针对消息丢失这一分布式系统的核心挑战,我将从消息传递链路的六个关键环节出发,构建一套多层次、递进式的完整解决方案。这套方案从最基础的可靠性配置,逐步升级到最终的业务补偿,并提供一套量化的选择框架。
📊 消息丢失的环节与解决方案全景图
下图清晰地展示了消息从生产到消费的全链路中,六个可能丢失的关键环节及其应对策略的逻辑关系,帮助你建立整体视图:
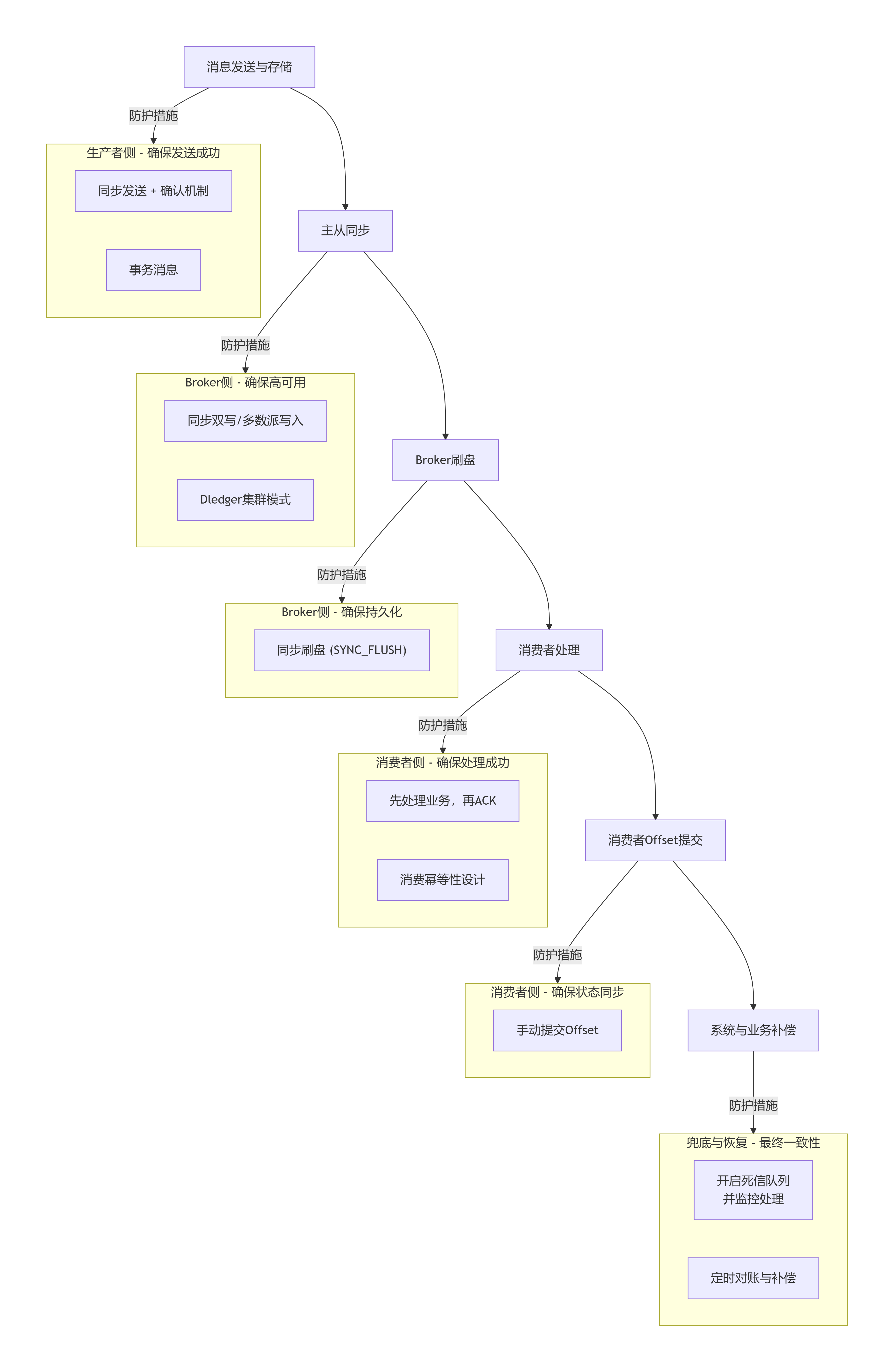
🛡️ 各环节深度解决方案与配置
生产者发送阶段
📊 如何选择与组合方案?
你可以根据业务场景的可靠性要求,参考下图来选择不同层次的方案进行组合:
注:所有方案生效的前提是Broker端采用了可靠的配置(如
SYNC_FLUSH同步刷盘和SYNC_MASTER主从同步),这需要运维侧配合,单靠生产者无法保证。
🚨 特别注意事项
📝 总结
要在生产者发送阶段防止消息丢失,你需要构建一个纵深防御体系:
Broker存储阶段
在Broker存储阶段防止消息丢失,核心在于通过配置确保消息持久化到磁盘 并在多副本间同步。梳理了从单节点到高可用集群的详细配置方案。
🗂️ Broker存储可靠性核心配置
Broker的可靠性主要通过 "刷盘策略" 和 "主从复制模式" 两个维度控制。你可以根据下表理解其配置与影响:
| 配置维度 | 可选模式 | 数据安全性与性能影响 | 适用场景 |
|---|---|---|---|
刷盘策略 (flushDiskType) |
同步刷盘 (SYNC_FLUSH) | 安全高 :消息写入物理磁盘后才返回成功。 性能低:写入延迟增加(约10倍)。 | 金融交易、核心订单等对可靠性要求极高的场景。 |
| 异步刷盘 (ASYNC_FLUSH) | 安全低 :消息写入内存即返回,有丢电丢消息风险。 性能高。 | 日志采集、状态跟踪等容忍少量丢失的场景。 | |
主从复制 (brokerRole) |
同步复制 (SYNC_MASTER) | 可用性高 :消息从Master复制到Slave后才返回成功。 性能中:增加单次写入延迟。 | 通用业务,需要保证主节点宕机时消息不丢失。 |
| 异步复制 (ASYNC_MASTER) | 可用性中 :消息写入Master即返回,复制异步进行,有极小丢失窗口。 性能高。 | 对性能敏感,允许极端情况下丢失少量数据的场景。 |
🔧 配置操作与部署建议
1. 单节点Broker配置 (最常用)
如果你的Broker以单主模式运行,核心任务是确保同步刷盘 。修改 conf/broker.conf 文件:
# 关键配置:启用同步刷盘
flushDiskType = SYNC_FLUSH
# 其他重要参数
# Broker节点名称,同一集群内需唯一
brokerName = broker-a
# Broker角色,单节点通常为 ASYNC_MASTER(因为无Slave可复制)
brokerRole = ASYNC_MASTER
# 每个队列的默认大小,根据磁盘和内存调整
mapedFileSizeCommitLog = 1073741824 # 1GB重启Broker生效 :./mqbroker -c ../conf/broker.conf
2. 主从架构部署 (高可用)
为了避免单点故障导致服务不可用和数据丢失,必须部署主从。
3. 启用Dledger集群 (生产环境推荐)
Dledger基于Raft协议,实现了真正的多副本强一致和数据高可用,是当前生产环境的标准方案。
📊 不同场景的配置组合方案
你可以根据业务需求,参考下表选择并组合配置:
| 可靠性要求 | 推荐配置组合 | 预期效果 | 业务场景举例 |
|---|---|---|---|
| 基础可靠 | ASYNC_FLUSH + ASYNC_MASTER (单节点或主从) |
性能最佳,但存在服务器断电丢消息、主节点宕机丢消息的风险。 | 应用日志、监控数据上报。 |
| 标准可靠 | SYNC_FLUSH + SYNC_MASTER (主从架构) |
最通用平衡方案。可防止单机断电丢失,主节点故障时数据不丢失。 | 绝大多数电商订单、状态通知。 |
| 金融级可靠 | 启用Dledger集群 (自动包含同步刷盘和多数派复制) | 最高可靠性。可容忍 (N-1)/2 个节点同时故障,数据强一致。 | 资金交易、核心账务、分布式事务。 |
🚨 重要注意事项与监控
总结
Broker存储阶段的可靠性是消息不丢的基石。核心决策是:
通常建议从 SYNC_FLUSH + SYNC_MASTER 主从架构 起步,如需更高可用性则平滑升级到 Dledger 集群。
消费者处理阶段
消费者阶段是消息不丢失的最后一道防线,也是实现业务一致性的关键 。这个阶段的可靠性不依赖单一配置,而需要一套从处理流程、状态管理到容错设计的完整方案。
📋 消费者端防丢失核心方案一览
下表汇总了消费者端防止消息丢失或处理失败的四种核心思路,你可以根据对可靠性的要求进行选择和组合:
| 方案维度 | 核心措施 | 关键目的 | 可靠性等级 |
|---|---|---|---|
| 1. 消费状态管理 | 手动提交Offset | 基础:避免自动提交导致消息丢失。 | 基础级 |
| 2. 消费流程设计 | 先执行业务,再确认消费 | 核心:确保业务成功是确认消费的前提。 | 标准级 |
| 3. 消费容错设计 | 幂等性处理 + 死信队列 | 高级:应对重试带来的重复和无法处理的"毒药消息"。 | 高可靠级 |
| 4. 兜底与恢复 | 消息轨迹 + 业务对账 | 最高:用于排查和最终一致性补偿。 | 金融级 |
🔧 各方案详细实现与代码要点
1. 消费状态管理:使用手动提交Offset
这是防止消息丢失的第一原则。务必设置为手动提交,并在业务成功后提交。
// 1. 设置为手动提交Offset(这是默认且推荐的方式)
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("GROUP_NAME");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
// 2. 注册消息监听器,在回调中处理业务并手动返回消费状态
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
try {
// 执行你的核心业务逻辑(例如:更新订单状态)
boolean businessSuccess = processBusiness(msg);
if (!businessSuccess) {
// 业务逻辑失败,稍后重试
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
} catch (Exception e) {
// 发生未预期异常,稍后重试
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
// 所有消息处理成功,确认消费(提交Offset)
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});2. 消费流程设计:严格的"先处理,后确认"顺序
你必须保证 "业务事务" 在 "消息确认" 之前完成。下图清晰地展示了这一核心流程,以及异常情况下的处理路径:
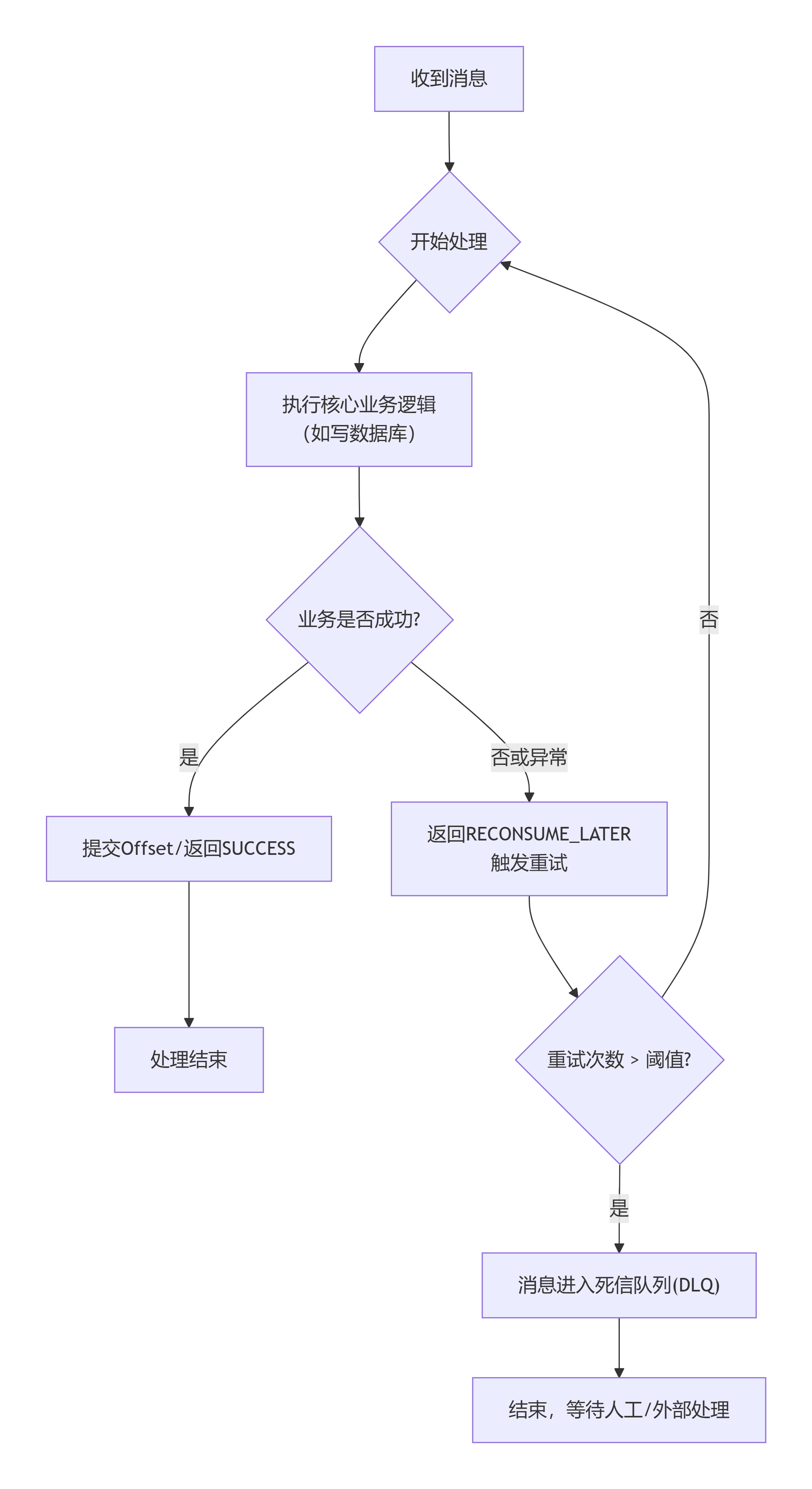
3. 消费容错设计:幂等性 + 死信队列(DLQ)
这是应对重试和异常消息的黄金组合。
4. 兜底与恢复:消息轨迹与业务对账
这是保证最终一致性的终极手段。
📊 方案选择与配置参考
根据你的业务场景,可以参考下表进行配置组合:
| 场景分类 | 推荐方案组合 | 配置与代码重点 |
|---|---|---|
| 普通业务 (通知、状态同步) | 手动提交 + 先处理再确认 + 基础幂等 | 1. 确认是手动提交。 2. 消费逻辑内做好异常捕获,失败返回RECONSUME_LATER。 3. 用Redis做简单幂等。 |
| 核心交易 (订单、资金) | 以上全部 + 死信监控 | 1. 加强幂等性(如结合数据库唯一约束)。 2. 部署独立的DLQ消费者并设置告警。 3. 考虑缩短消费超时时间 (consumeTimeout)。 |
| 金融级业务 | 以上全部 + 对账补偿 | 1. 开启消息轨迹。 2. 建立定期(如每小时)的自动化对账作业。 3. 消费逻辑可考虑实现异步确保型(本地事务表)。 |
⚠️ 关键注意事项
总结
在消费者阶段,确保消息不丢的黄金法则 是:手动提交Offset,并在业务事务成功完成后,才返回CONSUME_SUCCESS 。同时,必须用幂等性 来防御重试,用死信队列 来隔离异常,最终用对账补偿来兜底。
系统与业务补偿(兜底方案)
系统与业务补偿(兜底方案)是防止消息丢失的最后一道、也是最关键的一道防线 。它不关注"如何防止丢失",而是解决"丢失或不一致发生后,如何发现和恢复"的问题。
这套方案的核心思想是 "主动探测,事后补偿" ,通过技术监控和业务对账,确保系统最终一致。下图清晰地展示了兜底方案的核心组成部分及其工作流程:
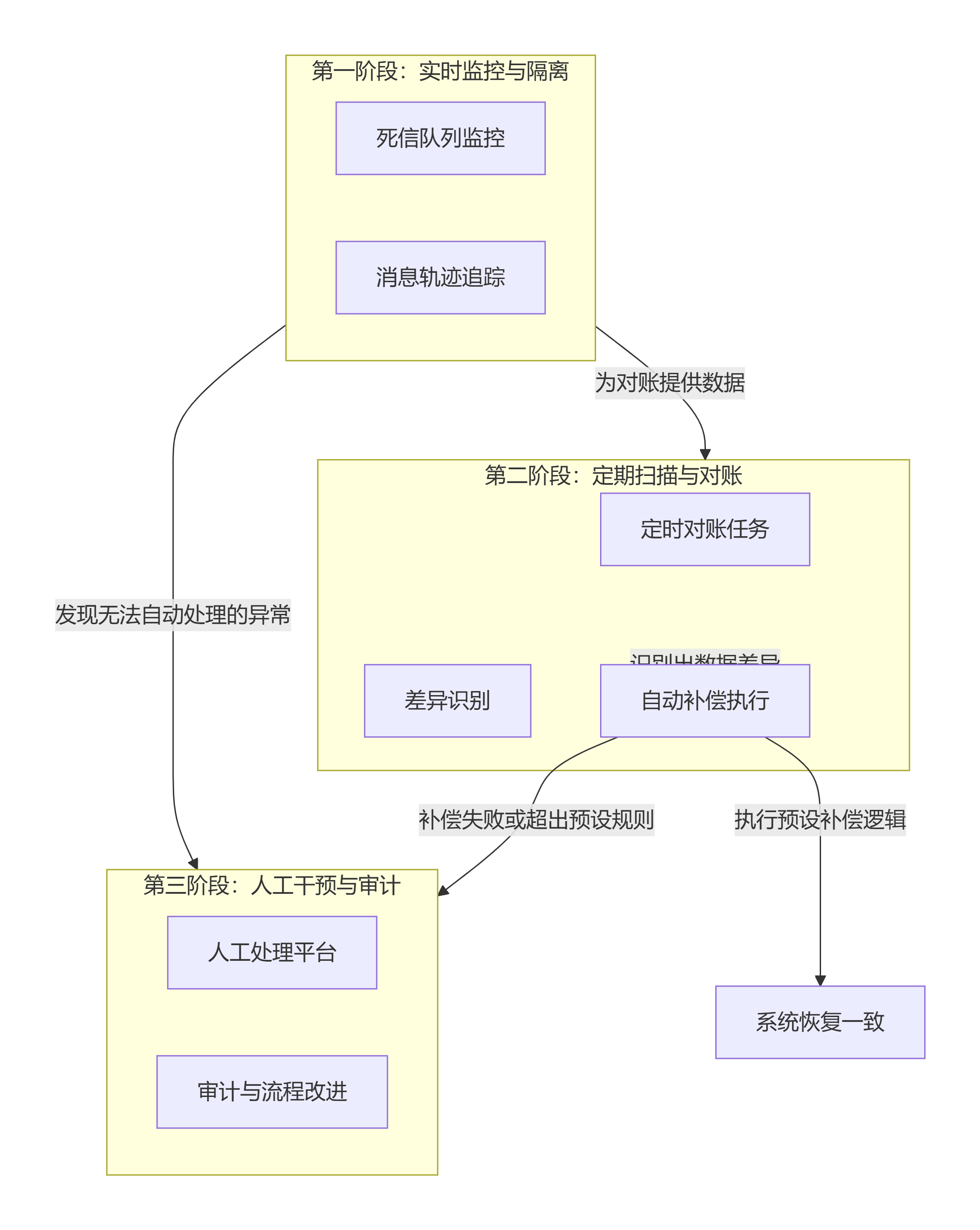
🔍 详细方案分解
1. 实时监控与自动隔离
这是兜底方案的第一道自动化关卡,目标是即时发现问题并隔离,防止影响扩散。
2. 定期扫描与对账补偿
这是兜底方案的核心 ,通过离线作业比对数据,解决那些监控无法发现的静默丢失 或逻辑不一致。
3. 人工干预与审计平台
对于自动补偿失败的复杂案例,必须提供清晰的人工操作界面。
📊 实施建议:分阶段构建
根据业务的重要性,你可以分阶段引入这些兜底措施:
| 阶段 | 核心建设 | 适用场景 | 关键产出 |
|---|---|---|---|
| 第一阶段 (基本可用) | 1. 为所有核心业务消费者组 配置DLQ监控和告警 。 2. 启用消息轨迹,便于排查。 | 所有上线业务 | 实时告警能力、问题排查工具 |
| 第二阶段 (标准可靠) | 针对最重要的1-2个核心链路(如支付成功回调),实现每日T+1对账。 | 核心交易链路 | 每日对账报告、部分自动补偿 |
| 第三阶段 (高可靠) | 将对账周期缩短至每小时级 ,并搭建人工业务操作平台处理差错单。 | 金融、资金类业务 | 近实时差异发现、人工处理流程 |
| 第四阶段 (主动运维) | 将对账结果反向推动消息链路的前端架构、代码逻辑和监控的改进,形成闭环。 | 追求卓越的系统 | 系统健壮性持续提升 |
⚠️ 核心原则与注意事项
总结 :一个健壮的消息系统,其兜底方案不是单一的"杀手锏",而是一个从实时监控到离线对账,再到人工干预的立体化防御体系 。它的价值不仅在于事后补救,更在于通过持续发现的差异,倒逼前置环节(生产、消费)的架构和代码变得更为健壮,从而形成一个持续改进的闭环。
📈 方案选择与权衡指南
不同场景对消息可靠性的要求不同。你可以根据下表,结合业务需求与资源进行权衡决策:
| 方案组合 | 适用场景 | 可靠性 | 性能影响 | 复杂度 |
|---|---|---|---|---|
| 基础可用 (异步刷盘+异步主从+自动提交) | 日志收集、状态跟踪等容忍少量丢失的场景 | 较低 | 最低 | 低 |
| 标准可靠 (同步刷盘+同步主从+手动提交+消费幂等) | 绝大多数订单、交易、通知类业务 | 高 | 中等 | 中等 |
| 金融级可靠 (Dledger集群+事务消息+DLQ监控+定期对账) | 资金扣减、核心账务变动等要求极高的场景 | 极高 | 较高 | 高 |
核心建议:
-
核心风险:网络抖动、Broker宕机导致发送失败。
-
解决方案:
-
同步发送 + 发送状态检查 :务必使用
send()同步方法,并检查返回的SendResult。确保SendStatus为SEND_OK,这仅表示消息已到达Broker内存,不保证持久化。 -
事务消息:用于保证本地数据库操作与消息发送的原子性。适用于充值、下单等强一致性场景。
-
失败重试 :设置
retryTimesWhenSendFailed(默认2次)。重试可能造成消息重复,需配合消费者幂等性。
-
-
关键配置示例:
javaDefaultMQProducer producer = new DefaultMQProducer("ProducerGroup"); producer.setNamesrvAddr("localhost:9876"); producer.setRetryTimesWhenSendFailed(3); // 增加重试次数 producer.start(); SendResult result = producer.send(msg); if (result.getSendStatus() != SendStatus.SEND_OK) { // 记录日志、告警、落库,启动异步补偿任务 }🛡️ 生产者端防丢失核心方案
这些方案是从代码层面进行控制和加固,能预防绝大部分的发送失败。
方案层级 核心措施 关键实现与配置 可靠性提升等级 第一层:基础保障 同步发送 + 确认机制 使用 send()同步方法,并检查SendResult状态是否为SEND_OK。这是最基础也是必须的步骤。基础级 设置消息Key 为每条消息设置具有业务意义的唯一Key(如订单ID),这是后续排查和补偿的关键依据。 第二层:自动重试 启用SDK内置重试 客户端SDK内置了重试机制。可设置 setRetryTimesWhenSendFailed(默认2次),网络异常、超时或Broker短暂故障时会自动重试。标准级 第三层:可靠事务 事务消息 使用 TransactionMQProducer。用于保证本地数据库操作 与消息发送的最终一致性,是金融、交易等场景的刚需。金融级 第四层:业务兜底 业务层持久化与异步重试 当所有重试均失败后,将消息持久化到本地数据库或文件,由后台任务异步重试直至成功。这是防止消息丢失的终极业务兜底方案。 极高 💡 各方案关键点与示例
下面是几个核心方案的关键实现细节,能帮你更好地落地:
-
同步发送与检查 :这是所有方案的基石。发送后必须检查
SendResult。SendResult result = producer.send(msg); if (result.getSendStatus() != SendStatus.SEND_OK) { // 记录日志、告警,并触发持久化到DB等兜底逻辑 log.error("消息发送失败: {}", result); saveToDBForRetry(msg); // 存入数据库,启动后台重试 } -
事务消息流程:它分为两个阶段,解决本地事务和消息发送的原子性问题。
-
第一阶段 :发送半事务消息到Broker,此时消息对消费者不可见。
-
第二阶段 :执行本地事务(如更新订单状态),并根据结果(成功/失败)向Broker提交Commit 或Rollback指令。
-
回查机制:如果第二阶段因网络等原因未提交,Broker会定时回查生产者,确认消息最终状态。
-
-
业务兜底实现:当客户端重试耗尽后,应将消息落库,逻辑示例如下:
try { SendResult result = producer.send(msg); } catch (Exception e) { // 1. 将消息、Topic、业务Key、创建时间等存入本地数据库的“重试表” messageRetryService.saveToRetryTable(msg); // 2. 由独立的定时任务扫描“重试表”,重新调用生产者发送 }这是RocketMQ官方推荐的做法,因为客户端设计为无状态,将持久化重试交给业务应用更可靠。
-
"发送成功"的含义 :生产者收到
SEND_OK只表示消息已到达Broker内存 ,不代表已持久化到磁盘。要保证Broker断电不丢,必须配置flushDiskType = SYNC_FLUSH。 -
必须做 :使用同步发送并检查结果。
-
建议做 :启用SDK内置重试 ,并为消息设置业务Key以便追踪。
-
按需做 :对于分布式事务场景,使用事务消息 ;对于可靠性要求极高的场景,增加业务层持久化与异步重试的终极兜底。
-
重试带来的重复 :无论是SDK重试还是业务重试,都可能使消费者收到重复消息,必须在消费端实现幂等性处理。
-
流控处理:如果Broker因压力触发流控(错误码530),客户端会按指数退避策略重试。此时应监控告警,并评估是否需要扩容。
-
核心风险:服务器断电、磁盘损坏导致内存中消息丢失。
-
解决方案:
-
同步刷盘 (SYNC_FLUSH) :修改Broker配置
flushDiskType = SYNC_FLUSH。确保消息写入磁盘后才返回成功给生产者。这是防止单机Broker消息丢失最根本的手段,但性能下降约10倍。 -
主从同步 (SYNC_MASTER) :修改Broker配置
brokerRole = SYNC_MASTER。生产者发送消息时,需等待消息从Master同步至Slave后再返回成功。防止Master主机宕机导致消息丢失。 -
启用Dledger集群 :基于Raft协议,确保多数节点写入成功。这是当前生产环境高可用部署的推荐标准。
-
-
配置参考 (
broker.conf):# 采用同步刷盘,保证持久化 flushDiskType = SYNC_FLUSH # 采用同步主从,保证高可用(对性能有影响) brokerRole = SYNC_MASTER
-
架构:一组Master-Slave构成一个Broker组。
-
配置 :在Slave节点的配置文件中,指定其角色为
SLAVE,并指向Master的地址。# 在 slave 节点的 broker.conf 中 brokerRole = SLAVE brokerName = broker-a # 必须和其Master的brokerName一致 brokerId = 1 # 0表示Master,大于0表示Slave # 可以指定从哪个Master同步(通常通过namesrv自动发现) -
发送端设置 :生产者需将
sendLatencyFaultEnable设为true,以便在Master故障时自动切换到Slave。
-
准备:至少3个节点。
-
配置:在每个节点的配置文件中启用Dledger。
bash
# 在 broker.conf 中 enableDLegerCommitLog = true dLegerGroup = RaftNode00 # 集群组名,组内一致 dLegerPeers = n0-127.0.0.1:40911;n1-127.0.0.1:40912;n2-127.0.0.1:40913 # 集群内所有节点地址 # 当前节点标识,在组内唯一 dLegerSelfId = n0 brokerName = RaftNode00 # 建议与dLegerGroup一致 -
启动 :使用
./mqbroker -c ../conf/broker.conf启动所有节点。 -
优势 :消息写入需多数节点 成功;自动选主,故障秒级切换。
-
性能与资源权衡:同步刷盘和同步复制会显著增加写入延迟(约数毫秒到十数毫秒)。务必根据业务容忍度选择。
-
磁盘是关键 :使用高性能SSD 并确保充足空间。监控
CommitLog磁盘使用率,设置阈值告警(如>80%)。 -
必须监控:
-
消息堆积量 :
ConsumerLag,若持续增长可能消费能力不足。 -
写入/读取TPS:评估Broker负载。
-
节点健康状态:主从同步延迟、Dledger集群节点是否在线。
-
-
要防断电丢失,必须开启
SYNC_FLUSH同步刷盘。 -
要防主机宕机丢失,必须部署主从并开启
SYNC_MASTER同步复制,或直接采用更先进的 Dledger 集群。
-
核心风险:消费逻辑失败、进程崩溃,导致消息虽被消费但业务未实际处理。
-
解决方案:
-
可靠的消费逻辑 :遵循"先业务处理,后确认消费 "的原则。在
consumeMessage方法中,业务逻辑成功完成后,再返回CONSUME_SUCCESS。 -
手动提交Offset :避免使用
CONSUME_FROM_TIMESTAMP等可能跳过消息的自动提交方式。消费失败时,返回RECONSUME_LATER,让消息在指定延迟后重试。 -
消费幂等性设计 :这是必须项。由于生产者重试和消费者重试,同一条消息可能被投递多次。常用方法:
-
数据库唯一键:如订单ID。
-
Redis原子SetNX:设置消息唯一键,并设置合理过期时间。
-
-
-
消费端代码示例:
consumer.registerMessageListener((MessageListenerConcurrently) (msgs, context) -> { for (MessageExt msg : msgs) { String msgId = msg.getMsgId(); String bizId = msg.getKeys(); // 通常使用业务ID // 1. 检查幂等性 (例如用Redis判断bizId是否已处理) if (redisTemplate.opsForValue().setIfAbsent("CONSUMED:" + bizId, "1", 1, TimeUnit.HOURS)) { // 2. 执行核心业务逻辑 try { processBiz(msg); // 3. 业务成功,可确认消费(这里由框架自动返回SUCCESS) } catch (Exception e) { // 4. 业务失败,返回稍后重试 return ConsumeConcurrentlyStatus.RECONSUME_LATER; } } else { // 已消费过,直接确认 log.info("消息已消费,跳过重复处理: {}", bizId); } } return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; });
-
实现消费幂等性 (必须)
由于生产者重试和消费者
RECONSUME_LATER,同一条消息可能被多次消费。常用方案:-
数据库唯一键:利用业务ID(如订单号)作为唯一约束,重复插入会失败。
-
Redis原子操作 :使用
SETNX命令设置消息Key,并设置合理的过期时间。
// 示例:使用Redis实现幂等性检查 String messageId = msg.getMsgId(); String bizId = msg.getKeys(); // 建议使用业务ID,更稳定 String redisKey = "MSG_STATUS:" + bizId; // 尝试设置键值,如果已存在则设置失败 Boolean isNew = redisTemplate.opsForValue().setIfAbsent(redisKey, "PROCESSED", 10, TimeUnit.MINUTES); if (Boolean.TRUE.equals(isNew)) { // 首次处理,执行业务 processBusiness(msg); } else { // 已处理过,直接确认,避免重复业务操作 log.info("消息已处理,跳过: {}", bizId); } -
-
监控与处理死信队列 (DLQ)
当消息重试超过最大次数(默认16次)后,RocketMQ会将其自动转移到死信队列。必须监控和处理DLQ。
// 创建一个专门消费死信队列的消费者 DefaultMQPushConsumer dlqConsumer = new DefaultMQPushConsumer("DLQ_GROUP"); // Topic名称规则:%DLQ% + 消费者组名 dlqConsumer.subscribe("%DLQ%YOUR_CONSUMER_GROUP", "*"); // 处理死信消息(记录日志、告警、人工干预等)
-
开启消息轨迹 :在Broker和客户端启用
traceTopicEnable=true,便于追踪消息全链路。 -
建立业务对账机制:定期(如每天凌晨)扫描业务数据和消息消费记录,对状态不一致的数据进行补偿或人工修复。
-
Offset提交 :
CONSUME_SUCCESS会提交这一批消息 的Offset。如果一批10条,第5条失败返回RECONSUME_LATER,整批都会重试 。如需精细控制,可在processBusiness内做部分成功持久化。 -
重试间隔:重试消息的延迟级别会逐渐增加(从几秒到数小时),避免在业务高峰时雪崩。
-
并发度平衡 :
consumeThreadMin和consumeThreadMax设置需适中,过高会打垮DB,过低会导致堆积。
-
核心场景:当所有常规措施都失效(如Bug导致逻辑错误、极端异常数据),消息进入死循环重试或堆积时。
-
解决方案:
-
死信队列 (DLQ) :RocketMQ自动将重试超过最大次数(默认16次)的消息转入一个特殊的死信队列。必须监控和处理DLQ。
-
定时对账与补偿作业 :这是保证最终一致性的终极手段。根据业务周期(如每天凌晨),扫描业务数据和消息流水,对状态不一致的数据进行修补或人工干预。
-
-
死信队列监控与告警:
-
是什么 :任何重试超过最大次数(默认16次)的消息都会进入专属的
%DLQ%ConsumerGroupNameTopic。 -
怎么做:
-
部署监控:为所有重要的消费者组部署独立的DLQ监控消费者,或使用RocketMQ控制台、Prometheus监控DLQ消息堆积量。
-
设置阈值告警 :当DLQ中消息数在10分钟内增长超过一定数量(如50条),立即触发电话或短信告警。
-
编写处理程序 :根据业务规则,为DLQ编写自动重投递 或转储到数据库待处理的程序。
// 示例:一个简单的DLQ消费者,将消息转储到MySQL供人工处理 public class DLQConsumer { public static void main(String[] args) { DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("DLQ_PROCESS_GROUP"); consumer.subscribe("%DLQ%YOUR_BUSINESS_GROUP", "*"); consumer.registerMessageListener((msgs, context) -> { for (MessageExt msg : msgs) { // 1. 入库:将消息详情、重试原因、业务键存入“异常消息表” saveToExceptionTable(msg); // 2. 告警:发送钉钉/企微机器人通知 sendAlert(msg); // (可选)3. 根据某些规则尝试自动修复并重新投递到原Topic } return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; }); } } -
-
-
消息轨迹追踪:
-
启用 :在Broker和客户端配置
traceTopicEnable=true。 -
价值 :当用户投诉"我的订单没成功"时,可以通过
Message ID或Business Key在控制台完整追踪该消息的生产、存储、消费状态,快速定位是未发送、未消费还是消费失败。
-
-
对账系统设计:
-
对账粒度:通常按业务实体对账(如订单ID、支付流水号)。
-
数据源:
-
端A(消息发送方) :业务数据库的"主事务表"(如
orders表)。 -
端B(消息消费方) :业务数据库的"结果表"(如
account_balance表),或消息消费的流水日志。
-
-
对账Key :使用消息的
keys属性(即业务ID)。
-
-
对账流程与补偿:
-
扫描:定时任务(如每天凌晨2点)扫描T-1日"端A"所有应触发消息的业务记录。
-
比对:逐条检查对应的"端B"记录是否存在且状态一致。
-
处理差异:
差异类型 可能原因 补偿动作(示例) 端B数据缺失 消息根本未消费或消费严重失败 调用下游业务接口补发数据,或重新投递一条新的补偿消息。 状态不一致 消费逻辑有Bug或并发问题 生成差错单,通知人工介入检查业务逻辑。 数据重复 消费端幂等失效 触发数据合并或清理程序,并报警检查幂等逻辑。 -
结果处理:记录对账报告,成功补偿的标记完成,无法自动处理的生成"差错单"流转给人工。
-
-
功能:查询异常消息、查看对账差异单、手动重发消息、一键触发补偿、操作日志审计。
-
定位 :这是止血和修复 的平台,同时也是发现系统性风险的入口。
-
补偿的幂等性 :任何自动补偿逻辑(如重新投递消息、调用补单接口)本身也必须是幂等的,防止因重复执行产生新问题。
-
补偿的可终止性:补偿逻辑必须有明确的终止条件,避免无限循环。
-
人工优先原则:当自动化补偿策略不明确或存在风险时,应优先生成差错单交由人工判断,而非盲目执行。
-
成本与收益平衡:对账频率越高,覆盖越全面,资源消耗也越大。应根据业务价值和数据重要性进行权衡。
-
评估必要性:并非所有业务都需要"金融级可靠",过度设计会增加复杂度和成本。
-
明确写入保证 :理解
SEND_OK仅代表消息到达Broker内存 ,要保证不丢失,必须开启SYNC_FLUSH或部署Dledger。 -
幂等性是基石:只要使用了生产者重试或消费者重试,就必须实现消费幂等。
-
补偿不可缺:任何技术保障都有极限,必须配备死信队列监控和最终业务对账作为最后防线。
-