前言
深度求索公司又一次延续了它假期前搞事情的风格(依然记得春节被DeepSeek-R1支配的恐惧),国庆放假前夕,9月29日下午距离DeepSeek-V3.1 Terminus发布仅仅过去一周,全新一代DeepSeek-V3.2-Exp模型就正式亮相了,同时发布了相关论文。

本次更新中DeepSeek开创性的提出了一项全新的技术DeepSeek Sparse Attention (DeepSeek稀疏注意力机制),简称DSA,首次在长上下文场景中实现了细粒度的动态稀疏注意力,最终实现大模型训练和推理效率的跨代级提升。本期内容笔者将和大家一起快速了解DeepSeek-V3.2模型特性,并为大家快速解读DeepSeek V3.2论文核心要点,深入了解DSA(DeepSeekSparse Attention)这项跨时代技术的底层原理以及V3.2模型的训练流程。
一、DeepSeek-V3.2核心特性
1.1 DSA高效训练提升
DeepSeek-V3.2是基于V3.1模型在引入DSA算子后经过后训练得到的全新模型。根据官方发布的公告显示,DSA算子能够将模型的训练和推理效率提高30%-50%。
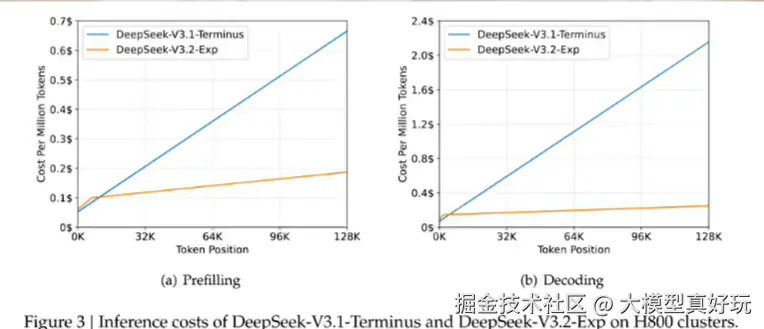
尽管相比DeepSeek-V3.1模型,DeepSeek-V3.2模型没有实质性的性能提升,评测结果如下图。但训练效率的提升本身就是巨大的技术进步,更高的训练效率意味着更低的训练成本,这务必也会为未来更大规模长文本的模型训练奠定扎实的技术基础。要知道在评测中5%的提升是重大进步,10%的提升可以称为巨大进步,而像DSA这种一出手就提升50%的技术,谁知道会不会又引领一波未来大模型训练的潮流?这么看DeepSeek的小版本更新还是太低调了。
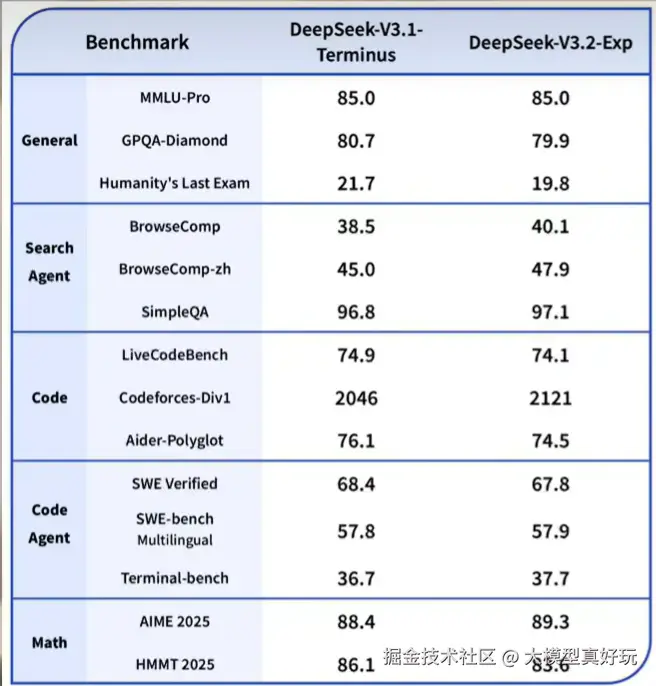
1.2 低廉调用成本
对于开发者来说DeepSeek-V3.2发布的最大利好是模型调用成本大幅降低。得益于DSA技术的应用,可以说DeepSeek再次有效内卷,刷新了大模型的价格底线,这样的公司给咱们开发者来一打。
根据官方通告目前V3.2还属于实验性版本,后续将在此模型基础上进一步优化性能。DeepSeek-V3.2已经全面开源,DSA论文已在Github上发布,模型权重也在ModelScope和HuggingFace上开源。
API方面V3.2模型也已经全面替换V3.1模型正式上线,开发者可以使用deepseek-chat调用模型的对话模式,使用deepseek-reasoner调用模型的推理模式。因为是实验性的发布,DeepSeek也保留了V3.1-Terminus的访问接口,只需要修改base_url为"https://api.deepseek.com/v3.1_terminus_expires_on_20251015"就可以访问DeepSeekV3.1-Terminus模型。
二、DSA技术详解
DeepSeek-V3.2 模型是在DeepSeek-V3.1模型基础上继续训练得到,二者在架构上的唯一区别是V3.2模型引入了DSA------DeepSeek Sparse Attention(DeepSeek稀疏注意力)机制,也是整个DeepSeek-V3.2模型的核心。
2.1 什么是注意力机制?
首先我们来了解什么是大模型的注意力机制,大模型预训练时的核心任务是根据前面的文字去预测后面最可能出现的文字。为了预测更加准确,它必须知道前面哪些字词和当前预测最相关,而注意力机制的作用就是在每次预测下一个词之前,帮模型快速挑选包含重点信息的词。
举个例子:"今天苹果公司在发布会上发布了iphone17"这句话如果围绕"苹果公司在发布会发布了"进行后续文本预测,模型首先会遍历每个词,经过复杂计算得到重点词的权重,权重越高表示该词对下面词语的预测作用越大。比如这里会把注意力更多分配给"发布会","公司"等词,并判断这里的苹果是公司名称而不是水果。
2.2 DSA稀疏注意力机制简介
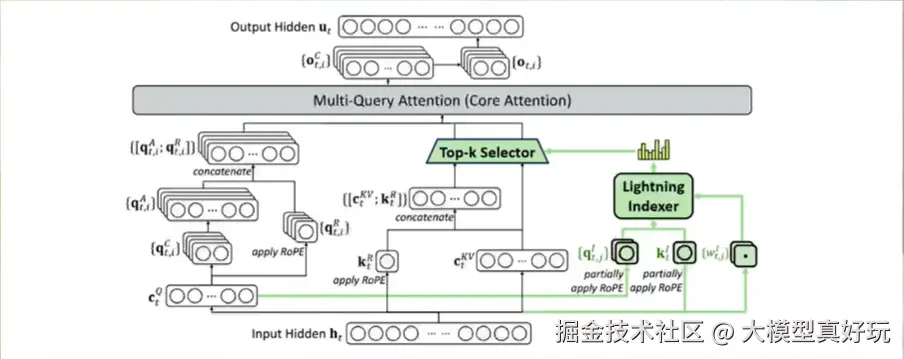
所谓稀疏注意力机制就是不再让模型复杂计算前面每个词的注意力权重,而是先用一个轻量的"索引器"快速扫描一遍,找出最有可能相关的几段文本,再只对这些关键文本进行精确计算。
对稀疏注意力来说,起决定性作用的是轻量级的索引器。不同于现有的其它稀疏注意力机制,DSA开创性地提出了名为lightning indexer闪电索引器和一个细粒度令牌选择机制。传统稀疏注意力机制往往基于规则或固定流程进行筛选,而闪电索引器关键在于先轻量级快速全局扫描,然后动态调整重点关注的部分,从而提高索引器的执行效率。并且由于DeepSeek-V3.2是在V3.1基础上训练的,V3.2模型的DSA是基于MLA实现的,具体架构如图所示:
2.3 DeepSeek-V3.2后训练机制
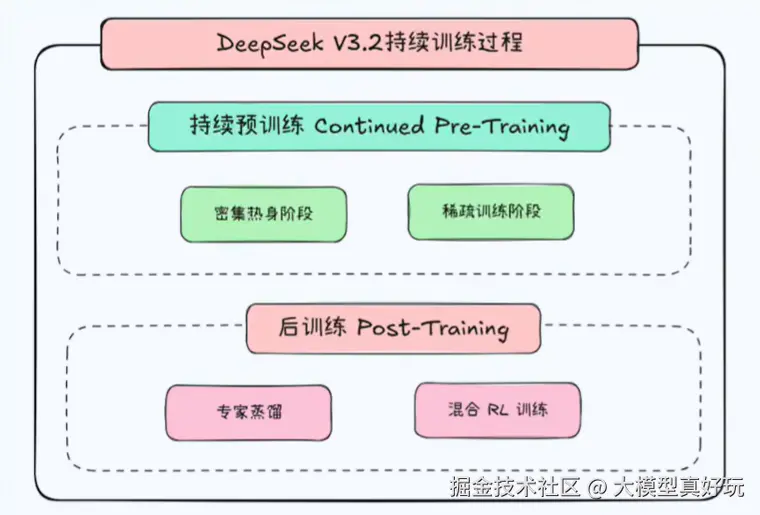
DeepSeek不但设计了DSA算子,还开创了四阶段后训练流程:
- 第一阶段是密集热身训练,用于完成DSA闪电索引器的参数训练
- 第二阶段是稀疏训练阶段, 将代入模型全部参数和DSA一起训练
- 第三阶段是专家蒸馏,采用专家模型输出一些如编程、Agent工具调用等数据对V3.2模型进行蒸馏
- 第四阶段是RL强化学习混合训练,采用GRPO算法进一步将模型表现与人类偏好对齐。
其中蒸馏和RL强化学习混合训练是DeepSeek-R1模型新提出的训练方法,经历这四个阶段训练的DSA算子不仅能让原始模型保持既有性能,同时大幅降低模型的推理计算成本。随着模型上下文越长,DSA算法的作用越显著,推理成本下降也越显著。
三、总结
DeepSeek-V3.2的发布再次宣告深度求索公司在大模型领域的核心地位,一个公司只有脚踏实地的技术沉淀才能屹立于强敌之林而不倒。虽然DeepSeek-V3.2相比DeepSeek-V3.1没有显著的性能提升,但DSA算法可谓是一项当之无愧的重大技术创新,一旦降低了模型训练成本,未来就会有更大的模型训练和探索空间,相信DeepSeek论文中提出的DSA训练流程相信很快也将被广泛应用到各主流模型的训练过程中。本篇内容分享就全部结束啦,同时笔者的《深入浅出LangChain&LangGraph》系列文章假期也会继续更新,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩, 免费获得笔者工作实践中的大模型相关资料分享。