论文阅读 | ECCV 2024 | DAMSDet:具有竞争性查询选择与自适应特征融合的动态自适应多光谱检测变换器
- [1&&2. 摘要&&引言](#1&&2. 摘要&&引言)
- 3.方法
-
- [3.1 概述 (Overview)](#3.1 概述 (Overview))
-
- [3.2 模态竞争性查询选择 (Modality Competitive Query Selection)](#3.2 模态竞争性查询选择 (Modality Competitive Query Selection))
- [3.3 多光谱Transformer解码器 (Multispectral Transformer Decoder)](#3.3 多光谱Transformer解码器 (Multispectral Transformer Decoder))
- [4 实验](#4 实验)
- [4.1 数据集与评估指标 (Dataset and Metric)](#4.1 数据集与评估指标 (Dataset and Metric))
-
- [4.2 实现细节 (Implementation Details)](#4.2 实现细节 (Implementation Details))
- [4.3 与先进方法(SOTA)的比较 (Comparison with SOTA)](#4.3 与先进方法(SOTA)的比较 (Comparison with SOTA))
-
-
- [4.4 M3FD上的消融实验 (Ablation Study on M3FD)](#4.4 M3FD上的消融实验 (Ablation Study on M3FD))
-
- [5 结论](#5 结论)

题目:DAMSDet: Dynamic Adaptive Multispectral Detection Transformer with Competitive Query Selection and Adaptive Feature Fusion
期刊:ECCV(European Conference on Computer Vision )
论文:paper
代码:code
年份:2024
1&&2. 摘要&&引言
红外-可见光目标检测旨在通过融合红外和可见光图像的互补信息,实现鲁棒甚至全天候的目标检测。然而,高度动态变化的互补特性以及普遍存在的模态错位,使得互补信息的融合变得困难。
在本文中,我们提出了一种 动态自适应多光谱检测 Transformer(DAMSDet),以同时解决这两个挑战。具体来说:
-
本文·提出了一种 模态竞争性查询选择(Modality Competitive Query Selection, MCQS)策略,以提供有用的先验信息。该策略可以为每个目标动态选择基本显著的模态特征表示。
-
为了有效挖掘互补信息并适应错位情况,本文提出了一种 多光谱可变形交叉注意力(Multispectral Deformable Cross-attention, MDCA)模块,能够针对每个目标自适应地采样并聚合红外与可见光的多语义层级特征。
-
此外,我们进一步采用 DETR 的级联结构,以更好地挖掘互补信息。
本文的主要贡献可归纳如下:
- 提出了一种新颖的红外-可见光目标检测方法DAMSDet,能够动态聚焦主导模态目标并自适应融合互补信息
- 提出了多模态初始化查询的竞争性选择策略,动态感知每个目标的主导模态并为后续融合过程提供有效先验信息
- 设计了多光谱可变形交叉注意力模块,可同时自适应挖掘不同语义层级的细粒度局部互补信息,并适应模态不对准情况
- 在涵盖不同场景的四个公开数据集上的实验表明,该方法相较现有最优方法实现了显著提升
3.方法
3.1 概述 (Overview)
DAMSDet的整体架构如图2所示。
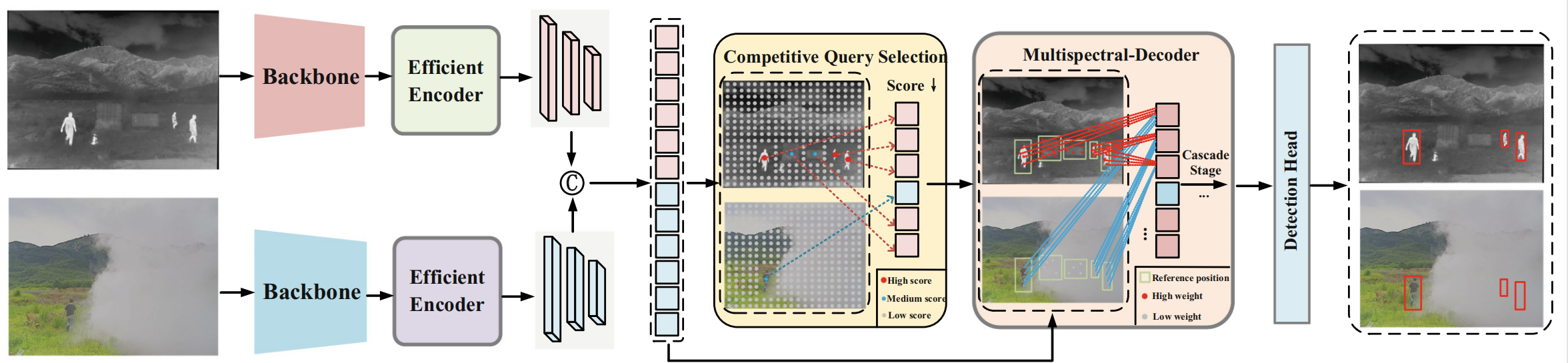
图 2. DAMSDet 整体架构
我们提出的 DAMSDet 包含四个主要组件:
两个模态专用的 CNN 骨干网络(用于特征提取);
两个模态专用的高效编码器(Efficient Encoder)19(用于特征编码);
模态竞争查询选择模块(Modality Competitive Query Selection module)(用于选择初始目标查询);
多光谱 Transformer 解码器(Multispectral Transformer Decoder)(用于挖掘互补信息并优化查询)。
方法包含四个主要组件:两个模态特定的CNN骨干网络、两个模态特定的高效编码器、模态竞争性查询选择模块以及一个多光谱Transformer解码器。给定一对红外和可见光图像,我们首先分别使用两个模态特定的CNN骨干网络和两个模态特定的高效编码器来提取和编码它们的特征。随后,将编码后的特征展平、拼接,并输入到模态竞争性查询选择模块。该模块选择显著的模态特征作为初始对象查询。接着,这些模态特定的对象查询进入多光谱Transformer解码器,该解码器通过级联的解码器层,利用红外和可见光的多层次语义特征图来细化这些查询。最后,这些细化后的对象查询通过检测头进行映射,获得所有对象的边界框和分类分数。
高效编码器结合了Transformer和CNN以显著降低计算复杂度,其结构遵循RT-DETR19。接下来,我们将详细阐述所提出的模态竞争性查询选择策略以及带有多光谱可变形交叉注意力模块 (Multispectral Deformable Cross-attention module) 的多光谱Transformer解码器。
3.2 模态竞争性查询选择 (Modality Competitive Query Selection)
DETR中的对象查询是一组可学习的嵌入,包含了对象的内容和位置信息。这些查询作为对象的特征表示,在解码器中与图像特征序列交互,并通过预测头映射生成边界框和分类分数。除了将对象查询设置为可学习嵌入外,也有一些方法使用Top-K得分特征作为初始对象查询34,35,42。可学习的对象查询难以优化,因为它们没有明确的物理意义19。在红外和可见光图像中,两种模态特征之间存在差异,这进一步复杂化了可学习对象查询的优化。因此,从编码后的特征图中选择对象查询更适合处理红外-可见光目标检测任务中互补特性的动态变化。
具体而言,我们将来自红外和可见光模态的编码后特征序列拼接起来,并馈入一个线性投影层以获得特征点分数。从这个组合的特征表示中,我们选择Top-K得分特征作为初始对象查询。这些Top-K特征分别来源于红外或可见光特征,每个特征代表其各自模态中的一个特定对象实例。此方法可以定义如下:
z = TopK ( Linear ( Concat ( I , V ) ) ) z = \text{TopK}(\text{Linear}(\text{Concat}(I, V))) z=TopK(Linear(Concat(I,V)))
其中 z z z 表示选中的K个特征集合, I I I 和 V V V 分别代表展平后的编码红外和可见光特征序列。我们对选中的查询特征进行额外的二元匹配(与真实标注),计算损失以确保得分较高的模态特定特征包含准确的对象信息。
如前所述,红外或可见光图像可能包含无用的干扰信息,这可能会混淆网络。我们通过竞争性选择模态特定特征来为每个对象构建显著的特征表示。这种方法有助于在早期阶段避免从另一模态引入干扰,并为后续解码器中的查询细化提供有用的先验信息,强调查询对对象的表示应优先考虑其来源模态。此外,我们使用IOU感知分类损失 (IOU-aware classification loss) 19,36 的优化策略来进一步提高所选特征的质量。
有效性分析 (Effectiveness Analysis) 。为观察我们的模态竞争性查询选择策略在网络中的性能,我们在配对图像上可视化所选模态特定初始查询的位置和分数。具体来说,我们将这些选中的特征映射以获得参考点的坐标,这些坐标随后被投影到红外或可见光图像上。如图3所示,可视化结果显示不同的对象实例由不同的主导模态特征显著地表示。此选择结果与我们的直觉一致,证明了该方法能根据变化的条件动态选择每个对象的主导检测模态。

冗余查询 (Redundant Queries) 。我们还观察到红外和可见光图像中存在指向同一对象的冗余查询。然而,得益于DETR的一对一匹配优化模式以及应用于解码器中所有模态特定查询的自注意力机制,网络有效地消除了这种冗余信息。为进一步解决这个潜在问题,我们在训练期间引入了噪声查询学习 (Noise Query Learning) 13,35策略,以促进学习每个对象的最佳模态匹配。
3.3 多光谱Transformer解码器 (Multispectral Transformer Decoder)
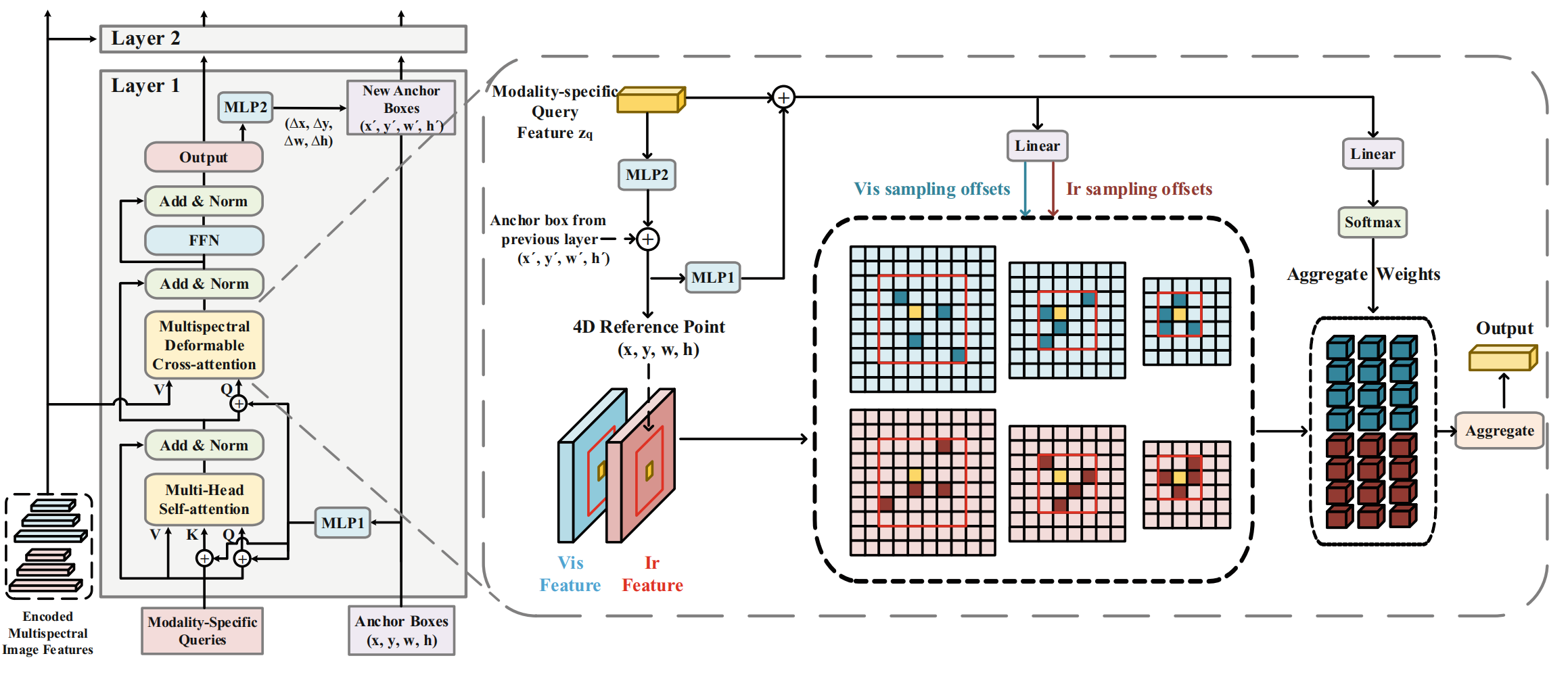
多光谱Transformer解码器的细节如图4所示。在每一层中,模态特定的对象查询首先经过多头自注意力以获得上下文信息并减少冗余。随后,我们的多光谱可变形交叉注意力模块 (Multispectral Deformable Cross-attention module) 利用多语义层级的红外和可见光特征来细化这些模态特定的查询。此外,我们采用4D锚框来约束多光谱可变形交叉注意力模块内的采样范围,并通过级联的解码器层迭代地细化查询和锚框。具体来说,在具有D层的多光谱解码器中,我们从第d层中的第q个模态特定查询 z q d z_{q}^{d} zqd 映射得到细化后的4D参考点 b q d b_{q}^{d} bqd。该过程可描述如下:
b q d = σ ( σ − 1 ( b q d − 1 ) + MLP ( z q d − 1 ) ) b_{q}^{d} = \sigma(\sigma^{-1}(b_{q}^{d-1}) + \text{MLP}(z_{q}^{d-1})) bqd=σ(σ−1(bqd−1)+MLP(zqd−1))
其中 d ∈ { 2 , 3 , ... , D } d\in\{2,3,\ldots, D\} d∈{2,3,...,D},MLP由两个线性投影层组成, σ \sigma σ 代表sigmoid函数, σ − 1 \sigma^{-1} σ−1 代表反sigmoid函数,且 b q 1 b_{q}^{1} bq1 是初始化的锚框。初始锚框设置与Deformable DETR42中的两阶段方法一致。这个细化后的4D参考点作为后续在多语义层级红外和可见光特征图上采样的参考位置约束。
多光谱可变形交叉注意力模块 (Multispectral Deformable Cross-attention Module)。在Deformable DETR42中,关键特征通过在特征图上的稀疏采样进行聚合,我们将其扩展到多模态形式以实现自适应的红外和可见光特征融合。多光谱可变形交叉注意力模块的详细架构如图4所示。具体来说,我们通过一个MLP层将4D参考点映射为位置嵌入。将模态特定查询特征与位置嵌入结合后,使用两个线性层分别预测两种模态上多语义特征图的采样偏移和聚合权重。最后,这些采样到的多语义红外和可见光特征通过聚合权重进行聚合。由于该方法能够独立预测红外和可见光模态的采样位置偏移,网络仍能够关注未对齐图像对中未对齐对象的特征。
给定输入的多语义红外和可见光特征图 { x 1 l , x 2 l } l = 1 L \left\{x_{1}^{l}, x_{2}^{l}\right\}{l=1}^{L} {x1l,x2l}l=1L,我们使用 b q b{q} bq 的归一化中心点作为2D参考点 p ^ q \hat{p}{q} p^q。我们将多光谱可变形交叉注意力模块 F 定义如下:
F ( z q , p q , { x m l } m = 1 , 2 l = 1 , . . . , L ) = ∑ m = 1 2 ∑ h = 1 H W h ∑ l = 1 L ∑ k = 1 K A m h l q k ⋅ W h ′ x m l ( p q + Δ p m h l q k ) F(z_q, p_q, \{x_m^l\}{m=1,2}^{l=1,...,L}) = \sum_{m=1}^{2} \sum_{h=1}^{H} W_h \left \\sum_{l=1}\^{L} \\sum_{k=1}\^{K} A_{mhlqk} \\cdot W'_h x_m\^l (p_q + \\Delta p_{mhlqk}) \\right F(zq,pq,{xml}m=1,2l=1,...,L)=m=1∑2h=1∑HWhl=1∑Lk=1∑KAmhlqk⋅Wh′xml(pq+Δpmhlqk)
其中 m ∈ { 1 , 2 } m\in\{1,2\} m∈{1,2} 表示可见光和红外模态, h h h 索引注意力头, l l l 索引输入特征语义层级, k k k 索引采样点。 A m h l q k A_{mhlqk} Amhlqk 和 Δ p m h l q k \Delta p_{mhlqk} Δpmhlqk 分别表示在 m m m 模态内、第 l l l 个特征语义层级、第 h h h 个注意力头中的第 k k k 个注意力权重和采样点。注意力权重 A m h l q k A_{mhlqk} Amhlqk 通过 ∑ m ∑ l = 1 L ∑ k = 1 K A m h l q k = 1 \sum_{m}\sum_{l=1}^{L}\sum_{k=1}^{K} A_{mhlqk}=1 ∑m∑l=1L∑k=1KAmhlqk=1 进行归一化。函数 P l ( p q ) P_l(p_q) Pl(pq) 将 p q p_q pq 缩放至第 l l l 个语义层级的特征图,函数 P l ( Δ p m h l q k ) P_l(\Delta p_{mhlqk}) Pl(Δpmhlqk) 将预测的偏移量约束在 b q b_q bq 的范围内,以便关注对象周围的信息并降低优化难度。

有效性分析 (Effectiveness analysis)。为观察此特征融合方法的有效性,我们在不同解码器层的不同语义层级上可视化两种模态中采样的位置和权重,如图5所示。结果显示,随着解码器层的加深,我们的方法倾向于自适应地关注红外模态中的低层级语义特征和可见光模态中的附加高层级语义特征。这个结果是合理的,因为红外模态携带的信息较少,但能提供可靠的低层级语义信息(如基本轮廓和形状),而包含更多信息的可见光模态能额外提供更抽象的高层级语义信息(如更可靠的对象类别上下文关系)。此外,我们观察到这些点能适应未对齐场景,并自适应地关注对象的关键信息,例如对定义对象边界很重要的边缘信息。不同解码器层中采样位置和权重分布的差异也验证了级联结构对于可靠互补信息挖掘的有效性。更多细节见第4.4节。
4 实验
4.1 数据集与评估指标 (Dataset and Metric)
我们在四个数据集上进行了实验,这些数据集涵盖了不同场景和不同尺度的目标。我们使用标准的COCO AP指标作为评估指标。这四个数据集是:M3FD 17, FLIR 4, LLVIP 7 和 VEDAI24。
M3FD。M3FD数据集包含4,200对红外-可见光图像,分辨率为1024x768。它涵盖了多样化的场景和六个目标类别,图像对存在轻微未对齐。由于该数据集未提供公开的划分,我们根据不同场景将数据集划分为包含3,368对的训练集和包含831对的验证集。这意味着训练集和验证集在场景上具有较低的相似性。
FLIR。我们使用对齐版本37,分辨率为640 x 512,包含4,129对图像用于训练,1,013对用于测试,并包含三个目标类别。该数据集包含白天和夜间场景,图像对存在明显的未对齐。
LLVIP。该数据集用于低光照监控场景下的行人检测。它包含12,025对图像用于训练,3,463对用于测试,分辨率为1280x1024,图像对配准良好。大多数场景处于黑暗条件,仅包含行人这一个类别。
VEDAI。该数据集是用于车辆检测的多光谱航空影像数据集,包含1,200对图像,分辨率为1024 x 1024,其图像对经过严格配准。它包含九个目标类别,且大多数目标很小,这对类DETR的检测器构成了巨大挑战。我们按照23的方法将其边界框转换为水平框。
4.2 实现细节 (Implementation Details)
我们采用ResNet506作为骨干网络,特征图语义层级为L=3。高效编码器(Efficient Encoder)包含一层,而多光谱解码器(MS-Decoder)包含六层。我们设置注意力头数、采样点数和选择的查询数分别为H=8,K=4和N=300。
我们使用在COCO数据集上预训练的权重。在M3FD、FLIR和LLVIP数据集上,学习率设置为0.0001;在VEDAI数据集上,学习率设置为0.00025。为与SOTA方法进行公平比较,我们在M3FD和FLIR数据集上将输入图像尺寸设置为 640 × 640 640\times 640 640×640 进行训练和测试,而在LLVIP和VEDAI数据集上则设置为1024 x 1024。我们在FLIR和LLVIP数据集上训练了20个周期(epoch),在M3FD和VEDAI数据集上训练了50个周期。网络使用Nvidia RTX3090 GPU进行训练。
4.3 与先进方法(SOTA)的比较 (Comparison with SOTA)
M3FD上的比较:我们划分的M3FD数据集非常具有挑战性,包含不同场景,所有SOTA方法的mAP值都较低,如表1所示。然而,我们的方法性能要好得多,并且明显优于这些SOTA方法。具体来说,我们的方法在mAP50上比CFT22高出12%,在mAP75上高出11.4%,在mAP上高出10.4%。它还在mAP50上比ICAFusion30高出12.4%,在mAP75上高出11.5%,在mAP上高出11%。这种显著的性能改进表明,我们的方法能更好地适应红外-可见光目标检测中复杂多变的场景。
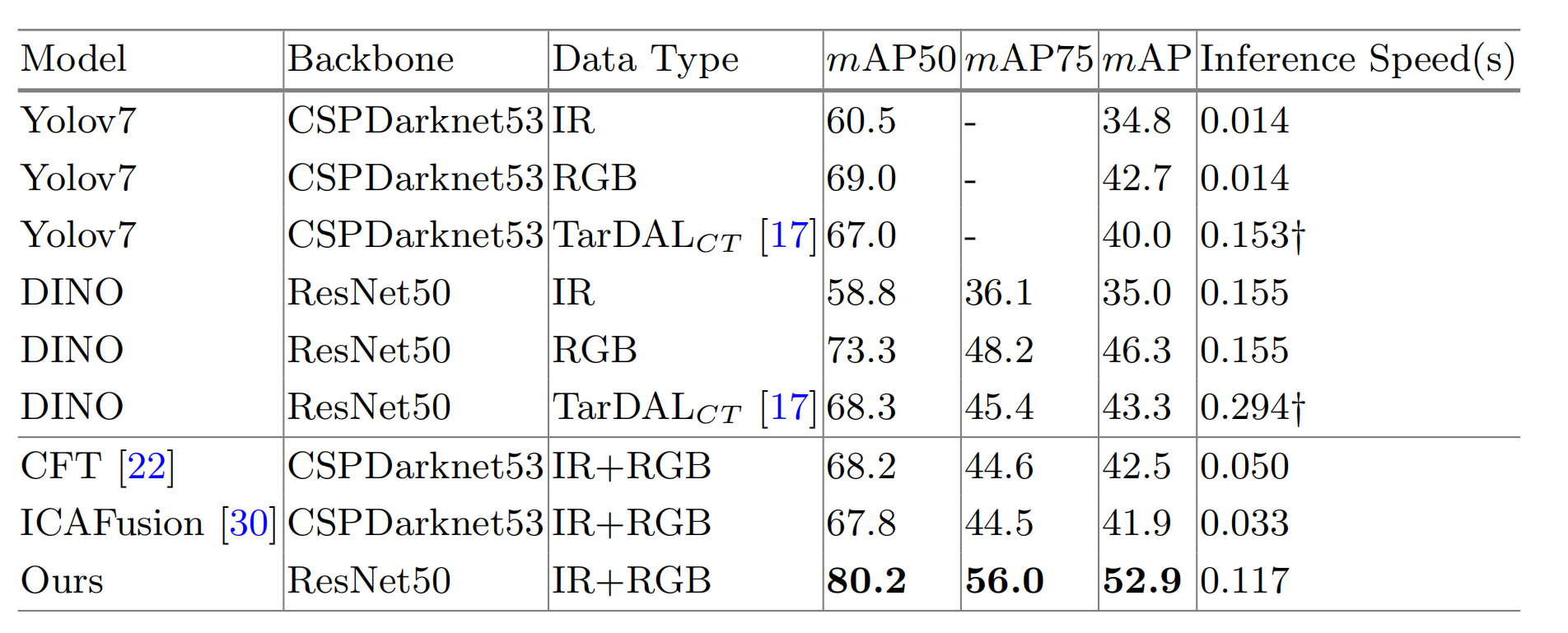
表 1. M3FD数据集上的比较。TarDALCT代表通过17获得的红外-可见光融合图像。包括图像融合和目标检测推理时间。
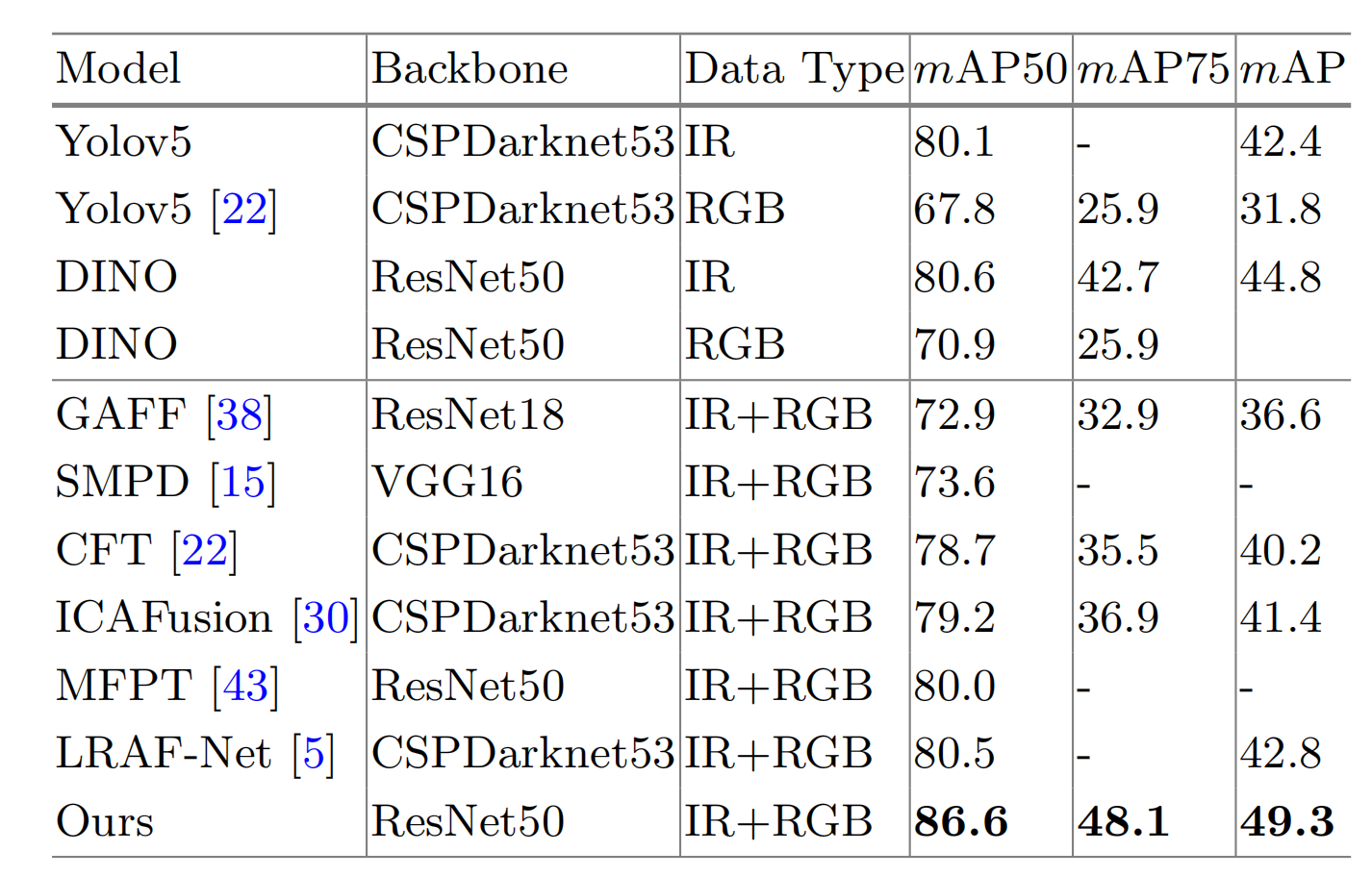
FLIR上的比较 :如表2所示,我们的方法优于单模态方法,并且在mAP50上超越了最佳特征融合方法6.1%,在整体mAP上超越了6.5%,证明我们的方法能在不同光照条件下有效挖掘互补信息。
表 2. FLIR-aligned数据集上的比较。
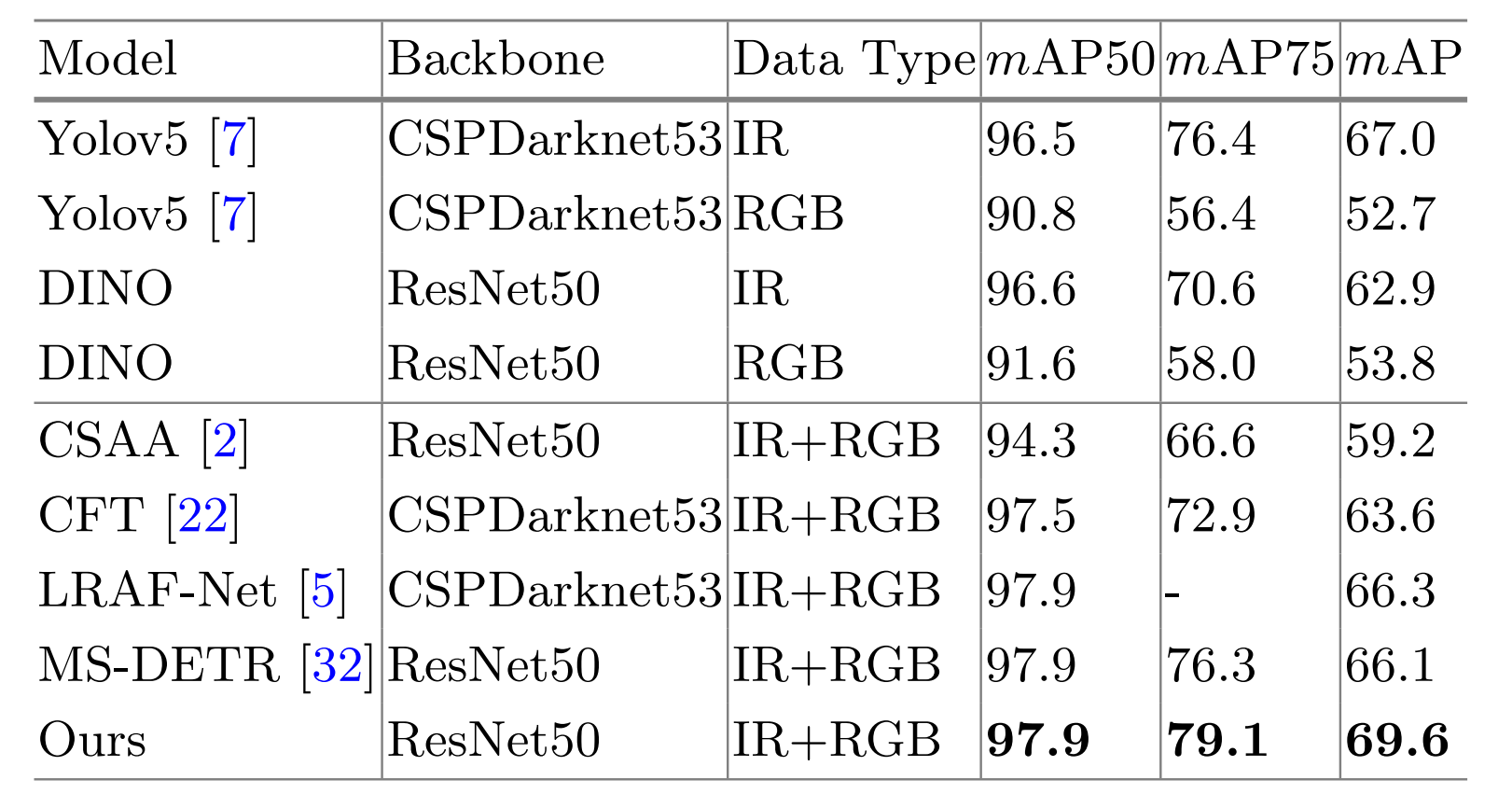
LLVIP上的比较 :如表3所示,该数据集在mAP50上性能已接近饱和,但我们的方法在mAP75上仍然比最佳方法(MS-DETR32)高出2.8%,在mAP上比最佳方法(LRAF-Net5)高出3.3%,表明我们的方法能够挖掘更全面、更细粒度的互补信息。
表 3. LLVIP数据集上的比较。
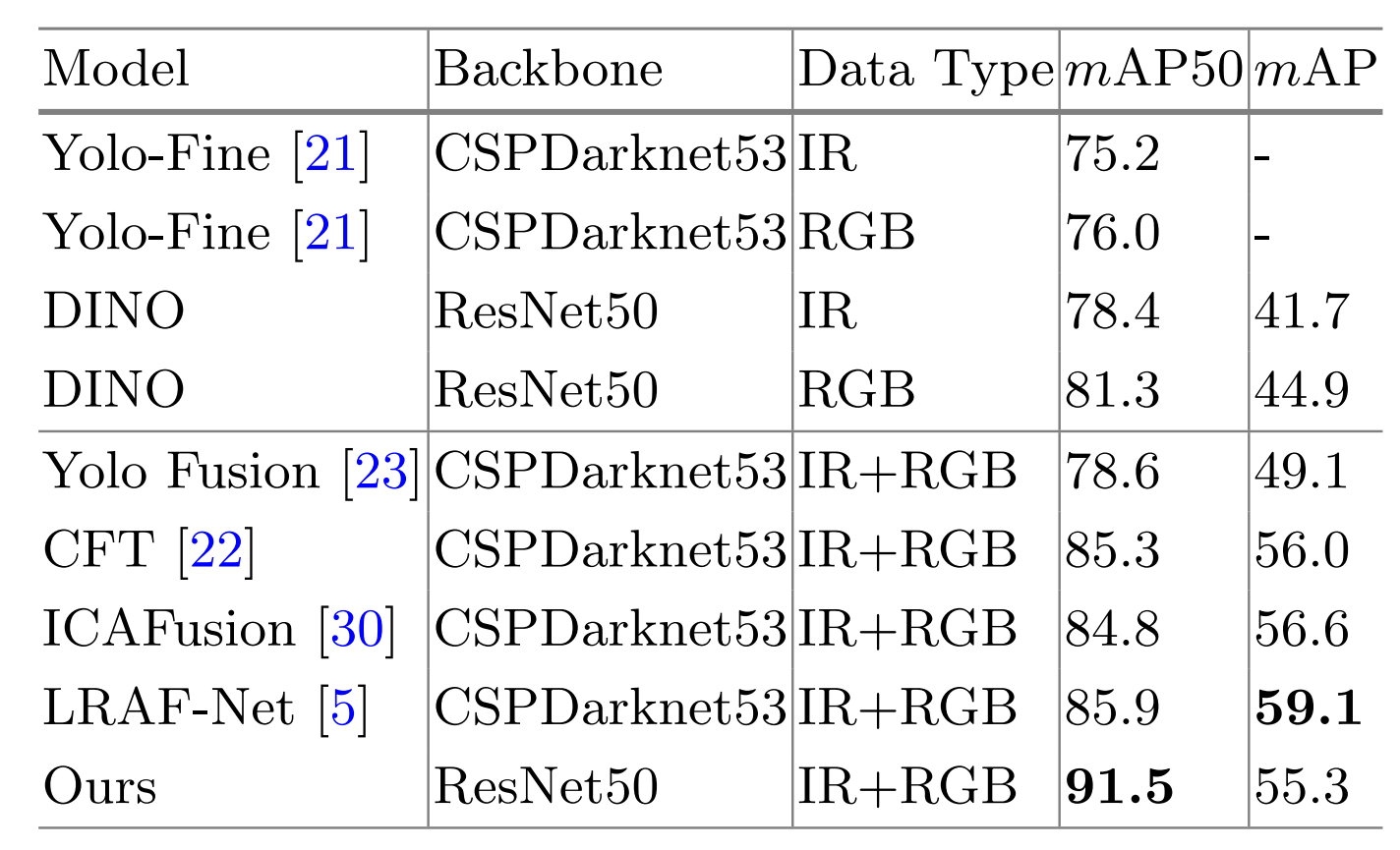
VEDAI上的比较 :如表4所示,我们的方法对于小目标仍然能良好工作,并且优于大多数SOTA方法。特别是在mAP50上,我们的方法比最佳方法(LRAF-Net5)高出5.6%。在mAP上,我们的方法并未超越LRAF-Net5(一个基于CNN的检测器)。原因可能在于,与长程信息提取相比,小目标检测更依赖于局部特征提取,而CNN在这方面可能比Transformer更具优势。另一方面,这些小目标的边界框较小,对位移敏感,即使几个像素的位移也会导致IOU的显著变化和随后的mAP下降。因此,边界框预测的高精度对于小目标检测至关重要。相对而言,CNN方法可以实现更高的边界框精度,从而获得更高的mAP。尽管如此,mAP50上的改进证明了我们的方法在小目标场景中的潜力。
表 4. VEDAI数据集上的比较。

检测可视化 (Detection Visualization)。为进行质量分析,我们在M3FD(a,b)、FLIR(c,d)和VEDAI(e,f)数据集上提供了一些代表性的检测结果。如图6所示,我们的方法能够在不同场景中精确定位目标并获得更高的检测置信度。这些结果表明,我们的DAMSDet可以自适应地关注主导模态,并有效挖掘细粒度的多层级语义互补信息。
4.4 M3FD上的消融实验 (Ablation Study on M3FD)
为验证我们方法中关键模块和策略的有效性,我们在M3FD数据集上进行了消融实验。
模态竞争性查询选择(MCQS)的效果。我们在相加后的编码特征上应用标准查询选择,以显示模态竞争性查询选择的有效性。
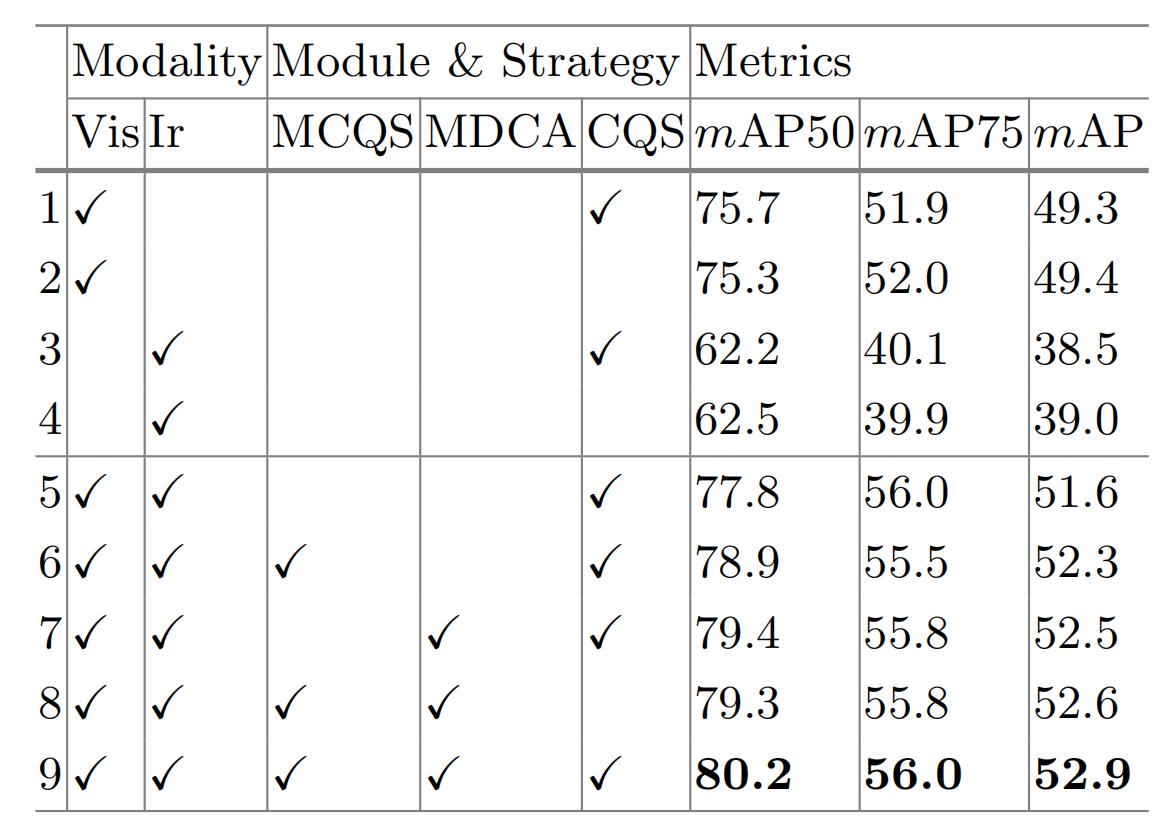
如表5的第5和第6行所示,我们的模态竞争性查询选择策略通过动态选择模态特定查询避免了早期引入干扰,从而带来了1.1%的mAP50提升和0.7%的mAP提升。
多光谱可变形交叉注意力模块(MDCA)的效果 。我们在解码器中对两个编码器输出相加得到的融合特征应用标准的可变形交叉注意力。如表5的第5和第7行所示,我们的方法带来了1.5%的mAP50提升和0.9%的mAP提升。这种改进可归因于我们的方法能够有效适应模态未对齐场景,同时以更细粒度的方式为每个对象执行自适应特征聚合。当然,当同时使用模态竞争性查询选择和多光谱可变形交叉注意力模块时,我们在所有AP指标上取得了最佳结果,如表5的第9行所示。
表 5. M3FD数据集上的消融研究。MCQS、MDCA和CQS分别代表模态竞争性查询选择、多光谱可变形交叉注意力和内容查询选择。
内容查询选择(CQS)的效果。我们分析了红外-可见光目标检测中不同内容查询策略的性能。为进行比较,我们将我们网络的单分支作为单模态检测方法。在表5的第8和第9行中,"without CQS"表示将内容查询设置为可学习查询,而位置查询仍然通过模态竞争性查询选择获得(类似于DINO35中的混合查询选择)。我们可以看到,使用CQS会带来更好的结果,因为它为后续多光谱解码器中的多光谱交叉注意力提供了更强的先验信息。然而,如表5的前4行所示,内容查询的选择或可学习性对单模态目标检测的影响有限,因为单模态的特征表示相对一致。
5 结论
本文提出DAMSDet,旨在同时解决红外-可见光目标检测中的互补信息融合和模态未对齐问题。通过模态竞争性查询选择(Modality Competitive Query Selection),DAMSDet能够根据互补特性动态选择特定对象的显著模态特征表示。在多光谱可变形交叉注意力模块(Multispectral Deformable Cross-attention module) 中,我们将特征融合与模态未对齐问题联系起来,在多语义层级上挖掘可靠的互补信息。在四个不同场景数据集上的实验表明,与其他最先进的方法相比,所提出的方法取得了显著的改进。