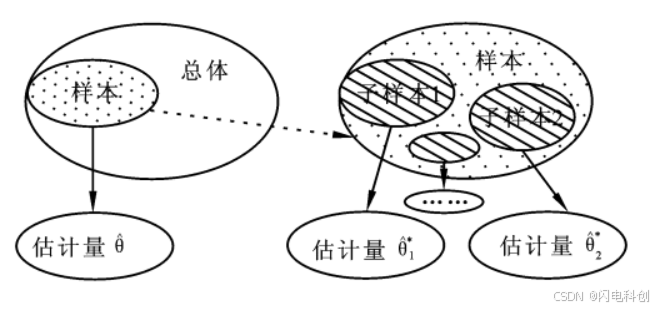
在深度学习中,Bootstrap 是一种用于提高模型稳健性和泛化能力的技术,主要通过对数据集的重采样来进行训练。这一技术源于统计学中的 自助法(Bootstrap Resampling),用于从现有数据中生成多个"新的"数据集,从而评估模型的表现或者训练一个更强健的模型。
计算机人工智sci/ei会议/ccf/核心,擅长机器学习,深度学习,神经网络,语义分割等计算机视觉,精通大小论文润色修改,代码复现,创新点改进等等。文末有方式
- Bootstrap 方法概述
Bootstrap 是一种通过对原始数据集进行有放回的抽样,生成多个训练子集的技术。简单来说,它的主要过程是从原始数据集中随机抽取样本,生成多个不同的数据集,然后对每个数据集进行模型训练。通过这种方式,Bootstrap 能帮助减小模型的过拟合风险,并且提高模型的稳健性。
- Bootstrap 在深度学习中的应用
在深度学习中,Bootstrap 方法可以通过不同方式融入到模型训练过程中,以下是几种常见的应用方式:
2.1 训练数据的重采样(Bagging)
"Bagging"(Bootstrap Aggregating)是 Bootstrap 技术在集成学习中的一种应用。通过从原始训练集进行有放回的抽样,得到多个训练子集,然后在这些子集上分别训练多个相同的模型,最后对这些模型的预测结果进行聚合(如投票、平均等)。这种方法特别适用于减少模型的方差,增强模型的稳定性。
1.过程:
2.从训练数据集中进行有放回抽样,生成多个不同的训练子集(每个子集的大小通常与原数据集相同)。
3.在每个子集上训练相同的深度学习模型。
4.对所有模型的预测结果进行集成,常见的集成方法有投票法(分类任务)和平均法(回归任务)。
5.优点:
6.减少过拟合:通过在多个子集上训练模型,能够有效减少单个模型对训练集的过拟合现象。
7.提高泛化能力:集成多个模型的预测结果能够减少模型的方差,从而提高泛化能力。
8.缺点:
9.计算开销较大,因为需要训练多个模型。
10.随着模型数量的增加,计算成本和内存消耗也会显著增加。
2.2 自助法(Bootstrap)用于估计模型误差
在深度学习训练中,我们通常使用验证集来评估模型的性能。通过 Bootstrap 方法,可以从训练数据中进行多次采样,生成多个不同的训练集,从而训练多个模型并评估它们的误差。这种方法可以用于估计模型的方差以及评估模型的稳定性。
11.过程:
12.多次从原始训练集进行有放回的抽样,每次生成一个新的训练子集。
13.对每个子集训练一个模型,并记录模型在原始数据集(或验证集)上的表现。
14.通过计算不同模型的表现,得到模型的方差和误差估计。
15.优点:
16.提供了对模型性能的更全面评估,尤其是模型在不同训练集上的表现。
17.有助于判断模型是否稳定,并发现模型可能过拟合或欠拟合的情况。
2.3 Bootstrap 用于模型集成(如随机森林)
深度学习模型的集成方法通常采用"随机森林"技术,其中每个决策树都是通过对数据集进行Bootstrap抽样后训练得到的。在随机森林中,通过集成多个模型的预测结果,能够显著提高模型的准确性和稳定性。
在深度学习的集成方法中,类似的技巧也能被采用。例如,我们可以通过在不同的数据子集上训练多个神经网络模型,并对它们的结果进行加权平均,从而得到最终的预测。这种方法能够帮助减少单个模型的误差,提高整体预测效果。
- 深度学习中的 Bootstrap 优化
虽然传统的深度学习方法通常是通过完整的训练集来训练模型,但引入 Bootstrap 方法时,我们可以在每轮训练中使用随机抽样的子集,从而在一定程度上增加训练的多样性,并增强模型的鲁棒性。这与深度学习中的 dropout 技术相似,都是通过引入一定的随机性来提高模型的泛化能力。
- Bootstrap 和 Dropout 的对比
18.Bootstrap:基于训练数据集的重采样,生成多个训练子集,并在这些子集上训练不同的模型。最终通过集成这些模型来提高预测准确性和稳定性。
19.Dropout:在训练神经网络时,随机丢弃部分神经元的激活值,目的是让神经网络更具鲁棒性,防止过拟合。
虽然两者的核心思想不同,但它们都有一个共同的目标:通过引入随机性来提升模型的泛化能力。
- 实际应用中的挑战与局限
尽管 Bootstrap 方法在集成学习中取得了显著的成功,但它在深度学习中应用时也面临一些挑战:
20.计算资源需求:每次训练都需要使用一个不同的数据子集,计算资源和时间开销会大大增加。
21.数据重复性:由于数据是有放回地采样的,因此有些数据可能会在多个子集中出现,而有些数据可能完全未被采样。这种情况可能会影响模型训练的稳定性。
22.模型复杂性:训练多个深度学习模型并集成可能导致模型过于复杂,从而在部署阶段增加计算负担。
- 总结
Bootstrap 是一种强大的技术,通过数据的重采样生成多个子集,进而训练多个模型并进行集成,从而提高模型的泛化能力。在深度学习中,Bootstrap 的应用(如 Bagging 方法)可以帮助减小模型的方差,提高预测的稳定性。此外,Bootstrap 还可以用于误差估计和模型性能评估。然而,它也带来了一定的计算开销和资源消耗,因此在实际应用中需要权衡其优势和局限性。