Python 豆瓣TOP250 爬虫(类)讲解
这是继我的文章:Python 爬虫(豆瓣top250)-享受爬取信息的快乐 后写的第二遍文章,也是对第一篇文章的补充吧,本人也是Python小白,有一点点的C++基础,学到了一些Python的爬虫知识,所以想跟大家分享一下,请大佬勿喷!下面我们先给出全部代码:
python
import requests # 用于HTTP请求
from bs4 import BeautifulSoup # 用户HTML文件解析
import time #用于延迟访问,更像人类
import csv
import queue # 用于任务队列
import threading # 创建写线程与解析线程
class DoubanMovieCrawler:
def __init__(self, delay : float = 0.1, thread_num : int = 3):
""" 初始化爬虫
csv_filename 存储文件名称
delay 爬取间隔
"""
self.__delay = delay
self.__base_url = "https://movie.douban.com/top250"
# 任务队列
self.__tasks_queue = queue.Queue()
# 写入队列
self.__write_queue = queue.Queue()
# 保存词典
self.__save_dict = {}
# 解析线程列表
self.__parse_threads_queue = []
for i in range(thread_num):
parser = threading.Thread(target = self._parse_thread_worker, name = f"Parse Thread-{i + 1}")
parser.start()
self.__parse_threads_queue.append(parser)
# 写入线程列表
self.__write_thread_queue = []
write_thread = threading.Thread(target = self._write_thread_worker, name = "Write Thread")
write_thread.start()
self.__write_thread_queue.append(write_thread)
#请求头配置
self.__headers = {
# 用户代理,模拟不同浏览器和操作系统
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
# 接受的内容类型
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 接受的语言
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
# 接受的编码格式
# 'Accept-Encoding': 'gzip, deflate, br',
# 保持连接
'Connection': 'keep-alive',
# (可选) 从哪个页面跳转而来,对于防盗链的网站很重要
'Referer': 'https://www.google.com/',
# (可选) Cookie,处理需要登录或有用户状态的网站
'Cookie': 'bid=XXX
}
# 禁用代理,避免网络问题
self.__proxies = {
'http': None,
'https': None,
}
# -------------------------------------------- 解析方法 ---------------------------------------------
# 多页解析函数
def parse_pages(self, start : int, end: int, file_name : str = 'movie.csv'):
for page in range(start, end + 1):
self.__tasks_queue.put(page)
# 所有页面被处理完了
self.__tasks_queue.join()
# 开始保存工作
if file_name == 'movie.csv':
file_name = file_name.replace('.csv', f'-{start}-{end}.csv')
self.__write_queue.put(file_name)
self.__write_queue.join()
# 单页解析函数
def parse_single_page(self, page : int, file_name : str = 'movie.csv'):
self.parse_pages(page, page, file_name)
# ---------------------------------------------- stop方法 -------------------------------------------
def stop(self):
# 先停止解析线程
for _ in range(len(self.__parse_threads_queue)):
self.__tasks_queue.put(None)
# 等待解析线程结束
for thread in self.__parse_threads_queue:
thread.join()
# 停止写入线程
self.__write_queue.put(None)
# 等待写入线程结束
for thread in self.__write_thread_queue:
thread.join()
# 最后清空字典
self.__save_dict.clear()
#---------------------------------------------- 私有化方法 ----------------------------------------------
# 储存数据
def _save_csv(self, file_name = None) -> None:
try:
with open(file_name, 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(
['序号', '中文名', '英文名', '别名', '演员信息', '电影信息', '评分', '评价人数', '名言'])
for key in sorted(self.__save_dict.keys()):
writer.writerow(self.__save_dict[key])
except Exception as e:
print(f"csv写入失败:{e}")
# info解析函数
def _parse_movie_info(self, info_div, count):
try:
# 获取标题
# 获取info 下的所有 class 为 title 的sapn
title_spans = info_div.find_all('span', attrs={'class': 'title'})
# 获取info 下的所有 class 为 other 的sapn
other_span = info_div.find('span', attrs={'class': 'other'})
# 获取中文名
chinese_title = title_spans[0].get_text()
# 获取英文名字,并且处理一些文字
english_title = 'None'
if len(title_spans) > 1:
english_title = title_spans[1].get_text().replace('\xa0/\xa0', '').strip()
# 获取别名
other_title = other_span.text.replace('\xa0/\xa0', '').strip()
# 获取导演与演员信息以及电影信息
movie_attributes = info_div.select_one('div.bd p')
# 去掉</br>
if movie_attributes.br:
movie_attributes.br.replace_with('|||')
text = movie_attributes.get_text().replace('\xa0', '').replace('"', '')
parts = text.split('|||')
actors_info, attribute_info = [' '.join(part.split()) for part in parts]
# 获取评分
bd_div = info_div.find('div', attrs={'class': 'bd'})
rating = bd_div.find('span', attrs={'class': 'rating_num'}).get_text()
review_element = None
for span in bd_div.find_all('span'):
if span.text and '人评价' in span.text:
review_element = span.text
review_element = review_element.replace('人评价', '')
break
# 获取名言
quote_element = (bd_div.find('p', attrs={'class': 'quote'}).find('span').get_text()) \
if bd_div.find('p', attrs={'class': 'quote'}) else None
# 保存数据进入全局词典
self.__save_dict[count] = [count, chinese_title, english_title, other_title,
actors_info, attribute_info, rating, review_element, quote_element]
# 打印信息
print(f"----------------------- {count} -----------------------")
print(f"中文名:{chinese_title} \n英文名:{english_title} \n别名:{other_title}")
print(f"{actors_info}")
print(f"电影信息:{attribute_info}")
print(f"评分:{rating} 评价人数:{review_element}")
print(f"名言:{quote_element}")
print(f"-------------------------------------------------")
except Exception as e:
print(f"解析单个网页信息出错:{e}")
# 单页解析函数
def _parse_page(self, page_number: int):
try:
# 获取响应
start_index = (page_number - 1) * 25
url = rf"{self.__base_url}?start={start_index}&filter="
response = requests.get(url, headers=self.__headers, proxies=self.__proxies, timeout=5)
if response.status_code == 200:
print(f"请求成功,开始解析第 {page_number} 页网址")
# 解析响应文本,使用HTML格式
soup = BeautifulSoup(response.text, 'lxml')
# 获取全部电影数目
movie_list = soup.find_all('div', attrs={'class': 'item'})
# 遍历每一个电影数目,获取其中的信息
count = (page_number - 1) * 25 + 1
for movie_item in movie_list:
# 获取电影的整个信息
info_div = movie_item.find('div', attrs={'class': 'info'})
self._parse_movie_info(info_div, count)
count += 1
time.sleep(self.__delay) # 增加一个小的延迟,模拟人类行为,是个好习惯
else:
print(f"请求失败!状态码:{response.status_code}")
except requests.RequestException as e:
print(f"请求错误:{e}")
# 解析线程工作函数
def _parse_thread_worker(self):
while True:
page_num = self.__tasks_queue.get()
if page_num is None:
self.__tasks_queue.task_done()
break
else:
self._parse_page(page_num)
self.__tasks_queue.task_done()
#写入线程工作函数
def _write_thread_worker(self):
while True:
file_name = self.__write_queue.get()
if file_name is None:
self.__write_queue.task_done()
break
else:
self._save_csv(file_name)
self.__save_dict.clear()
self.__write_queue.task_done()一、总流程
这是我在上一篇文章的基础上改进的一个豆瓣TOP爬虫,我将它包装成了一个类 ,同时引入了多线程,应该算是一个升级版吧,但是还是不完善的,我觉得它还有很多的提升空间,那就交给大家了。下面我们开始讲解代码:
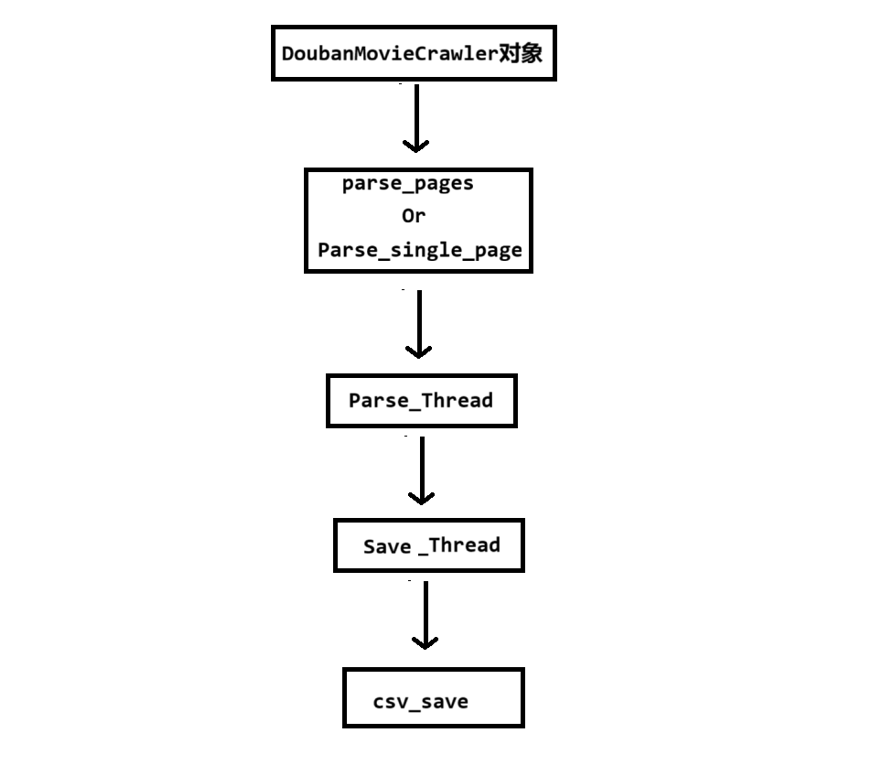
总的流程是:爬虫对象调用爬虫分析页面函数(多页或者单页) ---> 将任务加入任务队列给任务线程 执行 ---> 任务线程执行完分析后交给保存队列执行保存任务。
二、确定类的属性变量
一个类里面一般都含有私有属性变量与公共属性变量,这些属性一个程序员一开始并不会全部都考虑周全,都是边完善这个类边补充上去的,但是为了讲解方便,我这里把所有用到的属性变量就先给出来了。
python
class DoubanMovieCrawler:
def __init__(self, delay : float = 0.1, thread_num : int = 3):
""" 初始化爬虫
csv_filename 存储文件名称
delay 爬取间隔
"""
self.__delay = delay
self.__base_url = "https://movie.douban.com/top250"
# 任务队列
self.__tasks_queue = queue.Queue()
# 写入队列
self.__write_queue = queue.Queue()
# 保存词典
self.__save_dict = {}
# 解析线程列表
self.__parse_threads_queue = []
for i in range(thread_num):
parser = threading.Thread(target = self._parse_thread_worker, name = f"Parse Thread-{i + 1}")
parser.start()
self.__parse_threads_queue.append(parser)
# 写入线程列表
self.__write_thread_queue = []
write_thread = threading.Thread(target = self._write_thread_worker, name = "Write Thread")
write_thread.start()
self.__write_thread_queue.append(write_thread)
#请求头配置
self.__headers = {
# 用户代理,模拟不同浏览器和操作系统
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
# 接受的内容类型
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 接受的语言
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
# 接受的编码格式
# 'Accept-Encoding': 'gzip, deflate, br',
# 保持连接
'Connection': 'keep-alive',
# (可选) 从哪个页面跳转而来,对于防盗链的网站很重要
'Referer': 'https://www.google.com/',
# (可选) Cookie,处理需要登录或有用户状态的网站
'Cookie': 'bid=XXX
}
# 禁用代理,避免网络问题
self.__proxies = {
'http': None,
'https': None,
}我来逐一分析这个类初始化方法中各个属性的作用:
1. 基础属性
self.__delay
python
self.__delay = delay作用:控制爬取间隔时间(秒)
- 模拟人类行为 - 避免请求过于频繁
- 防反爬机制 - 降低被网站封禁的风险
- ⚖ 负载均衡 - 减轻目标服务器压力
self.__base_url
python
self.__base_url = "https://movie.douban.com/top250"作用:豆瓣电影Top250的基础URL
- URL模板 - 后续拼接分页参数
- 目标定位 - 明确爬取的网站和页面
2. 多线程相关属性
self.__tasks_queue
python
self.__tasks_queue = queue.Queue()作用:存储解析任务的队列
- 任务分发 - 将页面编号放入队列供线程获取
- 生产者-消费者模式 - 主线程生产任务,工作线程消费任务
- 线程安全 - Queue自带线程同步机制
self.__write_queue
python
self.__write_queue = queue.Queue()作用:存储文件写入任务的队列
- 文件写入调度 - 控制何时写入哪个文件
- 避免文件冲突 - 确保同时只有一个写入操作
- 批量处理 - 收集完数据后统一写入
self.__save_dict
python
self.__save_dict = {}作用:存储爬取到的电影数据
- 数据缓存 - 临时存储解析出的电影信息
- 按序号索引 - key为电影序号,value为电影详细信息列表
- 线程共享 - 多个解析线程往同一字典写入数据
self.__parse_threads_queue
python
self.__parse_threads_queue = []
for i in range(thread_num):
parser = threading.Thread(target = self._parse_thread_worker, name = f"Parse Thread-{i + 1}")
parser.start()
self.__parse_threads_queue.append(parser)作用:管理解析线程
- 并发处理 - 创建多个线程同时解析不同页面
- 性能提升 - 提高爬取效率
- 资源管理 - 保存线程引用便于后续控制
self.__write_thread_queue
python
self.__write_thread_queue = []
write_thread = threading.Thread(target = self._write_thread_worker, name = "Write Thread")
write_thread.start()
self.__write_thread_queue.append(write_thread)作用:管理文件写入线程
- 专职写入 - 专门负责数据写入CSV文件
- 避免冲突 - 确保同时只有一个线程写文件
- 数据清理 - 写入完成后清空字典
3. HTTP请求配置属性
self.__headers
python
self.__headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9...',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Referer': 'https://www.google.com/',
'Cookie': 'bid=XXX...'
}self.__headers (请求头):
- 作用: 这是一个字典,包含了模拟浏览器访问网页时发送的 HTTP 请求头信息。
- 目的 : 让爬虫的请求看起来更像一个真实的浏览器发出的,而不是一个程序。这是反爬虫的重要一环。
User-Agent: 告诉服务器你的"浏览器"身份。这是最重要的请求头之一,很多网站会拒绝没有User-Agent的请求。Accept,Accept-Language: 告诉服务器你能接受什么样的数据类型和语言。Connection:keep-alive表示与服务器保持长连接,可以提高后续请求的效率。Referer: 告诉服务器你是从哪个页面跳转过来的。有些网站会用它来做防盗链。Cookie: 用于向服务器发送你的身份凭证。对于需要登录才能访问的网站,Cookie是必需的。
三、各个函数的介绍(AI)
每一个函数实在太多的细节了,这里我使用了AI帮助我讲解,希望大家原谅
1. _save_csv(self, file_name)
-
作用 : 这个函数是数据持久化的终点。它负责将内存中
self.__save_dict字典里收集到的所有电影数据一次性写入到一个 CSV 文件中。 -
实现细节:
- 打开文件 :
with open(file_name, 'w', newline='', encoding='utf-8-sig') as csvfile:'w': 以写入模式打开文件。如果文件已存在,会覆盖旧内容。newline='':这是写入 CSV 文件时的标准做法,用于防止在 Windows 系统下出现多余的空行。encoding='utf-8-sig': 使用utf-8-sig编码(带BOM的UTF-8)。这非常关键,因为它可以确保输出的 CSV 文件被 Excel 等软件正确识别,从而避免中文乱码问题。
- 创建写入器 :
writer = csv.writer(csvfile): 创建一个 CSV 写入器对象,它能方便地将列表数据转换为 CSV 格式的一行。
- 写入表头 :
writer.writerow(['序号', '中文名', ...]): 首先写入文件的第一行,即表头,明确每一列数据的含义。
- 写入数据 :
for key in sorted(self.__save_dict.keys()):: 为了保证写入的电影顺序是按照"序号"从小到大排列的,这里先对字典的键(也就是电影的序号count)进行排序。writer.writerow(self.__save_dict[key]): 遍历排序后的键,从字典中取出对应的电影数据(这是一个列表),然后将其作为一行写入 CSV 文件。
- 异常处理 :
try...except: 使用了基本的异常处理,如果文件写入过程中发生任何错误(如权限问题、磁盘已满等),程序会打印错误信息而不会直接崩溃。
- 打开文件 :
2. _parse_movie_info(self, info_div, count)
-
作用 : 这是数据提取的核心。该函数接收一个包含单部电影所有信息的 HTML 代码块 (
info_div),然后从中精准地解析出电影的各项具体数据。 -
实现细节:
- 解析标题 :
- 它首先寻找所有
class="title"的<span>标签。通常第一个是中文名,第二个是英文名。 english_title = title_spans[1].get_text().replace('\xa0/\xa0', '').strip(): 这里对英文名做了处理,\xa0是一个不间断空格,.replace()和.strip()用于清除这些多余的字符,得到纯净的英文标题。- 别名的处理方式类似。
- 它首先寻找所有
- 解析演职员和电影信息 :
info_div.select_one('div.bd p'): 使用 CSS 选择器select_one来定位包含这些信息的<p>标签,这通常比find更灵活。movie_attributes.br.replace_with('|||'): 这是一个非常巧妙的处理。原始 HTML 中,导演信息和电影信息是用<br>标签换行分隔的。代码将<br>标签替换成了一个特殊的分隔符|||,这样后续就可以用split('|||')轻松地将两段文本分开了。
- 解析评分和评价人数 :
rating = bd_div.find('span', attrs={'class': 'rating_num'}).get_text(): 精准定位评分所在的<span>。if span.text and '人评价' in span.text:: 评价人数的提取稍微复杂,因为没有特定的 class。代码通过遍历所有<span>并检查其文本内容是否包含"人评价"这几个字来找到目标。
- 解析名言 (Quote) :
if bd_div.find('p', attrs={'class': 'quote'}) else None: 这是一个条件表达式,因为不是每部电影都有"名言"。它会先检查是否存在class="quote"的元素,如果存在,就提取文本;如果不存在,就将quote_element赋值为None,避免了程序因找不到元素而报错。
- 存储数据 :
self.__save_dict[count] = [...]: 将所有解析出的数据存入一个列表,并以电影序号count为键,存储在共享的__save_dict字典中。
- 打印信息 :
- 解析完成后,在控制台打印出提取到的信息,这对于调试和实时监控爬虫进度非常有用。
- 解析标题 :
3. _parse_page(self, page_number)
-
作用: 负责处理单个分页的完整流程:发送网络请求、获取页面 HTML、然后调用解析函数来处理页面内容。
-
实现细节:
- 构造URL :
start_index = (page_number - 1) * 25: 豆瓣 Top250 每页显示 25 条,通过这个公式计算出当前页码对应的start参数值。url = rf"{self.__base_url}?start={start_index}&filter=": 使用 f-string 动态构建目标页面的完整 URL。
- 发送请求 :
response = requests.get(...): 使用requests库发送 GET 请求,并带上预设的headers和proxies。timeout=5设置了5秒的超时,防止因某个请求卡死而导致整个程序无响应。
- 处理响应 :
if response.status_code == 200:: 检查 HTTP 状态码,只有当返回200(表示成功)时,才继续执行解析。soup = BeautifulSoup(response.text, 'lxml'): 使用BeautifulSoup库和lxml解析器(性能较好)来解析返回的 HTML 文本,生成一个可以方便操作的soup对象。
- 分发解析任务 :
movie_list = soup.find_all('div', attrs={'class': 'item'}): 找到页面上所有代表电影条目的<div class="item">。for movie_item in movie_list:: 遍历这个列表,对每一个电影条目,调用self._parse_movie_info函数,将具体的解析工作交给它。
- 延迟 :
time.sleep(self.__delay): 在处理完一个电影条目后,暂停一小段时间。注意 :这里的延迟是在解析内部,而不是在请求之间。一个更好的做法是在发送下一次requests.get之前进行延迟。
- 构造URL :
4. _parse_thread_worker(self)
-
作用: 这是"解析线程"的目标函数,每个解析线程都在无限循环地执行这个函数。
-
实现细节:
- 无限循环 :
while True:使线程一直保持活动状态,随时准备接收任务。 - 获取任务 :
page_num = self.__tasks_queue.get(): 这是核心。get()方法会阻塞 线程,直到__tasks_queue队列中有新的任务(这里是页码page_num)进来。一旦拿到任务,线程就会继续执行。 - 终止信号 (Poison Pill) :
if page_num is None:: 这是一个约定好的"毒丸"信号。当主线程向队列中放入一个None时,工作线程就知道所有任务都已完成,应该退出了。self.__tasks_queue.task_done(): 在退出前,必须调用task_done()来减少队列的任务计数,否则主线程的queue.join()会一直等待。break: 跳出while True循环,线程执行完毕,自然终止。
- 执行任务 :
self._parse_page(page_num): 调用页面解析函数,执行真正的爬取和解析工作。self.__tasks_queue.task_done(): 每完成一个任务,必须调用此方法。这会通知队列,一个任务已经被处理完毕。
- 无限循环 :
5. _write_thread_worker(self)
-
作用: 这是"写入线程"的目标函数,它独立负责所有的数据写入操作。
-
实现细节:
- 获取任务 :
file_name = self.__write_queue.get(): 与解析线程类似,它会阻塞等待__write_queue队列中的任务(这里是文件名)。 - 终止信号 : 同样使用
None作为"毒丸"来终止线程。 - 执行任务 :
self._save_csv(file_name): 调用 CSV 保存函数,将__save_dict中当前积累的所有数据写入文件。self.__save_dict.clear(): 这是一个非常关键的步骤 。在数据写入完成后,它会清空共享的__save_dict字典。这样做的目的是为了给下一批要写入的数据腾出空间,防止数据重复写入。self.__write_queue.task_done(): 通知队列写入任务已完成。
- 获取任务 :
总结与重要观察
这个设计模式将爬虫的不同阶段(请求、解析、存储)解耦:
- 解析线程 (
_parse_thread_worker) 是生产者 :它们负责生产解析好的数据,并放入共享的__save_dict中。 - 写入线程 (
_write_thread_worker) 是消费者 :它负责消费__save_dict中的数据,并将其清空。
可能大家会担心保存数据字典__save_dict的读写锁问题,每一个线程写入的Key没有重复,后面全部写入结束之后会重新排序,所以大家不用担心!