
2025
1.摘要
background
大规模视觉语言模型(VLMs)已扩展到理解图像和视频。视觉 token 压缩被用于减少视觉输入 token 的长度。现有高性能模型通常针对图像和视频采用不同的 token 压缩策略,导致不一致性,限制了它们结合图像和视频的能力。
innovation
为了解决上述问题,本论文将每张图像扩展为"静态"视频,并引入了一种统一的、名为"渐进式视觉 token 压缩"(PVC)的 token 压缩策略。PVC 渐进式编码每一帧的 token,并自适应压缩以补充前一帧未提取的信息。该策略高效压缩视频 token,同时保留图像空间细节。
- 方法 Method
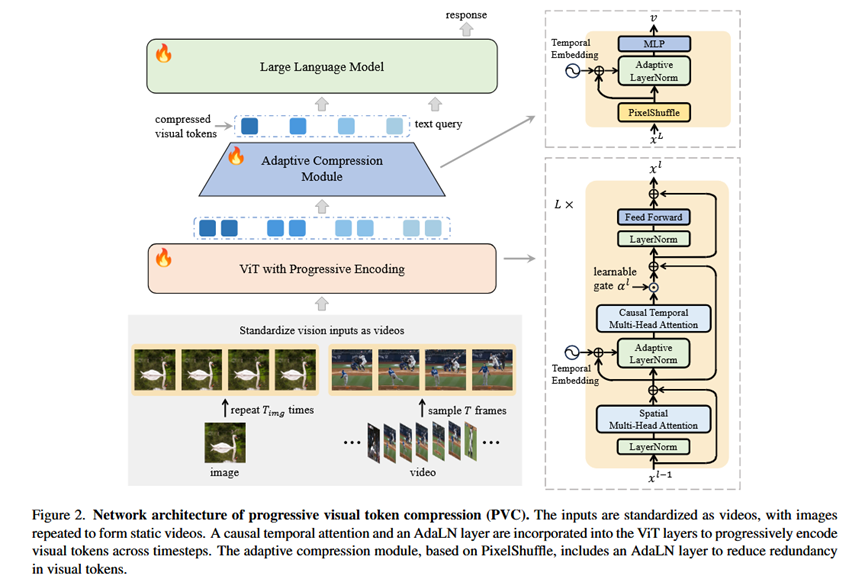
本论文提出的 PVC 架构包括一个带有渐进式编码的 Vision Transformer (ViT)、一个自适应 token 压缩模块和一个大型语言模型 (LLM)。
标准化 VLM 输入为视频:
输入: 图像 x 或原生视频。
处理: 将每张图像 x 重复 T_img 次(默认为 4 次),形成静态帧序列 x, x, ..., x。对于原生视频,统一采样 T 帧(训练期间 T 从 16, 96 中随机选择)。
输出: 统一的视频格式输入,使 LLM 能够多次回顾图像,捕捉更丰富的空间信息。
带有渐进式编码的 Vision Transformer (ViT):
目的: 避免视频帧冗余编码,使当前帧仅编码前一帧未提取的新信息。
组成: 在 ViT 层中引入了一个因果时间注意力模块(Temporal Multi-Head Attention, T-MHA)和一个注入时间步信息的自适应层归一化(Adaptive Layer Normalization, AdaLN)。
T-MHA: 应用于 ViT 最后 L 层的时间维度,使每个 patch token 关注同一空间位置的先前帧 token。它有助于捕捉时间相关性。
Temporal Embedding (TE): 将相对时间戳编码为 256 维正弦位置嵌入,并通过 MLP 生成时间嵌入,用于 AdaLN。
AdaLN: 用于调整归一化参数,使模型适应不同任务需求。在静态视频中,AdaLN 帮助在不同时间步提取不同的空间信息,避免冗余编码。
ViT 层定义: x := x + S-MHA(LayerNorm(x)) (空间多头注意力);x := x + α T-MHA(AdaLN(x; x + TE)) (时间多头注意力,其中 α 是可学习门);x := x + FFN(LayerNorm(x)) (前馈网络)。
自适应压缩模块:
目的: 减少视觉 token 的数量,同时避免不同帧之间的表示冗余。
组成: 基于 PixelShuffle 46 操作(将相邻 2x2 区域的 4 个 token 沿通道维度连接成单个 token,实现 16 倍压缩)和一个共享 MLP。
创新点: 在共享 MLP 之前集成了 AdaLN 层,允许网络在不同时间步提取不同的时空信息,避免冗余表示。
输入: ViT 输出的视频 token x,维度为 B, T, N, C'。
输出: 压缩后的 token v,每帧的 token 数量从 N 减少到 M (默认 M = N/16)。
- 实验 Experimental Results
实验数据集:
图像-语言基准: AI2D, ChartQA, DocVQA, InfoVQA, SQA, TextVQA, MMB, MME, MMMU, SEED-I, OCRBench。
视频-语言基准: MVBench, VideoMME, MLVU, LongVideoBench, NextQA, Egoschema, PercepTest, ActNet-QA。
实验结论:
与 SOTA 方法对比: PVC 在长视频任务(如 VideoMME, MLVU)和细粒度短视频任务(如 MVBench)上表现出色,同时在图像任务上保持竞争力。例如,PVCInternVL2-8B 在 MVBench 上达到 73.8,超过了现有开源模型 69.1 的最佳准确率。在 NextQA 和 ActNet-QA 上也取得了最佳结果。
消融研究(AdaLN 条件):
使用 AdaLN 能够显著提升性能,尤其是在保留空间细节的任务(如 InfoVQA)和捕捉时间关联的任务(如 VideoMME)上。
仅使用时间嵌入 (TE) 作为条件已显著提升性能,而结合 x (即前一层聚合的时间信息) 进一步提升性能,有助于更好地提取互补信息并最小化冗余。
消融研究(关键组件):
标准化视频输入: 直接将图像标准化为视频(设置 (b))会损害 OCR 相关图像任务的性能,因为重复的视觉 token 编码了重复信息,导致空间细节丢失。但对长视频任务有益。
渐进式编码: 引入时间注意力(设置 (c))缓解了信息损失,在需要空间细节的任务上保持了与基线模型相当的性能,并显著提升了长视频任务的性能。
自适应压缩: 添加自适应压缩模块(PVC)进一步提升了所有任务的性能,尤其在长视频任务上,证明了其更好地利用了视频帧内的表示冗余。
渐进式压缩的有效性:
在 MVBench 和 VideoMME 上,增加视频帧数会持续提升 PVC 模型的性能,表明它能更好地去除时间冗余和捕捉时间动态。
在图像任务上,增加图像重复次数对基线模型没有帮助,但对 PVC 模型(尤其是在 InfoVQA 等细节敏感任务上)显著提升了性能,因为重复的帧通过渐进式编码补充了详细信息。
图像重复和渐进式编码的速度: 对于 8B 模型,重复图像只会引入微小的开销(+6.0% FLOPs 相对,-6.3% FPS 相对),因为视觉特征计算可以部分重用,且主要计算负载在 LLM 中。
- 总结 Conclusion
PVC 提供了一种统一的图像和视频处理方法,通过将视觉输入标准化为视频,结合渐进式编码模块和自适应压缩模块,能够有效捕捉空间细节和时间动态。它在细粒度短视频和长视频任务中实现了最先进的性能,同时在细节敏感的图像基准测试中保持了准确性。