dlib 库
dlib 库是什么?
是一个适用于 C++ 和 Python 的第三方库。包含机器学习、计算机视觉和图像处理的工具包,被广泛的应
用于机器人、嵌入式设备、移动电话和大型高性能计算环境。是开源许可用户免费使用。
opencv 优缺点:
优点
1 )可以在 CPU 上实时工作;
2 )简单的架构;
3 )可以检测不同比例的人脸。
缺点
1 )会出现大量的把非人脸预测为人脸的情况;
2 )不适用于非正面人脸图像;
3 )不抗遮挡。
dlib 优缺点:
优点
1 )适用于正面和略微非正面的人脸;
2 )语法极简单
3 )再小的遮挡下仍可工作。
缺点
1 )不能检测小脸,因为它训练数据的最小人脸尺寸为 80×80 ,较
小尺寸的人脸数据需自己训练检测器;
2 )边界框通常排除前额的一部分甚至下巴的一部分;
3 )不适用于侧面和极端非正面,如俯视或仰视。
安装 dlib 库方法:
pip install dlib --i 镜像地址
但是有可能报错
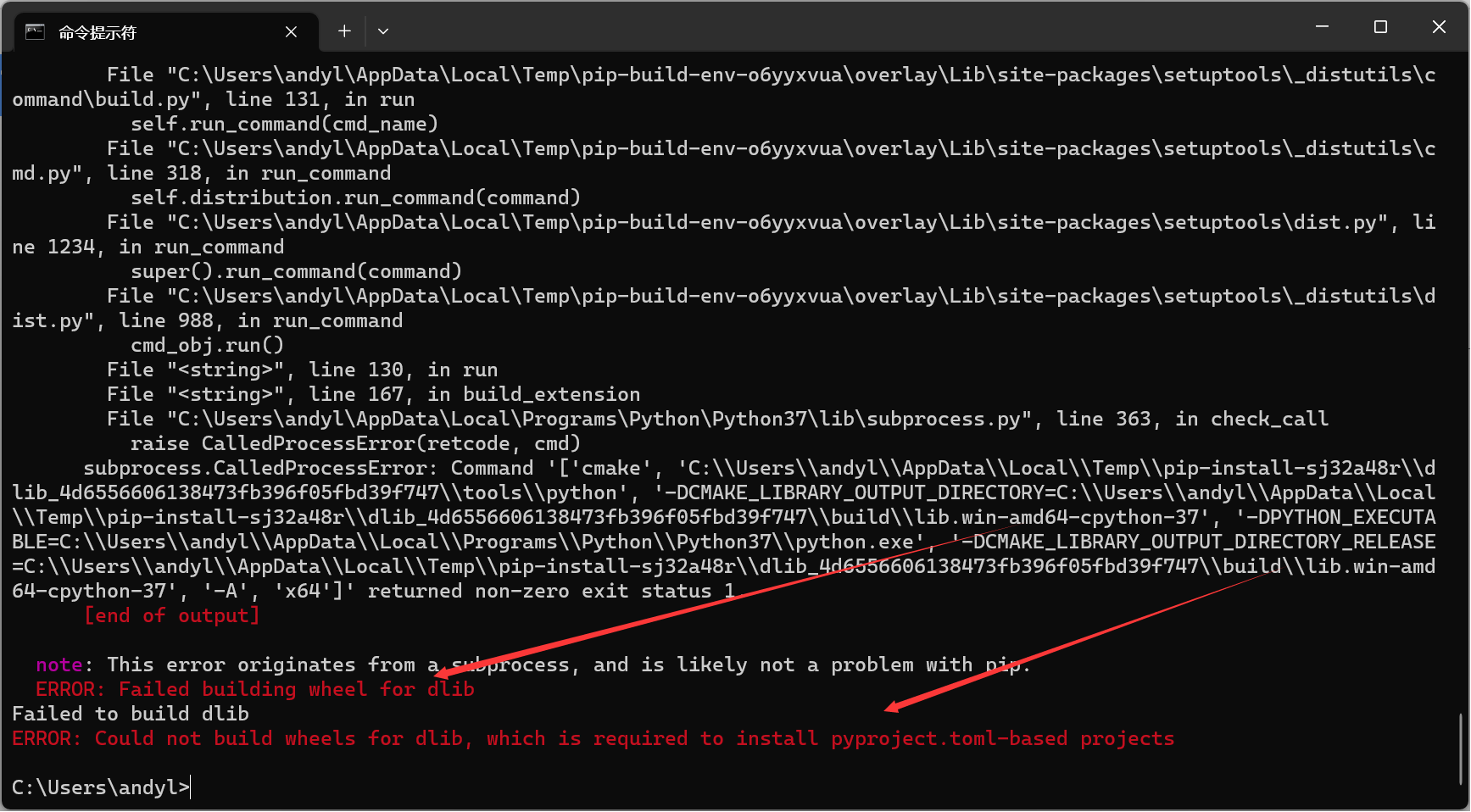
去找适配的python版本的dilp库版本

dilp人脸检测
代码
python
import cv2
import dlib
# get_frontal_face_detector()生成人脸检测器
# 使用HOG算法、线性分类器、金字塔图像结构和滑动窗口检测等技术。
# 比opencv提供的harr级联分类器效果更好
detector=dlib.get_frontal_face_detector()# 构造脸部位置检测器HOG
img=cv2.imread("people1.png")
# faces = detector(image,n)使用人脸检测器返回检测到的人脸框
# 参数:image: 待检测的可能含有人脸的图像。
# 参数n:表示采用上采样(放大)的次数。上采样会让图像变大,能够检测到更多人脸对象,提高小人脸的检测效果
#通常建议将此参数设置为 0 或 1。较大的值会增加检测的准确性,但会降低处理速度。
# 返回值faces:返回检测图像中的所有人脸框。
faces=detector(img,0)
for face in faces: #对每个人脸框进行逐个处理
# 获取人脸框的坐标
x1=face.left()
y1=face.top()
x2=face.right()
y2=face.bottom()
# 绘制人脸框
cv2.rectangle(img,(x1,y1),(x2,y2),(0,255,0),2)
# 显示捕获到的各个人脸框
cv2.imshow("result",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
python
x1=face.left()
y1=face.top()
x2=face.right()
y2=face.bottom()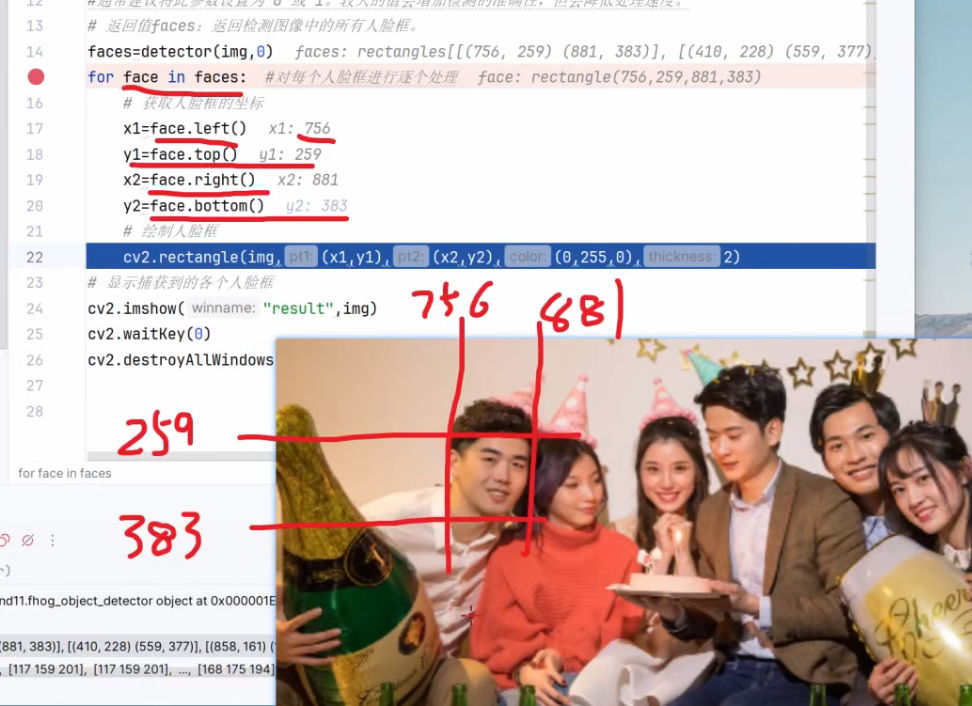
人像检测摄像头
代码
python
# import cv2
# import dlib
#
# cap=cv2.VideoCapture(0)# 摄像头初始化
# detector=dlib.get_frontal_face_detector()# 获得脸部位置检测器
# # 针对每一帧进行处理
# while True:
# ret,img=cap.read() # 捕获一帧
# if ret is None: # 没有捕获到帧,直接退出
# break
# # 可以将当前帧处理为灰度,方便后续计算
# gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# faces=detector(gray,0)
# for face in faces: #对每个人脸框进行逐个处理
# # 获取人脸框的坐标
# x1=face.left()
# y1=face.top()
# x2=face.right()
# y2=face.bottom()
# # 绘制人脸框
# cv2.rectangle(img,(x1,y1),(x2,y2),(0,255,0),2)
# # 显示当前帧,及捕获到的各个人脸框
# cv2.imshow("Dlib",img)
# # 如果按下Ecs键,则退出(Esc的ASCII码为27)
# if cv2.waitKey(1)==27:
# break
# cap.release()
# cv2.destroyAllWindows()
# opencv 与 dlib 对比
import cv2
import dlib
faceCascade=cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
detector=dlib.get_frontal_face_detector()# 获得脸部位置检测器
cap=cv2.VideoCapture('xiao.mp4')
while True:
ret,image=cap.read()
image=cv2.flip(image,1)
imaged=image.copy()
if ret is None:
break
gray=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
facesd = detector(gray, 0)
for face in facesd: #对每个人脸框进行逐个处理
# 获取人脸框的坐标
x1=face.left()
y1=face.top()
x2=face.right()
y2=face.bottom()
# 绘制人脸框
cv2.rectangle(imaged,(x1,y1),(x2,y2),(0,255,0),2)
faces=faceCascade.detectMultiScale(gray,scaleFactor=1.1,minNeighbors=16,minSize=(5,5))
for (x,y,w,h) in faces:
cv2.rectangle(image,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('opencv',image)
cv2.imshow('dlib',imaged)
key=cv2.waitKey(10)
if key==27:
break
cap.release()
cv2.destroyAllWindows()
#
#
#
#
#
#
#
#
#
#关键点定位
代码
python
'''关键点定位:表示定位到人脸的眼睛、鼻子、眉毛、轮廓等'''
# import numpy as np
# import cv2
# import dlib
#
# img = cv2.imread("teacherli.jpg")# 读取图像
# detector = dlib.get_frontal_face_detector()#构造人脸检测器
# faces = detector(img, 0)#检测人脸
# #dlib.shape_predictor载入模型(加载预测器)
# # 可以从https://github.com/davisking/dlib-models下载
# predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# for face in faces: #获取每一张脸的关键点(实现检测)
# shape=predictor(img, face)# 获取关键点
# # 将关键点转换为坐标(x,y)的形式
# # landmarks = np.matrix([[p.x, p.y] for p in shape.parts()])
# landmarks = np.array([[p.x, p.y] for p in shape.parts()])
# #绘制每一张脸的关键点(绘制shape中的每个点)
# for idx, point in enumerate(landmarks):
# # pos = (point[0, 0], point[0, 1])# 当前关键的坐标
# pos = [point[0],point[1]]# 当前关键的坐标
# # 针对当前关键点,绘制一个实心圆
# cv2.circle(img, pos, 2, color=(0, 255, 0),thickness=-1)
# # 普通大小的等宽字体 线条类型:抗锯齿线条。
# cv2.putText(img, str(idx), pos, cv2.FONT_HERSHEY_SIMPLEX, 0.4,
# (255, 255, 255), 1, cv2.LINE_AA)
# cv2.imshow("img", img)
# cv2.waitKey()
# cv2.destroyAllWindows()
"""摄像头检测68关键点"""
import cv2
import dlib
import numpy as np
cap=cv2.VideoCapture(0)# 摄像头初始化
detector=dlib.get_frontal_face_detector()# 获得脸部位置检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 针对每一帧进行处理
while True:
ret,img=cap.read() # 捕获一帧
img=cv2.flip(img, 1) # 图片翻转,水平翻转(镜像)
if ret is None: # 没有捕获到帧,直接退出
break
# 可以将当前帧处理为灰度,方便后续计算
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces=detector(gray,0)
for face in faces: #对每个人脸框进行逐个处理
shape = predictor(img, face)
landmarks = np.array([[p.x, p.y] for p in shape.parts()])
for idx, point in enumerate(landmarks):
pos = [point[0], point[1]] # 当前关键的坐标
cv2.circle(img, pos, 2, color=(0, 255, 0))
# 普通大小的等宽字体 线条类型:抗锯齿线条。
cv2.putText(img, str(idx), pos, cv2.FONT_HERSHEY_SIMPLEX, 0.4, (255, 255, 255), 1, cv2.LINE_AA)
# 显示当前帧,及捕获到的各个人脸框
cv2.imshow("68points",img)
# 如果按下Ecs键,则退出(Esc的ASCII码为27)
if cv2.waitKey(10)==27:
break
cap.release()
cv2.destroyAllWindows()轮廓检测
代码
python
import numpy as np
import dlib
import cv2
def drawLine(start,end): #将指定的点连接起来
pts = shape[start:end] # 获取点集
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(image, ptA, ptB, (0, 255, 0), 2)
def drawConvexHull(start,end):
#将指定的点构成一个凸包,绘制成轮廓,一般眼睛、嘴使用凸包用来绘制
Facial = shape[start:end+1]
mouthHull = cv2.convexHull(Facial) # 凸包函数
cv2.drawContours(image, [mouthHull], -1, (0, 255, 0), 2)#(0, 255, 0)是轮廓的颜色 后面的2是轮廓的宽度,如果是-1的话就是填充
image=cv2.imread("teacherli.jpg")
detector = dlib.get_frontal_face_detector()# 构造脸部位置检测器
faces = detector(image, 0)#检测人脸方框位置
#读取人脸关键点定位模型
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
for face in faces:# 对检测到的rects,逐个遍历
shape = predictor(image, face) # 获取关键点
# 将关键点转换为坐标(x,y)的形式
shape = np.array([[p.x, p.y] for p in shape.parts()])
drawConvexHull(36,41) # 绘制右眼凸包
drawConvexHull(42,47) # 绘制左眼凸包
drawConvexHull(48,59) #绘制嘴外部凸包
drawConvexHull(60,67) # 绘制嘴内部凸包
drawLine(0,17) # 绘制脸颊点线
drawLine(17,22) # 绘制左眉毛点线
drawLine(22,27) # 绘制右眉毛点线
drawLine(27,36) # 绘制鼻子点线
cv2.imshow("Frame", image)
cv2.waitKey()
cv2.destroyAllWindows()环境问题不要问大模型目前的大模型比较糟糕
疲劳检测
代码
python
"""疲劳检测,可用于驾驶员监控、学员上课状态检测等。"""
import numpy as np
import dlib
import cv2
from sklearn.metrics.pairwise import euclidean_distances #计算欧氏距离
from PIL import Image, ImageDraw, ImageFont
def eye_aspect_ratio(eye):
"""---------计算眼睛纵横比--------------"""
# 1 2
# 0 3 <----这是眼睛的6个关键点
# 5 4
#---------------------------------------------
A = euclidean_distances(eye[1].reshape(1,2), eye[5].reshape(1,2))
B = euclidean_distances(eye[2].reshape(1,2), eye[4].reshape(1,2))
C = euclidean_distances(eye[0].reshape(1,2), eye[3].reshape(1,2))
ear = ((A + B) /2.0) / C#纵横比
return ear
def cv2AddChineseText(img, text, position, textColor=(255, 0, 0), textSize=50):
""" 向图片中添加中文 """
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))#实现array到image的转换
draw = ImageDraw.Draw(img)# 在img图片上创建一个绘图的对象
# 字体的格式
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8")
draw.text(position, text, textColor, font=fontStyle) # 绘制文本
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)# 转换回OpenCV格式
def drawEye(eye):#绘制眼框凸包
eyeHull = cv2.convexHull(eye)
cv2.drawContours(frame, [eyeHull], -1, (0, 255, 0), 1)
COUNTER = 0 # 闭眼持续次数统计
detector = dlib.get_frontal_face_detector()# 构造脸部位置检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")#读取人脸关键点定位模型
cap = cv2.VideoCapture(0)
while True:
ret,frame = cap.read()
faces = detector(frame, 0) # 获取人脸
for face in faces: # 循环遍历每一个人脸
shape = predictor(frame, face) #获取关键点
# 将关键点转换为坐标(x,y)的形式
shape = np.array([[p.x, p.y] for p in shape.parts()])
rightEye = shape[36:42] # 右眼,关键点索引从36到41(不包含42)
leftEye = shape[42:48] # 左眼,关键点索引从42到47(不包含48)
rightEAR = eye_aspect_ratio(rightEye)# 计算右眼纵横比
leftEAR = eye_aspect_ratio(leftEye)# 计算左眼纵横比
ear = (leftEAR + rightEAR) / 2.0# 均值处理
if ear < 0.3: #小于0.3认为闭眼,也可能是眨眼
COUNTER += 1 # 每检测到一次,将+1
if COUNTER >= 50: #持续50帧都闭眼,则警报
frame = cv2AddChineseText(frame, "!!!!危险!!!!", (250,250))
# 宽高比>0.3,则计数器清零、解除疲劳标志
else:
COUNTER = 0 #闭眼次数清零
drawEye(leftEye) #绘制左眼凸包
drawEye(rightEye) #绘制右眼凸包
info = "EAR: {:.2f}".format(ear[0][0])
frame = cv2AddChineseText(frame, info, (0,30))#显示眼睛闭合程度值
cv2.imshow("Frame", frame)
if cv2.waitKey(1) == 27:
break
cv2.destroyAllWindows()
cap.release()dlib---人脸应用实例---表情识别
实现方法:
人在微笑时,嘴角会上扬,嘴的宽度和与整个脸颊(下颌)的宽度之比变大。
M/J > 0.45

一个一个点并不是一个一个点而是圆圈
((A+B+C)/3)/M>0.5