习实战》B-001:《红楼梦》B-002:《百年孤独》
这样排列,虽然整齐,但内容相关的书籍可能相隔甚远。
智能方式:按内容主题给每本书分配"坐标"
- 《人工智能导论》:
[0.9, 0.1, 0.8, ...] - 《机器学习实战》:
[0.85, 0.2, 0.75, ...] - 《红楼梦》:
[0.1, 0.9, 0.05, ...] - 《百年孤独》:
[0.15, 0.85, 0.1, ...]
在这个智能系统中:
- 相近坐标的书籍内容相似
- AI可以快速找到相关书籍
- 新书来了也能自动分配坐标
这就是Embedding的核心思想------把文字映射到数学空间中的点!
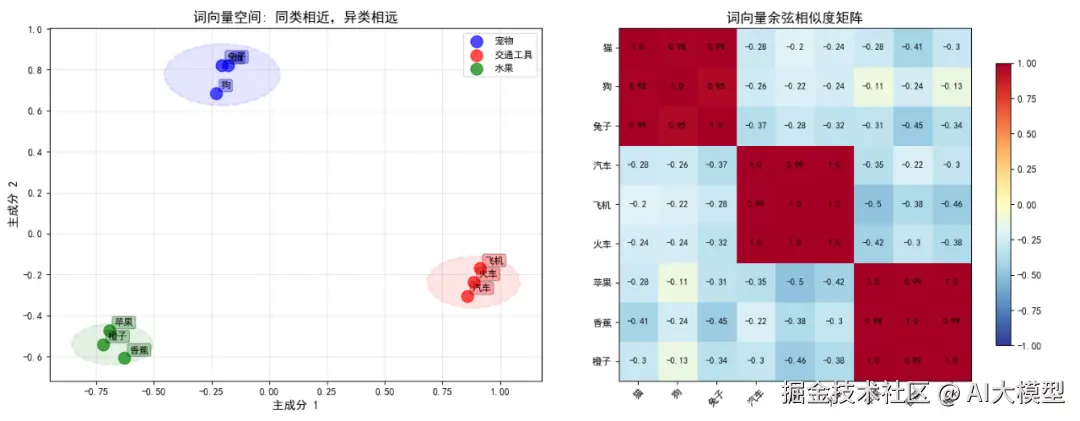
在向量空间中,语义相近的词(如"猫"和狗")彼此靠近,而不同类别的词则距离较远
二、Embedding是什么?文字的数字"身份证"
基础定义
Embedding(嵌入) :将离散的符号(如单词、句子)转换为连续向量表示的技术。
换句话说:
- 输入:文字(如"猫"、"狗")
- 输出:一串数字(如0.2, -0.5, 0.8, ..., 0.1)
一个具体例子
rust
# 假设的简单Embedding示例
"猫" -> [0.3, 0.8, -0.2]
"狗" -> [0.4, 0.7, -0.1]
"汽车" -> [-0.5, 0.1, 0.9]
"飞机" -> [-0.6, 0.2, 0.8]在这个例子中:
- 语义相近的词,向量也相近
- "猫"和"狗"都是宠物,向量距离近
- "汽车"和"飞机"都是交通工具,向量距离近
- 宠物与交通工具之间,向量距离远
三、为什么需要Embedding?三大核心价值
-
让计算机"理解"语义
计算机只懂数字,不懂文字。Embedding把文字变成数字,同时保留了语义信息:
- 相似的词有相似的向量
- 词之间的关系可以用向量运算表示
-
解决"词汇鸿沟"问题
传统方法中,"电脑"和"计算机"被认为是完全不同的词。但在Embedding空间中,它们的向量会很接近,因为含义相似。
-
为深度学习提供输入
神经网络需要数值输入,Embedding正好提供了这种能力,让模型可以处理文本数据。
四、Embedding的奇妙特性:向量运算的魔力
这是Embedding最让人惊叹的部分------词向量可以进行数学运算!
经典例子:国王 - 男人 + 女人 ≈ 女王
c
vector("国王") - vector("男人") + vector("女人") ≈ vector("女王")更多例子:
北京 - 中国 + 法国 ≈ 巴黎苹果 - 水果 + 公司 ≈ 微软(科技公司)这种特性说明,Embedding不仅编码了词义,还编码了词与词之间的关系!
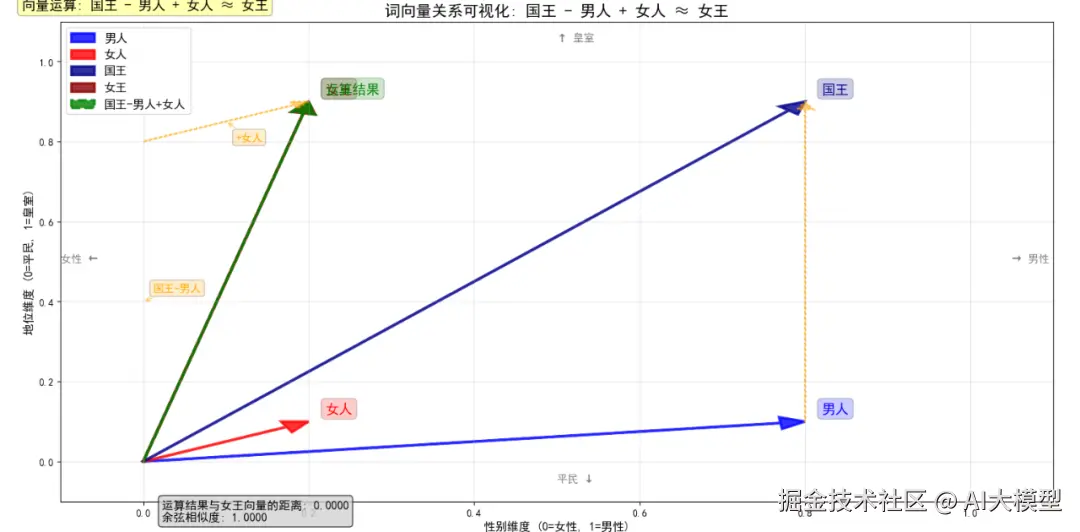
经典的词向量类比运算:通过向量加减捕捉语义关系
五、Embedding是如何生成的?
理解Embedding的产生过程,能让你真正掌握它的本质:
训练原理:"观其伴,知其义"
核心思想:一个词的含义,可以由它周围出现的词来决定。
训练过程:
- 选择目标词(如"人工智能")
- 观察它的上下文("学习__技术很有前途")
- 调整向量,使相似上下文的词有相似向量
- 重复数百万次,直到向量稳定
常用方法:
-
Word2Vec
:经典的词嵌入方法
-
GloVe
:基于全局词频统计
-
BERT等Transformer
:生成上下文相关的嵌入
六、Embedding在大模型中的关键作用
-
理解的基石
大模型首先将Token转换为Embedding,然后基于这些向量进行各种计算。可以说,Embedding是模型理解语言的起点。
-
语义搜索的核心
当你在智能搜索中输入问题时,系统:
- 将问题转换为Embedding
- 在向量空间中寻找最相关的文档
- 返回相似度最高的结果
-
推荐系统的原理
电商平台使用Embedding来:
- 理解商品描述
- 计算商品之间的相似度
- 推荐相关商品
-
文本分类的依据
通过Embedding,模型可以判断:
- 邮件是正常邮件还是垃圾邮件
- 评论是正面评价还是负面评价
- 新闻属于哪个类别
七、动手体验:感受Embedding的力量
理论说再多,不如亲身体验。我强烈推荐你尝试以下工具:
1. 可视化工具
-
TensorFlow Embedding Projector
:可以直观看到词向量的分布 projector.tensorflow.org/
-
ANN Benchmark
:体验最近邻搜索 ann-benchmarks.com/index.html
2. 在线演示
- 在Hugging Face上尝试各种Embedding模型
- 使用OpenAI的Embedding API
实践练习:
找一段文本,尝试:
- 计算不同词的相似度
- 寻找与某个词最相近的词
- 进行向量运算实验
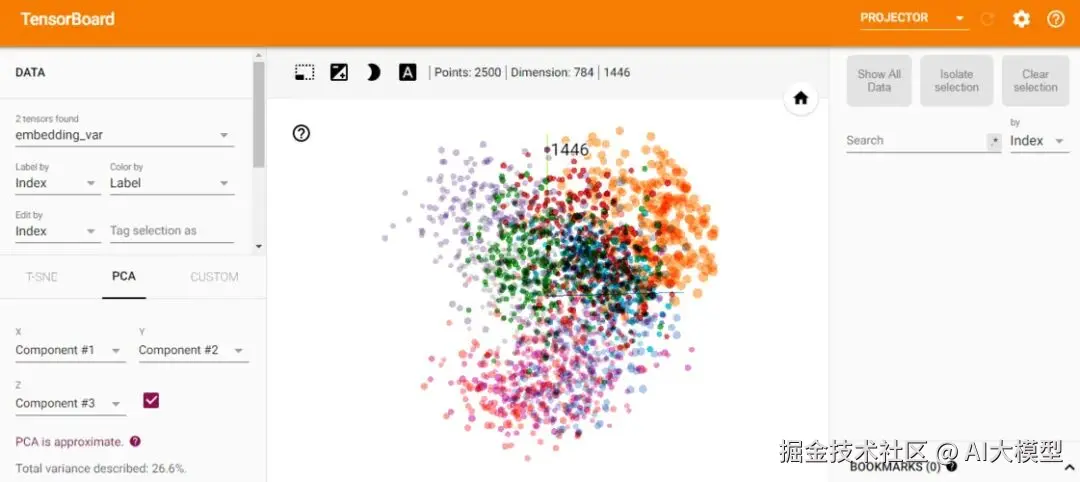
TensorFlow Embedding Projector 可视化工具,可交互式探索高维词向量
八、Embedding的进阶知识
当你深入使用时,会遇到这些概念:
1. 静态vs动态Embedding
-
静态
:每个词有固定的向量(如Word2Vec)
-
动态
:同一个词在不同上下文中向量不同(如BERT)
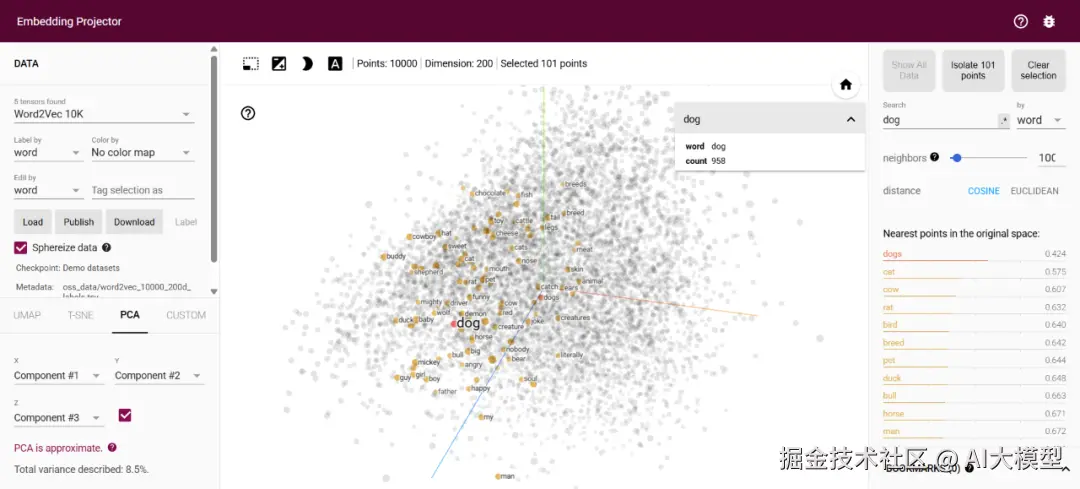
TensorFlow Embedding Projector搜索dog,可以看到和cat、cow、rat、bird等。
2. 句子和文档Embedding
不仅词可以有Embedding,整个句子、段落、文档都可以被表示为向量。
3. 多模态Embedding
现在还有图像Embedding、音频Embedding,让不同模态的数据可以在同一个空间中进行比较。
实践建议:用好Embedding的秘诀
基于对Embedding的理解,这里有几点实用建议:
-
选择合适的维度
:不是维度越高越好,需要平衡效果和效率
-
考虑上下文相关性
:对于需要理解语境的任务,选择动态Embedding
-
注意领域适应性
:通用Embedding可能不适合专业领域
-
利用预训练模型
:大多数情况下,使用现成的Embedding比从头训练更高效
结语
恭喜!现在你已经掌握了Embedding这个神奇的概念。我们来回顾一下今天的重点:
- ✅ Embedding把文字转换为数值向量,让计算机能"理解"语义
- ✅ 相似的词有相似的向量,保持了语义关系
- ✅ 向量可以进行数学运算,揭示了词之间的复杂关系
- ✅ Embedding是很多AI应用的基础,从搜索到推荐都离不开它
从Token到Embedding,我们看到了AI如何一步步地理解人类语言。Token解决了"分词"问题,Embedding解决了"理解"问题。
学习就像爬山,每掌握一个概念,就登上了一个新的高度。如果你对Embedding还有任何疑问,欢迎随时回看这篇文章。下节课见!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。