前言
刚开始接触机器学习,一股脑涌进来好多新的概念,想看视频课、看相关书籍进行学习,头昏脑涨地更厉害了,严重打击了学习的信心,所以我今天做了一个梳理,先理顺一下这些个概念之间的关系,然后再进行深入学习,我觉得这样在接下来的学习中效果会更好一些。
正文
在聊接下来的内容之前,我先讲一下模型和算法是什么。
模型 (model)就是机器学习算法从数据中学习到的"规律"或"函数",就像从1,3,5,7,...1,3,5,7,...1,3,5,7,...这些数字中总结出(2n+12n+12n+1,n∈Nn \in Nn∈N)这个规律,这就是一个非常简单的数列模型,之后,你只需要把任何一个正整数输入这个模型,它就能根据学习到的规律输出一个结果。当然,模型的形式不只有公式,它还可以是一条直线或曲线、一棵决策树、一片森林、一个复杂的神经网络、一个支持向量机等等。训练 (train)就是学习这个规律的过程,推理(infer)就是应用这个规律的过程。
算法 (Algorithm)是过程,是学习方法,好比一本菜谱,模型(model)是结果,是学习到的规律本身,好比你通过菜谱练习炒菜,最终掌握了这门手艺,这个"手艺"就是一个模型,你可以根据这个手艺来炒任何菜。在实践中,模型也可以指模型结构(如线性模型、神经网络架构),而算法指训练这个模型的优化方法(如梯度下降)。
机器学习
我们都知道人工智能,AI嘛,就是致力于让机器在感知、推理、学习、决策等方面表现出智能,那么怎么才能让机器变得智能呢,就像我们人类能从一堆数据中总结出规律一样,让机器思考的一种核心方法就是让机器自己从数据中学习规律,并进行预测或决策,即机器学习(Machine Learning,ML)。
那么方式呢,怎么才能让机器进行学习呢?我们刚开始接触数列的时候,老师通常都会先告诉我们什么是数列,数列的分类,然后再告诉你不同的数列应用不同的通项公式去求这个数列的公式,然后再出大量的题目给我们练习,在机器学习中类似于这种传统的教学方法就是传统机器学习方法,具体的一些算法如决策树、SVM、线性回归。
也不免有一些特别聪明的人,根本不用老师教怎么做,他通过练习大量的题目,并通过从这些题目中得到相应的反馈(比如答案正确与否),然后自己就能摸索出各种类型数列的通项公式,这就是深度学习 (Deep Learning)。深度学习的核心就是使用了一种叫做神经网络(Neural Network)的复杂模型来学习的,取名来源是受人脑神经元启发,但与人脑仍有巨大差别。这种神经网络的架构也分很多种,我见过最多的是卷积神经网络(Convolutional Neural Networks,CNN)、循环神经网络(Recurrent Neural Networks,RNN)和Transformer架构,这些概念又是什么意思,有什么区别,可以留到后面学习,这里只做简单梳理。

监督学习、无监督学习和强化学习
既然有了学习方式,我们还得有学习目标,于是监督学习 (Supervised Learning)、无监督学习 (Unsupervised Learning)和强化学习(Reinforcement Learning)就闪亮登场了。要区分这三种学习目标,首先要看是否基于与环境交互的奖励机制,如果是,那么就是强化学习,如果不是,就看数据集是否有标签,如果有标签(包括数据集中部分数据有标签),那就是监督学习,否则就是无监督学习,如下图(ps:示意图,仅帮助理解),啥意思呢,且听我慢慢道来。
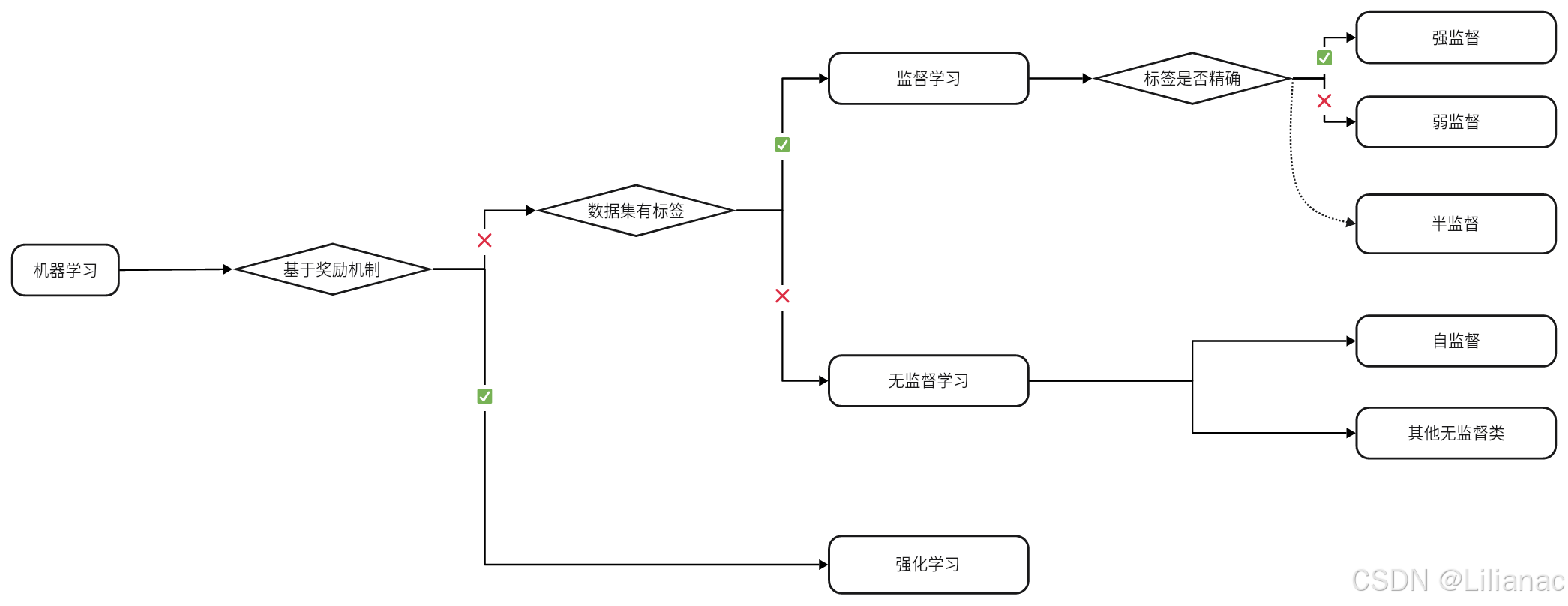
强化学习(Reinforcement Learning)
我们首先来了解一下什么是奖励机制,我们想象这样一个场景,你身处在一片望不到头的瓜田里面,瓜田的主人让你学习挑好瓜的本领,你每挑好一个瓜,瓜田主人都会给予你相应的奖励或惩罚(假设瓜田主人看一眼瓜就知道好坏)。比如你挑到一个好瓜,瓜田主人就奖励你一百块,如果你挑到一个坏瓜或者没熟的瓜,就罚你一百块,全程瓜田主人都不会给你任何提示,只是通过这种奖惩机制让你学习哪种瓜可能是好瓜。你通过这种与环境的交互从中学习好瓜具有的特征,从中总结出规律,从而练就挑瓜的本领。练成的这种本领叫什么?对了,就叫模型。这样一个过程就是强化学习的过程。奖励机制替代了标签,它是强化学习与监督/无监督学习最大的区别。
无监督学习(Unsupervised Learning)
假如我们手里有一堆动物的图片,那么对这些图片命的名就是标签(label)。因此如果这些图片没有任何一张有命名,把这些图片喂给机器让其学习,这就是无监督学习。用生活中的例子,把老师比作标签,你要做的习题集就是数据集,那么无监督学习,顾名思义就是没有老师监督你学习,也没有标准答案,你完全靠自己发现这些习题集之间的联系或规律。
进行无监督学习的方法中最著名的就是自监督学习,自己监督自己去学习,你会自己给自己出题,比如故意把一道题的题目遮住一部分,然后猜被遮住的内容是什么,通过这种方式,从数据本身创造标注,然后进行学习的过程。自监督学习不依赖人工标注,因此在数据层面可视作广义无监督;但它通过从数据中自动生成伪标签,把任务转化为监督训练,因此也常被认为是介于无监督与监督之间的特殊形式。
监督学习(Supervised Learning)
监督学习与无监督学习的区别从名字上看就很明显,既然无监督学习没有老师监督你学习,那么监督学习就是有老师监督你学习了。还是无监督学习里面举的那堆动物图片,如果那堆图片有被命名的,把这些图片喂给机器让其学习,就是监督学习。既然有图片被命名,那么根据图片命名的多少和精度,我们又可以分为强监督学习 (Fully Supervised Learning)、弱监督学习 (Weakly Supervised Learning)和半监督学习(Semi-Supervised Learning)。
强监督学习就是所有图片都被精确的命名,包括每张图片是什么动物、动物在图片什么位置、在做什么动作等等精准的信息;弱监督学习也是所有图片都被命名,但不是精准的,图片的命名可能只包括动物类型,且命名可能有错误(即常说的噪声noisy/noise);半监督学习的思想是结合了监督学习和无监督学习,这个方法的数据集是只有部分数据被精准标注,其余数据都没有被标注。
再举一个生活中的例子来加深对这三种监督学习的理解:
强监督就是老师对习题集中的每道题都非常详细的讲解,不仅有标准答案,还有解题过程。
弱监督就是老师只给你最终答案,不给你解题过程,甚至答案有可能是错误的(即有噪声),你需要从这些不完美的信息中学习。
半监督就是老师很忙,只能给你详细解答习题集中的部分题目,其余题目都是没有答案的,你需要从老师讲解的题中找到解题方法,然后去做那些没有答案的题目。你通过研究那些没有答案的题目加深了对知识点的理解,从而能更好的解答没有出现在习题集中的题目。这种即利用了老师的指导(监督),又进行了自我探索(无监督)的方法就是半监督学习,所以我才会说半监督的思想是结合了监督学习和无监督学习。
这里说的其实是狭义上对弱监督学习的定义,在最开始的研究中,"弱监督"通常指的是标签本身的质量问题,半监督学习只有部分标签被精准标注,所以和弱监督学习不同,因此半监督学习和弱监督学习是同级关系。但是广义上对弱监督学习的定义是指任何比强监督学习更弱、更廉价、更容易获取的标注信息的学习范式都是弱监督,此时,半监督学习是被纳入弱监督学习的范畴的。
所以从广义上对弱监督学习的定义,它被分为三大分支:不完整、不精确、不准确监督。这三种分类同样是针对数据集的,分别表示数据集只有一小部分有标签、数据集的标签不够精细、数据集的标签存在噪声,也都是能从字面上理解这三种分类的。
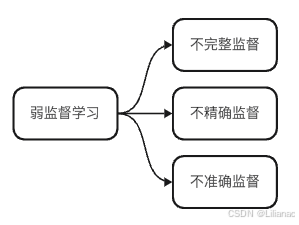
因此,在广义上对弱监督的定义中,半监督学习就属于不完整的监督这一类。
总结
有些同学可能会有点混淆了传统机器学习\深度学习和监督学习\无监督学习\强化学习,前者是学习"工具",后者是学习"目标",任何一种"学习目标"都可以用不同的"工具来实现。比如我们学习的最终目标是考研上岸,不同的同学用不同的方法,有些同学喜欢自己学,有些同学觉得自己学习能力不足,需要用到一些高级的工具,如网课、线下报班之类的。用一个图来帮助我们理解:
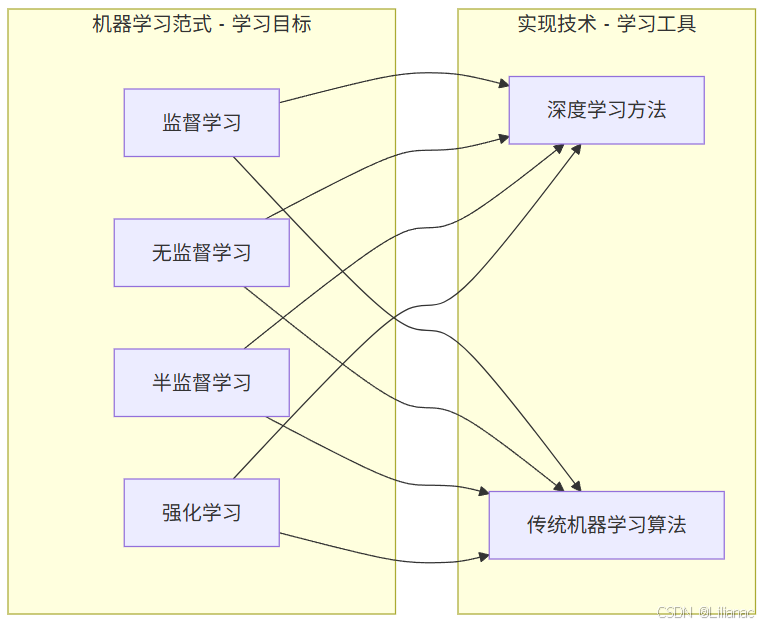
所以我们要让机器学习,首先要看任务是否涉及与环境的交互和奖励机制,如果是,就属于强化学习;如果不是,再根据数据是否带标签选择监督或无监督。确定好了目标之后,我们再选择用什么工具来实现,可以使用传统的机器学习算法,也可以搭建复杂的深度学习模型,甚至二者结合。
关于这些概念大概就梳理到这里了,下一期我再继续详细讲弱监督学习。