我的笔记更多是记录个人学习过程中理解上的难点以及对于代码逻辑进行整体梳理,对细节print输出,更多还是给自己看的,大家不习惯的还是推荐去看原教程和代码,如下。
all-in-rag/docs/chapter4/12_query_construction.md at main · datawhalechina/all-in-rag · GitHub
本章的主要目的是学习查询检索。这里讲的正是查询。
用户提出了一个问题,是人类语言,大模型需要去数据库中找相关数据,怎样对齐这两种语言呢?
查询构建就是将文本请求转化为sql相关字段,让大模型可以直接利用数据库来寻找可信的数据。

下面是查询索引在RAG中的位置,可以看到,查询构建在向量化嵌入这一步,他完成的正是文本和数据库之间的沟通桥梁这个作用。
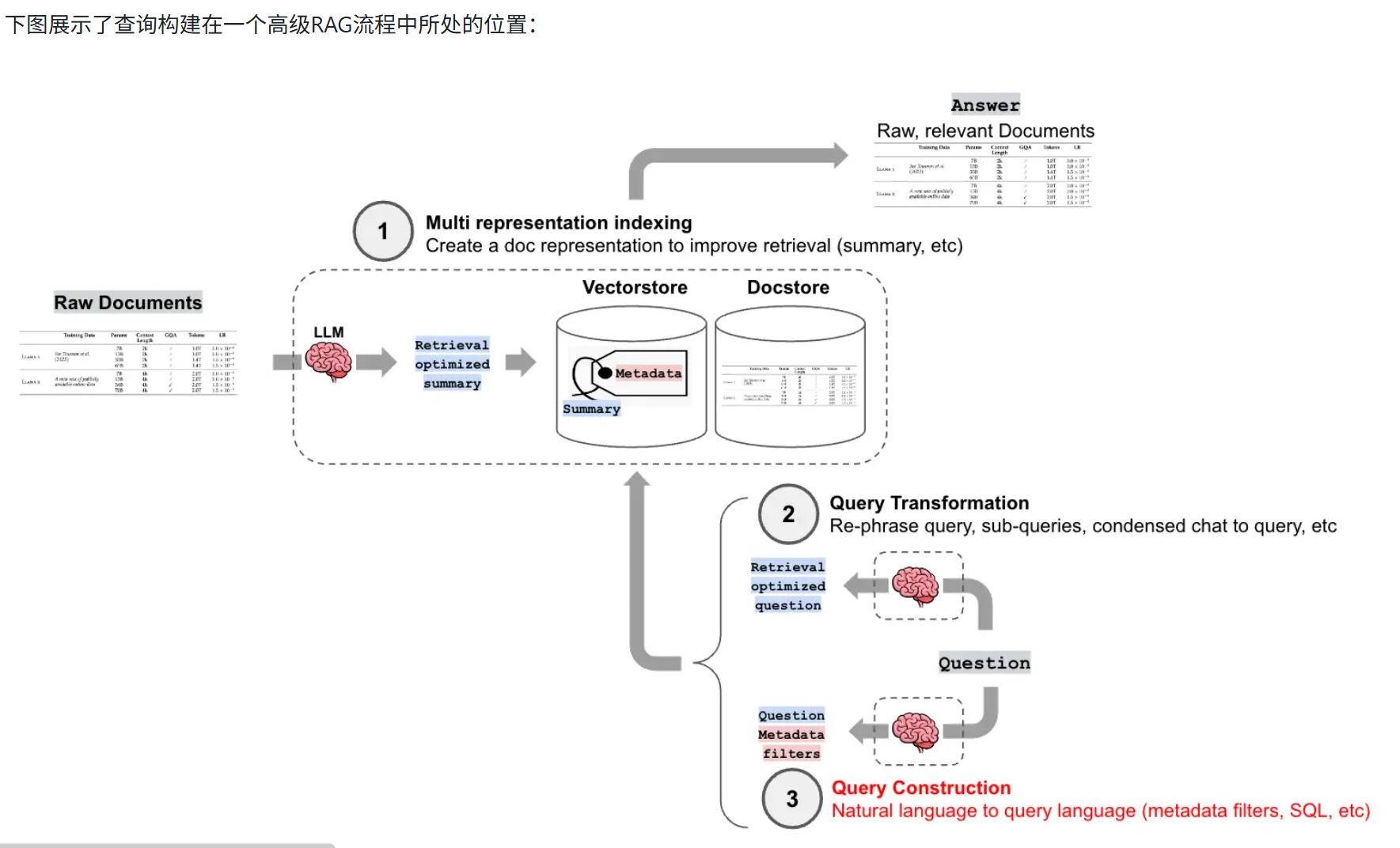
那这个桥梁是怎么起作用的呢?
其实上一节学到文本的索引里会包含一些摘要之类的帮助快速查找的元数据,我们在元数据中将sql中专业的字段和自然语言熟悉的description(描述)联系起来。把这个描述送进LLM里,大模型就可以联系二者,判断出需要索引的数据库字段是哪个~

最后介绍一下整体代码逻辑,这个代码逻辑是我在这一章里理解起来最流畅的,干杯!
他仍然遵循数据处理,向量构建,对齐文本与SQL,输出结果这个标准流程。
首先数据处理也就是它的目的部分,将b站视频相关数据爬取下来,查询他的播放量,作者等。我们的目的是查询"时间最短的视频","时长大于600秒的视频"。b站相关视频的数据比较杂,所以我们逐条过滤取需要的字段加入元数据中。
# 1. 初始化视频数据
video_urls = [
"https://www.bilibili.com/video/BV1Bo4y1A7FU",
"https://www.bilibili.com/video/BV1ug4y157xA",
"https://www.bilibili.com/video/BV1yh411V7ge",
]
bili = []
try:
loader = BiliBiliLoader(video_urls=video_urls)
docs = loader.load()
for doc in docs:
original = doc.metadata
# 提取基本元数据字段
metadata = {
'title': original.get('title', '未知标题'),
'author': original.get('owner', {}).get('name', '未知作者'),
'source': original.get('bvid', '未知ID'),
'view_count': original.get('stat', {}).get('view', 0),
'length': original.get('duration', 0),
}
doc.metadata = metadata
bili.append(doc)然后是向量存储和配置元数据字段信息。
利用智源的模型进行向量嵌入,将过滤的数据信息和描述整合起来形成接下来要使用的元数据。
# 2. 创建向量存储
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vectorstore = Chroma.from_documents(bili, embed_model)
# 3. 配置元数据字段信息
metadata_field_info = [
AttributeInfo(
name="title",
description="视频标题(字符串)",
type="string",
),
AttributeInfo(
name="author",
description="视频作者(字符串)",
type="string",
),
AttributeInfo(
name="view_count",
description="视频观看次数(整数)",
type="integer",
),
AttributeInfo(
name="length",
#description="视频长度(整数)",
description = "视频长度/时长(整数,单位:秒),可用于查找最短、最长或特定时长的视频",
type="integer"
)
]最后是最核心的部分,创建自查询检索器。
首先引入大模型,然后将大模型,向量存储库,文件内容描述和元数据都送入检索器,准备进行查询。
# 4. 创建自查询检索器
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
api_key=os.getenv("DEEPSEEK_API_KEY")
)
retriever = SelfQueryRetriever.from_llm(
llm=llm,
vectorstore=vectorstore,
document_contents="记录视频标题、作者、观看次数等信息的视频元数据",
metadata_field_info=metadata_field_info,
enable_limit=True,
verbose=True
)
# 5. 执行查询示例
queries = [
"时间最短的视频",
"时长大于600秒的视频"
]
for query in queries:
print(f"\n--- 查询: '{query}' ---")
results = retriever.invoke(query)查看输出结果会发现,查询第一条失败,第二条成功了。
这说明我们的模型可以完成检索相关的工作,无法完成排序比较相关的工作。
--- 查询: '时间最短的视频' ---
INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
INFO:langchain.retrievers.self_query.base:Generated Query: query=' ' filter=None limit=1
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则
作者: 二次元的Datawhale
观看次数: 18788
时长: 1063秒
==================================================
--- 查询: '时长大于600秒的视频' ---
INFO:httpx:HTTP Request: POST https://api.deepseek.com/v1/chat/completions "HTTP/1.1 200 OK"
INFO:langchain.retrievers.self_query.base:Generated Query: query=' ' filter=Comparison(comparator=<Comparator.GT: 'gt'>, attribute='length', value=600) limit=None
WARNING:chromadb.segment.impl.vector.local_hnsw:Number of requested results 4 is greater than number of elements in index 3, updating n_results = 3
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】03.Prompt如何迭代优化
作者: 二次元的Datawhale
观看次数: 7090
时长: 806秒
==================================================
标题: 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则
作者: 二次元的Datawhale
观看次数: 18788
时长: 1063秒ok,代码看完了。所以后面有自定义完成每个步骤的(那个可以完成排序任务),理解会更深入,但是同时也非常烧脑。
这是我看的最流畅的代码了!其他的都好烧脑~