https://leetcode.cn/problems/flatten-a-multilevel-doubly-linked-list
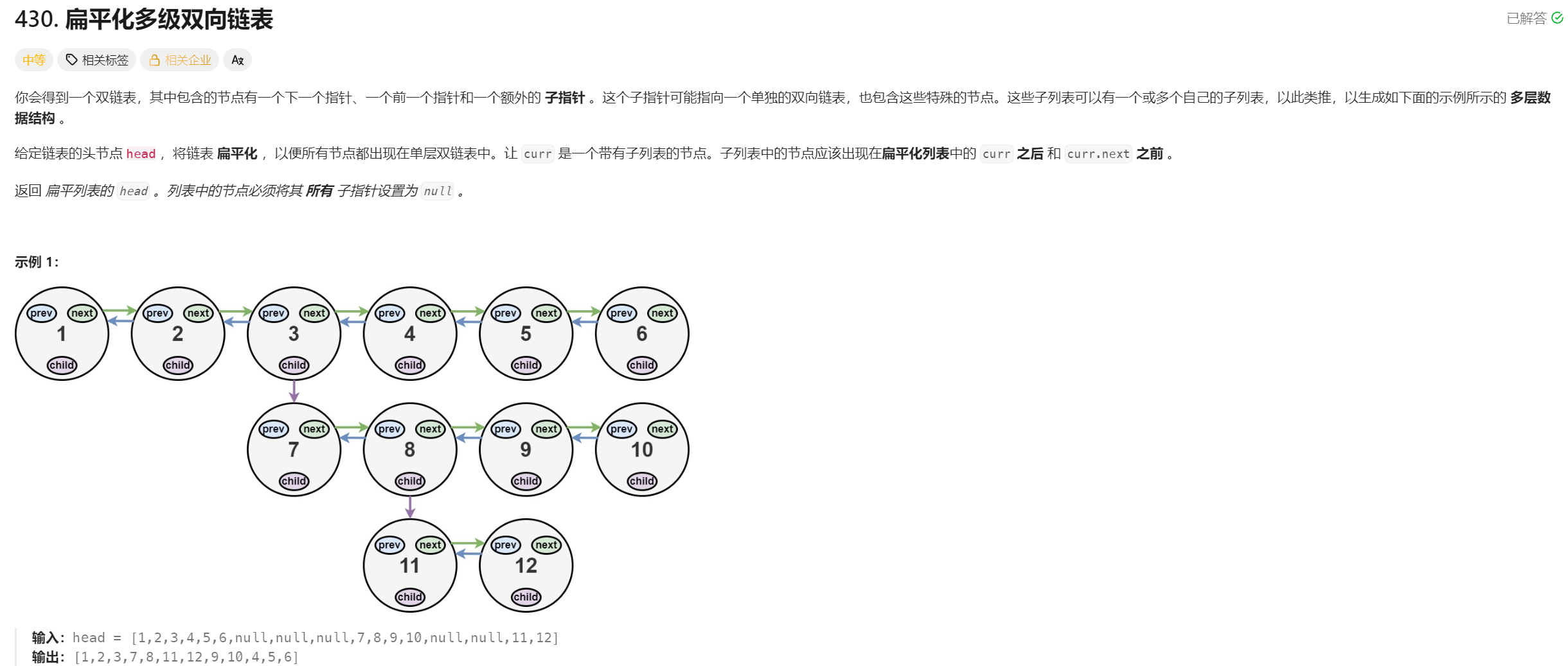
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表 中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
简单来说就是把多层的链表通过插入合成一条链表
自用,感觉dfs版比较绕,得多复习几次,很容易出错
方法1:递归
出现这种一级一级嵌套很容易想到使用递归,但是递归的代码没有那么好写
cpp
class Solution {
public:
Node* flatten(Node* head) {
Node* curr = head;
while (curr) {
if (curr->child) {
Node* next = curr->next;
Node* childHead = flatten(curr->child);
// 插入 child 链表
curr->next = childHead;
childHead->prev = curr;
curr->child = nullptr;
// 找到 child 链表的尾部
Node* tail = childHead;
while (tail->next) {
tail = tail->next;
}
// 把尾部和原来的 next 连接
if (next) {
tail->next = next;
next->prev = tail;
}
}
curr = curr->next;
}
return head;
}
};首先要明确要干什么
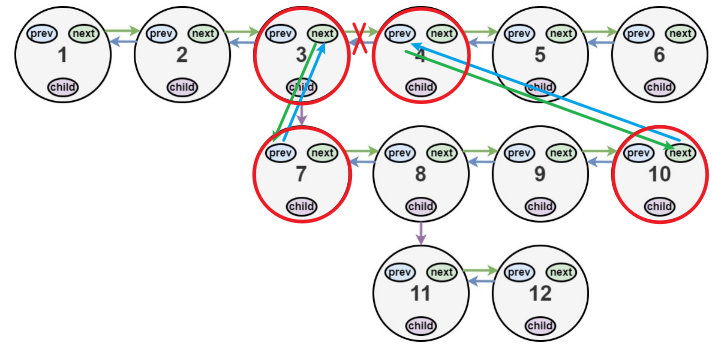
在每一层递归中要完成断开原来的连接,把断开的位置接上
在当前层循环中完成两件事,其一是检测当前层的每一个节点的child指针是否为空
其二是完成相关的连接
在if语句内部也完成两件事,分别是平坦化和连接
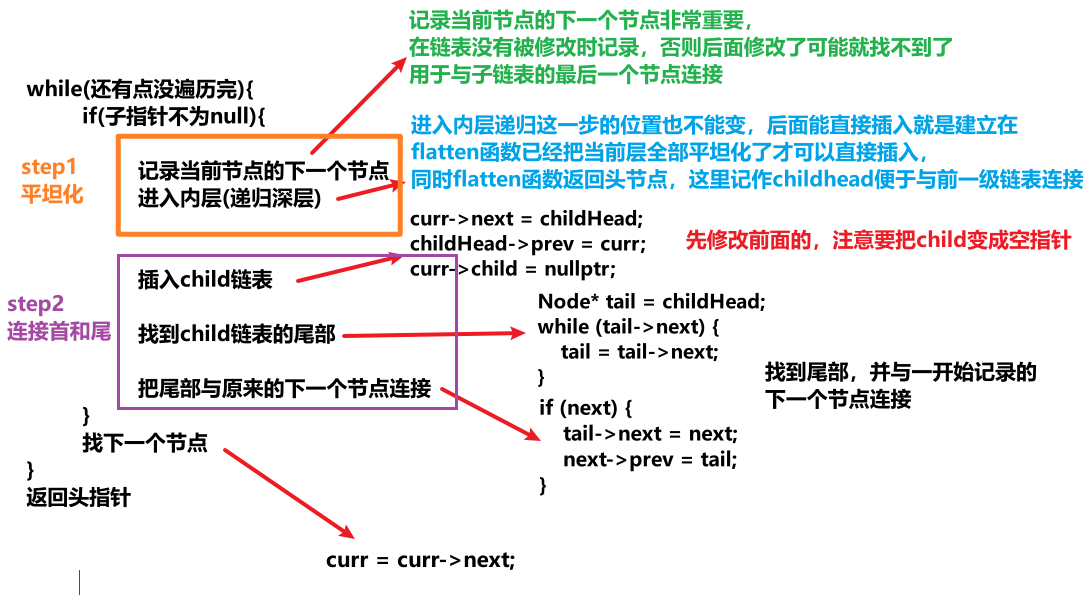
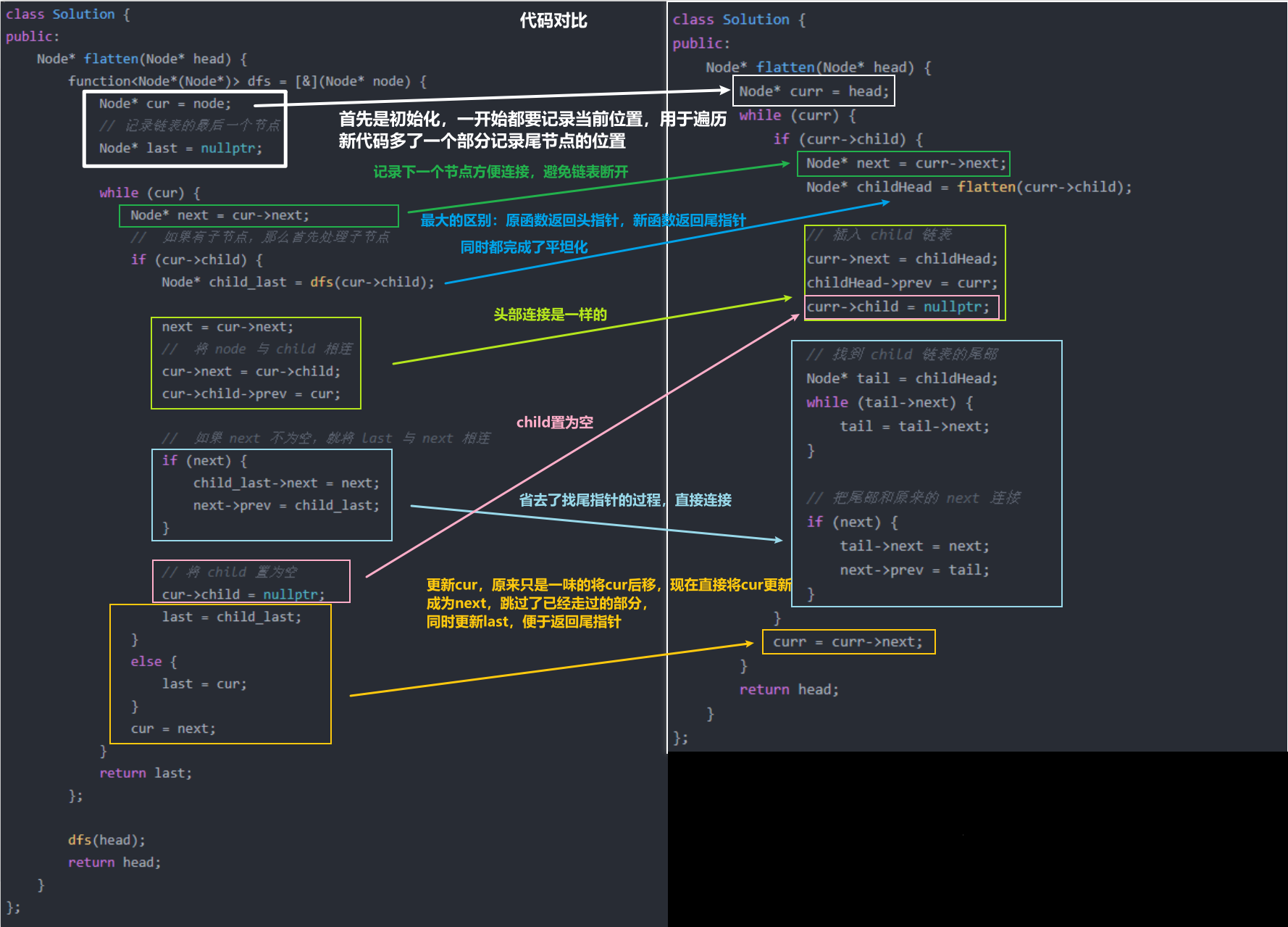
但是我们会注意到
由于递归使得主链的curr指针总是把之前走过的点又走一遍
比如:这里虽然你已经平坦化,并把下面的部分都插入到了3和4之间,但是由于curr指针仍然在3,想要走到4仍然要沿着绿线走一遍,增加了时间复杂度
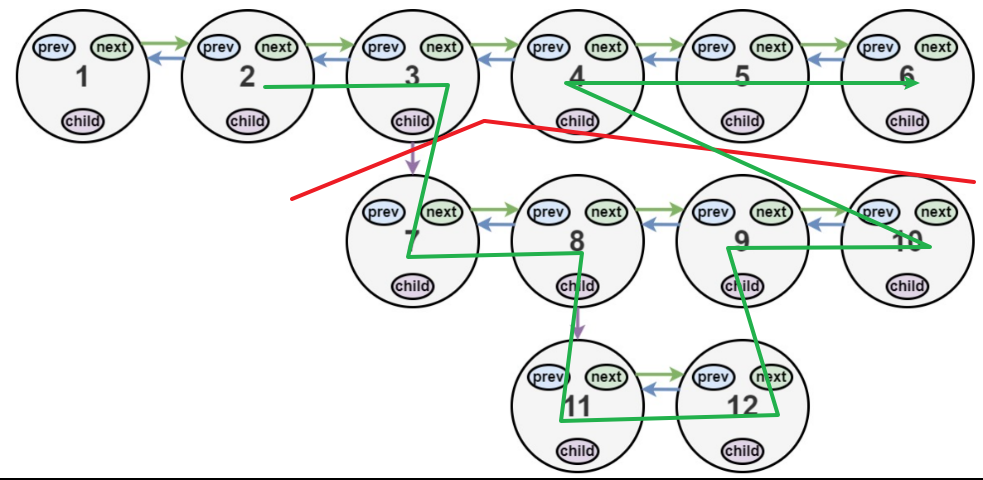
所以我们就可以考虑记录每一次的链表末尾,
如果有一个函数能同时完成平坦化并且返回链表末尾的指针就好了,
但是原函数返回的是链表的头指针,因此我们得自己写一个函数辅助
方法2:递归+dfs函数优化
这里参考力扣官方题解
cpp
class Solution {
public:
Node* flatten(Node* head) {
function<Node*(Node*)> dfs = [&](Node* node) {
Node* cur = node;
// 记录链表的最后一个节点
Node* last = nullptr;
while (cur) {
Node* next = cur->next;
// 如果有子节点,那么首先处理子节点
if (cur->child) {
Node* child_last = dfs(cur->child);
next = cur->next;
// 将 node 与 child 相连
cur->next = cur->child;
cur->child->prev = cur;
// 如果 next 不为空,就将 last 与 next 相连
if (next) {
child_last->next = next;
next->prev = child_last;
}
// 将 child 置为空
cur->child = nullptr;
last = child_last;
}
else {
last = cur;
}
cur = next;
}
return last;
};
dfs(head);
return head;
}
};
作者:力扣官方题解
链接:https://leetcode.cn/problems/flatten-a-multilevel-doubly-linked-list/solutions/1013884/bian-ping-hua-duo-ji-shuang-xiang-lian-b-383h/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。其中函数的主要部分就是这个dfs函数
补充:关于lambda表达式
其实只是把「递归函数」定义成 lambda 表达式 ,再存到 std::function 里,以便 lambda 内部能调用自己 (实现递归)。
拆开看就四件事:
-
std::function<Node*(Node*)>一个函数对象类型 ,签名是「接收
Node*,返回Node*」。 -
dfs变量名,后面用它来递归。
-
= [&]
捕获列表:[&]表示「所有外部变量按引用捕获」,这样 lambda 里才能看见并调用 自己(dfs)。
-
(Node* node) { ... }真正的函数体,和普通函数写法一模一样。
假如孩子指针全为空,代码执行
cpp
class Solution {
public:
Node* flatten(Node* head) {
function<Node*(Node*)> dfs = [&](Node* node) {
Node* cur = node;
// 记录链表的最后一个节点
Node* last = nullptr;
while (cur) {
Node* next = cur->next;
last = cur;
cur = next;
}
return last;
};
dfs(head);
return head;
}
};
这样相当于就遍历了一次链表,返回了最后一个位置,也是没有问题的