1 Kafka 性能压测
-
Kafka 提供了一个性能压测脚本,可用于衡量集群整体性能;
sh[root@192-168-65-112 kafka_2.13-3.8.0]# bin/kafka-producer-perf-test.sh --topic test --num-record 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=worker1:9092 acks=1 212281 records sent, 42456.2 records/sec (41.46 MB/sec), 559.9 ms avg latency, 1145.0 ms max latency. 463345 records sent, 92669.0 records/sec (90.50 MB/sec), 229.6 ms avg latency, 946.0 ms max latency. 1000000 records sent, 80560.702489 records/sec (78.67 MB/sec), 237.82 ms avg latency, 1145.00 ms max latency, 145 ms 50th, 699 ms 95th, 959 ms 99th, 1123 ms 99.9th.- 对名为
test的主题进行生产者性能测试,发送 100 万条记录,每条记录大小 1024 字节,throughput -1表示尽可能高的吞吐量,指定了 Kafka 集群的引导服务器等配置; - 压测结果:展示了不同阶段发送记录的数量、每秒记录数(吞吐量)、平均延迟、最大延迟等指标,还给出了不同分位数(如 50th、95th、99th 等)的延迟情况,这些指标能反映 Kafka 生产者的性能表现。
- 对名为
-
通常将这种性能压测作为 Kafka 的基准测试,以此衡量 Kafka 服务端配置是否充足。
2 搭建 Kafka 监控平台 EFAK
-
EFAK 简介:EFAK(原 Kafka-eagle)是用于监控 Kafka 集群整体运行情况的框架,在生产环境常用,官网地址为:https://www.kafka-eagle.org/;

-
环境准备:
- 从官网 Download 页面下载 EFAK 运行包(如
efak-web-3.0.2-bin.tar.gz); - EFAK 依赖环境主要是 Java 和数据库,数据库支持本地化的 SQLite 以及集中式的 MySQL(生产环境建议用 MySQL),且需准备好对应的服务器和 MySQL 数据库,数据库无需初始化,EFAK 执行过程中会自动完成初始化;
- 从官网 Download 页面下载 EFAK 运行包(如
-
安装过程(以 Linux 服务器为例):
-
解压压缩包:将 EFAK 压缩包解压到指定目录
shtar -zxvf efak-web-3.0.2-bin.tar.gz -C /app/kafka/eagle -
修改配置文件 :修改
efak解压目录下的conf/system-config.properties文件,该文件提供了完整配置,下面只列出需要修改的部分properties###################################### # multi zookeeper & kafka cluster list # Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead ###################################### # 指向Zookeeper地址 efak.zk.cluster.alias=cluster1 cluster1.zk.list=worker1:2181,worker2:2181,worker3:2181 ###################################### # zookeeper enable acl ###################################### # Zookeeper权限控制 cluster1.zk.acl.enable=false cluster1.zk.acl.schema=digest #cluster1.zk.acl.username=test #cluster1.zk.acl.password=test123 ###################################### # kafka offset storage ###################################### # offset选择存在kafka中。 cluster1.efak.offset.storage=kafka #cluster2.efak.offset.storage=zk ###################################### # kafka mysql jdbc driver address ###################################### #指向自己的MySQL服务。库需要提前创建 efak.driver=com.mysql.cj.jdbc.Driver efak.url=jdbc:mysql://192.168.65.212:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull efak.username=root efak.password=root -
配置环境变量:
shvi ~/.bash_profile # 配置KE_HOME环境变量,并添加到PATH中。 export KE_HOME=/app/kafka/eagle/efak-web-3.0.2 PATH=$PATH:#KE_HOME/bin:$HOME/.local/bin:$HOME/bin # 让环境变量生效 source ~/.bash_profile -
启动 EFAK :先启动 ZooKeeper 和 Kafka 服务,再调用 EFAK 的
bin目录下的ke.sh脚本启动服务。启动成功后会显示相关提示信息,包含可访问的页面地址(如http://192.168.232.128:8048)、默认账号(admin)和密码(123456)等;sh[oper@worker1 bin]$ ./ke.sh start # 日志很长,看到以下内容表示服务启动成功 [2023-06-28 16:09:43] INFO: [Job done!] Welcome to ______ ______ ___ __ __ / ____/ / ____/ / | / //_/ / __/ / /_ / /| | / ,< / /___ / __/ / ___ | / /| | /_____/ /_/ /_/ |_|/_/ |_| ( Eagle For Apache Kafka® ) Version v3.0.2 -- Copyright 2016-2022 ******************************************************************* * EFAK Service has started success. * Welcome, Now you can visit 'http://192.168.232.128:8048' * Account:admin ,Password:123456 ******************************************************************* * <Usage> ke.sh [start|status|stop|restart|stats] </Usage> * <Usage> https://www.kafka-eagle.org/ </Usage> *******************************************************************
-
-
访问管理页面 :可通过指定地址(如
http://192.168.232.128:8048)访问 EFAK 管理页面,默认用户名admin,密码123456,页面可展示 Brokers、Topics、ZooKeepers、Consumers 等 Kafka 相关信息以及 Kafka 集群的资源使用情况等;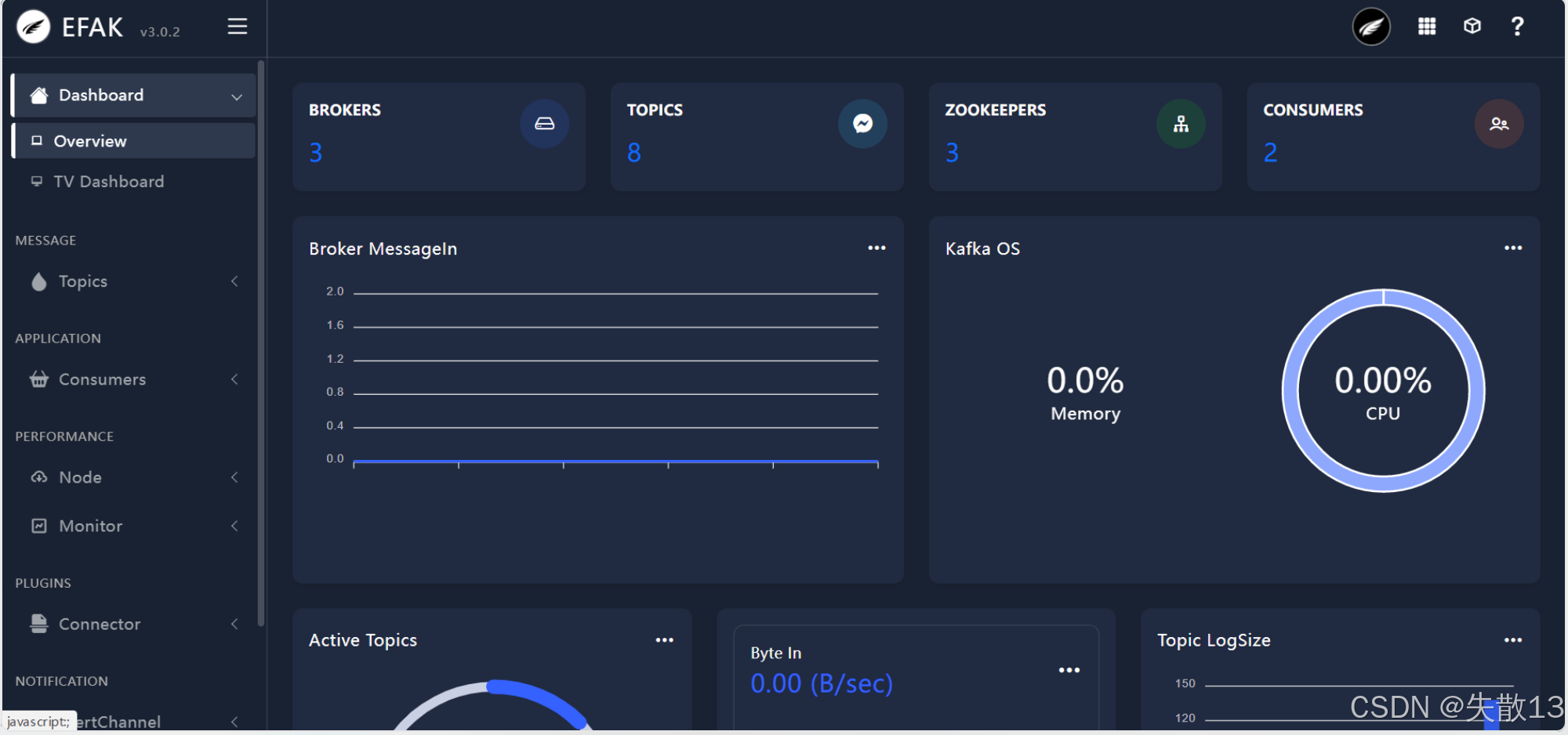
-
关于 EFAK 更多使用方式(如集群部署等),可参考官方文档。
3 Kraft 集群
3.1 简介
-
Kraft 是 Kafka 从 2.8.0 版本开始支持的新集群架构方式,目的是摆脱 Kafka 对 ZooKeeper 的依赖。以往基于 ZooKeeper 搭建的集群,增加了 Kafka 演进与运维难度,成为 Kafka 拥抱云原生的障碍。使用 Kraft 集群后,Kafka 集群不再依赖 ZooKeeper,将之前由 ZooKeeper 管理的集群数据转为由自身管理;
官方规划未来用 Kraft 模式替代现有 ZooKeeper 模式,但目前 Kraft 集群稳定性不如 ZooKeeper 集群,大部分企业仍在使用 ZooKeeper 集群。2022 年 10 月 3 日发布的 3.3.1 版本才将 Kraft 标注为准备用于生产(KIP - 833: Mark KRaft as Production Ready),离大规模使用还有较长距离;
Kafka 脱离 ZooKeeper 是长期过程,之前版本迭代中已逐步减少 ZooKeeper 中的数据。Kafka 的 bin 目录下大量脚本,早期需指定 ZooKeeper 地址,后续版本逐步改为通过
--bootstrap-server参数指定 Kafka 服务地址,目前版本基本所有脚本都已抛弃--zookeeper参数; -
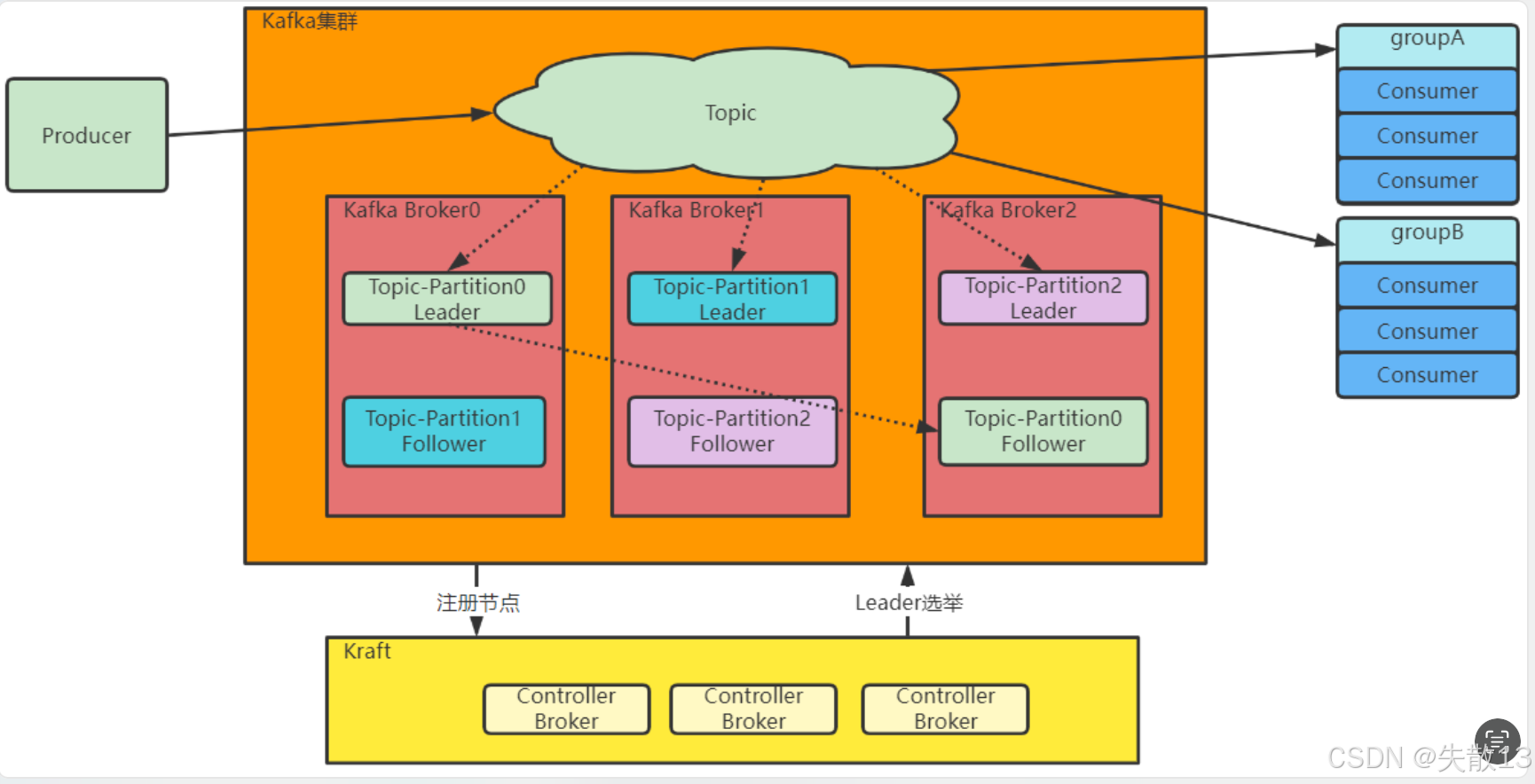
与传统集群的区别:
- 传统 Kafka 集群将每个节点状态信息统一存在 ZooKeeper 中,通过 ZooKeeper 动态选举产生 Controller 节点,由 Controller 节点管理 Kafka 集群(如触发 Partition 选举);
- 而 Kraft 集群中,会固定配置几台 Broker 节点共同担任 Controller 角色,各 Partition 的 Leader 节点由这些 Controller 选举产生,原本存在 ZooKeeper 中的元数据也转而保存到 Controller 节点中;
Raft 协议是去中心化集群管理的常见算法,类似 Paxos 协议,是基于多数同意产生集群共识的分布式算法,Kraft 是 Kafka 基于 Raft 协议进行的定制算法;
-
Kraft 集群的优势:
- Kafka 可不依赖外部框架独立运行,减少 ZooKeeper 性能抖动对 Kafka 集群性能的影响,且 Kafka 产品版本迭代更自由;
- Controller 不再由 ZooKeeper 动态选举产生,而是通过配置文件固定,适合配合高可用工具保持集群稳定性;
- 摆脱 ZooKeeper 后,集群扩展时元数据的读写能力得到增强,因为 ZooKeeper 产品特性不适合存储大量数据,这对 Kafka 集群规模(尤其是 Partition 规模)有极大限制;
-
存在的问题:由于分布式算法的复杂性,Kraft 集群和同样基于 Raft 协议定制的 RocketMQ 的 Dledger 集群一样,还不太稳定,在真实企业开发中使用相对较少。
3.2 配置 Kraft 集群
-
在 Kafka 的
config目录下有kraft文件夹,其中包含三个参考配置文件,分别对应 Kraft 中三种不同角色的示例配置:broker.properties(数据节点配置)controller.properties(Controller 控制节点配置)- server.properties`(既可以是数据节点,也可以是 Controller 控制节点配置)
-
下面列出几个比较关键的配置项,按照自己的环境进行定制即可:
properties# 配置当前节点的角色。Controller相当于Zookeeper的功能,负责集群管理。Broker提供具体的消息转发服务 process.roles=broker,controller # 配置当前节点的id。与普通集群一样,要求集群内每个节点的ID不能重复 node.id=1 # 配置集群的投票节点。@前面的是节点的id,后面是节点的地址和端口(该端口与客户端访问端口不同),通常将集群内的所有Controllor节点都配置进去 controller.quorum.voters=1@worker1:9093,2@worker2:9093,3@worker3:9093 # Broker对客户端暴露的服务地址。基于PLAINTEXT协议 advertised.listeners=PLAINTEXT://worker1:9092 # Controller服务协议的别名。默认就是CONTROLLER controller.listener.names=CONTROLLER # 配置监听服务。不同服务可以绑定不同接口,这种配置方式在端口前省略了主机IP,主机IP默认使用java.net.InetAddress.getCanonicalHostName() listeners=PLAINTEXT://:9092,CONTROLLER://:9093 # 数据文件地址。默认配置在/tmp目录下 log.dirs=/app/kafka/kraft-log # Topic默认的partition分区数 num.partitions=2- 对于
controller.quorum.voters:@符号前面表示节点 ID,需与node.id对应,后面表示节点的协议地址;- 若一个节点只是
broker(不参与投票),其node.id不能包含在controller.quorum.voters包含的节点 ID 中;
- 对于
-
需将配置文件分发,并修改每个服务器上的
node.id属性和advertised.listeners属性; -
因为 Kafka 的 Kraft 集群对数据格式有额外要求,所以在启动 Kraft 集群前,要对日志目录进行格式化;
sh[root@192-168-65-112 kafka_2.13-3.8.0]$ bin/kafka-storage.sh random-uuid # 生成随机 UUID j8XGPOrcR_yX4F7ospFkTA # 格式化,其中 -t 表示集群 ID,三个服务器可使用同一个集群 ID [root@192-168-65-112 kafka_2.13-3.8.0]$ bin/kafka-storage.sh format -t j8XGPOrcR_yX4F7ospFkTA -c config/kraft/server.properties Formatting /app/kafka/kraft-log with metadata.version 3.4-IV0. -
完成上述步骤后,可指定配置文件启动 Kafka 服务,例如在 Worker1 上启动 Broker 和 Controller 服务:
sh[root@192-168-65-112 kafka_2.13-3.8.0]$ bin/kafka-server-start.sh -daemon config/kraft/server.properties [root@192-168-65-112 kafka_2.13-3.8.0]$ jps 10993 Jps 10973 Kafka -
后续操作:等三个服务都启动完成后,就可以像普通集群一样去创建 Topic,并维护 Topic 的信息了。
4 Kafka 与流式计算
4.1 批量计算与流式计算
- Kafka 的一个重要用途是作为流式计算的数据源;
- 批量计算与流式计算的对比 :
- 批量计算:通常针对静态数据,即每次拿一批完整的数据进行计算。例如通过 SQL 语句从数据库中查询一批完整数据计算,或者使用 Kafka 消费者时每次从 Kafka 拉取一批数据计算后再取下一批,属于典型的批量计算。批量计算关注系统中的全量数据(多为静态),一般用于大型离线计算;
- 流式计算:通常关注系统中当前传输的实时动态产生的数据,用于对实时性要求更高的计算,比如统计网站实时 PV、UV 值(根据每次用户请求动态累加计算),实时性比批量计算处理用户访问记录更好。流式计算是处理海量数据的重要分支,业界有 Spark Streaming、Flink 等大型流式计算框架支持,像针对 MQ 产品的消费端程序,理想场景是来一条处理一条的流式计算,但常见 MQ 产品为保证数据传输性能,多以小批量形式传输,降低了数据实时性,而 Kafka 推出了 Stream 流式计算 API;
- 流式计算 API 的发展:RocketMQ、RabbitMQ 等其他 MQ 产品也陆续推出流式计算 API,但由于 Kafka 数据吞吐量和处理性能强大,天生适合作为流式计算的重要数据源,且围绕 Kafka 的大数据流式计算技术生态最为完整。
4.2 一个简单的流式计算示例
-
下面实现一个基于 Kafka Streams 实现的简单流式计算示例------单词计数(word count);
word count 是流式计算中最基础的案例,类似 Java 的"Hello world",用于实时统计 Kafka 中每个单词传递的次数。
-
依赖引入:
xml<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-streams</artifactId> <version>3.8.0</version> </dependency> -
代码实现:
javapublic class WordCountStream { // 输入主题 INPUT_TOPIC 和输出主题 OUTPUT_TOPIC private static final String INPUT_TOPIC = "inputTopic"; private static final String OUTPUT_TOPIC = "outputTopic"; public static void main(String[] args) { Properties props = new Properties(); // 应用程序 ID props.putIfAbsent(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount"); // Kafka 引导服务器地址 props.putIfAbsent(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.112:9092"); // 状态存储缓存最大字节数 props.putIfAbsent(StreamsConfig.STATESTORE_CACHE_MAX_BYTES_CONFIG, 0); // 默认键和值的序列化类 props.putIfAbsent(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.StringSerde.class); props.putIfAbsent(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.StringSerde.class); // 消费者偏移量重置策略 props.putIfAbsent(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); // 创建 KafkaStreams 实例:通过 buildTopology() 方法构建拓扑结构,结合配置属性创建 KafkaStreams 实例 KafkaStreams streams = new KafkaStreams(buildTopology(), props); final CountDownLatch latch = new CountDownLatch(1); // 优雅关闭。确保 KafkaStreams 调用 close() 方法清除本地缓存 Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") { @Override public void run() { streams.close(); latch.countDown(); } }); try { // 启动流式处理 streams.start(); // 等待,若出现异常则退出程序 latch.await(); } catch (final Throwable e) { System.exit(1); } System.exit(0); } private static Topology buildTopology() { // 构建拓扑 StreamsBuilder streamsBuilder = new StreamsBuilder(); // 从 INPUT_TOPIC 获取 KStream 类型的数据源 source KStream<Object, String> source = streamsBuilder.stream(WordCountStream.INPUT_TOPIC); // 处理数据 // flatMapValues:对每个值(将字符串转为小写后,按非单词字符分割成单词列表)进行处理,返回多个值 source.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+"))) // groupBy:将每个单词作为键进行分组 .groupBy((key, value) -> value) // count:对每个分组进行计数,得到一个 KTable(中间结果集) .count() // toStream:将 KTable 转换为 KStream 数据流 .toStream() // to:将处理结果输出到 OUTPUT_TOPIC,并指定键和值的序列化类 .to(OUTPUT_TOPIC, Produced.with(Serdes.String(),Serdes.String())); // 返回构建好的拓扑 return streamsBuilder.build(); } } -
通过这个案例,能够统计出
INPUT_TOPIC下每个单词出现的次数,并将结果输出到OUTPUT_TOPIC下,实现了一条一条处理消息的流式计算。
4.3 流式计算的基本构成方式
-
Kafka Streams 核心构成:
-
通过构建包含数据处理链路的
Topology(拓扑)来处理数据,只要Source端有数据,就会经Topology逐条处理,如同水管接水龙头,水龙头有水就可立即处理;Topology 指的是包含了数据处理链路的结构,描述了数据从输入源(Source)经过一系列处理步骤,最终到达输出目标(Sink)的整个流程。它定义了数据如何流动以及在每个阶段如何被处理 ,类似于一张数据处理的 "流程图" 或者 "路线图";
-
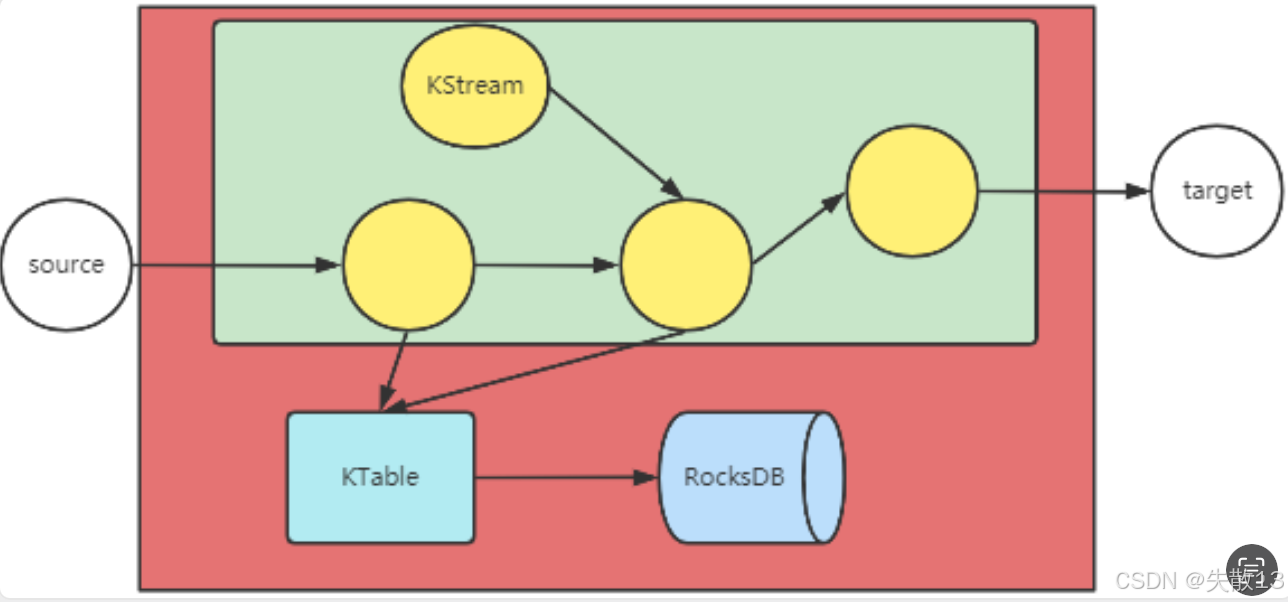
核心概念有
KStream(代表数据流)和KTable(代表中间结果集),KTable的数据会存储在RocksDB中;
-
-
若觉得
KStream和KTable太抽象,Kafka Streams 还提供了LowLevel API,能更自由地构建复杂的Topology。代码示例:javapublic class WordCountProcessorDemo { private static final String INPUT_TOPIC = "inputTopic"; // 定义输入主题名称 private static final String OUTPUT_TOPIC = "outputTopic"; // 定义输出主题名称 public static void main(String[] args) { // 配置Kafka Streams应用属性 Properties props = new Properties(); props.putIfAbsent(StreamsConfig.APPLICATION_ID_CONFIG, "word"); // 应用唯一标识 props.putIfAbsent(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.65.112:9092, 192.168.65.170:9092, 192.168.65.193:9092"); // Kafka集群地址 props.putIfAbsent(StreamsConfig.STATESTORE_CACHE_MAX_BYTES_CONFIG, 0); // 禁用状态缓存 props.putIfAbsent(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.StringSerde.class); // 默认键序列化器 props.putIfAbsent(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.StringSerde.class); // 默认值序列化器 props.putIfAbsent(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest"); // 从最新偏移量开始消费 // 创建Kafka Streams实例 KafkaStreams streams = new KafkaStreams(buildTopology(), props); final CountDownLatch latch = new CountDownLatch(1); // 用于等待应用关闭的同步工具 // 添加关闭钩子,确保应用优雅关闭 Runtime.getRuntime().addShutdownHook(new Thread("streams-wordcount-shutdown-hook") { @Override public void run() { streams.close(); // 关闭Kafka Streams latch.countDown(); // 释放等待锁 } }); // 启动流处理应用 try { streams.start(); // 启动Kafka Streams latch.await(); // 等待直到应用被关闭 } catch (final Throwable e) { System.exit(1); // 发生异常时非正常退出 } System.exit(0); // 正常退出 } // 构建处理拓扑结构 private static Topology buildTopology(){ // 创建新的拓扑实例 Topology topology = new Topology(); // 添加数据源处理器,从输入主题读取数据 topology.addSource("source", WordCountProcessorDemo.INPUT_TOPIC); // 添加自定义的字数统计处理器,连接到数据源 topology.addProcessor("process", new MyWCProcessor(), "source"); // 添加数据输出处理器,将结果写入输出主题 topology.addSink("sink", OUTPUT_TOPIC, new StringSerializer(), new LongSerializer(), "process"); return topology; } // 自定义处理器供应商类,负责创建字数统计处理器实例 static class MyWCProcessor implements ProcessorSupplier<String,String,String,Long> { @Override public Processor<String, String, String, Long> get() { return new Processor<String, String, String, Long>() { private KeyValueStore<String,Long> kvstore; // 用于存储单词计数的键值存储 @Override public void init(ProcessorContext<String, Long> context) { // 设置定时标点器,每秒触发一次,发送当前所有单词计数 context.schedule(Duration.ofSeconds(1), PunctuationType.STREAM_TIME, timestamp -> { try(KeyValueIterator<String, Long> iter = kvstore.all()){ // 获取存储中所有键值对 System.out.println("=======" + timestamp + "======"); // 打印时间戳分隔符 while (iter.hasNext()){ KeyValue<String, Long> entry = iter.next(); // 获取下一个键值对 System.out.println("[" + entry.key + "," + entry.value + "]"); // 打印单词和计数 // 将单词计数记录转发到下游处理器 context.forward(new Record<>(entry.key, entry.value, timestamp)); } } }); // 从上下文中获取名为"counts"的状态存储 this.kvstore = context.getStateStore("counts"); } @Override public void process(Record<String, String> record) { System.out.println(">>>>>" + record.value()); // 打印接收到的原始消息 // 将消息内容转换为小写并按非单词字符分割成单词数组 String[] words = record.value().toLowerCase().split("\\W+"); // 遍历每个单词并更新计数 for (String word : words) { Long count = this.kvstore.get(word); // 从存储中获取当前单词的计数 if(null == count){ this.kvstore.put(word, 1L); // 如果单词不存在,初始化为1 }else{ this.kvstore.put(word, count + 1L); // 如果单词存在,计数加1 } } } }; } // 定义处理器所需的状态存储 @Override public Set<StoreBuilder<?>> stores() { // 创建并返回一个内存键值存储构建器 return Collections.singleton(Stores.keyValueStoreBuilder( Stores.inMemoryKeyValueStore("counts"), // 存储名称 Serdes.String(), // 键的序列化器(字符串) Serdes.Long())); // 值的序列化器(长整型) } } } -
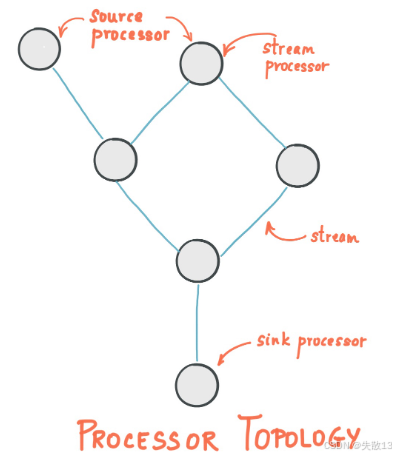
Kafka Streams 通过一系列
Processor处理节点构建数据处理链条,类似工厂流水线。有三种Processor处理节点:Source Processor:代表数据起点,直接读取一个或多个 Topic 中的数据,传递给下游Processor;- 普通
Processor:代表数据的一个处理节点,从上游Processor读取数据,处理后传递给下游Processor; Sink Processor:代表数据终点,从上游Processor读取数据后,输出到一个或多个 Topic 中;
-
这种基于
Processor的处理方式是流式计算的标准处理方式。Kafka Streams 是围绕 Kafka 构建的流式数据处理框架,若需要对接更多Source和Sink,或进行更大规模甚至集群化的数据计算,就需要更大型的流式计算框架(如 Spark Streaming、Flink),这些大型框架功能更丰富、性能更强,但基础流式计算思路与 Kafka Streams 一脉相承。